文章鏈接:
2502.12524![]() https://arxiv.org/pdf/2502.12524
https://arxiv.org/pdf/2502.12524
摘要 (Abstract)??
長期以來,增強 YOLO 框架的網絡架構至關重要,但盡管注意力機制在建模能力方面已被證明具有優越性,改進卻主要集中在基于 CNN 的方面。這是因為基于注意力的模型無法匹配基于 CNN 模型的速度。本文提出了一種以注意力為中心的 YOLO 框架,即 YOLOv12,它在匹配先前基于 CNN 模型速度的同時,利用了注意力機制的性能優勢。
YOLOv12 在精度上超越了所有流行的實時目標檢測器,并具有有競爭力的速度。例如,YOLOv12-N 在 T4 GPU 上實現了 40.6% 的 mAP 和 1.64 ms 的推理延遲,優于先進的 YOLOv10-N/YOLOv11-N 2.1%/1.2% mAP,同時速度相當。這一優勢延伸到其他模型規模。YOLOv12 也超越了改進 DETR 的端到端實時檢測器,如 RT-DETR/RT-DETRv2:YOLOv12-S 擊敗了 RT-DETR-R18/RT-DETRv2-R18,同時運行速度快?42%,僅使用?36%?的計算量和 45% 的參數。更多比較如圖 1 所示。
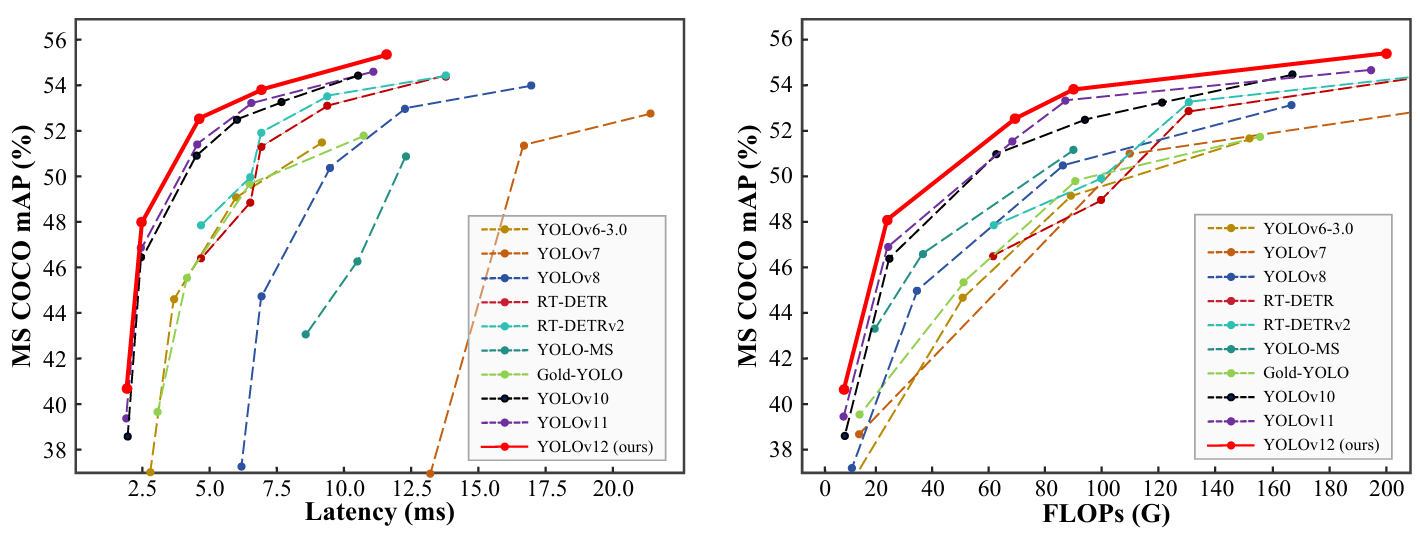
圖 1. 與其他流行方法在延遲-精度(左)和 FLOPs-精度(右)權衡方面的比較。
1. 引言 (Introduction)??
