文章目錄
- 對比去噪訓練
- 混合查詢選擇
- look forward twice
論文全稱為:DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
提出了三個新的方法:
-
首先,為了改進一對一的匹配效果,提出了一種對比去噪訓練方法,通過同時添加同一個GT的正、負樣本來進行對比去噪訓練。在同一個GT中加入兩個不同的噪聲后,將具有較小噪聲的框標記為正,另一個標記為負。對比去噪訓練可以幫助模型避免同一目標的重復輸出
-
其次,使用了一種類似兩階段的模型(Deformable DETR的two stage)。提出了一種混合查詢選擇方法,這有助于更好地初始化查詢. 從encoder的輸出中選擇初始錨定框作為位置查詢,類似于Deformable DETR.然而,讓內容查詢像以前一樣可以學習,從而鼓勵第一個解碼器層關注空間先驗(空間位置先驗與當前的圖像更加的相關)
-
第三,為了利用后期層的refined box信息來幫助優化相鄰早期層的參數,提出了一種新的look forward twice方案,用后面的層的梯度來修正更新后的參數
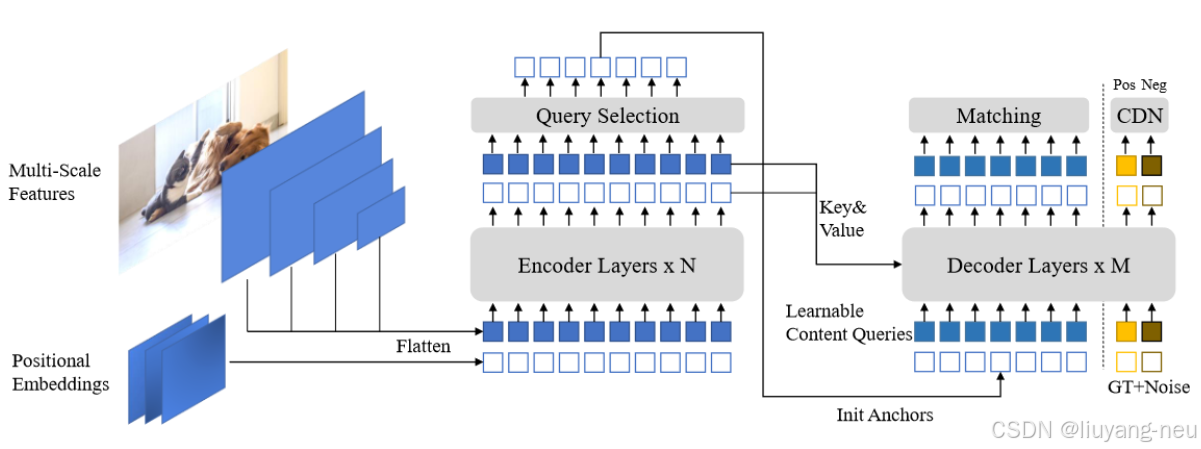
DINO-DETR的整體架構如上圖所示,首先通過backbone得到多尺度的特征,然后給特征加上位置編碼,將他們喂給Transformer Encoder得到增強后的特征。在decoder之前,作者將原本的decoder query視作兩個部分,位置query和內容query。作者提出了一種新的混合的query selection策略來初始化作為位置query的anchors,但是內容query不會初始化(仍然是可學習的使它們保持可學習性)。通過這些用初始化后的anchors(位置)和可學習的內容query, 作者使用Deformable-DETR的deformable attention來組合來自encoder輸出的特征,逐層更新decoder query。最終網絡通過內容query預測refined anchor boxes和分類等結果。同時作者改進了DN-DETR,提出了一個對比去噪訓練的方法,在DN-DETR的基礎上將困難負樣本考慮在內。最后為了充分利用后層refined box的信息來優化緊鄰的前一層的網絡參數,作者還提出了一個look forward twice方法。下面分別詳細講講上述提到的幾個改進。
對比去噪訓練
DN-detr的去噪訓練幫助網絡學習基于那些在gt boxes周圍的anchors進行預測。但是它沒有考慮去預測“no object"的情況,即那些anchors周圍沒有gt boxes的時候,應該預測出負例。因此作者在DN-DETR的基礎上額外構造了負樣本,即提出Contrastive DeNoising (CDN)。
在實現上,DINO-DETR擁有兩個超參數 λ1,λ2(λ1<λ2) 用于控制正負噪聲樣本的生成,而DN-DETR只有一個超參數 λ ,DN-DETR控制生成的噪聲不超過 λ 并期望網絡可以用在gts附近的輕微噪聲querys去重構出gts。
如下圖右側所示的同心正方形,DINO-DETR構造正負兩種類型的CDN queries,其中positive queries在內部方形,有著比 λ1 更小的噪聲scale, 用于重構出他們對應的gts;negative queries在內部方形和外部方形之間,即噪聲scale在λ1,λ2(λ1<λ2)之間。作者表示可以通過更小的 λ2 構造困難負樣本來提高模型性能。一個CND group可以包含多個正樣本和負樣本,例如一張圖片有n個gts, 每個gt有一正一負兩個噪聲樣本,那么一個CND group有2xn個queries。
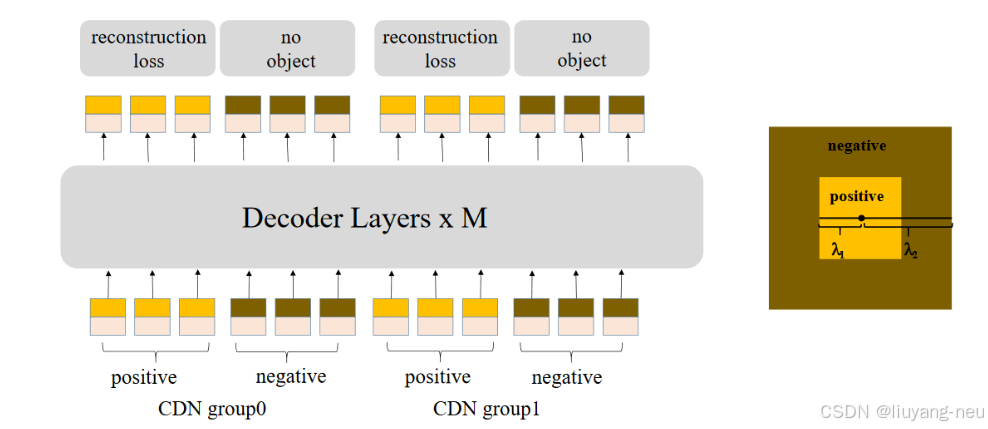
