LC 585 2016年的投資
思路:
本題思路好想 , 就是把2015年投資相同的找出來 ,再找出這其中經緯度不同的id對應的2016年的保險。
實際操作中, 發現用group by很麻煩, 那么想到窗口函數也能 分組進行統計
利用 count() over (partition by)可以分組統計的同時 ,不合并原始行 , 可以很方便的查找出符合條件的行。
with temp as(
select Insurance.pid ,
tiv_2016,
count(*) over(partition by tiv_2015) cnt ,
count(*) over(partition by lat , lon) cnt2
from Insurance)select round(sum(tiv_2016) , 2) as tiv_2016 from temp
where cnt > 1 and cnt2 = 1知識點:
1.partition by 相關語法?
count(*) over(partition by column1[column2]) 和group by 一樣 ,partition by 后面可以加多個字段 ,這些字段全都相同的才視為同一組。
2.group by相關語法
一開始用group by , 寫出這樣的語句
select pid from Insurance
group by tiv_2015 having count(tiv_2015) > 1
以為可以從這張表中找出 pid為1,3,4
但事實上,
- ??GROUP BY tiv_2015??:將數據按?
tiv_2015?分組,得到以下分組:tiv_2015 = 10:包含?pid = 1, 3, 4。tiv_2015 = 20:包含?pid = 2。
- ??HAVING COUNT(...) > 1??:保留重復的?
tiv_2015?分組(即?tiv_2015 = 10)。 - ??SELECT pid??:由于?
pid?不在?GROUP BY?中且非聚合列,數據庫會從?tiv_2015 = 10?的分組中 ??隨機選擇一個?pid??(如?1)。
根本原因在于 select的列必須在group by的列中 , 或者跟著聚合函數才行!
LC 185 部門工資前三高的員工
知識點
和排名相關的窗口函數
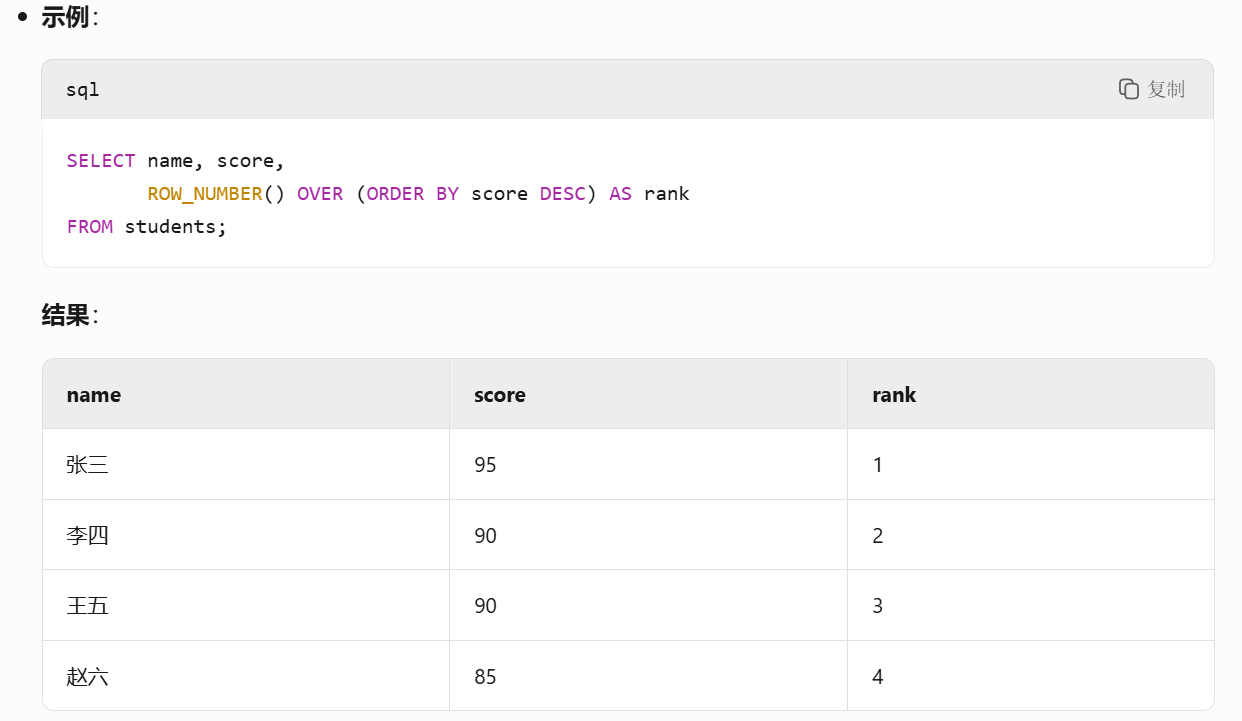
1.ROW_NUMBER()
ROW_NUMBER() OVER (ORDER BY column [ASC|DESC])它會為每一行分配連續的序號,不管值相不相同.
2.rank()
為每一行分配排名,相同值共享同一排名,后續排名跳過重復位次。
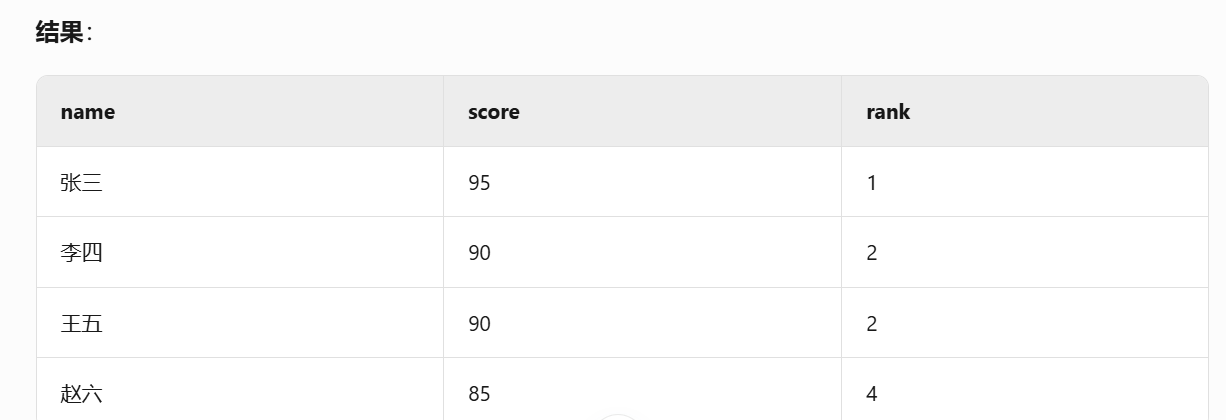
