目錄
一:基于 kubernetes 的 Prometheus 介紹
1:環境簡介
2:監控流程
3:Kubernetes 監控指標
二:Prometheus 的安裝
1:從 Github 克隆項目分支
2:安裝 Prometheus Operator
--server-side
3:Operator 容器啟動起來后安裝 Prometheus Stack
備注:
5:查看 Prometheus 容器的狀態
6:查看 servicemonitors
6:修改 grafana 的 service 的類型為 NodePort
7:訪問 grafana
8:修改 Prometheus 的 Service 類型
9:訪問 Prometheus
10:查看監控目標
三:配置 Grafana Dashbord
1:添加數據源
(1)添加數據源
(2)數據源選擇 Prometheus
(3)配置數據源
2:通過 Node id 導入監控模板
其他模板:
四:監控 MySQL 數據庫
1:在 Kubernetes 中安裝一個 mysql
2:設置 mysql 密碼
3:查看 pod
4:創建 service,暴露 mysql 端口
5:訪問測試
6:設置權限
7:配置 mysql exporter 采集 mysql 監控文件
1. 創建?mysql - exporter?資源
2. 查看?mysql - exporter?資源狀態
3. 測試獲取?metrics?數據
9:配置ServiceMonitor
10:創建這個 ServiceMonitor
11:在 prometheus 查看監控目標中是否出現了 mysql
12:在 grafana 中添加 mysql 監控模板
五:對接釘釘報警
1:部署 DingTalk
2:修改配置文件
3:啟動服務
4:配置Alertmanager
6:測試
一:基于 kubernetes 的 Prometheus 介紹
1:環境簡介
node - exporter + prometheus + grafana 是一套非常流行的 Kubernetes 監控方案。它們的功能如下:
- node - exporter:節點級指標導出工具,可以監控節點的 CPU、內存、磁盤、網絡等指標,并暴露 Metrics 接口。
- Prometheus:時間序列數據庫和監控報警工具,可以抓取 Cadvisor 和 node - exporter 暴露的 Metrics 接口,存儲時序數據,并提供 PromQL 查詢語言進行監控分析和報警。
- Grafana:圖表和 Dashboard 工具,可以查詢 Prometheus 中的數據,并通過圖表的方式直觀展示 Kubernetes 集群的運行指標和狀態。
2:監控流程
(1) 在 Kubernetes 集群的每個節點安裝 Cadvisor 和 node - exporter,用于采集容器和節點級指標數據。
(2) 部署 Prometheus,配置抓取 Cadvisor 和 node - exporter 的 Metrics 接口,存儲 containers 和 nodes 的時序數據。
(3) 使用 Grafana 構建監控儀表盤,選擇 Prometheus 作為數據源,編寫 PromQL 查詢語句,展示 K8S 集群的 CPU 使用率、內存使用率、網絡流量等監控指標。
(4) 根據監控結果,可以設置 Prometheus 的報警規則,當監控指標超過閾值時發送報警信息。這套方案能夠全面監控 Kubernetes 集群的容器和節點,通過 Metrics 指標和儀表盤直觀反映集群狀態,并實現自動報警,非常適合 k8S 環境下微服務應用的穩定運行。
具體實現方案如下:
- node-exporter: 在每個節點也作為 DaemonSet 運行,采集節點 Metrics。
- Prometheus: 部署 Prometheus Operator 實現,作為 Deployment 運行,用于抓取 Metrics 和報警。
- Grafana: 部署 Grafana Operator 實現,用于儀表盤展示。
3:Kubernetes 監控指標
K8S 本身的監控指標:
- CPU 利用率:包括節點 CPU 利用率、Pod CPU 利用率、容器 CPU 利用率等,用于監控 CPU 資源使用情況。
- 內存利用率:包括節點內存利用率、Pod 內存利用率、容器內存利用率等,用于監控內存資源使用情況。
- 網絡流量:節點網絡流量、Pod 網絡流量、容器網絡流量,用于監控網絡收發包大小和帶寬利用率。
- 磁盤使用率:節點磁盤使用率,用于監控節點磁盤空間使用情況。
- Pod 狀態:Pod 的 Running、Waiting、Succeeded、Failed 等狀態數量,用于監控 Pod 運行狀態。
- 節點狀態:節點的 Ready、NotReady 和 Unreachable 狀態數量,用于監控節點運行狀態。
