文章目錄
- HTTP協議
- 理解相關概念
- HTTP相關背景知識
- 認識URL
- HTTP協議在網絡通信的宏觀認識
- urlencode & urldecode
- HTTP請求和應答的格式
- 模擬實現瀏覽器訪問自定義服務器
- 關于http request
- http request的請求行——URI
- 使用瀏覽器完成靜態資源的訪問
- 常用的報頭屬性
- http response
- 狀態碼
- 重定向
- 重定向使用效果
- 簡單理解重定向的原理
- 理解請求方法
- HTTP的Header
HTTP協議
本篇文章,我們將來了解一下網絡中一種非常常用、也可以說是最常見的網絡協議——HTTP
對于協議,其實已經有一定的理解了!在網絡實踐的自定義協議實現網絡計算器已經大概知道了,應用層上的協議是如何進行定制并運行的:
詳情參考這篇文章:網絡實踐——自定義協議
應用層的協議是需要根據特定的需求來進行定制的。所以,這也就是為什么OSI七層模型中,上面三層是沒有辦法設置到內核中的。
這種應用協議,都是在應用層實現的。說到底,也就是程序員實現的!
這里,我們來理解一下關于HTTP協議:
在互聯網世界中,HTTP(HyperText Transfer Protocol,超文本傳輸協議),一個至關重要的協議。定義了客戶端(如瀏覽器)與服務器之間如何通信,以交換或傳輸超文本(如 HTML 文檔)。
這種協議都是由一些特別頂級的程序員進行設定編寫的!可以直接供其他人參考和使用:
HTTP 協議是客戶端與服務器之間通信的基礎。客戶端通過 HTTP 協議向服務器發送請求,服務器收到請求后處理并返回響應。HTTP 協議是一個==無連接、無狀態==的協議,即每次請求都需要建立新的連接,且服務器不會保存客戶端的狀態信息。
Tips:
這里存在著很多關于HTTP的相關概念,這里我們一下子也是解釋不清楚的!
后序我們將根據HTTP相關的知識來模擬實現HTTP協議通信的過程。邊寫代碼的同時,來理解其背后的相關原理和相關概念!!!
理解相關概念
這里我們先引入一些相關概念,就是便于后面編寫代碼的!我們不做理解。我們等到后序編寫代碼的時候可以再回頭理解這些理論知識!
HTTP相關背景知識
認識URL
我們來看這么一串網址:

首先,第一個部分http://,我們把它堪稱固定的一部分,這個是指示當前協議的。
第二個部分user:pass,這個是登陸的相關信息。不過有時候可以省略不出現。
第三個部分www.example.jp是域名!即我們要找的網址是哪一個!
第四個部分就是要訪問某網址對應服務器的端口號。
第五個部分,我們發現是一個帶層次的文件路徑!我們發現,以/分割路徑!
后面?部分,都是一些相關的參數。
我們現在直接看這個URL(網址),我們肯定是很懵的,不用擔心,這些我們后面都會進行講解!我們只需要知道的是,我們可以通過這么一串URL進行訪問網絡資源即可!
HTTP協議在網絡通信的宏觀認識
對于URL來說,雖然其可以被分為很多部分,但其實,最簡單的主體應該是:
https://服務器地址:端口號,甚至有些時候,端口號都不用!
然后,我們會有一個疑問?為什么只使用類似于www.example.com,瀏覽器就能夠自動的跳轉到正確的網址呢?

首先,對于這個服務器地址,其實還有另外一種我們很熟悉的叫法——域名!
比如前段時間www.ai.com,訪問該域名就訪問到了Deepseek!(現在被改了)
這里直接揭曉答案:
其實域名,就是服務器對應的IP地址!因為ip地址具有標識唯一地址性!
那么,我們是如何通過這樣一個域名來訪問對應的服務器呢?
首先,我們一般訪問服務器都是通過瀏覽器這個客戶端來進行訪問的!瀏覽器在接收到一個域名后,就會向域名解析器(這個地址瀏覽器能夠找的到,一般是被存儲在指定位置),然后通過域名解析器,將常見的域名轉化為其服務器對應的ip地址!
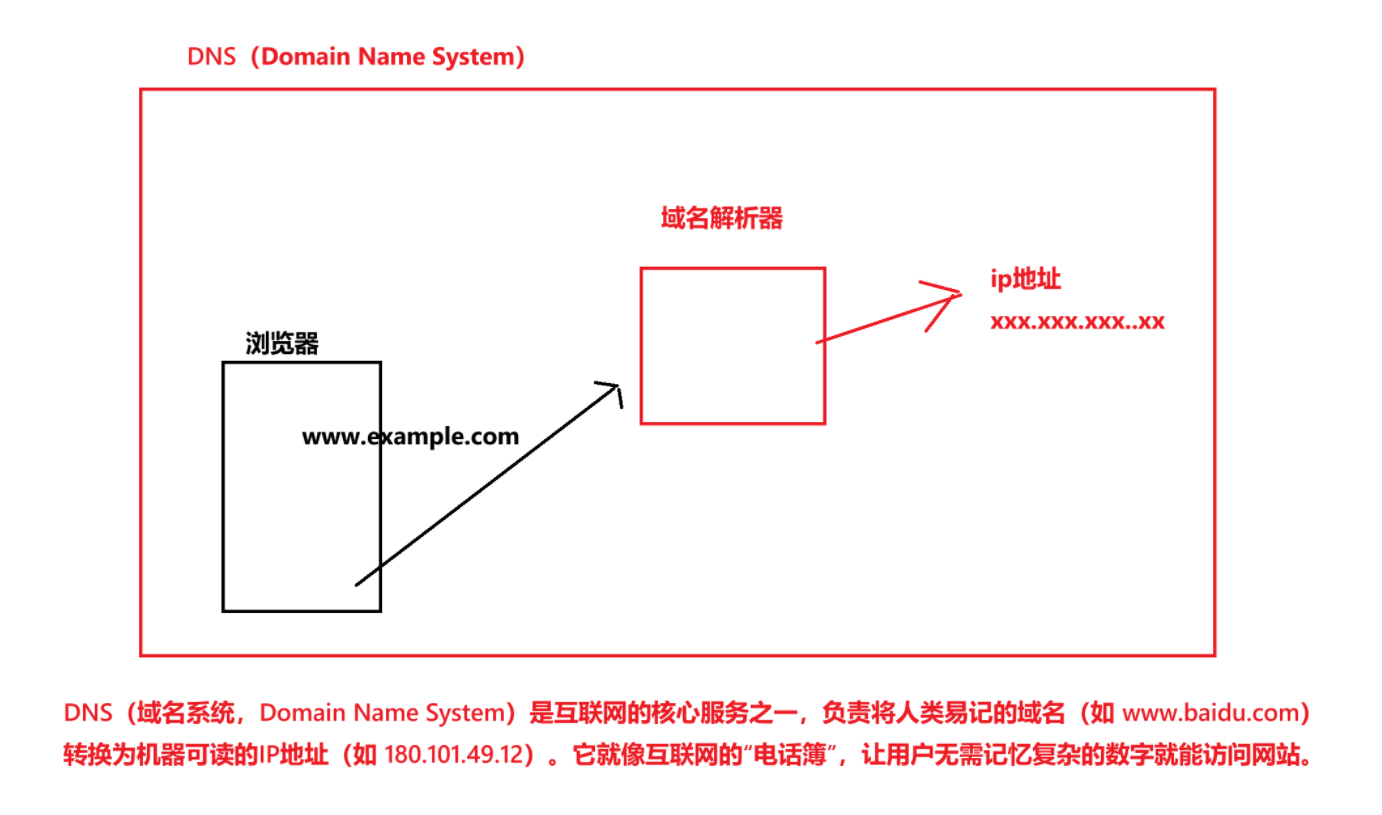
上述的過程,被叫做DNS系統,即域名系統。
這個域名解析器,其實是屬于基礎設施的!因為它非常重要!有一些大公司,如Google,他們會有自己的域名解析器,用于將域名快速轉化為ip地址!
提出一個問題: 為什么不直接使用ip地址呢?非要進行這么一層轉化?
因為使用域名更符合我們人類的閱讀,能夠見名思義!如www.baidu.com
直接使用ip地址其實是不太知道到底要訪問哪個服務器的,而且,最大的問題是,不方便記憶和使用。直接使用域名是非常方便的!
我們理解完了域名,還需要在理解使用HTTP通信相關資源:
我們知道:要訪問服務器,必須知道它的ip + port!(eg: ./tcpserver*.exe 8080)
我們上網的主要目的是什么?其實就兩大點:
1.從服務器中獲取資源(網頁、css、視頻、圖片、文本…)
2.把相關資源/數據上傳到服務器
本質上,我們上網,就是在拿著客戶端和服務器做IO操作罷了!
那么,我們訪問的資源存放在服務器哪里呢?我們要上傳的資源放在哪里呢?

