C++是在C的基礎之上,容納進去了面向對象編程思想,并增加了許多有用的庫,以及編程范式 等。熟悉C語言之后,對C++學習有一定的幫助。
本章節主要目標:
- 補充C語言語法的不足,以及C++是如何對C語言設計不合理的地方進行優化的。
比如:作用域方面、IO方面、函數方面、指針方面、宏方面等。 - 為后續類和對象學習打基礎。
C++初階課程的核心就是類和對象,然后使用類和對象+模版,實現基礎的一些數據結構。
在學類和對象之前,需要先學C++入門,C++的祖師爺覺得C語言很多地方設計得不好,于是開發了許多C++的小語法,去改進C語言的不足。
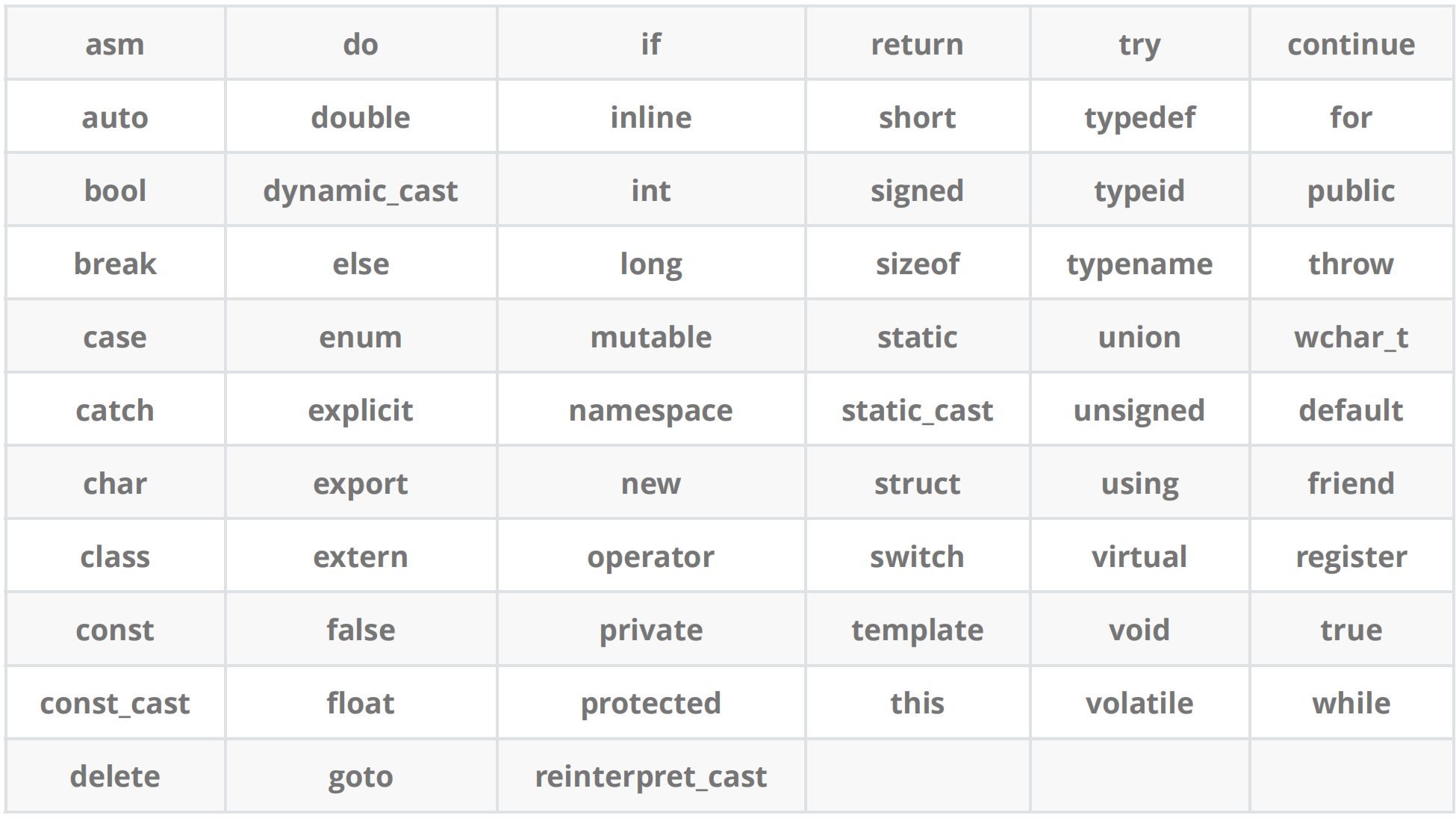
0. C++關鍵字(C98)
C++總計?63?個關鍵字,C語言32個關鍵字。
ps:下面我們只是粗略看一下C++有哪些關鍵字,不對關鍵字進行具體的講解。后面我們學到以后再細講。
1. 命名空間
1.1 namespace的價值
在C/C++中,變量、函數和后面要學到的類都是大量存在的。
這些變量、函數和類的名稱若都存在于全局作用域中的話,則很可能會導致很多沖突。
使用命名空間的目的
- 對標識符的名稱進行本地化,以避免命名沖突或名字污染。
?namespace 關鍵字的出現就是針對這種問題的。
c語言項目類似下面程序這樣的命名沖突是普遍存在的問題,C++引入namespace就是為了更好的解決這樣的問題。(C的缺陷 / 不足)
#include <stdio.h?
#include <stdlib.h> //不包含這個頭文件,則不會報錯
int rand = 10;
int main()
{// 編譯報錯:error C2365: “rand”: 重定義;以前的定義是“函數”printf("%d\n", rand);return 0;
}//頭文件展開,里面的rand()函數和全局的rand變量——>命名沖突即C語言中,變量不能和函數重名。
命名沖突——C的缺陷之一:存在于編碼者與庫、(一個大項目的)編碼者之間。
C語言是解決不了這個問題的,兩個都想叫rand,最終只能有一個在全局域取名為rand。
解決C語言第一個缺陷——命名沖突:同名xx不知道使用哪一個,的第一個C++語法namespace。
7.2 namespace的語法規則
(1)namespace定義
? 定義命名空間,需要使用到namespace關鍵字,后面跟命名空間的名字,然后接一對{ }即可。——和結構體不一樣的是,后面不需要加分號。
{}中即為命名空間的成員,可以把日常定義的變量、函數、類型封裝到命名空間里面。
- 命名空間中可以定義變量/函數/類型等。
命名空間中是各種標識符的定義:變量名、函數名、類型名……
命名空間中的變量、函數、類型不會和全局沖突,只有指定才會找到。
(2)域
? namespace本質是定義出一個域(命名空間域),這個域跟全局域各自獨立,不同的域可以定義同名變量,所以下面的rand不再沖突了。
C++中域有函數局部域、全局域、命名空間域、類域;
#include <stdio.h>
#include <stdlib.h>
// 1. 正常的命名空間定義
// bit是命名空間的名字,?般開發中是用項?名字做命名空間名。
// 示例用的是bit,自己練習可以考慮用自己名字縮寫,如張三:zs
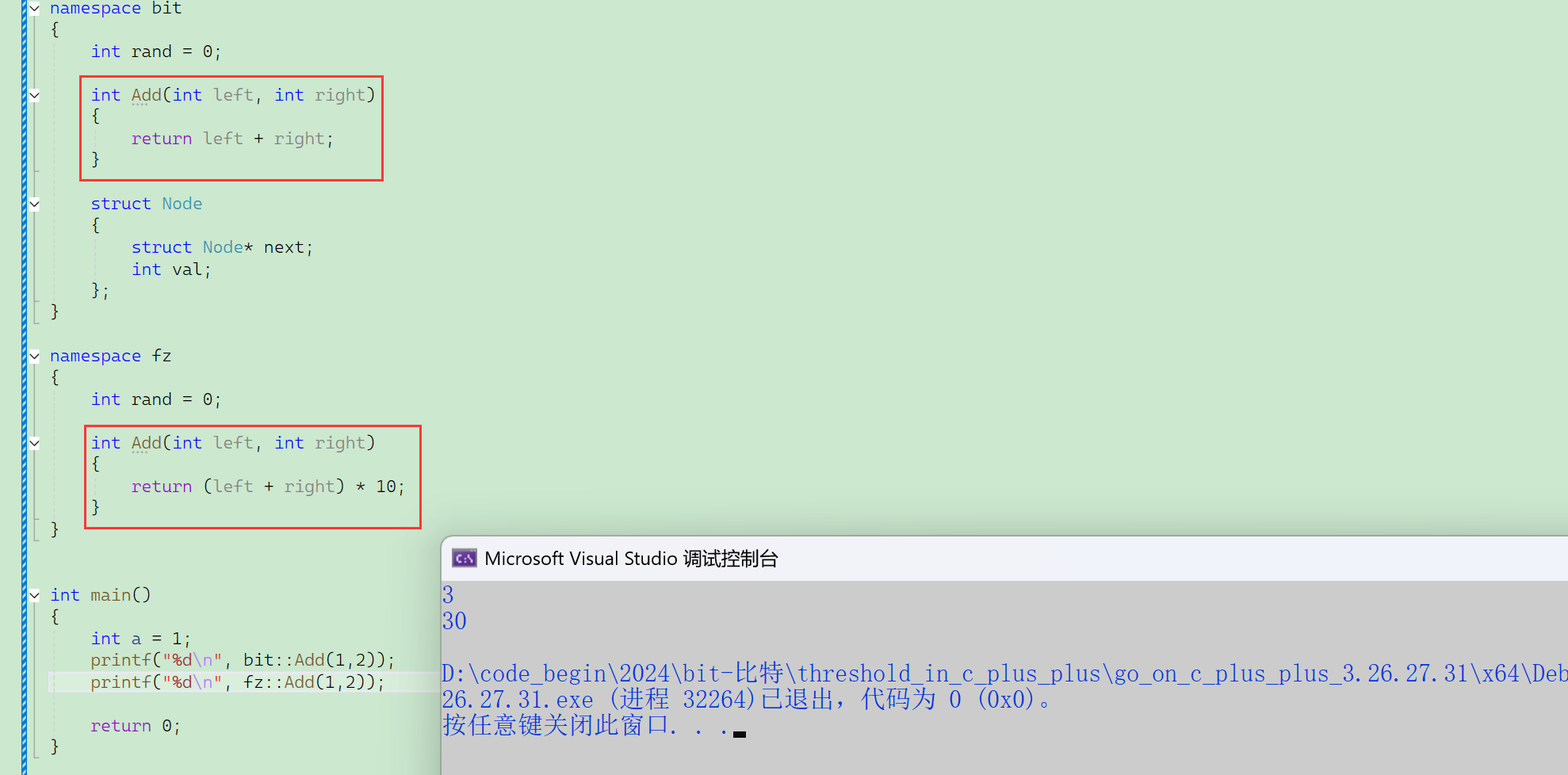
namespace bit
{// 命名空間中可以定義變量/函數/類型int rand = 10;int Add(int left, int right){return left + right;}struct Node{struct Node* next;int val;};
}int main()
{// 這里默認是訪問的是全局的rand函數指針printf("%p\n", rand);// 這里指定bit命名空間中的randprintf("%d\n", bit::rand);return 0;
}代碼編譯時,遇到標識符——變量(名)、函數(名)、類型(名),編譯器需要去找它的出處(定義),找不到會報錯“未聲明的標識符”。
編譯默認查找順序——
- 當前局部域(自留地)
- 全局域找——頭文件包含的東西也在全局域(村子野地)
類比做菜摘蔥,優先去自留地摘,沒有再去村子野地摘。
命名空間相當于在全局域,劃分出一些獨立的域(命名空間域)
——將一些村子野地,劃歸成自家的自留地。
編譯時不會到其他命名空間中去找(隔壁張大爺自留地)。
這樣的話,加了命名空間,同時不包含 <stdlib.h>頭文件,就會報錯:errorC2065:未聲明的標識符。
而指定查找域,則只會去這一個域里面找。
類比做菜摘蔥,指定去張大爺地摘。
(3)域的作用
不同域可以定義同名的變量/函數/類型——域可以做到名字的隔離。
{ }括起來的都是域,全局域可以不用{ }括起來。
? 域影響的是編譯時語法查找一個變量/函數/類型出處(聲明或定義)的邏輯,所以有了域隔離,名字沖突就解決了。
- 局部域和全局域除了會影響編譯查找邏輯,還會影響變量的生命周期。
- 命名空間域和類域不影響變量生命周期。
(命名空間域都是修飾全局的,只是把名字給隔離起來了)
域的作用是影響編譯時的查找規則——先到局部域,再到全局域&展開的命名空間域。
局部優先原則: 默認優先訪問局部變量。

C語言,在局部,訪問同名全局變量的方法。
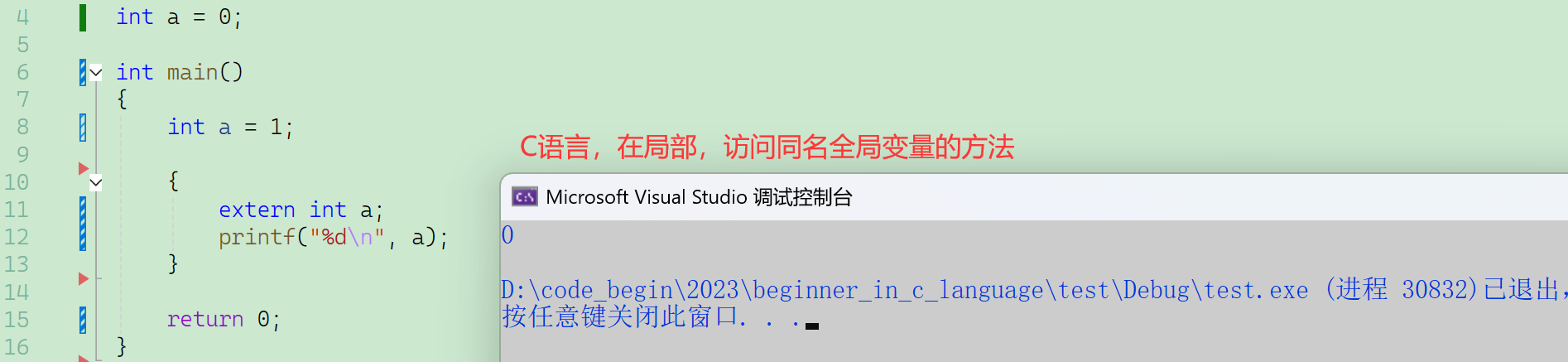
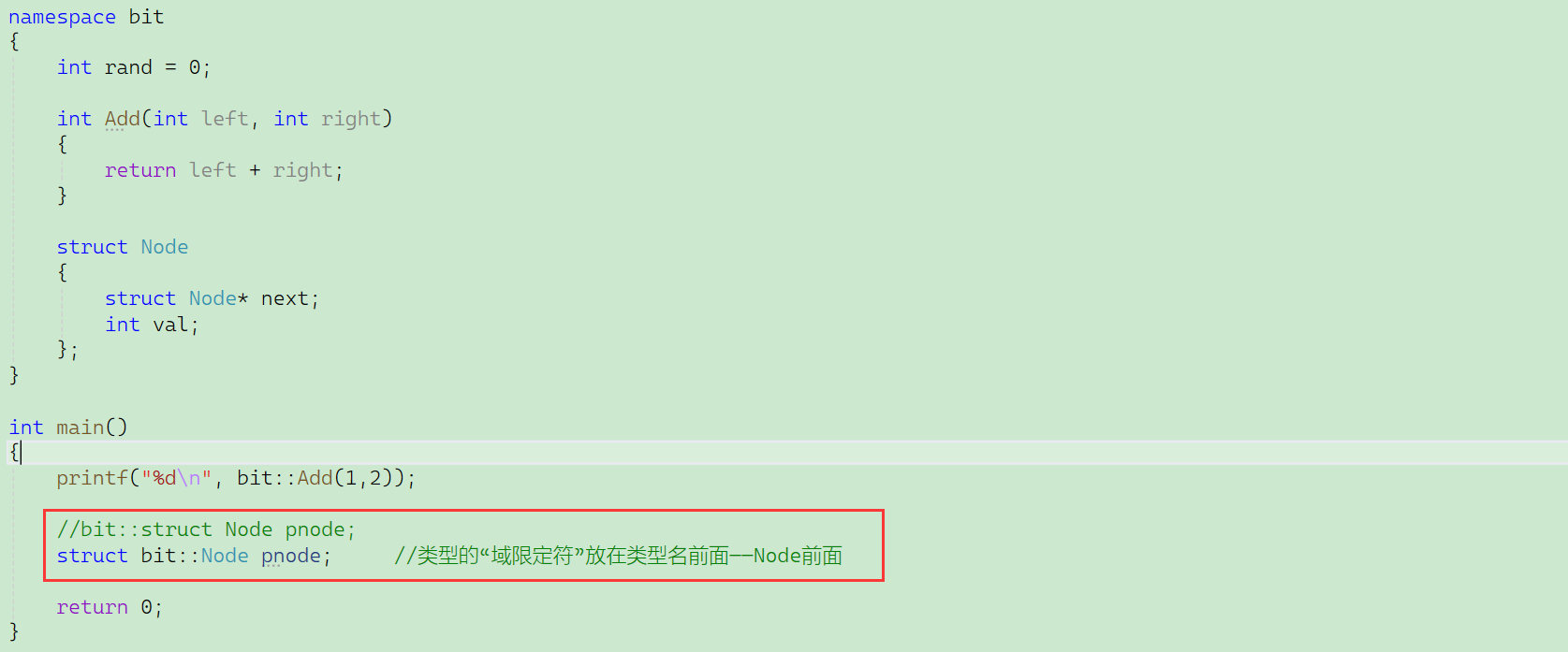
C++,在局部,訪問同名全局變量的方法——作用域限定符(作用域解析運算符)

(4)嵌套定義
? namespace只能定義在全局,當然它還可以嵌套定義。
? 變量rand還是全局變量,只是封裝到了bit命名空間中。
命名空間內部可以定義變量、函數、類型,還可以定義其他的命名空間。
//2. 命名空間可以嵌套
namespace bit
