歸一化
在對輸入數據進行預處理時會用到歸一化,將輸入數據的范圍收縮到0到1之間,這有利于避免綱量對模型訓練產生的影響。
但當模型過深時會產生下述問題:
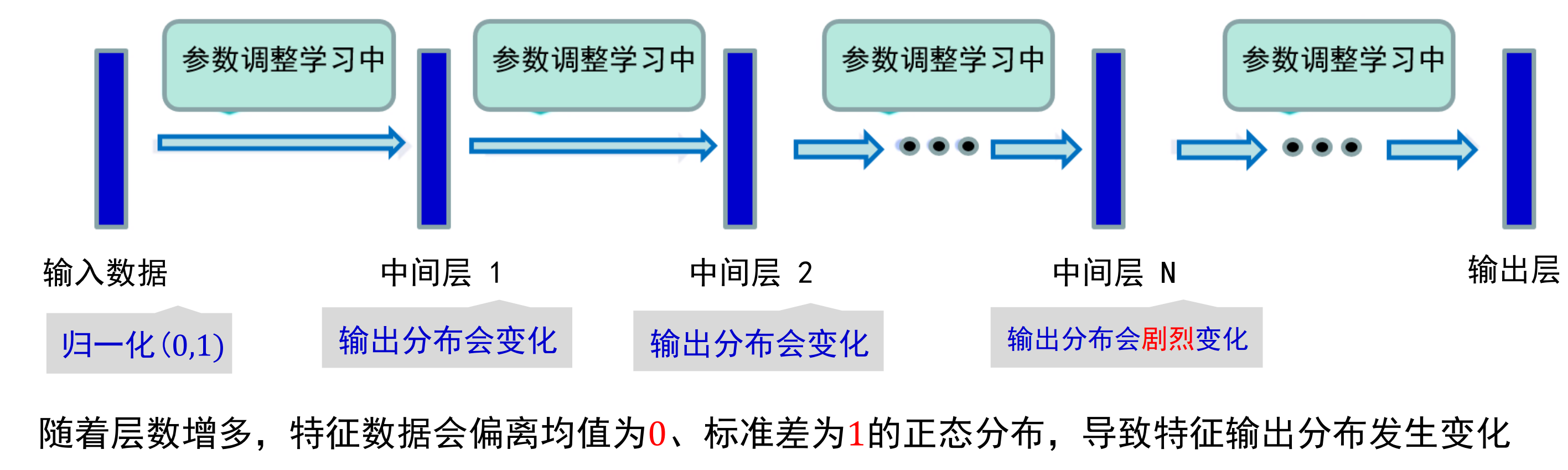
當一個學習系統的輸入分布發生變化時,這種現象稱之為“內部協變量偏移”(Internal Covariate Shift)。
內部協變量偏移
內部協變量偏移借鑒了統計學中的“協變量偏移”概念, 協變量(Covariate)指的是在分析某一因變量與其關系時,除了自變量以外,可能影響因變量的其他變量。
協變量的存在可能混淆自變量和因變量之間的因果關系,故在研究中通常對協變量進行控制或校正。模型在訓練時遇到數據分布發生變化,會影響模型的泛化能力。
內部協變量偏移的影響
需要較低的學習率
如果某一層的輸入分布突然變化(例如均值或方差大幅波動),則該層的參數更新可能會破壞之前學到的特征。為了穩定訓練,必須使用較小的學習率,這會顯著減慢訓練速度。
參數初始化敏感
參數初始化不合理會直接影響到模型的收斂速度、訓練效率以及最終模型的性能。
原因:
- 引發梯度消失/爆炸問題:在計算梯度時會計算激活函數的倒數(斜率),而特別時飽和的激活函數的斜率在某些位置接近于0(或很大),這就會導致梯度消失或爆炸問題。
- 更快的模型收斂:更快的模型收斂
有利于訓練的參數初始化

訓練一個深度學習模型,如果希望模型有比較好的收斂效果,需要的前提
條件是每一層的輸入數據有穩定的數據分布
批次歸一化
批次歸一化是對一個 batch 的數據在網絡各層的輸出做標準化處理,固定小批量里面的均值和方差,使得在不同層數據保持相同分布,即滿足標準正態分布。
優點
- 批規一化允許使用更高的學習率
- 并且對初始化的要求不那么嚴格
- 它還起到了正則化的作用,在某些情況下甚至可以消除對 Dropout 的需求
步驟
𝐵𝑎𝑡𝑐?𝑁𝑜𝑟𝑚 主要思路是在訓練時按 𝑚𝑖𝑛𝑖 ? 𝑏𝑎𝑡𝑐? 為單位,對神經元的數值進行歸一化,使數據的分布滿足 均值為 0,方差為 1。具體計算過程如下(4步):
- 計算 𝑚𝑖𝑛𝑖 ? 𝑏𝑎𝑡𝑐? 內樣本的均值

