大模型訓練流程實踐
本文較長,建議點贊收藏,以免遺失。更多AI大模型開發 學習視頻/籽料/面試題 都在這>>Github<< >>Gitee<<
6.1 模型預訓練
在上一章,我們逐步拆解了 LLM 的模型結構及訓練過程,從零手寫實現了 LLaMA 模型結構及 Pretrain、SFT 全流程,更深入地理解了 LLM 的模型原理及訓練細節。但是,在實際應用中,手寫實現的 LLM 訓練存在以下問題:
- 手寫實現 LLM 結構工作量大,難以實時跟進最新模型的結構創新;
- 從零實現的 LLM 訓練無法較好地實現多卡分布式訓練,訓練效率較低;
- 和現有預訓練 LLM 不兼容,無法使用預訓練好的模型參數
因此,在本章中,我們將介紹目前 LLM 領域的主流訓練框架 Transformers,并結合分布式框架 deepspeed、高效微調框架 peft 等主流框架,實踐使用 transformers 進行模型 Pretrain、SFT 全流程,更好地對接業界的主流 LLM 技術方案。
6.1.1 框架介紹
Transformers 是由 Hugging Face 開發的 NLP 框架,通過模塊化設計實現了對 BERT、GPT、LLaMA、T5、ViT 等上百種主流模型架構的統一支持。通過使用 Transformers,開發者無需重復實現基礎網絡結構,通過 AutoModel 類即可一鍵加載任意預訓練,圖6.1 為 Hugging Face Transformers 課程首頁:

圖6.1 Hugging Face Transformers
同時,框架內置的 Trainer 類封裝了分布式訓練的核心邏輯,支持 PyTorch 原生 DDP、DeepSpeed、Megatron-LM 等多種分布式訓練策略。通過簡單配置訓練參數,即可實現數據并行、模型并行、流水線并行的混合并行訓練,在 8 卡 A100 集群上可輕松支持百億參數模型的高效訓練。配合 SavingPolicy 和 LoggingCallback 等組件,實現了訓練過程的自動化管理。其還支持與 Deepspeed、peft、wandb、Swanlab 等框架進行集成,直接通過參數設置即可無縫對接,從而快速、高效實現 LLM 訓練。
對 LLM 時代的 NLP 研究者更為重要的是,HuggingFace 基于 Transformers 框架搭建了其龐大的 AI 社區,開放了數億個預訓練模型參數、25萬+不同類型數據集,通過 Transformers、Dataset、Evaluate 等多個框架實現對預訓練模型、數據集及評估函數的集成,從而幫助開發者可以便捷地使用任一預訓練模型,在開源模型及數據集的基礎上便捷地實現個人模型的開發與應用。

圖6.2 Hugging Face Transformers 模型社區
在 LLM 時代,模型結構的調整和重新預訓練越來越少,開發者更多的業務應用在于使用預訓練好的 LLM 進行 Post Train 和 SFT,來支持自己的下游業務應用。且由于預訓練模型體量大,便捷集成 deepspeed 等分布式訓練框架逐漸成為 LLM 時代 NLP 模型訓練的必備技能。因此,Transformers 已逐步成為學界、業界 NLP 技術的主流框架,不管是企業業務開發還是科研研究,都逐漸首選 Transformers 進行模型實現。同時,新發布的開源 LLM 如 DeepSeek、Qwen 也都會第一時間在 Transformers 社區開放其預訓練權重與模型調用 Demo。通過使用 Transformers 框架,可以高效、便捷地完成 LLM 訓練及開發,實現工業級的產出交付。接下來,我們就會以 Transformers 框架為基礎,介紹如何通過 Transformers 框架實現 LLM 的 Pretrain 及 SFT。
6.1.2 初始化 LLM
我們可以使用 transformers 的 AutoModel 類來直接初始化已經實現好的模型。對于任意預訓練模型,其參數中都包含有模型的配置信息。如果是想要從頭訓練一個 LLM,可以使用一個已有的模型架構來直接初始化。這里,我們以 Qwen-2.5-1.5B的模型架構為例:
圖6.3 Qwen-2.5-1.5B
該界面即為 HuggingFace 社區中的 Qwen-2.5-1.5B 模型參數,其中的 config.json 文件即是模型的配置信息,包括了模型的架構、隱藏層大小、模型層數等,如圖6.4所示:
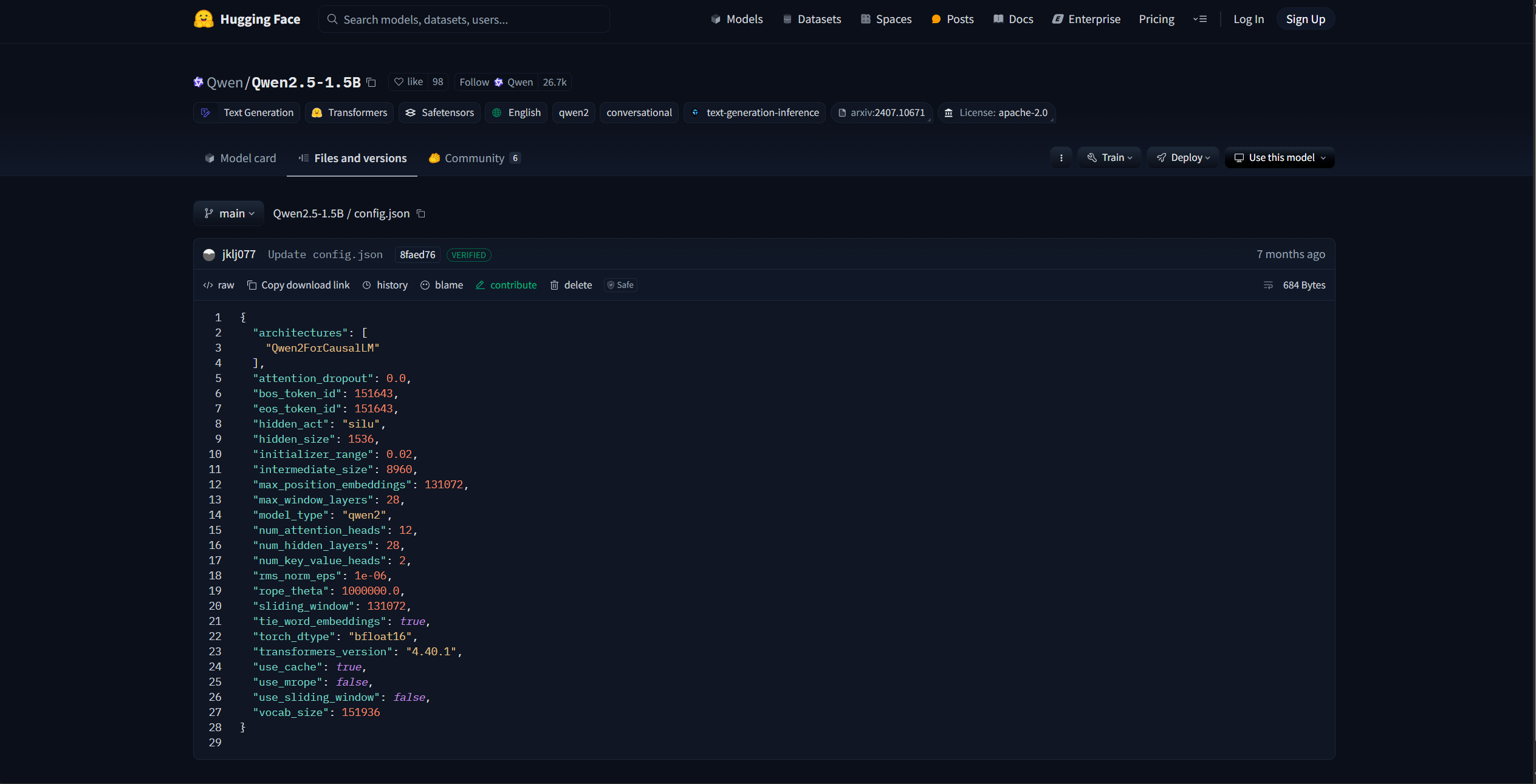
圖6.4 Qwen-2.5-1.5B config.json 文件
我們可以沿用該模型的配置信息,初始化一個 Qwen-2.5-1.5B 模型來進行訓練,也可以在該配置信息的基礎上進行更改,如修改隱藏層大小、注意力頭數等,來定制一個模型結構。HuggingFace 提供了 Python 工具來便捷下載想使用的模型參數:
import os
# 設置環境變量,此處使用 HuggingFace 鏡像網站
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# 下載模型
os.system('huggingface-cli download --resume-download Qwen/Qwen2.5-1.5B --local-dir your_local_dir')
如圖6.5,此處的 “Qwen/Qwen2.5-1.5B”即為要下載模型的標識符,對于其他模型,可以直接復制 HuggingFace 上的模型名即可:
圖6.5 模型下載標識
下載完成后,可以使用 AutoConfig 類直接加載下載好的配置文件:
# 加載定義好的模型參數-此處以 Qwen-2.5-1.5B 為例
# 使用 transforemrs 的 Config 類進行加載
from transformers import AutoConfig# 下載參數的本地路徑
model_path = "qwen-1.5b"
config = AutoConfig.from_pretrained(model_name_or_path)
也可以對配置文件進行自定義,然后以同樣的方式加載即可。可以使用 AutoModel 類基于加載好的配置對象生成對應的模型:
# 使用該配置生成一個定義好的模型
from transformers import AutoModelForCausalLMmodel = AutoModelForCausalLM.from_config(config,trust_remote_code=True)
由于 LLM 一般都是 CausalLM 架構,此處使用了 AutoModelForCausalLM 類進行加載。如果是用于分類任務訓練,可使用 AutoModelForSequenceClassification 類來加載。查看該 model,圖6.6可以看到其架構和定義的配置文件相同:

圖6.6 模型結構輸出結果
該 model 就是一個從零初始化的 Qwen-2.5-1.5B 模型了。一般情況下,我們很少從零初始化 LLM 進行預訓練,較多的做法是加載一個預訓練好的 LLM 權重,在自己的語料上進行后訓練。這里,我們也介紹如何從下載好的模型參數中初始化一個預訓練好的模型。
from transformers import AutoModelForCausalLMmodel = AutoModelForCausalLM.from_pretrained(model_name_or_path,trust_remote_code=True)
類似的,直接使用 from_pretrained 方法加載即可,此處的 model_name_or_path 即為下載好的參數的本地路徑。
我們還需要初始化一個 tokenizer。此處,我們直接使用 Qwen-2.5-1.5B 對應的 tokenizer 參數即可:
# 加載一個預訓練好的 tokenizer
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
加載好的 tokenizer 即可直接使用,對任意文本進行分詞處理。
6.1.3 預訓練數據處理
與第五章類似,我們使用出門問問序列猴子開源數據集作為預訓練數據集,可以用與第五章一致的方式進行數據集的下載和解壓。HuggingFace 的 datasets 庫是和 transformers 框架配套的、用于數據下載和處理的第三方庫。我們可以直接使用 datasets 的 load_dataset 函數來加載預訓練數據:
# 加載預訓練數據
from datasets import load_datasetds = load_dataset('json', data_files='/mobvoi_seq_monkey_general_open_corpus.jsonl')
