概覽
到2025年,雖然PET(Pattern-Exploiting Training)和Prompt Tuning在學術界仍有探討,但在工業和生產環境中它們已基本被LoRA/QLoRA等參數高效微調(PEFT)方法取代 。LoRA因其實現簡單、推理零開銷,并能在大規模模型上以極少量參數達到與全量微調相當的效果,已成為最受歡迎的PEFT技術 。QLoRA在此基礎上再結合4-bit量化,使得即便是65B級模型也能在單塊48 GB GPU上完成微調,內存占用降低近3倍,性能幾乎無損 。
1 PET 與 Prompt Tuning ,P-Tuning 的現狀
1.1 PET(Pattern-Exploiting Training)
PET于2021年在EACL提出,通過“Pattern + Verbalizer Pair”(PVP)將分類和推理任務轉換為完形填空問題來利用預訓練模型 。
然而,由于其需要手工設計模板、映射詞表,且在真正生產環境中難以自動化部署,PET已很少在實際項目中使用,大多數團隊已轉向更為通用且自動化程度更高的PEFT方法 。所以懶得寫PET了。直接看后面ptuning和lora,
1.2 Prompt Tuning
Prompt Tuning(又稱Soft Prompt Tuning)在2021年提出,直接對輸入端添加 L 個可訓練嵌入向量,僅更新這部分參數來適配下游任務 。
盡管Prompt Tuning在少樣本和學術基準上表現良好,但因其訓練不穩定、對超大模型需要較長的收斂時間,故在商業產品中采用的越來越少,主要用于研究和小規模試驗場景 。
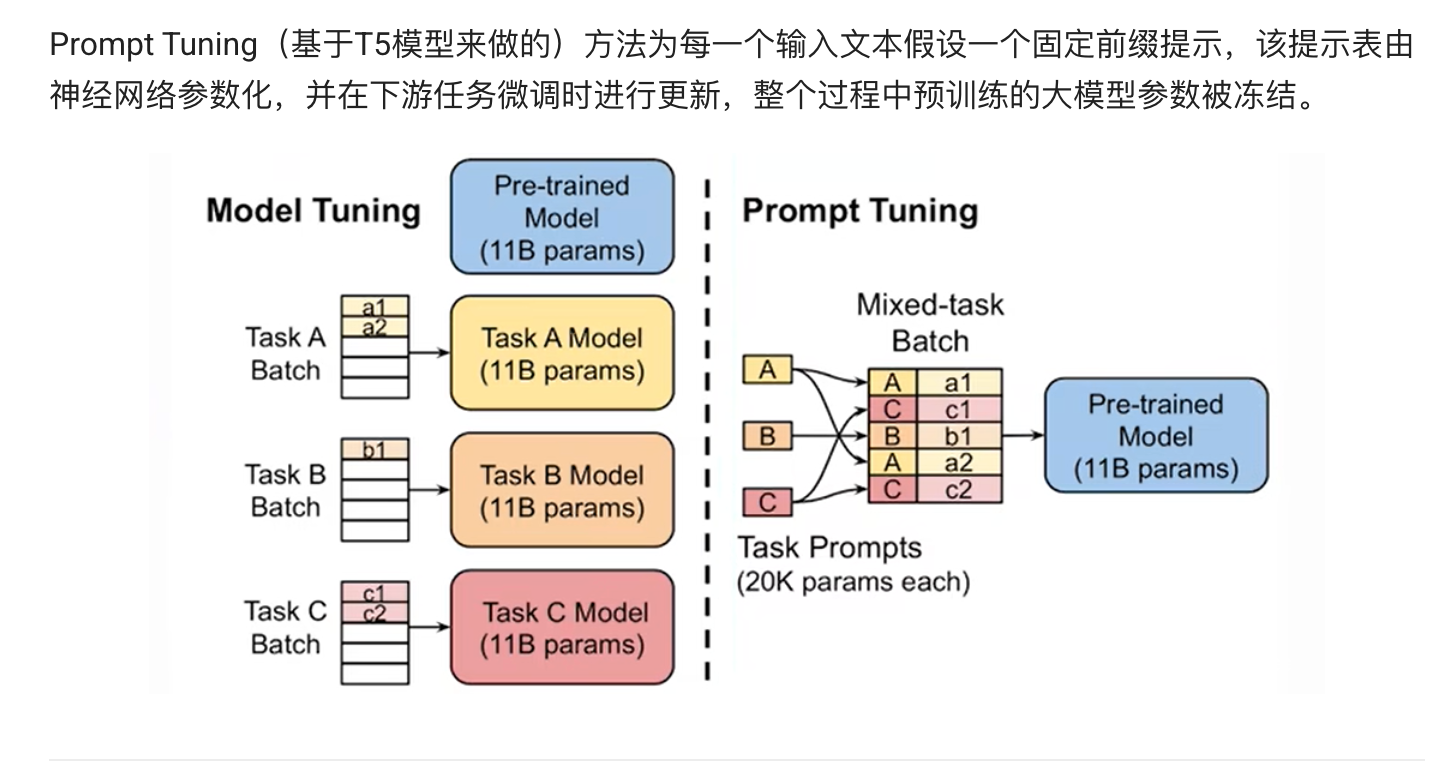
?