- 容器重啟次數:單個容器或 Pod 內所有容器的重啟次數,用于監控容器穩定性。
- API 服務指標:Kubernetes API Server 的請求 LATENCY、請求 QPS、錯誤碼數量等,用于監控 API Server 性能。
- 集群組件指標:etcd、kubelet、kube-proxy 等組件的運行指標,用于監控組件運行狀態。
- API 服務指標:Kubernetes API Server 的請求 LATENCY、請求 QPS、錯誤碼數量等,用于監控 API Server 性能。
- 集群組件指標:etcd、kubelet、kube-proxy 等組件的運行指標,用于監控組件運行狀態。
這些都是 Kubernetes 集群運行狀態的關鍵指標,通過 Prometheus 等工具可以進行收集和存儲,然后在 Grafana 中設計相應的 Dashboard 進行可視化展示。當這些指標超出正常范圍時,也可以根據閾值設置報警,保證 Kubernetes 集群和服務的穩定運行。
例如:
- CPU 利用率超過 80% 報警
- 內存利用率超過 90% 報警
- 網絡流量 / 磁盤空間突增報警
- Pod / 節點 NotReady 狀態超過 10% 報警
- API Server 請求 LATENCY 超過 200ms 報警
- etcd 節點 Down 報警等等。
這些報警規則的設置需要根據集群大小和服務負載進行評估。
二:Prometheus 的安裝
1:從 Github 克隆項目分支
[root@k8s - master ~]# git clone -b \
release - 0.10 https://github.com/prometheus - operator/kube - prometheus.git
2:安裝 Prometheus Operator
Prometheus Operator 是 CoreOS 開源的項目,它提供了一種 Kubernetes - native 的方式來運行和管理 Prometheus。Prometheus Operator 可以自動創建、配置和管理 Prometheus 實例,并將其與 Kubernetes 中的服務發現機制集成在一起,從而實現對 Kubernetes 集群的自動監控。
Prometheus 和 Prometheus Operator 的區別如下:
Prometheus 是一種開源的監控系統,用于記錄各種指標,并提供查詢接口和告警機制。而 Prometheus Operator 則是一種用于在 Kubernetes 上運行和管理 Prometheus 的解決方案。相比于傳統方式手動部署 Prometheus,Prometheus Operator 可以自動創建、配置和管理 Prometheus 實例,并將其與 Kubernetes 中的服務發現機制集成在一起,大幅簡化了我們的工作量。
安裝方法如下:
署 Prometheus,Prometheus Operator 可以自動創建、配置和管理 Prometheus 實例,并將其與
Kubernetes 中的服務發現機制集成在一起,大幅簡化了我們的工作量。
[root@k8s-master ~]# cd kube-prometheus/
[root@k8s-master ~]# kubectl apply --server-side -f manifests/setup
備注:
--server-side
這個特性主要目標是把邏輯從?kubectl apply?移動到?kube-apiserver?中,這可以修復當前遇到的很多有關所有權沖突的問題。
可以直接通過 API 完成聲明式配置的操作,而無需依賴于特定的?kubectl apply?命令
如果要刪除 Prometheus Operator,可以使用下面的命令
kubectl delete --ignore-not-found=true -f manifests/setup
備注:
prometheus-operator 的作用主要是用來創建 prometheus 的相關資源以及監視與管理它創建出來的資源對象。
3:Operator 容器啟動起來后安裝 Prometheus Stack
[root@k8s-master ~]# kubectl apply --server-side -f manifests/
備注:
刪除 Prometheus Stack
kubectl delete --ignore-not-found=true -f manifests/ -f manifests/setup
備注:
kube-prometheus-stack 是一個全家桶,提供監控告警組件 alert-manager、grafana 等子組件。
5:查看 Prometheus 容器的狀態
root@k8s-master ~]# kubectl get pod -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 79m
