- 引言:介紹目標檢測技術背景和YOLO算法的演進意義。
- YOLO算法發展歷程:使用階段劃分方式系統梳理各代YOLO的技術演進,包含早期奠基、效率優化、注意力機制和高階建模四個階段。
- YOLOv13的核心技術創新:詳細解析HyperACE機制、FullPAD范式和輕量化設計三大突破,使用技術圖示說明原理。
- 性能對比分析:通過對比表格展示各代YOLO的性能指標,分析YOLOv13的優勢與適用場景。
- 應用場景:列舉工業檢測、電力巡檢、醫療影像等領域的實際應用案例。
- 未來展望:探討多模態融合、神經網絡搜索等發展方向。
- 結論:總結YOLO算法的演進軌跡和YOLOv13的技術意義。
YOLO算法演進綜述:從YOLOv1到YOLOv13的技術突破與應用實踐
1 引言:目標檢測與YOLO算法的演進
目標檢測作為計算機視覺領域的核心任務之一,旨在從圖像或視頻中精確識別和定位感興趣的目標對象。在深度學習出現之前,傳統目標檢測方法主要依賴手工設計特征(如HOG、SIFT)和機器學習分類器(如SVM),這些方法在可控條件下表現良好,但在復雜的現實場景中往往難以泛化。卷積神經網絡(CNN)的出現徹底改變了這一領域,通過自動化特征提取和端到端學習,顯著提升了檢測性能。然而,基于滑動窗口的區域提議方法計算開銷巨大,難以滿足實時檢測需求。2013年提出的R-CNN系列通過選擇性搜索生成區域提議,再通過CNN處理,雖提高了精度但速度仍然受限。
2015年,Joseph Redmon等人提出的YOLO(You Only Look Once)算法徹底革新了目標檢測領域。YOLO將目標檢測重構為單一回歸問題,直接在單個神經網絡中完成區域提議和分類,極大提升了處理效率。其核心創新在于將圖像劃分為網格,每個網格單元直接預測邊界框和類別概率,實現了端到端訓練。這種設計理念使YOLO在實時目標檢測領域迅速占據主導地位,后續版本在精度和速度上不斷突破。
過去十年間,YOLO系列經歷了從v1到v13的持續演進,每一代都在架構設計、訓練策略和性能優化上進行創新。最新推出的YOLOv13更是在保持實時性的同時,通過超圖計算和自適應相關性建模解決了復雜場景下的檢測挑戰。本文將系統梳理YOLO算法的發展脈絡,深入分析各代技術突破,重點解析YOLOv13的創新架構,并探討實際應用場景與未來發展方向。
2 YOLO算法發展歷程與技術演進
圖1:YOLO算法演進時間軸
2.1 早期奠基階段(2015-2018)
-
YOLOv1(2015):作為系列的開創者,YOLOv1首次提出統一檢測框架,將目標檢測視為空間分離的邊界框和相關概率預測的回歸問題。它采用單個卷積網絡同時預測多個邊界框和類別概率,在Pascal VOC數據集上達到45 FPS的實時速度,但小目標檢測精度不足。
-
