??在這一節里,我們將詳細介紹 PyTorch 到 ONNX 的轉換函數—— torch.onnx.export。我們希望大家能夠更加靈活地使用這個模型轉換接口,并通過了解它的實現原理來更好地應對該函數的報錯(由于模型部署的兼容性問題,部署復雜模型時該函數時常會報錯)。
1.計算圖導出方法
??TorchScript 是一種序列化和優化 PyTorch 模型的格式,在優化過程中,一個torch.nn.Module模型會被轉換成 TorchScript 的 torch.jit.ScriptModule模型。現在, TorchScript 也被常當成一種中間表示使用。我們在其他文章中對 TorchScript 有詳細的介紹(TorchScript 解讀(一):初識 TorchScript - 知乎),這里介紹 TorchScript 僅用于說明 PyTorch 模型轉 ONNX的原理。
torch.onnx.export中需要的模型實際上是一個torch.jit.ScriptModule。而要把普通 PyTorch 模型轉一個這樣的 TorchScript 模型,有跟蹤(trace)和記錄(script)兩種導出計算圖的方法。如果給torch.onnx.export傳入了一個普通 PyTorch 模型(torch.nn.Module),那么這個模型會默認使用跟蹤的方法導出。這一過程如下圖所示:

回憶一下我們第一篇教程知識:跟蹤法只能通過實際運行一遍模型的方法導出模型的靜態圖,即無法識別出模型中的控制流(如循環);記錄法則能通過解析模型來正確記錄所有的控制流。我們以下面這段代碼為例來看一看這兩種轉換方法的區別:
import torch class Model(torch.nn.Module): def __init__(self, n): super().__init__() self.n = n self.conv = torch.nn.Conv2d(3, 3, 3) def forward(self, x): for i in range(self.n): x = self.conv(x) return x models = [Model(2), Model(3)]
model_names = ['model_2', 'model_3'] for model, model_name in zip(models, model_names): dummy_input = torch.rand(1, 3, 10, 10) dummy_output = model(dummy_input) model_trace = torch.jit.trace(model, dummy_input) model_script = torch.jit.script(model) # 跟蹤法與直接 torch.onnx.export(model, ...)等價 torch.onnx.export(model_trace, dummy_input, f'{model_name}_trace.onnx', example_outputs=dummy_output) # 記錄法必須先調用 torch.jit.sciprt torch.onnx.export(model_script, dummy_input, f'{model_name}_script.onnx', example_outputs=dummy_output)
??在這段代碼里,我們定義了一個帶循環的模型,模型通過參數n來控制輸入張量被卷積的次數。之后,我們各創建了一個n=2和n=3的模型。我們把這兩個模型分別用跟蹤和記錄的方法進行導出。
值得一提的是,由于這里的兩個模型(model_trace, model_script)是 TorchScript 模型,export函數已經不需要再運行一遍模型了。(如果模型是用跟蹤法得到的,那么在執行torch.jit.trace的時候就運行過一遍了;而用記錄法導出時,模型不需要實際運行)參數中的dummy_input和dummy_output`僅僅是為了獲取輸入和輸出張量的類型和形狀。