答案就是在這個URL中可以體現到的帶層次的文件路徑!它是以/為分隔符的!
進一步了解:這樣一個以/為分隔符,有層次的文件路徑,我們在哪里見過呢?
答案就是我們學的Linux系統!所以,我們可以大致知道,大部分的URL中,帶層次的文件路徑都是以/作為分隔符的,所以,它們都是以Linux系統來運行服務器的!
(這和我們一開始學習Linux系統就說,Linux系統常用于企業中做服務器的觀點是相吻合的!)
這里還要提出一個問題:
我們已經知道文件路徑是Linux下的文件路徑,那么第一個/代表的是服務器的根目錄嗎?
答案:其實不是!這個不可能是Linux服務器的根目錄。我們想一下都知道,根目錄底下有很多重要的東西,企業是不可能隨便讓用戶訪問的!這個其實是要訪問的web根目錄!
這里不知道沒有關系,我們后面寫代碼的時候能知道!
訪問/上傳的資源都存在了對應的文件目錄下,所以,我們訪問的所有資源,都是文件!如視頻、網頁、音頻、文本… 它們都是文件,只不過是不同格式罷了!
所以,我們拿著瀏覽器訪問服務器,訪問/上傳資源,本質上就是IO操作!服務器是一個進程,我們使用的瀏覽器,作為客戶端,在我們的主機上也是一個進程!
這兩個進程是不同主機的,進行通信!這不就是網絡通信嗎?那就是使用socket進行通信!
而服務器是需要綁定確定的端口號的!但是,很多時候,我們并沒有輸入端口號,就能訪問到正確的網頁,這是為什么?
因為,成熟的協議,都是由固定的端口號的!
http:80
https:443
ssh:22
# 可以使用下面這條指令查詢ssh服務的固定端口號22
ynp@hcss-ecs-1643:~$ sudo netstat -tulnp | grep sshd # sshd,說明是ssh的守護進程版
但是,未來我們實現的服務器(簡單實現),是必須要輸入端口號的!因為我們綁定了一個具體的端口號。我們在不升級權限到root的情況下是沒有辦法綁定0~1023的端口號的!
urlencode & urldecode
有時候我們會發現,網址后面有一長串亂七八糟的東西:
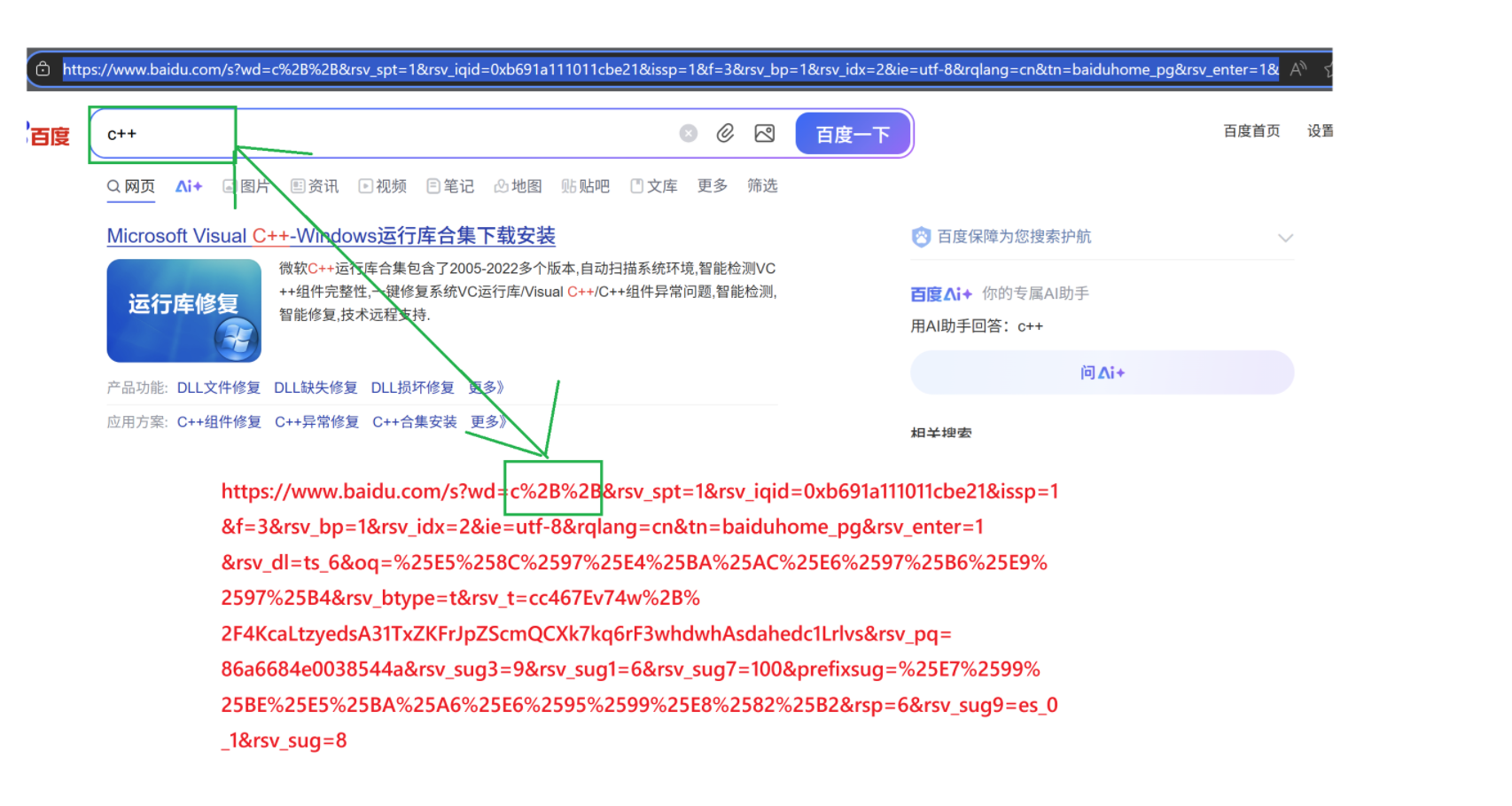
我們可以發現,我們輸入的內容,會被解析成其它的內容,如+ -> %2B。
這種情況都是出現在動態交互式的網站的!也就是返回一些動態處理的結果的場景!
其實是因為:
像/ ? :等字符,已經被url當做特殊意義理解了。因此這些字符不能隨意出現。
比如,某個參數中需要帶有這些特殊字符,就必須先對特殊字符進行轉義。
轉義的規則如下:
將需要轉碼的字符轉為16進制,然后從右到左,取4位(不足4位直接處理),每2位做一位,前面加上%,編碼成%XY格式。
比如+,ASCII:43,HEX:0x2B,從右到左取四位(不足直接操作) -> %2B
這個過程,其實就是給報文進行encode的過程。然后發送回來給我們看的,是decode后的。這點我們只需要了解一下就好了!我們不需要深入了解。
這里看這個網址能不能幫助實現url對應編碼解碼:urlencode & urldecode工具(不一定能用!)
HTTP請求和應答的格式
上面,我們是基本了解清楚了,基于HTTP的相關通信過程、本質、方式。
但是,這里學習的是HTTP協議!而且是一個應用層的協議!
我們是自行實現過這種協議的——網絡版本計算器。
我們在協議中,定義了請求、應答,通信的雙方就是基于特定的協議來進行網絡通信!
這里的HTTP也是一樣的,我們來看一下它們的請求和應答的格式:
HTTP請求:
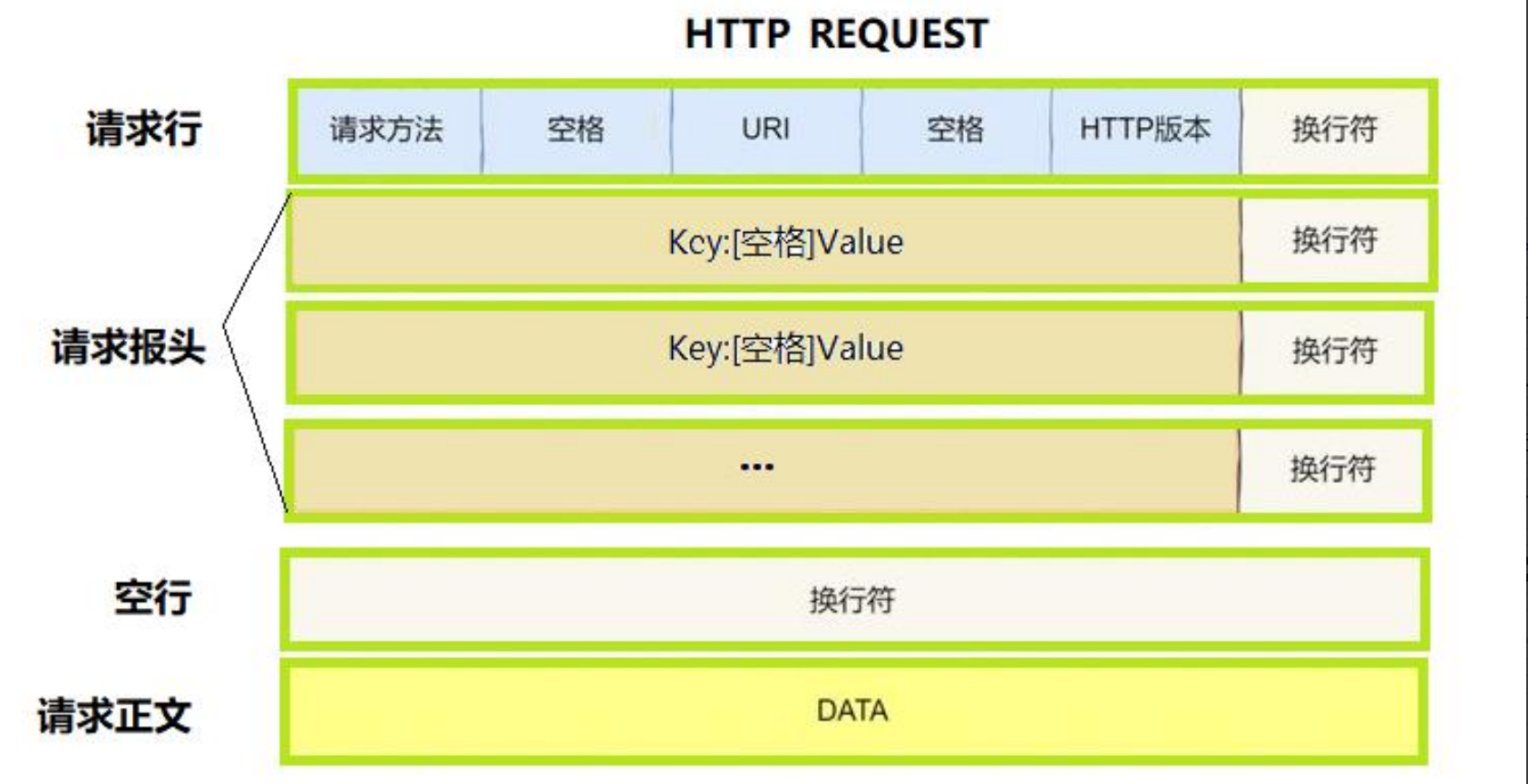
HTTP應答:

中間的報頭部分,都是一對對的key&value形式鍵值對,中間以:[空格]作為分割!
這里我們需要厘清幾個細節,方便后序理解:
首先,這個請求和應答的本質是什么?就是個結構體,協議不就是結構化的數據嗎?
但是,真正在網絡中傳輸的呢?
因為需要兼容多平臺,所以不可能直接傳結構化的數據的!所以,這就需要使用到序列化和反序列化的概念,所以,我們是否可以把上面的協議和請求看成一個大字符串?答案是可以!
這里也是提出幾個問題:
1.這個協議,報頭和有效載荷如何分離?
2.不同行之間如何分割?
3.序列化和反序列化誰來做?
回答這三個問題非常簡單:
1.在HTTP請求和應答中,我們發現都會有一行空行。所以,要進行分離有效載荷和報頭的分離是很簡單地,以空行作為分割即可。
2.不同行之間,都是通過換行符來進行分割的。提取一行是很簡單的事情。
3.序列化和反序列化,肯定是在應用層來做!這個我們是非常熟悉的了。
模擬實現瀏覽器訪問自定義服務器
這里我們直接給出整份源碼先,然后根據這一份代碼來進行相關講解:HTTP模擬
今天我們就使用HTTP協議來手搓一個簡單地服務器,旨在理解HTTP背后的相關原理。
我們前面并沒有將HTTP中其它的原理,只認識了請求和應答。但是沒有關系,我們后序都會通過寫代碼的形式來進行理解原理!
今天這里,我們不需要寫客戶端了!我們只需要寫服務器就可以了!因為我們其實已經有現成的基于HTTP/HTTPS協議通信的客戶端——瀏覽器。我們只需要拿著瀏覽器訪問即可!
關于http request
我們現在只是知道了http request的格式,但是并沒有見過真的,我們可以來看一下:
這里我們只展示此時添加新的代碼,其余的都是以前封裝的組件之類的。
Http.hpp:
#pragma once
#include <memory>
#include <unordered_map>
#include <sstream>
#include <fstream>
#include <functional>
#include "Common.hpp"
#include "TcpServer.hpp"
#include "Util.hpp"
#include "Log.hpp"const std::string space = " ";
const std::string line_break = "\r\n";
const std::string headers_sep = ": ";using namespace myLog;const std::string webroot = "./wwwroot";
const std::string homepage = "index.html";
const std::string page_404 = "404.html";//這里要說明的是:Http協議,是不依賴于第三方庫進行序列化和反序列化的!//Http請求格式
class HttpRequest{
public:HttpRequest():_blank_line(line_break),_is_interact(false),_args(""){}~HttpRequest(){}//其實,今天來說,客戶端是瀏覽器!我們可以直接拿瀏覽器來訪問我們寫的服務器。所以,請求的序列化寫不寫都可以!
//但是就不寫了,就留一個方法
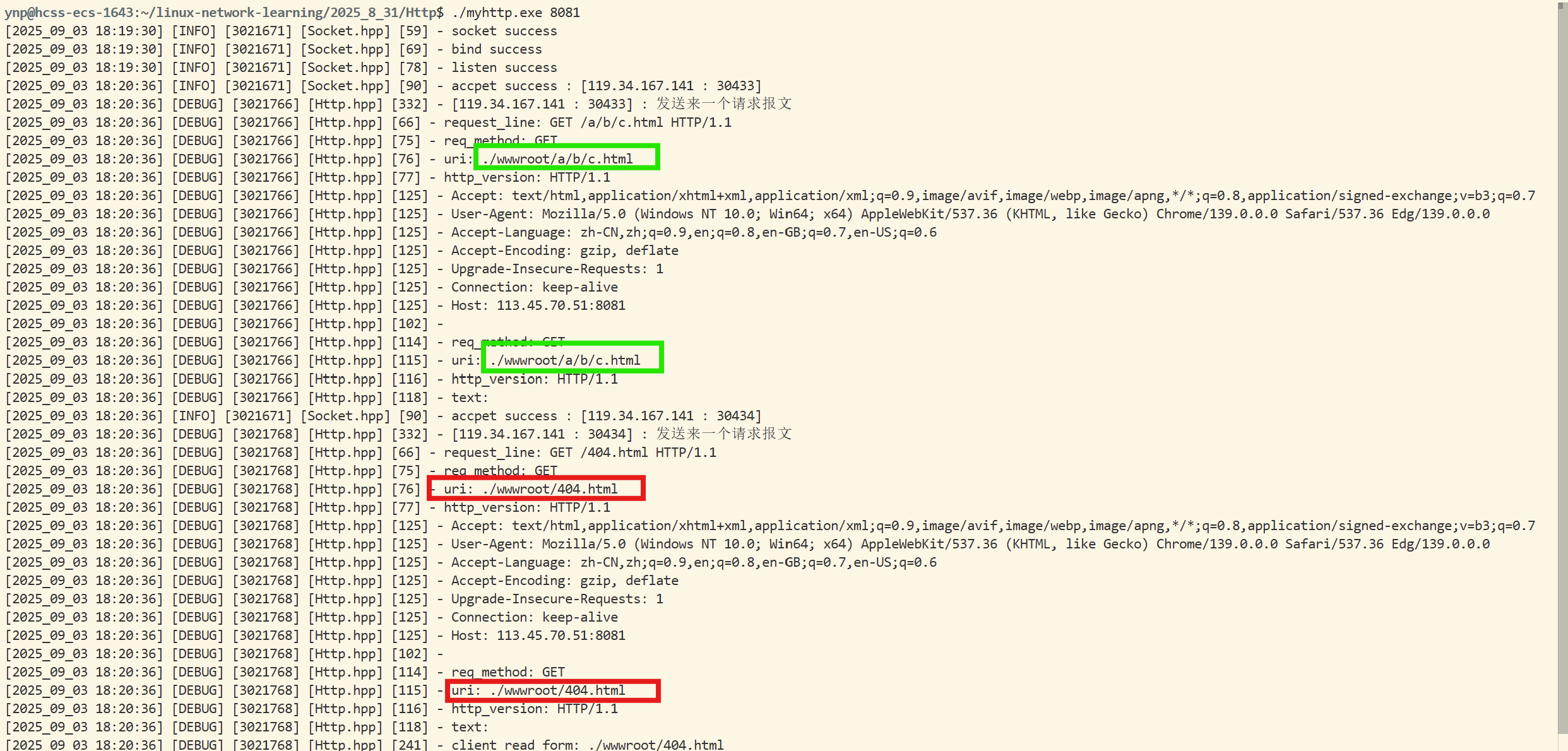
//因為http協議已經有固定的序列化方式和反序列化格式了!std::string Serialize(){return "";}void ParseRequestLine(std::string& request_line){std::stringstream ss(request_line);//以空格作為分隔符,將字符串分割后依次插入對應的字段ss >> _req_method >> _uri >> _http_version;}bool GetKV_AndSet(std::string headline){//key: valuesize_t pos = headline.find(headers_sep);if(pos == std::string::npos) return false;std::string key = headline.substr(0, pos);std::string value = headline.substr(pos + headers_sep.size());_headers[key] = value;return true;}//反序列化還是要寫的bool DeSerialize(std::string& req_str){//1.提取請求行std::string request_line;Util::ReadOneLine(req_str, &request_line, line_break);LOG(LogLevel::DEBUG) << "request_line: " << request_line;//2.把請求行放入到對應的字段 -> 使用stringstreamParseRequestLine(request_line);//這里要注意,uri對應的就是要訪問的服務器上對應的資源if(_uri == "/") _uri = webroot + _uri + homepage;else _uri = webroot + _uri; LOG(LogLevel::DEBUG) << "req_method: " << _req_method;LOG(LogLevel::DEBUG) << "uri: " << _uri;LOG(LogLevel::DEBUG) << "http_version: " << _http_version;if(_req_method == "POST" || _req_method == "post") _is_interact = true;//3.把報頭提取出進行分析std::string header_line;Util::ReadOneLine(req_str, &header_line, line_break);//到這里都正常//只要不是讀出來 "",就表明還是報頭 while(header_line != ""){//此時讀到了一行 -> key: value(正常來說,如果是空行讀出來就是 "")GetKV_AndSet(header_line);header_line.clear();Util::ReadOneLine(req_str, &header_line, line_break);}//此時讀到了空行就退出循環了,并且ReadOneLine中已經把讀到的給刪除了DebugHeaders();//如果使用POST來進行傳參,那么參數在正文,這里就不管了//req_str剩下的就是正文了!_text = req_str;LOG(LogLevel::DEBUG) << _text;//如果使用GET方法傳內容給服務器,那么參數在uri上,所以得對uri作進一步解析std::string tmp = "?";auto pos = _uri.find(tmp);if(pos != std::string::npos) {// /login?username=adasdad&password=adaadsasd_args = _uri.substr(pos + tmp.size());//截取參數_uri = _uri.substr(0, pos);//獲取真正的服務!_is_interact = true;}LOG(LogLevel::DEBUG) << "req_method: " << _req_method;LOG(LogLevel::DEBUG) << "uri: " << _uri;LOG(LogLevel::DEBUG) << "http_version: " << _http_version;if(_args != "") LOG(LogLevel::DEBUG) << "uri args: " << _args;LOG(LogLevel::DEBUG) << "text: " << _text;return true;}void DebugHeaders(){for(auto& head : _headers){LOG(LogLevel::DEBUG) << head.first << headers_sep << head.second;}}std::string GetUri(){return _uri;}std::string GetText(){return _text;}bool Is_Interact(){return _is_interact;}std::string GetArgs(){return _args;}
private:std::string _req_method;std::string _uri;std::string _http_version;std::unordered_map<std::string, std::string> _headers;std::string _blank_line;std::string _text;bool _is_interact;//判斷是否有交互 -> 后序來實現交互功能(如登錄請求...) /login /registerstd::string _args;//參數(如果使用GET方法,參數會被設置到_uri上)
};//Http應答格式
class HttpResponse{
public:HttpResponse():_blank_line(line_break),_http_version("/HTTP/1.0"){}~HttpResponse(){}std::string Serialize(){std::string status_line = _http_version + space + std::to_string(_status_code) + space + _code_description + line_break;std::string head_line;for(auto& head : _headers){std::string oneline = head.first + headers_sep + head.second + line_break;head_line += oneline;}return status_line + head_line + _blank_line + _text;}//今天來講,反序列化Response是客戶端做 -> 瀏覽器做,我們不需要寫bool DeSerialize(){return true;}void SetTargetFile(const std::string target_file){_target_file = target_file;}void SetCodeAndDesc(int code){_status_code = code;switch(code){case 404:_code_description = "Not Found";break;case 200:_code_description = "OK";break;case 301:_code_description = "Moved Permanently";break;case 302:_code_description = "See Other";break;default:break;}}std::string UriToSuffix(const std::string uri){auto pos = uri.rfind(".");if(pos == std::string::npos) return "text/html";std::string suffix = uri.substr(pos);MimeTypes mime;return mime.getMimeType(suffix);}void SetHeaders(const std::string& key, const std::string& value){if(_headers.find(key) != _headers.end()) return;_headers.emplace(key, value);}bool MakeResponse(){bool res = Util::ReadFileContent(_target_file, &_text);int text_size = 0;//正文長度,后序設置長度Content-Lengthif(!res){#ifdef TWO//這里可以嘗試試用一下重定向的方式,設置狀態碼301 / 302//SetCodeAndDesc(301); //永久重定向SetCodeAndDesc(302); //短暫重定向SetHeaders("Location", "/404.html");
#endif#define ONE
#ifdef ONELOG(LogLevel::DEBUG) << "client want get" << _target_file << "but not found";_text = "";SetCodeAndDesc(404);_target_file = webroot + "/" + page_404;text_size = Util::GetFileSize(_target_file);Util::ReadFileContent(_target_file, &_text);//此時讀到了內容(404page)就放到正文內了!//然后需要設置一些字段進入到報頭中(這里就先只設置兩個)std::string content_type = UriToSuffix(_target_file);SetHeaders("Content-Type", content_type);SetHeaders("Content-Length", std::to_string(text_size));
#endif }else{LOG(LogLevel::DEBUG) << "client read form: " << _target_file;SetCodeAndDesc(200);text_size = Util::GetFileSize(_target_file);std::string content_type = UriToSuffix(_target_file);SetHeaders("Content-Type", content_type);SetHeaders("Content-Length", std::to_string(text_size));}return true;}void SetText(std::string& text){_text = text;}//為了方便服務端使用,這里的應答相關字段就用public修飾了。要不然進行修改的時候很麻煩!
public:std::string _http_version;int _status_code;std::string _code_description;std::unordered_map<std::string, std::string> _headers;std::string _blank_line;std::string _text;std::string _target_file;//要訪問的資源 -> 以便后序方便輸入正文!
};using http_route_t = std::function<void(HttpRequest&, HttpResponse&)>;class Http{