alertmanager-main-1 2/2 Running 0 79m
alertmanager-main-2 2/2 Running 0 79m
blackbox-exporter-746c64fd88-prn6l 3/3 Running 0 87m
grafana-5fc7f9f55d-x4gv4 1/1 Running 0 87m
kube-state-metrics-6c8846558c-c6k55 3/3 Running 0 87m
node-exporter-hsr28 2/2 Running 0 87m
node-exporter-tq7vv 2/2 Running 0 87m
node-exporter-zns11 2/2 Running 0 87m
prometheus-adapter-6455646bdc-991gh 1/1 Running 0 87m
prometheus-adapter-6455646bdc-nxh5z 1/1 Running 0 87m
prometheus-k8s-0 2/2 Running 0 79m
prometheus-k8s-1 2/2 Running 0 79m
prometheus-operator-f59c8b954-hmtx8 2/2 Running 0 87m6:查看 servicemonitors
servicemonitors 定義了如何監控一組動態的服務,使用標簽選擇來定義哪些 Service 被選擇進行監控。這可以讓團隊制定一個如何暴露監控指標的規范,然后按照這些規范自動發現新的服務,而無需重新配置。
為了讓 Prometheus 監控 Kubernetes 內的任何應用,需要存在一個 Endpoints 對象,Endpoints 對象本質上是 IP 地址的列表,通常 Endpoints 對象是由 Service 對象來自動填充的,Service 對象通過標簽選擇器匹配 Pod,并將其添加到 Endpoints 對象中。一個 Service 可以暴露一個或多個端口,這些端口由多個 Endpoints 列表支持,這些端點一般情況下都是指向一個 Pod。
Prometheus Operator 引入的這個 ServiceMonitor 對象就會發現這些 Endpoints 對象,并配置 Prometheus 監控這些 Pod。ServiceMonitorSpec 的 endpoints 部分就是用于配置這些 Endpoints 的哪些端口將被 scrape 指標的。
Prometheus Operator 使用 ServiceMonitor 管理監控配置。
ServiceMonitor 的創建方法如下:
[root@k8s-master ~]# kubectl get servicemonitors -A
NAMESPACE NAME AGE
monitoring alertmanager-main 2m9s
monitoring blackbox-exporter 2m8s
monitoring coredns 2m6s
monitoring grafana 2m7s
monitoring kube-apiserver 2m6s
monitoring kube-controller-manager 2m6s
monitoring kube-scheduler 2m6s
monitoring kube-state-metrics 2m7s
monitoring kubelet 2m6s
monitoring node-exporter 2m6s
monitoring prometheus-adapter 2m5s
monitoring prometheus-k8s 2m6s
monitoring prometheus-operator 2m5s6:修改 grafana 的 service 的類型為 NodePort
注意:默認的 type 為 ClusterIP 的類型
[root@k8s-master ~]# kubectl edit svc grafana -n monitoring
spec:clusterIP: 10.107.64.140clusterIPs:- 10.107.64.140externalTrafficPolicy: ClusterinternalTrafficPolicy: ClusteripFamilies:- IPv4ipFamilyPolicy: SingleStackports:- name: httpnodePort: 32082port: 3000protocol: TCPtargetPort: httpselector:app.kubernetes.io/component: grafanaapp.kubernetes.io/name: grafanaapp.kubernetes.io/part-of: kube-prometheussessionAffinity: Nonetype: NodePort
