強烈推薦!臺大李宏毅自注意力機制和Transformer詳解!_嗶哩嗶哩_bilibili
目錄
1. 詞嵌入&問題情形
2. self-attention?自注意力機制
3. 自注意力的變形
3.1 多頭注意力(multi-head)
3.2 位置編碼
3.3 截斷自注意力(truncated)
3.4 與CNN對比
3.5 與RNN對比
4. Transformer架構
4.1 編碼器?Encoder
4.2?自回歸解碼器
4.3 非自回歸解碼器
5. Transformer訓練過程與技巧
1. 詞嵌入&問題情形
詞嵌入(word embedding) 用一個有語義信息的向量表示每個詞,意思相關的會靠的近
詞嵌入的訓練基于分布式假說:"單詞的語義由其上下文決定"。通過分析單詞在文本中的共現模式,模型學習用向量表示單詞的語義和語法特征。
比如用“開心”的場景 都可以替換為“高興”? 這兩個詞的上下文很像 說明他們語義很像;
“蘋果”的上下文 和“梨”的上下文也很像,可能他們是同類型的
情形1:輸入等于輸出 如給一個句子輸出每個單詞的詞性(動詞名詞這些)都一一對應
情形2:多對一 給一段文字打標簽 輸出這段話是正面還是負面的
情形3:Seq2Seq序列到序列 如語言翻譯 語音識別,輸入的字符長度無法知道輸出的字符長度
聊天機器人:我和他說話 輸入一個序列? 機器人返回一個序列
QA問答問題:所有任務都可以轉化為 給材料給任務序列,返回答案序列
給文章打一個標簽是 多對一問題;給文章打多個標簽 就是多對多問題