public:Http(uint16_t port):_server(std::make_unique<TcpServer>(port)){}~Http(){}bool RegisterRoute(std::string func_name, http_route_t func){//如(/login, Login)func_name = webroot + func_name; //./wwwroot/loginif(_route.find(func_name) == _route.end()){//該任務不存在于表中 -> 可以插入 //這里就規定,插入的名字就是傳入func的對應的小寫auto it = _route.emplace(func_name, func);return it.second;}return false;}//這里就默認都是找的到的!bool AnalyseRequestLine(std::string& reqline, const std::string& key, std::string* value){//從請求行報文中,根據key讀取對應的valuesize_t key_pos = reqline.find(key);//key_pos為key字符子串的起始位置if(key_pos == std::string::npos) return false;size_t value_pos = key_pos + key.size() + headers_sep.size();//value_pos為value字符子串的起始位置size_t value_end = reqline.find(line_break, value_pos);//從value_pos開始找"\r\n"if(value_end == std::string::npos) return false;*value = reqline.substr(value_pos, value_end - value_pos);return true;}bool ReadAllRequestHeader(std::string& inbuffer, std::string* text){//我們已經有了從一個大字符串中,切割字符串的能力了//這里的大報文都是以"\r\n"作為分割的,我們讀取的時分隔符前面的//所以,我們可以一直讀取,直到讀到空行了,能得到完整的報頭!//header內有一個屬性:Content-length,其存儲的時正文的長度!std::string oneline;//報文可能有若干情況://四分之一條,半條、一整條,多條...//但是,今天是一個客戶端對應一個進程 -> 發送來多條那就可能是客戶端多次請求//這里一次只弄一條出來!while(Util::ReadOneLine(inbuffer, &oneline, line_break)){//只要為真,就說明還有"\r\n"可以讀到,就還有機會出現空格*text += oneline + line_break;if(oneline == "") return true;oneline.clear(); }return false;}//這里不寫死循環了,只做短服務void HandleHttpRequest(std::shared_ptr<Socket> socket, const InetAddr& client){//大概率是能讀到至少一個完整報文的!std::string readbuffer;int n = socket->Recv(&readbuffer);//但是,這里怎么能夠保證報文的完整性呢? -> 在Netcal那里實現過,這里模擬一下//這里只需要實現Decode即可,因為前面已經有一堆的字段了(已經具備Encode了)!(有效載荷在blank_line后面)if(n > 0){LOG(LogLevel::DEBUG) << client.GetFormatStr() << ": 發送來一個請求報文";//首先,得保證讀到完整的請求->如果這一次沒能成功讀到完整請求,就不進行處理了!std::string all_reqline;if(ReadAllRequestHeader(readbuffer, &all_reqline) == false) return;//讀到完整的請求報頭 -> all_reqline//all_reqline里面有一個字段是指向正文長度的(前提是,Http請求中,正文部分長度 > 0,要不然其實是看不到的!)//如果發送來的正文長度 == 0,看不到這個字段!std::string text_len;if(AnalyseRequestLine(all_reqline, "Content-Length", &text_len) == false) text_len = "0";//成功讀取長度到text_len -> 需要轉成整數int len = std::stoi(text_len);//讀取正文(從readbuffer中, 長度為len)if(readbuffer.size() < len) return; //正文長度不對!std::string text = readbuffer.substr(0, len);std::string req_str = all_reqline + text;//反序列化HttpRequest hreq;hreq.DeSerialize(req_str);//應答對應的協議結構HttpResponse hresp;//今天這里加多一步,反序列化后,就需要知道當前是否需要進行交互了if(hreq.Is_Interact()){//需要進行交互std::string service_name = hreq.GetUri();//但是,這個服務可能不存在于_route表中if(_route.find(service_name) == _route.end()){//重定向到對應的404網頁hresp.SetCodeAndDesc(301);hresp.SetHeaders("Location", "/404.html");socket->Send(hresp.Serialize()); }else{_route[service_name](hreq, hresp);std::string res_str = hresp.Serialize();socket->Send(res_str);}return;}//如果不需要進行交互訪問,只訪問靜態資源,就走原來的邏輯!//分析請求 + 制作應答//反序列化的時候,已經把要訪問的web根目錄底下的文件進行處理了!hresp.SetTargetFile(hreq.GetUri());hresp.MakeResponse();//應答進行序列化std::string resp_str = hresp.Serialize();//發送應答socket->Send(resp_str);}//用來測試是否能讀到報文并反序列化/* HttpRequest req;req.DeSerialize(readbuffer); */}void HttpServerInit(){_server->Init();}void HttpServerStart(){_server->Run([this](std::shared_ptr<Socket> socket, const InetAddr& client){this->HandleHttpRequest(socket, client);});}private:std::unique_ptr<TcpServer> _server;std::unordered_map<std::string, http_route_t> _route;
};
Util.hpp:
#pragma once
#include <fstream>
#include "Common.hpp"
#include "Log.hpp"using namespace myLog;//用來實現一些常用的方法 -> 全是靜態成員函數
class Util{
public:
//從字符串str中,讀取出sep前面的串(不包含sep!!!!!),帶出去給outbufferstatic bool ReadOneLine(std::string& str, std::string* outbuffer, const std::string sep){size_t pos = str.find(sep);if(pos == std::string::npos) return false;else{*outbuffer = str.substr(0, pos);str.erase(0, pos + sep.size());return true;}}//獲取某個文件的大小static int GetFileSize(const std::string& file_path){std::ifstream in(file_path, std::ios::binary);if(!in.is_open()) return -1;in.seekg(0, in.end);int filesize = in.tellg();in.seekg(0, in.beg);in.close();return filesize;}//以二進制方式,把文件內的內容以字節流方式讀取出來!!!static bool ReadFileContent(const std::string& file_path, std::string* out){//這里不能單純的使用文本讀取!應當使用二進制讀取 -> 因為可能有圖片,有視頻...這些都是二進制的std::ifstream in(file_path);if(!in.is_open()) return false;//這個時候就知道,大致有多少二進制數據要被讀取出來了 -> 可以獲取文件的字節數int readsize = GetFileSize(file_path);if(readsize <= 0) return false; out->resize(readsize);//使用二進制讀取in.read((char*)out->c_str(), readsize);in.close();return true;}private:
};//這里搞多一個類,以便于Content-Type字段使用
class MimeTypes {
private:std::unordered_map<std::string, std::string> mimeTypes;public:MimeTypes() {// 初始化常用 MIME 類型// 文本類型mimeTypes[".txt"] = "text/plain";mimeTypes[".html"] = "text/html";mimeTypes[".htm"] = "text/html";mimeTypes[".css"] = "text/css";mimeTypes[".js"] = "text/javascript";mimeTypes[".csv"] = "text/csv";mimeTypes[".xml"] = "text/xml";// 圖像類型mimeTypes[".jpg"] = "image/jpeg";mimeTypes[".jpeg"] = "image/jpeg";mimeTypes[".png"] = "image/png";mimeTypes[".gif"] = "image/gif";mimeTypes[".svg"] = "image/svg+xml";mimeTypes[".webp"] = "image/webp";mimeTypes[".ico"] = "image/x-icon";// 應用程序類型mimeTypes[".json"] = "application/json";mimeTypes[".pdf"] = "application/pdf";mimeTypes[".zip"] = "application/zip";mimeTypes[".doc"] = "application/msword";mimeTypes[".docx"] = "application/vnd.openxmlformats-officedocument.wordprocessingml.document";// 多媒體類型mimeTypes[".mp3"] = "audio/mpeg";mimeTypes[".ogg"] = "audio/ogg";mimeTypes[".mp4"] = "video/mp4";mimeTypes[".mov"] = "video/quicktime";mimeTypes[".avi"] = "video/x-msvideo";// 字體類型mimeTypes[".woff"] = "font/woff";mimeTypes[".woff2"] = "font/woff2";mimeTypes[".ttf"] = "font/ttf";mimeTypes[".otf"] = "font/otf";}// 根據文件擴展名獲取 MIME 類型std::string getMimeType(const std::string& fileExtension) const {auto it = mimeTypes.find(fileExtension);if (it != mimeTypes.end()) {return it->second;}// 默認返回二進制流類型return "application/octet-stream";}// 添加自定義 MIME 類型void addMimeType(const std::string& fileExtension, const std::string& mimeType) {mimeTypes[fileExtension] = mimeType;}
};今天的調用邏輯是:
Http類底層包含著一個TCP服務器,今天我們就寫一個短連接服務!
每次接收到一個請求,我們就讓TCP服務器回調Http類中的HandleHttpRequest
方法,這樣子,就完成了服務器端和應用層的解耦!
HandleHttpRequest接收請求,然后對其反序列化、分析、制作應答、序列化后在發送給客戶端瀏覽器進行解析展示即可!
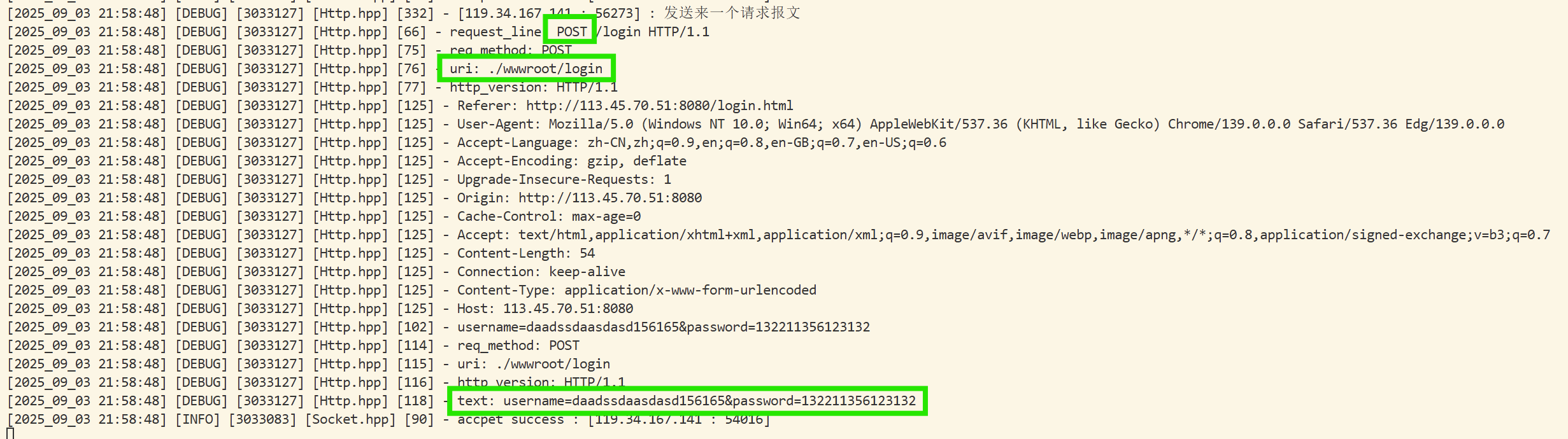
到這里,我們就想要做一件事情:看一下真正的http request到底是長什么樣子:
啟動服務器,然后再瀏覽器的URL搜索框中輸入:服務器主機ip:綁定端口號
(其實就是直接把服務器從套接字收到的字節流提取出來然后打印!)這個我沒有在展示的代碼中體現,自己加上去看一下就可以了!
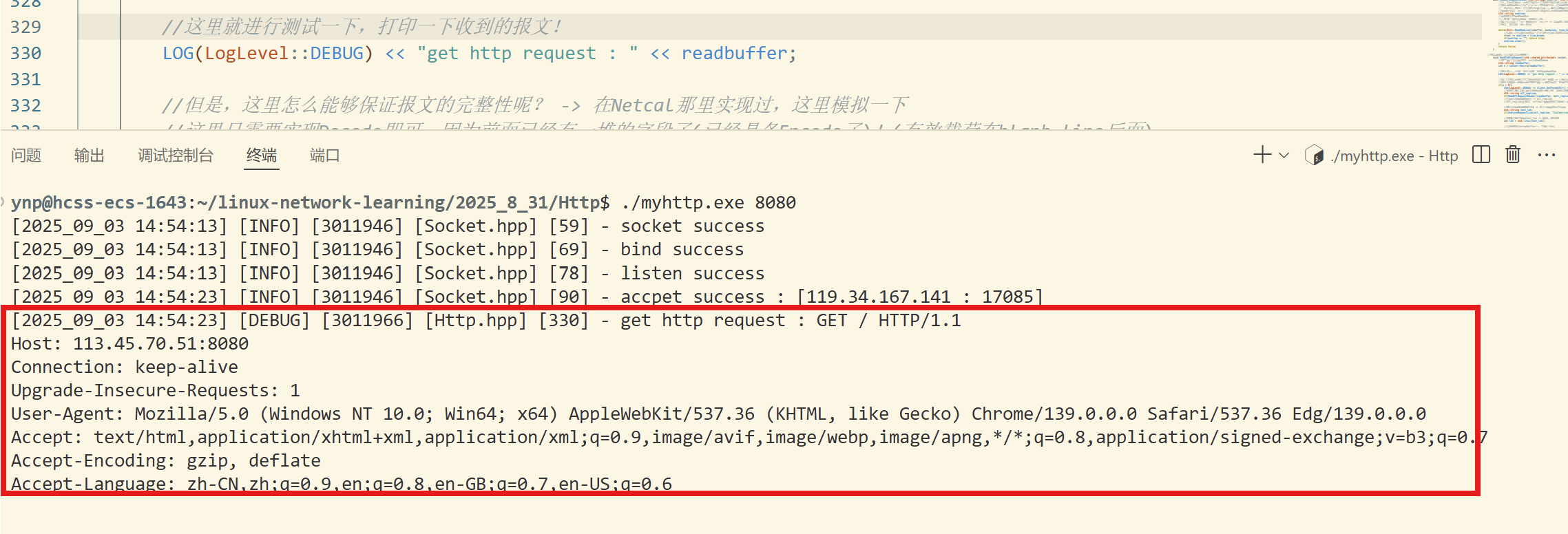
我們可以發現,確實是有這么樣的一個請求協議:
GET / HTTP/1.1
Host: 113.45.70.51:8080
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36 Edg/139.0.0.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6注意,這里操作的方式并沒有通過客戶端向服務器傳輸資源,所以正文部分是空的,所以,我們可以看到打印出來是有兩行的空行的!
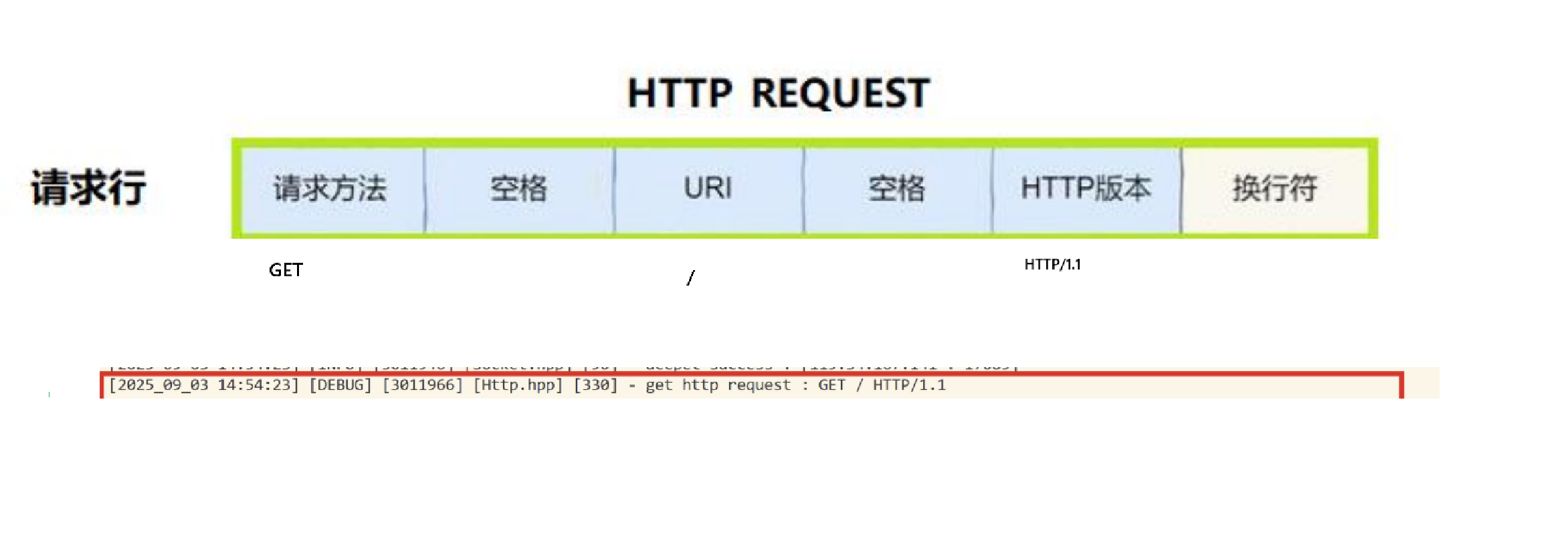
第一行是請求行,中間以空格作為分隔符。
中間就是以key&value形式的鍵值對,就是相關的報頭屬性!
空行作為完整請求報頭和有效載荷的分割符號。
這里正文是空的,所以看起來也是空行!
至此,我們就切實感受到了協議是長什么的!后序,我們將根據我們對協議的認識,以及HTTP協議的原理,來進行相關代碼編寫和結論的認證!
http request的請求行——URI
這里我們先不講請求方法,也先不講HTTP版本,這些都是客戶端發來的。這些我們后序一開始寫代碼的時候不用太過關注。
但是,請求行的第二個位置,URI,這是一個非常重要的部分!
URI就是我們前面所說的:一個帶有層次的文件路徑。
這里就是單純的一個/,前面說了,這個訪問的是web根目錄,是什么意思呢?
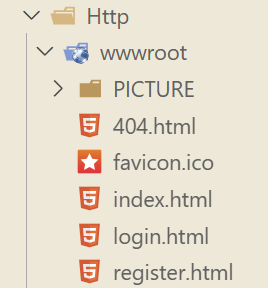
我這里直接展示我的代碼結構了,一看就明白:

所以,這里的URI就是我們當前服務器中,存儲資源的目錄!
后序,我們將讓AI形成若干網頁,我們就可以實現通過瀏覽器來訪問我們自己的服務器了。
使用瀏覽器完成靜態資源的訪問
我們需要先來了解一下,什么是靜態資源?
比如我們今天存放在服務器指定目錄下的文本、音頻、網頁,這些都是靜態資源!這些是不涉及客戶端和服務端的動態交互的。就是申請對應的資源并返回。
我們先把靜態資源訪問的邏輯寫完,到時候再來補充動態交互的內容(如登錄、注冊)!
我們今天就實現簡單地短服務!即底層的TCP服務器,accept到一個客戶端后,回調處理對應的請求,然后就結束,關閉套接字!下次客戶端要訪問就得重新connect!
代碼主邏輯:
void HandleHttpRequest(std::shared_ptr<Socket> socket, const InetAddr& client){//大概率是能讀到至少一個完整報文的!std::string readbuffer;int n = socket->Recv(&readbuffer);//但是,這里怎么能夠保證報文的完整性呢? -> 在Netcal那里實現過,這里模擬一下//這里只需要實現Decode即可,因為前面已經有一堆的字段了(已經具備Encode了)!(有效載荷在blank_line后面)if(n > 0){LOG(LogLevel::DEBUG) << client.GetFormatStr() << ": 發送來一個請求報文";//首先,得保證讀到完整的請求->如果這一次沒能成功讀到完整請求,就不進行處理了!std::string all_reqline;if(ReadAllRequestHeader(readbuffer, &all_reqline) == false) return;//讀到完整的請求報頭 -> all_reqline//all_reqline里面有一個字段是指向正文長度的(前提是,Http請求中,正文部分長度 > 0,要不然其實是看不到的!)//如果發送來的正文長度 == 0,看不到這個字段!std::string text_len;if(AnalyseRequestLine(all_reqline, "Content-Length", &text_len) == false) text_len = "0";//成功讀取長度到text_len -> 需要轉成整數int len = std::stoi(text_len);//讀取正文(從readbuffer中, 長度為len)if(readbuffer.size() < len) return; //正文長度不對!std::string text = readbuffer.substr(0, len);std::string req_str = all_reqline + text;//反序列化HttpRequest hreq;hreq.DeSerialize(req_str);//應答對應的協議結構HttpResponse hresp;//分析請求 + 制作應答//反序列化的時候,已經把要訪問的web根目錄底下的文件進行處理了!hresp.SetTargetFile(hreq.GetUri());hresp.MakeResponse();//應答進行序列化std::string resp_str = hresp.Serialize();//發送應答socket->Send(resp_str);}
上述就是主邏輯。很多接口就是完成具體任務的。這里不講解實現,只講功能!
1.讀取到客戶端的報文后,服務器不能立馬反序列化!因為沒有辦法保證當前讀到的是一個完整的http request請求報文!所以,我們需要做一步工作,確保讀到的報文正確!
如何保證讀到的報文完整呢?
1.我們可以先把完整的請求報頭讀完【空行之前】
2.對讀到的報頭進行解析!如果說正文長度>0,在中間報頭部分會存在:Content-Length: xxx
這個是用來指示正文長度的。如果長度為0可能會不顯示!
3.根據Content-Length讀取正文長度
這些工作,都放在了接口Http.ReadAllRequestHeader來做!
今天這里規定,一旦發現保溫不完整、正文長度不匹配時,我們都不予受理!
2.講請求行進行分析,讀取到正確的正文長度,并提取正文:

這里為了代碼更好的復用性,寫了一個接口AnalyseRequestLine,即分析請求行。就是把完整的請求行傳入,傳入要找的key,最后把value帶出給text_len!
經過上面的步驟,我們就可以提取正文了,然后就是拼接處完整的http request報文!