- 計算 𝑚𝑖𝑛𝑖 ? 𝑏𝑎𝑡𝑐? 內樣本的方差
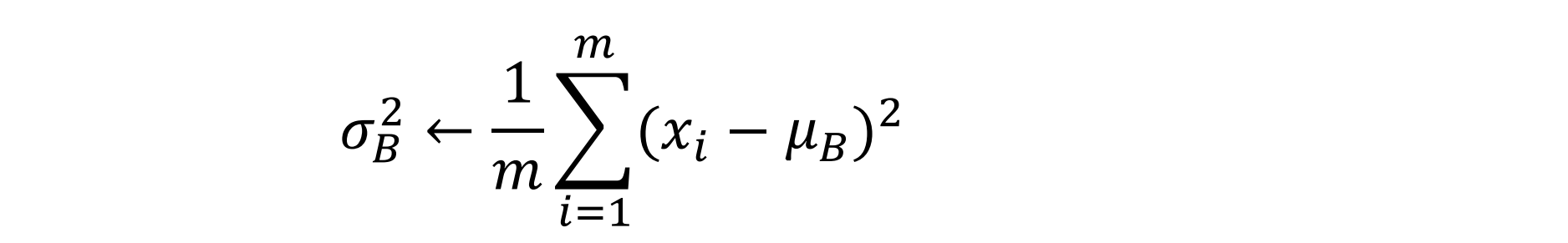
- 歸一化


其中 𝜖 是一個微小值(例如 1e?7) - 對標準化的輸出進行縮放和平移
如果強行限制輸出層的分布滿足標準正態化,使得數據集中在激活函數中心的線性區域,反而使激活函數喪失了非線性特性。
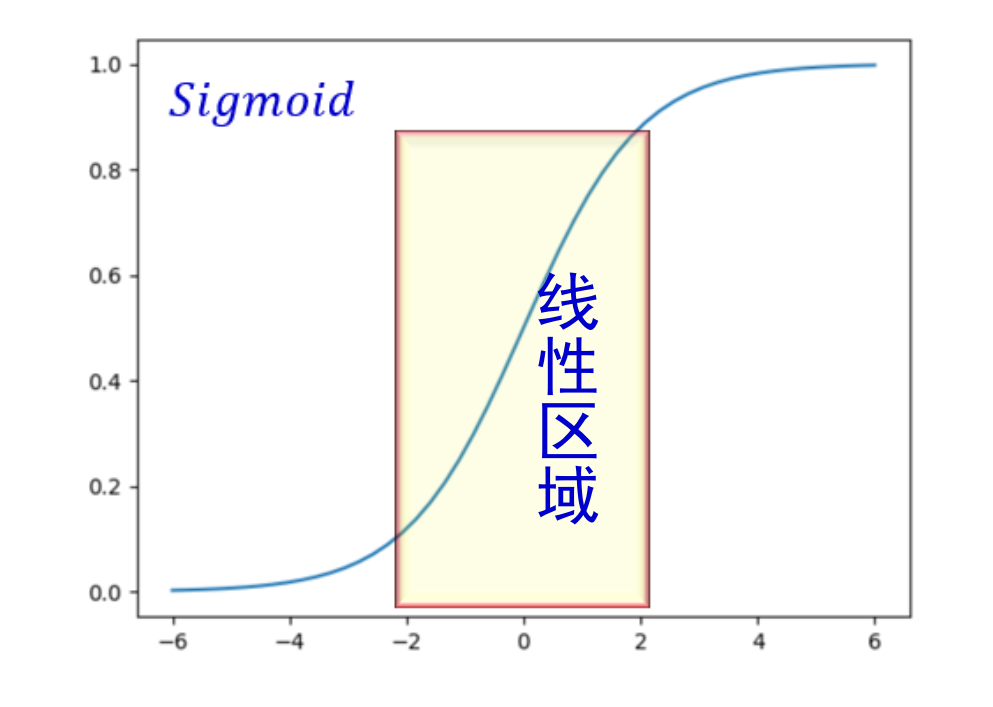
可能會導致某些特征模式的丟失。因此在 BN 操作中為每個卷積核引入了兩個可訓練參數:縮放 (𝑆𝑐𝑎𝑙𝑒)因子 𝛾 和偏移(𝑆?𝑖𝑓𝑡)因子 𝛽。
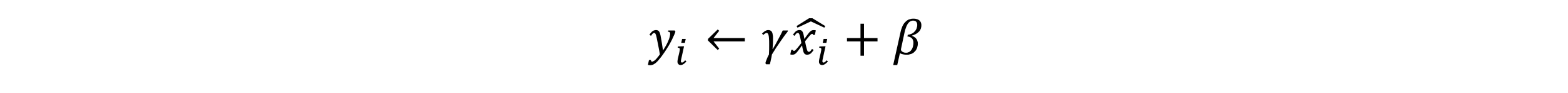
其中γ 和β 是可學習的參數,可以賦初始值 𝛾 = 1,β = 0 , 在訓練過程中不斷學習調整。而均值 𝜇𝐵 和方差 𝜎𝐵2 是計算得到的。
調節的原理:
γ 的作用:γ 可以調整歸一化后數據的方差,使其恢復到原始數據的尺度。

