文章目錄
- 概要
- 1.下載模型
- 2.llama factory 訓練模型
- 2.1 模型微調
- 2.2 模型評估
- 2.3 模型對話
- 2.4 導出模型
- 3.硬件選擇
概要
LLaMA Factory 是一個簡單易用且高效的大型語言模型訓練與微調平臺。通過它,用戶可以在無需編寫任何代碼的前提下,在本地完成上百種預訓練模型的微調。
1.下載模型
在LLaMA Factory頁面中,選擇了模型后,可能是因為網絡原因,會導致加載模型失敗,這種情況可以通過把模型自己下載后,然后把模型路徑改為本地模型的路徑,來解決。
在模型平臺上下載模型,比如Hugging Face (https://huggingface.co)
或者采用modelscope,我這里采用modelscope。
pip install modelscopemodelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --local_dir /home/model/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
# 執行上述指令后,模型參數被下載至:/home/model/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B文件夾。[root@VM-0-9-tencentos DeepSeek-R1-Distill-Qwen-1.5B]# pwd
/home/model/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
[root@VM-0-9-tencentos DeepSeek-R1-Distill-Qwen-1.5B]# ls -hl
total 3.4G
-rw-r--r-- 1 root root 679 Sep 3 17:16 config.json
-rw-r--r-- 1 root root 73 Sep 3 17:16 configuration.json
drwxr-xr-x 2 root root 27 Sep 3 17:16 figures
-rw-r--r-- 1 root root 181 Sep 3 17:16 generation_config.json
-rw-r--r-- 1 root root 1.1K Sep 3 17:16 LICENSE
-rw-r--r-- 1 root root 3.4G Sep 3 17:20 model.safetensors
-rw-r--r-- 1 root root 16K Sep 3 17:16 README.md
-rw-r--r-- 1 root root 3.0K Sep 3 17:16 tokenizer_config.json
-rw-r--r-- 1 root root 6.8M Sep 3 17:16 tokenizer.json
[root@VM-0-9-tencentos DeepSeek-R1-Distill-Qwen-1.5B]# 2.llama factory 訓練模型
2.1 模型微調
在圖形化UI界面設置模型名稱、模型路徑和數據集,這里我以LLama-Factory中自帶的多模態數據集“mllm_demo”數據集為例:
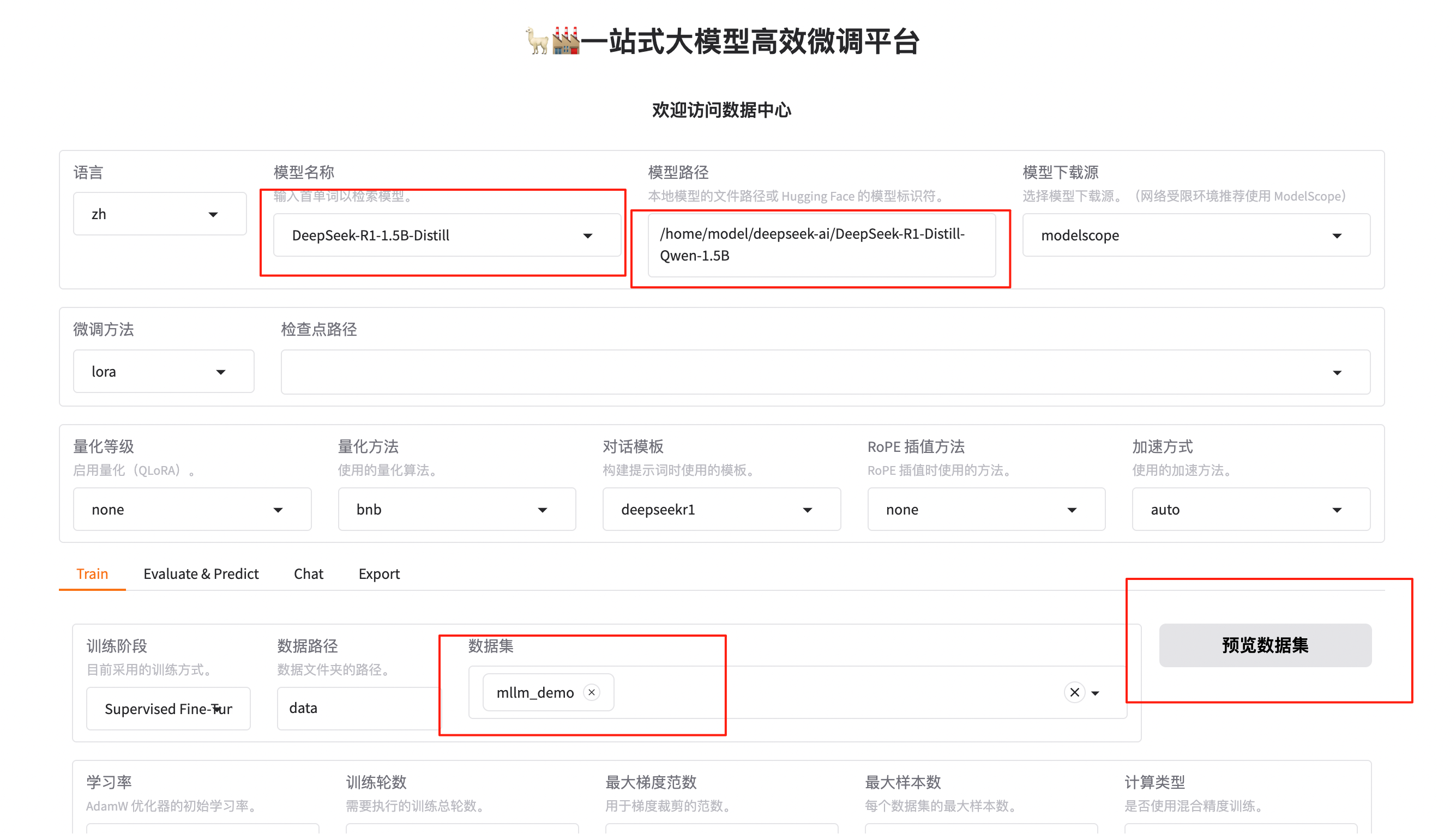
可以選擇預覽數據集,預覽數據結構:

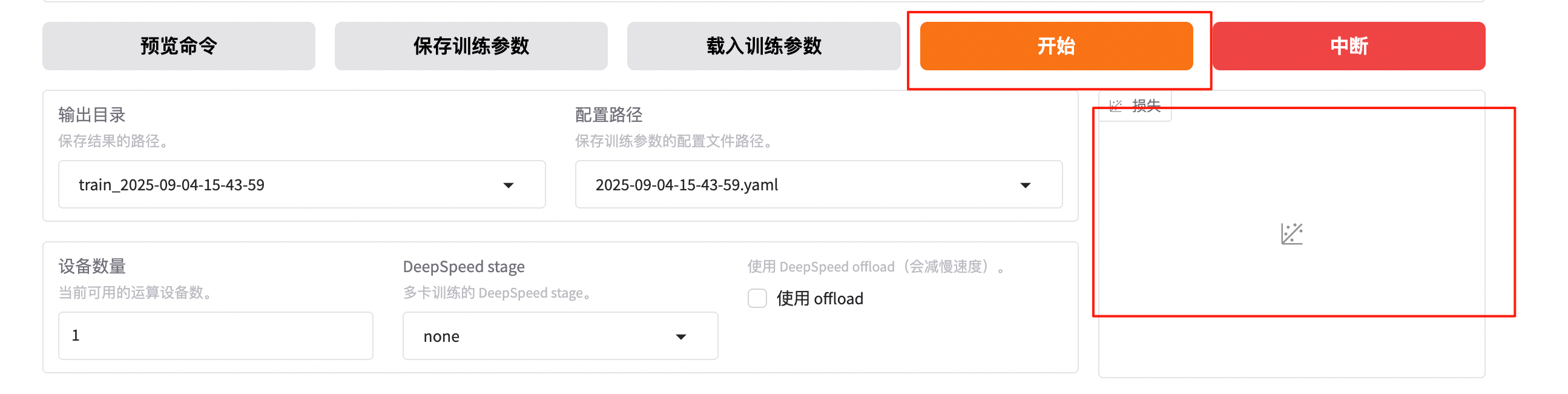
可以選擇預覽命令查看模型訓練的實際指令,輸出目錄可以選擇默認以時間戳命名的路徑,確認沒問題后點“開始”即可開始訓練.訓練時,在右下角可以實時查看loss下降的曲線,非常直觀和方便.