運行上面的代碼,我們把得到的 4 個 onnx 文件用 Netron 可視化:
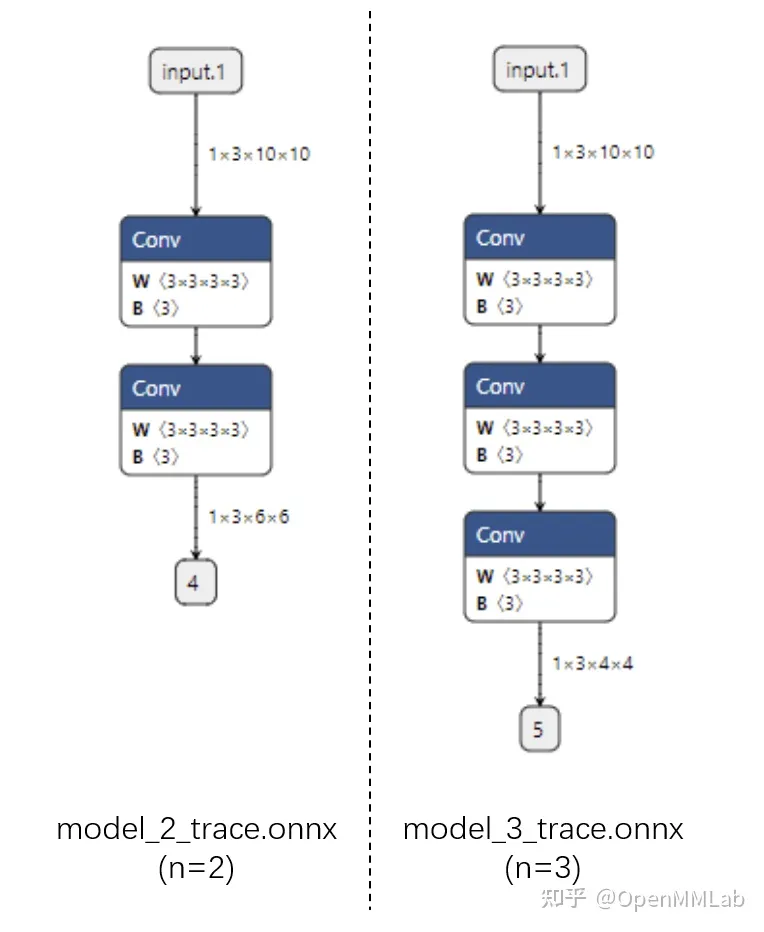
首先看跟蹤法得到的 ONNX 模型結構。可以看出來,對于不同的 n,ONNX 模型的結構是不一樣的。
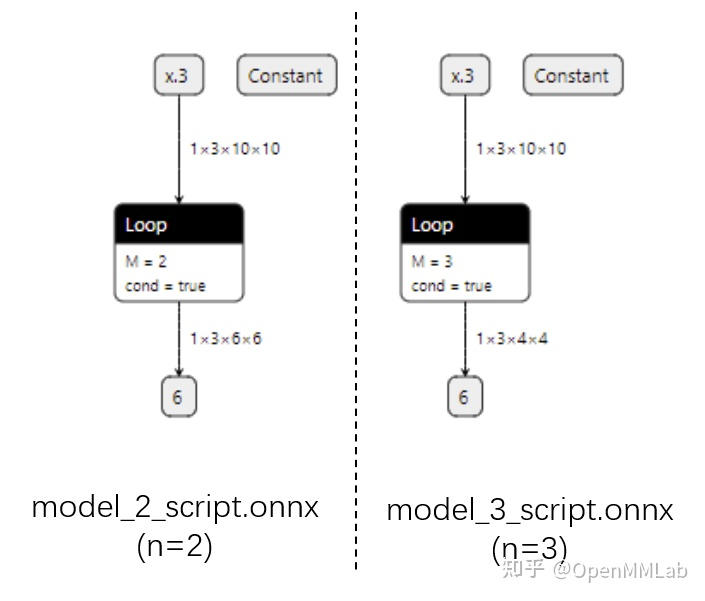
而用記錄法的話,最終的 ONNX 模型用 Loop 節點來表示循環。這樣哪怕對于不同的 n,ONNX 模型也有同樣的結構。
由于推理引擎對靜態圖的支持更好,通常我們在模型部署時不需要顯式地把 PyTorch 模型轉成 TorchScript 模型,直接把 PyTorch 模型用 torch.onnx.export 跟蹤導出即可。了解這部分的知識主要是為了在模型轉換報錯時能夠更好地定位問題是否發生在 PyTorch 轉 TorchScript 階段。
2.參數講解
??了解完轉換函數的原理后,我們來詳細介紹一下該函數的主要參數的作用。我們主要會從應用的角度來介紹每個參數在不同的模型部署場景中應該如何設置,而不會去列出每個參數的所有設置方法。該函數詳細的 API 文檔可參考:
torch.onnx.export 在 torch.onnx.init.py文件中的定義如下:
def export(model, args, f, export_params=True, verbose=False, training=TrainingMode.EVAL, input_names=None, output_names=None, aten=False, export_raw_ir=False, operator_export_type=None, opset_version=None, _retain_param_name=True, do_constant_folding=True, example_outputs=None, strip_doc_string=True, dynamic_axes=None, keep_initializers_as_inputs=None, custom_opsets=None, enable_onnx_checker=True, use_external_data_format=False):
??前三個必選參數為模型、模型輸入、導出的 onnx 文件名,我們對這幾個參數已經很熟悉了。我們來著重看一下后面的一些常用可選參數。
- export_params
模型中是否存儲模型權重。一般中間表示包含兩大類信息:模型結構和模型權重,這兩類信息可以在同一個文件里存儲,也可以分文件存儲。ONNX 是用同一個文件表示記錄模型的結構和權重的。
我們部署時一般都默認這個參數為 True。如果 onnx 文件是用來在不同框架間傳遞模型(比如 PyTorch 到 Tensorflow)而不是用于部署,則可以令這個參數為 False。 - input_names, output_names
設置輸入和輸出張量的名稱。如果不設置的話,會自動分配一些簡單的名字(如數字)。
ONNX 模型的每個輸入和輸出張量都有一個名字。很多推理引擎在運行 ONNX 文件時,都需要以“名稱-張量值”的數據對來輸入數據,并根據輸出張量的名稱來獲取輸出數據。在進行跟張量有關的設置(比如添加動態維度)時,也需要知道張量的名字。
在實際的部署流水線中,我們都需要設置輸入和輸出張量的名稱,并保證 ONNX 和推理引擎中使用同一套名稱。 - opset_version
轉換時參考哪個 ONNX 算子集版本,默認為 9。后文會詳細介紹 PyTorch 與 ONNX 的算子對應關系。 - dynamic_axes
指定輸入輸出張量的哪些維度是動態的。
