KIMI-VL TECHNICAL REPORT
-
原文摘要
-
核心模型:Kimi-VL
-
模型架構:基于 MoE 設計,僅激活語言解碼器的 2.8B 參數(Kimi-VL-A3B),在保持高效計算的同時實現高性能。
- MoE(Mixture of Experts,混合專家模型): 一種通過動態激活模型中的部分參數來處理任務的架構設計
- 模型由多個小型子網絡(專家)組成,每個專家擅長處理特定類型的數據或任務。
- 雖然模型總參數量可能很大(例如千億級),但實際計算時僅激活少量參數,實現高效推理。
- MoE(Mixture of Experts,混合專家模型): 一種通過動態激活模型中的部分參數來處理任務的架構設計
-
核心能力:
- 多模態推理:支持圖像、視頻、OCR、數學推理、多圖像理解等復雜任務。
- 長上下文理解:擴展至 128K 上下文窗口,在長視頻和長文檔任務中表現優異。
- 高分辨率視覺處理:通過 MoonViT 視覺編碼器 直接處理原生分辨率圖像,在 InfoVQA和 ScreenSpot-Pro等任務中領先,同時計算成本更低。
-
性能對比
-
-
對標模型:與當前高效 VLMs 競爭,包括 GPT-4o-mini、Qwen2.5-VL-7B、Gemma-3-12B-IT,并在部分領域(如長上下文、高分辨率理解)超越 GPT-4o。
-
通用任務表現:在多輪智能體任務(如 OSWorld)中匹配主流大模型,展現強大的通用性。
- 進階變體:Kimi-VL-Thinking
-
訓練方法:通過 長鏈思維(CoT)監督微調(SFT)和強化學習(RL)優化,專注于長程推理能力。
-
性能亮點:
- 復雜任務得分:MMMU(61.7)、MathVision(36.8)、MathVista(71.3),在僅激活 2.8B 參數的條件下,樹立了高效多模態推理模型的新標桿。
-
- 進階變體:Kimi-VL-Thinking
-
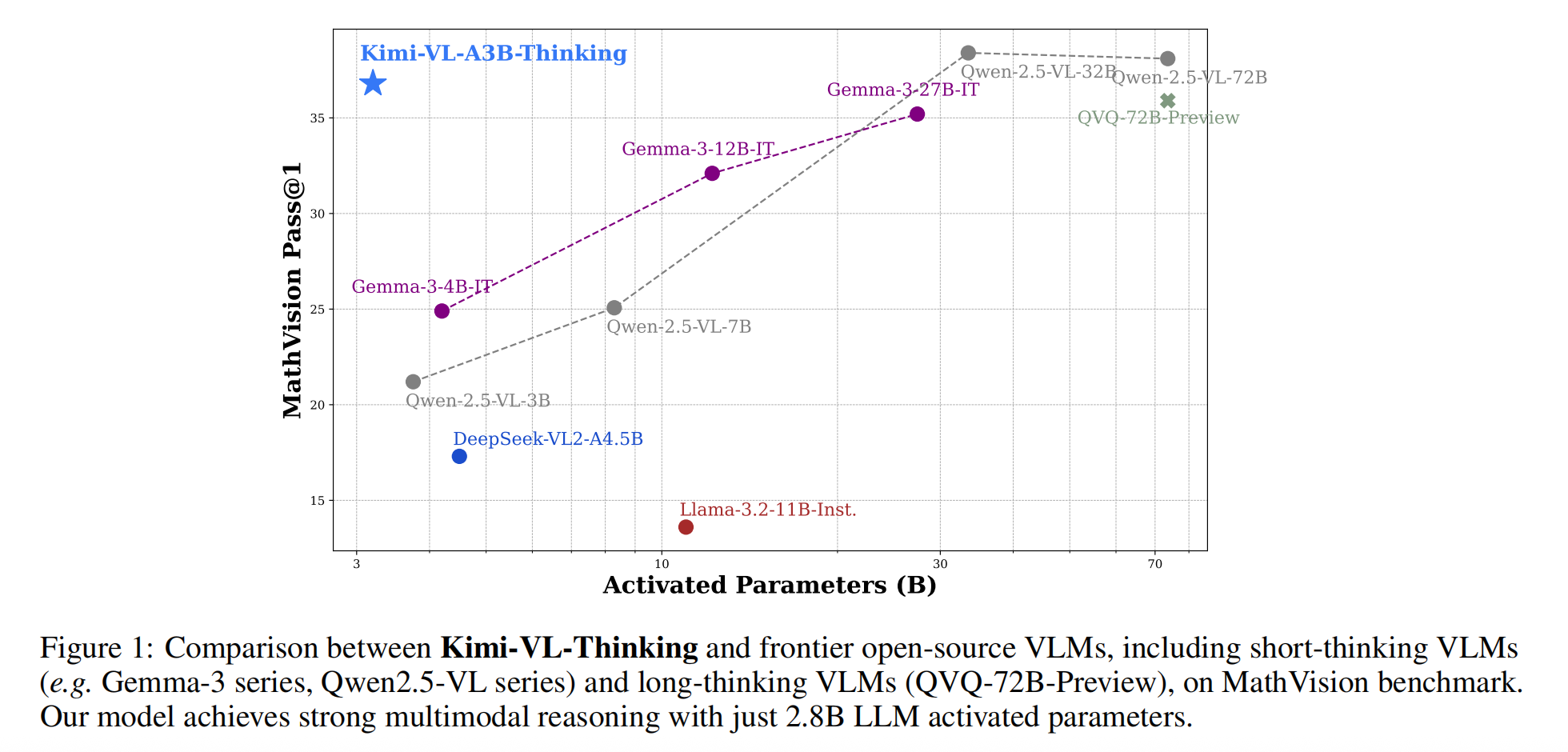
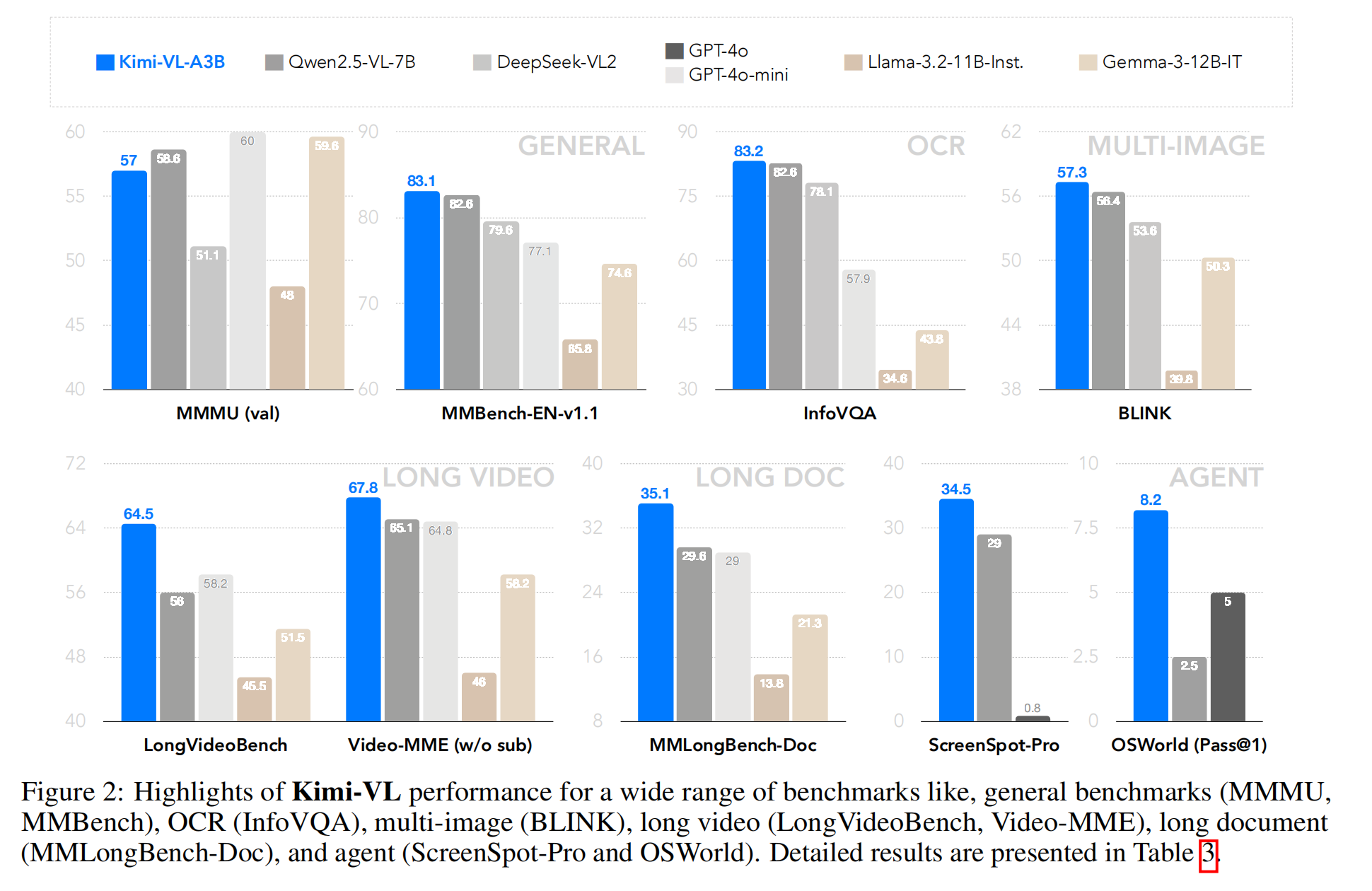
1. Introduction
-
研究背景與行業趨勢
-
多模態交互成為剛需:
- 人類對AI的期待已超越純文本交互,轉向更自然的多模態理解(如GPT-4o、Gemini)。
- 最新模型(如OpenAI o1、Kimi k1.5)進一步推動 多模態長鏈推理(long-CoT),解決更復雜問題。
-
開源VLMs的滯后性:
- 相比純文本模型(如DeepSeek R1),開源VLMs在可擴展性、計算效率、長鏈推理上顯著落后
- 現有模型(如Qwen2.5-VL、Gemma-3)仍依賴稠密架構,不支持長鏈推理
- 早期MoE-VLMs(如DeepSeek-VL2、Aria)存在視覺編碼器僵化、上下文窗口短(4K)、細粒度視覺任務弱 等問題。
-
關鍵問題:
- 開源社區需要一個結構創新、能力穩定、支持長鏈推理的VLM。
-
-
Kimi-VL的核心貢獻
-
架構創新
-
高效MoE語言模型:
- 基于 Moonlight MoE架構,僅激活 2.8B參數(總量16B),計算成本低。
-
原生高分辨率視覺編碼器:
- MoonViT(400M參數)支持原生分辨率輸入,適應多樣視覺場景(如OCR、屏幕截圖)。
-
-
能力突破
-
Kimi-VL在三大維度表現卓越:
-
強通用性(Smart):
- 文本能力媲美純文本LLMs,在多模態推理和智能體任務中競爭力強。
-
長上下文處理(Long):
- 128K上下文窗口,在長視頻和長文檔任務中遠超同類模型。
-
細粒度感知(Clear):
- 在視覺感知、OCR、高分辨率截圖等任務中優于現有稠密/MoE VLMs。
-
-
-
-
進階版本:Kimi-VL-Thinking
-
通過 長鏈思維(long-CoT)微調 + 強化學習(RL),進一步提升復雜多模態推理能力