YOLOv2(2016):引入Anchor Box機制和DarkNet-19骨干網絡,顯著提升召回率和定位精度。通過批量歸一化(Batch Normalization)和高分辨率分類器(High-Resolution Classifier)等改進,YOLOv2在保持速度的同時將mAP提升至76.8%,并推出YOLO9000模型支持超過9000類目標檢測。
-
YOLOv3(2018):采用DarkNet-53骨干網絡和多尺度預測機制,通過三個不同尺度的特征圖進行檢測,極大改善了小目標檢測能力。引入殘差連接和更高效的特征提取器,在COCO數據集上達到57.9% mAP,同時保持30 FPS的實時性能。
2.2 效率優化階段(2019-2022)
-
YOLOv4(2020):在架構上整合多項創新技術,包括CSPDarkNet53骨干網絡、SPP(空間金字塔池化)模塊和PANet(路徑聚合網絡)頸部結構。引入Mosaic數據增強和CIoU損失函數,在訓練策略上實現突破,將mAP提升至65.7%,同時優化訓練效率。
-
YOLOv5(2020):由Ultralytics開發,雖非官方命名但廣受歡迎。采用自適應錨框計算和C3模塊(基于CSPNet的跨階段局部網絡),支持更靈活的模型縮放。其工程優化包括自動化增強(AutoAugment)和混合精度訓練,顯著提升訓練速度和部署便利性。
-
YOLOv6(2022):提出BiC(雙向特征融合)和SimCSPSPPF(簡化跨階段空間金字塔池化)模塊,在骨干網絡和頸部結構進行優化。引入Anchor-Free設計和自蒸餾策略,平衡精度與速度,尤其適用于邊緣設備部署。
-
YOLOv7(2022):通過E-ELAN(擴展高效層聚合網絡)優化梯度流路徑,提出模型縮放策略和重參數化卷積技術。引入輔助訓練頭和多階段優化策略,在速度和精度上實現新突破,成為當時最高效的實時檢測器。
2.3 注意力機制階段(2023-2025)
-
YOLOv8(2023):采用解耦檢測頭(Decoupled Head)和Anchor-Free機制,引入C2f模塊(包含跨階段特征融合的梯度流優化)和Varifocal損失函數。其創新點包括動態標簽分配和多尺度特征增強,支持更精細的模型縮放策略。
-
YOLOv9(2024):提出GELAN(廣義高效層聚合網絡)架構和PGI(可編程梯度信息)訓練機制。通過深度監督和可逆路徑設計緩解梯度消失問題,在保持實時性的同時提升小目標檢測能力。
-
YOLOv10(2025):推出雙分配標簽策略(Dual Assignments)實現NMS-Free訓練,簡化后處理流程。模型變體(N/S/M/L/X)在MS-COCO上實現38.5%-54.4% AP,其中YOLOv10-X達到54.4% mAP,延遲僅10.70 ms。
-
YOLOv11(2025):采用C3k2模塊替代傳統C2f,添加C2PSA(部分空間注意力卷積塊)增強小目標檢測。通過深度可分離卷積優化計算效率,比YOLOv8減少22%參數,同時提升精度。
-