為了追求效率,ONNX 默認所有參與運算的張量都是靜態的(張量的形狀不發生改變)。但在實際應用中,我們又希望模型的輸入張量是動態的,尤其是本來就沒有形狀限制的全卷積模型。因此,我們需要顯式地指明輸入輸出張量的哪幾個維度的大小是可變的。
我們來看一個dynamic_axes的設置例子:
import torch class Model(torch.nn.Module): def __init__(self): super().__init__() self.conv = torch.nn.Conv2d(3, 3, 3) def forward(self, x): x = self.conv(x) return x model = Model()
dummy_input = torch.rand(1, 3, 10, 10)
model_names = ['model_static.onnx',
'model_dynamic_0.onnx',
'model_dynamic_23.onnx'] dynamic_axes_0 = { 'in' : [0], 'out' : [0]
}
dynamic_axes_23 = { 'in' : [2, 3], 'out' : [2, 3]
} torch.onnx.export(model, dummy_input, model_names[0],
input_names=['in'], output_names=['out'])
torch.onnx.export(model, dummy_input, model_names[1],
input_names=['in'], output_names=['out'], dynamic_axes=dynamic_axes_0)
torch.onnx.export(model, dummy_input, model_names[2],
input_names=['in'], output_names=['out'], dynamic_axes=dynamic_axes_23)
??首先,我們導出 3 個 ONNX 模型,分別為沒有動態維度、第 0 維動態、第 2 第 3 維動態的模型。
在這份代碼里,我們是用列表的方式表示動態維度,例如:
dynamic_axes_0 = { 'in' : [0], 'out' : [0]
}
??由于在這份代碼里我們沒有更多的對動態維度的操作,因此簡單地用列表指定動態維度即可。
之后,我們用下面的代碼來看一看動態維度的作用:
import onnxruntime
import numpy as np origin_tensor = np.random.rand(1, 3, 10, 10).astype(np.float32)
mult_batch_tensor = np.random.rand(2, 3, 10, 10).astype(np.float32)
big_tensor = np.random.rand(1, 3, 20, 20).astype(np.float32) inputs = [origin_tensor, mult_batch_tensor, big_tensor]
exceptions = dict() for model_name in model_names: for i, input in enumerate(inputs): try: ort_session = onnxruntime.InferenceSession(model_name) ort_inputs = {'in': input} ort_session.run(['out'], ort_inputs) except Exception as e: exceptions[(i, model_name)] = e print(f'Input[{i}] on model {model_name} error.') else: print(f'Input[{i}] on model {model_name} succeed.')