3.對http request進行反序列化

這里需要注意有一個_is_interact,這個是表示當前是否交互用的!這里我們不需要管!這個我們放在后面講解如何進行交互的時候來說。
注意,這里如果URI是單純的一個/,我們不可能把整個web根目錄下的內容返回給客戶端,一般來說,這個是在請求首頁,就類似于www.baidu.com的搜索框那樣!
4.分析對應的請求,制作應答序列化后返回

那么,要訪問的資源,或者上傳的資源,都是通過MakeResponse這個接口來進行處理!制作好對應的應答。這里是訪問靜態資源!!!
(制作應答的邏輯就不展示了,總之就是設置好對應的應答協議字段,把資源設置到正文部分(字節流)即可!)
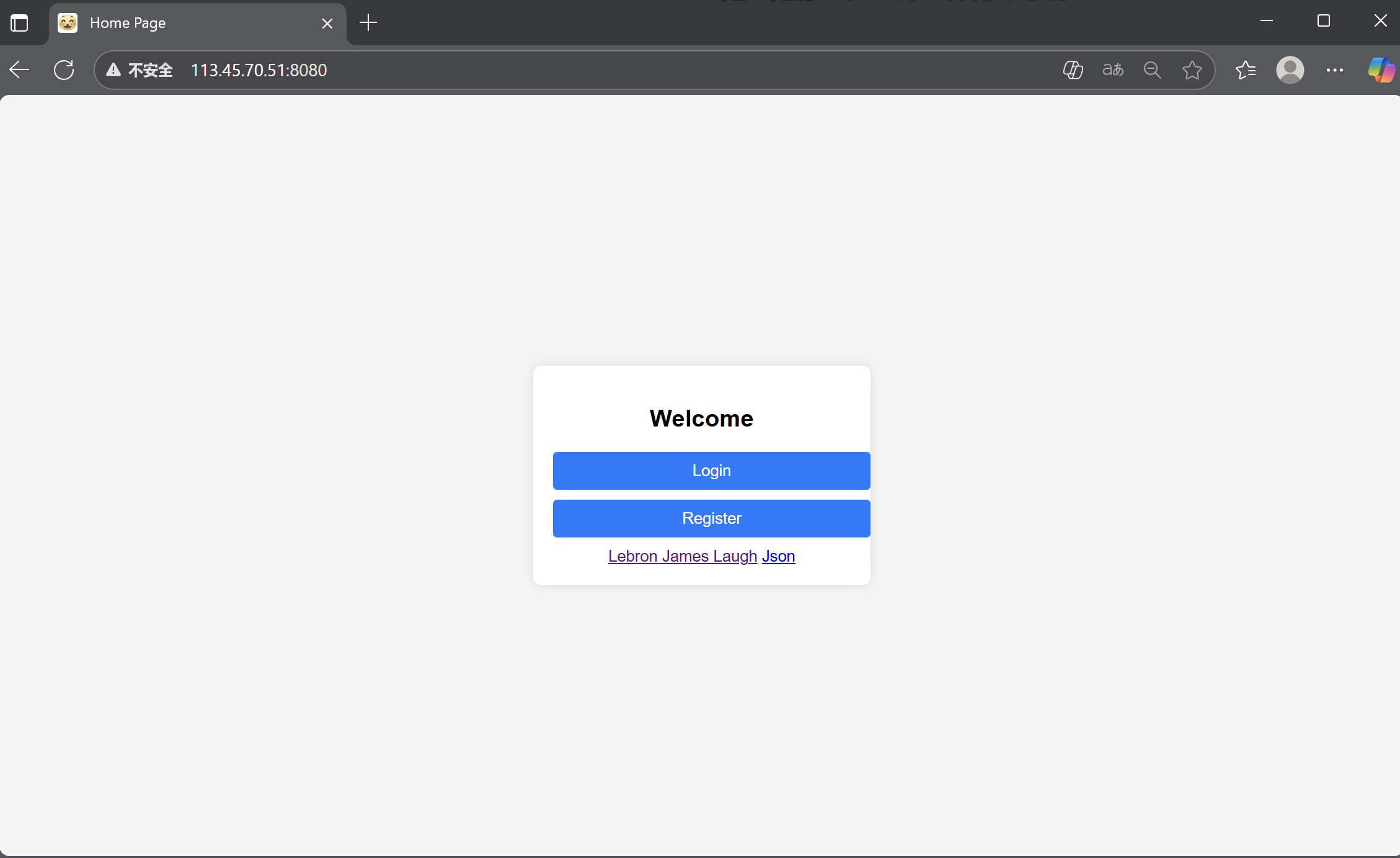
所以,我們讓ai生成一點網頁,在我們的資源站上放入一些圖片:
我們來運行看一下效果:
注意,當前路徑下有一個favicon.ico文件,這個其實就是圖片文件。就像我們打開一個網頁,瀏覽器選項卡左上角的那個小圖標:
因為輸入對應的ip:端口號訪問,其實瀏覽器不止是申請首頁資源(index.html,如果不帶任何的路徑默認就是訪問/,即首頁)。同時,瀏覽器還會申請/favicon.ico資源,就是訪問這個小圖標。直接網上找一個放在web根目錄下即可!
同時,我在首頁位置插入了兩張圖片:
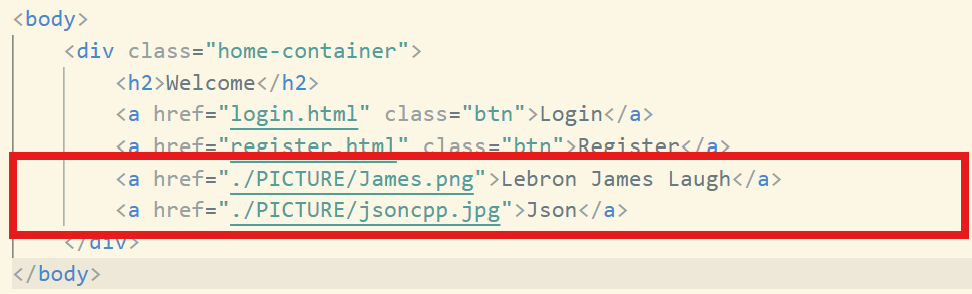
這些是前端的內容,這里就不說了。我們可以到大模型詢問使用,或者相關網站:
https://cn.w3schools.com/html/html5_video.asp
常用的報頭屬性
上述我只是簡單地了介紹了,訪問服務器靜態資源的主要邏輯。并沒有說到其中的一些問題:
就是我們今天設置應答的時候,我們是需要返回個別中間報頭的!也是常用的。
第一個報頭就是Content-Length,這個是指示正文長度的。
也就是今天我們制作應答的時候,返回資源都是放在應答的正文部分,讓瀏覽器去解釋。
其實這個報頭設置不設置都可以,現在的瀏覽器很強大,是可以解析出來的。但是可以設置一下,就設置到底層的哈希表中即可。
第二個報頭是非常非常重要的!如果不進行設置,會導致一個很嚴重的問題:
當我們發圖片的時候,如果沒有設置對應的報頭,就會導致瀏覽器無法顯示該圖片!
因為有一個報頭Content-Type,指示這次發送的資源是什么類型的,這是有常見的轉化表的。為了方便使用,定義了一個MimeTypes類進行轉化使用:

所以,我們就需要主動的設置報頭屬性,要不然瀏覽器解釋不了!!!!
還有就是,今天的服務器,只能支持短連接,也就是完成一次請求,服務器處理后就會直接關閉連接。如果說,我們直接把圖片,視頻等其他資源放到該網頁上,服務器是要進行多次請求的。這里就不演示了,知道即可。
但是,我們今天這里全是使用HTML的a標簽,這就是一個跳轉鏈接,只有點擊它,瀏覽器會再次進行請求對應的資源。
http response

我們知道,上面是http response的格式。
中間的報頭我們已經說了兩個了:Content-Length和Content-Type
還有其他的報頭,但是我們會放在后面去說。
正文部分就是我們要交給用戶端的資源。就是把資源文件以二進制方式讀取出來放到正文。
我們最需要了解的就是,第一行狀態行!
第一個是服務器版本,我們這里直接默認是HTTP/1.0即可。因為HTTP/1.0使用短連接多,1.1版本才是長連接。這里我們寫的是短連接。
這個版本是為了對照服務器和客戶端兩端版本的。因為有時候一些服務器是沒有辦法支持過高的標準的,或者服務器不支持一些老標準!所以需要兩端版本對照!
第二三個可以一起說,狀態碼和描述,這是什么意思?
其實就是當前服務器處理請求的時候,可能會出現一些問題,又或是一些特殊的處理方式。這個時候,就有可能需要向客戶端返回當前處理的狀態!
最常見的就是:404 Not Found!
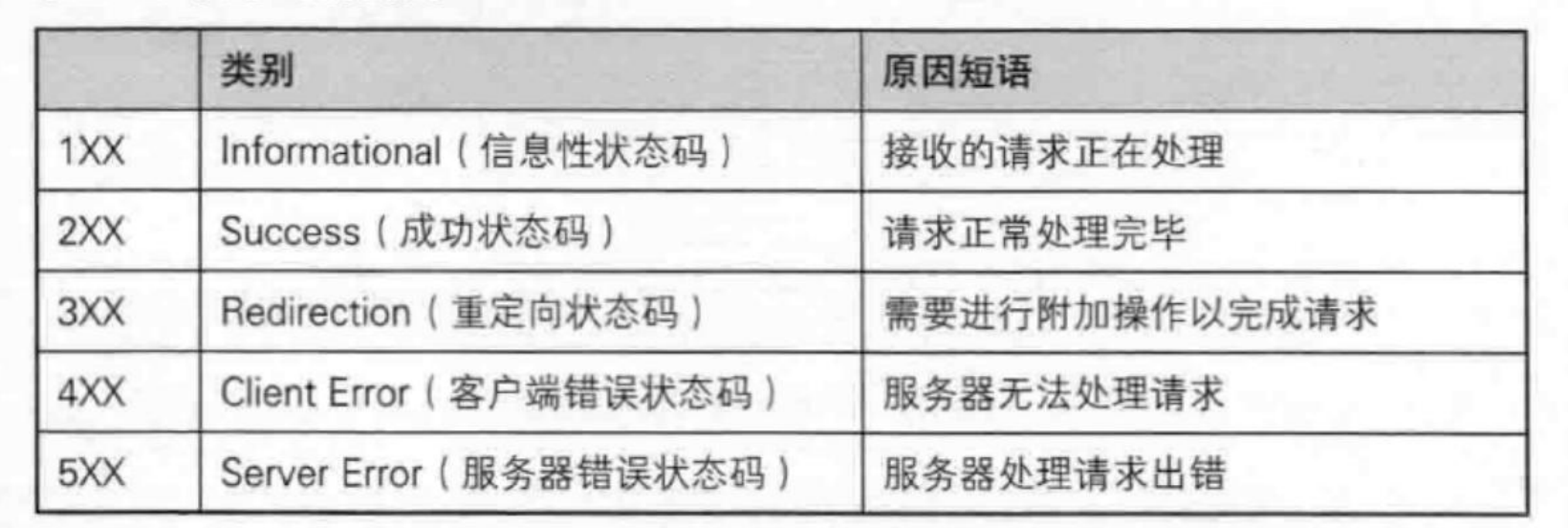
狀態碼
1開頭的就是可能當前服務器還在處理客戶端發來的請求。
2開頭的一般都是處理請求成功
3重定向,這個我們需要好好了解一下。比如我們有時候可以發現,我們訪問一個網站,突然換網址了,需要我們跳轉到另外一個網站,這就是簡單地重定向!
又比如我們在某些app里面的搖一搖跳轉,這也是屬于重定向!
當然,第三點也不止局限于這里。也有可能是某些服務器不是真正提供服務的,可能是代理服務器。就是客戶端向該代理服務器發送請求,服務器會返回重定向的網址和信息給客戶端,此時瀏覽器一旦接收到重定向的信息,就會立馬再次向新的服務器申請服務!
4開頭表示的是客戶端錯誤!比如最常見的404,找不到資源。
5.這個表示的是服務器的錯誤,比如服務器過載、進程創建失敗等。
但是,這里要說的是,其實很多公司內部是對于返回狀態碼是寫的比較隨意的。特別像是5開頭的,如果返回這個錯誤碼,就等同于告訴外界公司服務器的軟肋了!所以,有可能有時候服務器錯誤返回200都是有可能的事情。
重定向
我們需要來重點了解一下重定向:
| 狀態碼 | 狀態短語 | 說明 |
|---|---|---|
| 300 | Multiple Choices | 請求的資源有多個選擇,用戶或瀏覽器需要選擇其中一個進行訪問。 |
| 301 | Moved Permanently | 請求的資源已永久移動到新位置,未來所有請求應使用新URI。 |
| 302 | Found | 請求的資源臨時從不同URI響應請求,客戶端應繼續使用原始URI。 |
| 303 | See Other | 對當前請求的響應可以在另一個URI找到,且必須使用GET方法獲取。 |
| 304 | Not Modified | 資源未修改(用于緩存重定向),客戶端可以繼續使用緩存的版本。 |
| 307 | Temporary Redirect | 臨時重定向,與302類似,但明確要求方法和主體不能更改。 |
| 308 | Permanent Redirect | 永久重定向,與301類似,但明確要求方法和主體不能更改。 |
我們就舉兩個例子來說:
301 Moved Permanently 請求的資源已永久移動到新位置,未來所有請求應使用新URI。
302 Found/See Other 求的資源臨時從不同URI響應請求,客戶端應繼續使用原始URI。
這兩個其實真正使用起來,區別是不大的。但是我們還是要講解一下他們的區別:
| 狀態碼 | 類型 | 搜索引擎行為 | 瀏覽器行為 | 形象比喻 |
|---|---|---|---|---|
| 301 | 永久重定向 | 更新權重到新URL | 緩存跳轉,后續直接訪問新地址 | “永久搬家” |
| 302 | 臨時重定向 | 保留原URL權重 | 每次訪問都重新跳轉 | “臨時借住” |
關鍵區別:
- 永久性:301是永久變更,302是臨時變更
- SEO影響:301轉移權重,302保留原權重
- 緩存行為:301會被瀏覽器緩存,302每次重新跳轉
| 類型 | 工作流程 | 緩存機制 |
|---|---|---|
| 301 | 1. 客戶端首次請求 → 服務器返回301和新地址 2. 瀏覽器自動緩存該重定向 3. 后續所有請求直接跳轉新地址(不再詢問服務器) | 永久緩存(直到清除瀏覽器緩存) |
| 302 | 1. 每次請求 → 服務器都返回302和新地址 2. 瀏覽器不會緩存重定向 3. 每次都要完整走請求流程 | 不緩存 |
重定向使用效果
其實重定向的方式有很多種,但是真正使用起來是肉眼看不出區別的:
在HttpResponse的MakeResponse接口中,我們對于找不到的內容是做了處理的。即讓正文部分返回一個404 Not Found的網頁。現在,我們其實也可以直接重定向過去該網頁。