-
小模型大能量:盡管參數量小,性能超越許多更大規模的SOTA VLMs。
-
2. Approach
2.1 Model Architecture
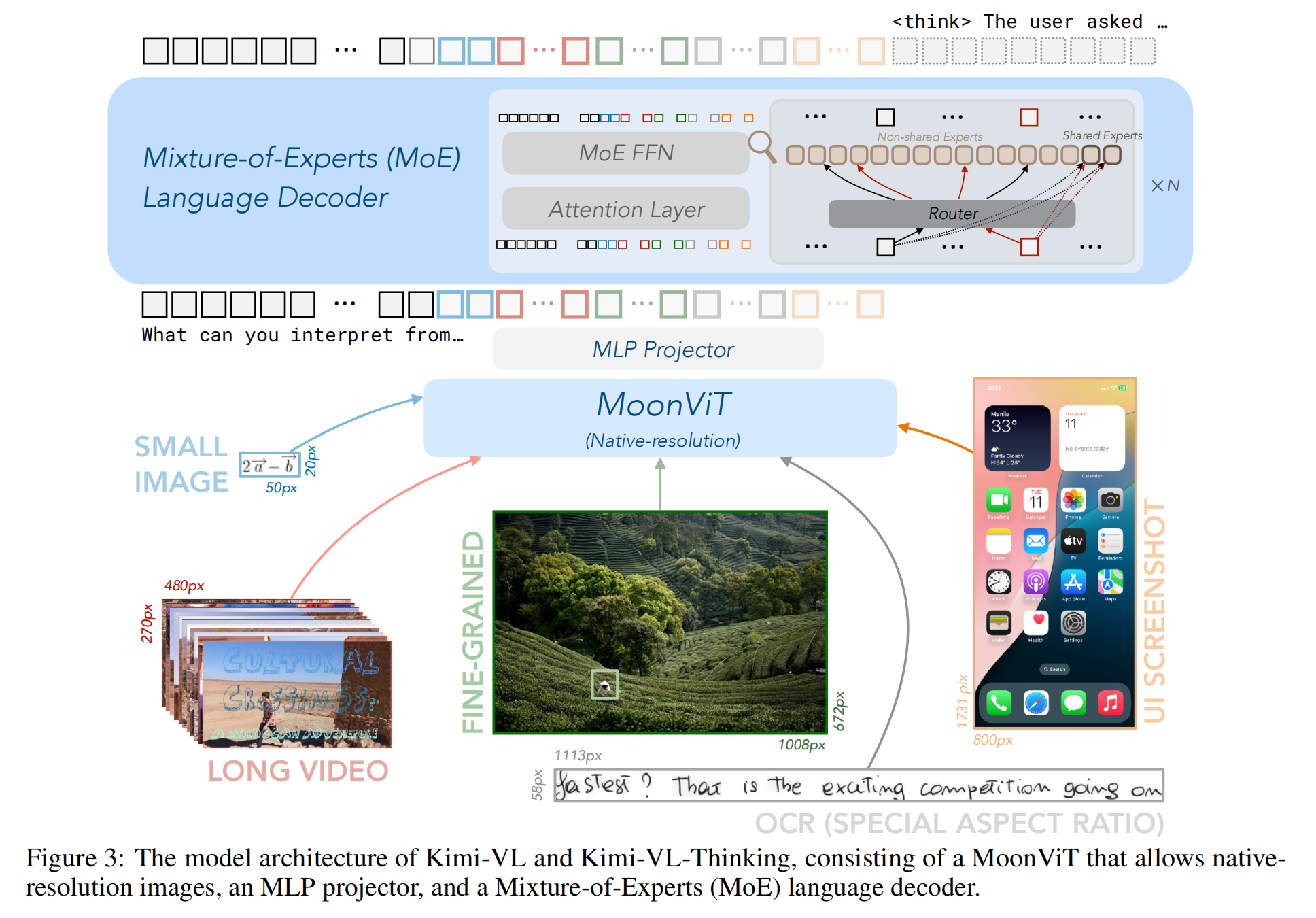
2.1.1 MoonViT: A Native-resolution Vision Encoder
-
核心設計目標
-
原生分辨率支持:直接處理不同尺寸的輸入,無需強制縮放或裁剪。
-
計算統一性:與語言模型共享相同的序列化計算機制(如 FlashAttention),優化訓練效率。
-
細粒度空間編碼:在超高分辨率下仍能保持精確的 空間位置感知(如 OCR 精確定位)。
-
-
關鍵技術組件
-
圖像序列化:NaViT 的 Patch 打包方法
- 分塊(Patchify):將圖像劃分為可變大小的 patches。
- 展平(Flatten):每個patch線性投影為 1D 向量。
- 序列拼接(Pack):所有patches按順序拼接為單一 1D 序列(類似文本 token 序列)。
-
位置編碼:雙機制協同
-
MoonViT 結合兩種位置編碼方法,以平衡預訓練知識繼承和高分辨率適應性:
- 插值絕對位置編碼(Interpolated Absolute PE):
- 繼承自 SigLIP-SO-400M視覺編碼器的預訓練權重,使用可學習的固定大小絕對位置編碼。
- SigLIP-SO-400M,是一個由 Google 提出的視覺-語言預訓練模型
- 局限性:超高分辨率時插值位置信息可能失真。
- 繼承自 SigLIP-SO-400M視覺編碼器的預訓練權重,使用可學習的固定大小絕對位置編碼。
- 插值絕對位置編碼(Interpolated Absolute PE):
-
-
2D 旋轉位置編碼(2D Rotary PE, RoPE):
-
沿圖像高度和寬度維度分別應用 RoPE,增強細粒度空間感知。
-
優勢:RoPE 的 距離衰減特性 更適合長序列和高分辨率定位(如屏幕文字檢測)。
-
-
-
MoonViT作用:在同一個batch中,支持不同分辨率的輸入
2.1.2 MLP Projector
-
核心功能
-
輸入:MoonViT 提取的 圖像特征序列(形狀為
[N, L, D_v],其中L是序列長度,D_v是視覺特征維度)。 -
輸出:與 LLM 嵌入維度對齊的投影特征(形狀為
[N, L', D_m],D_m是語言模型隱藏層維度)。 -
目標:
- 壓縮視覺特征的 空間冗余信息(如相鄰像素相似性)。
- 將視覺語義映射到語言模型的多模態聯合空間。
-
-
具體實現
-
Pixel Shuffle 操作(空間壓縮)
-
作用:降低特征圖的空間分辨率,同時增加通道維度,保留更多語義信息。
-
操作方式:
- 對 MoonViT 輸出的圖像特征執行 2×2 下采樣:
- 將相鄰的
2×2區域(共 4 個特征點)拼接為 1 個特征點,通道數擴展為原來的 4 倍。 - 數學表達:輸入特征
[N, H, W, D_v]→ 輸出[N, H/2, W/2, 4*D_v]。
- 將相鄰的
- 對 MoonViT 輸出的圖像特征執行 2×2 下采樣:
-
優勢:
- 減少序列長度(
L = H×W→L' = (H/2)×(W/2)),降低后續計算量。 - 通過通道擴展保留局部細節。
- 減少序列長度(
-
-
兩層 MLP(維度投影):將特征維度投影到語言模型嵌入維度。
-
2.1.3 Mixture-of-Experts (MoE) Language Model
-
模型架構基礎
-
類型:
- Kimi-VL 的語言模型采用 Moonlight 模型,屬于 Mixture-of-Experts(MoE)架構。
-
參數規模:
- 總參數量:16B(160 億參數)。
- 激活參數量:每次推理或訓練僅激活 2.8B 參數(約占總量的 17.5%)。
-
參考架構:
- 其設計與 DeepSeek-V3 相似,采用了類似的 MoE 分層和專家分配策略。
-
-
初始化與預訓練策略
-
初始化起點
-
檢查點選擇:
- 模型從一個 中間預訓練檢查點 初始化,該檢查點已通過 5.2T純文本 token 的訓練。
-
初始能力:
- 此時模型已具備較強的文本理解能力。
- 支持的上下文窗口為 8192 token(8k)。
-
-
多模態繼續預訓練
-
訓練數據:
-
在初始化后,使用 混合數據 繼續預訓練,包括:
-
多模態數據(圖像-文本對、視頻-文本對等)。
-
純文本數據(用于保持語言能力)。
-
總數據量:2.3T token(2.3 萬億)。
-
-
-
-
2.2 Muon Optimizer
-
原版 Muon 優化器的基礎
-
一種自適應優化算法,特點包括:
-
參數更新機制:動態調整學習率,結合動量和梯度二階矩估計。
-
數學性質:理論上保證收斂性,適合大規模模型訓練。
-
-
-
Kimi-VL 的改進點
-
新增權重衰減(Weight Decay)
-
參數級更新尺度調整
-
分布式實現(ZeRO-1 策略)
-
基礎技術:
參考微軟 ZeRO-1,將優化狀態(如動量、梯度方差)分片存儲在不同設備上。 -
優化目標:
- 內存效率:減少單卡內存占用,支持更大模型或 batch size。
- 通信開銷:僅同步必要的梯度信息,避免全量通信瓶頸。
-
數學性質保留: 分布式實現需嚴格保證與原算法的數學等價性(如梯度更新一致性)。
-
-
-
在 Kimi-VL 中的應用
- 優化所有參數:包括:
- 視覺編碼器(MoonViT)
- 投影層(MLP Projector)
- 語言模型(Moonlight MoE)
- 優化所有參數:包括:
2.3 Pre-training Stages

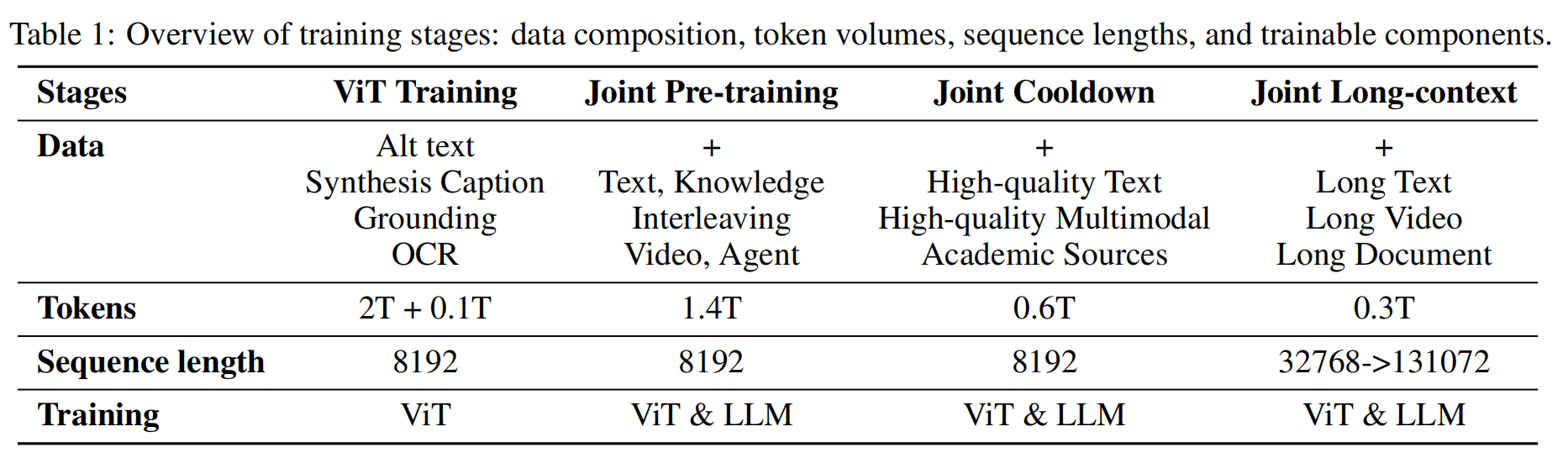
-
在加載上述中間語言模型后,Kimi-VL的預訓練共包含 4個階段,總計消耗 4.4Ttoken:
-
獨立的ViT訓練:
- 首先訓練一個獨立的視覺編碼器(ViT),以建立一個強大的 原生分辨率視覺編碼器。
-
聯合訓練三階段:
-
預訓練階段:同時提升模型的 語言能力 和 多模態能力。
-
冷卻階段(Cooldown):調整訓練策略,優化模型穩定性。
-
上下文激活階段:擴展模型上下文窗口,使其支持 128K token 的長序列輸入。
-
-
2.3.1 ViT Training Stages
-
訓練數據與目標
-
數據組成: MoonViT 使用 圖像-文本對 進行訓練,其中文本包含多種形式:
- 圖像替代文本(alt texts):描述性文本
- 合成標注(synthetic captions):自動生成的圖像描述
- 邊界框標注(grounding bboxes):物體定位信息
- OCR 文本:圖像中的文字識別結果
-
訓練目標: 聯合優化兩個損失函數:
- SigLIP 損失: L s i g l i p L_{siglip} Lsiglip?
- 基于對比學習(contrastive loss)的變體,拉近匹配圖像-文本對的嵌入距離,推開不匹配對。
- 圖像編碼器和文本編碼器共同計算此損失。
- 生成損失: L c a p t i o n L_{caption} Lcaption?
- 交叉熵損失(cross-entropy),用于訓練文本解碼器生成圖像描述(caption)。
- 文本解碼器基于圖像編碼器的特征進行 下一詞預測(NTP)。
-
總損失函數:
L = L siglip + λ ? L caption L = L_{\text{siglip}} + \lambda \cdot L_{\text{caption}} L=Lsiglip?+λ?Lcaption?- 生成損失的權重系數 λ = 2 \lambda = 2 λ=2,強調描述生成任務的重要性