{// 鵬哥namespace pg{int rand = 1;int Add(int left, int right){return left + right;}}// 杭哥namespace hg{int rand = 2;int Add(int left, int right){return (left + right)*10;}}
}int main()
{printf("%d\n", bit::pg::rand);printf("%d\n", bit::hg::rand);printf("%d\n", bit::pg::Add(1, 2));printf("%d\n", bit::hg::Add(1, 2));return 0;
}嵌套的命名空間,在使用的時候也要使用多個域作用限定符來訪問。
(5)多個同名namespace
? 項目工程中多文件中定義的同名namespace會認為是一個namespace,不會沖突。
// 多?件中可以定義同名namespace,他們會默認合并到?起,就像同?個namespace?樣
// Stack.h
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<stdbool.h>
#include<assert.h>namespace bit
{typedef int STDataType;typedef struct Stack{STDataType* a;int top;int capacity;}ST;void STInit(ST* ps, int n);void STDestroy(ST* ps);void STPush(ST* ps, STDataType x);void STPop(ST* ps);STDataType STTop(ST* ps);int STSize(ST* ps);bool STEmpty(ST* ps);
}// Stack.cpp
#include"Stack.h"
namespace bit
{void STInit(ST* ps, int n){assert(ps);ps->a = (STDataType*)malloc(n * sizeof(STDataType));ps->top = 0;ps->capacity = n;}// 棧頂void STPush(ST* ps, STDataType x){assert(ps);// 滿了, 擴容if (ps->top == ps->capacity){printf("擴容\n");int newcapacity = ps->capacity == 0 ? 4 : ps->capacity*2;STDataType* tmp = (STDataType*)realloc(ps->a,newcapacity * sizeof(STDataType));if (tmp == NULL){perror("realloc fail");return;}ps->a = tmp;ps->capacity = newcapacity;}ps->a[ps->top] = x;ps->top++;}//...
}// Queue.h
#pragma once
#include<stdlib.h>
#include<stdbool.h>
#include<assert.h>namespace bit
{typedef int QDataType;typedef struct QueueNode{int val;struct QueueNode* next;}QNode;typedef struct Queue{QNode* phead;QNode* ptail;int size;}Queue;void QueueInit(Queue* pq);void QueueDestroy(Queue* pq);// 入隊列void QueuePush(Queue* pq, QDataType x);// 出隊列void QueuePop(Queue* pq);QDataType QueueFront(Queue* pq);QDataType QueueBack(Queue* pq);bool QueueEmpty(Queue* pq);int QueueSize(Queue* pq);
}// Queue.cpp
#include"Queue.h"
namespace bit
{void QueueInit(Queue* pq){assert(pq);pq->phead = NULL;pq->ptail = NULL;pq->size = 0;}// ...
}// test.cpp
#include"Queue.h"
#include"Stack.h"// 全局定義了一份單獨的Stack
typedef struct Stack
{int a[10];int top;
}ST;void STInit(ST* ps){}
void STPush(ST* ps, int x){}int main()
{// 調用全局的ST st1;STInit(&st1);STPush(&st1, 1);STPush(&st1, 2);printf("%d\n", sizeof(st1));// 調用bit namespace的bit::ST st2;printf("%d\n", sizeof(st2));bit::STInit(&st2);bit::STPush(&st2, 1);bit::STPush(&st2, 2);return 0;
}情景1:假設上述代碼中,棧的隊列的初始化函數,都希望叫作Init(不希望用名字來區分),那么就需要將棧和隊列的代碼,放入不同的命名空間中。
情景2:害怕自己的棧的STInit()和別人的沖突,就不能直接#include "Stack.h",這樣會直接暴露在全局域,需要先在頭文件中,把代碼都放到命名空間中,才能#include "Stack.h"
一個一般的項目有幾十上百個頭文件,定義多少個命名空間?