??我們在模型導出計算圖時用的是一個形狀為(1, 3, 10, 10)的張量。現在,我們來嘗試以形狀分別是(1, 3, 10, 10), (2, 3, 10, 10), (1, 3, 20, 20)為輸入,用ONNX Runtime運行一下這幾個模型,看看哪些情況下會報錯,并保存對應的報錯信息。得到的輸出信息應該如下:
Input[0] on model model_static.onnx succeed.
Input[1] on model model_static.onnx error.
Input[2] on model model_static.onnx error.
Input[0] on model model_dynamic_0.onnx succeed.
Input[1] on model model_dynamic_0.onnx succeed.
Input[2] on model model_dynamic_0.onnx error.
Input[0] on model model_dynamic_23.onnx succeed.
Input[1] on model model_dynamic_23.onnx error.
Input[2] on model model_dynamic_23.onnx succeed.
??可以看出,形狀相同的(1, 3, 10, 10)的輸入在所有模型上都沒有出錯。而對于batch(第 0 維)或者長寬(第 2、3維)不同的輸入,只有在設置了對應的動態維度后才不會出錯。我們可以錯誤信息中找出是哪些維度出了問題。比如我們可以用以下代碼查看input[1]在model_static.onnx中的報錯信息:
print(exceptions[(1, 'model_static.onnx')]) # output
# [ONNXRuntimeError] : 2 : INVALID_ARGUMENT : Got invalid dimensions for input: in for the following indices index: 0 Got: 2 Expected: 1 Please fix either the inputs or the model.
??這段報錯告訴我們名字叫in的輸入的第 0 維不匹配。本來該維的長度應該為 1,但我們的輸入是 2。實際部署中,如果我們碰到了類似的報錯,就可以通過設置動態維度來解決問題。
3.使模型在 ONNX 轉換時有不同的行為
??有些時候,我們希望模型在導出至 ONNX 時有一些不同的行為模型在直接用 PyTorch 推理時有一套邏輯,而在導出的ONNX模型中有另一套邏輯。比如,我們可以把一些后處理的邏輯放在模型里,以簡化除運行模型之外的其他代碼。torch.onnx.is_in_onnx_export()可以實現這一任務,該函數僅在執行 torch.onnx.export()時為真。以下是一個例子:
import torch class Model(torch.nn.Module): def __init__(self): super().__init__() self.conv = torch.nn.Conv2d(3, 3, 3) def forward(self, x): x = self.conv(x) if torch.onnx.is_in_onnx_export(): x = torch.clip(x, 0, 1) return x