注意,由于數據集較大,加載可能會出現時間較長或內存不夠的情況,建議前期測試時將預訓練數據集拆分一部分出來進行測試。加載出來的 ds 是一個 DatasetDict 對象,加載的數據會默認保存在 train 鍵對應的值中,可以通過以下代碼查看:
ds["train"][0]

圖6.7 數據集展示
可以通過 feature 屬性查看數據集的特征(也就是列),這里需要保存一下數據集的列名,因為后續數據處理時,再將文本 tokenize 之后,需要移除原先的文本:
# 查看特征
column_names = list(ds["train"].features)
# columnes_name:["text"]
接著使用加載好的 tokenizer 對數據集進行處理,此處使用 map 函數來進行批量處理:
# 對數據集進行 tokenize
def tokenize_function(examples):# 使用預先加載的 tokenizer 進行分詞output = tokenizer([item for item in examples["text"]])return output# 批量處理
tokenized_datasets = ds.map(tokenize_function,batched=True,num_proc=10,remove_columns=column_names,load_from_cache_file=True,desc="Running tokenizer on dataset",
)
處理完成后的數據集會包括’input_ids’, 'attention_mask’兩列,分別是文本 tokenize 之后的數值序列和注意力掩碼(標識是否 padding)。map 方法會通過 remove_columns 參數將原先的‘text’移除,訓練中不再使用。
由于預訓練一般為 CLM 任務,一次性學習多個樣本的序列語義不影響模型性能,且訓練數據量大、訓練時間長,對訓練效率要求比較高。在預訓練過程中,一般會把多個文本段拼接在一起,處理成統一長度的文本塊,再對每個文本塊進行訓練。在這里,我們實現一個拼接函數將文本塊拼接到 2048個 token 長度,再通過 map 方法來進行批量處理:
# 預訓練一般將文本拼接成固定長度的文本段
from itertools import chain# 這里我們取塊長為 2048
block_size = 2048def group_texts(examples):# 將文本段拼接起來concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}# 計算拼起來的整體長度total_length = len(concatenated_examples[list(examples.keys())[0]])# 如果長度太長,進行分塊if total_length >= block_size:total_length = (total_length // block_size) * block_size# 按 block_size 進行切分result = {k: [t[i : i + block_size] for i in range(0, total_length, block_size)]for k, t in concatenated_examples.items()}# CLM 任務,labels 和 input 是相同的result["labels"] = result["input_ids"].copy()return result# 批量處理
lm_datasets = tokenized_datasets.map(group_texts,batched=True,num_proc=10,load_from_cache_file=True,desc=f"Grouping texts in chunks of {block_size}",batch_size = 40000,
)
train_dataset = lm_datasets["train"]
處理得到的 train_dataset 就是一個可直接用于 CLM Pretrain 的預訓練數據集了,其每個樣本長度為 2048個 token。
6.1.4 使用 Trainer 進行訓練
接下來,我們使用 transformers 提供的 Trainer 類進行訓練。Trainer 封裝了模型的訓練邏輯,且做了較好的效率優化、可視化等工作,可以高效、便捷地完成 LLM 的訓練。
首先我們需要配置訓練的超參數,使用 TrainingArguments 類來實例化一個參數對象:
from transformers import TrainingArguments
# 配置訓練參數training_args = TrainingArguments(output_dir="output",# 訓練參數輸出路徑per_device_train_batch_size=4,# 訓練的 batch_sizegradient_accumulation_steps=4,# 梯度累計步數,實際 bs = 設置的 bs * 累計步數logging_steps=10,# 打印 loss 的步數間隔num_train_epochs=1,# 訓練的 epoch 數save_steps=100, # 保存模型參數的步數間隔learning_rate=1e-4,# 學習率gradient_checkpointing=True# 開啟梯度檢查點
)
然后基于初始化的 model、tokenzier 和 training_args,并傳入處理好的訓練數據集,實例化一個 trainer 對象:
from transformers import Trainer, default_data_collator
from torchdata.datapipes.iter import IterableWrapper# 訓練器
trainer = Trainer(model=model,args=training_args,train_dataset= IterableWrapper(train_dataset),eval_dataset= None,tokenizer=tokenizer,# 默認為 MLM 的 collator,使用 CLM 的 collaterdata_collator=default_data_collator
)
再使用 train 方法,即會按照配置好的訓練超參進行訓練和保存:
trainer.train()
注:上述代碼存放于
./code/pretrain.ipynb文件中。
6.1.5 使用 DeepSpeed 實現分布式訓練
由于預訓練規模大、時間長,一般不推薦使用 Jupyter Notebook 來運行,容易發生中斷。且由于預訓練規模大,一般需要使用多卡進行分布式訓練,否則訓練時間太長。在這里,我們介紹如何基于上述代碼,使用 DeepSpeed 框架實現分布式訓練,從而完成業界可用的 LLM Pretrain。
長時間訓練一般使用 bash 腳本設定超參,再啟動寫好的 python 腳本實現訓練。我們使用一個 Python 腳本(./code/pretrain.py)來實現訓練全流程。
先導入所需第三方庫:
import logging
import math
import os
import sys
from dataclasses import dataclass, field
from torchdata.datapipes.iter import IterableWrapper
from itertools import chain
import deepspeed
from typing import Optional,Listimport datasets
import pandas as pd
import torch
from datasets import load_dataset
import transformers
from transformers import (AutoConfig,AutoModelForCausalLM,AutoTokenizer,HfArgumentParser,Trainer,TrainingArguments,default_data_collator,set_seed,
)
import datetime
from transformers.testing_utils import CaptureLogger
from transformers.trainer_utils import get_last_checkpoint
import swanlab
首先需要定義幾個超參的類型,用于處理 sh 腳本中設定的超參值。由于 transformers 本身有 TraingingArguments 類,其中包括了訓練的一些必備超參數。我們這里只需定義 TrainingArguments 中未包含的超參即可,主要包括模型相關的超參(定義在 ModelArguments)和數據相關的超參(定義在 DataTrainingArguments):