實時目標檢測因其低延遲特性(這提供了顯著的實用性[4, 17, 24, 28])一直吸引著廣泛關注。其中,YOLO 系列[3, 24, 28, 29, 32, 45-47, 53, 57, 58]有效地在延遲和精度之間建立了最佳平衡,從而主導了該領域。盡管 YOLO 的改進主要集中在損失函數[8, 35, 43, 44, 48, 67, 68]、標簽分配[22, 23, 34, 59, 69]等領域,網絡架構設計仍然是關鍵的研究重點[24, 28, 32, 57, 58]。盡管以注意力為中心的視覺變換器(ViT)架構已被證明具有更強的建模能力,即使在小型模型中也是如此[20, 21, 25, 50],但大多數架構設計仍主要集中于 CNN。
這種情況的主要原因在于注意力機制的低效性,這源于兩個主要因素:注意力機制的二次計算復雜性和低效的內存訪問操作(后者是 FlashAttention[13, 14] 解決的主要問題)。因此,在相似的計算預算下,基于 CNN 的架構性能比基于注意力的架構高出約 3 倍[38],這極大地限制了注意力機制在推理速度至關重要的 YOLO 系統中的采用。
本文旨在解決這些挑戰,并進一步構建一個以注意力為中心的 YOLO 框架,即 YOLOv12。我們引入了三項關鍵改進。首先,我們提出了一個簡單而高效的區域注意力模塊(A2),它在保持大感受野的同時,以一種非常簡單的方式降低了注意力的計算復雜度,從而提高了速度。其次,我們引入了殘差高效層聚合網絡(R-ELAN)以解決由注意力引入的優化挑戰(主要是大規模模型)。R-ELAN 在原始 ELAN[57] 的基礎上引入了兩項改進:(i)采用縮放技術的塊級殘差設計,和(ii)重新設計的特征聚合方法。第三,我們在原始注意力之外進行了一些架構改進以適應 YOLO 系統。我們升級了傳統的以注意力為中心的架構,包括:引入 FlashAttention 以克服注意力的內存訪問問題;移除位置編碼等設計以使模型快速簡潔;將 MLP 比率從 4 調整到 1.2(或 2 用于 N-/S-/M 規模模型)以平衡注意力和前饋網絡之間的計算量以獲得更好的性能;減少堆疊塊的深度以促進優化;并盡可能利用卷積算子以發揮其計算效率。
基于上述設計,我們開發了一個新的實時檢測器系列,包含 5 種模型規模:YOLOv12-N、S、M、L 和 X。我們在標準目標檢測基準上進行了大量實驗,遵循 YOLOv11[28] 且不添加任何額外技巧,結果表明 YOLOv12 在這些規模上的延遲-精度和 FLOPs-精度權衡方面均顯著優于先前的流行模型,如圖 1 所示。例如,YOLOv12-N 實現了 40.6% 的 mAP,以相似的推理速度優于 YOLOv10-N[53] 2.1% mAP,優于 YOLOv11-N[28] 1.2% mAP。這一優勢在其他規模模型上保持一致。與 RT-DETR-R18[66]/RT-DETRv2-R18[40] 相比,YOLOv12-S 的 mAP 高 1.5%/0.1%,同時延遲速度快 42%/42%,僅需其?36%/36%?的計算量和?45%/45%?的參數。
總之,YOLOv12 的貢獻是雙重的:1)它建立了一個以注意力為中心的、簡單而高效的 YOLO 框架,通過方法創新和架構改進,打破了 CNN 模型在 YOLO 系列中的主導地位。2)在不依賴預訓練等額外技術的情況下,YOLOv12 實現了具有快速推理速度和更高檢測精度的最先進結果,展示了其潛力。
2. 相關工作 (Related Work)??
??實時目標檢測器 (Real-time Object Detectors).??
由于其顯著的實際價值,實時目標檢測器一直吸引著學術界的關注。YOLO 系列[3,9,24,28,29,32,45-47,53,54,57,58]已成為實時目標檢測的領先框架。早期的 YOLO 系統[45-47]從模型設計的角度為 YOLO 系列奠定了基礎。YOLOv4[3] 和 YOLOv5[29] 在框架中添加了 CSPNet[55]、數據增強和多尺度特征。YOLOv6[32] 通過主干網絡(backbone)和頸部網絡(neck)的 BiC 和 SimCSPSPPF 模塊以及基于錨框(anchor-aided)的訓練進一步推進了這些改進。YOLOv7[57] 引入了 E-ELAN[56](高效層聚合網絡)以改善梯度流以及各種免費禮包(bag-of-freebies),而 YOLOv8[24] 集成了高效的 C2f 模塊以增強特征提取。在最近的迭代中,YOLOv9[58] 引入了 GELAN 進行架構優化和 PGI(可編程梯度信息)進行訓練改進,而 YOLOv10[53] 采用具有雙重分配(dual assignments)的無 NMS 訓練以提高效率。YOLOv11[28] 通過在檢測頭中采用 C3K2 模塊(GELAN[58] 的一種規格)和輕量級深度可分離卷積(depthwise separable convolution),進一步降低了延遲并提高了精度。最近,一種端到端的目標檢測方法,即 RT-DETR[66],通過設計高效的編碼器和不確定性最小化的查詢選擇機制,改進了傳統的端到端檢測器[7, 33, 37, 42, 71]以滿足實時需求。RT-DETRv2[40] 通過引入免費禮包(bag-of-freebies)進一步增強了它。與之前的 YOLO 系列不同,本研究旨在構建一個以注意力為中心的 YOLO 框架,以利用注意力機制的優越性。
??高效視覺變換器 (Efficient Vision Transformers).??
降低全局自注意力(global self-attention)的計算成本對于有效地將視覺變換器應用于下游任務至關重要。PVT[61] 通過多分辨率階段和下采樣特征來解決這個問題。Swin Transformer[39] 將自注意力限制在局部窗口內,并調整窗口劃分風格以連接非重疊窗口,在通信需求與內存和計算需求之間取得平衡。其他方法,例如軸向自注意力(axial self-attention)[26]和十字交叉注意力(criss-cross attention)[27],在水平和垂直窗口內計算注意力。CSWin transformer[16] 在此基礎上構建,引入了十字形窗口自注意力(cross-shaped window self-attention),沿水平和垂直條紋并行計算注意力。此外,在諸如[12, 64]等工作中建立了局部-全局關系,通過減少對全局自注意力的依賴來提高效率。Fast-iTPN[50] 通過令牌遷移(token migration)和令牌聚集(token gathering)機制提高了下游任務的推理速度。一些方法[31,49,60,62]使用線性注意力(linear attention)來降低注意力的復雜度。盡管基于 Mamba 的視覺模型[38, 70]旨在實現線性復雜度,但它們仍然無法達到實時速度[38]。FlashAttention[13, 14] 識別出導致注意力計算效率低下的高帶寬內存瓶頸,并通過 I/O 優化來解決這些問題,減少內存訪問以提高計算效率。在本研究中,我們摒棄了復雜的設計,并提出了一種簡單的區域注意力機制(area attention mechanism)來降低注意力的復雜度。此外,我們采用 FlashAttention 來克服注意力機制固有的內存訪問問題[13,14]。

圖 2. 代表性局部注意力機制與我們的區域注意力(Area Attention)的比較。區域注意力采用最直接的平均劃分方式,將特征圖垂直或水平劃分為 l 個區域(默認為 4)。這避免了復雜操作,同時確保了大感受野,從而實現了高效率。?
