前言
我在此文《ForceVLA——將具備力感知的MoE整合進π0的動作專家中:從而融合“視覺 語言 力反饋”三者實現精密插拔》的開頭說過,我司「七月在線」目前側重以下兩大本體的場景落地
- 人形層面,側重
1.1 人形靈巧操作
1.2 人形展廳講解 - 機械臂層面,側重
2.1 智能裝配
2.2 精密插拔
而訓練人形機器人做靈巧操作的方式之一便是從人類視頻中學習
當然,此類模型,如今已經層出不窮了,且真實機器人數據采集在模仿學習領域推動了機器人操作的重大進展,然而,數據采集過程中對機器人硬件的依賴從根本上限制了數據的規模
- EgoVLA探討了利用第一視角人類視頻訓練VLA模型的方法
使用人類視頻的優勢不僅在于其規模,更重要的是場景和任務的豐富性 - 通過在預測人類手腕和手部動作的人類視頻上訓練的VLA,可以執行逆運動學和動作重定向,將人類動作轉換為機器人動作
且僅需少量機器人操作演示對模型進行微調,便可獲得機器人策略
第一部分?EgoVLA
1.1 引言、相關工作
1.1.1 引言
如EgoVLA原論文所說,近年來,得益于大規模真實機器人數據采集[1,2],機器人操作領域取得了巨大進展。與利用仿真方法相比,直接用真實機器人數據進行監督學習能夠避免Sim2Real域間差異,并能輕松提升任務復雜度
- 為了高效采集復雜的機器人操作數據,研究人員提出了多種遙操作工具,包括關節映射[3,4,5]、外骨骼[6,7,8]以及虛擬現實設備[9,10,11]。盡管這些方法令人鼓舞,但對機器人和專家操作員的需求從根本上限制了可采集數據的規模
- 從人類視頻中學習操作如何?如果將人類視為一種特殊形式的機器人,那么全世界有80億個機器人正在各類環境中持續運行——而我們希望機器人能夠在這些環境中操作
近期關于手-物體交互預測的研究[12]在預測人類操作的長期意圖方面取得了有希望的成果。如果能夠利用這些人類數據來訓練機器人策略,不僅能夠輕松擴展訓練數據的數量,更重要的是能夠提升任務和場景的多樣性
這使得機器人能夠在當前難以適應的場景或即使遠程操作也具有挑戰性的任務中進行訓練