- SigLIP 損失: L s i g l i p L_{siglip} Lsiglip?
-
-
模型初始化與訓練策略
-
初始化方案:
- 圖像/文本編碼器:從 SigLIP SO-400M加載預訓練權重。
- 文本解碼器:初始化自一個小型純文本語言模型(decoder-only)。
-
漸進式分辨率訓練:
- 采用 逐步增大輸入圖像分辨率 的策略,避免直接訓練高分辨率時的計算負擔。
-
訓練觀察:
- 當增加 OCR 數據比例時,caption loss顯著下降,表明文本解碼器學習了 OCR 能力
-
-
兩階段訓練流程
-
CoCa 式預訓練階段
-
數據量:消耗 2T token 的圖文數據。
-
訓練內容: 對ViT進行訓練
-
-
對齊階段(Alignment)
-
數據量:額外 0.1T token 的圖文數據。
-
訓練內容:
- 僅更新 MoonViT 和 MLP 投影器,語言模型參數凍結。
- 目標:將 MoonViT 的視覺嵌入更適配語言模型的輸入空間,降低初始困惑度(perplexity)。
-
效果:
- 對齊后,視覺特征與語言模型的兼容性顯著提升,為后續聯合預訓練(joint pre-training)奠定平滑過渡基礎。
-
-
2.3.2 Joint Pre-training Stage
-
訓練數據組成
-
純文本數據: 采樣分布與初始語言模型相同,確保語言能力不退化。
-
多模態數據: 包含 圖像-文本對、視頻-文本對 等。
-
-
訓練策略
- 學習率調度: 沿用初始語言模型 checkpoint 的 相同學習率調度策略,保持訓練穩定性。
-
分階段數據混合:
- 初始階段(純文本): 僅使用純文本數據訓練若干步。
- 漸進引入多模態數據: 逐步增加多模態數據的比例
-
總數據量:
- 本階段共消耗 1.4Ttoken 的數據。
2.3.3 Joint Cooldown Stage
-
核心目標
-
通過 高質量語言+多模態數據 微調,進一步提升模型在 數學推理、知識問答、代碼生成 等復雜任務上的性能。
-
避免過擬合,確保模型泛化能力。
-
-
數據策略
-
語言數據優化
-
基礎數據源:
- 從預訓練語料中精選 高保真(high-fidelity)文本子集。
-
合成數據增強:
- 數學/知識/代碼領域:通過專有語言模型生成 問答對(QA pairs),采用 拒絕采樣 控制質量。
- 作用:顯著提升模型在數學推理、代碼生成等任務的表現。
-
-
多模態數據優化
-
數據來源:
- 學術視覺數據集和視覺-語言數據。
-
處理方式:
- 過濾與重寫:將原始數據轉化為 視覺中心問答對(Visual QA pairs)
-
比例控制:
- QA 對僅占少量比例(例如 <10%),避免模型過度依賴問答模式而喪失泛化性。
-
-
-
訓練設計
-
學習重點:
- 激活特定能力:通過 QA 對針對性強化數學、代碼、視覺推理等技能。
- 高質量數據學習:優先學習篩選后的優質樣本,而非盲目擴大數據量。
-
防過擬合措施:
- 限制合成 QA 對的比例。
- 保留大部分數據為自然分布(如原始文本、圖像-描述對)。
-
2.3.4 Joint Long-context Activation Stage
-
階段目標與核心挑戰
-
目標:將模型的上下文窗口從 8K擴展至128K,使其能夠處理超長文本、視頻、多模態文檔等輸入。
-
核心挑戰:
- 保持短上下文任務性能的同時學習長序列依賴。
- 避免位置編碼(RoPE)外推時的性能崩潰。
-
-
關鍵技術實現
-
RoPE 位置編碼調整
- 修改參數:
- 將 RoPE 的 逆頻率(inverse frequency)從 50,000 調整至 800,000,以支持更長的位置索引。
- 作用:防止長序列位置編碼重復或沖突,確保位置信息唯一性。
- 修改參數:
-
兩階段漸進式擴展
-
子階段1:
- 上下文窗口從 8K → 32K(4倍擴展)。