# 超參類
@dataclass
class ModelArguments:"""關于模型的參數"""model_name_or_path: Optional[str] = field(default=None,metadata={"help": ("后訓練使用,為預訓練模型參數地址")},)config_name: Optional[str] = field(default=None, metadata={"help": "預訓練使用,Config 文件地址"})tokenizer_name: Optional[str] = field(default=None, metadata={"help": "預訓練 Tokenizer 地址"})torch_dtype: Optional[str] = field(default=None,metadata={"help": ("模型訓練使用的數據類型,推薦 bfloat16"),"choices": ["auto", "bfloat16", "float16", "float32"],},)@dataclass
class DataTrainingArguments:"""關于訓練的參數"""train_files: Optional[List[str]] = field(default=None, metadata={"help": "訓練數據路徑"})block_size: Optional[int] = field(default=None,metadata={"help": ("設置的文本塊長度")},)preprocessing_num_workers: Optional[int] = field(default=None,metadata={"help": "預處理使用線程數."},)
然后即可定義一個主函數實現上述訓練過程的封裝。首先通過 transformers 提供的 HfArgumentParser 工具來加載 sh 腳本中設定的超參:
# 加載腳本參數
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
在大規模的訓練中,一般使用 log 來保存訓練過程的信息,一般不推薦使用 print 直接打印,容易發生關鍵訓練信息的丟失。這里,我們直接使用 python 自帶的 logging 庫來實現日志記錄。首先需要進行 log 的設置:
# 設置日志
logging.basicConfig(format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",datefmt="%m/%d/%Y %H:%M:%S",handlers=[logging.StreamHandler(sys.stdout)],
)# 將日志級別設置為 INFO
transformers.utils.logging.set_verbosity_info()
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
這里將日志的級別設置為 INFO。logging 的日志共有 DEBUG、INFO、WARNING、ERROR 以及 CRITICAL 五個級別,將日志設置為哪個級別,就會只輸出該級別及該級別之上的信息。設置完成后,在需要記錄日志的地方,直接使用 logger 即可,記錄時會指定記錄日志的級別,例如:
# 訓練整體情況記錄
logger.warning(f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"+ f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
)
logger.info(f"Training/evaluation parameters {training_args}")
后續就不再贅述腳本中的日志記錄。
在大規模訓練中,發生中斷是往往難以避免的,訓練一般會固定間隔保存 checkpoint,中斷之后基于最近的 checkpoint 恢復訓練即可。因此,我們需要首先檢測是否存在舊的 checkpoint 并從 checkpoint 恢復訓練:
# 檢查 checkpoint
last_checkpoint = None
if os.path.isdir(training_args.output_dir):# 使用 transformers 自帶的 get_last_checkpoint 自動檢測last_checkpoint = get_last_checkpoint(training_args.output_dir)if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:raise ValueError(f"輸出路徑 ({training_args.output_dir}) 非空 ")elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:logger.info(f"從 {last_checkpoint}恢復訓練")
接著以上文介紹過的方式初始化模型,此處將從零初始化和基于已有預訓練模型初始化包裝在一起:
# 初始化模型
if model_args.config_name is not None:# from scrachconfig = AutoConfig.from_pretrained(model_args.config_name)logger.warning("你正在從零初始化一個模型")logger.info(f"模型參數配置地址:{model_args.config_name}")logger.info(f"模型參數:{config}")model = AutoModelForCausalLM.from_config(config,trust_remote_code=True)n_params = sum({p.data_ptr(): p.numel() for p in model.parameters()}.values())logger.info(f"預訓練一個新模型 - Total size={n_params/2**20:.2f}M params")
elif model_args.model_name_or_path is not None:logger.warning("你正在初始化一個預訓練模型")logger.info(f"模型參數地址:{model_args.model_name_or_path}")model = AutoModelForCausalLM.from_pretrained(model_args.model_name_or_path,trust_remote_code=True)n_params = sum({p.data_ptr(): p.numel() for p in model.parameters()}.values())logger.info(f"繼承一個預訓練模型 - Total size={n_params/2**20:.2f}M params")
else:logger.error("config_name 和 model_name_or_path 不能均為空")raise ValueError("config_name 和 model_name_or_path 不能均為空")
再類似的進行 tokenizer 的加載和預訓練數據的處理。該部分和上文完全一致,此處不再贅述,讀者可以在代碼中詳細查看細節。類似的,使用 Trainer 進行訓練:
logger.info("初始化 Trainer")
trainer = Trainer(model=model,args=training_args,train_dataset= IterableWrapper(train_dataset),tokenizer=tokenizer,data_collator=default_data_collator
)# 從 checkpoint 加載
checkpoint = None
if training_args.resume_from_checkpoint is not None:checkpoint = training_args.resume_from_checkpoint
elif last_checkpoint is not None:checkpoint = last_checkpointlogger.info("開始訓練")
train_result = trainer.train(resume_from_checkpoint=checkpoint)
trainer.save_model()
注意,由于上文檢測了是否存在 checkpoint,此處使用 resume_from_checkpoint 來實現從 checkpoint 恢復訓練的功能。