作者的關鍵觀察是:人類動作空間與機器人動作空間之間的差異可能并不大,并且可以通過少量幾何變換進行近似
與其在機器人數據上訓練機器人視覺-語言-動作(VLA)模型[13,14,15,16],來自1 UC San Diego,?2 UIUC,?3 MIT,?4 NVIDIA的研究者提出在人體數據上訓練人體第一視角VLA(EgoVLA)
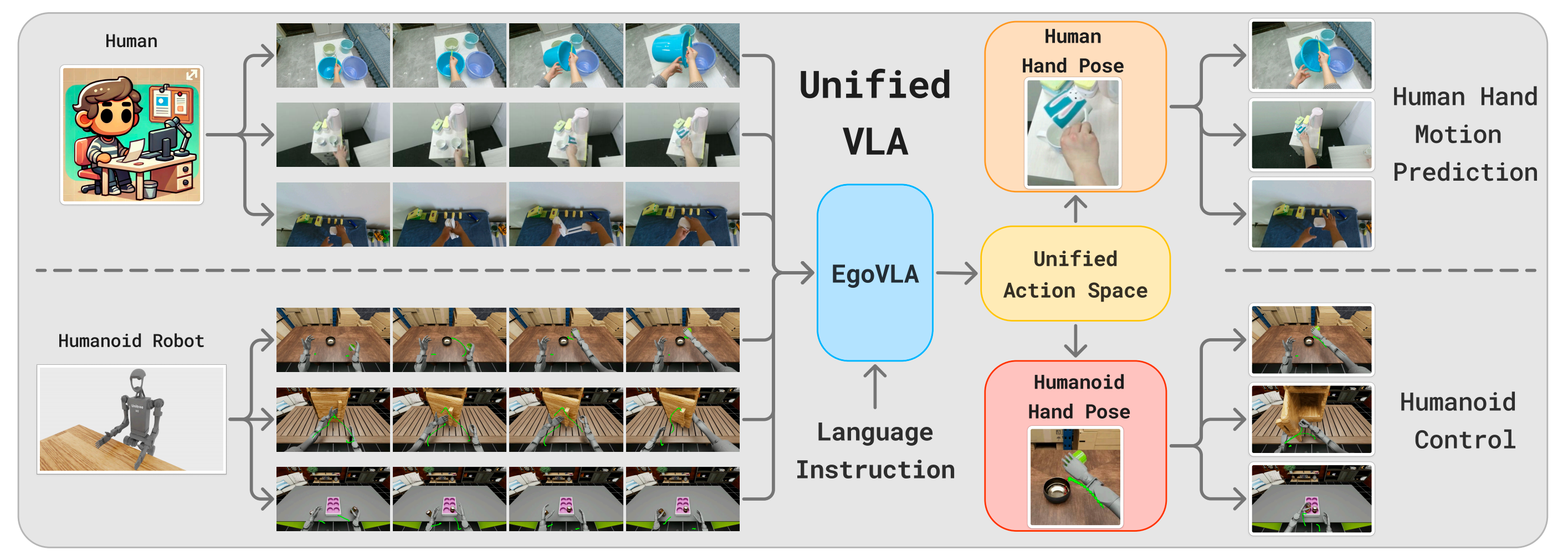
- 其對應的論文為:EgoVLA: Learning Vision-Language-Action Models from Egocentric Human Videos
- 其項目網址為:rchalyang.github.io/EgoVLA/
截止到25年8月中旬,他們暫未開源,如果他們計劃開源,則期待
具體而言
- 給定若干幀視覺觀測、語言指令以及當前手部姿態作為輸入,VLA將在未來幾個步驟內預測人類動作
動作空間包括人類手腕和手部關節角度。這個人類動作空間可以通過逆向運動學將手腕位置轉換為末端執行器位置,并通過動作重定向將人類手部關節轉換為機器人手部關節,從而轉化為機器人動作空間 - 因此,人體VLA本質上已經是一種機器人策略,只是輸入為人手圖像,且動作輸出仍存在誤差。但可以通過遙操作收集少量機器人演示,對VLA進行進一步微調來糾正這一點
如此,便無需大規模機器人數據進行訓練
為了評估機器人操作性能,作者提出了一種基于NVIDIA IsaacSim[17]的新型仿人雙臂操作基準測試,稱為Ego Humanoid Manipulation Benchmark。在該基準測試中,作者設置了12項任務,包括執行原子動作的簡單任務以及由多個原子動作組合而成的長時序任務
作者為每個任務收集了100個演示數據,并利用該基準測試對模型進行評估。在實驗中,作者首先在Ego-Centric Human Manipulation數據集上訓練EgoVLA模型,并針對特定任務在收集到的仿人操作演示上進行微調,說白了,就是通過人類第一視角的視頻做預訓練,然后用真機數據做微調
1.1.2 相關工作:涉及靈巧操作、VLA
第一,對于靈巧操作