說明:Prompt Tuning 直接將一段可訓練的向量拼接到輸入端,凍結主模型權重,僅優化這段“軟提示”及下游頭部參數。
# ——— 1. 準備模型 ——————————————————————————————
model = load_pretrained_model("bert-base-uncased") # 加載預訓練模型 [oai_citation:0?ACL Anthology](https://aclanthology.org/2021.emnlp-main.243/?utm_source=chatgpt.com)
freeze_parameters(model) # 凍結所有模型參數# 初始化可訓練的“軟提示”向量 (L × H)
L = 20 # Prompt 長度
H = model.config.hidden_size
prompt = RandomTensor(shape=(L, H), requires_grad=True) # 新增一個線性分類頭
classifier = Linear(H, num_labels) # num_labels 為類別數optimizer = AdamW([prompt, *classifier.parameters()], lr=1e-3)# ——— 2. 訓練循環 ——————————————————————————————
for epoch in range(num_epochs):for input_ids, labels in dataloader:# 2.1 獲取原始 token embeddings → [B, N, H]emb = model.embeddings(input_ids) # 2.2 在序列前拼接軟提示 → [B, L+N, H]pref = prompt.unsqueeze(0).expand(emb.size(0), -1, -1)inputs_embeds = concat(pref, emb, dim=1) # 2.3 僅給 embeddings,繞過原始 token‐to‐id 過程outputs = model.encoder(inputs_embeds) # 2.4 取第 L 個位置的輸出作為 “CLS” 表示 → [B, H]cls_repr = outputs[:, L, :] # 2.5 分類 & 計算損失logits = classifier(cls_repr)loss = CrossEntropy(logits, labels)# 2.6 反向只更新 prompt 和分類頭loss.backward()optimizer.step()optimizer.zero_grad()1.3 P Tuning?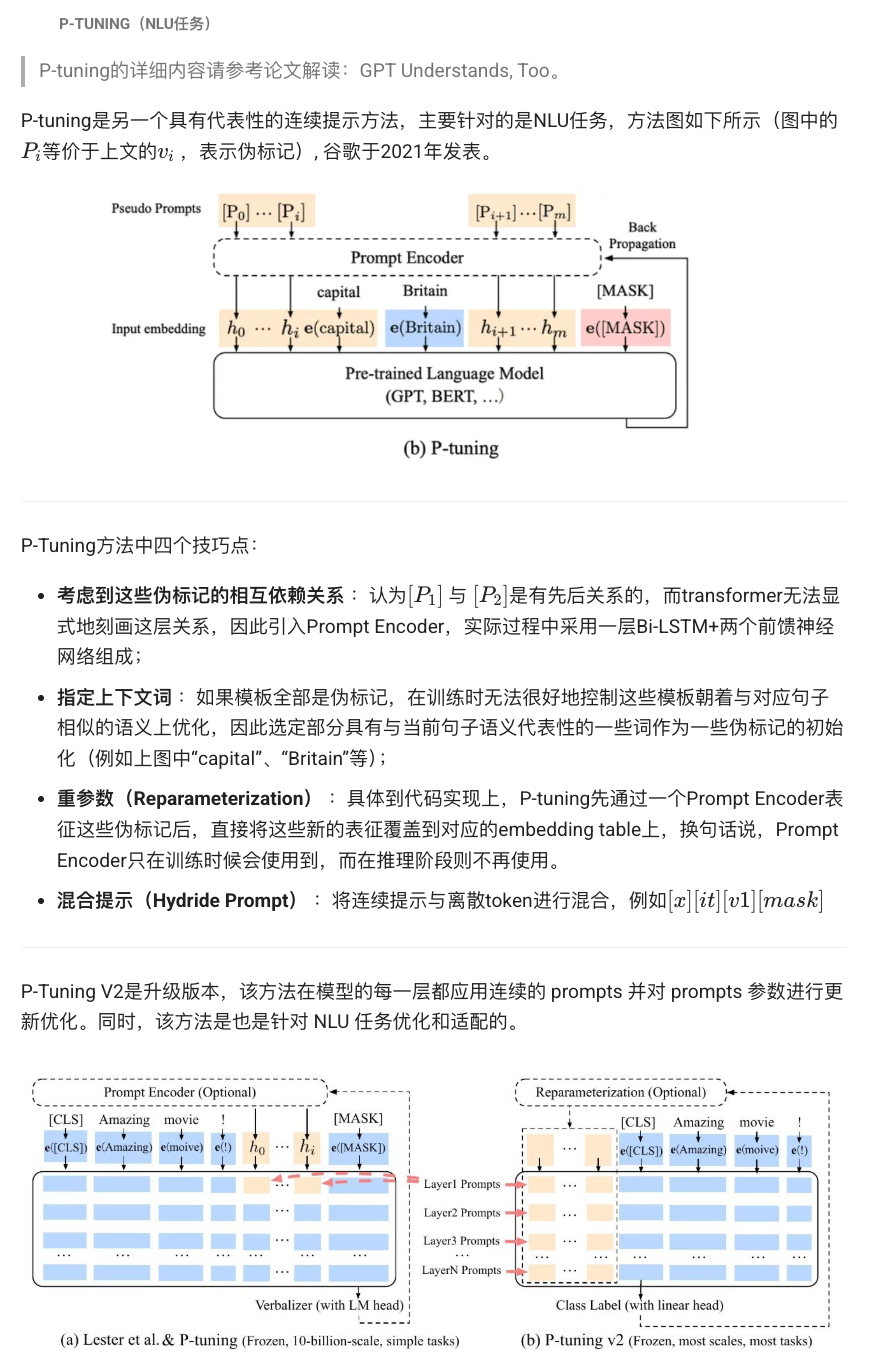
說明:P-Tuning 除了學習可訓練提示向量外,還通過一個小型網絡(如 LSTM 或 MLP)對提示向量進一步編碼,穩定并提升少樣本學習效果。
# ——— 1. 準備模型 ——————————————————————————————
model = load_pretrained_model("bert-base-uncased") # 加載預訓練模型 [oai_citation:3?arXiv](https://arxiv.org/abs/2103.10385?utm_source=chatgpt.com)