- 數據中 25% 為長序列數據,75% 為短序列數據。
-
子階段2:
- 上下文窗口從 32K → 128K(再次4倍擴展)。
- 數據比例同上(25% 長數據,75% 短數據)。
-
設計動機:
- 漸進擴展避免訓練不穩定,同時通過短數據回放(replay)防止能力遺忘。
-
-
-
長數據構成
-
純文本長數據
-
多模態長數據:
- 交錯長數據(Interleaved):圖文混合的長序列。
- 長視頻、長文檔
-
合成QA對增強:
- 生成少量長上下文相關的問答對,提升學習效率。
-
-
性能評估
- Needle-in-a-Haystack(NIAH)測試:
- 在超長文本(“Haystack”)中隱藏關鍵信息(“Needle”),測試模型能否準確召回。
- 同時測試純文本(如128K長文章)和多模態輸入(如1小時長視頻)。
- Needle-in-a-Haystack(NIAH)測試:
2.4 Post-Training Stages

2.4.1 Joint Supervised Fine-tuning (SFT)
-
階段目標
-
核心任務:通過指令微調將預訓練基礎模型轉化為 交互式 Kimi-VL 模型,使其具備:
- 多輪對話能力(遵循指令、上下文連貫)。
- 多模態指令理解(圖文混合任務處理)。
-
實現方式:采用 ChatML 格式 統一指令模板,保持與 Kimi-VL 架構的一致性。
-
-
關鍵技術設計
-
微調范圍
- 優化模塊:MoE LLM、MLP 投影層、MoonViT
-
監督信號:
- 僅對答案和特殊 token計算損失,屏蔽系統提示和用戶輸入部分。
- 目的:避免模型學習無關的指令模板內容,專注優化回答質量。
-
-
數據構成
-
混合數據:
- 多模態指令數據
- 純文本對話數據
-
數據格式:
- 使用 ChatML 結構化標記,明確區分對話角色(用戶/系統/助手)。
- 視覺嵌入注入:將圖像特征通過 MLP 投影后插入指令模板的指定位置,保留跨模態位置關系。
-
-
訓練策略
-
兩階段序列長度調整:
- 第一階段(32K 上下文):
- 訓練 1 個 epoch。
- 學習率從 2×10?? 衰減至 2×10??。
- 第二階段(128K 上下文):
- 學習率重新升溫至 1×10??,再衰減至 1×10??。
- 進一步強化長上下文指令跟隨能力。
- 第一階段(32K 上下文):
-
序列打包(Sequence Packing):
- 將多個訓練樣本拼接為單個長序列(如 3 個 10K 樣本 → 1 個 30K 序列),提升訓練效率。
- 通過特殊 token 分隔不同樣本,避免上下文混淆。
-
2.4.2 Long-CoT Supervised Fine-Tuning
-
階段目標
-
核心任務:通過高質量的小規模 CoT 數據來微調模型,使其掌握 類人的多模態推理能力,包括:
- Planning、Evaluation、Reflection、Exploration
-
實現方式:結合 提示工程(Prompt Engineering)和 拒絕采樣,構建高精度的長鏈推理數據集。
-
-
關鍵技術實現
-
數據集構建
-
數據生成方法:
- 提示工程引導:設計特定提示模板,要求模型生成包含完整推理鏈的回答。
- 拒絕采樣篩選:僅保留邏輯嚴密、步驟正確的輸出,過濾錯誤或簡化的回答。
-
數據內容:
- 包含 文本 和 圖像輸入 的長鏈推理示例。
- 示例需覆蓋 規劃→執行→評估→反思→探索 的全流程。
-
-
微調策略
- 輕量級 SFT(Supervised Fine-Tuning):
- 在小規模數據集(可能僅數千樣本)上微調,避免過擬合。
- 優化目標:讓模型學會“模仿”人類推理過程,而非單純記憶答案。
- 輕量級 SFT(Supervised Fine-Tuning):
-
2.4.3 Reinforcement Learning