3. 方法 (Approach)??
本節介紹 YOLOv12,一個從網絡架構角度結合注意力機制的 YOLO 框架創新。
3.1. 效率分析 (Efficiency Analysis)
注意力機制雖然在捕捉全局依賴關系和促進自然語言處理[5, 15]和計算機視覺[19, 39]等任務方面非常有效,但其固有速度慢于卷積神經網絡(CNN)。導致這種速度差異的主要因素有兩個。
??復雜度 (Complexity).??
首先,自注意力操作的計算復雜度隨輸入序列長度 L 呈二次方增長。具體來說,對于一個長度為 L、特征維度為 d 的輸入序列,計算注意力矩陣需要 O(L2d) 次操作,因為每個令牌(token)都需要關注其他所有令牌。相比之下,CNN 中卷積操作的復雜度在空間或時間維度上是線性的,即 O(kLd),其中 k 是卷積核大小,通常遠小于 L。因此,自注意力在計算上變得非常昂貴,特別是對于像高分辨率圖像或長序列這樣的大型輸入。
此外,另一個重要因素是,大多數基于注意力的視覺變換器(Vision Transformers),由于其復雜的設計(例如,Swin Transformer[39] 中的窗口劃分/反轉)和額外模塊的引入(例如,位置編碼),逐漸累積了速度開銷,導致其整體速度比 CNN 架構慢[38]。在本文中,設計模塊使用簡單干凈的操作來實現注意力,盡最大程度確保效率。
??計算 (Computation).??
其次,在注意力計算過程中,與 CNN 相比,內存訪問模式效率較低[13, 14]。具體來說,在自注意力期間,諸如注意力圖(QK?)和 softmax 圖(L x L)這樣的中間映射需要從高速 GPU SRAM(實際計算位置)存儲到高帶寬 GPU 內存(HBM),并在計算期間稍后檢索,而前者的讀寫速度是后者的 10 倍以上,從而導致顯著的內存訪問開銷并增加實際耗時(wall-clock time)1。此外,注意力中不規則的內存訪問模式引入了比 CNN 更多的延遲,CNN 利用結構化且局部化的內存訪問。CNN 受益于空間受限的卷積核,由于其固定的感受野和滑動窗口操作,能夠實現高效的內存緩存并減少延遲。
1?(原文腳注)實際耗時(wall-clock time):指程序從開始執行到結束所用的實際物理時間。
這兩個因素——二次計算復雜度和低效的內存訪問——共同導致注意力機制比 CNN 慢,特別是在實時或資源受限的場景中。解決這些限制已成為一個關鍵的研究領域,旨在減輕二次方縮放(quadratic scaling)的方法,如稀疏注意力機制和內存高效近似(例如,Linformer[60] 或 Performer[11])已被提出。
3.2. 區域注意力 (Area Attention)
降低原始注意力計算成本的一個簡單方法是使用線性注意力機制[49, 60],它將原始注意力的復雜度從二次方降低到線性。對于一個維度為 (n, h, d) 的視覺特征 f(其中 n 是令牌數量,h 是頭數,d 是頭大小),線性注意力將復雜度從 2n2hd 降低到 2nhd2,由于 n > d,從而降低了計算成本。然而,線性注意力存在全局依賴退化[30]、不穩定性[11]和分布敏感性[63]的問題。此外,由于低秩瓶頸[2, 10],當應用于輸入分辨率為 640 × 640 的 YOLO 時,它僅提供有限的速度優勢。
有效降低復雜度的另一種方法是局部注意力機制(例如,平移窗口[39]、十字交叉注意力[27]和軸向注意力[16]),如圖 2 所示,它將全局注意力轉換為局部注意力,從而降低計算成本。然而,將特征圖劃分為窗口會引入開銷或減少感受野,影響速度和精度。在本研究中,我們提出了簡單而高效的區域注意力模塊(Area Attention)。如圖 2 所示,將分辨率為 (H, W) 的特征圖劃分為 l 個大小為??或?