靈巧操作的研究已從基于控制的方法[19,20,21,22,23,24,25]發展到以學習為驅動的方法[26,27]
- 早期工作側重于精度,但在多樣化場景中的泛化能力有限。基于學習的方法引入了姿態向量生成[28,29,30]、中間表示[31,32]和接觸圖[33,34],但大規模靈巧操作仍然是一個未解難題
- 近期的研究嘗試利用第一視角人類視頻訓練特定任務的策略[35,36]
相比之下,作者旨在直接通過第一視角人類演示開發通用型操作模型
第二,對于VLA
- 視覺-語言模型(VLMs)[37,38,39]在多模態任務中展現出了強大的泛化能力[40,41,42,43,44]。在此基礎上,視覺-語言-動作模型(VLA)[16,14,45,13,15,46]通過大規模機器人數據對VLMs進行微調,實現了感知與動作的集成
- 然而,VLA的訓練對數據需求極高,通常需要大量的遠程操作[47,48]或腳本化執行[49,50]。OpenVLA[14]和Octo[13]利用了眾包機器人數據集[1],但在可擴展性方面仍面臨瓶頸
作者提出了一種替代方案:通過人類第一視角視頻進行策略學習,并結合小規模目標域微調
第三,對于第一人稱視覺
- 第一人稱視覺研究[51,52,53]傳統上在數據規模和多樣性方面受到限制。近期的數據集[54,55]在覆蓋范圍上有所提升,但主要關注超出現有機器人能力的活動。更簡單的數據集[56,57]雖然捕捉了日常交互,但缺乏姿態標注
- 為了解決這一問題,作者精選了有針對性的數據集組合,并引入了一個專為靈巧操作學習優化的第一人稱人體視頻數據集
第四,對于從野外視頻中學習
- 已有多項研究 [58,59] 提出從野外視頻中提取可供性或交互線索。受第一視角視覺的啟發,近期研究 [60,61,62,63,64,65,66] 利用人類視頻進行預訓練表征,并展示了積極的遷移效果
- 然而,大多數工作側重于無監督學習,未充分利用細粒度的手部或手腕姿態信息
相比之下,作者的工作在VLA框架下使用高質量的第一視角數據,直接提升靈巧策略學習,充分利用可穿戴手部追蹤技術的最新進展
1.2?從第一人稱人類視頻中學習操作技能