2.2 模型評估
-
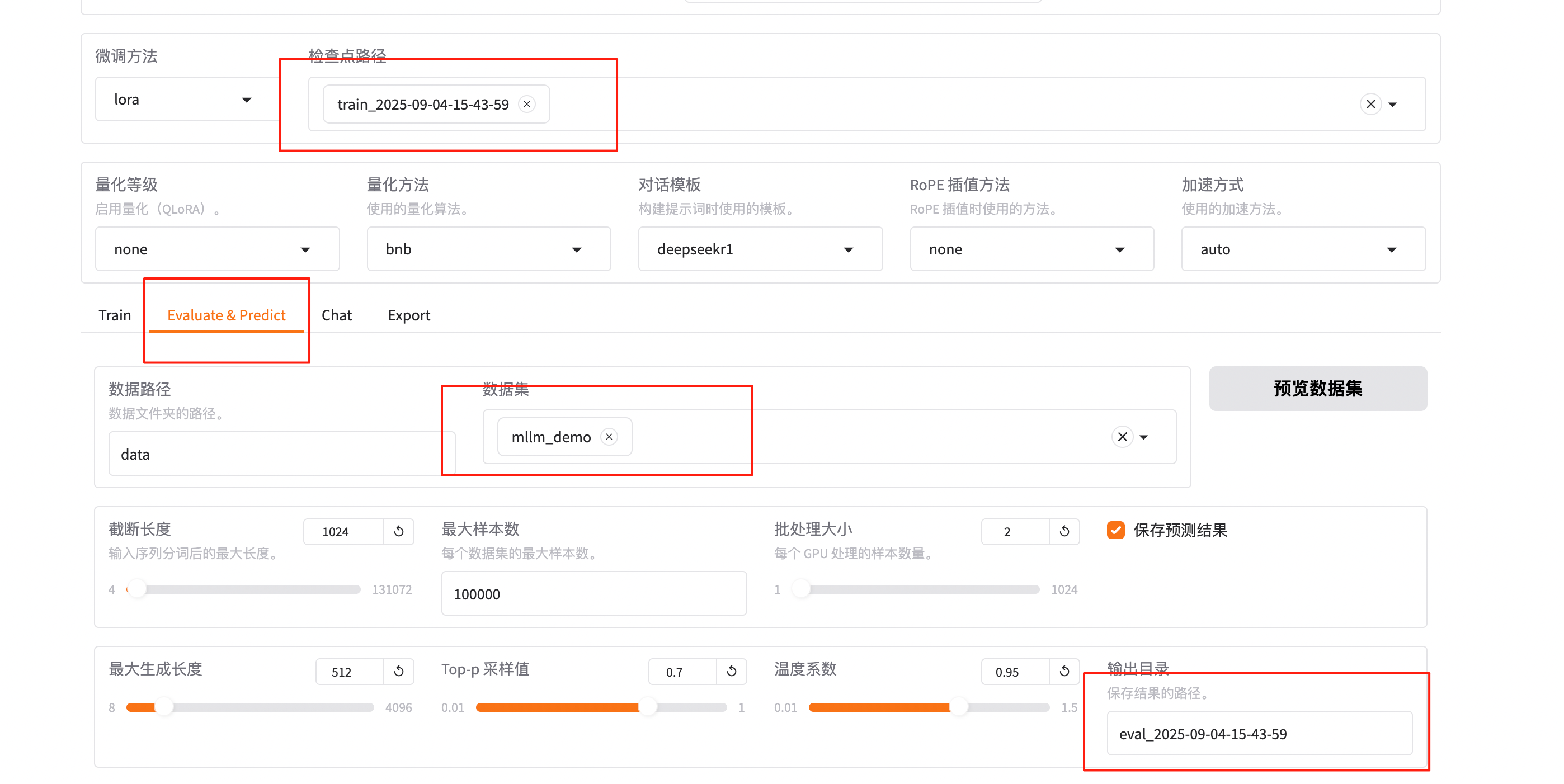
模型微調完成后,檢查點路徑下拉選擇train_2025-09-04-15-43-59。
-
在Evaluate&Predict頁簽中,數據集選擇mllm_demo(驗證集)評估模型,并將輸出目錄修改為eval_2025-09-04-15-43-59,模型評估結果將會保存在該目錄中。
-
單擊開始,啟動模型評估。模型評估大約需要5分鐘,評估完成后會在界面上顯示驗證集的分數。其中,ROUGE分數衡量了模型輸出答案(predict)和驗證集中的標準答案(label)的相似度,ROUGE分數越高代表模型學習得越好。

2.3 模型對話
訓練好以后可以設置檢查點路徑等參數:
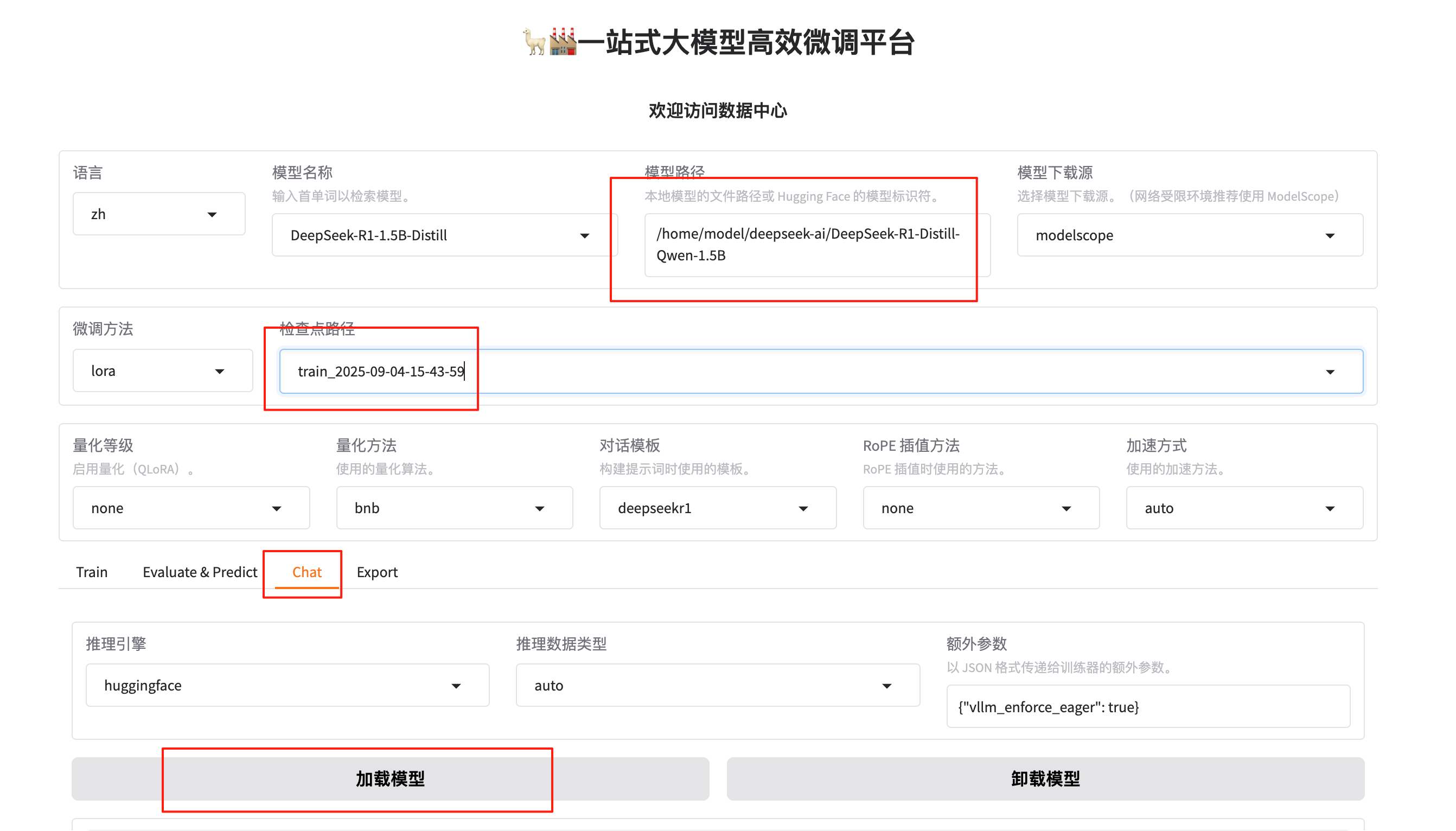
點擊加載模型,在頁面底部的對話框輸入想要和模型對話的內容,單擊提交,即可發送消息。發送后模型會逐字生成回答,從回答中可以發現模型學習到了數據集中的內容,能夠恰當地模仿目標角色的語氣進行對話。
單擊卸載模型和取消檢查點路徑,然后單擊加載模型,即可與微調前的原始模型聊天。你會發現提出同樣的問題,回答結果是不一樣的。