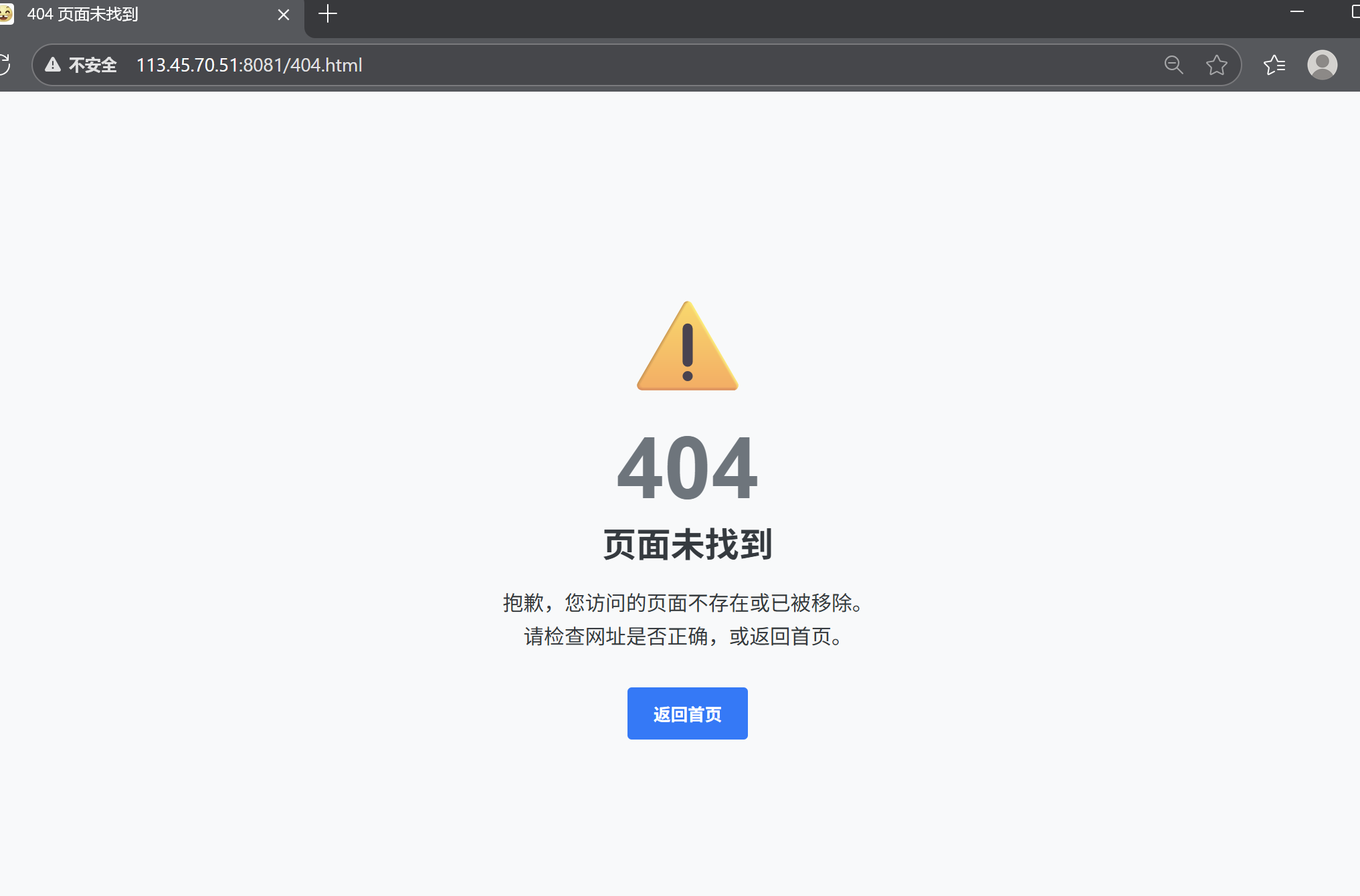
其實經過實驗,使用301進行重定向或者302都是差不多的!看不出區別。
簡單理解重定向的原理
我們需要了解的是,重定向的過程是什么?為什么瀏覽器能夠找到對應的資源進行重定向呢?
其實是因為,在Http Response的Header內,有一個字段叫做:Location: xxx。
這個是要配合3xx的狀態碼來進行使用的!
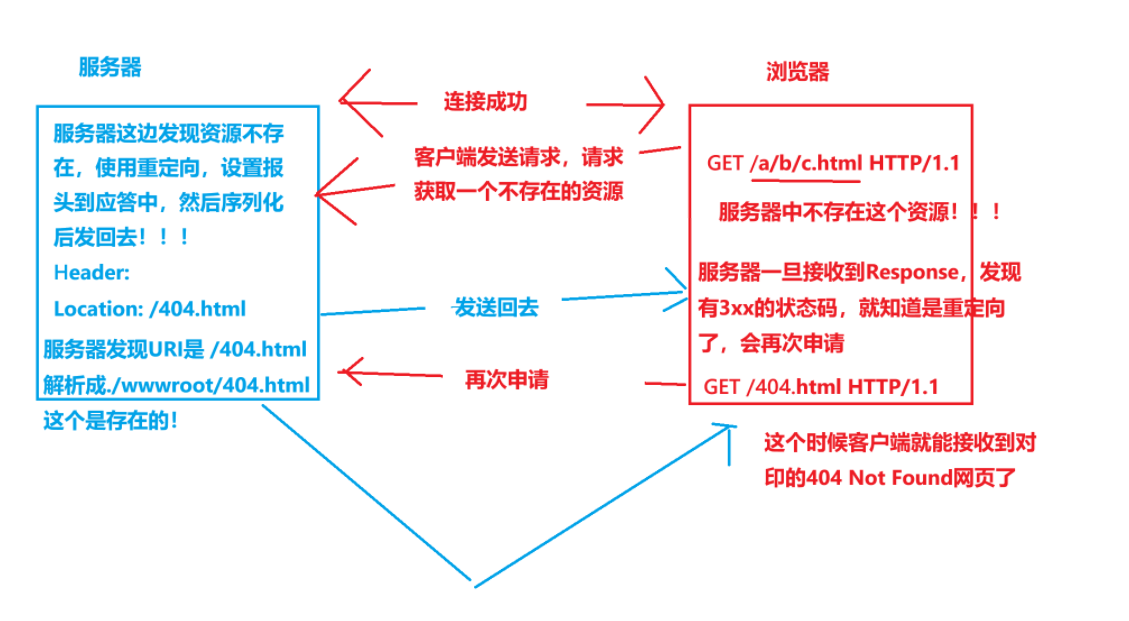
具體的過程如上所示!
理解請求方法
現在,我們需要來理解一下http request中的請求方法。
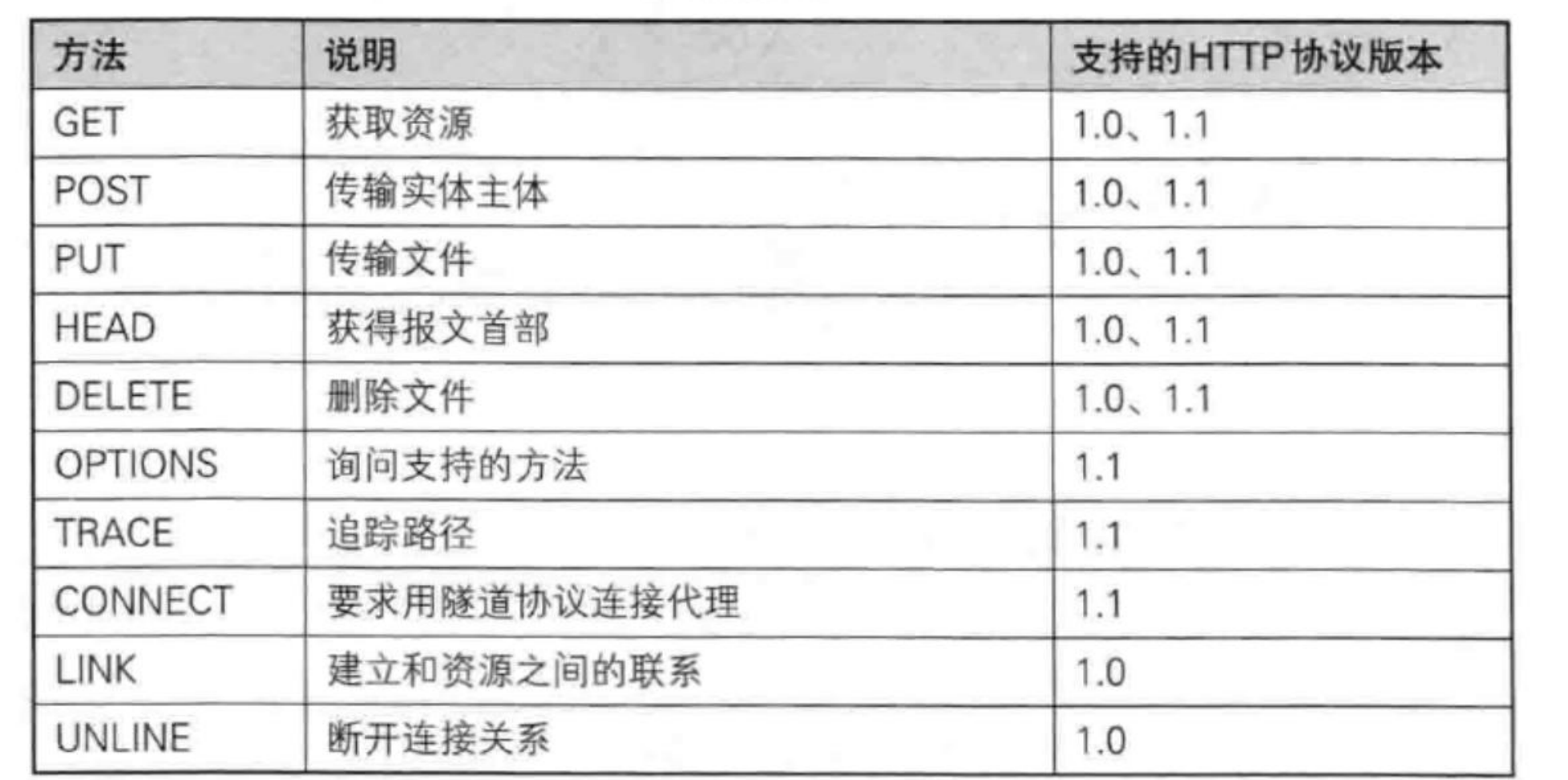
我們先來看最重要的兩個:GET / POST。
先直接說區別:
它們二者最大的區別就是,在與服務器進行動態交互的時候,客戶端需要提交一些參數。GET方法提交的參數會放在URL,POST方法是放在正文中!
接下來我們來做個實驗看,首先我們要知道,如何通過瀏覽器,從前端傳遞參數到后端:
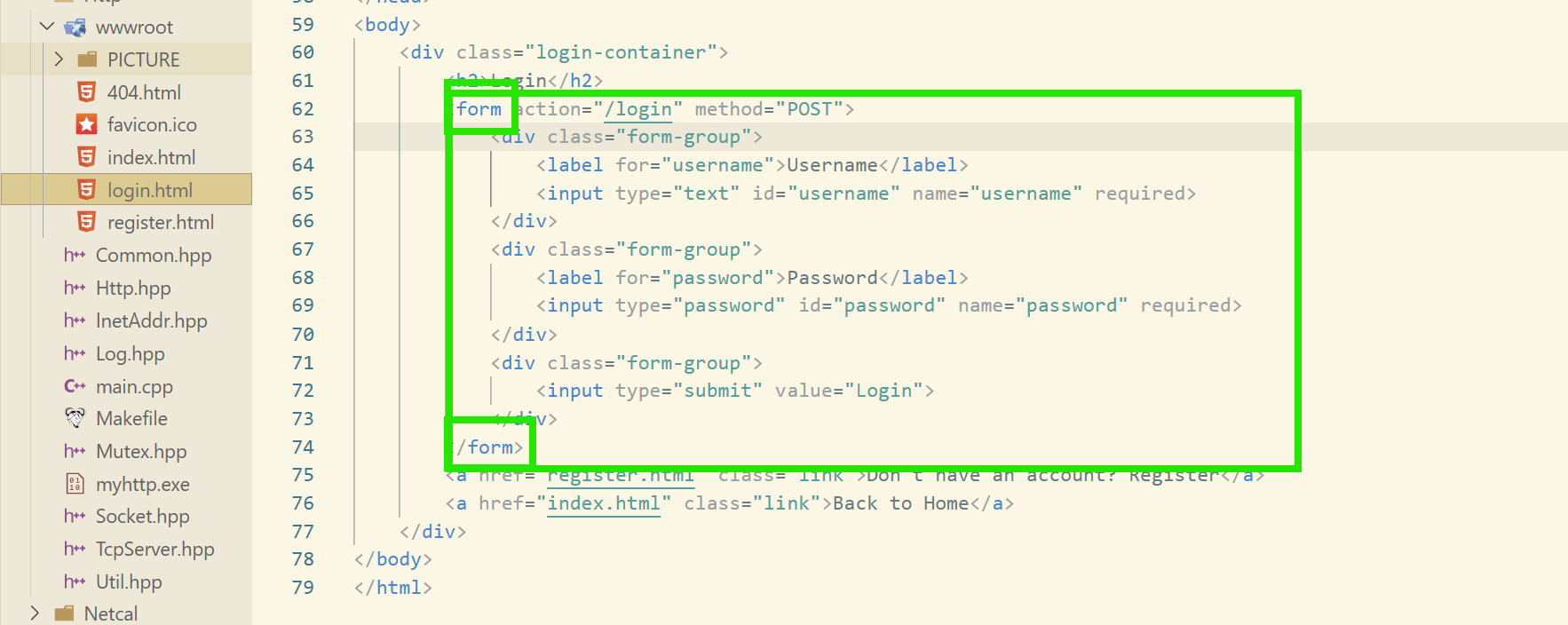
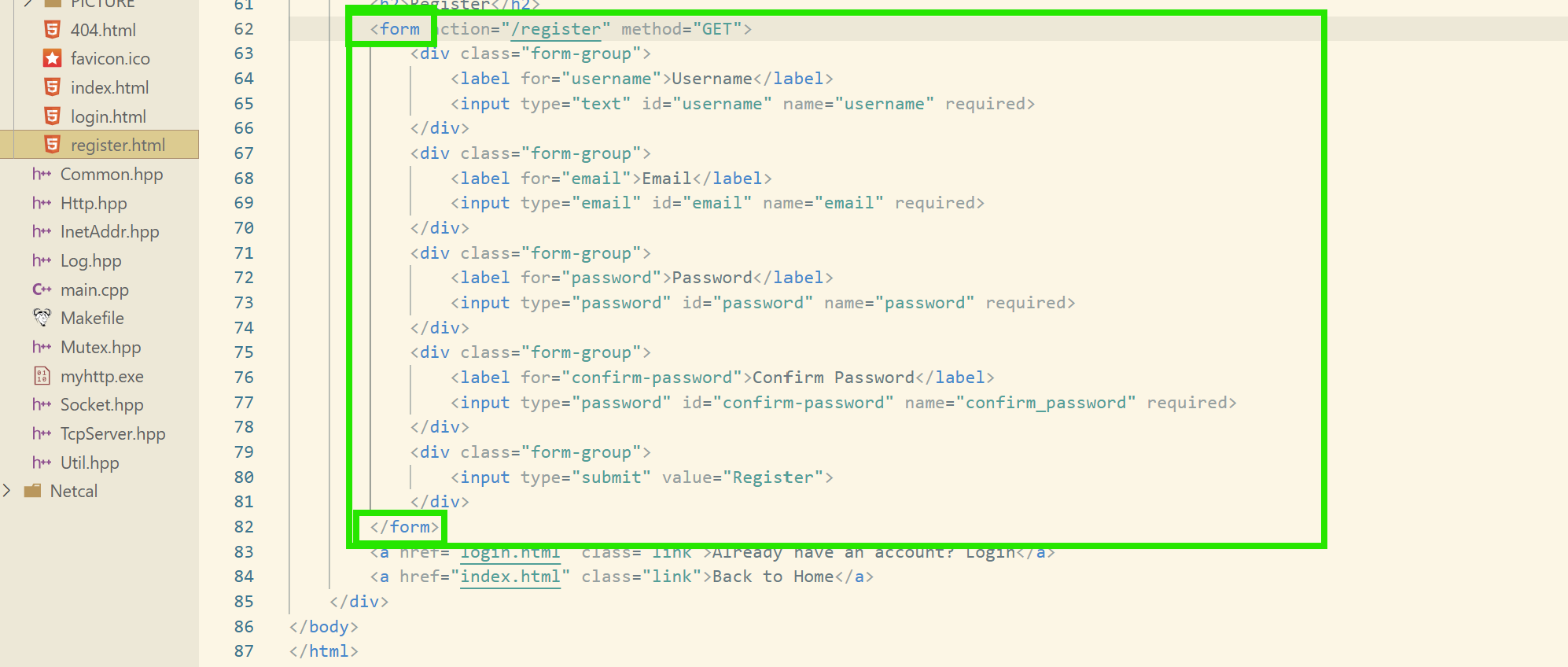
我們看這里ai生成的登錄注冊網頁,使用到了一個叫form表單的東西:
其實,我們在瀏覽器中的一些登錄界面也是使用這個表單的,我們可以看看:
然后,通過這個表單,就可以把輸入的參數(如我們這里的賬戶密碼)傳送給后端進行驗證了!
接下來,我們就以登陸注冊模塊來看看這兩個方法的不同!!!
login和regsiter是類似的這里,我們就拿登錄網頁來試一下就好了。
(這里需要注意,這種服務一般是需要進行交互的。我們之前說的都是靜態資源的獲取。所以,對于HTTP來說,需要多一個交互的服務。所以我在HTTP類中加入了一個_route哈希,用來進行檢索交互任務的。邏輯其實很簡單,看代碼是一定能看得懂的。這里就不說代碼了,直接上演示結果。)
method = GET:
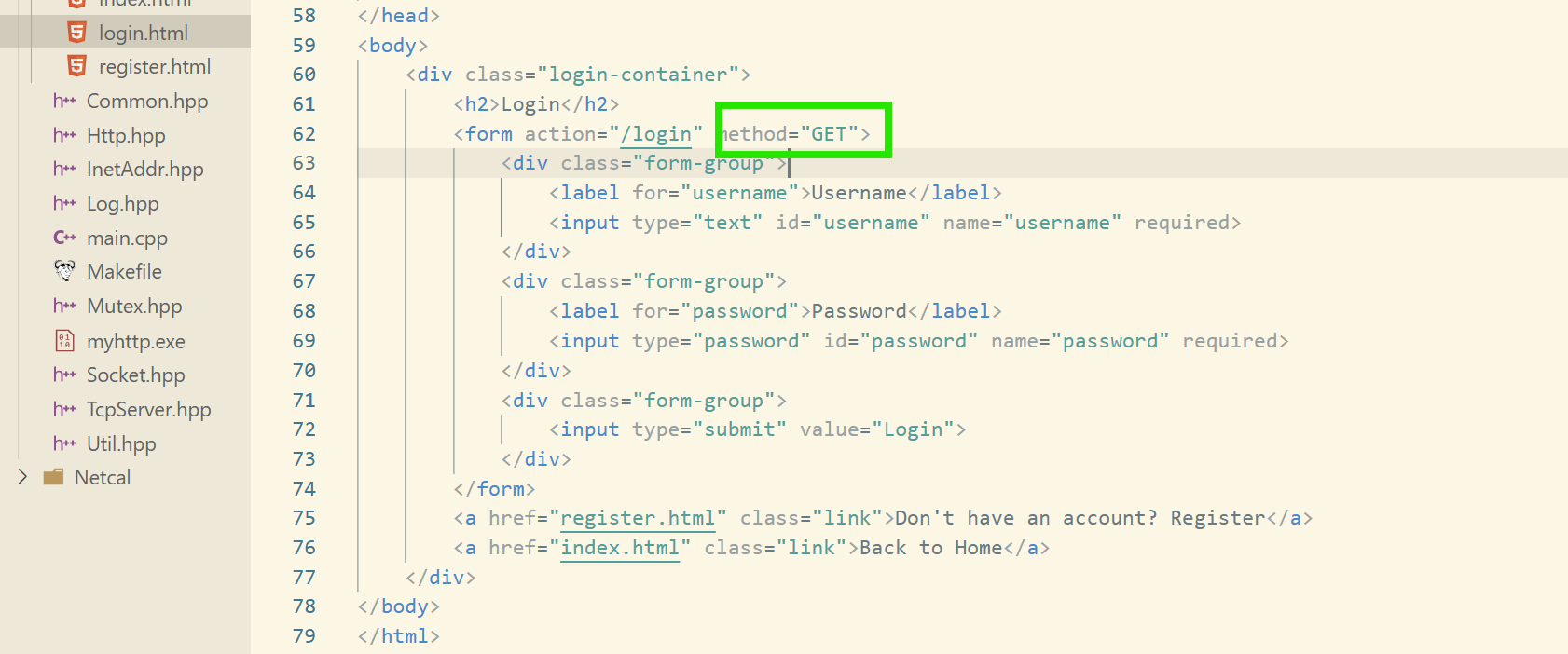
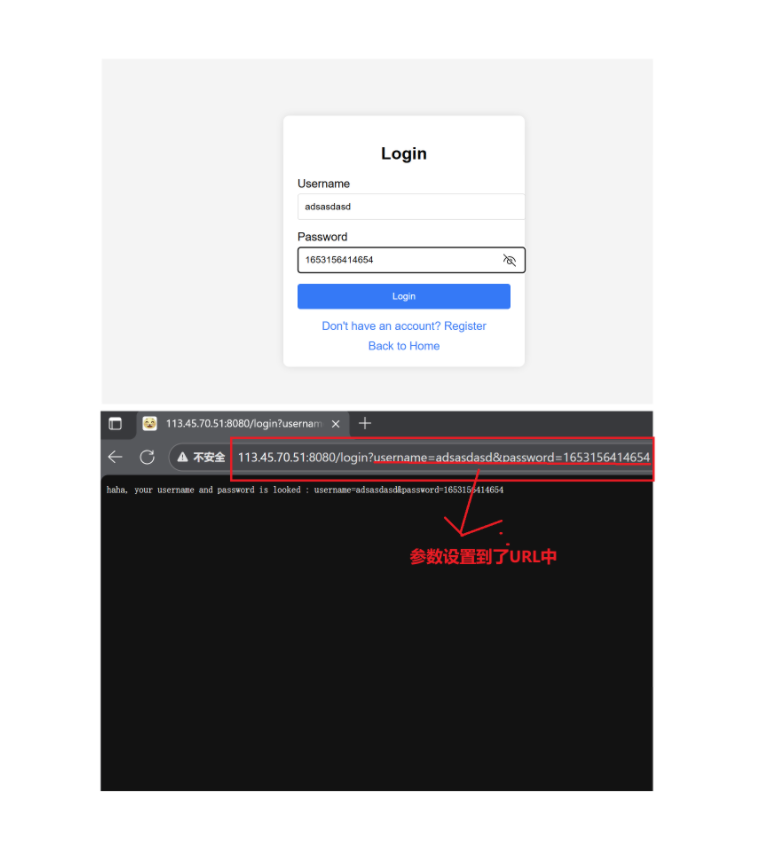
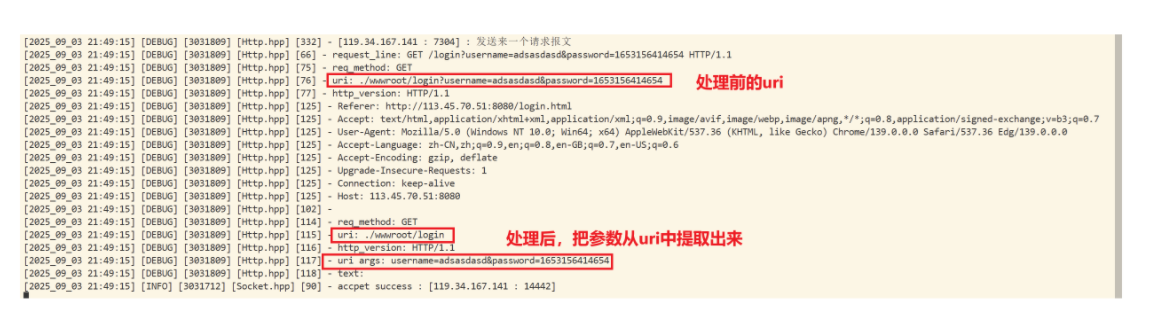
method = POST
我們只需要修改網頁即可,服務器是不用重新啟動的!因為網頁和服務器是互相獨立的。
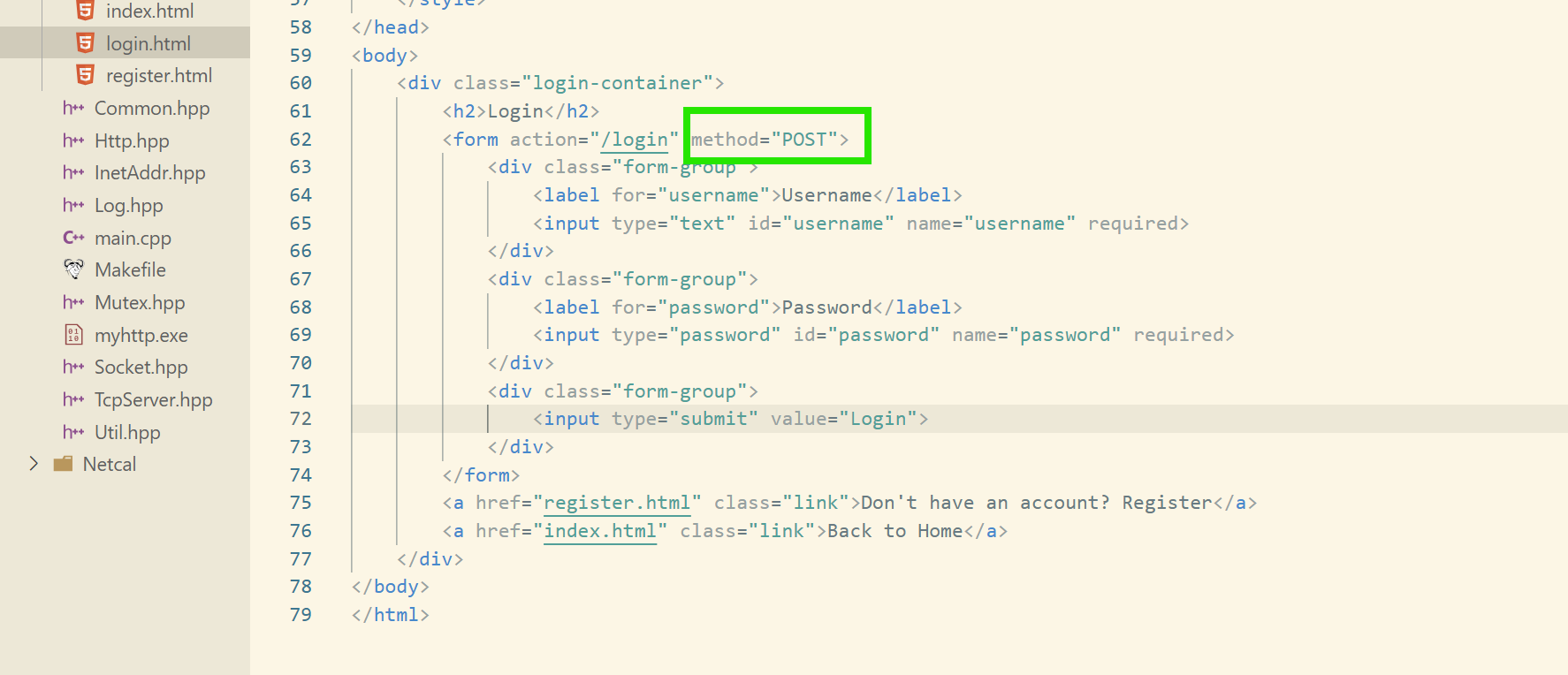
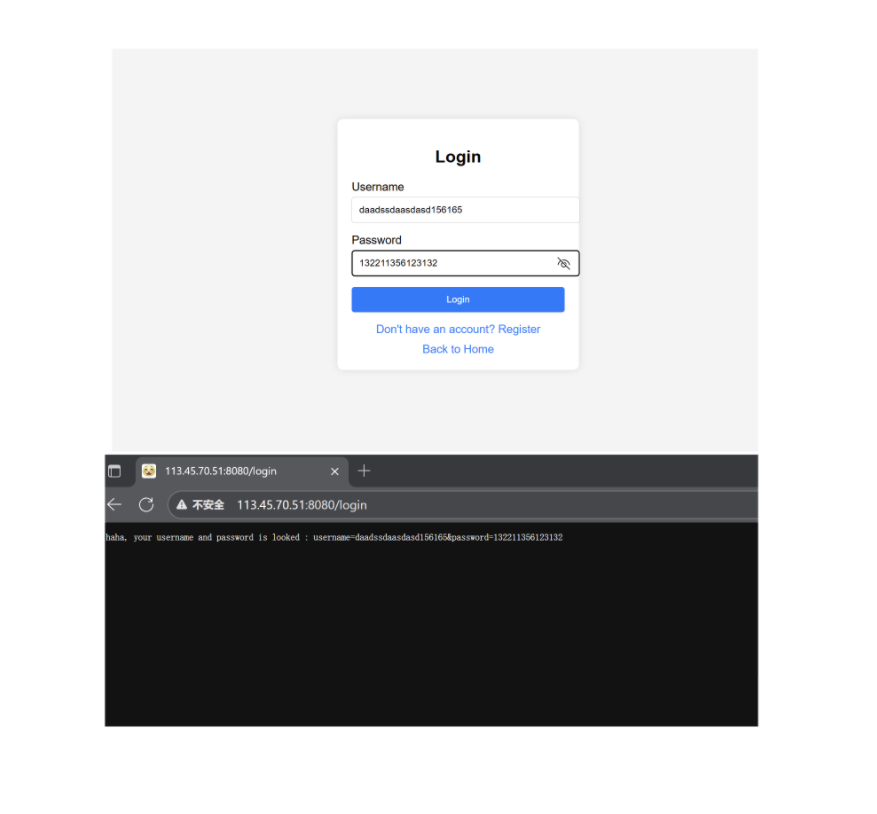
最后我們發現,事實確實如此。二者的區別就是在于傳參的不同。
只不過說,一般來說更習慣用GET來進行資源獲取,POST來進行參數提交。相對于GET來說,POST把參數(隱私信息)放在正文內,私密性可能更好一些些吧。
但其實,二者這樣提交都是不安全的!因為可以被別人抓包,這里推薦使用一款工具叫做fiddler classic,它可以進行抓包!這里就不演示了。
其他方法(選幾個進行介紹):
PUT方法:
用途:用于傳輸文件,將請求報文主體中的文件保存到請求 URL 指定的位置。
示例:PUT /example.html HTTP/1.1
特性:不太常用,但在某些情況下,如 RESTful API 中,用于更新資源。
