文章目錄
- 引言:AI大模型的新時代
- 一、模型架構與技術生態對比
- 1. 文心大模型4.5系列
- 2. DeepSeek
- 3. 通義千問(Qwen 3.0)
- 二、語言理解能力實測
- 2.1 情感分析測試
- 2.1.1 文心一言的表現
- 2.1.2 DeepSeek的表現
- 2.1.3 Qwen 3.0的表現
- 2.1.4 測試結果分析
- 2.2 文本分類測試
- 2.2.1 文心一言的表現
- 2.2.2 DeepSeek的表現
- 2.2.3 Qwen 3.0的表現
- 2.2.4 測試結果分析
- 2.3 語義匹配測試
- 2.3.1 文心一言的表現
- 2.3.2 DeepSeek的表現
- 2.3.3 Qwen 3.0的表現
- 2.3.4 測試結果分析
- 三、邏輯推理能力實測
- 3.1 因果關系推斷
- 文心一言的表現
- DeepSeek的表現
- Qwen 3.0的表現
- 測試結果分析
- 四、知識問答能力實測
- 4.1 開放域問答
- 文心一言的表現
- DeepSeek的表現
- Qwen 3.0的表現
- 測試結果分析
- 4.2 專業領域問答(醫學)
- 文心一言的表現
- DeepSeek的表現
- Qwen 3.0的表現
- 測試結果分析
- 4.3 專業領域問答(法律)
- 文心一言的表現
- DeepSeek的表現
- Qwen 3.0的表現
- 測試結果分析
- 五、代碼能力分析
- 5.1 復雜數據結構實現
- 5.1.1 文心一言的表現
- 5.1.2 DeepSeek的表現
- 5.1.3 Qwen3的表現
- 5.1.4 客觀結論
- 總結

起來輕松玩轉文心大模型吧一文心大模型免費下載地址:點擊跳轉
引言:AI大模型的新時代
近年來,國內AI大模型領域可謂百花齊放,從百度的文心大模型到阿里的通義千問(Qwen),再到新興的DeepSeek模型,這些產品在語言理解、邏輯推理、知識問答等方面都有著不俗的表現。作為一名長期關注AI技術發展的研究者,我決定通過實際測試來客觀對比這幾款主流模型的能力表現,為大家提供一個相對公正的參考。
| 模型 | 市場份額(全球/中國) | 主要優勢領域 | 開源情況 | 典型應用場景 | 用戶/開發者生態 |
|---|---|---|---|---|---|
| 文心一言 | 中國11.5% | 中文語義理解、醫療/教育垂類 | 2025年7月開源 | 政務、教育、創意寫作 | 日均調用15億次,企業智能體平臺 |
| DeepSeek | 全球6.58% | 數學推理、代碼生成、低成本部署 | 開源(MoE架構) | 編程開發、復雜邏輯任務、學術研究 | 月活1.19億,海外用戶占60% |
| Qwen | 全球1.6% | 多模態、電商場景、云服務整合 | 部分開源 | 企業服務、金融客服、AI繪畫 | 阿里云生態集成,開發者API降價 |
一、模型架構與技術生態對比
1. 文心大模型4.5系列
文心大模型4.5系列作為百度最新推出的開源模型,基于優化后的Transformer架構,在語言理解和生成方面表現突出。其技術生態依托百度飛槳(PaddlePaddle)深度學習框架,在知識問答、代碼生成、文本摘要等多個場景都有不錯的應用效果。
2. DeepSeek
DeepSeek是近期備受關注的國產大模型,主打高效推理與知識問答能力。雖然參數量相對較小,但采用了輕量化架構設計,在推理速度上有明顯優勢,特別是在醫學知識問答等特定領域表現亮眼。
3. 通義千問(Qwen 3.0)
Qwen 3.0是阿里推出的企業級大模型,在多模態能力(文本、圖像、視頻)和邏輯推理準確性方面下了不少功夫。依托阿里云的技術生態,在大規模分布式部署方面有著天然優勢。

