本文整理自 2025 年 8 月 29 日百度云智大會 —— AI + 算力平臺專題論壇,百度智能云 AI 計算首席科學家王雁鵬的同名主題演講。
大家下午好!昨天在主論壇,我們正式發布了百度百舸 AI 計算平臺 5.0,并展示了多項亮眼的性能數據。今天,我將從技術層面,與大家進行一次深度的探討和解讀。
百度百舸 4.0 發布的核心特性是支持十萬卡集群的穩定訓練,其能力主要圍繞大規模訓練場景構建。
過去一年,AI 技術的進展與落地速度前所未有,這使得我們的工作負載發生了根本性的變化。
我們正從以預訓練為主的單一負載,進入了一個混合負載的新階段。模型結構上,從傳統的稠密 Dense 模型,發展到 MoE 模型、多模態模型為主。業務場景上,用戶除了預訓練需求,在線推理、SFT、強化學習等需求占比顯著提升。
因此,百舸 5.0 進行了全面的升級:
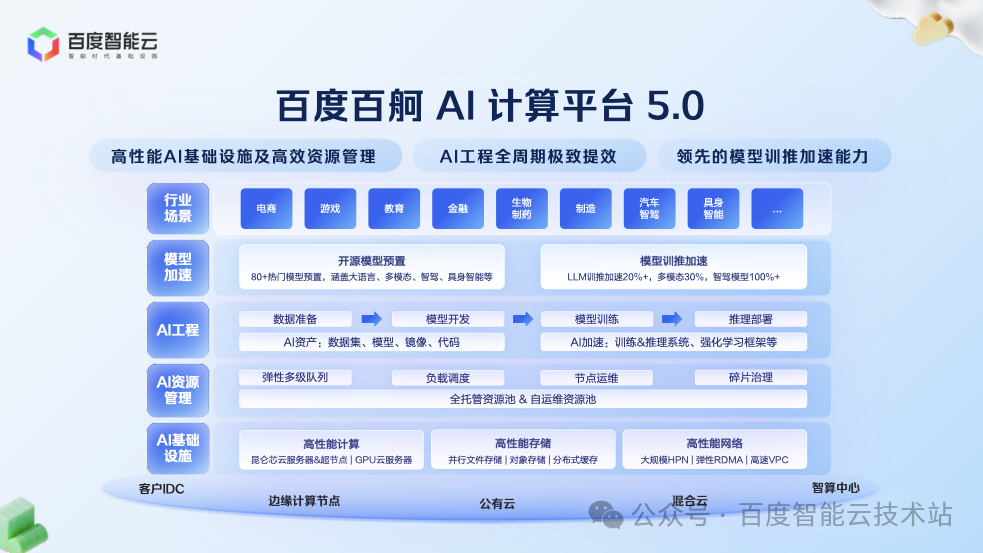
在 AI 基礎設施層面和資源管理層面,提供高性能的 AI 計算、AI 網絡、AI 存儲等產品,支持單一集群內高效的訓推混部。
在 AI 工程層面,覆蓋從數據準備、模型開發、模型訓練和推理部署的 AI 全流程,提供端到端產品能力。
在模型加速層面,對 Dense、MoE 等各類開源熱門模型均進行了深度性能加速,并以易用的產品化能力提供給客戶,讓加速能力可直接落地。
新出現的各類模型的迭代催生了新興行業的爆發式增長,而大模型能力的持續躍升,進一步加速了 AI 技術在各行業的深度落地進程。
百舸平臺精準銜接上層行業工具鏈,憑借一體化的技術和工程支撐能力,為具身智能、汽車智駕、電商等關鍵領域及場景賦能,有效降低 AI 應用門檻,助力相關行業加速實現 AI 技術的規模化落地與價值轉化。
今天分享的核心,是過去一年最重要的變局 ——?MoE 模型的興起。
某種意義上,MoE 是延續 Scaling Law 的關鍵創新。如果繼續使用 Dense 模型,參數量翻番帶來的計算量將無法承受,Scaling Law 將難以為繼。而 MoE 的邏輯是:僅激活部分專家層參與計算,在參數量翻倍的同時,計算量基本不變。這使得模型能力得以持續提升。
然而,MoE 架構給基礎設施帶來了巨大挑戰:
參數量劇增:訓練和推理從單機/單卡,走向大規模分布式集群。
通信量激增:計算量雖未大增,但通信量大幅提升,計算與通信的比率發生劇變。
系統復雜性提升:整個集群的構建和管理面臨全新考驗。
因此,要真正發揮 MoE 的優勢,必須對基礎設施進行一場全面的系統性升級。百舸 5.0 正是圍繞這一目標,從芯片、框架到集群,進行全棧協同優化。