status:loadBalancer: {}[root@k8s-master ~]# kubectl get svc grafana -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
grafana NodePort 10.99.26.98 <none> 3000:32082/TCP 28m7:訪問 grafana
http://<k8S 集群任意節點的 IP>:32082
注意:
默認的登錄賬號密碼為 admin/admin,第一次登陸會提示修改密碼,不想修改可以點擊 skip 跳過
8:修改 Prometheus 的 Service 類型
將 type 類型修改為 NodePort,默認的是 ClusterIP
[root@k8s-master ~]# kubectl edit svc prometheus-k8s -n monitoring
apiVersion: v1
kind: Service
metadata:creationTimestamp: "2023-04-05T03:49:40Z"labels:app.kubernetes.io/component: prometheusapp.kubernetes.io/instance: k8sapp.kubernetes.io/name: prometheusapp.kubernetes.io/part-of: kube-prometheusapp.kubernetes.io/version: 2.32.1name: prometheus-k8snamespace: monitoringresourceVersion: "4615"
uid: 9bdba2d2-a7e6-4bf2-9e3d-355d5e3de646
spec:clusterIP: 10.100.14.27clusterIPs:- 10.100.14.27externalTrafficPolicy: ClusterinternalTrafficPolicy: ClusteripFamilies:- IPv4ipFamilyPolicy: SingleStackports:- name: webnodePort: 32370port: 9090protocol: TCPtargetPort: web- name: reloader-webnodePort: 31480port: 8080protocol: TCPtargetPort: reloader-webselector:app.kubernetes.io/component: prometheusapp.kubernetes.io/instance: k8sapp.kubernetes.io/name: prometheusapp.kubernetes.io/part-of: kube-prometheussessionAffinity: clientIP: timeoutSeconds: 10800type: NodePort
status:loadBalancer: {}[root@k8s-master ~]# kubectl get svc -n monitoring prometheus-k8s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus-k8s NodePort 10.105.187.25 <none> 9090:32370/TCP 33m9:訪問 Prometheus
http://<k8S 集群任意節點的 IP>:32370
10:查看監控目標
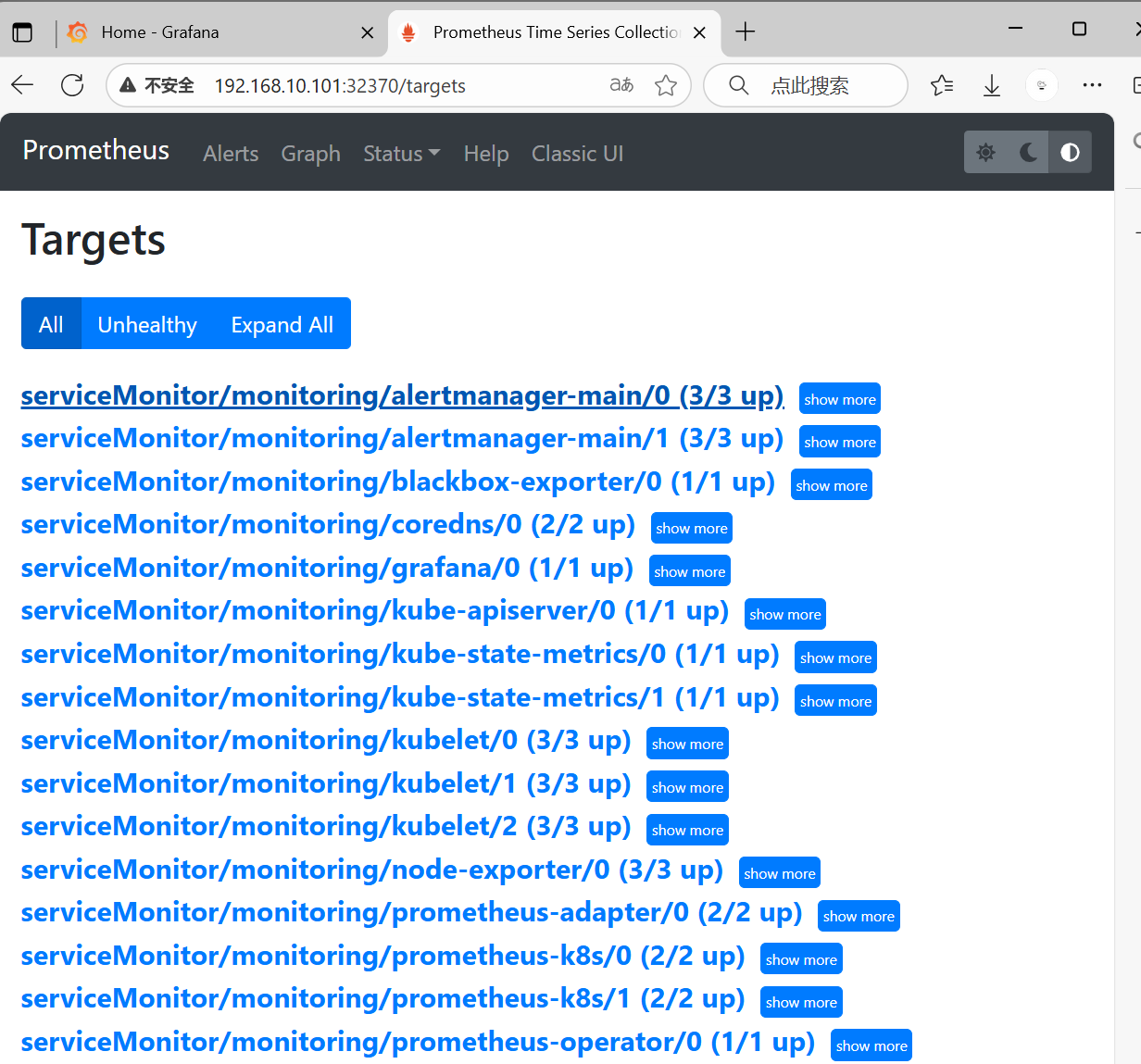
備注:
在 Prometheus 中一條告警規則有三個狀態:
- inactive:還未被觸發;
- pending:已經觸發,但是還未達到 for 設定的時間;
- firing:觸發且達到設定時間。
三:配置 Grafana Dashbord
1:添加數據源
注意:在本案例中,grafana 已經有了 Prometheus 的數據源,(1)、(2)、(3)步驟可以省去
(1)添加數據源
單擊 Dashboards 按鈕(四方塊圖標),選擇 “Add your first data source”
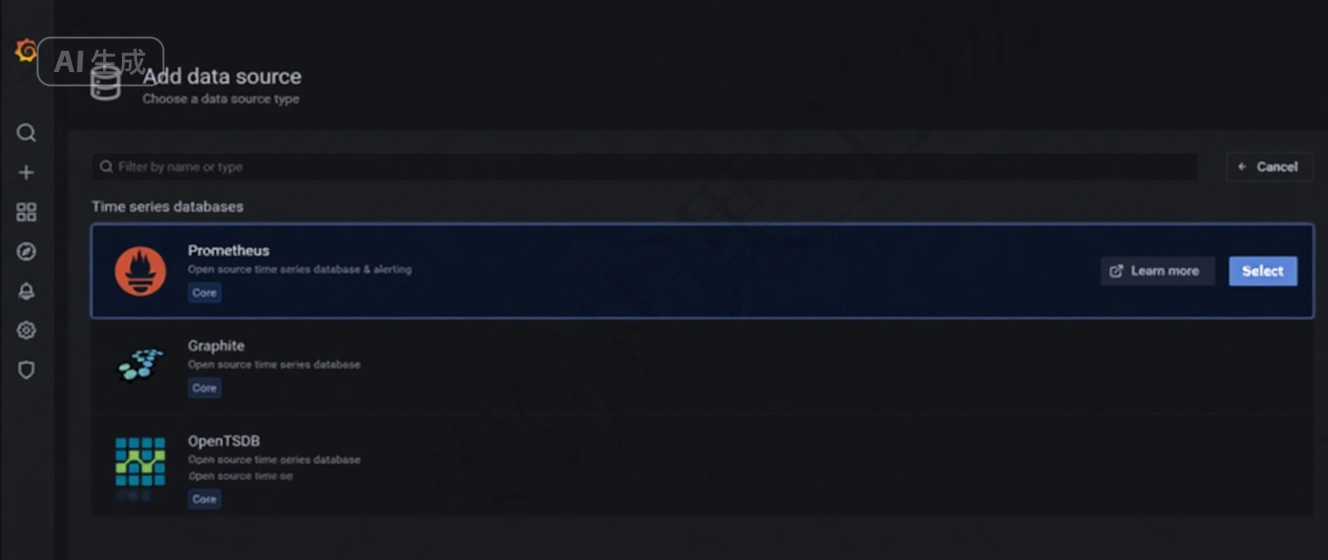
(2)數據源選擇 Prometheus
鼠標放到 Prometheus 上,選擇最右側的 “Select” 按鈕
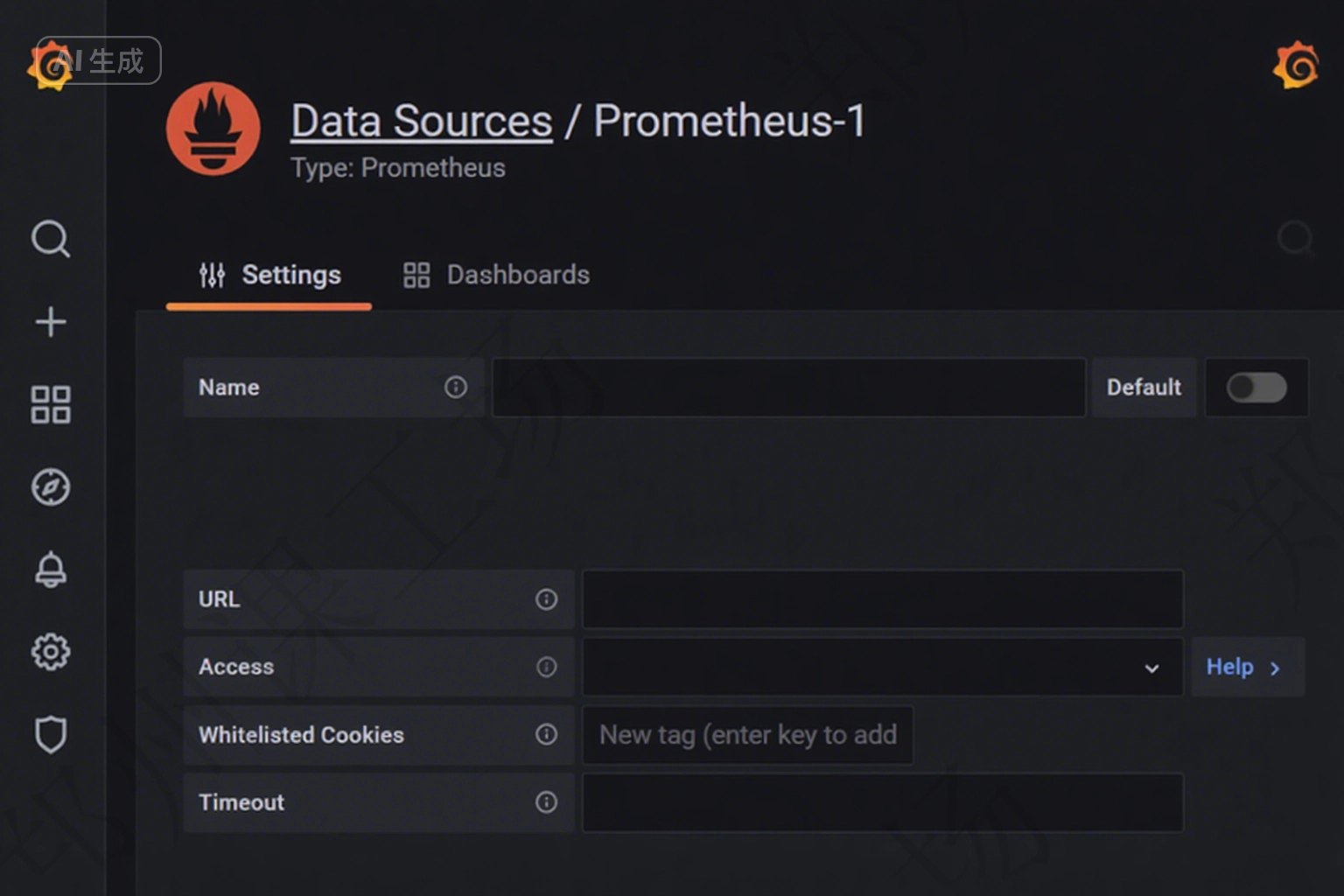
(3)配置數據源
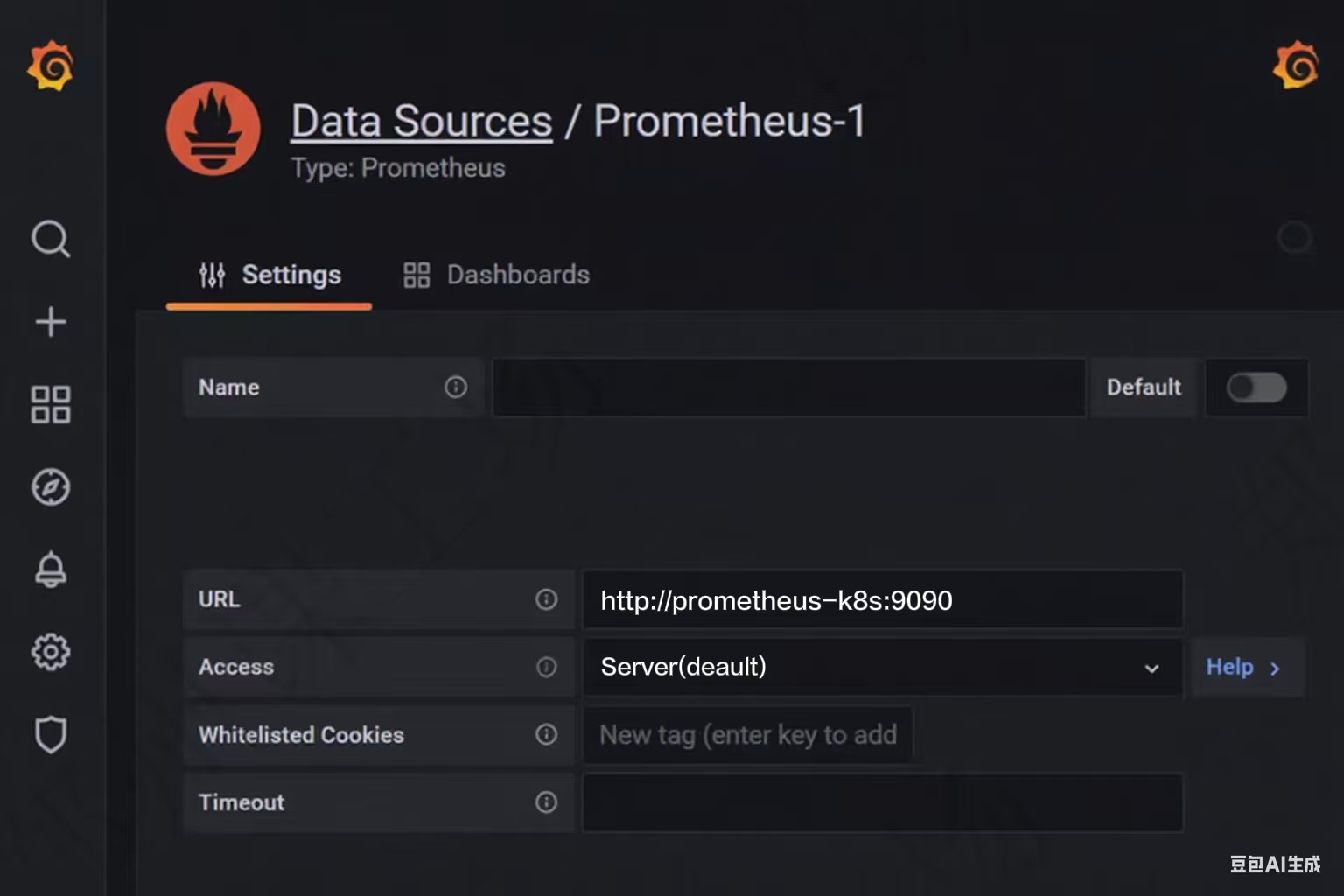