2. self-attention?自注意力機制
 ? 三個向量&三個步驟
? 三個向量&三個步驟
![]() ? ? ?
? ? ? ? ??
? ??![]()
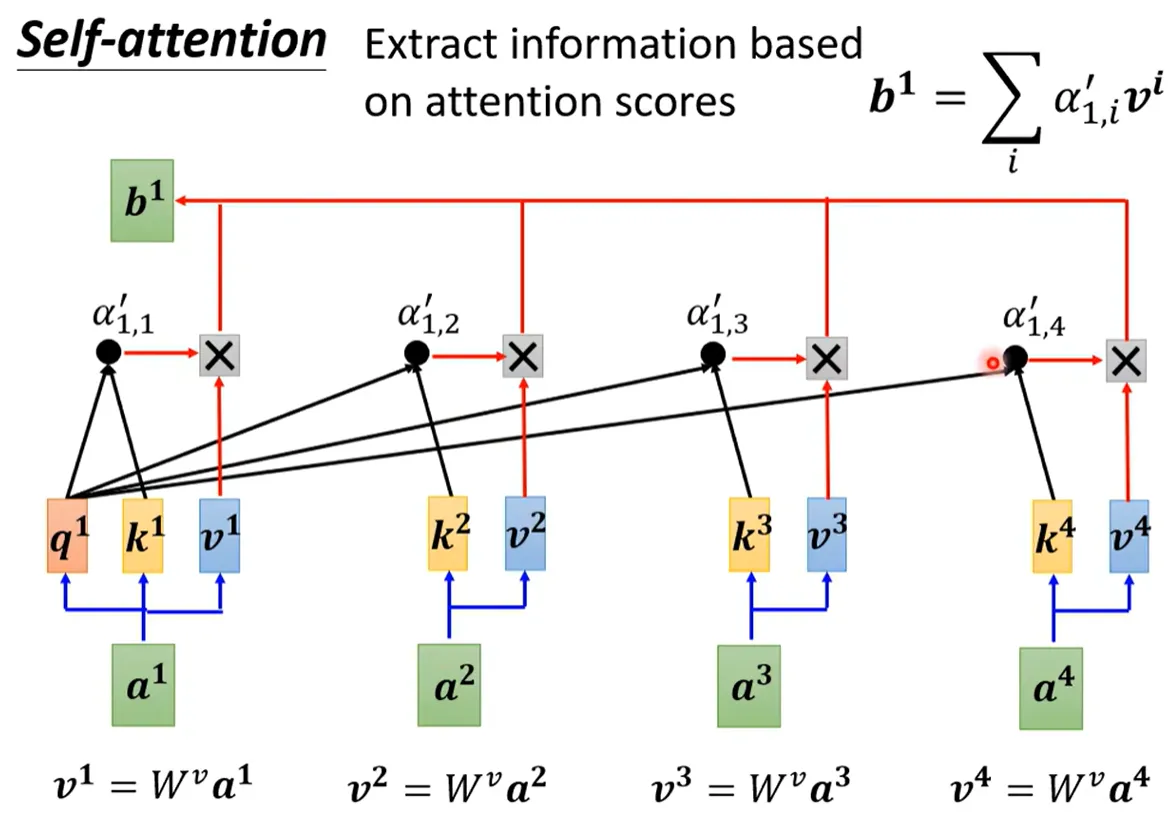
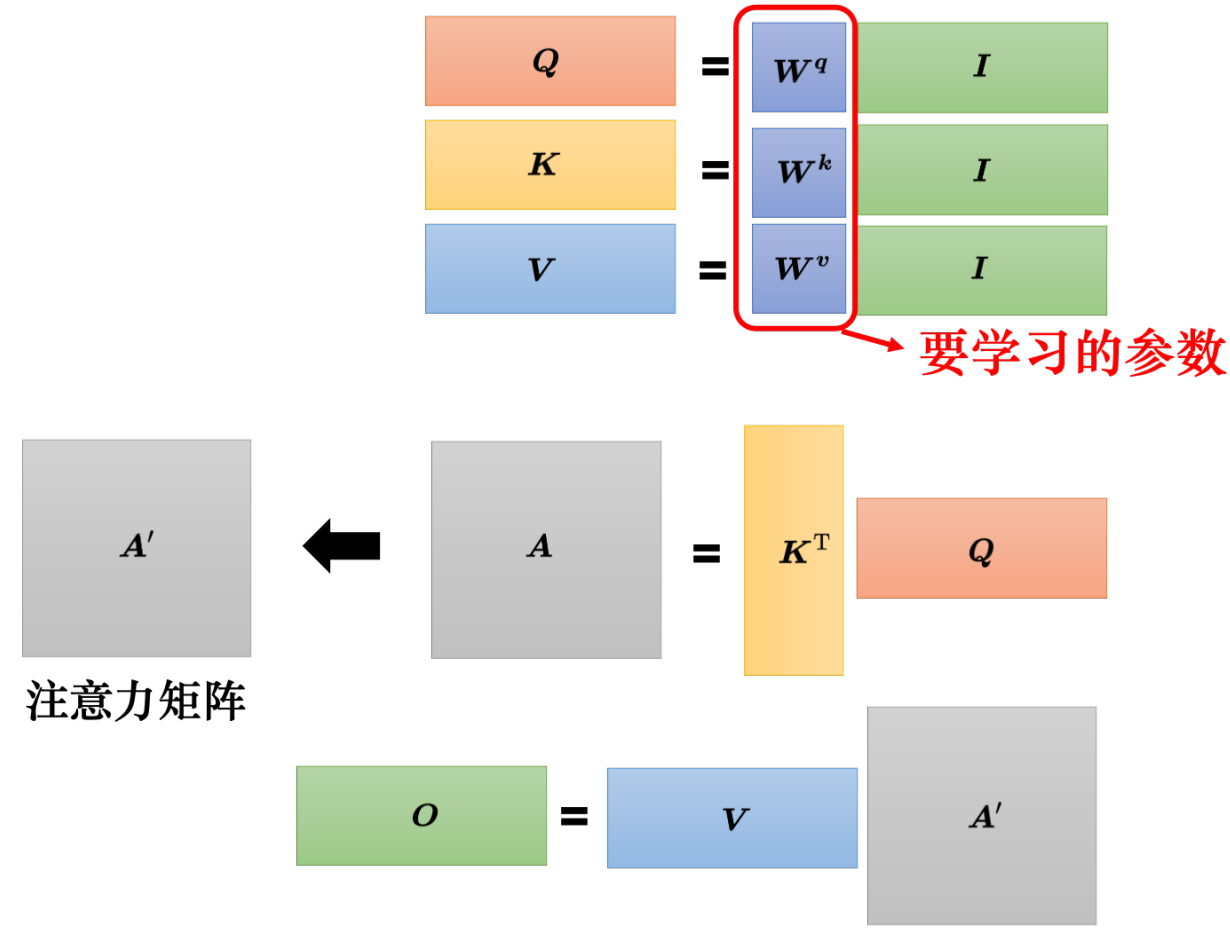
Q K V 三個向量需要 X分別乘以矩陣W;這三個矩陣W 需要訓練得到
我要問位置1的注意力值是多少,就拿Q1 和所有位置的K相乘后softmax 得到A'
再用A'V 得到自注意力?b1。? ? ? 用矩陣乘法可以寫成
3. 自注意力的變形
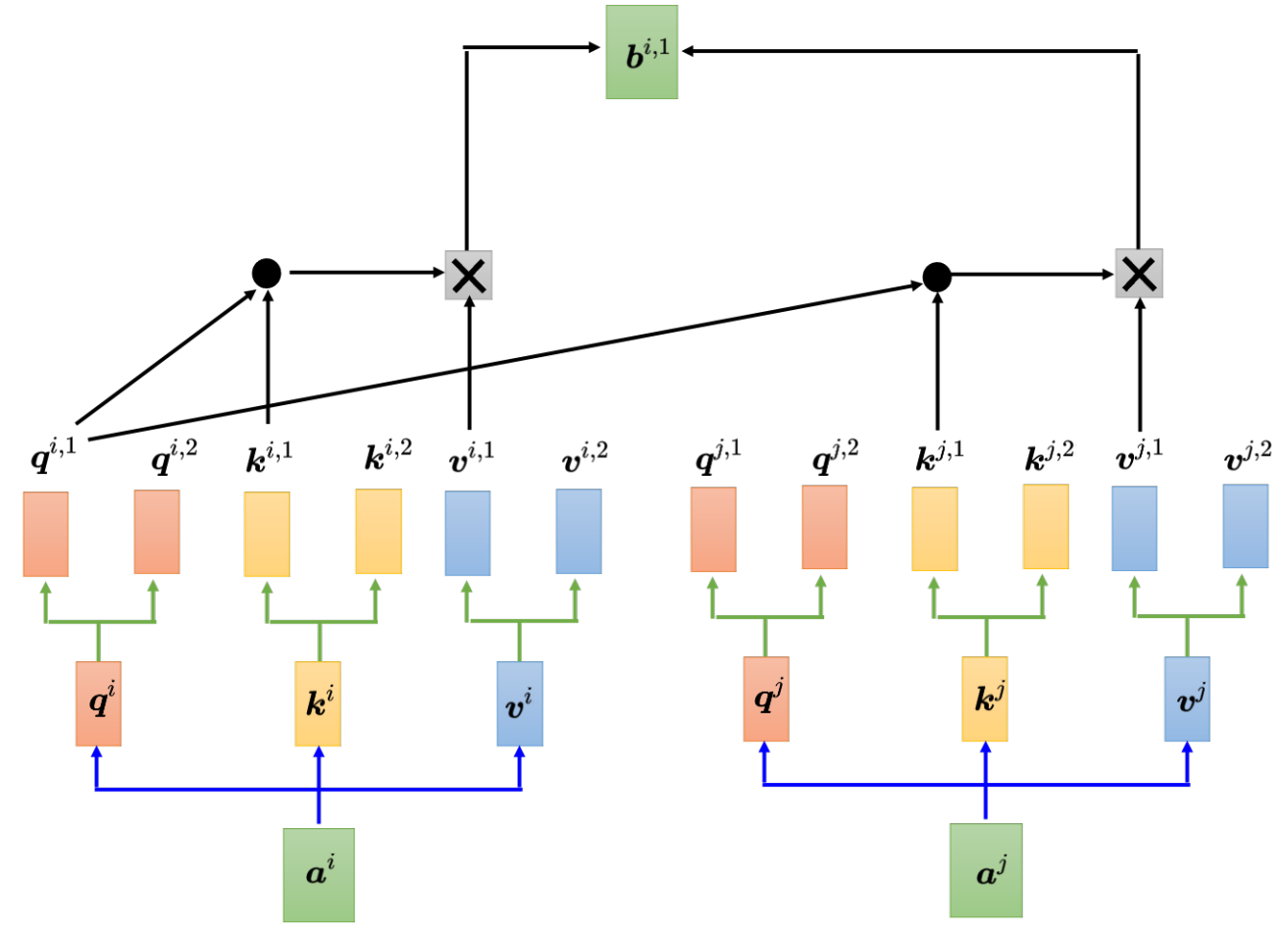