本節將介紹作者第一人稱人類操作數據集的構建過程,EgoVLA在該數據集上的訓練方法,如何彌合人類與仿人機器人之間的體現差異,以及EgoVLA在操作任務中的部署
1.2.1?以自我為中心的人體操作數據集
借鑒語言模型和視覺-語言模型訓練的經驗,作者強調數據集結構在提升模型性能中的重要性
- 他們構建了一個大規模的人類第一視角操作數據集,專注于包含技能豐富的視頻序列及其對應的姿態標注。該綜合數據集包含第一視角的RGB觀測、手腕姿態、手部姿態和攝像頭姿態
- 該數據集整合了來自四個來源的序列,其相對比例如圖3所示:
HOI4D包含4000段視頻,捕捉了如抓取-放置、重新定位和關節物體交互等單手操作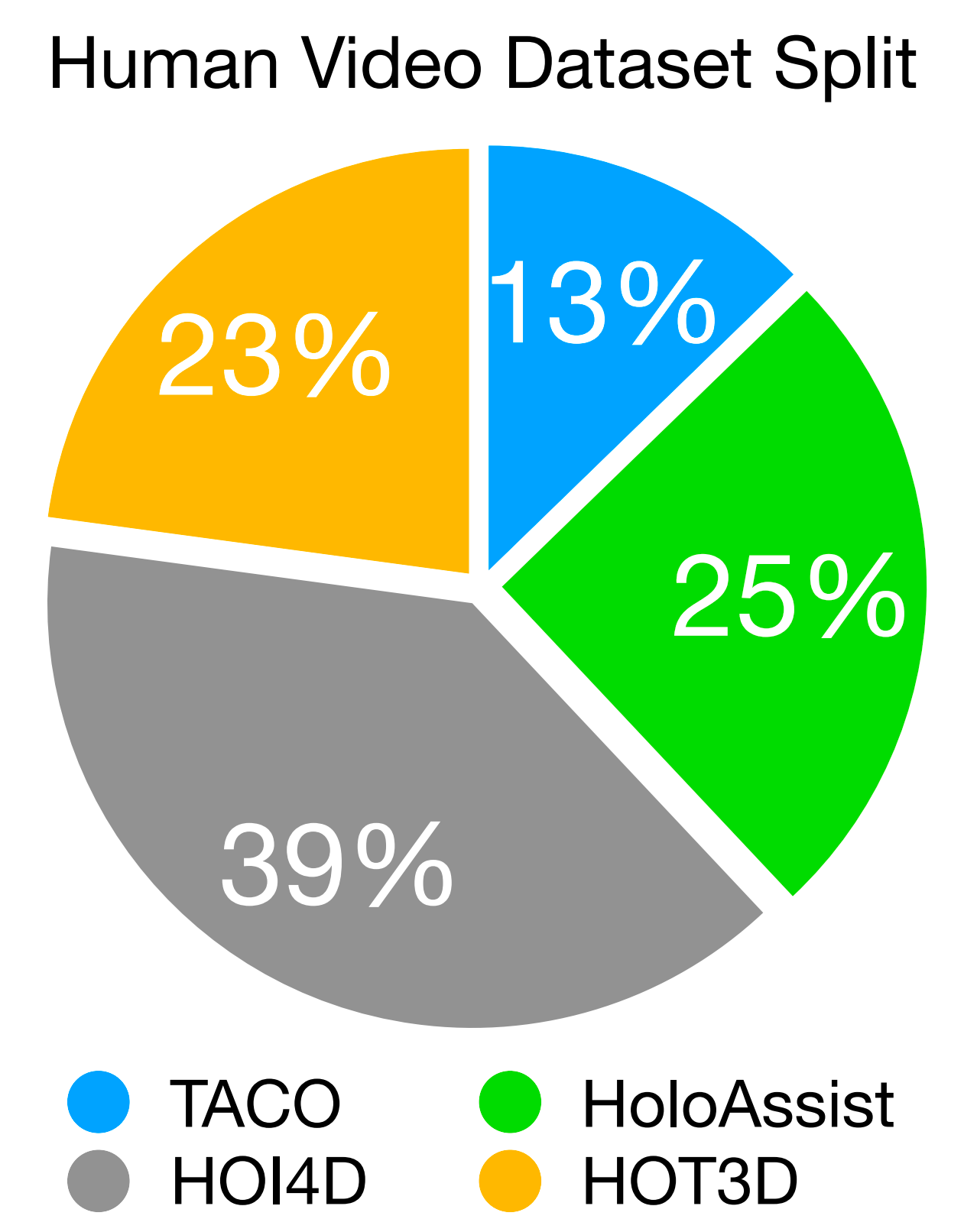
HOT3D提供了833分鐘與33個剛性物體交互的視頻,并配有精確的三維手部和攝像頭姿態標注
HoloAssist則包含了166小時的復雜任務錄制。例如電池更換、家具組裝和機器安裝
盡管其手部姿態標注較為噪聲,但它捕捉了豐富的雙手交互
且為避免HoloAssist因標簽噪聲而被過度代表,作者對其進行了1/10的均勻采樣,以平衡任務和數據來源
TACO包含2,317個動作序列,涵蓋151組工具-動作-物體三元組
對于數據處理:第一人稱視頻由于攝像機的持續移動,給學習帶來了挑戰
為了解決這一問題,作者利用世界坐標系下的攝像機位姿,將未來手腕的位置投影到當前攝像機幀中,從而確保監督的一致性。訓練樣本通過以3幀每秒的頻率采樣RGB觀測值生成,以實現計算效率與時間連續性的平衡。他們的數據集共包含約500,000對圖像與動作,涵蓋多種操作任務
1.2.2 EgoVLA模型:基于NVILA-2B + 基于Transformer的動作頭
作者在視覺-語言模型的基礎上構建了EgoVLA,以利用強大的視覺和語義推理能力
- 具體而言,他們采用NVILA-2B[67]作為主干網絡,該模型具有強大的視覺-語言理解能力和緊湊的體積,從而實現意圖推斷和高效微調
如圖2所示「EgoVLA以視覺歷史、語言指令和動作查詢token作為輸入。潛在特征通過動作頭被轉換為人類動作。且采用手腕姿態和MANO手部參數[18]作為人類動作空間」