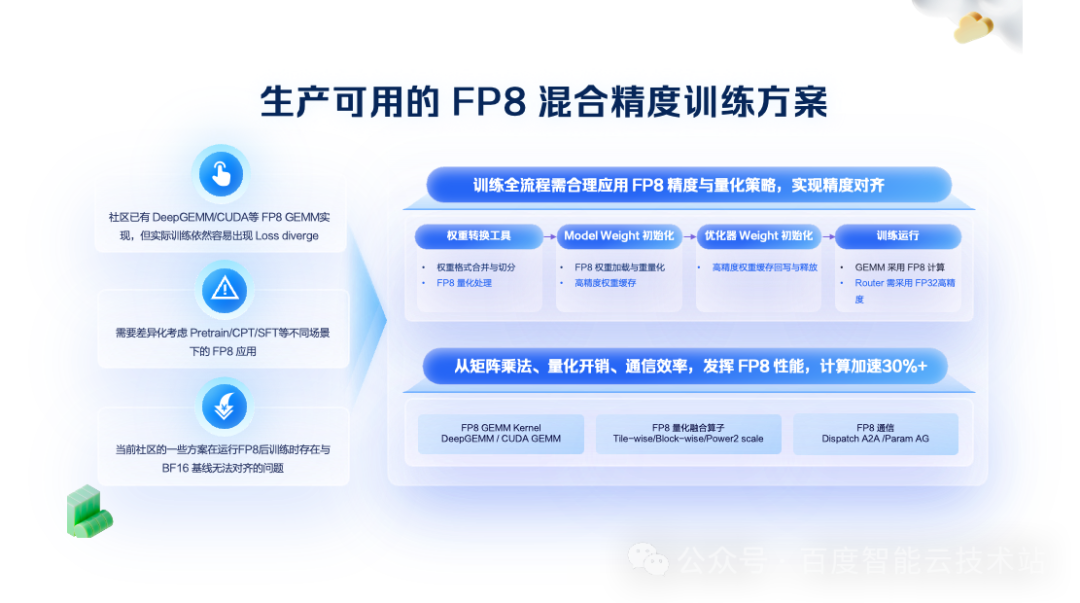
在訓練層面,百度百舸推出了「生產可用」的 FP8 混合精度訓練方案。
相比 BF16,FP8 能將計算量降低一半,理論性能提升巨大。但實踐中,即使接入第三方 NV 官方或者 FP8 算子庫,也可能會遇到 Loss 發散、推理陷入循環輸出、精度異常等問題。
實踐中,成功應用 FP8 進行訓練的關鍵,除了集成 FP8 GEMM Kernel 外,在訓練全流程階段合理應用 FP8 量化 Scale 模式也非常關鍵。為此,我們需要分階段考慮如何利用量化策略,具體包括:模型權重轉換、權重初始化、優化器初始化、訓練運行等。
通過這套全鏈路的方案,我們確保了在預訓練及 SFT 等后訓練過程中 FP8 的穩定應用。
在確保精度穩定后,我們進一步追求性能的極致。僅僅 GEMM 計算使用 FP8,對端到端性能提升有限。為此,我們進行了兩項關鍵優化:
算子融合:針對 FP8 引入的額外 Scale 算子,我們進行了更細粒度的融合,將其融入前向或后向計算中,大幅降低了算子開銷。
通信優化:通信在訓練中占比較大,若通信仍使用 FP16/FP32,將損失 FP8 的性能收益。我們調整并行策略,確保在通信過程中盡可能使用 FP8。
這套組合拳下來,我們實現了端到端訓練速度 30% 以上的提升。
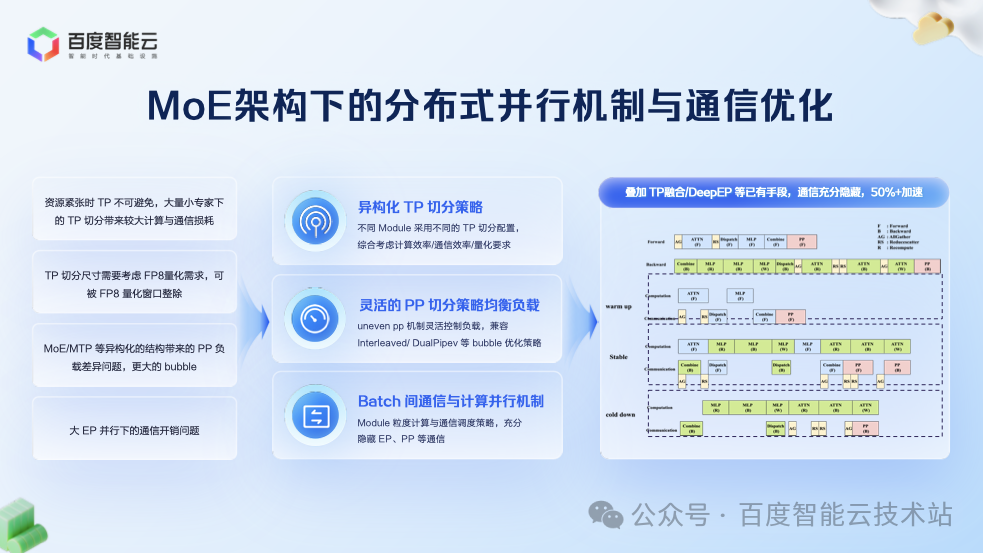