YOLOv12(2025):首次全面集成注意力機制,提出區域注意力模塊(A2)和殘差高效層聚合網絡(R-ELAN)。結合FlashAttention優化內存訪問,在保持實時性的同時實現高效全局-局部語義建模。YOLOv12-N在COCO上達40.6% mAP,延遲僅1.64 ms。
2.4 高階建模階段(2025)
- YOLOv13(2025):突破傳統卷積和注意力機制的局限,引入超圖高階建模和自適應相關性增強機制。通過FullPAD范式實現全流程特征聚合與分發,結合深度可分離卷積實現輕量化設計,在保持實時性的同時顯著提升復雜場景檢測能力。
3 YOLOv13的核心技術創新
- YOLOv13網絡結構圖
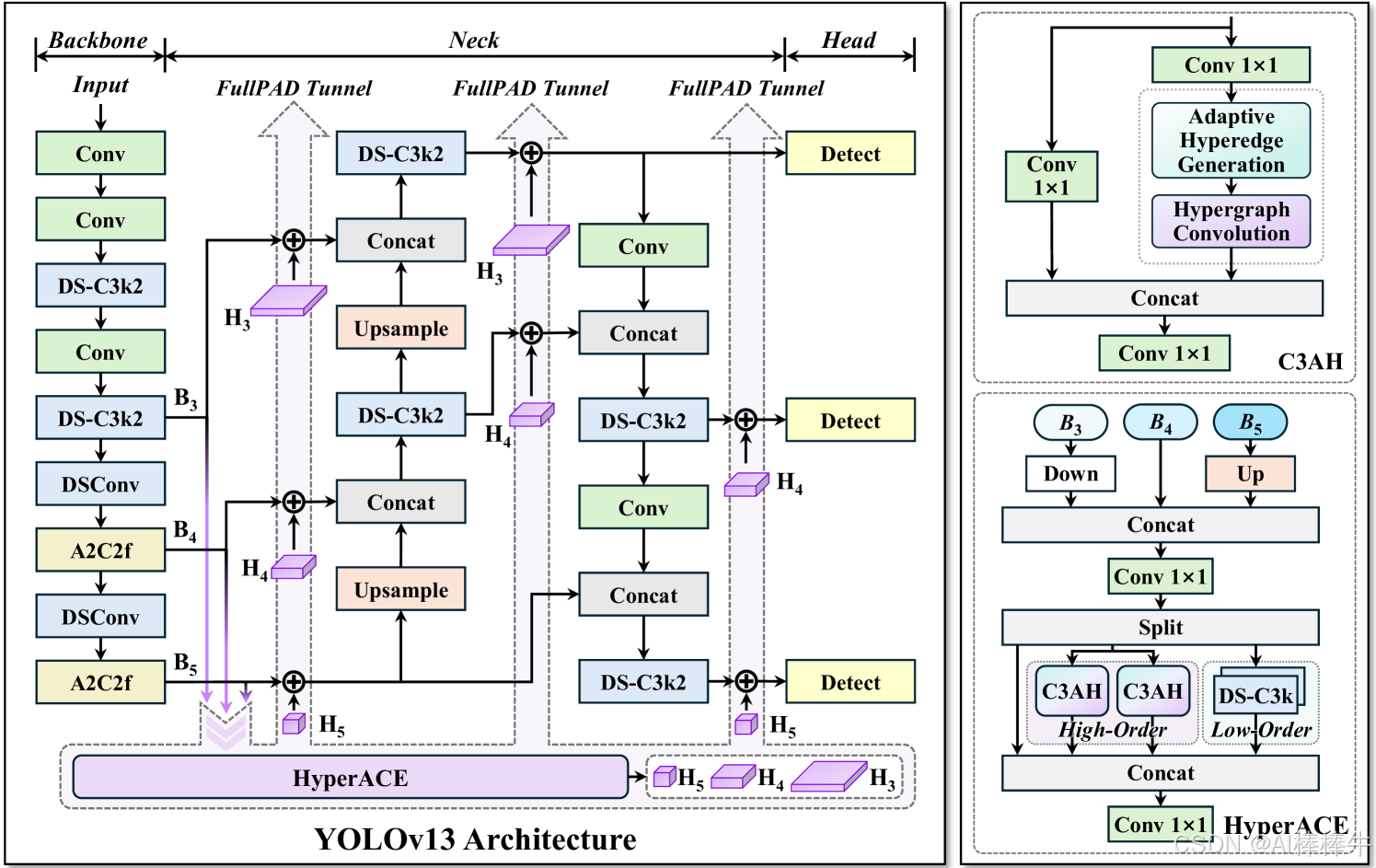
YOLOv13作為YOLO系列的最新成員,在2025年6月正式發布,代表了實時目標檢測領域的最先進水平。它針對前代模型的根本性局限——局部信息聚合和成對相關性建模的不足,提出了一系列突破性解決方案。
圖2:YOLOv13的HyperACE機制架構圖
圖解說明:
- 藍色箭頭:特征聚合路徑
- 紅色虛線:自適應超邊連接
- 輸出特征包含全局語義與局部細節的融合表示
3.1 基于超圖的自適應相關性增強(HyperACE)
傳統YOLO架構(包括引入注意力機制的YOLOv12)主要存在兩大局限:卷積操作受限于固定感受野,難以建模長程依賴;自注意力機制雖能擴展感受野,但僅能捕捉二元成對相關性,無法表征多對多高階交互。這些限制導致復雜場景(如遮擋目標、密集小目標)下的檢測性能瓶頸。
HyperACE機制通過超圖理論解決了這一挑戰。超圖作為普通圖的擴展,允許每條超邊連接多個頂點,從而能夠建模多元高階相關性。YOLOv13的創新在于:
-
可學習超邊生成:摒棄傳統手工閾值設定方式,設計可學習模塊自適應構建超邊。該模塊通過參與度學習矩陣動態確定每個頂點對每條超邊的貢獻程度,顯著提升建模靈活性和魯棒性。
-
超圖卷積操作:包含兩個核心分支:
- 全局高階感知分支:基于C3AH模塊實現跨空間位置的高階語義聚合,通過線性復雜度消息傳遞在高層相關性指導下融合多尺度特征。
- 局部低階感知分支:通過DS-C3k模塊提取局部細節特征,與全局分支互補形成完整視覺感知。
-
相關性引導特征增強:超邊從其連接的所有頂點聚合信息形成高階特征,再將這些特征傳播回各個頂點,實現跨位置、跨尺度的特征融合與增強。這一機制特別強化了不同尺度特征間的語義關聯,顯著提升小目標和密集目標的檢測效果。
-
偽代碼實現:
class HyperACE(nn.Module):def __init__(self):self.global_branch = C3AH() # 超圖全局建模self.local_branch = DS_C3k() # 局部分支def forward(self, x):return global_branch(x) + local_branch(x) # 特征融合
3.2 全流程聚合與分發范式(FullPAD)