EgoVLA的輸入包括當前和歷史的第一視角視覺觀測、語言指令、動作查詢token以及人體本體感知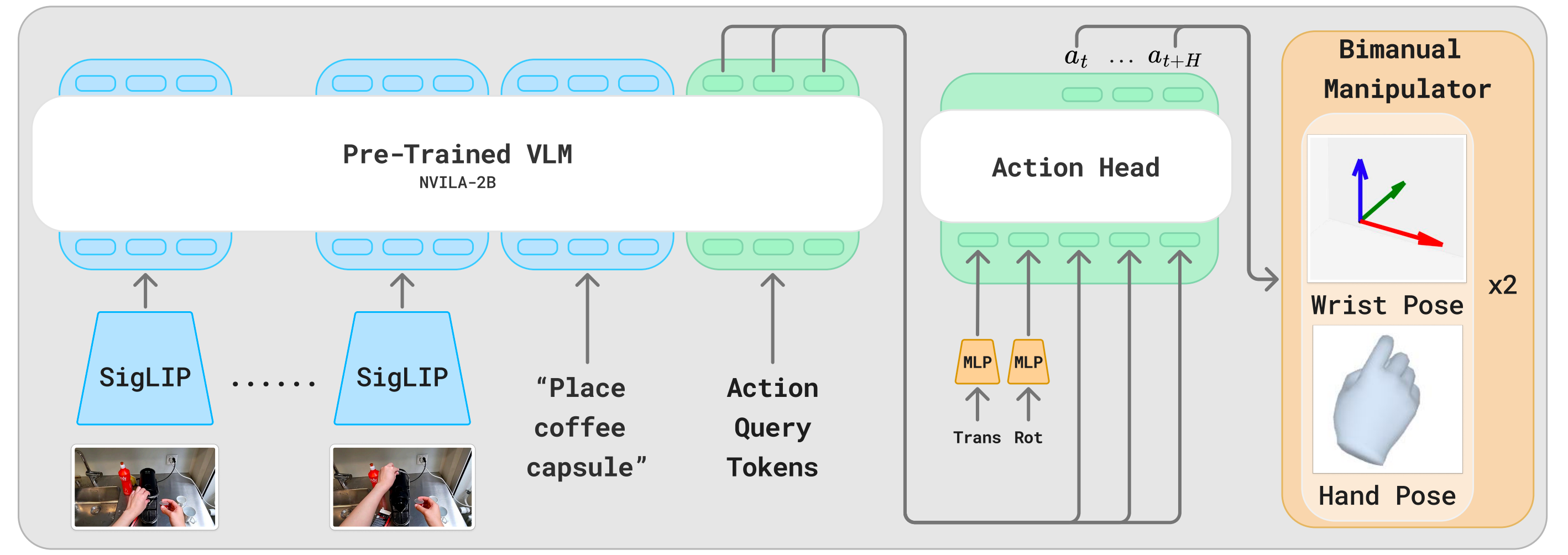
這些輸入由VLM主干網絡進行編碼,并通過動作頭進一步處理,以預測未來的人類或機器人動作
其中
? 視覺觀測由六幀RGB圖像組成:包括當前觀測幀以及以0.2秒間隔采樣的前五幀,總共覆蓋1秒的歷史。每幀分辨率為384×384
- 每個預測動作包括腕部姿態『相機坐標系下的三維平移和 rot6D 表示[68]的旋轉』以及手部關節角度,后者通過 MANO 手部模型[18]的前 15 個主成分(PCA)表示,說白了,就是通過MANO給人手手部關節建模,類似SMPL給人體建模一樣
EgoVLA被訓練用于回歸相機坐標系下的未來腕部姿態和手部關節參數。其目標函數為:
其中
和
?分別為腕部平移和手部關節角度回歸的 L2 損失。
是 rot6D[68] 腕部朝向的旋轉損失。
、
、
為加權系數
至于動作頭是一個基于 Transformer(300M)的結構,由六個編碼器層組成,每層隱藏單元數為1536
它的輸入包括人類(或機器人)的本體感覺狀態,以及與動作查詢token對應的潛在嵌入表示,并預測一個在1秒時間范圍內的動作序列(以30 Hz的頻率,未來30步)用于雙手
作者使用詞匯表中最后的H=30個詞ID作為動作查詢token
對于訓練細節:作者首先在自有的第一視角人類操作數據集上對EgoVLA進行預訓練,共20個周期。隨后,在機器人示范數據上進行115個周期的后續訓練,其中在第100個周期后降低學習率
在訓練過程中,包含視覺編碼器在內的整個模型都會進行微調。更多訓練配置詳見補充材料
1.2.3?將EgoVLA遷移到人形機器人
人類和人形機器人在操作框架上具有相似性,均使用雙臂和雙手。然而,由于攝像頭姿態、手部形態以及視覺外觀的差異,直接將EgoVLA遷移到人形機器人上具有一定挑戰性