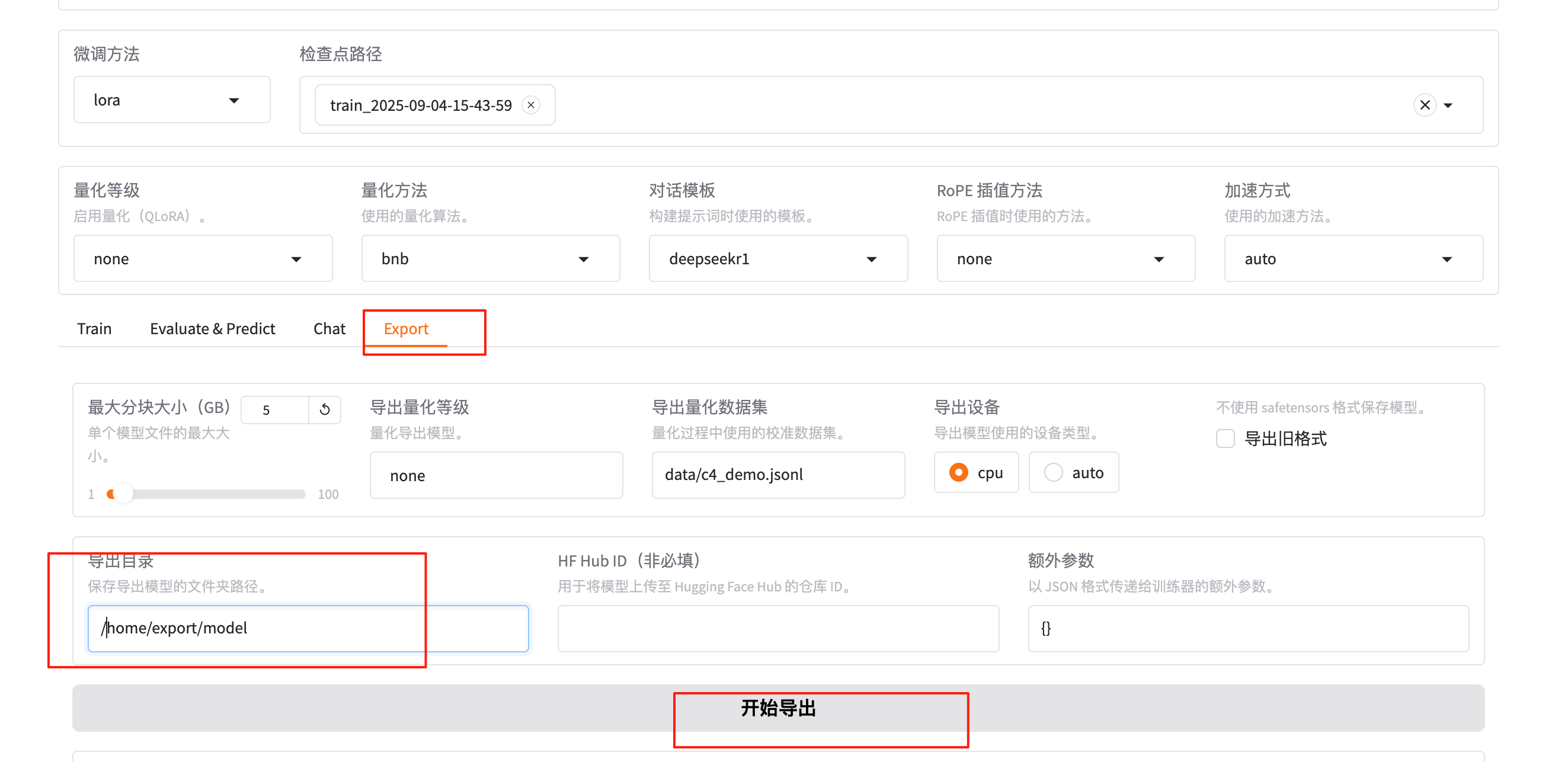
2.4 導出模型
訓練完成后,可以融合lora參數,導出作為一個新的模型。新的訓練好的模型參數結構和原來的模型(例如DeepSeek-R1-1.5B-Distill)結構一致。新的模型加載后,可以開始新的對話。
3.硬件選擇
可以采用第三方平臺或者接口實現DeepSeek會話,這里采用本地部署開源大模型。下面列出了不同大小的DeepSeek模型對應的顯存和內存需求。請根據你的顯卡配置和MacOS系統的內存選擇合適的模型。
?
| 模型大小? | 顯存需求(FP16 推理)? | 顯存需求(INT8 推理)? | 推薦顯卡? | MacOS 需要的 RAM? |
|---|---|---|---|---|
| 1.5b? | 3GB? | 2GB? | RTX 2060/MacGPU 可運行? | 8GB? |
| 7b? | 14GB?? | 10GB?? | RTX 3060 12GB/4070 Ti?? | 16GB?? |
| 8b? | 16GB?? | 12GB?? | RTX 4070/MacGPU 高效運行?? | 16GB?? |