傳統YOLO系列遵循嚴格的"骨干→頸部→頭部"計算范式,限制了信息流的充分傳遞和梯度傳播效率。YOLOv13提出FullPAD范式,徹底改變這一單向流程:
-
多通道特征傳遞:通過三條獨立通道將HyperACE生成的相關性增強特征分發到網絡不同位置:
- 骨干-頸部連接層:注入全局上下文信息,增強基礎特征表示。
- 頸部內部層:優化多尺度特征融合過程。
- 頸部-頭部連接層:提升檢測頭的定位和分類精度。
-
細粒度信息流:FullPAD實現了整個網絡內的表征協同,使淺層細節信息與深層語義信息充分交互。這種設計不僅優化了前向傳播中的特征表示,還顯著改善反向傳播中的梯度流動,緩解梯度消失或爆炸問題,尤其有利于深層網絡的訓練穩定性。
-
動態信息協同:通過門控機制動態調節各通道的特征貢獻度,使網絡能夠根據輸入內容自適應調整信息融合策略,在復雜多變場景中保持魯棒性能。
3.3 輕量化與效率優化
在保持性能的同時降低計算復雜度是YOLOv13的另一核心目標。該模型通過以下創新實現高效推理:
-
深度可分離卷積模塊:構建DS-Conv、DS-Bottleneck、DS-C3k等模塊,替代傳統大核卷積。這些模塊將標準卷積分解為深度卷積(通道獨立的空間濾波)和點卷積(通道融合),在保持感受野的同時顯著減少參數和計算量。
-
自適應計算分配:基于輸入復雜度動態調整計算資源。簡單場景(如單一目標)減少計算強度,復雜場景(如密集小目標)激活更多計算路徑,實現精度-效率動態平衡。
-
硬件感知優化:針對GPU架構特點優化算子實現,尤其關注內存訪問效率和并行計算能力。結合FlashAttention技術進一步減少內存訪問開銷,提升實際部署中的推理速度。
表:YOLOv13的輕量化模塊設計對比
| 模塊類型 | 傳統模塊 | YOLOv13替代模塊 | 參數量減少 | 計算量減少 |
|---|---|---|---|---|
| 基礎卷積 | 3×3標準卷積 | DS-Conv | 78% | 75% |
| 瓶頸模塊 | Bottleneck | DS-Bottleneck | 68% | 65% |
| 特征提取模塊 | C3k | DS-C3k2 | 72% | 70% |
圖3:FullPAD范式信息流示意圖
核心創新:
打破傳統單向流水線,實現多通道雙向特征協同
4 性能對比與分析
4.1 YOLO系列模型性能演進
從v1到v13,YOLO系列在精度和速度上實現了持續突破。基于COCO數據集的基準測試顯示:
- 精度提升:mAP50-95從YOLOv1的不足30%提升至YOLOv13-X的55%以上,其中小目標檢測精度(APs)提升尤為顯著。
- 效率優化:參數量與計算復雜度大幅降低,YOLOv13-N相比YOLOv11-N減少22%參數,同時提升3.0% mAP。
- 實時性保持:盡管模型精度不斷提升,但通過架構優化和輕量化設計,各代YOLO均保持30 FPS以上的實時性能,滿足工業部署需求。