為實現部署,作者利用少量機器人演示數據對EgoVLA進行微調,并借助如圖4所示的統一動作空間『統一動作空間:MANO手部參數被用作人類與機器人共享的動作空間。對于機器人手,在訓練過程中,優化后的MANO參數能夠產生與機器人手指尖相同的位置。在部署階段,一個小型MLP將預測的指尖位置映射為關節指令』
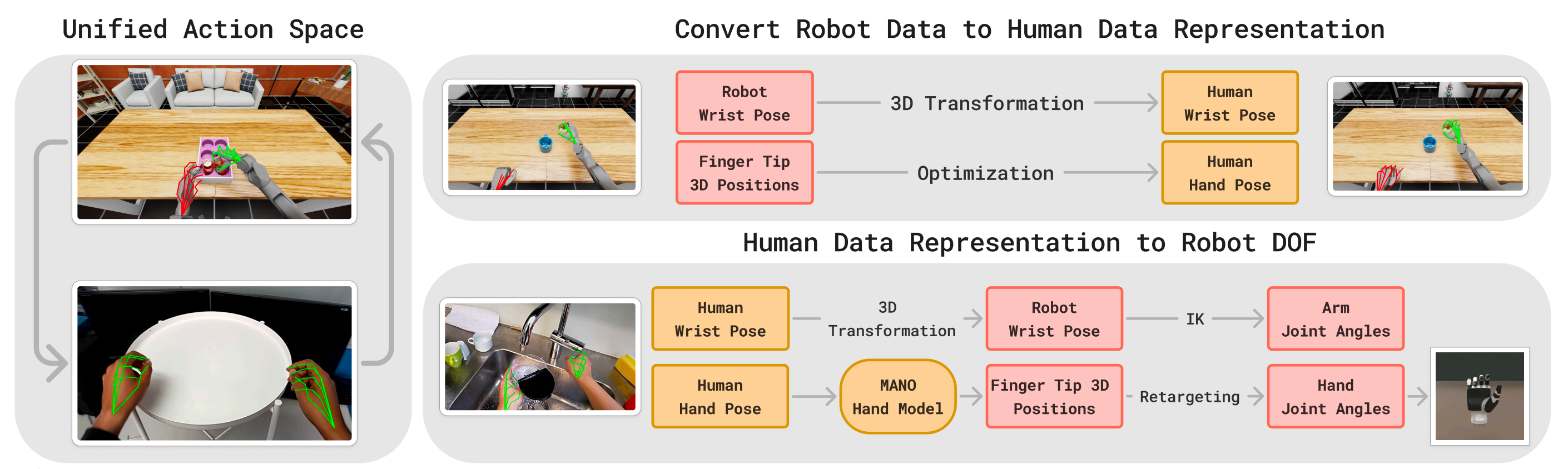
首先,對于將機器人數據重新映射到人類表示
為了在機器人數據上進行微調,作者首先需要將機器人的動作空間與人類表示對齊
- 對于末端執行器的姿態,通過三維變換來對齊機器人和人類的坐標系
- 對齊手部配置則更加復雜:作者估算能夠最好地近似機器人手部驅動的MANO[18]參數(相當于通過SMPL模型近似人體姿態),通過最小化預測(人體)指尖位置與(機器人)觀測指尖位置之間的差異來實現:
其中
為MANO手部參數
表示通過MANO正向運動學計算得到的(人類的)指尖位置
為觀測到的機器人指尖位置
該統一動作空間使得EgoVLA可以直接在機器人演示數據上進行微調,無需額外的架構更改或重新初始化
其次,對于人體手到機器人手的映射
在推理階段,由EgoVLA預測的手腕和手部姿態會被映射到機器人的執行器,如圖4(底部行)所示
- 首先,手腕姿態通過三維變換被轉換為機器人末端執行器的姿態,并通過逆向運動學(IK)求解相應的手臂關節角度
其次,對于手部驅動,作者使用MANO模型根據預測的MANO參數計算三維手部關鍵點 - 然后,利用一個輕量級的多層感知機(MLP),根據三維手部關鍵點預測機器人手部的關節指令
該MLP在機器人演示數據上訓練,其中手部動作被重新定向為人體手部的表示
This MLP is trained on robot demonstrations where hand actuations are retargeted into human hand representations.
該映射實現了平均指尖位置誤差為米
此外,通過該重定向流程回放原始演示能夠保持任務的有效性,表明重定向過程中引入的小誤差不會顯著影響控制性能。更多實現細節見補充材料
1.3?Ego 仿人操作基準