3.1 多頭注意力(multi-head)
每個位置 多個q k v,類似CNN中的通道提取不同視覺特征,提取多種語義/語法特征
捕捉更多樣、復雜的依賴關系。而且因為可以GPU并行計算 效率相近但建模能力顯著提升
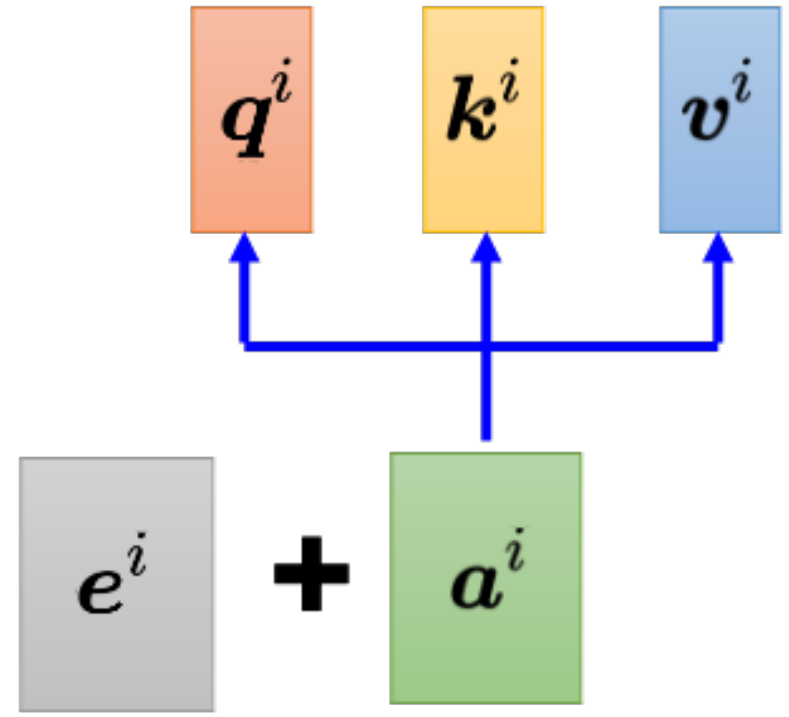
3.2 位置編碼
對于自注意力而言 注意力值與位置無關。但是像一段話中 詞的位置也是很重要的信息。
比如說句首的詞是動詞的概率特別小。? ? ? 實現方法為 在每個位置加一個專屬的e。
3.3 截斷自注意力(truncated)
原來的自注意力 是和整句話的所有發生關系。
如果一段話太長太長 可以設置一個范圍,只看這個范圍前后的。
?