該方法之所以有效,是因為它可以抑制混淆,并選擇高質量的anchors(查詢)來預測邊界框。當多個anchors靠近一個對象時,就會發生混淆,在這種情況下,模型很難決定選擇哪個錨點。這種混淆可能會導致兩個問題:
- 第一個是重復的預測。雖然detr類的模型可以通過基于集合的損失和自我注意的幫助來抑制重復的盒子,但這種能力是有限。使用CDN查詢,可以區分anchors之間的細微差別,并避免重復的預測
- 第二個問題是,一個遠離GT并且不應該被選擇的某個anchor可能會被選擇上,雖然去噪訓練改進了模型來選擇附近的anchor。但CDN通過讓模型拒絕更遠的anchor,進一步提高了這種能力。
混合查詢選擇
如(a)所示,在DETR 、DN-DETR 和DAB-DETR 中,解碼器查詢是靜態嵌入,而不從圖像中獲取任何編碼器特征,它們直接從訓練數據中學習位置和內容查詢,并將內容查詢設置為全部都是0的tensor;Deformable Detr的其中一個變體(two-stage),它從編碼器最后輸出中選擇前K個編碼器特征作為先驗,以增強解碼器查詢。如圖(b)所示,位置查詢和內容查詢都是通過對所選特性的線性變換生成的。此外,這些被選中的特征被輸送到一個輔助檢測頭,以獲得預測方框,并將其用于初始化參考方框。
在DINO中,只使用與所選 Top-K 特征相關的位置信息來初始化錨點框,而內容查詢則保持不變,如圖(c)所示(Deformable DETR 不僅利用 Top-K 特征來增強位置查詢,還增強了內容查詢)
外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳
內容查詢保持不變的原因:由于所選特征是未經進一步完善的初步內容特征,它們可能會含糊不清并誤導解碼器。例如,一個選定的特征可能包含多個對象,也可能只是一個對象的一部分。與此相反,我們的混合查詢選擇方法只用前 K 個選定特征來增強位置查詢,并保持內容查詢的可學習性。這有助于模型利用更好的位置信息,從編碼器中匯集更全面的內容特征。
look forward twice
傳統的decoder layer每層分別優化看做look forward once模式(如Deformable DETR其中的一個變體),其中 b i ? 1 b_{i?1} bi?1?是上一層的錨框預測,經過Layer i (Decoder的box_head的修正)后得出偏移量Δ b i b_{i} bi? ,來得到新的參考點 b i ’ b_{i}’ bi?’,進一步得到預測值 b i p r e d b_{i}^{pred} bipred? ,預測值會在輔助頭進行損失計算并進行反向傳播(只在本層進行梯度反向傳播,梯度不會回傳到前一層),當前層的預測點作為后一層的參考點(即 b i b_{i} bi?的值和 b i ’ b_{i}’ bi?’的值是一樣的),虛線表示梯度被截斷,所以梯度不會回傳到前一層(Deformable detr認為如果不進行隔斷處理的話,會導致網絡非常難以學習)。
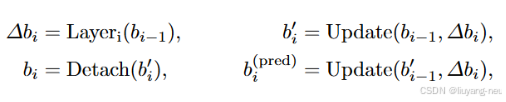
作者認為來自后一層的改進box的信息可以幫助校準其相鄰的前一層的預測結果。所以他相當于讓每層預測的結果往后多傳遞了一層,也就是 b i ? 1 p r e d b_{i?1}^{pred} bi?1pred? 是根據前一層的參考點 b i ? 1 ’ b_{i?1}’ bi?1?’和Δ b i b_{i} bi?得到的(如圖b),這樣預測進行反向傳播的時候,梯度會傳回到前一層。(這樣做的原因:因為最終取得的結果是最后一層的prediction,所以希望前面的層在優化的時候也會考慮一下后面的層,通過試驗得到forward兩次效果最好)



)
使用RAG增加私有知識庫)



帶論文文檔1萬字以上,文末可獲取,系統界面在最后面。)

作為另一個http接口的請求參數)








)