freeze_parameters(model) # 凍結所有模型參數# 定義 L 個“偽 token”ID,對應潛在的提示 embedding
L = 20
pseudo_ids = range(L)# 從模型 embedding table 提取初始向量 → [L, H]
H = model.config.hidden_size
init_emb = model.embeddings(pseudo_ids) # 定義一個 Prompt Encoder(LSTM/MLP)將 init_emb 映射到最終 prompt_emb
prompt_encoder = LSTM(input_size=H, hidden_size=H) # 新增分類頭
classifier = Linear(H, num_labels)optimizer = AdamW([*prompt_encoder.parameters(), *classifier.parameters()], lr=1e-3)# ——— 2. 訓練循環 ——————————————————————————————
for epoch in range(num_epochs):for input_ids, labels in dataloader:B, N = input_ids.size()# 2.1 用 Prompt Encoder 編碼初始偽 token 嵌入 → [1, L, H]prompt_emb, _ = prompt_encoder(init_emb.unsqueeze(0))prompt_emb = prompt_emb.expand(B, -1, -1) # → [B, L, H]# 2.2 獲取原始 token embeddings → [B, N, H]emb = model.embeddings(input_ids)# 2.3 拼接 prompt_emb 與 emb → [B, L+N, H]inputs_embeds = concat(prompt_emb, emb, dim=1)# 2.4 前向并行計算全序列輸出outputs = model.encoder(inputs_embeds)# 2.5 取第 L 個位置的向量作為分類表示 → [B, H]cls_repr = outputs[:, L, :]# 2.6 分類 & 計算損失logits = classifier(cls_repr)loss = CrossEntropy(logits, labels)# 2.7 反向僅更新 Prompt Encoder 與分類頭loss.backward()optimizer.step()optimizer.zero_grad()2 LoRA/QLoRA 的主導地位
2.1 LoRA(Low-Rank Adaptation)
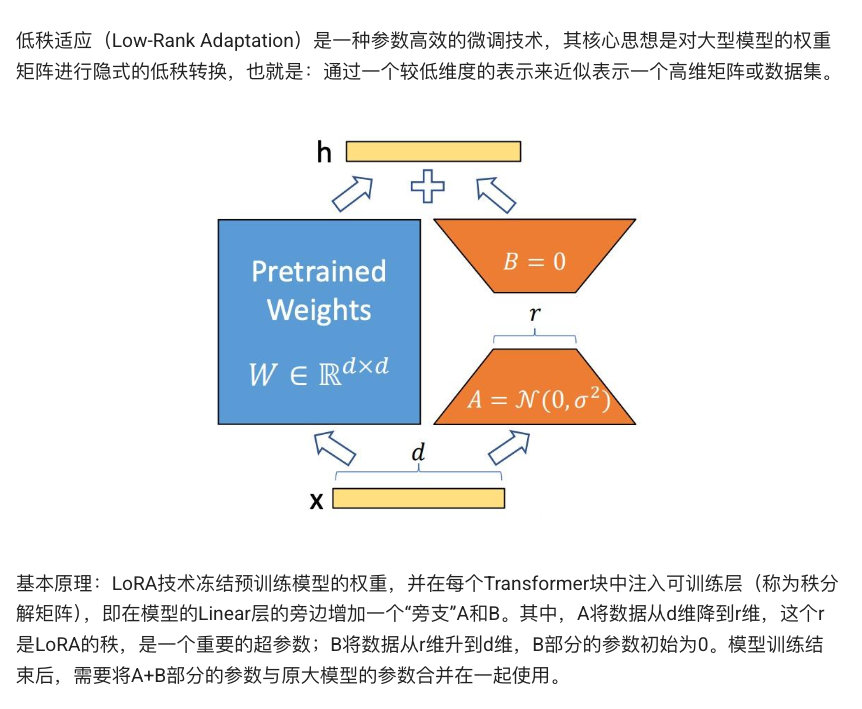

LoRA于2021年問世,通過凍結Transformer的主干權重,在每層線性映射旁支注入兩段低秩矩陣 A 與 B,僅訓練 A,B,可訓練參數量減少約10,000倍,且推理階段無額外延遲 。
實際項目中,LoRA因其“插拔式”適配、易于在各種框架中集成(如Hugging Face PEFT、ColossalAI等),幾乎成為所有PEFT管道的默認選擇 。