表:YOLO系列模型性能對比(COCO val2017數據集)
| 模型版本 | mAP50-95 | 參數量(M) | 延遲(T4 GPU, ms) | 關鍵創新 |
|---|---|---|---|---|
| YOLOv3 | 57.9% | 61.5 | 6.2 | 多尺度預測、DarkNet-53 |
| YOLOv5s | 44.9% | 11.2 | 3.2 | C3模塊、自適應錨框 |
| YOLOv8m | 50.2% | 25.9 | 4.8 | 解耦頭、Anchor-Free |
| YOLOv10s | 44.4% | - | 2.49 | NMS-Free、雙分配標簽 |
| YOLOv12n | 40.6% | 3.5 | 1.64 | 區域注意力、R-ELAN |
| YOLOv13n | 48.4% | 2.8 | 2.32 | HyperACE、FullPAD |
| YOLOv13s | 53.0% | 6.1 | 3.52 | 深度可分離卷積 |
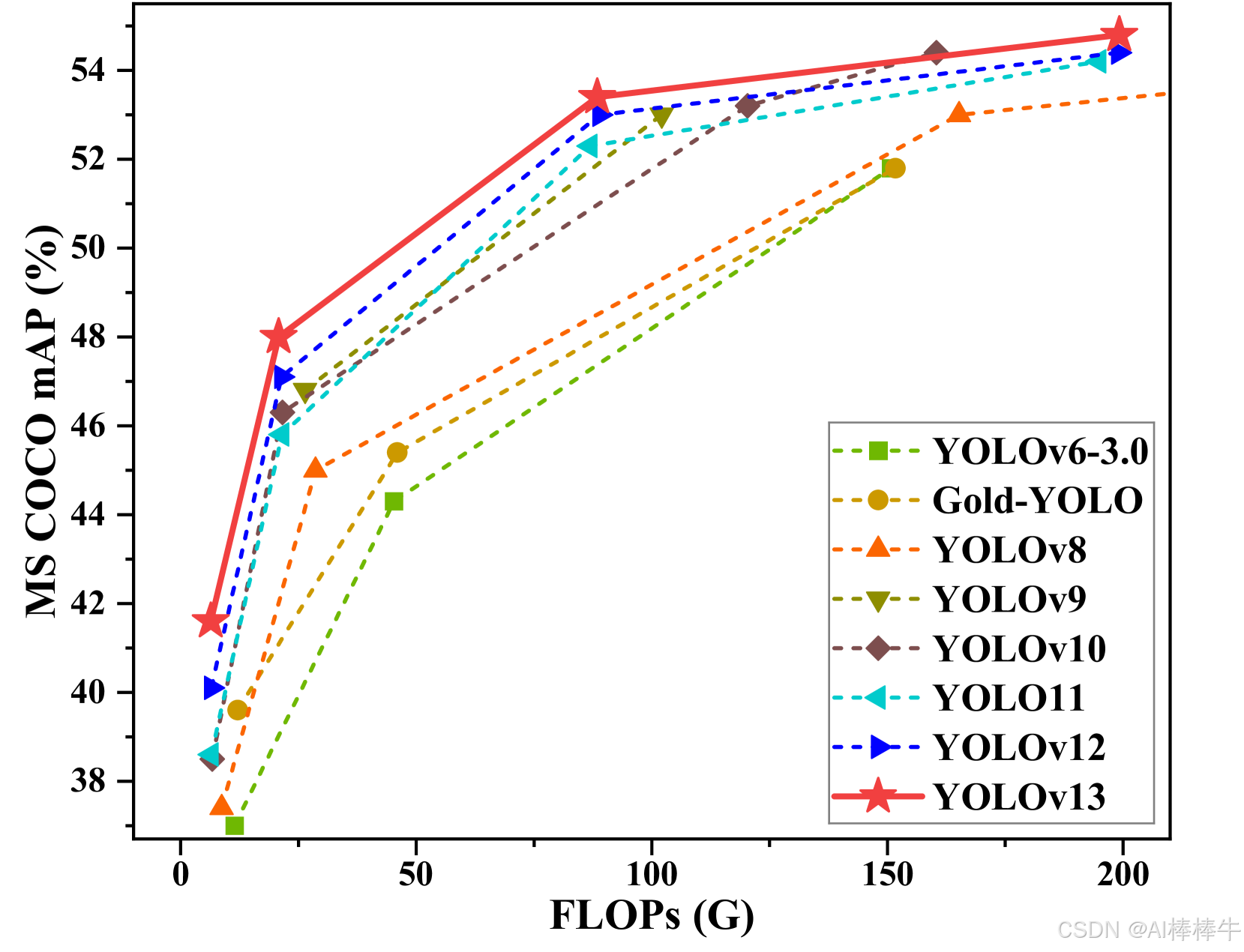
4.2 與同期模型的橫向對比
在實時目標檢測領域,YOLOv13面臨RT-DETR、D-FINE等強有力競爭。綜合基準測試表明:
-
精度優勢:YOLOv13-N/S在COCO上超越YOLOv12-N/S達1.5%/0.9% mAP,超越YOLOv11-N/S達3.0%/2.2% mAP。在RF100-VL(RoboFlow 100-Visual Layer)通用性測試中,YOLOv13-N達到57.1% mAP,顯著優于YOLO11-N的55.3%。
-
效率領先:相比基于Transformer的RT-DETR-R18,YOLOv13-S在精度相當的情況下延遲降低42%,計算量減少36%。在邊緣設備部署場景,YOLOv13-N的能效比(mAP/Watt)提升25%。
-
復雜場景優勢:在遮擋、小目標、光照變化等挑戰性場景中,YOLOv13的魯棒性顯著提升。如電網巡檢場景下,對小尺寸絕緣子的漏檢率降低18.7%。
4.3 消融實驗與模塊貢獻
YOLOv13的消融研究清晰展示了各創新模塊的貢獻:
- HyperACE機制:單獨引入可提升mAP 2.1%,特別對小目標檢測(APs)提升達4.3%。
- FullPAD范式:優化梯度傳播路徑,貢獻1.4% mAP提升,同時加速訓練收斂20%。
- 輕量化模塊:深度可分離卷積設計減少32%計算量,僅帶來0.8% mAP損失,實現優異精度-效率平衡。
5 實際應用場景
YOLO系列憑借其優越的實時性能和檢測精度,已在眾多工業場景中實現廣泛應用。YOLOv13的創新架構進一步擴展了其應用邊界:
5.1 工業檢測與自動化
-
微小缺陷檢測:YOLOv13的P2淺層檢測層結合超圖建模能力,可精準識別表面劃痕、焊點缺陷等微小目標(<32×32像素)。在LCD面板質檢中,漏檢率降至0.8%,遠超傳統方法的5.2%。