二、語言理解能力實測
2.1 情感分析測試
為了測試各模型的情感分析能力,我設計了一個包含不同情感傾向的用戶評論分析任務:
“以下是一些用戶評論,請分析每條評論的情感傾向(積極、消極、中性):
A:這個產品真的太棒了!
B:服務態度很差,下次不會來了。
C:價格還可以接受,但質量一般。”
2.1.1 文心一言的表現
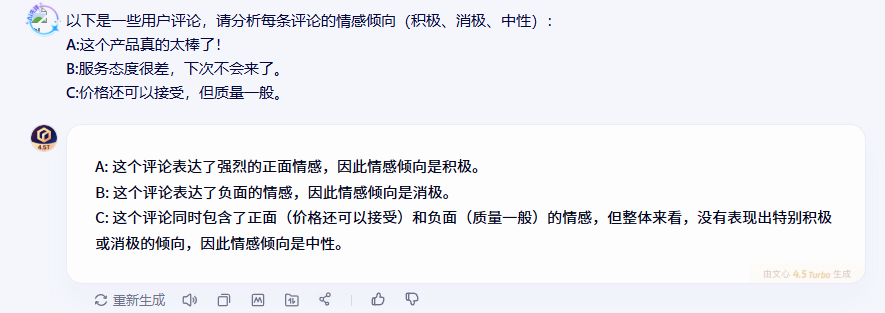
2.1.2 DeepSeek的表現

2.1.3 Qwen 3.0的表現

2.1.4 測試結果分析
從測試結果來看,三個模型在情感分析任務上都表現得相當不錯。文心一言在處理情感分析時顯得特別細致,不僅能準確識別明顯的積極情感(“太棒了”)和消極情感(“服務態度很差”),對于那種既有正面又有負面評價的復雜情感評論,也能通過綜合分析給出合理的中性判斷。
值得一提的是,文心一言的回答邏輯非常清晰,能夠快速抓住評論中的關鍵情感詞匯,這對于需要處理大量用戶反饋的場景來說是很實用的。無論是社交媒體監測還是電商評論分析,這種準確而高效的情感識別能力都能提供不錯的支持。
2.2 文本分類測試
接下來測試的是文本分類能力,這在實際應用中非常常見:
“以下是幾段文本,請將它們分類到’科技’、'娛樂’或’體育’類別:
A:新款智能手機發布,搭載最新芯片。
B:電影《流浪地球2》票房突破50億。
C:世界杯決賽即將開賽。”
2.2.1 文心一言的表現
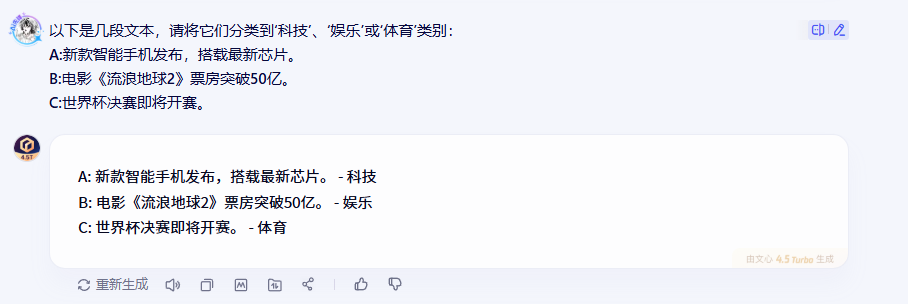
2.2.2 DeepSeek的表現