HTTP 配置項下的 URL 填寫 “http://prometheus-k8s:9090”,這里的 prometheus 是 K8s 集群內的 Service 名,也可以使用 IP 地址代替
然后點擊頁面底部的 “Save & Test” 按鈕,保存并確定測試通過。
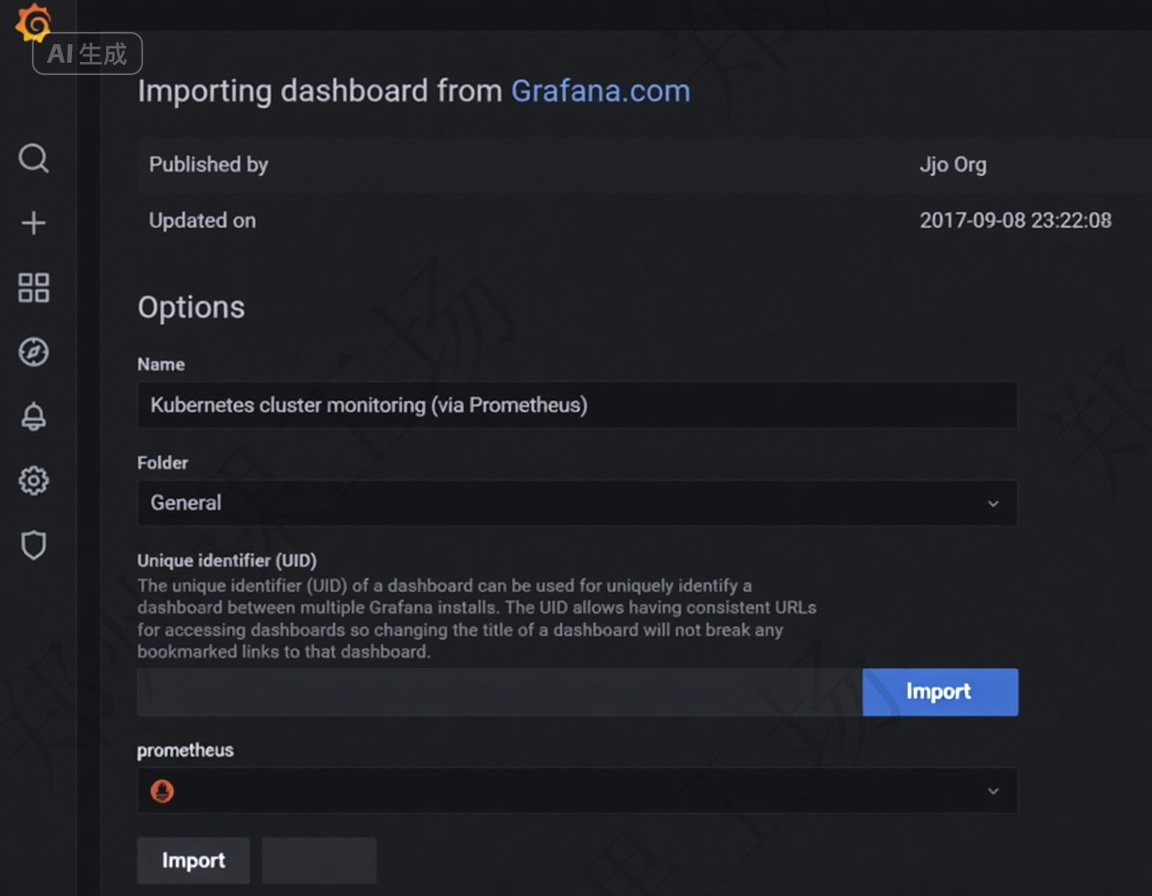
2:通過 Node id 導入監控模板
單擊首頁左側搜索框下面的 + 的按鈕。選擇 import 按鈕,輸入監控模板 id:13105
單擊 Load 按鈕加載即可,最后單擊 Import 按鈕導入
完成上述步驟后,可以看到Node節點在Dashbord監控頁面展示情況。
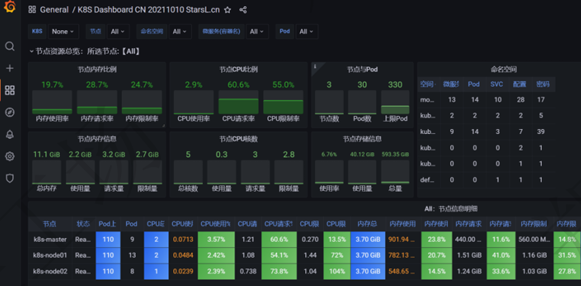
其他模板:
可以去官網查找更豐富的模板
Grafana dashboards | Grafana Labs
常見的模板有
- Kubernetes Cluster
? ? ? ?7249
-
Docker Registry
9621 -
Docker and system monitoring
893
-
K8S for Prometheus Dashboard 20211010 中文版
13105 -
Kubernetes Pods
4686 -
Linux Stats with Node Exporter
14731
四:監控 MySQL 數據庫
在 Prometheus 的監控體系中,符合云原生設計理念的應用通常自帶一個 Metrics 接口,這使得 Prometheus 能夠直接抓取到應用的監控數據。然而,對于非云原生應用(如 MySQL、Redis、Kafka 等),由于它們并未原生暴露 Prometheus 所需的 Metrics 接口,因此我們需要借助 Exporter 來實現數據的采集和暴露。本案例將以 MySQL 為例,詳細介紹如何通過 Exporter 實現對非云原生應用的監控,并將其集成到 Prometheus 監控體系中。
1:在 Kubernetes 中安裝一個 mysql
[root@k8s-master ~]# kubectl create deploy mysql --image=mysql:5.7.23
2:設置 mysql 密碼
[root@k8s-master ~]# kubectl set env deploy/mysql MYSQL_ROOT_PASSWORD=pwd123
備注:需要先設置密碼,mysql 的 pod 狀態才能正常
3:查看 pod
[root@k8s-master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
mysql-58dd9c4df4-17fgd 1/1 Running 0 2m53s
4:創建 service,暴露 mysql 端口
[root@k8s-master ~]# kubectl expose deployment mysql --type NodePort --port=3306
查看 service:
[root@k8s-master ~]# kubectl get svc -l app=mysql
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
mysql NodePort 10.96.116.184 <none> 3306:31152/TCP 37s 5:訪問測試
[root@k8s-master ~]# dnf -y install mysql
# IP 修改為 K8S 節點任意節點的 IP
[root@k8s-master ~]# mysql -u root -ppwd123 -h 192.168.207.137 -P 31152
6:設置權限
[root@k8s-master ~]# grant all on *.* to exporter@'%' identified by 'exporter'; 7:配置 mysql exporter 采集 mysql 監控文件
[root@k8s-master ~]# cat mysql-exporter.yaml
apiVersion: apps/v1
kind: Deployment
metadata: name: mysql-exporter namespace: monitoring
spec: replicas: 1 selector: matchLabels: k8s-app: mysql-exporter template: metadata: labels: k8s-app: mysql-exporter spec: containers: - name: mysql-exporter image: registry.cn-beijing.aliyuncs.com/dotbalo/mysqld-exporter env: - name: DATA_SOURCE_NAME value: "exporter:exporter@mysql.default:3306/"imagePullPolicy: IfNotPresentports:- containerPort: 9104