| 14b?? | 28GB?? | 20GB?? | RTX 4090/A100-40G?? | 32GB? |
| 32b?? | 64GB?? | 48GB? | A100-80G/2xRTX4090?? | 64GB?? |
如果電腦的顯存不夠用,可以通過量化來減少對顯存的需求。量化就是把模型的參數從較高的精度(比如32位)轉換為較低的精度(比如8位),這樣可以節省顯存空間,讓你的電腦能夠運行更大的模型。舉個例子,如果你的電腦顯存是8GB,而你想使用7b參數的模型,但顯存不足,那么通過量化處理后,你就可以在不增加硬件的情況下,使用這個大模型。
如果你不確定自己是否需要量化,可以參考下面的顯卡顯存列表來判斷自己電腦的顯存是否足夠運行所需的模型。
| 顯存大小 | 顯卡型號 |
|---|---|
| 3GB | GTX 1060 3GB |
| 4GB | GTX 1050 Ti |
| 6GB | GTX 1060 6GB, RTX 2060 6GB, RTX 3050 (6GB) |
| 8GB | GTX 1080, GTX 1070 Ti, RTX 2080 SUPER, RTX 2080, RTX 2070 SUPER, RTX 2070, RTX 2060, RTX 2060 SUPER, RTX 3070, RTX 3070 Ti, RTX 3060 Ti, RTX 3060 (8GB), RTX 3050 (8GB), RTX 4080, RTX 4060 Ti, RTX 4060, RTX 5070 |
| 11GB | GTX 1080 Ti, RTX 2080 Ti |
| 12GB | GRTX 2060 12GB, RTX 3060 (12GB), RTX 4070 Ti SUPER, RTX 4070, RTX 5070 Ti |
| 16GB | RTX 4060 Ti 16GB, RTX 5080 |
| 24GB | RTX 3090 Ti, RTX 3090, RTX 4080, RTX 4090 |
| 32GB | RTX 5090 |
以上就是在 CentOS 上模型下載與訓練的基本步驟。如果你遇到任何問題,可以查看 LLaMA Factory 的 GitHub 倉庫中的文檔或尋求社區的幫助。















:StandardScaler)