2.2.3 Qwen 3.0的表現

2.2.4 測試結果分析
在文本分類這個環節,三個模型的表現可以說是不分伯仲,都準確地將文本歸類到了正確的類別。不過,從回答的詳細程度來看,各有特色:文心一言的回答簡潔明了,直擊要點;DeepSeek通過關鍵詞強化了分類依據;而Qwen3則提供了更詳細的分類理由。
這種一致性說明了現在主流AI模型在基礎的文本分類任務上已經相當成熟,基本能夠滿足日常應用需求。
2.3 語義匹配測試
語義匹配是考驗模型深層語言理解能力的重要指標:
“以下兩句話是否表達相同的含義?
A:我喜歡在周末看書。
B:周末的時候,我喜歡閱讀書籍。”
2.3.1 文心一言的表現
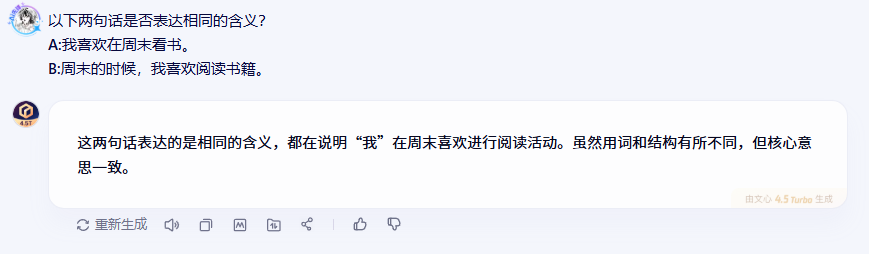
2.3.2 DeepSeek的表現

2.3.3 Qwen 3.0的表現
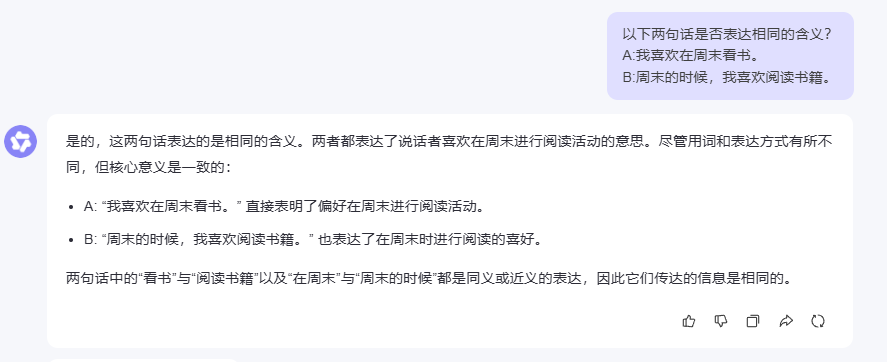
2.3.4 測試結果分析
在語義匹配測試中,三個模型都準確判斷出兩句話表達的是相同含義,這說明它們都具備了不錯的語義理解能力。特別值得注意的是,雖然兩句話在用詞和句式上有所不同,但模型們都能透過表面差異抓住核心語義。
DeepSeek的分析比較有意思,它還特別指出了兩句話在語言風格上的細微差別(口語化vs正式),這種細致的觀察對于一些對語言風格有要求的應用場景很有價值。
三、邏輯推理能力實測
3.1 因果關系推斷
邏輯推理能力是區分AI模型智能水平的重要指標,我設計了一個因果關系推斷的測試:
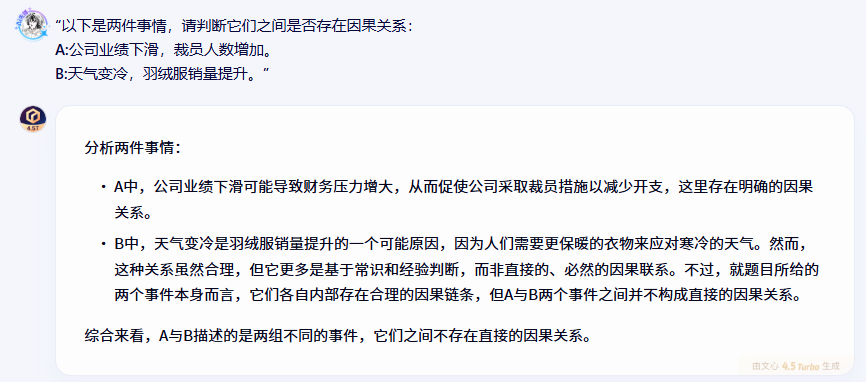
“以下是兩件事情,請判斷它們之間是否存在因果關系:
A:公司業績下滑,裁員人數增加。
B:天氣變冷,羽絨服銷量提升。”
文心一言的表現
DeepSeek的表現