---
apiVersion: v1
kind: Service
metadata:name: mysql-exporternamespace: monitoringlabels:k8s-app: mysql-exporter
spec:type: ClusterIPselector:k8s-app: mysql-exporterports:- name: apiport: 9104protocol: TCP1. 創建?mysql - exporter?資源
[root@k8s - master ~]# kubectl create -f mysql - exporter.yaml
2. 查看?mysql - exporter?資源狀態
[root@k8s - master ~]# kubectl get -f mysql - exporter.yaml
NAME READY UP - TO - DATE AVAILABLE AGE
deployment.apps/mysql - exporter 1/1 1 1 84sNAME TYPE CLUSTER - IP EXTERNAL - IP PORT(S) AGE
service/mysql - exporter ClusterIP 10.109.16.46 <none> 9104/TCP 84s
3. 測試獲取?metrics?數據
% Total % Received % Xferd Average Speed Time Time Time CurrentDload Upload Total Spent Left Speed
100 130k 0 130k 0 0 2923k 0 --:--:-- --:--:-- --:--:-- 2973k
promhttp_metric_handler_requests_total{code="503"} 0
9:配置ServiceMonitor
[root@k8s-master ~]# cat mysql-sm.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:name: mysql-exporternamespace: monitoringlabels:k8s-app: mysql-exporternamespace: monitoring
spec:jobLabel: k8s-appendpoints:- port: apiinterval: 30sscheme: httpselector:matchLabels:k8s-app: mysql-exporter
namespaceSelector:matchNames:- monitoring10:創建這個 ServiceMonitor
[root@k8s-master ~]# kubectl create -f mysql-sm.yaml
11:在 prometheus 查看監控目標中是否出現了 mysql
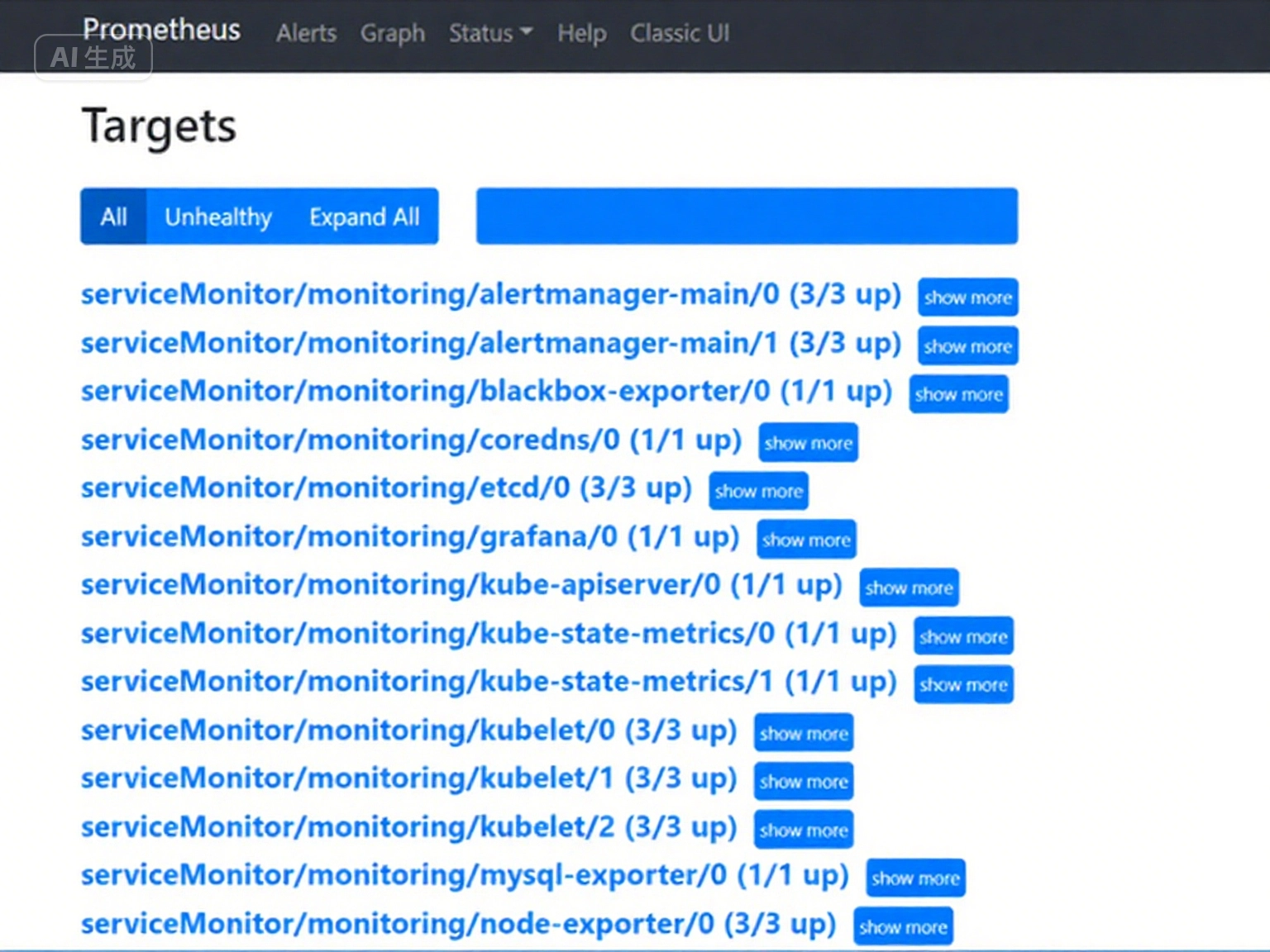
12:在 grafana 中添加 mysql 監控模板
模板 ID:6239
五:對接釘釘報警
首先在釘釘群里面添加一個自定義機器人
為釘釘機器人添加關鍵字:FIRING
1:部署 DingTalk
DingTalk(釘釘)是阿里巴巴集團開發的一款企業級通訊和協作平臺,旨在提升工作效率和團隊協作能力。它集成了即時通訊、視頻會議、任務管理、日程安排、文件共享等多種功能,適用于企業內部的溝通與協作。DingTalk 支持多平臺使用,包括移動設備(iOS、Android)和桌面端(Windows、macOS),并且提供了豐富的 API 接口,方便與企業現有的系統進行集成。
下載地址:
https://github.com/timonwong/prometheus - webhook - dingtalk/releases/download/v2.0.0/prometheus - webhook - dingtalk - 2.0.0.linux - amd64.tar.gz 在任意節點部署都行,本文是在 K8S 的 master 節點部署
tar -xf prometheus - webhook - dingtalk - 2.0.0.linux - amd64.tar.gz
mv prometheus - webhook - dingtalk - 2.0.0.linux - amd64 /usr2:修改配置文件
cd /usr/local/dingtalk
mv config.example.yml config.yml