由于 Dense 模型結構規整,可均勻拆分到各顯卡并行。但是 MoE 模型兼具「稀疏性」與「計算不均衡性」,需重構分布式并行策略。百舸 5.0 對此進行了深度優化:
異構 TP 切分:針對模型中不同 MLP 大小和 Attention 尺寸的層,采用不同的張量并行(TP)切分邏輯(如 TP4、TP8),實現更高效的計算拆分。
動態 PP 切分:在流水線并行(PP)中,由于 MoE 層與稠密層計算特征差異巨大,我們采用動態均衡策略進行切分,確保各階段計算負載均衡。
通信隱藏:結合 TP 計算和通信并行、DeepEP 等技術,通過 ?Batch 間并行機制,將 MoE 模型中暴漲的通信量隱藏在計算過程中,減少 GPU 的等待。
經過這些優化,訓練吞吐提升了 50% 以上。
如果說訓練的升級是精進,那么推理的升級則是一場徹底的革命。MoE 時代的推理實例,已從單卡單臺機器擴展到幾十臺機器,成為一個龐大的分布式系統。
半年前,我們通過 PD 分離和 EP 并行,打下了業界領先的基礎。但這只是一個開始。要構建一個真正高效的系統,需要更深層次的重構。
我們首先將分離式架構進行到底。PD 分離之所以成為業界共識,是因為 Prefill 和 Decode 的計算模式不同,混在一起會沖突。我們發現,分離可以做得更徹底:
VIT 分離:將多模態模型中的視覺編碼(VIT)與語言模型計算分離,以適應不同的計算特征。
Attention-MLP 分離:將訪存密集型的 Attention 計算與計算密集型的 MLP(專家網絡)計算分離,使它們能在最適合的硬件上并行執行。
這種深度分離為性能的極致提升奠定了基礎。