由于在大規模訓練中監測訓練進度、loss 下降趨勢尤為重要,在腳本中,我們使用了 swanlab 作為訓練檢測的工具。在腳本開始進行了 swanlab 的初始化:
# 初始化 SwanLab
swanlab.init(project="pretrain", experiment_name="from_scrach")
在啟動訓練后,終端會輸出 swanlab 監測的 url,點擊即可觀察訓練進度。此處不再贅述 swanlab 的使用細節,歡迎讀者查閱相關的資料說明。
完成上述代碼后,我們使用一個 sh 腳本(./code/pretrain.sh)定義超參數的值,并通過 Deepspeed 啟動訓練,從而實現高效的多卡分布式訓練:
# 設置可見顯卡
CUDA_VISIBLE_DEVICES=0,1deepspeed pretrain.py \--config_name autodl-tmp/qwen-1.5b \--tokenizer_name autodl-tmp/qwen-1.5b \--train_files autodl-tmp/dataset/pretrain_data/mobvoi_seq_monkey_general_open_corpus_small.jsonl \--per_device_train_batch_size 16 \--gradient_accumulation_steps 4 \--do_train \--output_dir autodl-tmp/output/pretrain \--evaluation_strategy no \--learning_rate 1e-4 \--num_train_epochs 1 \--warmup_steps 200 \--logging_dir autodl-tmp/output/pretrain/logs \--logging_strategy steps \--logging_steps 5 \--save_strategy steps \--save_steps 100 \--preprocessing_num_workers 10 \--save_total_limit 1 \--seed 12 \--block_size 2048 \--bf16 \--gradient_checkpointing \--deepspeed ./ds_config_zero2.json \--report_to swanlab# --resume_from_checkpoint ${output_model}/checkpoint-20400 \
在安裝了 Deepspeed 第三方庫后,可以直接通過 Deepspeed 命令來啟動多卡訓練。上述腳本命令主要是定義了各種超參數的值,可參考使用。在第四章中,我們介紹了 DeepSpeed 分布式訓練的原理和 ZeRO 階段設置,在這里,我們使用 ZeRO-2 進行訓練。此處加載了 ds_config_zero.json 作為 DeepSpeed 的配置參數:
{"fp16": {"enabled": "auto","loss_scale": 0,"loss_scale_window": 1000,"initial_scale_power": 16,"hysteresis": 2,"min_loss_scale": 1},"bf16": {"enabled": "auto"},"optimizer": {"type": "AdamW","params": {"lr": "auto","betas": "auto","eps": "auto","weight_decay": "auto"}},"scheduler": {"type": "WarmupLR","params": {"warmup_min_lr": "auto","warmup_max_lr": "auto","warmup_num_steps": "auto"}},"zero_optimization": {"stage": 2,"offload_optimizer": {"device": "none","pin_memory": true},"allgather_partitions": true,"allgather_bucket_size": 2e8,"overlap_comm": true,"reduce_scatter": true,"reduce_bucket_size": 2e8,"contiguous_gradients": true},"gradient_accumulation_steps": "auto","gradient_clipping": "auto","steps_per_print": 100,"train_batch_size": "auto","train_micro_batch_size_per_gpu": "auto","wall_clock_breakdown": false
}
最后,在終端 bash 運行該 pretrain.sh 腳本即可開始訓練。
6.2 模型有監督微調
在上一節,我們介紹了如何使用 Transformers 框架快速、高效地進行模型預訓練。在本部分,我們將基于上部分內容,介紹如何使用 Transformers 框架對預訓練好的模型進行有監督微調。
6.2.1 Pretrain VS SFT
首先需要回顧一下,對 LLM 進行預訓練和進行有監督微調的核心差異在于什么。在第四章中提到過,目前成型的 LLM 一般通過 Pretrain-SFT-RLHF 三個階段來訓練,在 Pretrain 階段,會對海量無監督文本進行自監督建模,來學習文本語義規則和文本中的世界知識;在 SFT 階段,一般通過對 Pretrain 好的模型進行指令微調,即訓練模型根據用戶指令完成對應任務,從而使模型能夠遵循用戶指令,根據用戶指令進行規劃、行動和輸出。因此,Pretrain 和 SFT 均使用 CLM 建模,其核心差異在于,Pretrain 使用海量無監督文本進行訓練,模型直接對文本執行“預測下一個 token”的任務;而 SFT 使用構建成對的指令對數據,模型根據輸入的指令,建模后續的輸出。反映到具體的訓練實現上,Pretrain 會對全部 text 進行 loss 計算,要求模型對整個文本實現建模預測;而 SFT 僅對輸出進行 loss 計算,不計算指令部分的 loss。
因此,相較于上一節完成的 Pretrain 代碼,SFT 部分僅需要修改數據處理環節,實現對指令對數據轉化為訓練樣本的構建,其余部分和 Pretrain 是完全一致的實現邏輯。本部分代碼腳本為./code/finetune.py。
6.2.2 微調數據處理
同樣與第五章類似,我們此處使用貝殼開源的 BelleGroup 數據集進行 SFT。
在 SFT 過程中,我們會定義一個 Chat Template,這個 Template 即表示了如何將對話數據轉化為一個模型可以建模擬合的文本序列。當我們使用做過 SFT 的模型進行下游任務微調時,一般需要查看該模型的 Chat Template 并進行適配,即是為了不損傷其在 SFT 中學到的指令遵循能力。由于我們此處使用 Pretrain 模型進行 SFT,可以自定義一個 Chat Template。由于我們使用了 Qwen-2.5-1.5B 模型結構進行 Pretrain,此處我們沿承使用 Qwen-2.5 的 Chat Template。如果讀者沒有足夠的資源進行上一部分模型的 Pretrain 的話,此處也可以使用官方的 Qwen-2.5-1.5B 模型作為 SFT 的基座模型。
我們首先定義幾個特殊 token,特殊 token 在模型進行擬合中有特殊的作用,包括文本序列開始(BOS)、文本序列結束(EOS)、換行符等。定義特殊 token,有助于避免模型在擬合過程中的語義混淆:
# 不同的 tokenizer 需要特別定義
# BOS
im_start = tokenizer("<|im_start|>").input_ids
# EOS
im_end = tokenizer("<|im_end|>").input_ids
# PAD
IGNORE_TOKEN_ID = tokenizer.pad_token_id
# 換行符
nl_tokens = tokenizer('\n').input_ids
# 角色標識符
_system = tokenizer('system').input_ids + nl_tokens
_user = tokenizer('human').input_ids + nl_tokens
_assistant = tokenizer('assistant').input_ids + nl_tokens