-
核心目標
-
通過強化學習進一步優化模型的自主推理能力,使其能夠:
-
自動生成CoT
-
動態糾錯與迭代優化
-
平衡推理效率與準確性:避免“過度思考”(生成冗余步驟)或“思考不足”(跳過關鍵步驟)
-
-
-
強化學習算法設計
-
算法選擇:Online Policy Mirror Descent
-
基礎思想:
- 參考 Kimi k1.5,采用 策略鏡像下降的變體,通過相對熵(KL散度)正則化穩定策略更新。
-
優化目標:
max ? θ E ( x , y ? ) ~ D [ E ( y , z ) ~ π θ [ r ( x , y , y ? ) ] ? τ KL ( π θ ( x ) ∥ π θ i ( x ) ) ] \max_{\theta} \mathbb{E}_{(x,y^*)\sim D} \left[ \mathbb{E}_{(y,z)\sim \pi_\theta} [r(x, y, y^*)] - \tau \text{KL}(\pi_\theta(x) \| \pi_{\theta_i}(x)) \right] θmax?E(x,y?)~D?[E(y,z)~πθ??[r(x,y,y?)]?τKL(πθ?(x)∥πθi??(x))]- 公式說明見Kimi-K1.5筆記
-
-
訓練流程
-
迭代更新:
- 每輪迭代從數據集 D D D 中采樣一批問題 x x x。
- 當前策略 π θ \pi_\theta πθ? 生成答案 y y y 和推理鏈 z z z。
- 根據獎勵 r ( x , y , y ? ) r(x, y, y^*) r(x,y,y?) 和KL正則項計算策略梯度,更新參數至 θ i + 1 \theta_{i+1} θi+1?。
- 更新后的策略 π θ i + 1 \pi_{\theta_{i+1}} πθi+1?? 作為下一輪的參考策略。
-
終止條件: 獎勵收斂或達到最大迭代次數。
-
-
關鍵技術優化
-
獎勵設計
-
基礎獎勵:二元獎勵 r ( x , y , y ? ) ∈ { 0 , 1 } r(x, y, y^*) \in \{0,1\} r(x,y,y?)∈{0,1},僅判斷最終答案正確性。
-
長度懲罰: 對過長的推理鏈施加負獎勵,避免“過度思考”。
-
課程獎勵(Curriculum Reward): 根據問題難度動態調整獎勵權重
-
-
采樣策略
-
課程采樣(Curriculum Sampling):按問題難度標簽從易到難逐步采樣。
-
優先級采樣(Prioritized Sampling):根據歷史成功率動態調整樣本權重,聚焦于當前模型易錯的樣本。
-
-
-
元推理能力提升(Meta-Reasoning)
-
錯誤檢測與回溯: 模型通過分析完整的推理歷史,自主修正錯誤。
-
參數化搜索策略: 將規劃過程編碼到模型參數中,無需外部規劃算法。
-
3. Data Construction
3.1 Pre-training Data
3.1.1 Caption Data
-
核心作用
-
模態對齊基礎: 為模型提供視覺與語言對齊的基礎能力,使其學會將圖像內容轉化為自然語言描述。
-
世界知識擴展: 通過海量描述數據,模型高效學習廣泛的世界知識
-
-
數據來源
-
開源數據集: 整合中英文開源描述數據集。
-
內部數據:
-
自建高質量描述數據,覆蓋多樣場景(如專業攝影、科學圖表、社交媒體圖片)。
-
合成數據限制
- 風險控制: 嚴格限制合成描述數據的比例,避免因缺乏真實世界知識導致幻覺(hallucination)(如虛構圖像細節)。
-
-
-
多分辨率訓練
- 動態分辨率調整: 在預訓練中隨機切換圖像分辨率,使視覺編碼器能同時處理高/低分辨率圖像。
3.1.2 Image-text Interleaving Data
-
核心價值與作用
-
多圖像理解能力:
- 通過單批次輸入多張關聯圖像(如步驟圖),模型學習跨圖像的語義關聯