(不分命名空間的話因為變量、函數、類型……的名字就得拉扯很久理不清)
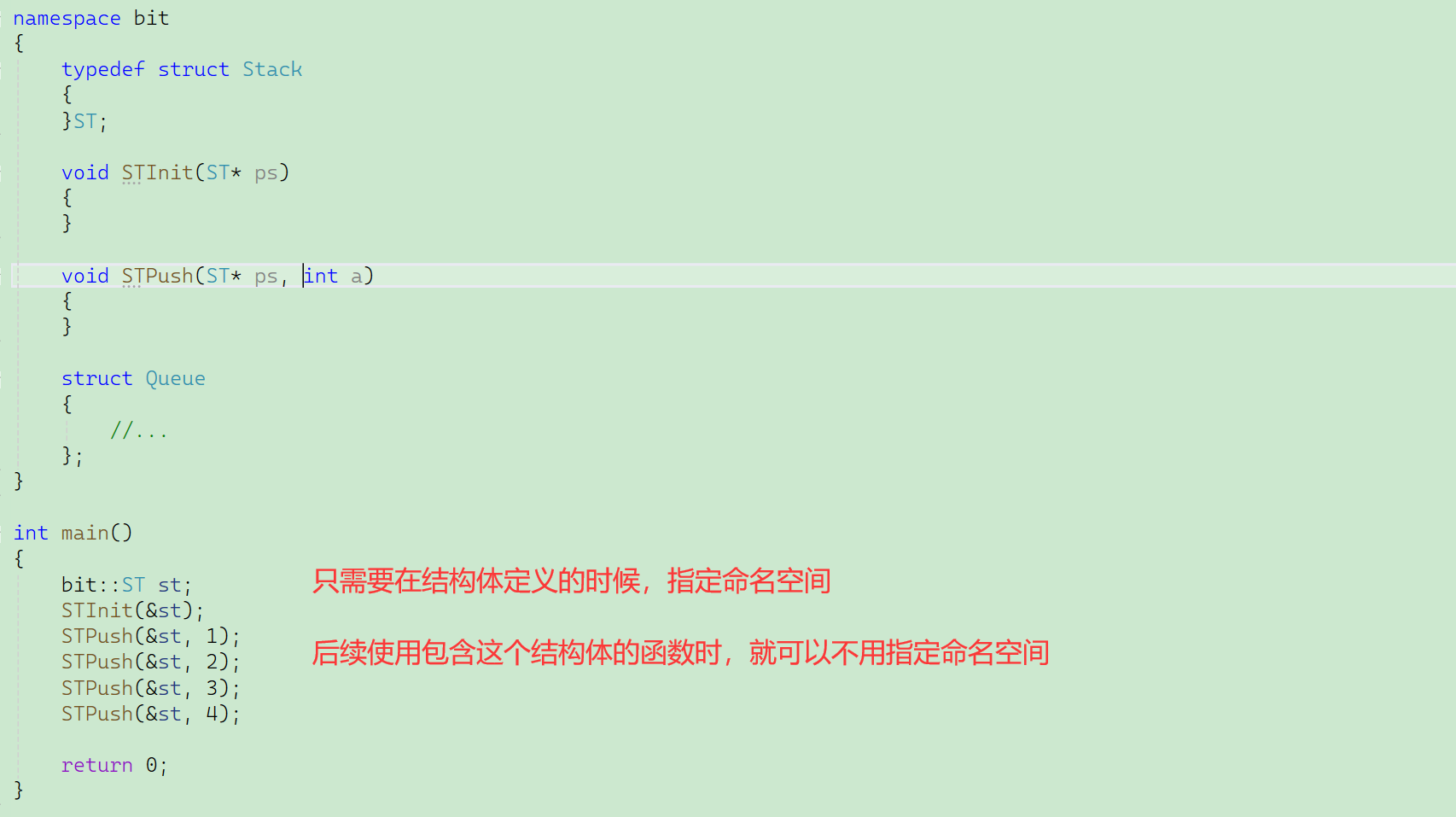
一般分組合作,一個組內幾個頭文件共用一個命名空間。
不同文件可以定義同名的命名空間,同名的命名空間可合并。
合并后(同一個域)有同名會報錯——命名沖突——1改名,2嵌套
而同一個文件也沒必要搞多個命名空間,一個足矣,即都放到一起——因為多個文件都可以共用一個命名空間。
(6)標準庫——標準命名空間
? C++標準庫都放在一個叫 std?(standard的縮寫)的命名空間中。
7.3 命名空間使用(3種方法)
編譯查找一個變量的聲明/定義時,默認只會在局部或者全局查找,不會到命名空間里面去查找。所以下面程序會編譯報錯。
#include<stdio.h>
namespace bit
{int a = 0;int b = 1;
}int main()
{// 編譯報錯:error C2065: “a”: 未聲明的標識符printf("%d\n", a);return 0;
}其他的例證:
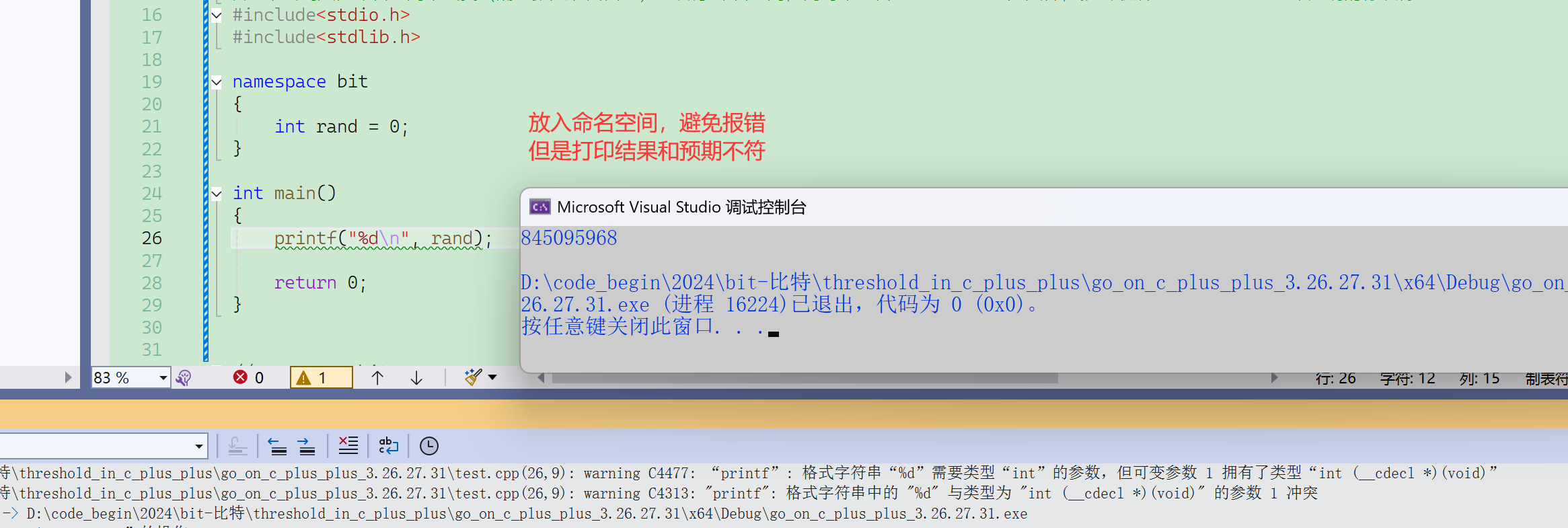
原因:有兩個rand,這里printf里的rand默認取庫里面的rand,即函數rand(),代表一個函數指針,d%改成p%就可以打印出這個函數指針。
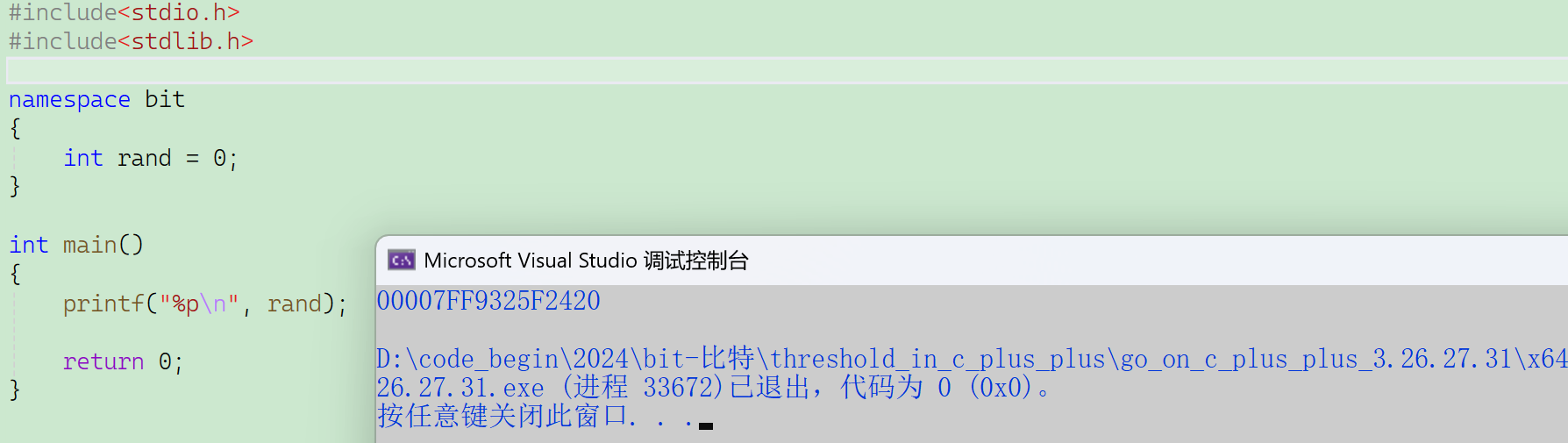
所以我們要使用命名空間中定義的變量/函數,有以下三種方式:
? 指定命名空間訪問,項目中推薦這種方式。
? using將命名空間中某個成員展開,項目中經常訪問的不存在沖突的成員推薦這種方式。
? 展開命名空間中全部成員,項目不推薦,沖突風險很大,日常小練習程序為了方便推薦使用。
(只有一個命名空間,或只有少量命名空間且相互之間不沖突時,可以完全展開)
總結。
- 指定域。
- 展開命名空間。(不指定域也不會報錯,會到展開的命名空間中去查找)
- 展開某個成員。
- 完全展開。
#include<stdio.h>
#include<stdlib.h>namespace bit
{int rand = 0;int x = 0int y = 0
}
// 指定命名空間訪問——最安全
int main()
{printf("%d\n", rand); //默認全局——庫函數rand()printf("%d\n", bit::rand);return 0;
}// using將命名空間中某個成員展開——某個頻繁使用的成員
using bit::x;
int main()
{printf("%d\n", bit::y);printf("%d\n", x);printf("%d\n", x);printf("%d\n", x);printf("%d\n", x);printf("%d\n", x); //x經常使用,y偶爾使用return 0;
}// 展開命名空間中全部成員——最危險
using namespce bit;
int main()
{printf("%d\n", rand);printf("%d\n", x);printf("%d\n", y);return 0;
}展開命名空間后不指定域也不會報錯的前提——和其他展開的命名空間域 or 全局域不沖突。
故雖然麻煩一點,盡量還是別展開。
展開頭文件:把頭文件的內容在預處理階段拷貝過來。
展開命名空間:命名空間是一個域,域的展開是開放訪問權限,域的作用是影響編譯時查找——先到局部域,沒有再到全局域,最后如果有展開的命名空間,就會到展開的命名空間內查找。
編譯默認查找
a、當前局部域?? ??? ??? ??? ?????????: 自留地
b、全局域找?? ??? ??? ??? ? ? ?????????: 村子野地
b、到展開的命名空間中查找 ? : 相當于張大爺在自己的自留地加了聲明,誰需要就來摘
沒加這個聲明時,默認不會到命名空間中去找。
- 注意展開不是放到全局域,展開后仍然是兩個域,只是展開的命名空間域、全局域在查找標識符的出處的時候,具有等價的優先級——局部域之后。
展開的命名空間域、全局域有同名函數不會報錯——不調用就不會報錯。
一旦調用就會產生調用歧義——調用哪個都可以,全局域、命名空間域都能去找。
(不指定的情況下,全局域、展開的命名空間域都會同等優先級地搜索)
但是指定域的方式去調用也不會出錯
::func(); //指定全局域里面去找//或者bit::func() //指定命名空間域里面去找
有了命名空間,就能很好地解決命名沖突的問題。
類型的“域限定符”放在類型名前面——Node前面。(標識符前面)
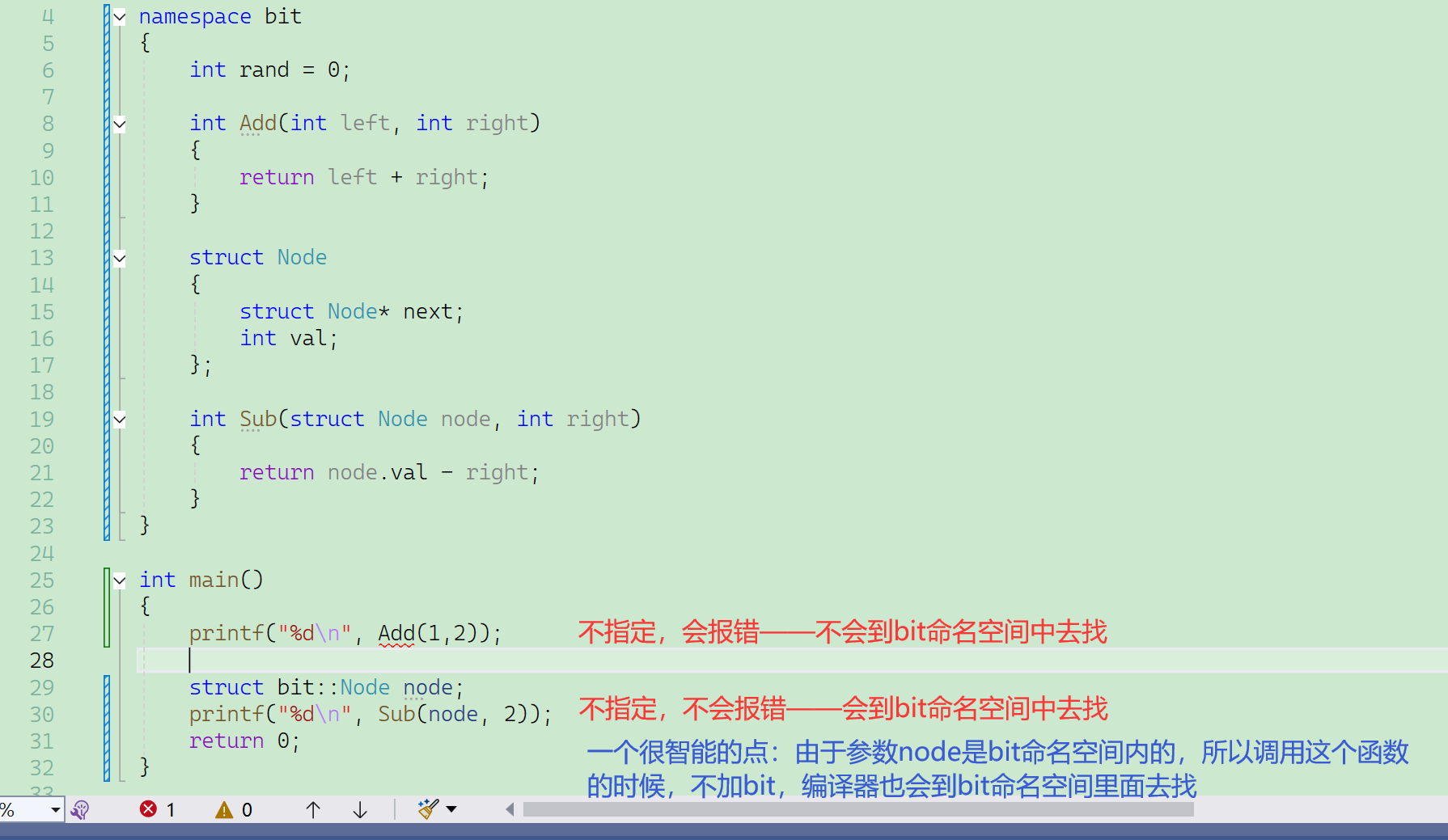
編譯器的一個很智能的點:
應用:
總結——命名空間的價值
命名空間就是把某塊空間圈起來, 圈起來之后影響了查找規則,以此解決了命名沖突。
(沖突的本質:不知道用哪一個)
2. C++輸入&輸出
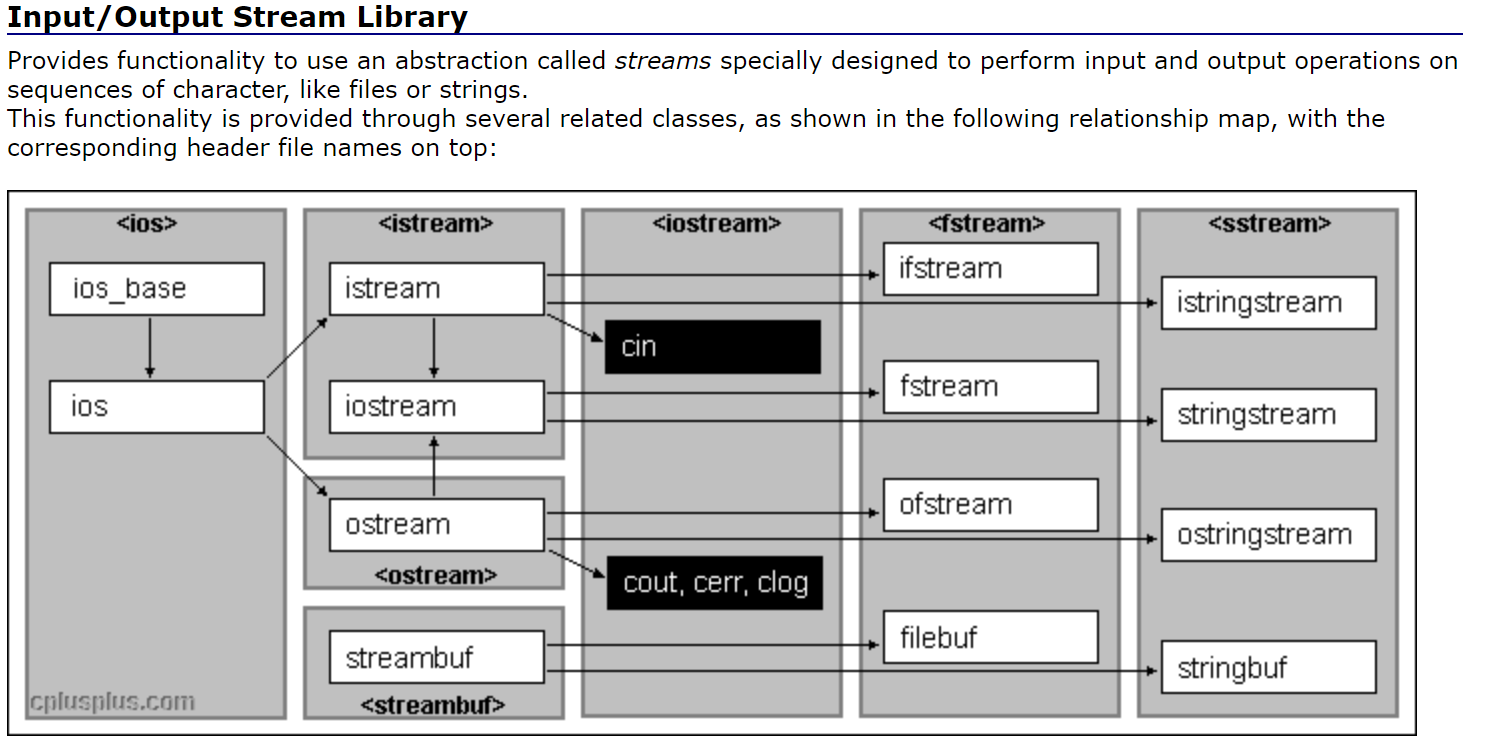
c++搞了一套新的輸入輸出流——IO流 ?/ ?iostream。
新的頭文件“iostream” ? ?—— ? ?相當于是stdio.h的進化版。
也可以繼續包含stdio頭文件使用 printf/scanf,但是c++更喜歡使用cout/cin——因為其在命名空間std內,產生隔離更安全。
這里的cout中的c不是c++的c,而是console(控制臺)的 c。
windows下的控制臺,相當于linux下的終端。
? <iostream> 是 Input Output Stream 的縮寫,是標準的輸入、輸出流庫,定義了標準的輸入、輸
出對象。