Qwen 系列的 Chat Template 一般有三個對話角色:System、User 和 Assistant。System 是系統提示詞,負責激活模型的能力,默認為“You are a helpful assistant.”,一般不會在 SFT 過程中更改使用。User 即為用戶給出的提示詞,此處由于數據集中的對話角色為 “human”,我們將 “user” 修改為了“human”。Assistant 即為 LLM 給出的回復,也就是模型在 SFT 過程中需要擬合的文本。
接著,由于該數據集是一個多輪對話數據集,我們需要對多輪對話進行拼接處理,將多輪對話拼接到一個文本序列中:
# 拼接多輪對話
input_ids, targets = [], []
# 多個樣本
for i in tqdm(range(len(sources))):# source 為一個多輪對話樣本source = sources[i]# 從 user 開始if source[0]["from"] != "human":source = source[1:]# 分別是輸入和輸出input_id, target = [], []# system: 【BOS】system\nYou are a helpful assistant.【EOS】\nsystem = im_start + _system + tokenizer(system_message).input_ids + im_end + nl_tokensinput_id += system# system 不需要擬合target += im_start + [IGNORE_TOKEN_ID] * (len(system)-3) + im_end + nl_tokensassert len(input_id) == len(target)# 依次拼接for j, sentence in enumerate(source):# sentence 為一輪對話role = roles[sentence["from"]]# user:<|im_start|>human\ninstruction【EOS】\n# assistant:<|im_start|>assistant\nresponse【EOS】\n_input_id = tokenizer(role).input_ids + nl_tokens + \tokenizer(sentence["value"]).input_ids + im_end + nl_tokensinput_id += _input_idif role == '<|im_start|>human':# user 不需要擬合_target = im_start + [IGNORE_TOKEN_ID] * (len(_input_id)-3) + im_end + nl_tokenselif role == '<|im_start|>assistant':# assistant 需要擬合_target = im_start + [IGNORE_TOKEN_ID] * len(tokenizer(role).input_ids) + \_input_id[len(tokenizer(role).input_ids)+1:-2] + im_end + nl_tokenselse:print(role)raise NotImplementedErrortarget += _targetassert len(input_id) == len(target)# 最后進行 PADinput_id += [tokenizer.pad_token_id] * (max_len - len(input_id))target += [IGNORE_TOKEN_ID] * (max_len - len(target))input_ids.append(input_id[:max_len])targets.append(target[:max_len])
上述代碼沿承了 Qwen 的 Chat Template 邏輯,讀者也可以根據自己的偏好進行修改,其核心點在于 User 的文本不需要擬合,因此 targets 中 User 對應的文本內容是使用的 IGNORE_TOKEN_ID 進行遮蔽,而 Assistant 對應的文本內容則是文本原文,是需要計算 loss 的。目前主流 LLM IGNORE_TOKEN_ID 一般設置為 -100。
完成拼接后,將 tokenize 后的數值序列轉化為 Torch.tensor,再拼接成 Dataset 所需的字典返回即可:
input_ids = torch.tensor(input_ids)
targets = torch.tensor(targets)return dict(input_ids=input_ids,labels=targets,attention_mask=input_ids.ne(tokenizer.pad_token_id),
)
完成上述處理邏輯后,需要自定義一個 Dataset 類,在該類中調用該邏輯進行數據的處理:
class SupervisedDataset(Dataset):def __init__(self, raw_data, tokenizer, max_len: int):super(SupervisedDataset, self).__init__()# 加載并預處理數據sources = [example["conversations"] for example in raw_data]# preprocess 即上文定義的數據預處理邏輯data_dict = preprocess(sources, tokenizer, max_len)self.input_ids = data_dict["input_ids"]self.labels = data_dict["labels"]self.attention_mask = data_dict["attention_mask"]def __len__(self):return len(self.input_ids)def __getitem__(self, i) -> Dict[str, torch.Tensor]:return dict(input_ids=self.input_ids[i],labels=self.labels[i],attention_mask=self.attention_mask[i],)
該類繼承自 Torch 的 Dataset 類,可以直接在 Trainer 中使用。完成數據處理后,基于上一節腳本,修改數據處理邏輯即可,后續模型訓練等幾乎完全一致,此處附上主函數邏輯:
# 加載腳本參數
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
model_args, data_args, training_args = parser.parse_args_into_dataclasses()# 初始化 SwanLab
swanlab.init(project="sft", experiment_name="qwen-1.5b")# 設置日志
logging.basicConfig(format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",datefmt="%m/%d/%Y %H:%M:%S",handlers=[logging.StreamHandler(sys.stdout)],
)# 將日志級別設置為 INFO
transformers.utils.logging.set_verbosity_info()
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()# 訓練整體情況記錄
logger.warning(f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"+ f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
)
logger.info(f"Training/evaluation parameters {training_args}")# 檢查 checkpoint
last_checkpoint = None
if os.path.isdir(training_args.output_dir):last_checkpoint = get_last_checkpoint(training_args.output_dir)if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:raise ValueError(f"輸出路徑 ({training_args.output_dir}) 非空 ")elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:logger.info(f"從 {last_checkpoint}恢復訓練")# 設置隨機數種子.