vi config.yml
## Request timeout
# timeout: 5s ## Uncomment following line in order to write template from scratch (be careful)
#no_builtin_template: true ## Customizable templates path
#templates:
# - contrib/templates/legacy/template.tmpl ## You can also override default template using `default_message`
## The following example to use the 'legacy' template from v0.3.0
#default_message:
# title: '{{ template "legacy.title" . }}'
# text: '{{ template "legacy.content" . }}' ## Targets, previously was known as "profiles"
targets: webhook1: url:
yaml
targets:webhook1:url: https://oapi.dingtalk.com/robot/send?access_token=6d07ddc122c69d0bb23a6212f2378b4da45c750ac09a2910f653cd5d324556cd# secret for signaturesecret: SEC00000000000000000000webhook2:url: https://oapi.dingtalk.com/robot/send?access_token=6d07ddc122c69d0bb23a6212f2378b4da45c750ac09a2910f653cd5d324556cdwebhook_legacy:url: https://oapi.dingtalk.com/robot/send?access_token=6d07ddc122c69d0bb23a6212f2378b4da45c750ac09a2910f653cd5d324556cd# Customize template contentmessage:# Use legacy templatetitle: '{{ template "legacy.title" . }}'text: '{{ template "legacy.content" . }}'webhook_mention_all:url: https://oapi.dingtalk.com/robot/send?access_token=6d07ddc122c69d0bb23a6212f2378b4da45c750ac09a2910f653cd5d324556cdmention:all: true
webhook_mention_users:url: https://oapi.dingtalk.com/robot/send?access_token=6d07ddc122c69d0bb23a6212f2378b4da45c750ac09a2910f653cd5d324556cdmention:mobiles: ['156xxxx8827', '189xxxx8325']備注:
江紅色部分替換成你的機器人的webhook
3:啟動服務
cat > /etc/systemd/system/prometheus - webhook - dingtalk.service << 'EOF'
[Unit]
Description=Prometheus Webhook DingTalk
After=network.target[Service]
User=root
Group=root
WorkingDirectory=/usr/local/dingtalk
ExecStart=/usr/local/dingtalk/prometheus - webhook - dingtalk
Restart=always
RestartSec=5
Environment="CONFIG_FILE=/usr/local/dingtalk/config.yml"[Install]
WantedBy=multi - user.target
EOFsudo systemctl daemon - reload
sudo systemctl start prometheus - webhook - dingtalk
sudo systemctl status prometheus - webhook - dingtalk[root@k8s - master ~]# ss -nlpt | grep 8060LISTEN 0 4096 *:8060 *:*