# 1. 初始化
model = GPTForCausalLM.from_pretrained("gpt2") # 加載預訓練 GPT-2
freeze_parameters(model) # 凍結所有原有參數# 2. 注入 LoRA 適配器
r = 8 # 低秩矩陣秩 rank
alpha = 16 # 縮放因子
for layer in model.transformer.h: # 遍歷 Transformer 每一層# 攔截自注意力和前饋層的 Linearfor name in ["c_attn", "c_proj", "mlp.c_fc", "mlp.c_proj"]:W = getattr(layer, name) # 原線性層# 保存原權重,用于推理時合并W.requires_grad = False # 新增 A、B 兩段可訓練矩陣A = nn.Parameter(torch.randn(W.in_features, r) * 0.01)B = nn.Parameter(torch.zeros(r, W.out_features))layer.register_parameter(f"{name}_lora_A", A)layer.register_parameter(f"{name}_lora_B", B)# 3. 前向時疊加低秩更新
def lora_forward(x, W, A, B):return x @ W.weight + (alpha / r) * (x @ A @ B)# 4. 替換每個需要微調的 Linear 層前向
for layer in model.transformer.h:for name in ["c_attn", "c_proj", "mlp.c_fc", "mlp.c_proj"]:orig_linear = getattr(layer, name)A = getattr(layer, f"{name}_lora_A")B = getattr(layer, f"{name}_lora_B")# 用閉包 Capture 原 Linear、A、Bdef new_forward(x, _orig=orig_linear, _A=A, _B=B):return lora_forward(x, _orig, _A, _B)orig_linear.forward = new_forward# 5. 訓練循環:僅更新 A、B 矩陣
optimizer = AdamW(filter(lambda p: p.requires_grad, model.parameters()), lr=1e-4)
model.train()
for batch in dataloader:outputs = model(**batch) # 包括 input_ids, attention_mask, labelsloss = outputs.lossloss.backward()optimizer.step()optimizer.zero_grad()LoRA 凍結預訓練模型權重,在每個線性層旁路注入低秩矩陣,只訓練這部分額外參數。LoRA 可在保持原模型推理效率的同時,將可訓練參數減少 10,000 倍,且不增加推理延遲