set_seed(training_args.seed)# 初始化模型
logger.warning("加載預訓練模型")
logger.info(f"模型參數地址:{model_args.model_name_or_path}")
model = AutoModelForCausalLM.from_pretrained(model_args.model_name_or_path,trust_remote_code=True)
n_params = sum({p.data_ptr(): p.numel() for p in model.parameters()}.values())
logger.info(f"繼承一個預訓練模型 - Total size={n_params/2**20:.2f}M params")# 初始化 Tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path)
logger.info("完成 tokenizer 加載")# 加載微調數據
with open(data_args.train_files) as f:lst = [json.loads(line) for line in f.readlines()[:10000]]
logger.info("完成訓練集加載")
logger.info(f"訓練集地址:{data_args.train_files}")
logger.info(f'訓練樣本總數:{len(lst)}')
# logger.info(f"訓練集采樣:{ds["train"][0]}")train_dataset = SupervisedDataset(lst, tokenizer=tokenizer, max_len=2048)logger.info("初始化 Trainer")
trainer = Trainer(model=model,args=training_args,train_dataset= IterableWrapper(train_dataset),tokenizer=tokenizer
)# 從 checkpoint 加載
checkpoint = None
if training_args.resume_from_checkpoint is not None:checkpoint = training_args.resume_from_checkpoint
elif last_checkpoint is not None:checkpoint = last_checkpointlogger.info("開始訓練")
train_result = trainer.train(resume_from_checkpoint=checkpoint)
trainer.save_model()
啟動方式也同樣在 sh 腳本中使用 deepspeed 啟動即可,此處不再贅述,源碼見 ./code/finetune.sh。
6.3 高效微調
在前面幾節,我們詳細介紹了基于 Transformers 框架對模型進行 Pretrain、SFT 以及 RLHF 的原理和實踐細節。但是,由于 LLM 參數量大,訓練數據多,通過上述方式對模型進行訓練(主要指 SFT 及 RLHF)需要調整模型全部參數,資源壓力非常大。對資源有限的企業或課題組來說,如何高效、快速對模型進行領域或任務的微調,以低成本地使用 LLM 完成目標任務,是非常重要的。
6.3.1 高效微調方案
針對全量微調的昂貴問題,目前主要有兩種解決方案:
Adapt Tuning。即在模型中添加 Adapter 層,在微調時凍結原參數,僅更新 Adapter 層。
具體而言,其在預訓練模型每層中插入用于下游任務的參數,即 Adapter 模塊,在微調時凍結模型主體,僅訓練特定于任務的參數,如圖6.8所示。
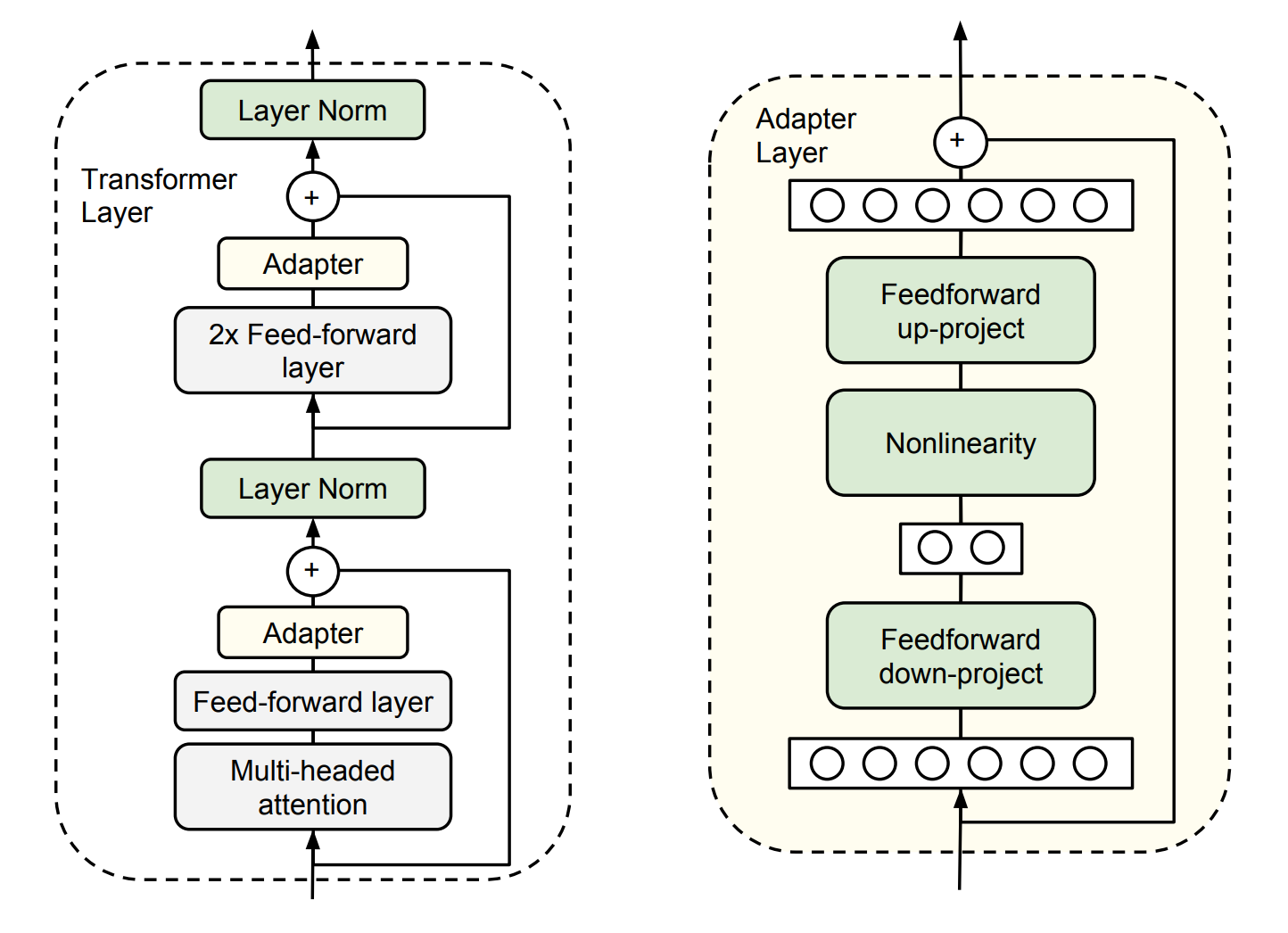
圖6.8 Adapt Tuning
每個 Adapter 模塊由兩個前饋子層組成,第一個前饋子層將 Transformer 塊的輸出作為輸入,將原始輸入維度 ddd 投影到 mmm,通過控制 mmm 的大小來限制 Adapter 模塊的參數量,通常情況下 m<<dm << dm<<d。在輸出階段,通過第二個前饋子層還原輸入維度,將 mmm 重新投影到 ddd,作為 Adapter 模塊的輸出(如上圖右側結構)。
LoRA 事實上就是一種改進的 Adapt Tuning 方法。但 Adapt Tuning 方法存在推理延遲問題,由于增加了額外參數和額外計算量,導致微調之后的模型計算速度相較原預訓練模型更慢。
Prefix Tuning。該種方法固定預訓練 LM,為 LM 添加可訓練,任務特定的前綴,這樣就可以為不同任務保存不同的前綴,微調成本也小。具體而言,在每一個輸入 token 前構造一段與下游任務相關的 virtual tokens 作為 prefix,在微調時只更新 prefix 部分的參數,而其他參數凍結不變。
也是目前常用的微量微調方法的 Ptuning,其實就是 Prefix Tuning 的一種改進。但 Prefix Tuning 也存在固定的缺陷:模型可用序列長度減少。由于加入了 virtual tokens,占用了可用序列長度,因此越高的微調質量,模型可用序列長度就越低。
6.3.2 LoRA 微調
如果一個大模型是將數據映射到高維空間進行處理,這里假定在處理一個細分的小任務時,是不需要那么復雜的大模型的,可能只需要在某個子空間范圍內就可以解決,那么也就不需要對全量參數進行優化了,我們可以定義當對某個子空間參數進行優化時,能夠達到全量參數優化的性能的一定水平(如90%精度)時,那么這個子空間參數矩陣的秩就可以稱為對應當前待解決問題的本征秩(intrinsic rank)。
預訓練模型本身就隱式地降低了本征秩,當針對特定任務進行微調后,模型中權重矩陣其實具有更低的本征秩(intrinsic rank)。同時,越簡單的下游任務,對應的本征秩越低。(Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning)因此,權重更新的那部分參數矩陣盡管隨機投影到較小的子空間,仍然可以有效的學習,可以理解為針對特定的下游任務這些權重矩陣就不要求滿秩。我們可以通過優化密集層在適應過程中變化的秩分解矩陣來間接訓練神經網絡中的一些密集層,從而實現僅優化密集層的秩分解矩陣來達到微調效果。
例如,假設預訓練參數為 θ0D\theta^D_0θ0D?,在特定下游任務上密集層權重參數矩陣對應的本征秩為 θd\theta^dθd,對應特定下游任務微調參數為 θD\theta^DθD,那么有:
θD=θ0D+θdM\theta^D = \theta^D_0 + \theta^d MθD=θ0D?+θdM
這個 MMM 即為 LoRA 優化的秩分解矩陣。
想對于其他高效微調方法,LoRA 存在以下優勢:
- 可以針對不同的下游任務構建小型 LoRA 模塊,從而在共享預訓練模型參數基礎上有效地切換下游任務。
- LoRA 使用自適應優化器(Adaptive Optimizer),不需要計算梯度或維護大多數參數的優化器狀態,訓練更有效、硬件門檻更低。
- LoRA 使用簡單的線性設計,在部署時將可訓練矩陣與凍結權重合并,不存在推理延遲。
- LoRA 與其他方法正交,可以組合。
因此,LoRA 成為目前高效微調 LLM 的主流方法,尤其是對于資源受限、有監督訓練數據受限的情況下,LoRA 微調往往會成為 LLM 微調的首選方法。
6.3.3 LoRA 微調的原理
(1)低秩參數化更新矩陣
LoRA 假設權重更新的過程中也有一個較低的本征秩,對于預訓練的權重參數矩陣 W0∈Rd×kW0 \in R^{d \times k}W0∈Rd×k (ddd 為上一層輸出維度,kkk 為下一層輸入維度),使用低秩分解來表示其更新:
W0+ΔW=W0+BAwhereB∈Rd×r,A∈Rr×kW_0 + {\Delta}W = W_0 + BA \space\space where \space B \in R^{d \times r}, A \in R^{r \times k}W0?+ΔW=W0?+BA??where?B∈Rd×r,A∈Rr×k
在訓練過程中,W0W_0W0? 凍結不更新,AAA、BBB 包含可訓練參數。
因此,LoRA 的前向傳遞函數為:
h=W0x+ΔWx=W0x+BAxh = W_0 x + \Delta W x = W_0 x + B A xh=W0?x+ΔWx=W0?x+BAx
在開始訓練時,對 AAA 使用隨機高斯初始化,對 BBB 使用零初始化,然后使用 Adam 進行優化。
訓練思路如圖6.9所示:
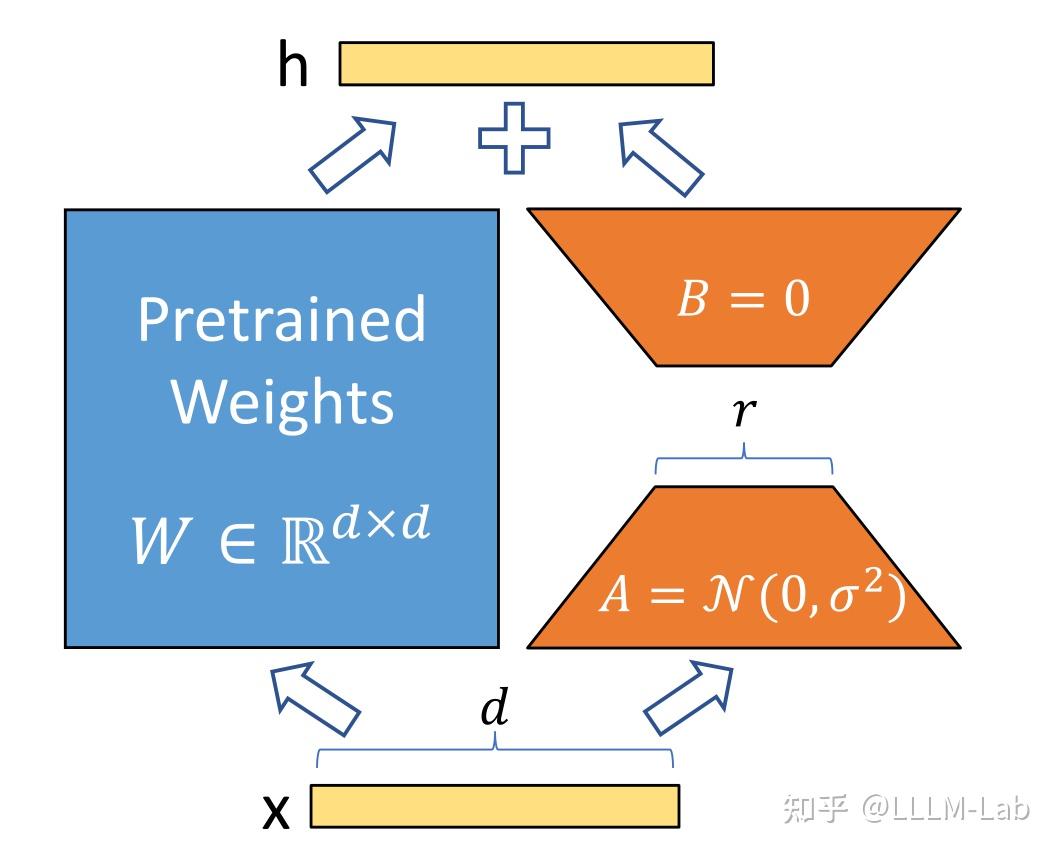
圖6.9 LoRA
(2)應用于 Transformer
在 Transformer 結構中,LoRA 技術主要應用在注意力模塊的四個權重矩陣:WqW_qWq?、WkW_kWk?、WvW_vWv?、W0W_0W0?,而凍結 MLP 的權重矩陣。
通過消融實驗發現同時調整 WqW_qWq? 和 WvW_vWv? 會產生最佳結果。
在上述條件下,可訓練參數個數為:
Θ=2×LLoRA×dmodel×r\Theta = 2 \times L_{LoRA} \times d_{model} \times rΘ=2×LLoRA?×dmodel?×r
其中,LLoRAL_{LoRA}LLoRA? 為應用 LoRA 的權重矩陣的個數,dmodeld_{model}dmodel? 為 Transformer 的輸入輸出維度,rrr 為設定的 LoRA 秩。
一般情況下,r 取到 4、8、16。
6.3.4 LoRA 的代碼實現
目前一般通過 peft 庫來實現模型的 LoRA 微調。peft 庫是 huggingface 開發的第三方庫,其中封裝了包括 LoRA、Adapt Tuning、P-tuning 等多種高效微調方法,可以基于此便捷地實現模型的 LoRA 微調。
本文簡單解析 peft 庫中的 LoRA 微調代碼,簡單分析 LoRA 微調的代碼實現。
(1)實現流程
LoRA 微調的內部實現流程主要包括以下幾個步驟:
-
確定要使用 LoRA 的層。peft 庫目前支持調用 LoRA 的層包括:nn.Linear、nn.Embedding、nn.Conv2d 三種。
-
對每一個要使用 LoRA 的層,替換為 LoRA 層。所謂 LoRA 層,實則是在該層原結果基礎上增加了一個旁路,通過低秩分解(即矩陣 AAA 和矩陣 BBB)來模擬參數更新。
-
凍結原參數,進行微調,更新 LoRA 層參數。
(2)確定 LoRA 層
在進行 LoRA 微調時,首先需要確定 LoRA 微調參數,其中一個重要參數即是 target_modules。target_modules 一般是一個字符串列表,每一個字符串是需要進行 LoRA 的層名稱,例如:
target_modules = ["q_proj","v_proj"]
這里的 q_proj 即為注意力機制中的 WqW_qWq?, v_proj 即為注意力機制中的 WvW_vWv?。我們可以根據模型架構和任務要求自定義需要進行 LoRA 操作的層。
在創建 LoRA 模型時,會獲取該參數,然后在原模型中找到對應的層,該操作主要通過使用 re 對層名進行正則匹配實現:
# 找到模型的各個組件中,名字里帶"q_proj","v_proj"的
target_module_found = re.fullmatch(self.peft_config.target_modules, key)
# 這里的 key,是模型的組件名
(3)替換 LoRA 層
對于找到的每一個目標層,會創建一個新的 LoRA 層進行替換。
LoRA 層在具體實現上,是定義了一個基于 Lora 基類的 Linear 類,該類同時繼承了 nn.Linear 和 LoraLayer。LoraLayer 即是 Lora 基類,其主要構造了 LoRA 的各種超參:
class LoraLayer:def __init__(self,r: int, # LoRA 的秩lora_alpha: int, # 歸一化參數lora_dropout: float, # LoRA 層的 dropout 比例merge_weights: bool, # eval 模式中,是否將 LoRA 矩陣的值加到原權重矩陣上):self.r = rself.lora_alpha = lora_alpha# Optional dropoutif lora_dropout > 0.0:self.lora_dropout = nn.Dropout(p=lora_dropout)else:self.lora_dropout = lambda x: x# Mark the weight as unmergedself.merged = Falseself.merge_weights = merge_weightsself.disable_adapters = Falsenn.Linear 就是 Pytorch 的線性層實現。Linear 類就是具體的 LoRA 層,其主要實現如下:
class Linear(nn.Linear, LoraLayer):# LoRA 層def __init__(self,in_features: int,out_features: int,r: int = 0,lora_alpha: int = 1,lora_dropout: float = 0.0,fan_in_fan_out: bool = False, merge_weights: bool = True,**kwargs,):# 繼承兩個基類的構造函數nn.Linear.__init__(self, in_features, out_features, **kwargs)LoraLayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout, merge_weights=merge_weights)self.fan_in_fan_out = fan_in_fan_out# Actual trainable parametersif r > 0:# 參數矩陣 Aself.lora_A = nn.Linear(in_features, r, bias=False)# 參數矩陣 Bself.lora_B = nn.Linear(r, out_features, bias=False)# 歸一化系數self.scaling = self.lora_alpha / self.r# 凍結原參數,僅更新 A 和 Bself.weight.requires_grad = False# 初始化 A 和 Bself.reset_parameters()if fan_in_fan_out:self.weight.data = self.weight.data.T替換時,直接將原層的 weight 和 bias 復制給新的 LoRA 層,再將新的 LoRA 層分配到指定設備即可。
(4)訓練
實現了 LoRA 層的替換后,進行微調訓練即可。由于在 LoRA 層中已凍結原參數,在訓練中只有 A 和 B 的參數會被更新,從而實現了高效微調。訓練的整體過程與原 Fine-tune 類似,此處不再贅述。由于采用了 LoRA 方式,forward 函數也會對應調整:
def forward(self, x: torch.Tensor):if self.disable_adapters:if self.r > 0 and self.merged:self.weight.data -= (transpose(self.lora_B.weight @ self.lora_A.weight, self.fan_in_fan_out) * self.scaling)self.merged = Falsereturn F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)'''主要分支'''elif self.r > 0 and not self.merged:result = F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)if self.r > 0:result += self.lora_B(self.lora_A(self.lora_dropout(x))) * self.scalingreturn resultelse:return F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)上述代碼由于考慮到參數合并問題,有幾個分支,此處我們僅閱讀第二個分支即 elif 分支即可。基于 LoRA 的前向計算過程如前文公式所示,首先計算原參數與輸入的乘積,再加上 A、B 分別與輸入的乘積即可。
6.3.5 使用 peft 實現 LoRA 微調
peft 進行了很好的封裝,支持我們便捷、高效地對大模型進行微調。此處以第二節的 LLM SFT 為例,簡要介紹如何使用 peft 對大模型進行微調。如果是應用在 RLHF 上,整體思路是一致的。
首先加載所需使用庫:
import torch.nn as nn
from transformers import AutoTokenizer, AutoModel
from peft import get_peft_model, LoraConfig, TaskType, PeftModel
from transformers import Trainer
其次加載原模型與原 tokenizer,此處和第二節一致:
# 加載基座模型
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True)
model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True
)
接著,設定 peft 參數:
peft_config = LoraConfig(task_type=TaskType.CAUSAL_LM,inference_mode=False,r=8,lora_alpha=32,lora_dropout=0.1,)
注意,對不同的模型,LoRA 參數可能有所區別。例如,對于 ChatGLM,無需指定 target_modeules,peft 可以自行找到;對于 BaiChuan,就需要手動指定。task_type 是模型的任務類型,大模型一般都是 CAUSAL_LM 即傳統語言模型。
然后獲取 LoRA 模型:
model = get_peft_model(model, peft_config)
此處的 get_peft_model 的底層操作,即為上文分析的具體實現。
最后使用 transformers 提供的 Trainer 進行訓練即可,訓練占用的顯存就會有大幅度的降低:
trainer = Trainer(model=model,args=training_args,train_dataset= IterableWrapper(train_dataset),tokenizer=tokenizer
)
trainer.train()
如果是應用在 DPO、KTO 上,則也相同的加入 LoRA 參數并通過 get_peft_model 獲取一個 LoRA 模型即可,其他的不需要進行任何修改。但要注意的是,LoRA 微調能夠大幅度降低顯卡占用,且在下游任務適配上能夠取得較好的效果,但如果是需要學習對應知識的任務,LoRA 由于只調整低秩矩陣,難以實現知識的注入,一般效果不佳,因此不推薦使用 LoRA 進行模型預訓練或后訓練。
)

)


)
、CommonJS(CJS)和UMD三種格式)
)
:高級實現——平衡源項、邊界條件與算法總成)
技術解析)


)