users:((("prometheus-wehb",pid=1990,fd=3)))4:配置Alertmanager
cd /root/kube-prometheus/manifests/
vi alertmanager-secret.yaml
# 注意 IP 地址修改為部署 DingTalk 節點的 IP
# 文件全部內容如下:
apiVersion: v1
kind: Secret
metadata:labels:app.kubernetes.io/component: alert-routerapp.kubernetes.io/instance: mainapp.kubernetes.io/name: alertmanagerapp.kubernetes.io/part-of: kube-prometheusapp.kubernetes.io/version: 0.23.0name: alertmanager-mainnamespace: monitoring
stringData:alertmanager.yaml: |-"global":"resolve_timeout": "5m""inhibit_rules":- "equal":- "namespace"- "alertname""source_matchers":"global":"resolve_timeout": "5m""inhibit_rules":- "equal":- "namespace"- "alertname""source_matchers":- "severity = critical""target_matchers":- "severity =~ info"- "equal":- "namespace"- "alertname""source_matchers":- "severity = info""target_matchers":- "severity = info""receivers":- "name": "webhook""webhook_configs":- "url": "http://192.168.207.137:8060/dingtalk/webhoo""send_resolved": true"route":"group_by":- "namespace""group_interval": "50s""group_wait": "30s""receiver": "webhook""repeat_interval": "1m""routes":- "matchers":- "alertname = Watchdog""receiver": "webhook" - "matchers":- "severity = critical""receiver": "webhook"- "matchers":- "alertname = TargetDown""receiver": "webhook"
#加載配置到 Alertmanager
bash
kubectl replace -f alertmanager-secret.yaml
#修改 Alertmanager 的 Service 類型為 NodePort
bash
kubectl edit svc -n monitoring alertmanager-main
#查看監聽端口
bash
kubectl get svc -n monitoring alertmanager-main
plaintext
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-main NodePort 10.104.241.78 <none> 5:訪問 Alertmanager 頁面
http:///<K8S 集群任意節點的 IP>:30586備注
Prometheus Alert 告警狀態有三種狀態:Inactive、Pending、Firing。
Inactive:非活動狀態,表示正在監控,但還未觸發任何警報。
Pending:表示警報需觸發,因警報可分組、壓抑 / 抑制或靜默,需等待驗證;驗證通過則轉?Firing。
Firing:警報發至?AlertManager,按配置發給接收者;警報解除則轉回?Inactive,循環往復。
若修改?alertmanager-secret.yaml,可重建:
kubectl delete -f alertmanager-secret.yaml
kubectl create -f alertmanager-secret.yaml
6:測試
可停止剛運行的 MySQL(通過設副本數量為 0 實現 )。
kubectl scale deployment mysql --replicas=0 然后等待是否會進行釘釘報警





登錄注冊 - Compose)
)


)






)