為什么頭文件iosream沒有.h——特別老的c++標準帶.h(還沒有命名空間),如老編譯器vc6.0就可以用。
后來出了命名空間,就包到新的不帶.h的頭文件里了。
頭文件.h只是一個標識,現在c++標準庫的頭文件幾乎都不帶.h。
C++對C兼容的時候,對C的頭文件都封裝了一個不帶.h的版本。
不帶.h的版本,就是用命名空間封裝過中的版本。(<stdlib.h> ? ?== ? ?<cstdlib>)
? std::cin 是 istream 類的對象,它主要面向窄字符(narrow characters (of type char))的標準輸
入流。
? std::cout 是 ostream 類的對象,它主要面向窄字符的標準輸出流。
? std::endl 是一個函數,流插入輸出時,相當于插入一個換行字符加刷新緩沖區。
??<< 是流插入運算符, >> 是流提取運算符。
(C語言還用這兩個運算符做位運算左移/右移)
cout和cin是全局的流對象,endl是特殊的C++符號,表示換行輸出。
他們都包含在包含< iostream >頭文件中。
? 使用C++輸入輸出更方便,不需要像printf/scanf輸入輸出時那樣,不需要手動指定格式,C++的輸入輸出可以自動識別變量類型(本質是通過函數重載實現的,這個以后會講到).
- 其實最重要的是 C++的流能更好的支持自定義類型對象的輸入輸出。
? IO流涉及類和對象,運算符重載、繼承等很多面向對象的知識,這些知識我們還沒有講解,所以這里我們只能簡單認識一下C++ IO流的用法,后面我們會有專門的一個章節來細節IO流庫。
? cout/cin/endl 等都屬于C++標準庫,C++標準庫都放在一個叫std(standard)的命名空間中。

編譯器查找的時候,默認先去局部,再去全局,全局域包含了頭文件,頭文件展開后按理來說應該有了,但是C++的標準庫里面做了一件事——為了防止標準庫里面的東西和程序員自己定義的東西沖突了,所以標準庫里面的代碼被封裝進了一個命名空間——std。
直接使用cout,并不會到命名空間std中去查找。
所以要通過命名空間的使用方式去用他們——3種方式。
① 指定命名空間域

② 完全展開
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
using namespace std;
int main()
{int a = 0;double b = 0.1;char c = 'x';cout << a << " " << b << " " << c << endl;std::cout << a << " " << b << " " << c << std::endl;scanf("%d%lf", &a, &b);printf("%d %lf\n", a, b);// 可以自動識別變量的類型cin >> a;cin >> b >> c; //可以連續提取——不需要取地址cout << a << endl;cout << b << " " << c << endl; //可以連續插入cout << b << " " << c << '\n'; //換行有兩種方式://'\n'//endlreturn 0;
}③ 指定展開

cin
- 作用:從console里面把輸入的數據拿出來放到這個對象(C習慣叫變量,c++習慣叫對象)里面。
- 優點:不用指定格式;也不需要取地址。
- cin不常用就不用指定展開。
? 一般日常練習中我們可以using namespace std,實際項目開發中不建議using namespace std。
? 這里我們沒有包含<stdio.h>,也可以使用printf和scanf,在包含<iostream>間接包含了。vs系列 編譯器是這樣的,其他編譯器可能會報錯。
cout、cin優點
- 可以“自動識別類型”(printf需要指定類型:%d、%s......),即可以隨便插入,不用考慮占位符
- 并且可以連續地輸出cout<<i<<j;
- 并且可以在中間自由插入。
- cout<<i<<"abcd"<<j;(插入字符串)
- cout<<i<<" "<<j;(插入空格隔開)
printf、scanf優點
- 更高效(99%的場景都不需要考慮這個)——因為C++要兼容C語言,會有一定的效率的影響
#include<iostream>
using namespace std;
int main()
{// 在io需求?較?的地?,如部分?量輸?的競賽題中,加上以下3?代碼// 可以提?C++IO效率ios_base::sync_with_stdio(false);cin.tie(nullptr);cout.tie(nullptr);return 0;
}? cin、cout也有相關的精度控制函數,默認是有多少輸出多少。
c++.ostream
cout需要控制精度、寬度時非常麻煩,涉及一系列函數——>能兼容printf就用printf。
但是VS下的iostream是包含了printf、scanf,Linux下就不一定了,可能會報錯,就需要多包一個頭文件。
競賽的2個tips
① C++IO效率
#include<iostream>
using namespace std;
int main()
{// 在io需求?較?的地?,如部分?量輸?的競賽題中,加上以下3?代碼// 可以提?C++IO效率ios_base::sync_with_stdio(false);cin.tie(nullptr);cout.tie(nullptr);return 0;
}② 萬能頭文件
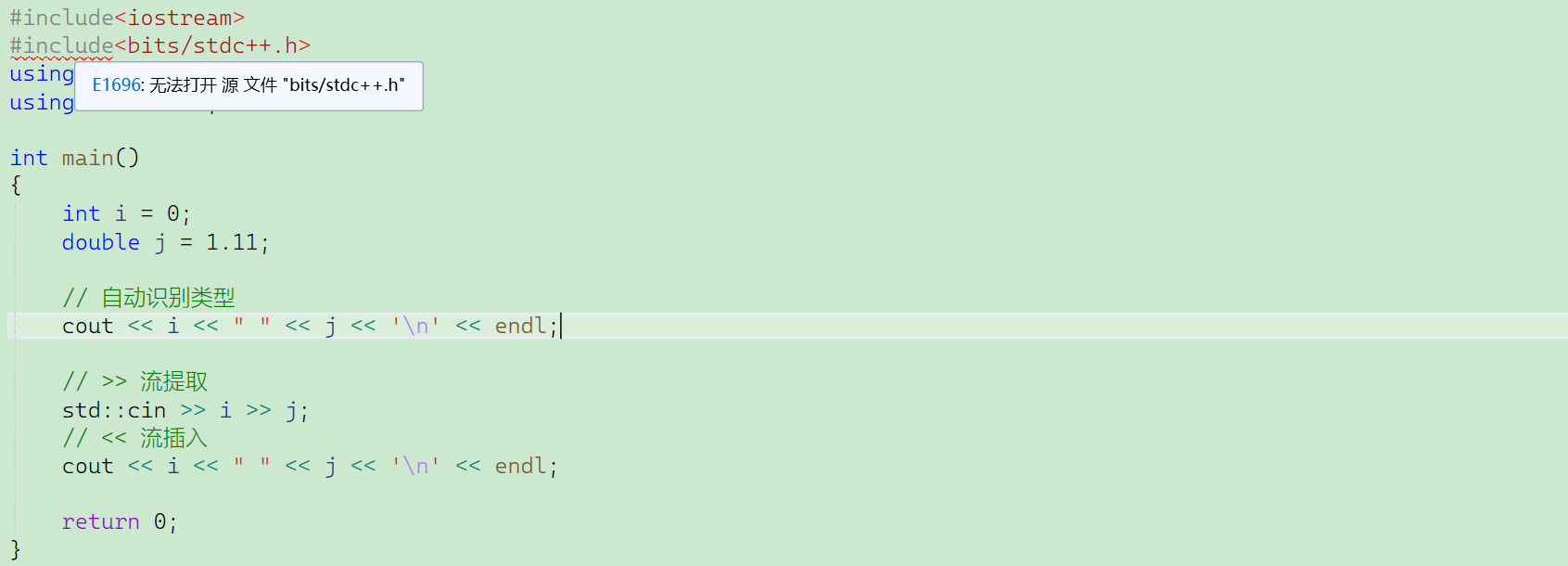
萬能頭文件<bits/stdc++.h>:把c++常見的基本都包進來了——但是VS不支持。