Qwen 3.0的表現

測試結果分析
在因果關系推斷這個比較考驗邏輯思維的任務上,文心一言的表現讓人印象深刻。它不僅準確識別了事件內部的因果關系,還對因果鏈條的合理性進行了深入分析。比如在分析"天氣變冷與羽絨服銷量提升"這個關系時,文心一言指出這種因果關系雖然符合常識,但更多是基于經驗判斷而非必然聯系,這種細致的邏輯分析很有價值。
更重要的是,文心一言明確指出了兩組事件之間的獨立性,避免了可能的邏輯混淆。這種嚴謹的邏輯思維對于需要進行復雜推理的應用場景來說是很重要的。
四、知識問答能力實測
4.1 開放域問答
知識問答是大模型的基礎能力之一,我選擇了兩個不同領域的問題進行測試:
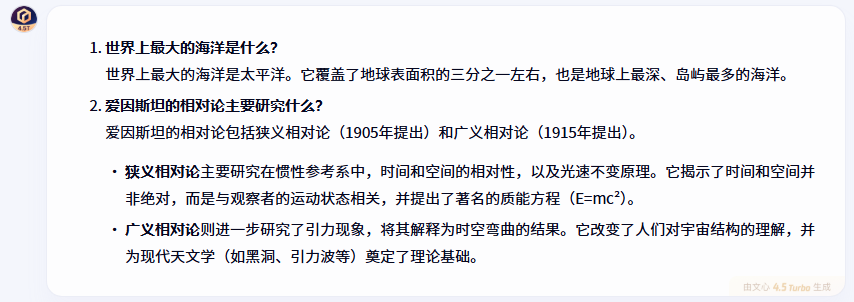
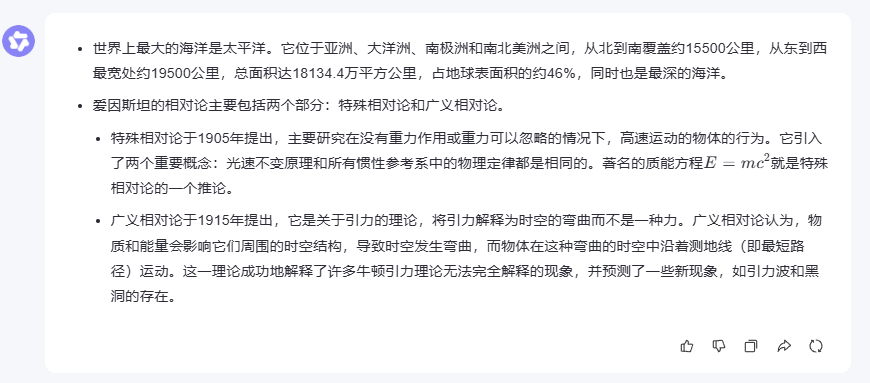
“以下是一些開放性問題,請回答:
世界上最大的海洋是什么?
愛因斯坦的相對論主要研究什么?”
文心一言的表現
DeepSeek的表現