?的段。這消除了顯式的窗口劃分,只需要一個簡單的重塑(reshape)操作,從而實現更快的速度。我們經驗性地將 l 的默認值設為 4,將感受野減小到原始的 1/4?,但它仍然保持一個大的感受野。采用這種方法,注意力機制的計算成本從 2n2hd 降低到
。我們證明,盡管復雜度為 n2,但當 n 固定在 640 時(如果輸入分辨率增加,n 會增加),這仍然足夠高效以滿足 YOLO 系統的實時要求。有趣的是,我們發現這種修改對性能的影響很小,但顯著提高了速度。
3.3. 殘差高效層聚合網絡 (Residual Efficient Layer Aggregation Networks)
高效層聚合網絡(ELAN)[57]旨在改進特征聚合。如圖 3(b) 所示,ELAN 分割過渡層(一個 1x1 卷積)的輸出,通過多個模塊處理其中一個分割塊,然后連接所有輸出并應用另一個過渡層(一個 1x1 卷積)來對齊維度。然而,正如[57]所分析的,這種架構可能引入不穩定性。我們認為這樣的設計會導致梯度阻塞(gradient blocking),并且缺乏從輸入到輸出的殘差連接。此外,我們圍繞注意力機制構建網絡,這帶來了額外的優化挑戰。經驗表明,L 和 X 規模的模型要么無法收斂,要么保持不穩定,即使使用 Adam 或 AdamW 優化器也是如此。
為了解決這個問題,我們提出了殘差高效層聚合網絡(R-ELAN),如圖 3(d) 所示。作為對比,我們引入了貫穿整個塊的從輸入到輸出的殘差捷徑(residual shortcut),并帶有縮放因子(默認 0.01)。這種設計與層縮放(layer scaling)[52]相似,后者被引入用于構建深度視覺變換器。然而,對每個區域注意力應用層縮放并不能克服優化挑戰,并且會引入延遲上的減速。這表明注意力機制的引入并不是收斂困難的唯一原因,ELAN 架構本身也是原因,這驗證了我們 R-ELAN 設計背后的基本原理。
我們還設計了一種新的聚合方法,如圖 3(d) 所示。原始的 ELAN 層處理模塊的輸入時,首先將其通過一個過渡層,然后將其分割成兩部分。一部分由后續塊進一步處理,最后兩部分連接起來產生輸出。相比之下,我們的設計應用一個過渡層來調整通道維度并產生一個單一的特征圖。然后這個特征圖通過后續塊處理,再進行連接,形成一個瓶頸結構。
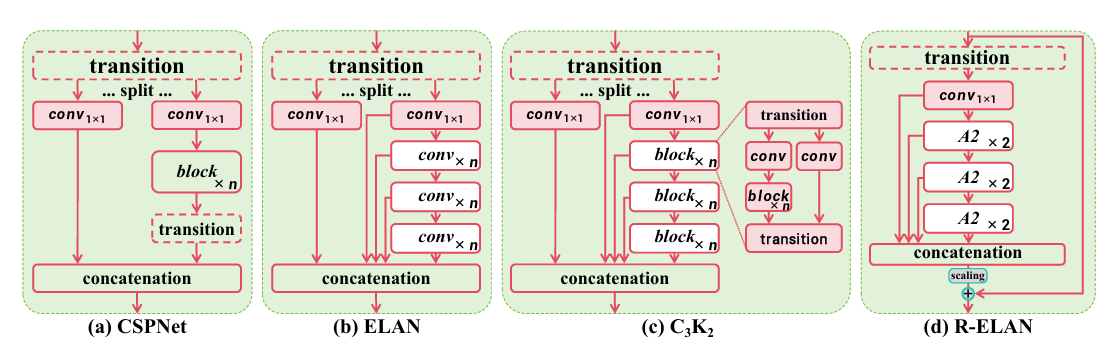
圖 3. 與流行模塊的架構比較,包括 (a):CSPNet [55], (b) ELAN [56], (c) C3K2 (GELAN 的一個實例) [28, 58], 以及 (d) 提出的 R-ELAN(殘差高效層聚合網絡)。?
這種方法不僅保留了原始的特征整合能力,還減少了計算成本和參數/內存使用量。
3.4. 架構改進 (Architectural Improvements)
在本節中,我們將介紹整體架構以及對原始注意力機制的一些改進。其中一些改進并非我們首次提出。
許多以注意力為中心的視覺變換器設計為樸素風格(plain-style)架構[1, 18, 19, 21, 25, 51],而我們保留了先前 YOLO 系統[3, 24, 28, 29, 32, 45-47, 53, 57, 58]的分層設計,并將證明其必要性。我們移除了主干網絡最后階段堆疊三個塊的設計,該設計存在于最近的版本中[24, 28, 53, 58]。相反,我們只保留一個 R-ELAN 塊,減少了塊的總數并有助于優化。我們繼承了 YOLOv11[28] 主干網絡的前兩個階段,不使用所提出的 R-ELAN。
此外,我們修改了原始注意力機制中的幾個默認配置,以更好地適應 YOLO 系統。這些修改包括:將 MLP 比率從 4 調整到 1.2(或為 N-/S-/M 規模模型調整為 2),以更好地分配計算資源以獲得更好的性能;采用?nn.Conv2d+BN(卷積+批量歸一化)代替?nn.Linear+LN(線性+層歸一化),以充分利用卷積算子的效率;移除位置編碼(positional encoding);并引入一個大的可分離卷積(7x7)(稱為位置感知器(position perceiver))來幫助區域注意力感知位置信息。這些修改的有效性將在第 4.5 節中得到驗證。
4. 實驗 (Experiment)??
本節分為四個部分:實驗設置、與流行方法的系統比較、消融研究以驗證我們的方法,以及通過可視化分析進一步探索 YOLOv12。
4.1. 實驗設置 (Experimental Setup)
我們在 MSCOCO 2017 數據集[36]上驗證所提出的方法。YOLOv12 系列包括 5 個變體:YOLOv12-N、YOLOv12-S、YOLOv12-M、YOLOv12-L 和 YOLOv12-X。所有模型均使用 SGD 優化器訓練 600 個 epoch,初始學習率為 0.01,與 YOLOv11[28]相同。我們采用線性學習率衰減計劃,并在前 3 個 epoch 執行線性預熱(warm-up)。遵循[53, 66]中的方法,所有模型的延遲均在配備 TensorRT FP16 的 T4 GPU 上進行測試。
??基線 (Baseline).??