但是一展開就會導致程序變大很多,日常、項目都不建議使用,競賽可用。
展開頭文件有極大的銷耗。
3. 缺省參數
? 缺省參數是聲明或定義函數時為函數的參數指定一個缺省值。在調用該函數時,如果沒有指定實參,則采用該形參的缺省值,否則使用指定的實參。
(有些地方把缺省參數也叫默認參數)
缺省參數分為:全缺省參數、半缺省參數。
? 全缺省就是全部形參給缺省值,半缺省就是部分形參給缺省值。
? C++規定半缺省參數必須從右往左依次連續缺省,不能間隔跳躍給缺省值。
(從左往右缺省帶有歧義)
從右往左給缺省值,函數調用就不存在歧義——調用函數的實參按形參列表從左往右依次給到形參
? 帶缺省參數的函數調用,C++規定必須從左到右依次給實參,不能跳躍給實參。
? 函數聲明和定義分離時,缺省參數不能在函數聲明和定義中同時出現,規定只能由函數聲明給缺省值。——如果聲明與定義位置同時出現,恰巧兩個位置提供的值不同,那編譯器就無法確定到底該用那個缺省值。
? 缺省值必須是常量或者全局變量。
? C語言不支持(編譯器不支持)。
#include <iostream>
#include <assert.h>
using namespace std;void Func(int a = 0)
{ cout << a << endl;
}int main()
{Func(); // 沒有傳參時,使用參數的默認值Func(10); // 傳參時,使用指定的實參return 0;
}缺省參數的優勢:
可以不傳參數,函數調用按默認值運行——可傳,可不傳,提高了程序的靈活度。
#include <iostream>
using namespace std;// 全缺省
void Func1(int a = 10, int b = 20, int c = 30)
{cout << "a = " << a << endl; cout << "b = " << b << endl;cout << "c = " << c << endl << endl;
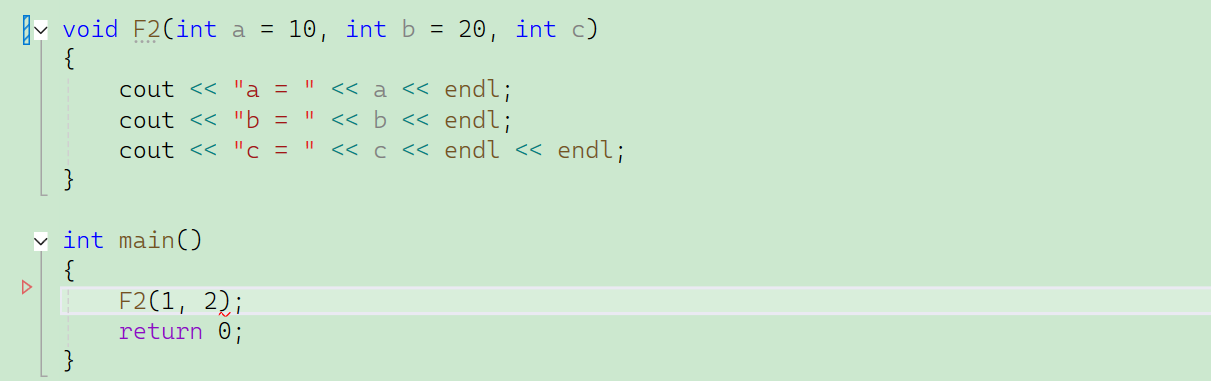
}// 半缺省——從右往左缺省 && 不能間隔著給
void Func2(int a, int b = 10, int c = 20)
{cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl << endl;
}int main()
{//帶缺省參數的函數,函數調用就有多種方式了Func1();Func1(1);Func1(1,2); //規定是按順序傳,傳一個參數就是給a,傳兩個參數就是給a,b——所以不允許間隔著給缺省值 //Func1(1, ,3) //不能跳躍著傳Func1(1,2,3); Func2(100);Func2(100, 200);Func2(100, 200, 300);return 0;
}缺省參數的用途——C的棧的初始化(開0個空間)是實現得不太好的。
在首次插入時開4個空間,后續擴容2倍。
// Stack.h
#include <iostream>
#include <assert.h>
using namespace std;typedef int STDataType;
typedef struct Stack
{STDataType* a;int top;int capacity;
}ST;
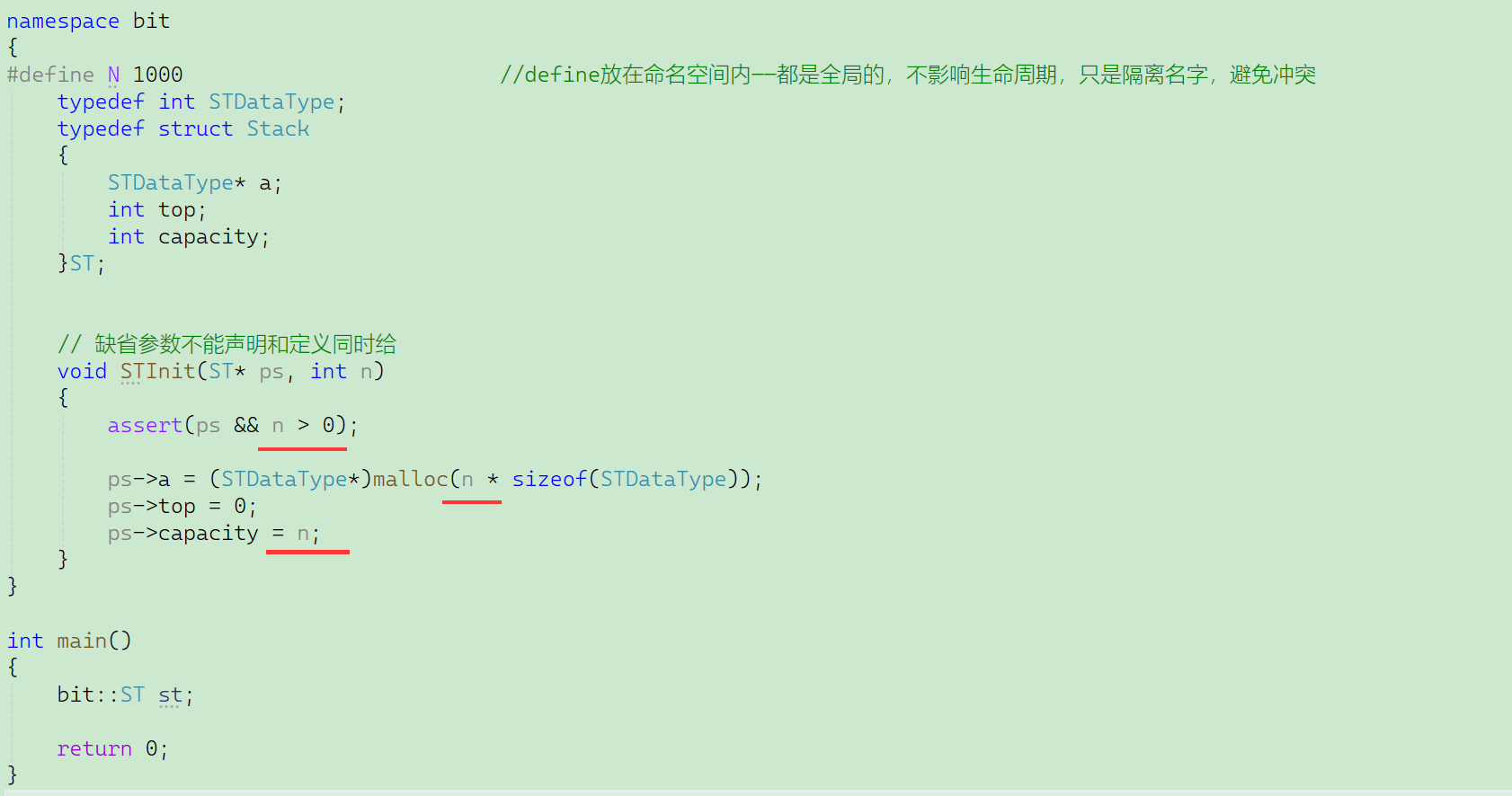
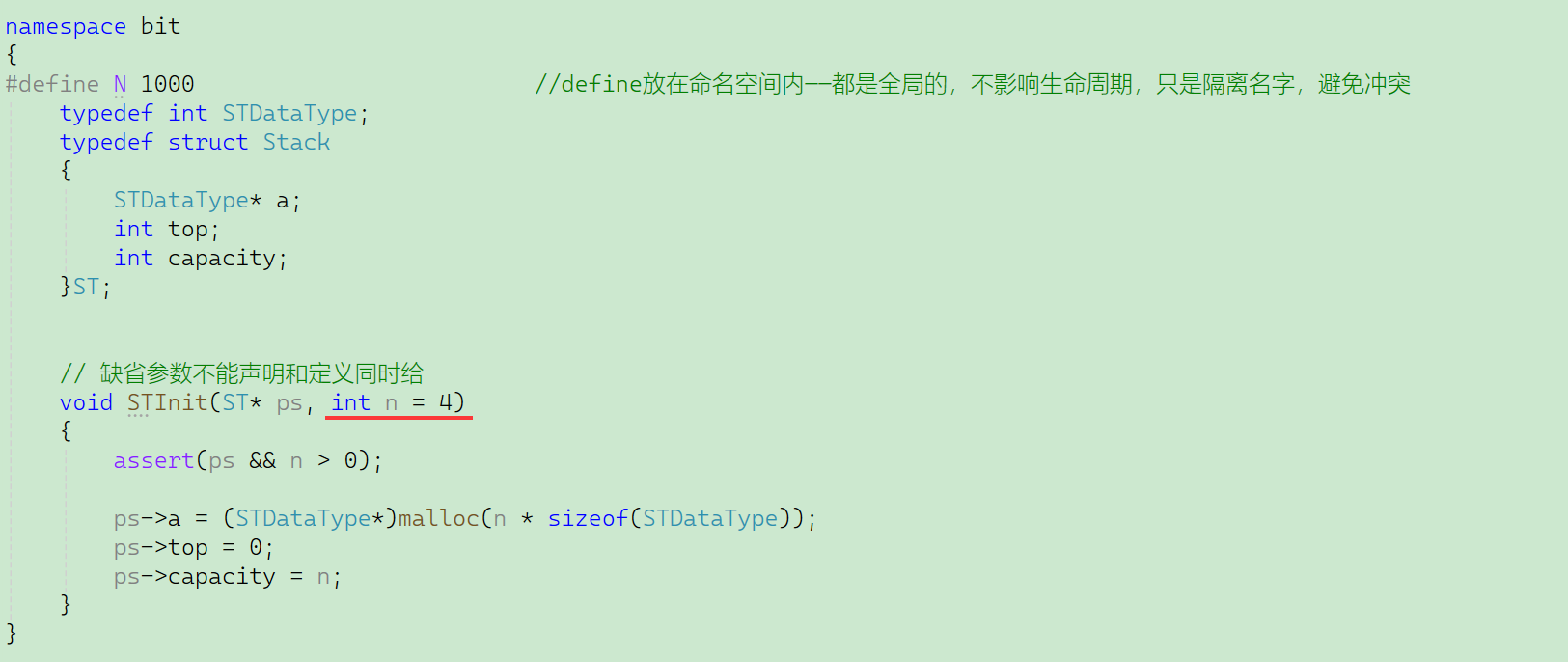
void STInit(ST* ps, int n = 4);// Stack.cpp
#include"Stack.h"
// 缺省參數不能聲明和定義同時給
void STInit(ST* ps, int n)
{assert(ps && n > 0);ps->a = (STDataType*)malloc(n * sizeof(STDataType));ps->top = 0;ps->capacity = n;
}// test.cpp
#include"Stack.h"
int main()
{ST s1;STInit(&s1);// 確定知道要插?1000個數據,初始化時?把開好,避免擴容ST s2;STInit(&s2, 1000);return 0;
}定義一個棧——>對棧初始化——>插入1000個數據 這個時候會導致一個問題——>這個程序會有大量的擴容——>而且擴容到后面,異地擴容消耗很大(如果沒有足夠的空間:開新的空間——拷貝數據——釋放舊的空間),而且越往后消耗越大(拷貝空間、拷貝時間)
C語言傳統的解決方案:
(1)定義一個宏N,一開始就先開一堆空間。

這樣寫死的方式都是不太好的,因為當初始數據較小時就會造成比較大的空間浪費。
(2)增加一個參數n,靈活一點,能夠幫助我們去控制,即要初始化多少你直接給我
(最好不要使用宏——>不好用)
(3)在C++,如果一開始不知道要初始化多大的空間,就可以給參數一個官方指導值(缺省值)
有了缺省參數,就能在初始化時不去指定具體開辟多大的空間,不指定就默認申請4字節的空間。
——體現半缺省的價值:知道要開多大就傳多大,不知道就開默認值。
4. 函數重載
4.1 函數重載的概念
函數重載:是函數的一種特殊情況,C++允許在同一作用域中聲明幾個功能類似的同名函數,這 些同名函數的形參列表(參數個數、類型、類型順序)不同,常用來處理實現功能類似、數據類型不同的問題。
函數重載的要點
- 同一作用域:同名函數——>形參不同(個數不同、類型不同)。
這樣C++函數調用就表現出了多態行為,使用更靈活。
C語言是不支持同一作用域中出現同名函數的。
error C2084:“函數“int?Add(int,int)”已有主體