3.dense_rank()
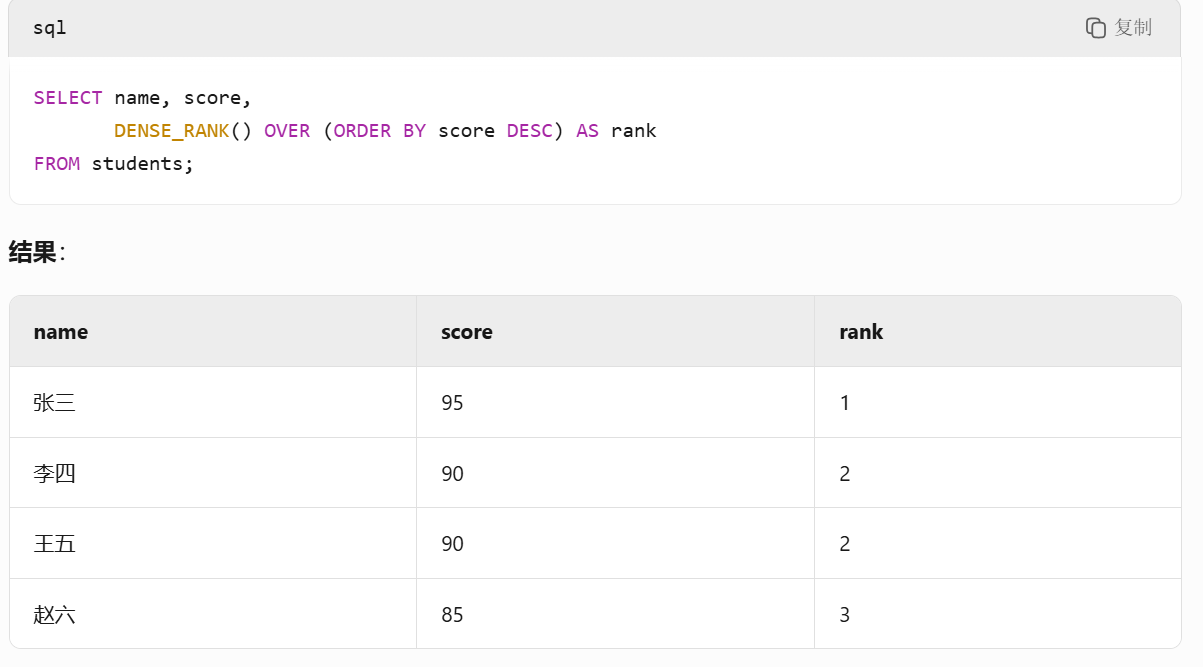
為每一行分配排名,相同值共享同一排名,后續排名不跳位。
注意,所有和排序相關的窗口函數 , 都必須 跟 order by?
這幾種排序的窗口函數 , 符合題意得是第三種,代碼如下:
with temp as
(select d.name Department ,e.name Employee , salary,
dense_rank() over(partition by d.id order by salary desc ) rk
from Employee e inner join Department d on e.departmentId = d.id)select Department , Employee , salary as Salary from temp
where rk <= 3LC1527 患某種疾病的患者
知識點:like的相關語法
like用于mysql中字符串的模糊匹配 ,
1.?LIKE 'abc%'?
表示 以abc開頭的字符串 ,%為通配占位符
2.LIKE '%abc%'
表示包含了abc的字符串
3.LIKE '%abc'?
表示包含以abc結尾的字符串。
記憶方法在于:%在哪邊 , 表示哪邊可以有其他的字符串內容
4. _ 占位符
用于匹配單個字符
-- 匹配第2個字符為 "a" 的字符串(如 "ba", "cat")
WHERE column LIKE '_a%';-- 匹配長度為3且第3個字符為 "x" 的字符串(如 "abx", "1x2")
WHERE column LIKE '__x';本體思路:
一個坑點在于, 糖尿病的字符串必須以 “DIAB1”開頭 ,SADIAB100并不是糖尿病
那么, 如何判斷給出的condition中包不包含“DIAB1”呢?
這里就用到like了 ,?
分兩種情況判斷 ,
1.DIAB1位于condition的開頭 , 那么用 like 'DIAB1%'即可
2.DIAB1位于condition的中間, 而題目明確指出 , condition字符串中, 不同病癥用空格分隔,
那么 要判斷DIAB1是否包含在字符串中 , 就是判斷? ' DIAB1'(DIAB1加了個空格)是否完整出現
使用like '% DIAB1'
select patient_id , patient_name , conditions
from Patients
where conditions like 'DIAB1%' or conditions like '% DIAB1%'

.openEndDrawer();不生效問題)


)


)

實現路徑損耗預測)