作為線上系統,低延遲至關重要。隨著上下文長度向 128K 甚至更長發展,計算量呈平方級增長,對響應時間構成巨大挑戰(如 16K 輸入比 4K 輸入計算量高 16 倍)。
針對輸入長度跨度范圍大的生產場景,為了保證服務質量,我們的解決方案是采用自適應混合并行策略:
對于 16K 以下的輸入,我們力求在單機內解決。通過機內 TP 和 SP 并行,并對這些并行策略進行深度優化,最大化減少通信開銷,實現接近線性的加速比。
對于 128K 等超長序列,系統可自適應地將請求拆分到多臺機器上并行處理,通過機間 TP 和 SP 并行,結合 Attention 分塊計算 + 計算通信重疊,突破單機局限。
這一系列技術,使得我們能夠將 16K 輸入的首 Token 延遲(TTFT)控制在 0.5秒以內,128K 輸入的響應時間也僅為 3 秒左右,滿足了線上業務對低延遲的嚴苛要求。

當推理系統從單機擴展到幾十臺機器的分布式系統時,負載均衡成為決定系統吞吐的核心挑戰。
首先,是動態 DP 負載均衡(DPLB)。推理請求的長度是動態變化的,無法像訓練任務那樣預先分配固定的計算量。如果調度不均,部分計算單元會因任務過重而成為瓶頸,其他單元則可能空閑等待,造成資源浪費。
為此,我們構建了高效的調度系統:
Batch 排隊機制優化:在 DP 間實現請求的零排隊,將等待時間降至最低。
Token 級精確控制:在 DP 內對請求的輸入進行 token 級細粒度切分,確保同一 batch 內的雙流任務的負載均勻。
通過這一系列技術,我們實現了整個推理系統無排隊、無空等的狀態,顯著提升了整體吞吐。

其次,是專家負載均衡(EPLB),這是 MoE 模型在 EP 并行下特有的挑戰。在每一輪 Batch 處理中,不同專家被激活的 Token 數量是不均衡的。如果某個 GPU 上處理的 Token 數遠超平均值,其執行時間,尤其是 AlltoAll 通信時間將成為整個系統的瓶頸,嚴重影響推理效率。
百舸 5.0 采用了更高效的專家負載均衡策略:
在靜態專家冗余策略上,我們使用了更具有統計學意義的百分位權重作為參考。
在動態負載路由策略上,系統在每一輪計算中,都會統計全局的專家激活情況。基于實時數據,動態選擇路由目標,實現 GPU 層面的負載均衡。
這從根本上解決了 MoE 模型的內生不均衡問題,保障了推理效率。

最后,是分布式 KV Cache。隨著 Agent 應用的普及,大量請求包含重復的System Prompt,這為「用存儲換計算」提供了巨大空間。緩存歷史計算的 KV 狀態,可避免重復計算,直接復用結果。
在構建 KV Cache 中最要的問題是要解決 HBM 容量有限的問題。為此,我們構建了三級緩存的分布式 KV Cache 體系,突破存儲容量限制:HBM -> 內存 -> SSD。該體系極大地擴展了緩存容量,支持更長的上下文和更高的復用率。
為解決慢速介質(如 SSD)的延遲問題,我們采用了實時全局索引,系統能全局感知和預測 Cache 需求,提前在后臺進行填充,從而大幅提升了緩存命中率。

總結來說,對于一個 PD 分離推理系統而言,它是一項系統性的工程。我們為了算子的計算效率推動了更極致的分離,在引擎層面實施自適應的并行策略,在系統層面實現 DP 和 EP 的負載均衡,在 KV Cache 層面最大化用存儲換計算的效益。
通過這一整套組合拳,我們讓整體的推理系統吞吐,在之前的版本基礎上,再次提升了 50% 以上,同時將首 Token 延遲控制在 0.5 秒。
我們相信,目前這套推理系統是業內領先的、已大規模生產級應用的系統,歡迎大家進行更深入的交流。