3.4 與CNN對比
CNN 需要人為設定 濾波器、感受野;每個神經元僅考慮感受野內的信息。
自注意力 是自己去學習像素之間的關系,考慮身邊哪些像素是相關的。
所以CNN可看做特殊的自注意力機制,作為有限制的模型,適合數據較小的時候使用。
而自注意力更靈活,需要更多的數據否則容易過擬合。
3.5 與RNN對比
1) 自注意力看全局,RNN只看左邊的。Bi-RNN雙向版本也看全局但仍有差異,因為自注意力在最右邊?看最左邊的詞可以一步到位,而RNN需要從最左邊一步一步將記憶(隱狀態)傳遞過來。
2) 自注意力可以并行 而RNN需要傳遞串行 所以自注意力更高效。
自注意力也可運用在圖的問題上 每個節點 連邊就是需要有關系? 連著邊才計算注意力分數
4. Transformer架構
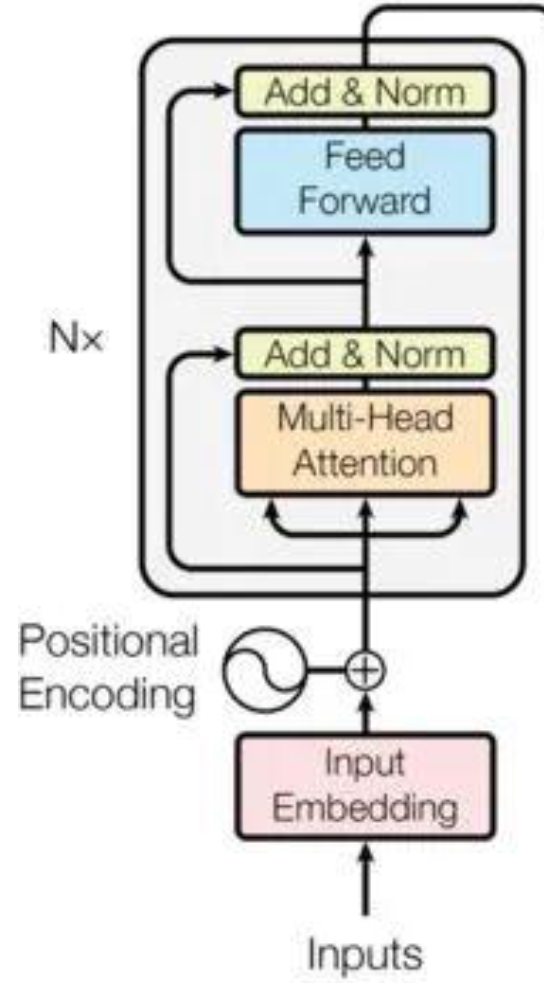
4.1 編碼器?Encoder
add&norm加入殘差連接的設計,對a自注意力算出b之后 b+a再層歸一化
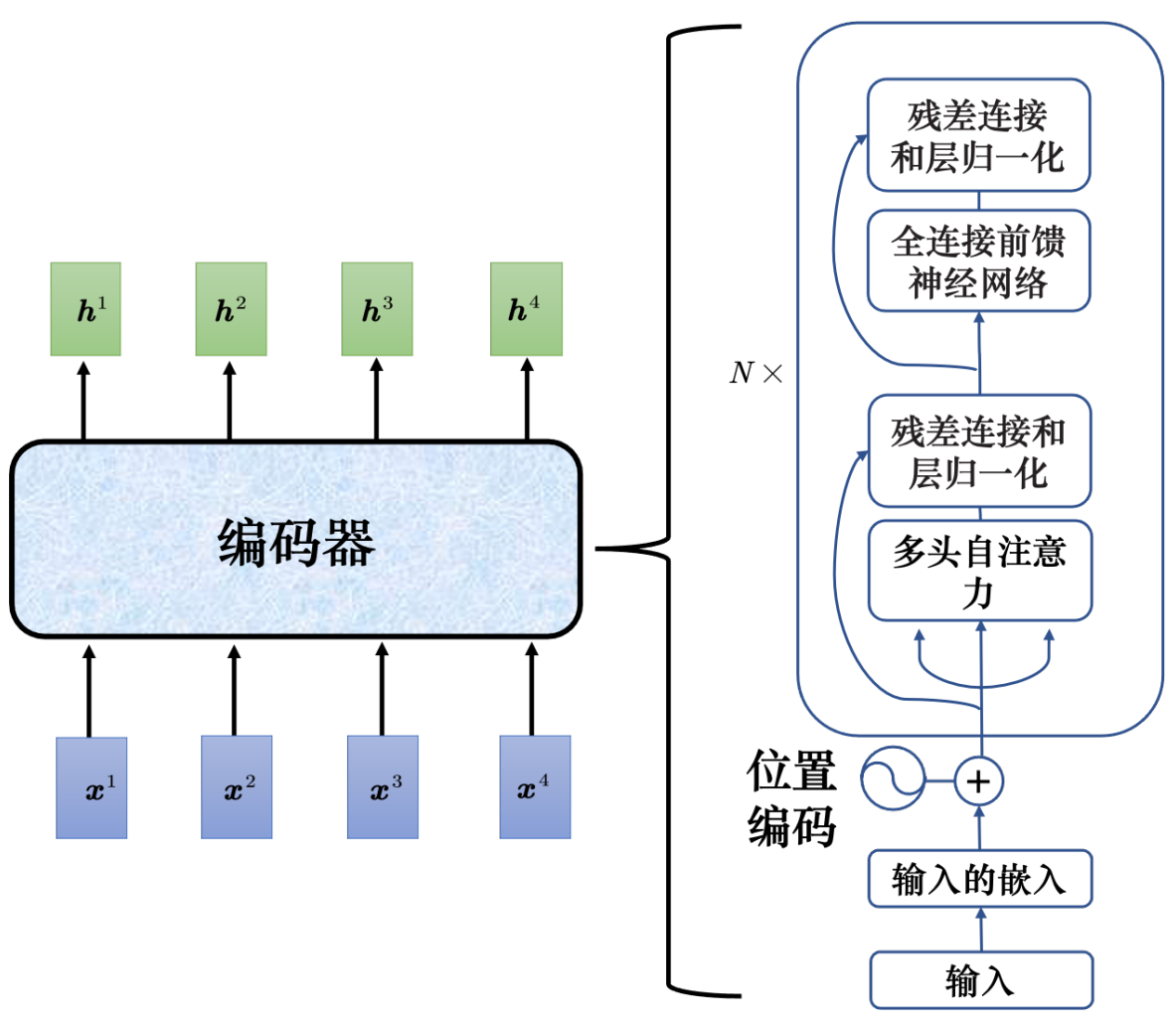 ? ?
? ?
4.2?自回歸解碼器
先輸入 <BOS>,輸出 w1,再把 w1 當做輸入,再輸出 w2,直到輸出 <EOS> 為止。
除了常規字符外還要 開始字符<BOS>? 結束字符<EOS> 代表句子的開始和結束。