(常用的是POST或者GET)
DELETE方法:
用途:用于刪除文件,是 PUT 的相反方法。
示例:DELETE /example.html HTTP/1.1
特性:按請求 URL 刪除指定的資源。
但是,一般來說,DELETE是不被允許的!因為一些公司不希望用戶能夠隨意刪除服務器內的一些資源,所以可能會拒絕該請求!
HEAD方法
用途:與 GET 方法類似,但不返回報文主體部分,僅返回響應頭。
示例:HEAD /index.html HTTP/1.1
特性:用于確認 URL 的有效性及資源更新的日期時間等。
但是這個方法,也大部分情況是被禁止的!而且也很少用。
OPTION方法
用途:用于查詢針對請求 URL 指定的資源支持的方法。
示例:OPTIONS * HTTP/1.1
特性:返回允許的方法,如 GET、POST 等。
HTTP的Header
Content-Type: 數據類型(text/html 等) ? Content-Length: Body 的長度
Host: 客戶端告知服務器, 所請求的資源是在哪個主機的哪個端口上;
User-Agent: 聲明用戶的操作系統和瀏覽器版本信息;
referer: 當前頁面是從哪個頁面跳轉過來的;
Location: 搭配 3xx 狀態碼使用, 告訴客戶端接下來要去哪里訪問;
Cookie: 用于在客戶端存儲少量信息. 通常用于實現會話(session)的功能;
Cookie我們放在后序的cookie和session話題來講解。
這里需要講一下connection報頭相關的內容。
我們今天寫的HTTP協議通信,是短連接的。也就是,客戶端發送來一個請求,服務端處理完該請求后,然后立馬斷開連接。如果服務端還有內容要申請,那就需要繼續請求!
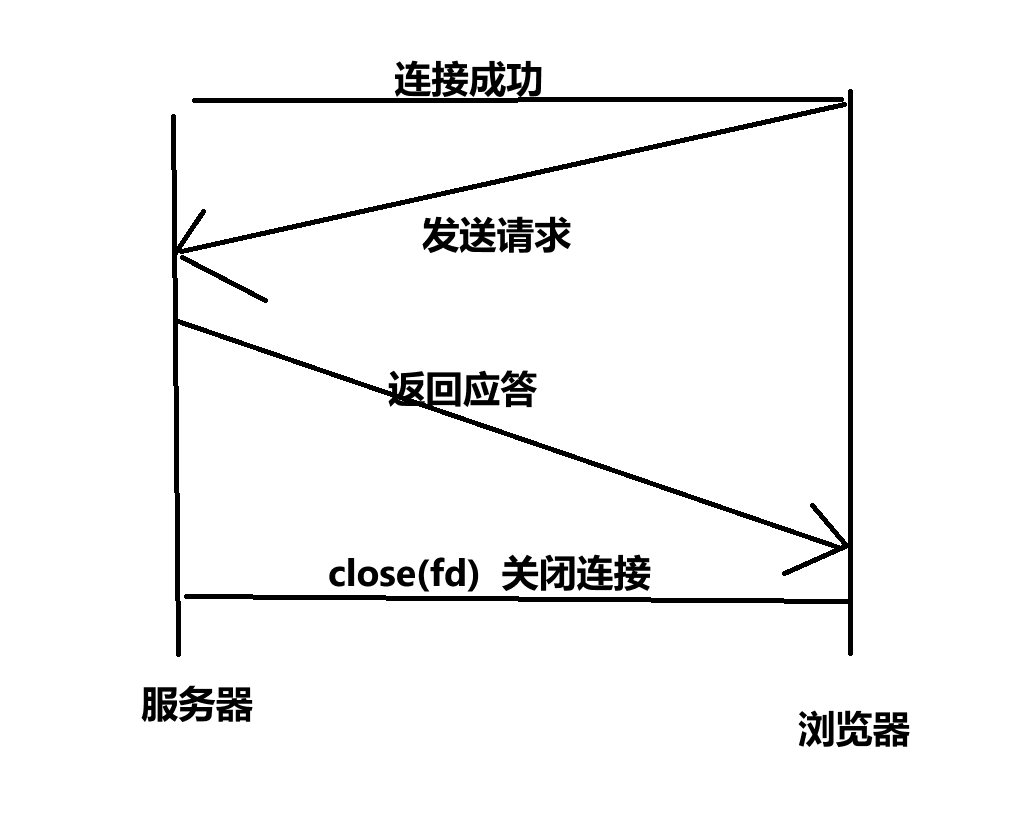
這種是短服務!也就是服務器一次只處理一個請求。這種在早期的HTTP/1.0協議中用的比較多。因為早期的HTTP協議中,一個網頁內是沒有像現在這樣如此多的資源的。
但是,如果像是今天的瀏覽器中的一張網頁,有大量的連接、視頻、圖片…如果還是采用短連接的方式,那么光是申請一張網頁,服務器就要不斷地進行:連接、創建子進程/線程,處理、關閉連接。更何況,建立連接也不是沒有成本的!
所以這就導致,如果對于一些資源比較多的網頁來講,使用短連接的服務肯定是不行的!所以,在HTTP/1.1協議后,就引入了這么一個報頭:connection。
HTTP 中的 Connection 字段是 HTTP 報文頭的一部分,它主要用于控制和管理客戶端與服務器之間的連接狀態。可以做到管理持久連接:Connection 字段還用于管理持久連接(也稱為長連接)。持久連接允許客戶端和服務器在請求/響應完成后不立即關閉 TCP 連接,以便在同一個連接上發送多個請求和接收多個響應。
語法格式
- Connection: keep-alive:表示希望保持連接以復用 TCP 連接。
- Connection: close:表示請求/響應完成后,應該關閉 TCP 連接。
其實我們自主實現的網絡版本計算器,就是長連接形式的!因為服務器是一直在進行服務,不會主動斷開與客戶端的連接!


:StandardScaler)




)

)


)
、CommonJS(CJS)和UMD三種格式)
)
:高級實現——平衡源項、邊界條件與算法總成)
技術解析)


)