我們選擇先前版本 YOLOv11[28] 作為基線。模型縮放策略也與其一致。我們使用了其提出的幾個 C3K2 模塊(這是 GELAN[58] 的一種特例)。我們沒有使用超出 YOLOv11[28] 的任何額外技巧。
4.2. 與最先進方法的比較 (Comparison with State-of-the-arts)
我們在表 1 中展示了 YOLOv12 與其他流行實時檢測器之間的性能比較。
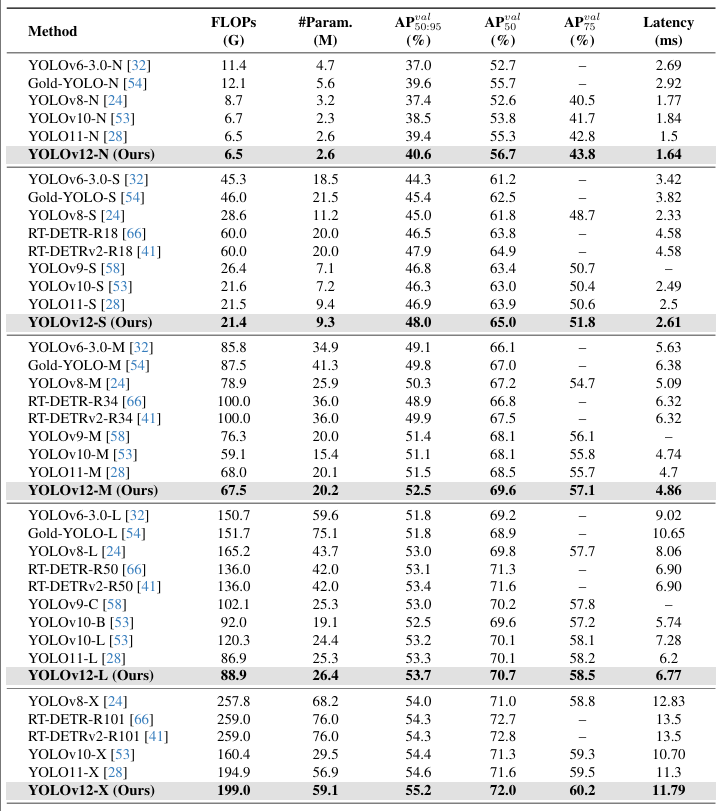
表 1. 與流行最先進實時目標檢測器的比較。所有結果均使用?640×640?輸入獲得。
對于 N 規模模型,YOLOv12-N 在 mAP 上分別優于 YOLOv6-3.0-N[32]、YOLOv8-N[24]、YOLOv10-N[53] 和 YOLOv11[28] 3.6%、3.3%、2.1% 和 1.2%,同時保持相似甚至更少的計算量和參數,并實現了 1.64 ms/圖像的快速延遲。
對于 S 規模模型,YOLOv12-S 具有 21.4G FLOPs 和 9.3M 參數,以 2.61 ms/圖像的延遲實現了 48.0 mAP。它分別優于 YOLOv8-S[24]、YOLOv9-S[58]、YOLOv10-S[53] 和 YOLOv11-S[28] 3.0%、1.2%、1.7% 和 1.1%,同時保持相似或更少的計算量。與端到端檢測器 RT-DETR-R18[66]/RT-DETRv2-R18[41] 相比,YOLOv12-S 實現了可媲美的性能,但具有更好的推理速度以及更少的計算成本和參數。
對于 M 規模模型,YOLOv12-M 具有 67.5G FLOPs 和 20.2M 參數,以 4.86 ms/圖像的速度實現了 52.5 mAP 的性能。與 Gold-YOLOvM[54]、YOLOv8-M[24]、YOLOv9-M[58]、YOLOv10[53]、YOLOv11[28] 以及 RT-DETR-R34[66]/RT-DETRv2-R34[40] 相比,YOLOv12-S 具有優越性。
對于 L 規模模型,YOLOv12-L 甚至以少 31.4G FLOPs 的優勢超越了 YOLOv10-L[53]。YOLOv12-L 以可比的 FLOPs 和參數,在 mAP 上優于 YOLOv11[28] 0.4%。YOLOv12-L 也以更快的速度、更少的 FLOPs(34.6%)和更少的參數(37.1%)優于 RT-DERT-R50[66]/RT-DERTv2-R50[41]。
對于 X 規模模型,YOLOv12-X 分別顯著優于 YOLOv10-X[53]/YOLOv11-X[28] 0.8% 和 0.6%,同時具有可比較的速度、FLOPs 和參數。YOLOv12-X 再次以更快的速度、更少的 FLOPs(23.4%)和更少的參數(22.2%)擊敗了 RT-DETR-R101[66]/RT-DETRv2-R101[40]。
特別地,如果使用 FP32 精度評估 L-/X 規模模型(這需要單獨以 FP32 格式保存模型),YOLOv12 將實現約?~0.2%?mAP 的改進。這意味著 YOLOv12-L/X 將報告 33.9%/55.4% mAP。
4.3. 消融研究 (Ablation Studies)
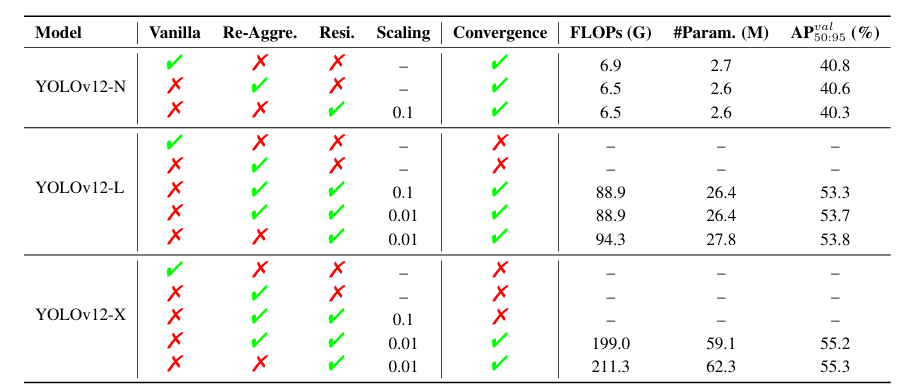
表 2. 所提出的殘差高效層聚合網絡(R-ELAN)的消融研究。Vanilla:使用原始 ELAN 設計;Re-Aggre.:采用我們提出的特征整合方法;Resi.:利用殘差塊技術;Scaling:殘差連接的縮放因子。?