2.2 QLoRA(Quantized LoRA)
QLoRA在LoRA之上先將預訓練模型量化至4-bit(NF4),再凍結量化權重并僅訓練LoRA分支,顯存占用降低近3倍,卻保持與16-bit LoRA幾乎相同的性能,被用于在單塊48 GB GPU上微調65B參數模型(如Guanaco)至近ChatGPT水平 。
# 1. 初始化與 4-bit 量化
model = GPTForCausalLM.from_pretrained("gpt2")
freeze_parameters(model)
# bitsandbytes 提供的 4-bit 量化函數
for name, param in model.named_parameters():param.data = quantize_4bit(param.data, dtype="nf4") # NF4 量化# 2. 注入 LoRA(與上述 LoRA 步驟一致)
r = 8; alpha = 16
for layer in model.transformer.h:for name in ["c_attn", "c_proj", "mlp.c_fc", "mlp.c_proj"]:W = getattr(layer, name)W.requires_grad = FalseA = nn.Parameter(torch.randn(W.in_features, r) * 0.01)B = nn.Parameter(torch.zeros(r, W.out_features))layer.register_parameter(f"{name}_lora_A", A)layer.register_parameter(f"{name}_lora_B", B)# 3. 替換前向(同 LoRA)
# …(如上)# 4. 訓練循環:僅更新 A、B
optimizer = AdamW(filter(lambda p: p.requires_grad, model.parameters()), lr=5e-5)
model.train()
for batch in dataloader:outputs = model(**batch) loss = outputs.loss loss.backward() optimizer.step() optimizer.zero_grad()?
QLoRA 首先將模型權重量化到 4-bit,然后在量化模型上應用 LoRA 適配器,僅訓練低秩矩陣,極大節省顯存并保持性能
QLoRA 能在單卡 48 GB GPU 上微調百億級模型,且性能與 16-bit LoRA 相當
?
?LoRA 與 QLoRA 在自回歸 GPT 模型上的核心實現思路,二者的唯一區別在于 步驟 1:是否對模型權重做 4-bit 量化。
小結
-
PET與Prompt Tuning:學術價值依舊,但因可用性、自動化程度及訓練效率原因,已在工業界被LoRA/QLoRA等PEFT所取代;
-
LoRA/QLoRA:憑借參數效率、推理零成本及與量化結合的超低資源需求,成為2025年主流的高效微調方案。
若您正在為生產環境選擇PEFT技術,建議優先考慮LoRA及其量化變體QLoRA,并輔以Hugging Face PEFT、ColossalAI等工具鏈來快速集成與部署。
?







)
)