#include<iostream>
using namespace std;// 1、參數類型不同
int Add(int left, int right)
{cout << "int Add(int left, int right)" << endl;return left + right;
}double Add(double left, double right)
{cout << "double Add(double left, double right)" << endl;return left + right;
}// 2、參數個數不同
void f()
{cout << "f()" << endl;
}void f(int a)
{cout << "f(int a)" << endl;
}// 3、參數類型順序不同
void f(int a, char b)
{cout << "f(int a,char b)" << endl;
}void f(char b, int a)
{cout << "f(char b, int a)" << endl;
}int main()
{Add(10, 20);Add(10.1, 20.2);f();f(10);f(10, 'a');f('a', 10);return 0;
}c++可根據形參匹配同名函數
(同一作用域內的同名函數——都在同一命名空間、或都在全局)
(不同域本就允許同名函數)。
之前是在不同作用域,即使有“不去訪問未展開的命名空間”的規定,也可以根據參數去調用命名空間內的函數。
原理都是參數匹配。
4.1.1 不構成函數重載的情況
(1)返回值不同
void fxx()
{//……
}int fxx()
{return 0;
}返回值不同是不構成重載的,函數重載根本就不看返回值,有返回值沒有返回值都沒關系,只看參數列表。
因為看返回值的不同,無法區分函數調用,調用時會根據參數去匹配函數。
換一個角度看,返回值在調用的時候并不是必須的,返回值可以不接收,但是參數必須傳遞。
上述代碼結果:報錯。
(2)缺省值不同
void f(int a = 10)
{//……
}void f(int a = 20)
{//……
}上述代碼結果:報錯。
(3)不同的(命名空間)域
//情景1:兩個同名函數——不構成重載,但是可以同時存在
namespace bit1
{void func(int a){//……}
}namespace bit2
{void func(int b){//……}
}情景2:若是都叫bit1——不構成重載,不能同時存在。
還是在同一命名空間(會合并),那同一作用域函數要同名存在,必須滿足重載規則。
4.1.2 函數重載的調用歧義
// 下?兩個函數構成重載
// f()但是調用時,會報錯,存在歧義,編譯器不知道調用誰
void f1()
{cout << "f()" << endl;
}void f1(int a = 10)
{cout << "f(int a)" << endl;
}int main()
{f1();return 0;
}不調用就不會報錯
全缺省和無參的同名函數,構成函數重載,但是調用f()會存在歧義。
調用全缺省的函數時給參數,也不會發生調用歧義。
4.1.3 非函數重載的調用歧義
調用歧義:兩個swag(int*,int*)都可以調——swag(&a,&b)不知道調哪一個 。? ??
但是swag(&c,&d)知道——只有全局域有其定義swag(double*,double*)
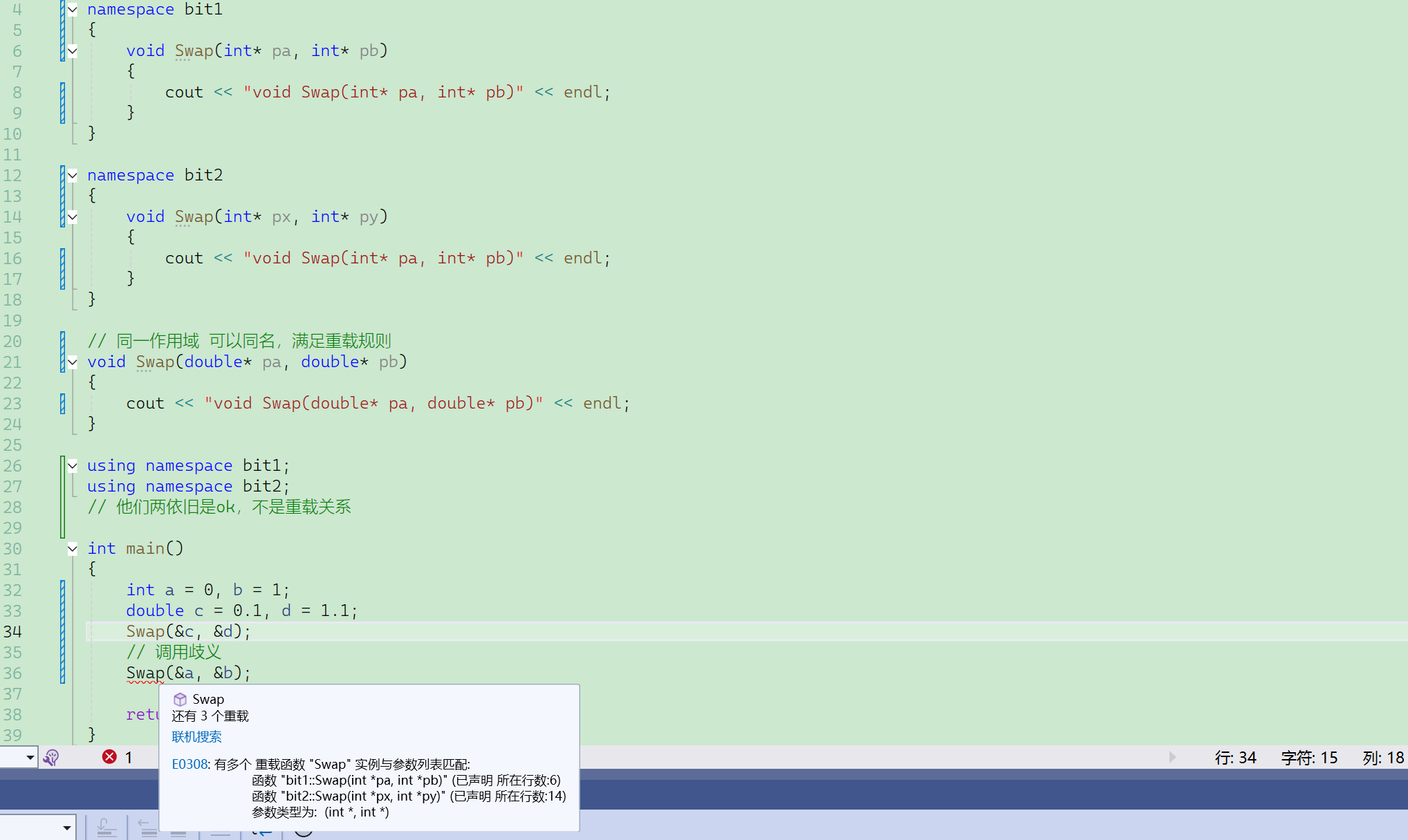
展開命名空間,兩個swap還是在各自的域中,不構成函數重載。
(不構成函數重載但是都可以存在,不調用就不會出錯,這里的錯誤在于調用歧義)
命名空間都展開——不構成重載關系——還是在各自的作用域,同一個域內才有重載的概念。
重載:同一個菜地。
展開:菜地旁插了塊牌子。
4.1.4 隱式類型轉換
//只有一個函數的時候——才存在隱式類型轉換
void f(int a, char b)
{cout << "f(int a,char b)" << endl;
}//void f(char b, int a)
//{
// cout << "f(char b, int a)" << endl;
//}int main()
{int a = 0, b = 1;double c = 0.1, d = 1.1;f(1, 'a');f('a', 1); //只有一個f(int,char),調用f(char,int)會有轉換return 0;
}//存在多個函數同名:只有匹配的問題,沒有轉換的問題——不讓轉
void f(int a, char b)
{cout << "f(int a,char b)" << endl;
}void f(char b, int a)
{cout << "f(char b, int a)" << endl;
}int main()
{int a = 0, b = 1;double c = 0.1, d = 1.1;f(1, 'a');f('a', 1);//兩個同名函數,這個調用就存在歧義f('a', 'a')//這個調用是帶有條件的,條件就是隱式類型轉換//調用第一個f(int,char)就是一參char——>int//調用第二個f(char,int)就是二參char——>int//這里的調用就存在歧義,不知道調哪一個——調用必須得沒有歧義return 0;
}
4.2 函數重載的原理
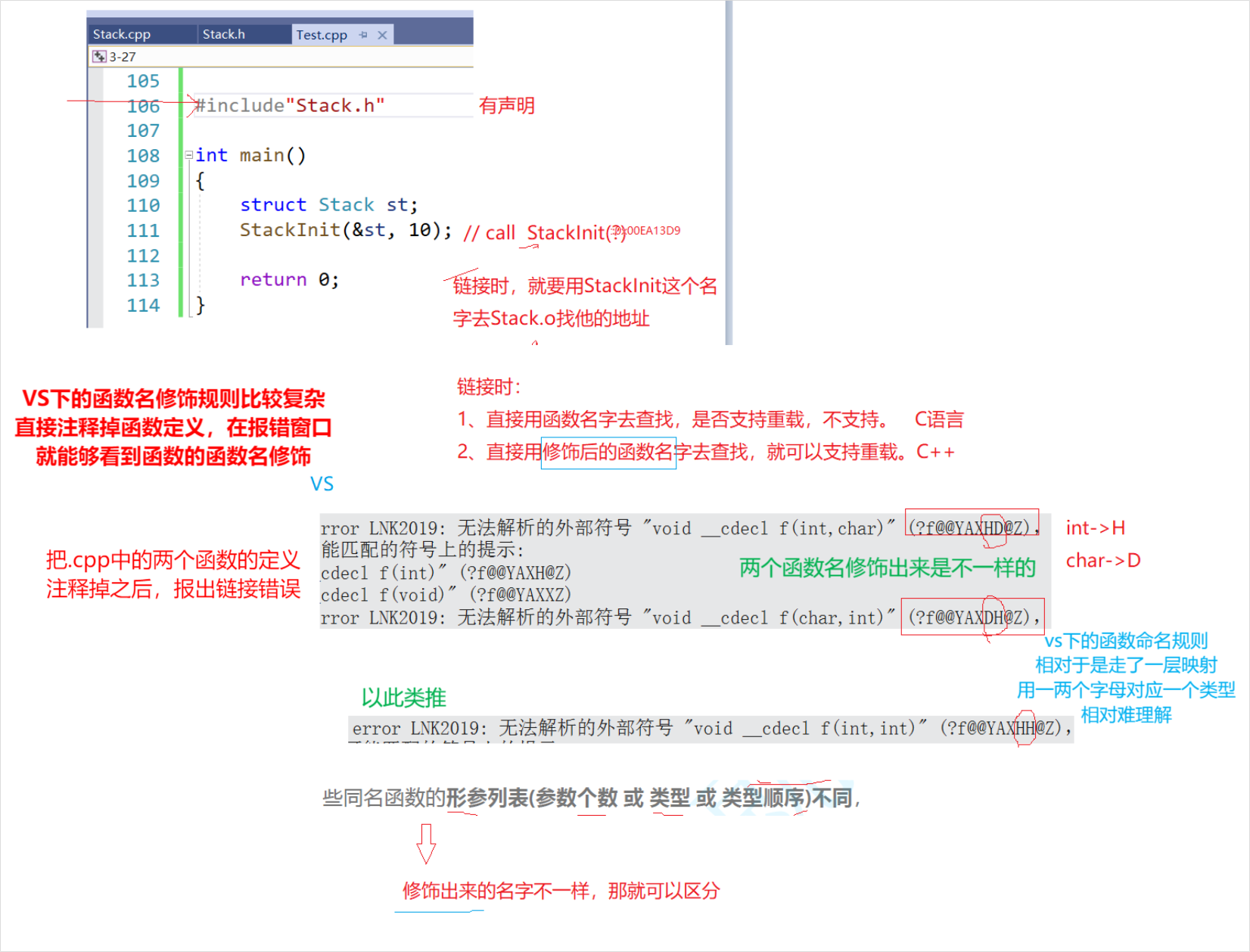
C++支持函數重載的原理--名字修飾(name Mangling)
為什么C++支持函數重載,而C語言不支持函數重載呢?