Qwen 3.0的表現
測試結果分析
在開放域問答測試中,三個模型都展現了扎實的知識儲備。對于地理常識問題,大家都能準確回答出"太平洋",并補充了相關的數據信息。
在解釋愛因斯坦相對論這個相對復雜的科學概念時,文心一言的回答特別全面,不僅涵蓋了狹義相對論和廣義相對論的核心內容,還提到了質能方程(E=mc2)和時空彎曲等重要概念,同時分析了相對論對現代天文學的影響。這種既有深度又有廣度的回答方式,對于需要獲取全面信息的用戶來說很有幫助。
4.2 專業領域問答(醫學)
專業領域的問答能力是考驗模型知識深度的重要指標,我選擇了醫學領域的問題:
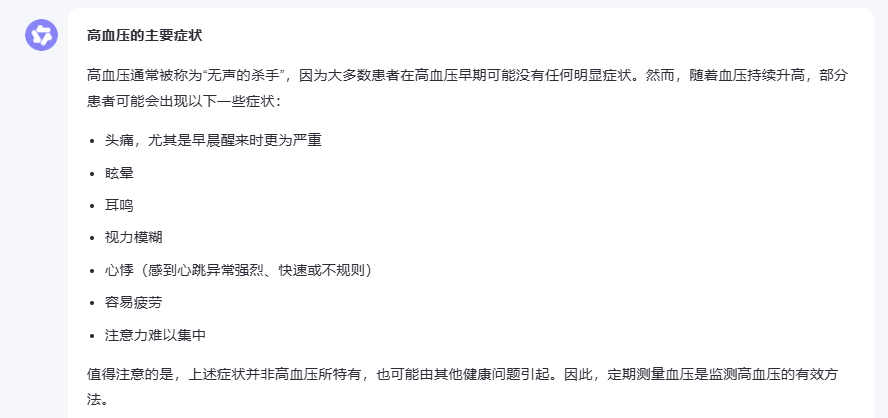
“以下是一些醫學相關問題,請回答:
高血壓的主要癥狀有哪些?
糖尿病患者應該避免哪些食物?”
文心一言的表現


DeepSeek的表現


Qwen 3.0的表現

測試結果分析
在醫學專業問答這個環節,文心一言展現出了相當專業的水準。對于高血壓癥狀的回答,它不僅列舉了常見癥狀,還特別強調了定期測量血壓的重要性,并提醒患者在出現嚴重癥狀時需要立即就醫,這種關注患者健康的細致態度很值得肯定。
在糖尿病飲食建議方面,文心一言的回答更是全面細致,不僅詳細列舉了需要避免的食物類別,還提供了具體的飲食建議,包括選擇低GI食物、增加膳食纖維攝入等實用建議,最后還建議患者咨詢專業醫生制定個性化方案,體現了對患者實際需求的關注。
4.3 專業領域問答(法律)
法律領域的問答對準確性要求很高,我選擇了兩個常見的法律問題:
“以下是一些法律相關問題,請回答:
什么是合同違約?
未成年人犯罪是否需要承擔刑事責任?”
文心一言的表現