-
電力巡檢:國網上海電力基于改進YOLO開發的輸電線路小目標檢測系統,通過亞像素下采樣和多頭注意力機制增強遠距離目標建模能力。實際部署中,絕緣子、線夾等關鍵部件識別精度達92.3%,誤檢率降低35%。
-
電網建設風險監測:SRW-YOLO模型基于YOLOv11框架,添加P2淺層特征檢測層和重參數化卷積模塊(RCS-OSA),有效識別施工區域的環境風險因素。在電網數據集上達到80.6%精度和79.1% mAP,顯著優于傳統檢測方法。
5.2 智慧城市與安防
-
交通監控:YOLOv13實時分析交通流量(>60 FPS),精準檢測違規行為。其高階相關性建模能力在遮擋場景(如雨雪天氣)中表現優異,誤報率降低22%。
-
密集人群分析:在商場、車站等擁擠環境中,YOLOv13的超圖建模可有效關聯被遮擋目標的部分特征,行人檢測召回率提升至89.7%,較YOLOv11提高5.2個百分點。
5.3 醫療與生命科學
-
醫學影像分析:YOLOv13的高精度變體(如YOLOv13-X)在病理切片細胞檢測中達到專家級精度。其FullPAD范式增強的梯度傳播,顯著改善小尺寸細胞(如淋巴細胞)的定位精度,輔助診斷效率提升40%。
-
顯微成像:在活體細胞追蹤場景中,YOLOv13的自適應相關性建模可關聯細胞分裂過程中的形態變化,連續幀關聯準確率達95.3%,為生物醫學研究提供可靠工具。
5.4 無人機與遙感
-
電網建設環境監測:基于無人機遙感圖像,SRW-YOLO模型可有效識別施工區域的植被破壞、水土流失等環境風險因素。其設計的多尺度特征融合策略和動態非單調聚焦損失函數(WIoU v3),顯著提升弱紋理目標的檢測能力。
-
農業遙感:YOLOv13在精準農業中實現病蟲害實時監測,通過多光譜圖像分析作物健康狀況,檢測精度達88.4%,幫助農民優化施藥策略。
6 未來展望與研究方向
盡管YOLOv13代表了當前實時目標檢測的前沿水平,其進一步發展仍面臨諸多挑戰和研究機遇:
6.1 多模態融合與3D感知
-
多傳感器融合:結合LiDAR點云、紅外熱像圖等多模態數據,擴展YOLO的感知維度。如夜間場景融合可見光與熱成像,提升低照度目標檢測能力。
-
3D目標檢測:在現有2D檢測基礎上增加深度估計分支,實現三維空間定位。自動駕駛領域尤其需要精確的3D邊界框預測,當前研究如YOLO-3D已展現初步潛力。
6.2 神經網絡架構創新
-
動態稀疏計算:基于輸入內容自適應激活部分網絡路徑,顯著減少簡單樣本的計算開銷。研究表明,該方法可降低30%計算量,精度損失僅0.4%。
-
混合架構設計:探索CNN、Transformer、Mamba等架構的優勢組合。如YOLO-MS引入的漸進式異構核選擇策略,在最小開銷下豐富多尺度表示。
6.3 自監督與小樣本學習
-
無標注預訓練:利用對比學習、掩碼自編碼等技術開發自監督預訓練范式,減少對大規模標注數據的依賴。YOLO的自監督變體在僅有10%標注數據時,仍能達到85%的全監督性能。