AI 計算的極致性能,需「芯片 + 系統」深度協同。
過去,國產芯片多用于推理,訓練則面臨擴展性、穩定性、精度三大挑戰。百度通過 3 萬卡昆侖芯集群持續打磨,成功實現了在萬卡級別上穩定、高效地訓練主流大語言模型、多模態模型和文生視頻模型,并保證了與主流芯片對齊的精度。這使得昆侖芯真正成為能訓練先進模型的先進國產芯。
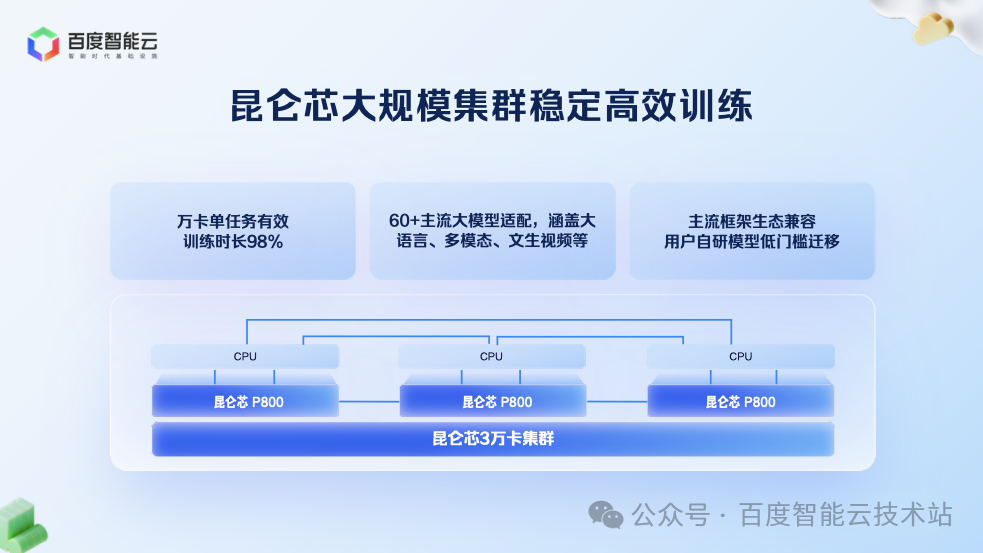
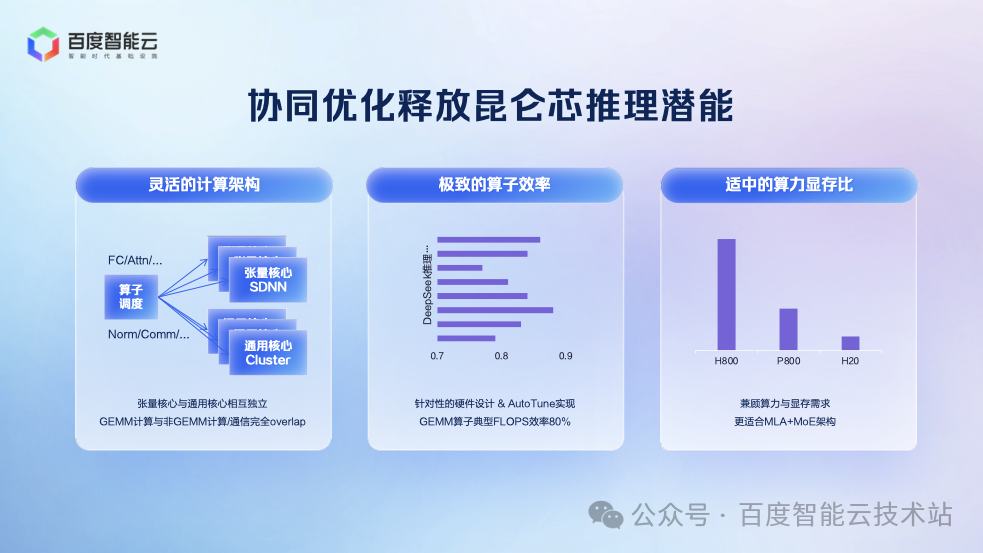
在推理服務上,我們充分利用昆侖芯 P800 的架構特點釋放性能優勢:
其張量核心與通用核心完全獨立,可實現計算與通信的充分并行,特別適合 MoE 架構。
其 Tensor Core 密度更高,使 GEMM、Attention 等核心算子效率均超過 80%,昆侖芯成為最適合 MoE 推理的芯片之一。
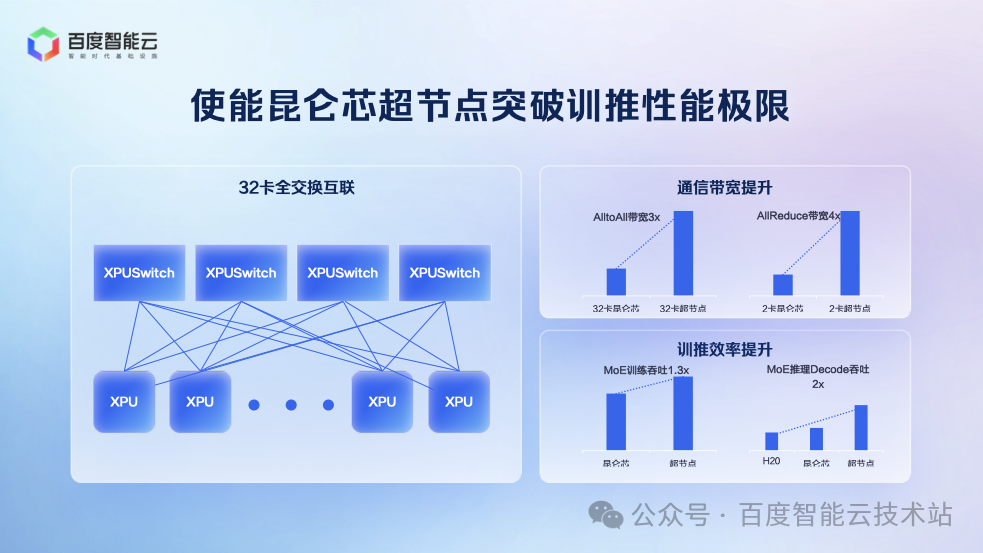
為了滿足 MoE 模型的訓推需求,百度推出 32 卡昆侖芯超節點,通過全互聯架構提升通信效率,兼顧易用性、成本、性能:
易用性:32 卡可部署于標準機柜,背板連接,無需機房改造。
成本:相較于傳統 8 卡服務器,成本增加比例極小。
性能:32 卡規模足以支持當前所有主流 MoE 模型的訓推需求,且通信效率大幅提升。
經測試,超節點的性能表現如下:
訓練性能:MoE 訓練吞吐提升 30%,單卡吞吐提升近一倍。
推理性能:推理吞吐提升一倍。
百度百舸平臺的這些新能力,已被各個行業客戶廣泛應用生產業務中。以某教育客戶為例,該客戶有大量多模態模型需求,如拍照解題、作業批改等,這意味著需要進行海量的 SFT(監督微調)任務,同時也承載著大量的在線推理任務。
百度百舸 5.0 通過硬件適配、資源混部、性能加速等,解決多模態訓推的核心痛點:
高效的推理能力:將之前運行在主流 GPU 的業務平滑降低至昆侖芯 P800,顯著降低了推理成本。
高效的資源利用率:通過百舸的彈性隊列和任務調度能力,實現了訓練任務與推理任務在同一集群內的高效混部,避免了資源閑置,大幅提升了整體資源利用率。
無縫的加速體驗:客戶可以無縫使用百舸提供的各項訓練和推理加速組件,無需復雜改造,即可享受性能紅利。
這一整套方案,不僅幫助客戶大幅降低了資源成本,更重要的是,顯著提升了其模型的訓練迭代速度,使其能夠更快地響應市場變化。

百度百舸 5.0 以 MoE 模型為核心,重構 AI 計算的基礎設施 —— 從訓練場景的 FP8 量化、分布式并行策略,到推理場景的分離式架構、負載均衡調度,再到硬件端的昆侖芯協同,每一步優化都緊扣混合負載的實際需求。
今天的分享到這里,謝謝大家!






:StandardScaler)




)

)


)
、CommonJS(CJS)和UMD三種格式)
)
:高級實現——平衡源項、邊界條件與算法總成)