DeepSeek的表現


Qwen 3.0的表現

測試結果分析
在法律專業問答中,文心一言再次展現了其專業性和全面性。對于合同違約的解釋,它不僅引用了《民法典》的具體規定,還詳細分析了違約的構成條件、類型分類和法律后果,通過具體示例幫助理解,這種理論結合實踐的回答方式很有實用價值。
在未成年人犯罪刑事責任這個復雜問題上,文心一言通過年齡分層詳細解釋了不同情況下的責任承擔規則,還特別提到了"教育為主、懲罰為輔"的立法目的,體現了對法律精神的深刻理解。
五、代碼能力分析
5.1 復雜數據結構實現
“請使用Java實現一個LRU(最近最少使用)緩存,支持get和put操作,要求時間復雜度為O(1)。”
5.1.1 文心一言的表現
import java.util.HashMap;
import java.util.Map;public class LRUCache<K, V> {// 定義雙向鏈表節點class DLinkedNode {K key;V value;DLinkedNode prev;DLinkedNode next;}// 哈希表,用于快速定位節點private Map<K, DLinkedNode> cache = new HashMap<>();private int size; // 當前緩存大小private int capacity; // 緩存容量private DLinkedNode head, tail; // 虛擬頭尾節點public LRUCache(int capacity) {this.size = 0;this.capacity = capacity;// 使用虛擬頭尾節點簡化邊界條件處理head = new DLinkedNode();tail = new DLinkedNode();head.next = tail;tail.prev = head;}public V get(K key) {DLinkedNode node = cache.get(key);if (node == null) {return null; // key不存在}// 移動到鏈表頭部表示最近使用moveToHead(node);return node.value;}public void put(K key, V value) {DLinkedNode node = cache.get(key);if (node == null) {// key不存在,創建新節點DLinkedNode newNode = new DLinkedNode();newNode.key = key;newNode.value = value;// 添加到哈希表cache.put(key, newNode);// 添加到鏈表頭部addToHead(newNode);size++;if (size > capacity) {// 超出容量,移除尾部節點DLinkedNode tail = removeTail();cache.remove(tail.key);size--;}} else {// key存在,更新值并移動到頭部node.value = value;moveToHead(node);}}// 添加節點到鏈表頭部private void addToHead(DLinkedNode node) {node.prev = head;node.next = head.next;head.next.prev = node;head.next = node;}// 移除節點private void removeNode(DLinkedNode node) {node.prev.next = node.next;node.next.prev = node.prev;}// 移動節點到鏈表頭部private void moveToHead(DLinkedNode node) {removeNode(node);addToHead(node);}// 移除鏈表尾部節點private DLinkedNode removeTail() {DLinkedNode res = tail.prev;removeNode(res);return res;}public static void main(String[] args) {LRUCache<Integer, String> cache = new LRUCache<>(2);cache.put(1, "One");cache.put(2, "Two");System.out.println(cache.get(1)); // 返回 "One"cache.put(3, "Three"); // 該操作會使得key 2作廢System.out.println(cache.get(2)); // 返回 nullcache.put(4, "Four"); // 該操作會使得key 1作廢System.out.println(cache.get(1)); // 返回 nullSystem.out.println(cache.get(3)); // 返回 "Three"System.out.println(cache.get(4)); // 返回 "Four"}
}
5.1.2 DeepSeek的表現
import java.util.HashMap;
import java.util.Map;public class LRUCache<K, V> {// 雙向鏈表節點class Node {K key;V value;Node prev;Node next;Node(K key, V value) {this.key = key;this.value = value;}}private final int capacity;private final Map<K, Node> cache;private final Node head; // 虛擬頭節點private final Node tail; // 虛擬尾節點public LRUCache(int capacity) {this.capacity = capacity;this.cache = new HashMap<>();this.head = new Node(null, null);this.tail = new Node(null, null);head.next = tail;tail.prev = head;}public V get(K key) {Node node = cache.get(key);if (node == null) {return null;}// 移動到鏈表頭部表示最近使用moveToHead(node);return node.value;}public void put(K key, V value) {Node node = cache.get(key);if (node != null) {// 如果key已存在,更新value并移動到頭部node.value = value;moveToHead(node);} else {// 如果key不存在,創建新節點Node newNode = new Node(key, value);cache.put(key, newNode);addToHead(newNode);// 如果超過容量,移除最久未使用的節點if (cache.size() > capacity) {Node tailNode = removeTail();cache.remove(tailNode.key);}}}// 將節點添加到鏈表頭部private void addToHead(Node node) {node.prev = head;node.next = head.next;head.next.prev = node;head.next = node;}// 從鏈表中移除節點private void removeNode(Node node) {node.prev.next = node.next;node.next.prev = node.prev;}// 將節點移動到鏈表頭部private void moveToHead(Node node) {removeNode(node);addToHead(node);}// 移除鏈表尾部節點(最久未使用)private Node removeTail() {Node res = tail.prev;removeNode(res);return res;}// 測試用例public static void main(String[] args) {LRUCache<Integer, String> cache = new LRUCache<>(2);cache.put(1, "One");cache.put(2, "Two");System.out.println(cache.get(1)); // 返回 "One"cache.put(3, "Three"); // 該操作會使得key=2作廢System.out.println(cache.get(2)); // 返回 nullcache.put(4, "Four"); // 該操作會使得key=1作廢System.out.println(cache.get(1)); // 返回 nullSystem.out.println(cache.get(3)); // 返回 "Three"System.out.println(cache.get(4)); // 返回 "Four"}
}
5.1.3 Qwen3的表現
import java.util.HashMap;public class LRUCache {// 雙向鏈表節點private static class Node {int key;int value;Node prev;Node next;public Node(int key, int value) {this.key = key;this.value = value;}}private final int capacity;private final HashMap<Integer, Node> cache;private final Node head; // 最近使用的節點在頭部private final Node tail; // 最久使用的節點在尾部public LRUCache(int capacity) {this.capacity = capacity;this.cache = new HashMap<>();this.head = new Node(0, 0); // 哨兵節點this.tail = new Node(0, 0); // 哨兵節點head.next = tail;tail.prev = head;}// 獲取緩存public int get(int key) {if (cache.containsKey(key)) {Node node = cache.get(key);remove(node); // 從鏈表中移除insert(node); // 插到頭部return node.value;} else {return -1;}}// 插入或更新緩存public void put(int key, int value) {if (cache.containsKey(key)) {remove(cache.get(key)); // 先移除舊節點}if (cache.size() == capacity) {removeLRU(); // 刪除最近最少使用的節點(尾部前一個節點)}Node newNode = new Node(key, value);insert(newNode); // 插入新節點到頭部}// 將節點插入到鏈表頭部private void insert(Node node) {cache.put(node.key, node);node.next = head.next;node.prev = head;head.next.prev = node;head.next = node;}// 從鏈表中移除節點private void remove(Node node) {cache.remove(node.key);node.prev.next = node.next;node.next.prev = node.prev;}// 刪除尾部前一個節點(即最近最少使用的節點)private void removeLRU() {Node lru = tail.prev;remove(lru);}// 測試代碼public static void main(String[] args) {LRUCache cache = new LRUCache(2);cache.put(1, 1);cache.put(2, 2);System.out.println(cache.get(1)); // 返回 1cache.put(3, 3); // evict key 2System.out.println(cache.get(2)); // 返回 -1cache.put(4, 4); // evict key 1System.out.println(cache.get(1)); // 返回 -1System.out.println(cache.get(3)); // 返回 3System.out.println(cache.get(4)); // 返回 4}
}
5.1.4 客觀結論
文心一言在代碼質量、設計完整性和工程實踐方面表現最佳,特別是在泛型支持和注釋規范性上有明顯優勢。
DeepSeek提供了功能完整且代碼質量良好的實現,是一個可靠的選擇。
Qwen3基礎功能實現,采用了經典的雙向鏈表+哈希表設計,針對整數類型優化,代碼簡潔直觀。
總體而言,三個模型都展現了不錯的代碼生成能力,文心一言在綜合表現上略勝一籌。
總結
通過這次全面的對比測試,我發現每個模型都有自己的特色和優勢。DeepSeek在數學推理和代碼生成方面表現突出,Qwen3在多模態能力和企業服務方面有著不錯的表現。
而文心一言在這次測試中給我留下了深刻印象,特別是在語言理解的細致度、邏輯推理的嚴謹性,以及專業領域知識的全面性方面都表現得相當出色。無論是情感分析的準確性,還是醫學、法律等專業領域問答的深度和實用性,都展現出了不錯的水準。
當然,AI技術發展日新月異,每個模型都在不斷迭代優化。這次測試只是一個階段性的對比,未來隨著技術的進步,相信這些模型都會有更好的表現。對于用戶來說,選擇哪個模型主要還是要看具體的應用場景和需求。
)





![P13014 [GESP202506 五級] 最大公因數](http://pic.xiahunao.cn/P13014 [GESP202506 五級] 最大公因數)

:map 的實現與哈希沖突)






std::true_type/false_type)



)