——函數名修飾規則
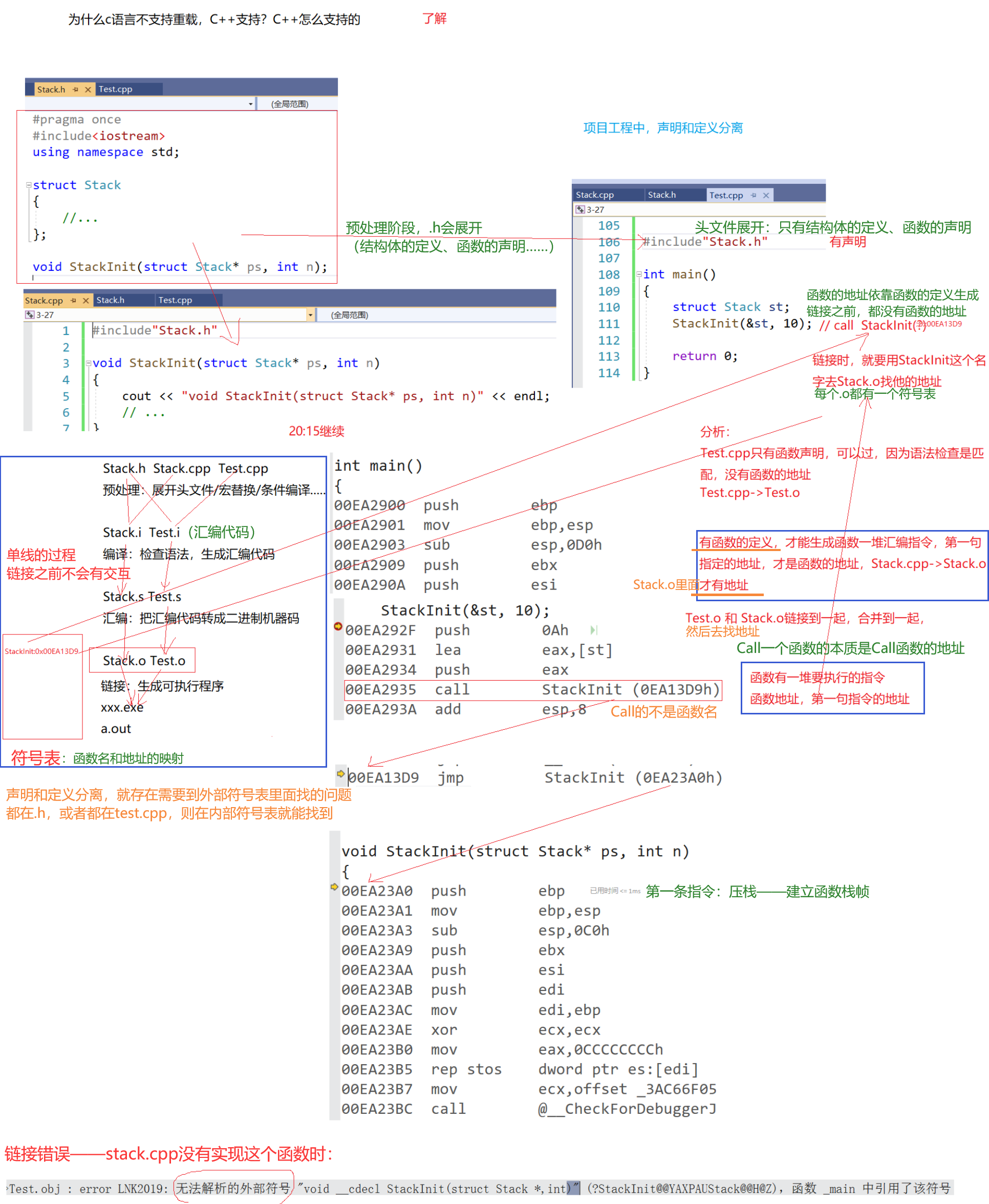
注意點:只要函數調用去匹配函數聲明的時候,在參數上是匹配的,那么這個調用就是合法的,即函數調用的合法性與函數定義無關,只與函數聲明有關。
聲明和定義分離時,就會有缺地址的問題——地址在外部符號表。
只有聲明,沒有定義(沒有地址),call指令就只檢查:
使用符不符合規則—參數匹不匹配—語法正不正確
語法不正確:報出語法錯誤。
語法正確:在鏈接的時候拿函數名去符號表里面找地址。
直接拿函數名去找嗎???
前面講這么多就是為了說明:
- 在鏈接時有這么一個查找的過程,為什么C不支持,而c++支持?
- 因為在鏈接的時候要用函數名去找地址,如果聲明和定義分離,即包.h一起編譯的匯編代碼缺地址,而調用一個函數,要用函數名去找,C語言直接用函數名去找,就區分不開。(聲明和定義沒有分離,是不找的)
- 而c++用修飾后的函數名去找,不同的編譯器有具體的函數名修飾規則(把參數帶進來),但都會把函數的參數的類型帶進來。
- 大概就是公共前綴+函數名+形參類型。
在C/C++中,一個程序要運行起來,需要經歷以下幾個階段:預處理、編譯、匯編、鏈接。
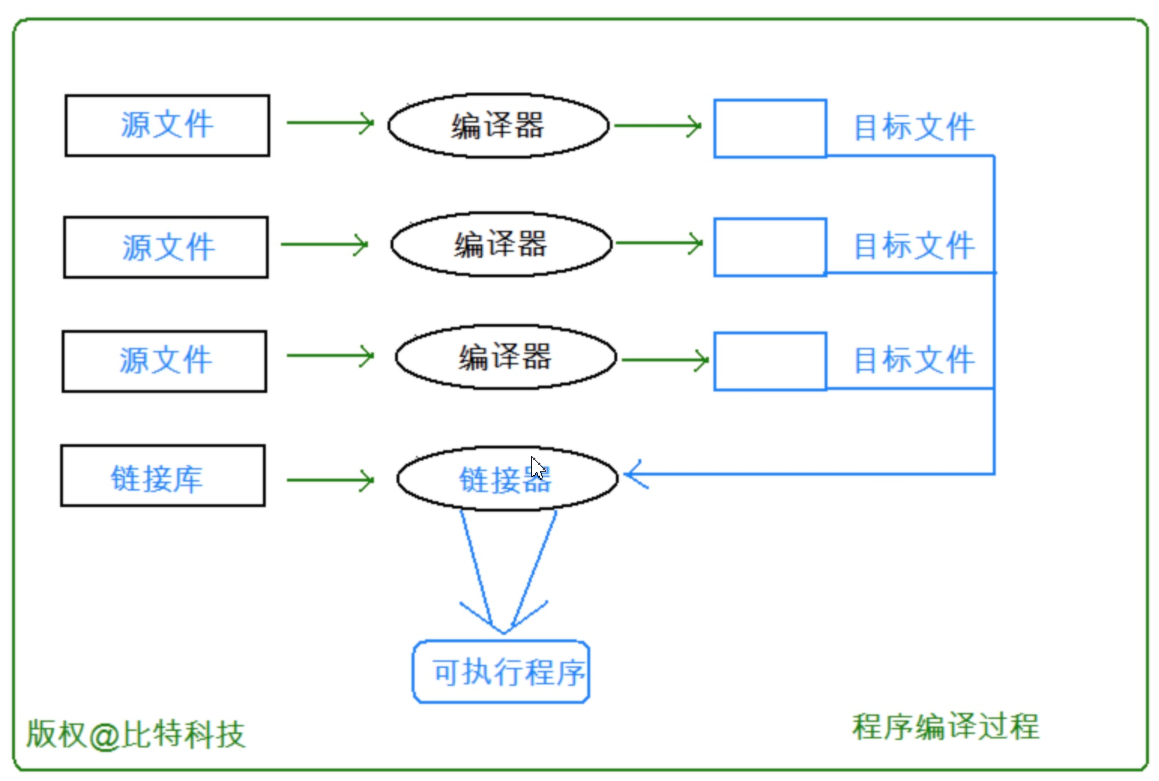

1. 實際項目通常是由多個頭文件和多個源文件構成,而通過C語言階段學習的編譯鏈接,我們可以知道,【當前a.cpp中調用了b.cpp中定義的Add函數時】,編譯后鏈接前,a.o的目標文件中沒有Add的函數地址,因為Add是在b.cpp中定義的,所以Add的地址在b.o中。那么怎么辦呢?