除了數據稀缺之外,基于學習的機器人技術面臨的另一大挑戰是缺乏可擴展、穩健且可復現的評估方式。現實世界中的評估通常成本高昂、耗時,并且存在安全性和可復現性的擔憂——這些障礙在資源有限的環境(如學術實驗室)中尤為突出
最新研究[69]表明,基于仿真的評估結果與現實世界性能高度相關,因此可作為可靠的替代手段
- 故為了實現仿人操作的一致性基準測試,作者提出了Ego仿人操作基準,該基準基于NVIDIA Isaac Lab[70]構建。Ego仿人操作基準并非用于直接的仿真到現實遷移,而是借鑒LIBERO[71]和SIMPLER[69]的做法,將仿真作為一個可控且可復現的測試平臺,用于評估操作策略
- 作者的仿真平臺采用Unitree H1[72]仿人機器人,配備兩只Inspire靈巧手[73],涵蓋了12項操作任務

此外,對于
- 觀測與動作空間
作者的基準測試為觀測提供了機器人關節位置、末端執行器位姿、接觸力以及自中心RGB-D視覺輸入
雖然EgoVLA僅使用自中心視覺、末端執行器位姿、手部關節驅動和任務描述,但還為未來研究提供了額外的模態
機器人通過末端執行器控制手臂,以及通過PD關節控制手部。每只手具有12個自由度(6個主動關節,6個聯動關節)
最終的36維動作空間將手臂逆向運動學與手部直接驅動相結合。控制頻率為30 Hz
且還為每個任務提供逐步的成功指示器和子任務完成標志。每個子任務的定義和成功度量標準詳見補充材料 - 多樣化視覺背景
仿真環境允許對視覺條件進行完全控制。比如包含了5種房間紋理(Room 1–5)和5種桌面紋理(Table 1–5),從而生成25種不同的視覺背景組合,用于對模型泛化能力的穩健評估 - 演示數據
為支持模仿學習,作者通過Meta Quest 3結合Open Television [10]采集了專家演示。演示數據均在Room 1、2或3中采集,桌面紋理固定為Table 1
針對每個任務,作者采集了100條成功的演示,單次演示的幀數根據任務復雜度在100至500之間
// 待更



的實用指南)
:Vue3中高效安全修改列表元素屬性的方法)

)
進階繪圖)



)


?)