??這里,我們僅在模型導出時把輸出張量的數值限制在[0, 1]之間。使用 is_in_onnx_export確實能讓我們方便地在代碼中添加和模型部署相關的邏輯。但是,這些代碼對只關心模型訓練的開發者和用戶來說很不友好,突兀的部署邏輯會降低代碼整體的可讀性。同時,is_in_onnx_export只能在每個需要添加部署邏輯的地方都“打補丁”,難以進行統一的管理。我們之后會介紹如何使用 MMDeploy 的重寫機制來規避這些問題。
4.利用中斷張量跟蹤的操作
??PyTorch 轉 ONNX 的跟蹤導出法是不是萬能的。如果我們在模型中做了一些很“出格”的操作,跟蹤法會把某些取決于輸入的中間結果變成常量,從而使導出的 ONNX 模型和原來的模型有出入。以下是一個會造成這種“跟蹤中斷”的例子:
class Model(torch.nn.Module): def __init__(self): super().__init__() def forward(self, x): x = x * x[0].item() return x, torch.Tensor([i for i in x]) model = Model()
dummy_input = torch.rand(10)
torch.onnx.export(model, dummy_input, 'a.onnx')
??如果你嘗試去導出這個模型,會得到一大堆 warning,告訴你轉換出來的模型可能不正確。這也難怪,我們在這個模型里使用了.item()把 torch 中的張量轉換成了普通的 Python 變量,還嘗試遍歷 torch 張量,并用一個列表新建一個 torch 張量。這些涉及張量與普通變量轉換的邏輯都會導致最終的 ONNX 模型不太正確。
另一方面,我們也可以利用這個性質,在保證正確性的前提下令模型的中間結果變成常量。這個技巧常常用于模型的靜態化上,即令模型中所有的張量形狀都變成常量。在未來的教程中,我們會在部署實例中詳細介紹這些“高級”操作。
5.PyTorch 對 ONNX 的算子支持
??在確保torch.onnx.export()的調用方法無誤后,PyTorch 轉 ONNX 時最容易出現的問題就是算子不兼容了。這里我們會介紹如何判斷某個 PyTorch 算子在 ONNX 中是否兼容,以助大家在碰到報錯時能更好地把錯誤歸類。而具體添加算子的方法我們會在之后的文章里介紹。
在轉換普通的torch.nn.Module模型時,PyTorch 一方面會用跟蹤法執行前向推理,把遇到的算子整合成計算圖;另一方面,PyTorch 還會把遇到的每個算子翻譯成 ONNX 中定義的算子。在這個翻譯過程中,可能會碰到以下情況:
該算子可以一對一地翻譯成一個 ONNX 算子。
該算子在 ONNX 中沒有直接對應的算子,會翻譯成一至多個 ONNX 算子。
該算子沒有定義翻譯成 ONNX 的規則,報錯。
那么,該如何查看 PyTorch 算子與 ONNX 算子的對應情況呢?由于PyTorch 算子是向 ONNX 對齊的,這里我們先看一下 ONNX 算子的定義情況,再看一下PyTorch 定義的算子映射關系。
6.ONNX 算子文檔
??ONNX 算子的定義情況,都可以在官方的算子文檔中查看。這份文檔十分重要,我們碰到任何和 ONNX 算子有關的問題都得來”請教“這份文檔。
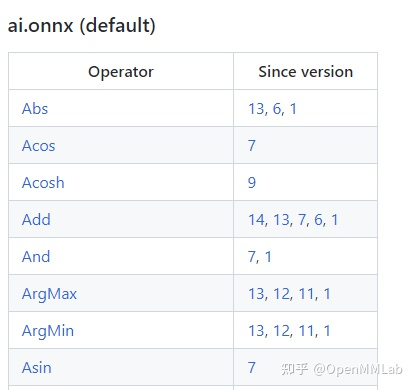
這份文檔中最重要的開頭的這個算子變更表格。表格的第一列是算子名,第二列是該算子發生變動的算子集版本號,也就是我們之前在torch.onnx.export中提到的opset_version表示的算子集版本號。通過查看算子第一次發生變動的版本號,我們可以知道某個算子是從哪個版本開始支持的;通過查看某算子小于等于opset_version的第一個改動記錄,我們可以知道當前算子集版本中該算子的定義規則。