2. 所以鏈接階段就是專門處理這種問題,鏈接器看到a.o調用Add,但是沒有Add的地址,就會到b.o的符號表中找Add的地址,然后鏈接到一起。
……
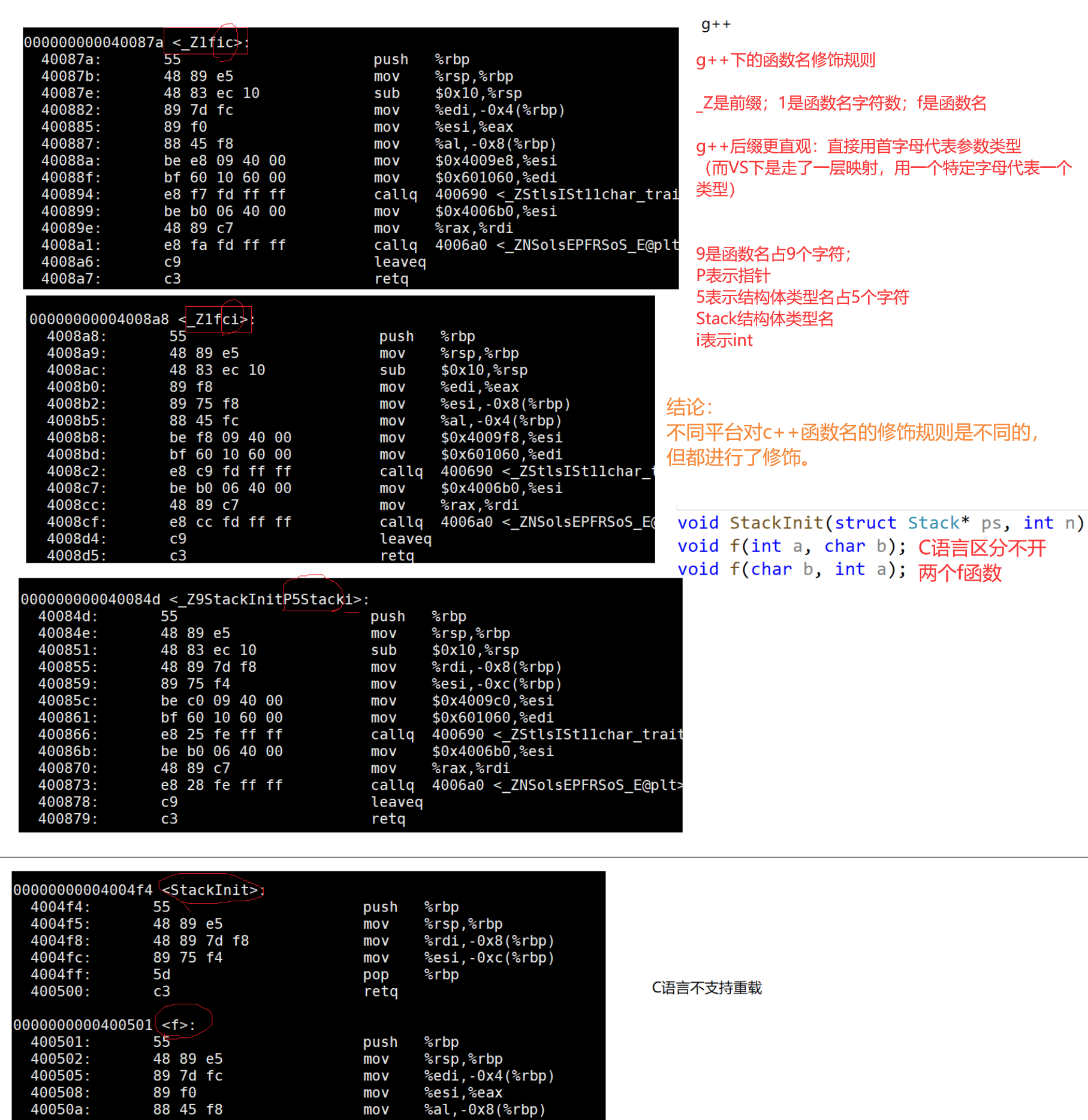
3. 那么鏈接時,面對Add函數,鏈接接器會使用哪個名字去找呢?這里每個編譯器都有自己的函數名修飾規則。
4. 由于Windows下vs的修飾規則過于復雜,而Linux下g++的修飾規則簡單易懂,下面我們使用了g++演示了這個修飾后的名字。
5. 通過下面我們可以看出gcc的函數修飾后名字不變。而g++的函數修飾后變成【_Z+函數長度+函數名+類型首字母】。
采用C語言編譯器編譯后結果
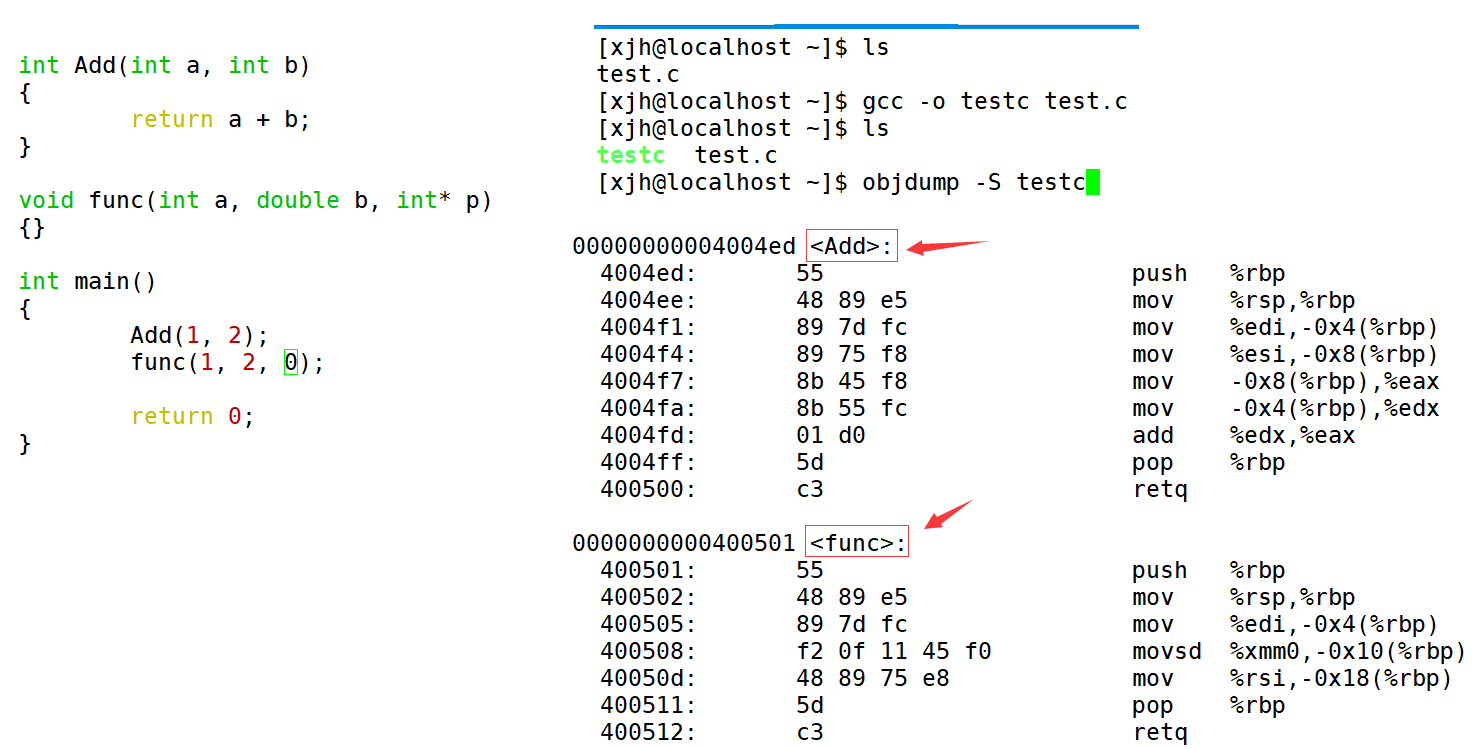
結論:在linux下,采用gcc編譯完成后,函數名字的修飾沒有發生改變。
采用C++編譯器編譯后結果
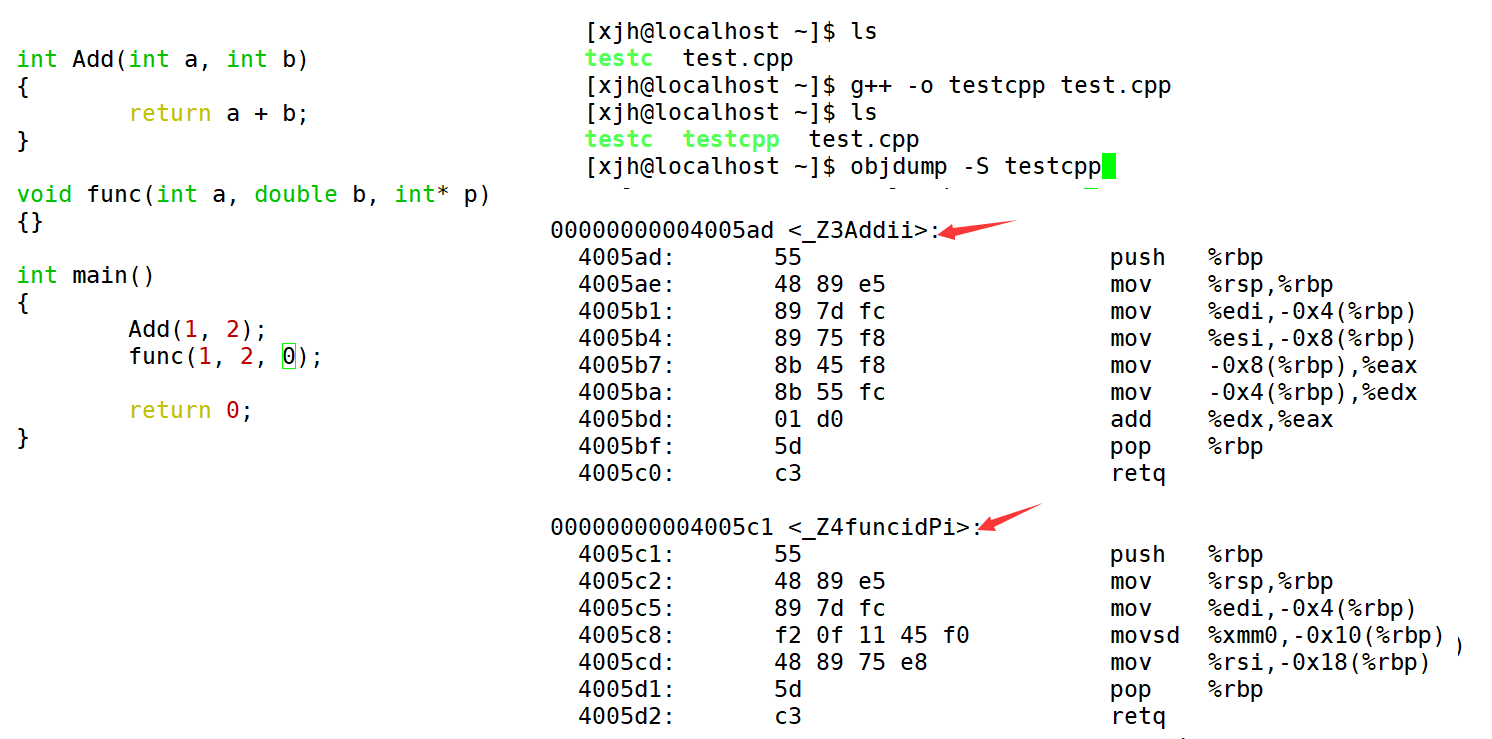
結論:在linux下,采用g++編譯完成后,函數名字的修飾發生改變,編譯器將函數參數類型信息添加到修改后的名字中。
Windows下名字修飾規則
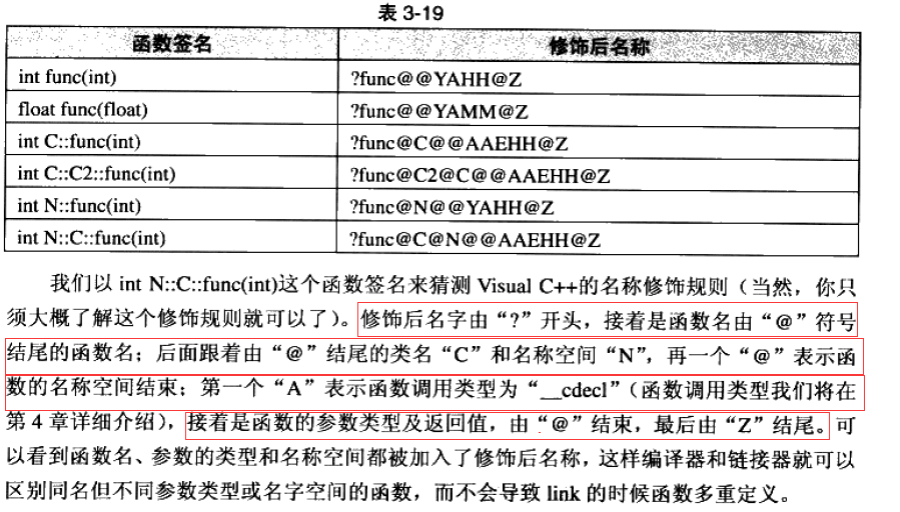
對比Linux會發現,windows下vs編譯器對函數名字修飾規則相對復雜難懂,但道理都是類似的,我們就不做細致的研究了。
【擴展學習:C/C++函數調用約定和名字修飾規則--有興趣好奇的同學可以看看,里面有對vs下函數名修飾規則講解】
C/C++的調用約定
6. 通過這里就理解了C語言沒辦法支持重載,因為同名函數沒辦法區分。而C++是通過函數修
飾規則來區分,只要參數不同,修飾出來的名字就不一樣,就支持了重載。
7. 如果兩個函數函數名和參數是一樣的,返回值不同是不構成重載的,因為調用時編譯器沒辦
法區分。
:封裝的層次(Python)——不同的邏輯“一樣”的預期)


:信任、約定與“安全基線”鏡像庫)

)












)