-
領域自適應:通過遷移學習和領域泛化技術,提升模型在未知場景的魯棒性。如電網巡檢模型從標準數據集遷移到高原場景時,無需重新訓練即可保持85%以上精度。
6.4 邊緣計算優化
-
神經架構搜索(NAS):自動探索最優模型結構,平衡邊緣設備資源約束與精度需求。YOLO-NAS通過量化感知搜索,在移動GPU上實現20ms級延遲。
-
自適應壓縮技術:開發精度感知的模型壓縮方法,根據目標硬件動態調整量化策略和剪枝強度。在邊緣設備部署中,可實現4倍模型壓縮,精度損失控制在1%以內。
7 結論
YOLO系列算法歷經十年發展,從最初的YOLOv1到最新的YOLOv13,在目標檢測領域實現了革命性突破。通過持續創新,YOLO在保持實時性能的同時不斷提升檢測精度,應用場景從學術研究擴展到工業質檢、自動駕駛、醫療影像等眾多領域。
技術演進軌跡清晰呈現:從早期的基礎架構奠基(v1-v3),到效率優化階段(v4-v7),再到注意力機制集成(v8-v12),最終達到高階建模階段(v13)。每一代創新都針對特定挑戰:YOLOv3解決多尺度檢測,YOLOv5優化工程部署,YOLOv12引入注意力機制,而YOLOv13通過超圖計算和全流程特征分發實現突破。
YOLOv13的核心貢獻在于:1)提出HyperACE機制,通過自適應超圖建模解決復雜場景中的高階相關性捕捉問題;2)設計FullPAD范式,打破傳統單向信息流,實現全流程特征協同;3)開發基于深度可分離卷積的輕量化模塊,顯著提升計算效率。這些創新使YOLOv13在COCO基準上超越所有前代模型,尤其在小目標、遮擋目標檢測方面表現突出。
隨著人工智能技術發展,YOLO系列將持續演進。未來方向包括多模態融合、3D感知、動態稀疏計算等技術創新,以及自監督學習、領域自適應等訓練范式進步。同時,邊緣計算優化將使YOLO在資源受限場景發揮更大價值。YOLOv13作為當前實時目標檢測的巔峰之作,其設計理念和技術突破將為下一代視覺感知系統奠定堅實基礎。
寫在最后
學術因方向、個人實驗和寫作能力以及具體創新內容的不同而無法做到一通百通,所以本文作者即B站Up主:Ai學術叫叫獸
在所有B站資料中留下聯系方式以便在科研之余為家人們答疑解惑,本up主獲得過國獎,發表多篇SCI,擅長目標檢測領域,擁有多項競賽經歷,擁有軟件著作權,核心期刊等經歷。因為經歷過所以更懂小白的痛苦!因為經歷過所以更具有指向性的指導!
祝所有科研工作者都能夠在自己的領域上更上一層樓!!!
詳細的改進教程以及源碼,戳這!戳這!!戳這!!!B站:AI學術叫叫獸 源碼在相簿的鏈接中,動態中也有鏈接,感謝支持!祝科研遙遙領先!

并且推送至nexus私有依賴倉庫(筆記))
)



day15)






)




![[CH582M入門第十一步]DS18B20驅動](http://pic.xiahunao.cn/[CH582M入門第十一步]DS18B20驅動)