● ??R-ELAN.?? 表 2 使用 YOLOv12-N/L/X 模型評估了所提出的殘差高效層聚合網絡(R-ELAN)的有效性。結果揭示了兩個關鍵發現:(i) 對于像 YOLOv12-N 這樣的小型模型,殘差連接不影響收斂但會降低性能。相反,對于大型模型(YOLOv12-L/X),它們對于穩定訓練至關重要。特別是,YOLOv12-X 需要一個最小的縮放因子(0.01)來確保收斂。(ii) 所提出的特征整合方法有效地減少了模型的 FLOPs 和參數方面的復雜性,同時僅邊際下降地保持可比性能。
● ??區域注意力 (Area Attention).?? 我們進行了消融實驗以驗證區域注意力的有效性,結果在表 3 中呈現。在 YOLOv12-N/S/X 模型上進行了評估,測量了在 GPU(CUDA) 和 CPU 上的推理速度。CUDA 結果使用 RTX 3080 和 A5000 獲得,而 CPU 性能在 Intel Core i7-10700K@ 3.80GHz 上測量。結果證明了采用區域注意力帶來的顯著加速。例如,在 RTX 3080 上使用 FP32,YOLOv12-N 的速度提高了約 0.7ms。這種加速在 FP16 和 CPU 上也是一致的。這表明區域注意力有效地減少了速度差異。
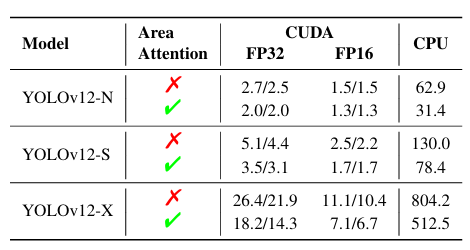
表 3. 所提出的區域注意力的消融研究。使用區域注意力(√),YOLOv12-N/S/X 模型在 GPU(CUDA)和 CPU 上運行均顯著更快。CUDA 結果在 RTX 3080/A5000 上測量。推理延遲:FP32 和 FP16 精度的毫秒(ms)。(所有結果均在不使用 FlashAttention[13,14] 的情況下獲得)?
4.4. 速度比較 (Speed Comparison)
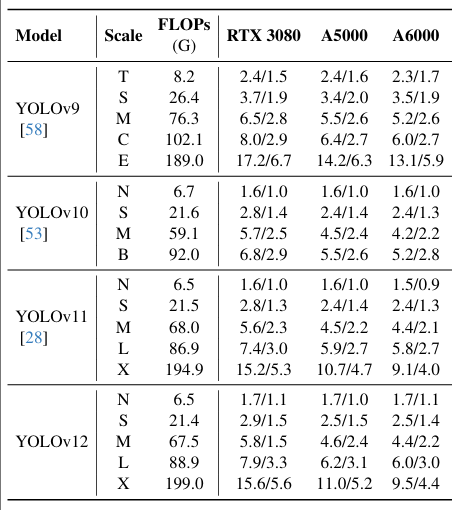
表 4. 不同 GPU(RTX 3080, RTX A5000, 和 RTX A6000)上推理速度的比較分析。推理延遲:FP32 和 FP16 精度的毫秒(ms)。?