解碼器就是在編碼器的基礎上 層的開始加上掩碼自注意力(masked 因為輸出是一個一個輸出的 阻止每個位置選擇其后面的輸入信息)
最終目的是要輸出下一個詞 就對結果向量進行線性映射+softmax 找最大概率的那個
解碼器多頭注意力那里 是編碼器和解碼器的橋梁;K和V來自編碼器,Q來自解碼器的上一層
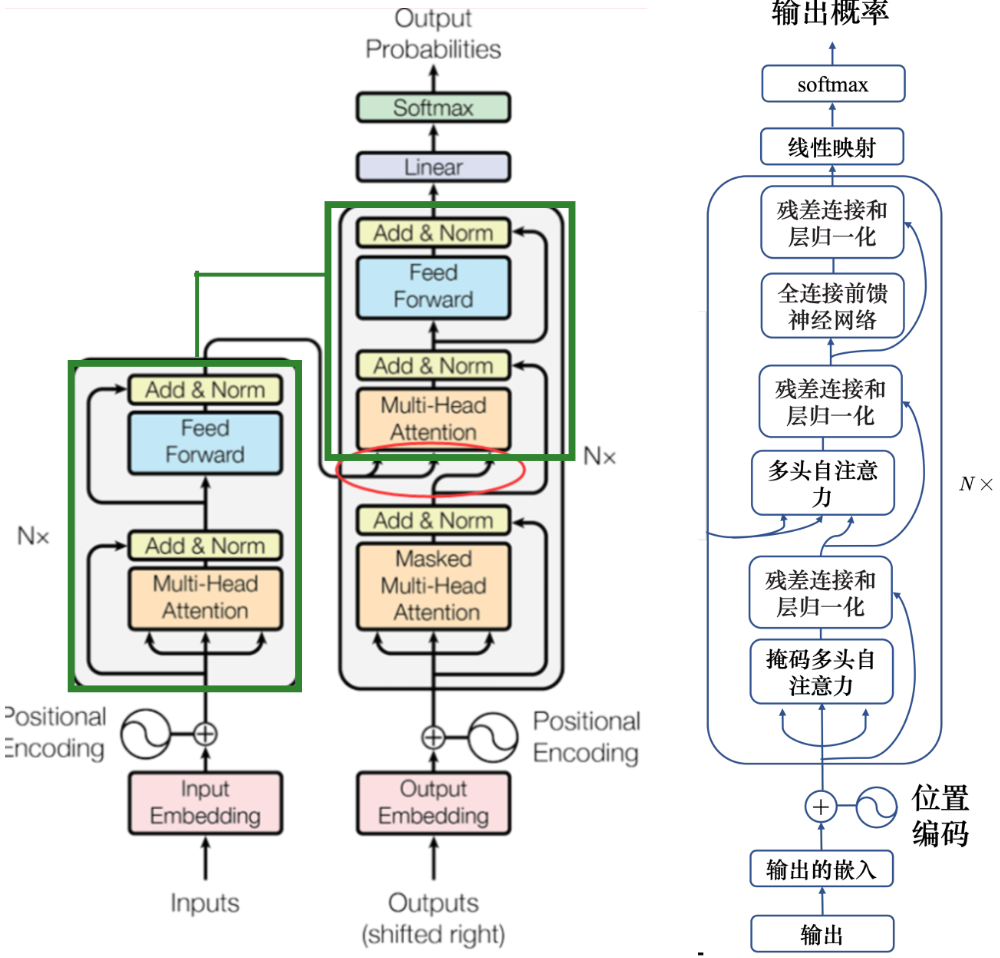
4.3 非自回歸解碼器
非自回歸不是一次產生一個字,而是一次把整個句子都產生出來;給多少<BOS> 就輸出多少字
優勢1是可以做到并行輸出 效率更高,但性能會差一些。
優勢2是可以控制輸出的長度。
5. Transformer訓練過程與技巧
實際與期望結果向量的交叉熵(比如輸入一段語音 期望輸出“機器學習<EOS>”)
訓練時用交叉熵,評估翻譯結果時的標準是?解碼器先產生一個完整的句子,再去跟正確的答案一整句做比較,兩個句子算出 BLEU 分數(訓練時不用BLEU因為計算復雜 且無法做微分)
1. 復制機制:解碼器直接從輸入中復制一些有用的東西
比如對話問題中,用戶給的比較生僻的輸入可以在回答中直接復制原問題里的詞
比如段落摘要問題中,很多原文的詞都可以直接復制信息
2. 引導注意力:當我們對一個問題有一定理解的時候 可以要求機器做注意力時以一定方向