β 的作用:β 可以調整歸一化后數據的均值,使其恢復到原始數據的均值。
這樣通過調節這兩個參數可以保留一部分原數據的分布。
批量歸一化的位置
放在激活函數前面
激活函數是類似于 sigmoid 有一定飽和區域的函數。則可以把歸一化層放在激活函數之前,在一定程度上可以緩解梯度消失問題
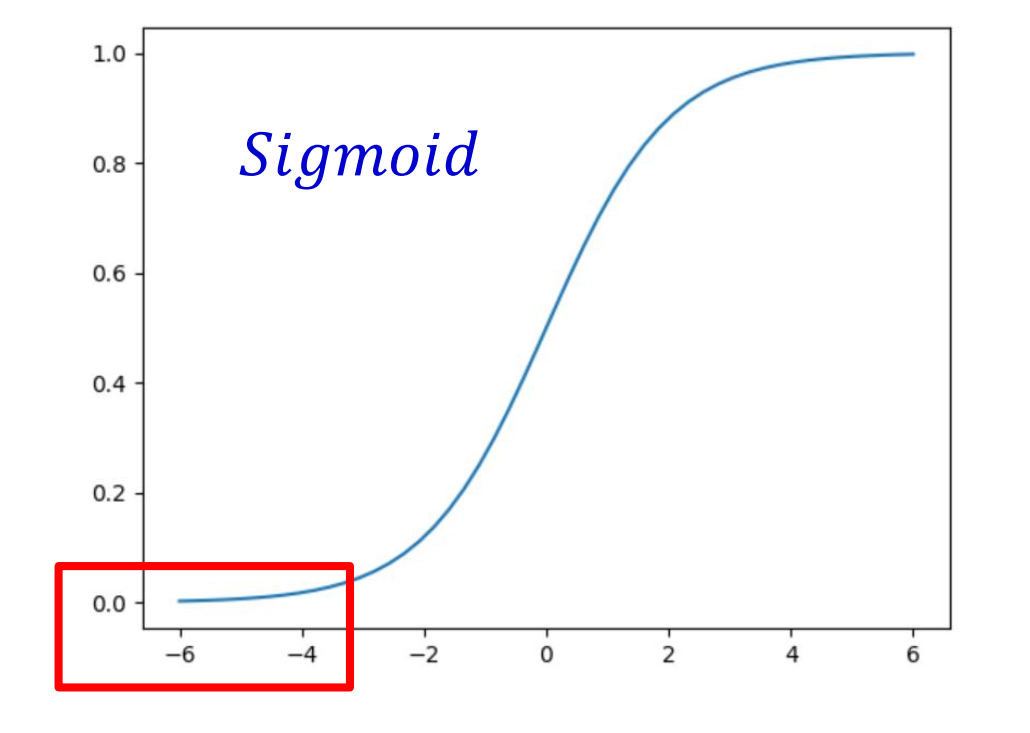
如上圖所示:假設未經過 BN 調整。
正態分布均值: ?6
方差: 1
意味著 95 % 的值落在位于兩個標準差[?2, 2] 的區間內,即 [?8, ?4] 之間,而對應的 Sigmoid 函數的值明顯接近于 0 ,這是典型的梯度飽和區。意味著梯度變化很小甚至消失。
而當落在的區間比較大時,計算出的梯度同樣很小。

問題:

因此要對分布區間進行一定的變換,使其大部分落在函數敏感區間。


放在激活函數之后
如果激活函數是類似于 relu 這樣的激活函數,那么可以把歸一化層放在激活函數之后,可以有效避免數據在激活之前被轉化成相似的模式,從而使得非線性特征分布趨于同化。
批歸一化與dropout的沖突
當 Dropout 和 BN 這兩個強大的方法在實際上結合使用的時候,反而經常無法獲得性能上額外的增益。事實上,當主流卷積網絡在同時配備 BN 和 Dropout 時,在很多情況下它們的性能甚至會變得更差。
方差偏移
每層的輸入分布由于上一層的參數更新變得不穩定(方差不一致),隨著信號變深,最終預測的數值偏差可能會被不斷的放大,從而降低系統的性能.
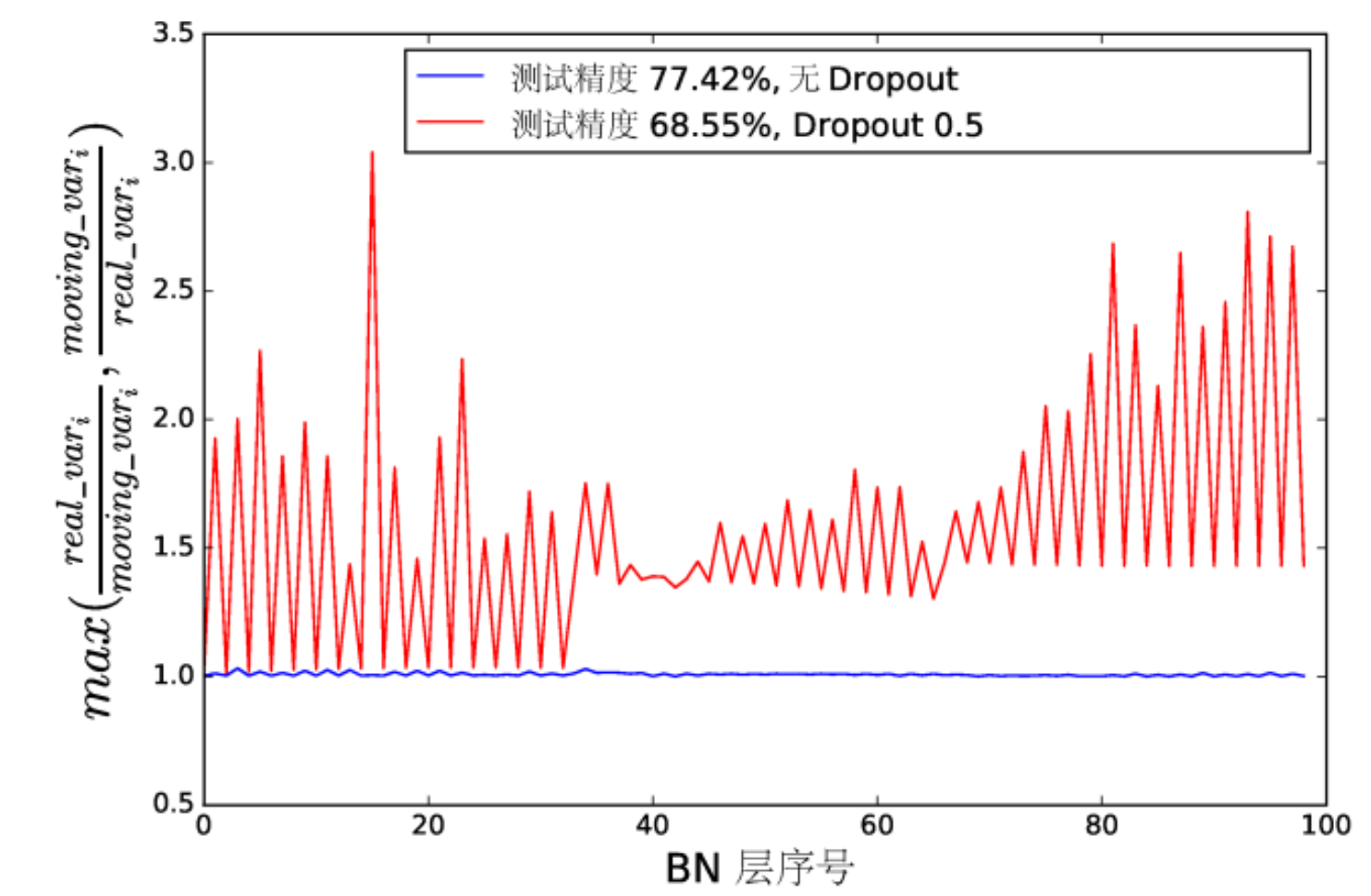
從圖中可以看到,沒有使用dropout的模型每層的方差變化不大(藍線),而使用了dropout的紅線方差極不穩定(紅線)
解決方法







)

)







技術規格解析:流媒體協議的新突破)
)