表 4 展示了在不同 GPU(RTX 3080、RTX A5000 和 RTX A6000)上推理速度的比較分析,使用 FP32 和 FP16 精度評估了 YOLOv9[58]、YOLOv10[53]、YOLOv11[28] 和我們的 YOLOv12。為確保一致性,所有結果均在同一硬件上獲得,并使用 ultralytics[28] 的集成代碼庫評估 YOLOv9[58] 和 YOLOv10[53]。結果表明,YOLOv12 實現了比 YOLOv9[58] 顯著更高的推理速度,同時與 YOLOv10[53] 和 YOLOv11[28] 相當。例如,在 RTX 3080 上,YOLOv9 報告為 2.4 ms (FP32) 和 1.5 ms (FP16),而 YOLOv12-N 實現了 1.7 ms (FP32) 和 1.1 ms (FP16)。類似的趨勢在其他配置中也成立。
圖 4 展示了額外的比較。左子圖展示了與流行方法的精度-參數權衡比較,其中 YOLOv12 建立了一個超越同類方法的優勢邊界,甚至超過了 YOLOv10(一個以顯著更少參數為特點的 YOLO 版本),展示了 YOLOv12 的有效性。我們在右子圖中比較了 YOLOv12 與先前 YOLO 版本在 CPU 上的推理延遲(所有結果均在 Intel Core i7-10700K@ 3.80GHz 上測量)。如圖所示,YOLOv12 以更有利的邊界超越了其他競爭者,突顯了其在多樣化硬件平臺上的效率。
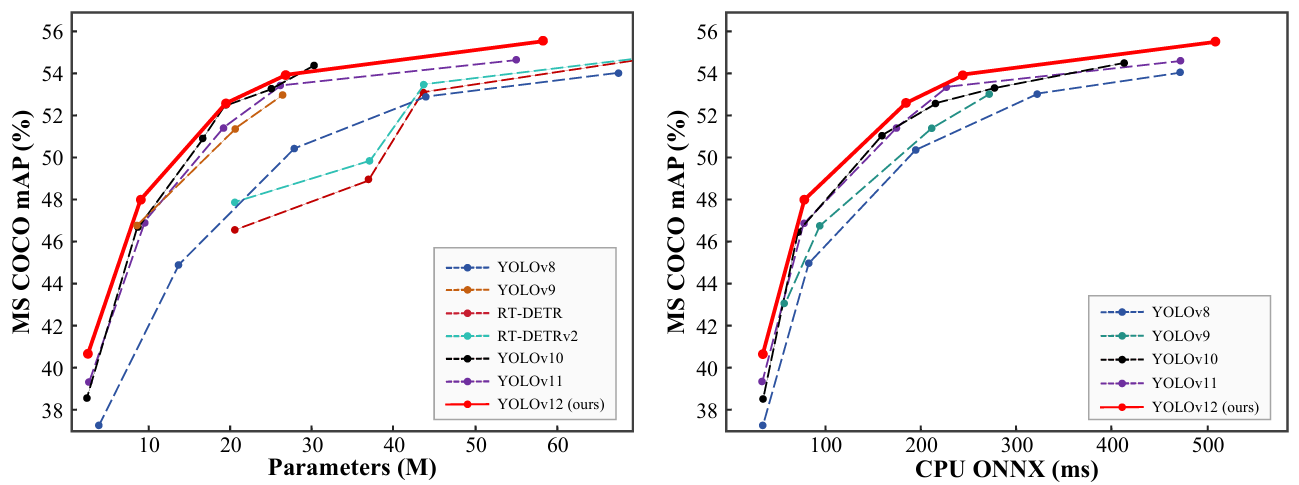
圖 4. 與流行方法在精度-參數(左)和 CPU 上精度-延遲權衡(右)方面的比較。?
4.5. 診斷與可視化 (Diagnosis & Visualization)
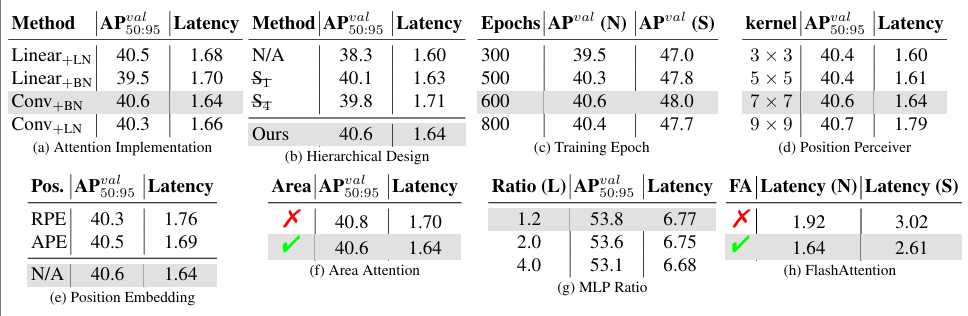
表 5. 診斷研究。為節省空間,我們僅在每個子表中顯示待診斷的因子。默認參數為(除非另有說明):使用 YOLOv12-N 模型從頭開始訓練 600 個周期。?
我們在表 5a 至 5h 中診斷了 YOLOv12 的設計。除非另有說明,我們在 YOLOv12-N 上執行這些診斷,默認從頭開始訓練 600 個 epoch。
● ??注意力實現 (Attention Implementation):?? 表 5a。我們檢查了實現注意力的兩種方法。基于卷積的方法由于卷積的計算效率而比基于線性(linear-based)的方法更快。此外,我們探索了兩種歸一化方法(層歸一化 (LN) 和批量歸一化 (BN)),發現結果:雖然層歸一化通常用于注意力機制,但與卷積一起使用時,其性能不如批量歸一化。值得注意的是,這已在 PSA 模塊[53]中使用,我們的發現與其設計一致。
● ??分層設計 (Hierarchical Design):?? 表 5b。與其他檢測系統(如 Mask R-CNN[1,25])不同,其中樸素視覺變換器的架構可以產生強大的結果,YOLOv12 表現出不同的行為。當使用樸素視覺變換器(N/A)時,檢測器的性能顯著下降,僅達到 38.3% mAP。一個更溫和的調整,例如省略第一階段(ST)或第四階段(S),同時通過調整特征維度保持相似的 FLOPs,分別導致輕微的性能下降 0.5% mAP 和 0.8% mAP。與先前的 YOLO 模型一致,分層設計仍然是最有效的,在 YOLOv12 中產生最佳性能。
● ??訓練周期 (Training Epochs):?? 表 5c。我們檢查了改變訓練周期數量對性能(從頭開始訓練)的影響。雖然一些現有的 YOLO 檢測器在大約 500 個訓練周期后達到最佳結果[24, 53, 58],但 YOLOv12 需要更長的訓練周期(約 600 個 epoch)才能達到峰值性能,保持與 YOLOv11[28] 相同的配置。
● ??位置感知器 (Position Perceiver):?? 表 5d。在注意力機制中,我們應用了一個具有大卷積核的可分離卷積到注意力值 v,將其輸出加到 v@attn。我們將此組件稱為位置感知器(Position Perceiver),因為卷積的平滑效應保留了圖像像素的原始位置,它有助于注意力機制感知位置信息(這已在 PSA 模塊[53]中使用,但我們擴展了卷積核,在不影響速度的情況下實現了性能改進)。如表所示,增加卷積核大小提高了性能但逐漸降低了速度。當核大小達到 9x9 時,減速變得顯著。因此,我們將 7x7 設置為默認核大小。
● ??位置嵌入 (Position Embedding):?? 表 5e。我們檢查了大多數基于注意力的模型中常用的位置嵌入(RPE:相對位置嵌入; APE:絕對位置編碼)對性能的影響。有趣的是,性能最佳的配置是在沒有任何位置嵌入的情況下實現的,這帶來了更簡潔的架構和更快的推理延遲。