-
長上下文多模態學習:
- 交錯數據天然包含長序列圖文交替輸入(如教科書圖文混排),訓練模型在長上下文窗口內保持跨模態注意力。
-
語言能力保護:
- 作者發現圖文交錯數據可防止純視覺訓練導致的語言能力退化。
-
-
數據來源與構建
-
開源數據集: 采用公開圖文交錯數據集,覆蓋百科、新聞等場景。
-
自建高質量數據: 教材、網頁內容、教程
-
合成數據: 通過語言模型生成與圖像匹配的連貫文本,增強知識一致性。
-
-
數據處理關鍵技術
-
質量管控流程
-
標準清洗:
- 去重(Deduplication):移除重復或近似的圖文塊。
- 過濾(Filtering):剔除低相關性圖文對。
-
順序校正(Reordering):
- 強制保持原始文檔的圖文順序,避免隨機打亂破壞邏輯鏈。
-
-
3.1.3 OCR Data
-
數據來源與覆蓋范圍
-
開源數據: 整合通用OCR數據集(如ICDAR、SROIE),涵蓋掃描文檔、自然場景文本等。
-
自建高質量數據: 多語言文本、 密集排版 、非結構化文本、多頁長文檔
-
-
數據處理與增強技術
-
數據多樣性擴展
- 圖像類型全覆蓋:
-
增強技術: 幾何變換、視覺干擾、字體與背景
-
長文檔處理優化
-
3.1.4 Knowledge Data
-
多模態知識數據的概念與之前提到的文本預訓練數據類似
-
此處專注于整合來自不同來源的人類知識,以進一步增強模型的能力。
- 例如,數據集中在精心整理的幾何數據,其對于開發視覺推理能力至關重要,確保模型能夠理解人類創建的抽象圖表。
-
語料庫遵循標準化的分類體系,以平衡不同類別的內容,確保數據來源的多樣性。
-
知識語料庫有相當一部分來源于互聯網材料,信息圖(infographics)可能導致模型僅關注基于OCR的信息。
- 在這種情況下,僅依賴基礎OCR流程可能會限制訓練效果。
- 為此,作者開發了一個額外的處理流程,以更好地提取圖像中純文本信息。
3.1.5 Agent Data
-
核心目標
-
增強模型在智能體任務中的兩大能力:
-
環境感知(Grounding)
-
多步規劃(Planning)
-
-
-
數據來源與采集平臺
-
公開數據:整合現有智能體數據集(如桌面操作、移動端交互日志)。
-
自建虛擬化平臺:
- 批量管理虛擬機環境(Ubuntu/Windows),通過啟發式方法(Heuristic Methods)自動采集:
- 屏幕截圖:記錄每個操作步驟的界面狀態。
- 動作數據:對應操作的元數據(如點擊坐標、鍵盤輸入、滾動行為)。
- 批量管理虛擬機環境(Ubuntu/Windows),通過啟發式方法(Heuristic Methods)自動采集:
-
-
數據格式化處理
-
密集 grounding 格式: 將屏幕元素(如按鈕、輸入框)標注為結構化數據,包含:
- 視覺位置
- 功能語義
-
連續軌跡格式:
- 將多步操作序列編碼為時間軸數據,保留動作之間的依賴關系。
-
-
動作空間設計(Action Space)
環境 動作類型 桌面端 鼠標點擊、鍵盤輸入、窗口切換、文件拖拽等 移動端 觸屏滑動、長按、多指縮放、返回鍵操作 網頁端 表單填寫、鏈接跳轉、下拉刷新、彈窗處理 -
圖標數據優化(Icon Data)
-
收集目標: 強化模型對軟件GUI圖標語義的理解。
-
處理方式:
- 標注圖標類別與功能描述
- 合成對抗樣本(如扭曲/遮擋圖標),提升魯棒性。
-
-
多步任務軌跡與思維鏈(Chain-of-Thought)
-
人工標注軌跡: 錄制人類完成復雜任務的全流程操作(如“配置開發環境”),包含:
- 屏幕錄像 + 動作序列
- 合成的思維鏈: 將每個動作的決策邏輯轉化為文本描述
-
作用: 訓練模型模仿人類規劃能力,在真實系統中執行多步任務
-
3.1.6 Video Data
-
視頻數據的作用
- 讓模型理解以圖像為主的長上下文序列