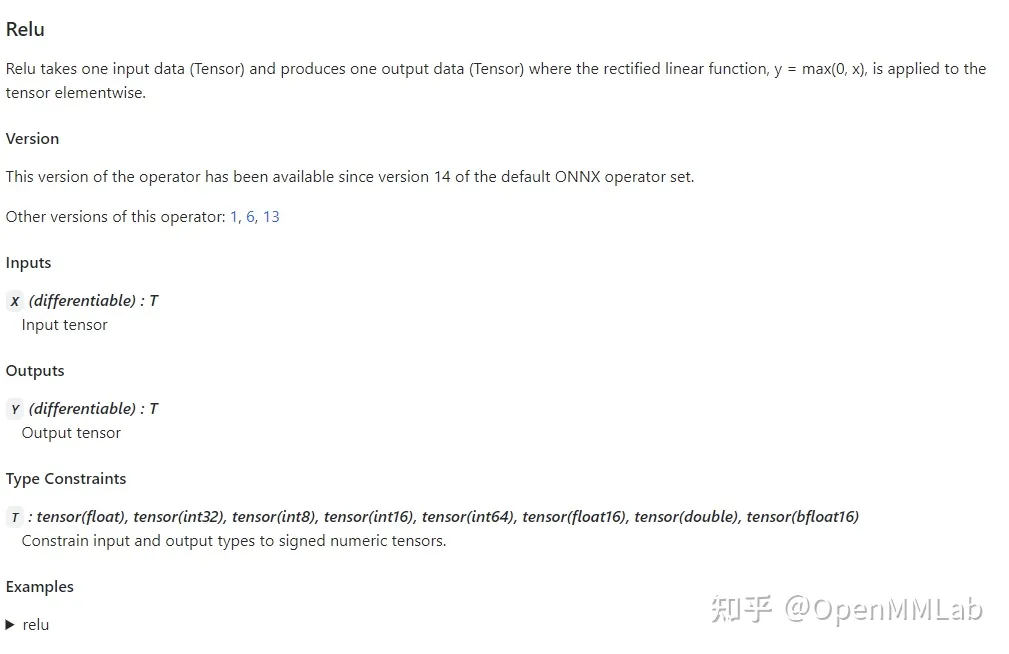
通過點擊表格中的鏈接,我們可以查看某個算子的輸入、輸出參數規定及使用示例。比如上圖是 Relu 在 ONNX 中的定義規則,這份定義表明 Relu 應該有一個輸入和一個輸入,輸入輸出的類型相同,均為 tensor。
7.PyTorch 對 ONNX 算子的映射
??在 PyTorch 中,和 ONNX 有關的定義全部放在 torch.onnx目錄中,如下圖所示:
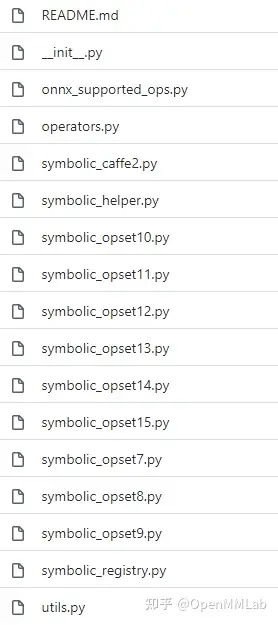
其中,symbolic_opset{n}.py(符號表文件)即表示 PyTorch 在支持第 n 版 ONNX 算子集時新加入的內容。我們之前講過, bicubic 插值是在第 11 個版本開始支持的。我們以它為例來看看如何查找算子的映射情況。
首先,使用搜索功能,在torch/onnx文件夾搜索"bicubic",可以發現這個這個插值在第 11 個版本的定義文件中:
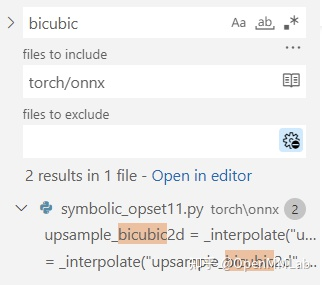
之后,我們按照代碼的調用邏輯,逐步跳轉直到最底層的 ONNX 映射函數:
upsample_bicubic2d = _interpolate("upsample_bicubic2d", 4, "cubic") -> def _interpolate(name, dim, interpolate_mode): return sym_help._interpolate_helper(name, dim, interpolate_mode) -> def _interpolate_helper(name, dim, interpolate_mode): def symbolic_fn(g, input, output_size, *args): ... return symbolic_fn
??最后,在symbolic_fn中,我們可以看到插值算子是怎么樣被映射成多個 ONNX 算子的。其中,每一個g.op就是一個 ONNX 的定義。比如其中的 Resize 算子就是這樣寫的:
return g.op("Resize", input, empty_roi, empty_scales, output_size, coordinate_transformation_mode_s=coordinate_transformation_mode, cubic_coeff_a_f=-0.75, # only valid when mode="cubic" mode_s=interpolate_mode, # nearest, linear, or cubic nearest_mode_s="floor") # only valid when mode="nearest"
??通過在前面提到的ONNX 算子文檔中查找 Resize 算子的定義,我們就可以知道這每一個參數的含義了。用類似的方法,我們可以去查詢其他 ONNX 算子的參數含義,進而知道 PyTorch 中的參數是怎樣一步一步傳入到每個 ONNX 算子中的。
掌握了如何查詢 PyTorch 映射到 ONNX 的關系后,我們在實際應用時就可以在 torch.onnx.export()的opset_version中先預設一個版本號,碰到了問題就去對應的 PyTorch 符號表文件里去查。如果某算子確實不存在,或者算子的映射關系不滿足我們的要求,我們就可能得用其他的算子繞過去,或者自定義算子了。

















C++入門基礎1)
:封裝的層次(Python)——不同的邏輯“一樣”的預期)