● ??區域注意力 (Area Attention):?? 表 5f。在此表中,我們默認使用 FlashAttention 技術。這導致雖然區域注意力機制增加了計算復雜度(帶來性能提升),但由此產生的減速仍然很小。關于區域注意力有效性的進一步驗證,請參閱表 3。
● ??MLP 比率 (MLP Ratio):?? 表 5g。在傳統的視覺變換器中,注意力模塊內的 MLP 比率通常設置為 4.0。然而,我們在 YOLOv12 中觀察到了不同的行為。在表中,改變 MLP 比率會影響模型大小,因此我們調整特征維度以保持整體模型一致性。特別是,YOLOv12 在 MLP 比率為 1.2 時實現了更好的性能,這背離了常規做法。這種調整將計算負載更多地轉向注意力機制,突顯了區域注意力的重要性。
● ??FlashAttention:?? 表 5h。此表驗證了 FlashAttention 在 YOLOv12 中的作用。它顯示 FlashAttention 將 YOLOv12-N 加速約 0.3ms,將 YOLOv12-S 加速約 0.4ms,且沒有其他成本。

?圖 5. YOLOv10[53]、YOLOv11[28] 和所提出的 YOLOv12 的熱力圖比較。與先進的 YOLOv10 和 YOLOv11 相比,YOLOv12 展示了對圖像中目標更清晰的感知。所有結果均使用 X 規模模型獲得。放大查看以比較細節。??
可視化:熱力圖比較 (Visualization: Heat Map Comparison).?? 圖 5 比較了 YOLOv12 與最先進的 YOLOv10[53] 和 YOLOv11[28] 的熱力圖。這些熱力圖是從 X 規模模型主干的第三階段提取的,突出了模型激活的區域,反映了其目標感知能力。如圖所示,與 YOLOv10 和 YOLOv11 相比,YOLOv12 產生了更清晰的目標輪廓和更精確的前景激活,表明感知能力得到改善。我們的解釋是,這種改進源于區域注意力機制,它比卷積網絡具有更大的感受野,因此被認為更擅長捕捉整體上下文,從而產生更精確的前景激活。我們相信這一特性賦予了 YOLOv12 性能優勢。
5. 結論 (Conclusion)??
本研究提出了 YOLOv12,它成功地將傳統上被認為難以滿足實時要求的以注意力為中心的設計引入到 YOLO 框架中,實現了最先進的延遲-精度權衡。為了實現高效推理,我們提出了一種新穎的網絡,該網絡利用區域注意力(area attention)來降低計算復雜度,并利用殘差高效層聚合網絡(R-ELAN)來增強特征聚合。此外,我們改進了原始注意力機制的關鍵組件,以更好地適應 YOLO 的實時約束,同時保持高速性能。因此,YOLOv12 通過有效結合區域注意力、R-ELAN 和架構優化,實現了最先進的性能,在精度和效率方面都帶來了顯著提升。全面的消融研究進一步驗證了這些創新的有效性。本研究挑戰了 CNN 基于設計在 YOLO 系統中的主導地位,并推進了注意力機制在實時目標檢測中的集成,為更高效、更強大的 YOLO 系統鋪平了道路。
??6. 局限性 (Limitations)??
YOLOv12 需要 FlashAttention[13, 14],該庫目前支持 Turing、Ampere、Ada Lovelace 或 Hopper 架構的 GPU(例如,T4, Quadro RTX 系列, RTX20 系列, RTX30 系列, RTX40 系列, RTX A5000/6000, A30/40, A100, H100 等)。
??7. 更多細節 (More Details)??
??微調細節 (Fine-tuning Details).?? 默認情況下,所有 YOLOv12 模型都使用 SGD 優化器訓練 600 個 epoch。遵循先前的工作[24, 53, 57, 58],SGD 動量和權重衰減分別設置為 0.937 和 5 x 10??。初始學習率設置為?1×10?2,并在整個訓練過程中線性衰減至?1×10?4。應用數據增強技術,包括 Mosaic[3, 57]、Mixup[71] 和 copy-paste 增強[65] 來提升訓練效果。遵循 YOLOv11[28],我們采用 Albumentations 庫[6]。詳細的超參數如表 7 所示。所有模型均在 8 張 NVIDIA A6000 GPU 上訓練。遵循既定慣例[24, 28, 53, 58],我們在不同目標尺度和 IoU 閾值上報告標準平均精度(mAP)。此外,我們報告所有圖像的平均延遲。我們建議在官方代碼庫查看更多細節:https://github.com/sunsmarterjie/yolov12。
??結果細節 (Result Details).?? 我們在表 6 中報告了結果的更多細節。
表6:YOLOv12在COCO數據集上的詳細表現。









![洛谷 P3478 [POI 2008] STA-Station](http://pic.xiahunao.cn/洛谷 P3478 [POI 2008] STA-Station)