如語音提取時讓它從左到右效果更好 如果順序胡亂結果就會有問題
3.?束搜索: 根據softmax的概率一個一個輸出 這是貪心的思想,再往后延伸效果不一定好
如果要后面的效果好 窮舉搜索 再分支往后看 分叉太多情況太多會導致也往后看不了多少
beam search束搜索 用于自回歸生成任務(即每一步依賴前一步的輸出)
維護一個有限的候選序列集合?平衡計算復雜度和結果質量,
在生成序列的每一步,不保留所有可能的候選,而是僅保留概率最高的 K 個。
4. 加入噪聲/隨機性:
訓練時加噪聲,讓機器看過更多不同的可能性,讓模型比較魯棒,比較能夠對抗它在測試的時候沒有看過的狀況。? ?
測試的時候加一些噪聲,用正常的解碼的方法產生出來的聲音聽不太出來是人聲,也不一定是最好的結果,產生比較好的聲音需要一些隨機性。
5. 計劃采樣(訓練集加入錯誤 提高容錯)
曝光偏差:訓練時看到的是完全正確的 測試時解碼器看到自己的輸出 所以會看到一些錯誤信息。
如果看到錯誤信息 后面會出現不堪設想的一步錯步步錯,
比如“機器學習”的qi 輸出成了 “氣”? 因為是串行一個一個生成的 所以后續跟著錯很多。
所以我們考慮在訓練集中 加一些錯誤的信息 期望使得它看到錯誤的信息 也能有一定容錯。





棧和隊列)

隨機數與隨機顏色)



)