- 讓模型能夠感知短視頻片段中細粒度的時空對應關系
-
數據來源
- 開源數據集
- 網絡級視頻數據
-
長視頻caption:
- 對于長視頻,作者設計了生成密集字幕的流程。
- 與處理描述數據類似,需嚴格限制合成密集視頻描述數據的比例,以降低幻覺風險。
3.1.7 Text Data
- 文本預訓練語料直接采用Moonlight的數據,該語料庫旨在為大型語言模型訓練提供全面且高質量的數據,涵蓋五大領域:英語、中文、代碼、數學與推理、以及知識。
- 作者對所有預訓練數據源進行嚴格驗證,評估其對整體訓練效果的貢獻,并通過大量實驗確定不同文檔類型的采樣策略。
- 在最終訓練語料中提高關鍵子文檔的采樣頻率,同時保持其他文檔類型的適當比例以維護數據多樣性和模型泛化能力。
3.2 Instruction Data
- 本階段數據主要旨在提升模型的對話能力和指令跟隨能力。
- 對于非推理類任務:
- 先通過人工標注構建種子數據集訓練初始模型,再通過該模型生成多樣回答并由人工篩選優化;
- 對于視覺編程、視覺推理和數理問題等推理任務:
- 則采用基于規則和模型的拒絕采樣法擴展數據集。
- 最終的標準監督微調(SFT)數據集保持文本token與圖像token約1:1的比例平衡。
3.3 Reasoning Data
-
目標:增強模型在多模態推理方面的能力
-
數據集構建過程:
- 構建一個帶標準答案標注的問答數據集
- 其中包含需要多步推理的問題,例如數學求解和領域特定的視覺問答(VQA)。
- 利用Kimi k1.5,結合精心設計的推理提示,為每個問題生成多條詳細的推理路徑。
- 在拒絕采樣階段,將真實標簽和模型預測輸入現成的獎勵模型進行評判。
- 錯誤的思維鏈響應會根據模型評估和基于規則的獎勵機制被過濾掉,從而提升推理數據的質量。
- 構建一個帶標準答案標注的問答數據集
4. Evaluation
-
Benchmarks
-
Image Benchmark
-
MMMU (Yue, Ni, et al. 2024)
-
MMBench-EN-v1.1 (Yuan Liu et al. 2023)
-
MMStar (Lin Chen et al. 2024)
-
MMVet (W. Yu et al. 2024)
-
RealWorldQA (x.ai 2024)
-
AI2D (Kembhavi et al. 2016)
-
MathVision (K. Wang et al. 2024)
-
MathVista (P. Lu et al. 2023)
-
BLINK (X. Fu et al. 2024)
-
InfoVQA (Mathew et al. 2022)
-
OCRBench (Yuliang Liu et al. 2023)
-
-
Video and Long Document Benchmark
-
VideoMMMU (K. Hu et al. 2025)
-
MMVU (Y. Zhao et al. 2025)
-
Video-MME (C. Fu et al. 2024)
-
MLVU (J. Zhou et al. 2024)
-
LongVideoBench (H. Wu et al. 2024)
-
EgoSchema (Mangalam et al. 2023)
-
VSI-Bench (Yang et al. 2024)
-
TOMATO (Shangguan et al. 2025)
-
-
Agent Benchmark
-
ScreenSpot V2 (Zhiyong Wu et al. 2024)
-
ScreenSpot Pro (K. Li et al. 2025)
-
OSWorld (T. Xie et al. 2024)
-
WindowsAgentArena (Bonatti et al. 2024)
-
-
)

實現路徑損耗預測)
















)