本文一定要閱讀我上篇文章!!!
超詳細VLLM框架部署qwen3-4B加混合推理探索!!!-CSDN博客
本文是基于上篇文章遺留下的問題進行說明的。
一、本文解決的問題
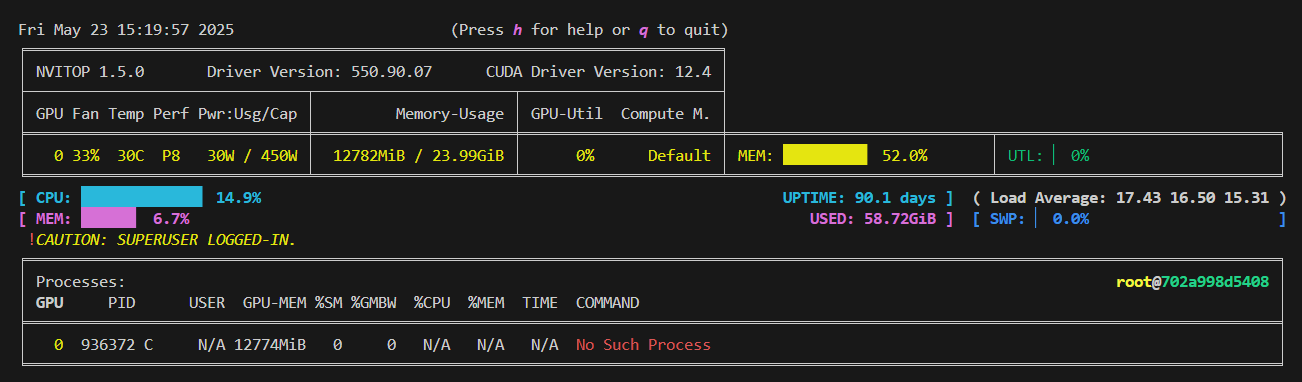
問題1:我明明只部署了qwen3-4B的模型,為什么啟動VLLM推理框架后能占到顯存的0.9,占了22GB顯存?
問題2:VLLM框架部署Qwen3-4B的GPU最小配置應該是多少,怎么計算?
問題3:VLLM框架預留更多的GPU資源對模型推理速度影響多大?
問題4:并發處理10-20人的訪問本地模型請求,GPU配置應該怎么計算,怎么分配?
二、解決問題1
問題1:我明明只部署了qwen3-4B的模型,為什么啟動VLLM推理框架后能占到顯存的0.9,占了22GB顯存?
官網回答圖片,可以知道VLLM框架是預置了0.9的顯存給這個模型,但是模型實際不一定需要要那么多顯存。還有最大輸入的token默認值是40960,正常我們輸入的長文本不需要那么大。

因此可以自定義分配GPU顯存給VLLM服務,測試一下,當然你分配的顯存越少,推理速度越慢。
比如我分配了0.5的顯存重啟VLLM服務,就可以看到分配的顯存就是0.5左右。
vllm serve /root/lanyun-tmp/modle/Qwen3-4B --max-model-len 10000 --gpu-memory-utilization 0.5?
三、解決問題2
問題2:VLLM框架部署Qwen3-4B的GPU最小配置應該是多少,怎么計算?
執行完下述命令后
?vllm serve /root/lanyun-tmp/modle/Qwen3-4B --max-model-len 10000 --gpu-memory-utilization 0.5?
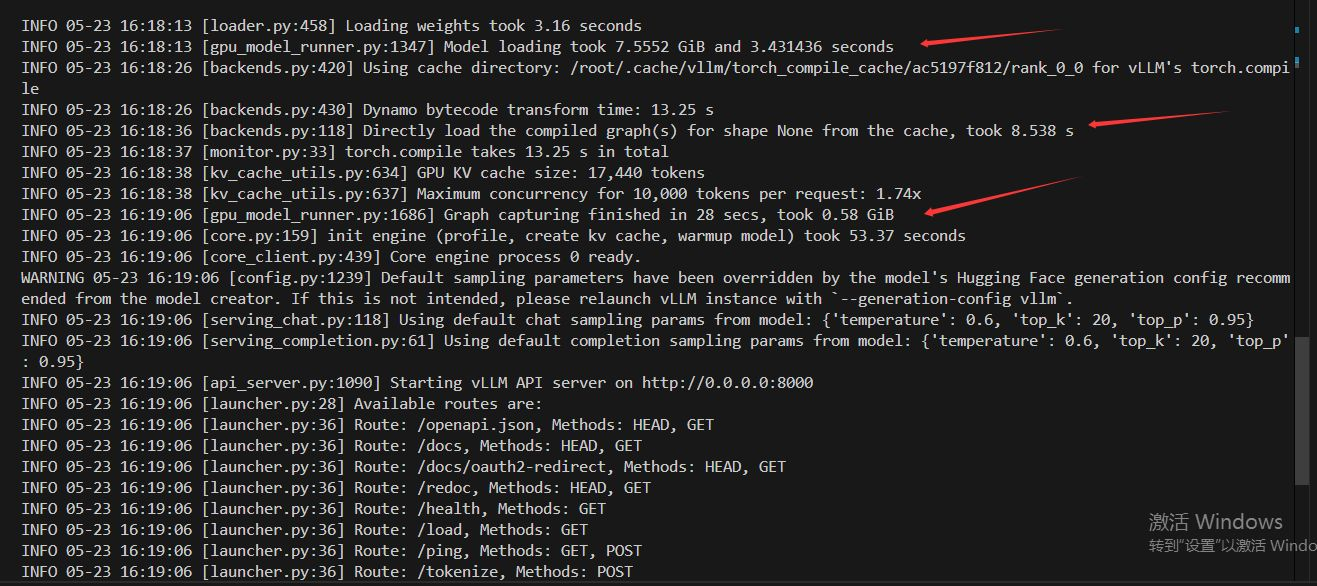
首先先分析配置日志
-
??顯存占用??
- ??模型加載??:7.552 GiB(主模型權重)。
- ??KV緩存??:17,440 tokens(具體顯存需結合模型參數,但日志未直接給出數值)。
- ??圖捕獲階段??:0.58 GiB(動態編譯優化時的臨時占用)。
- ??總計顯存??:主模型+臨時操作約為 ??8.13 GiB左右??(KV緩存需額外計算,但日志未明確)。
- ??總計顯存??:主模型+臨時操作約為 ??8.13 GiB左右??
也就是說,除了自定義的KV緩存,至少8.13GB
?我們還可以自己計算KV顯存,根據模型的配置文件和下述公式,得到緩存是1.37GB,也可以直接把模型配置發給deepseek叫它計算。

KV緩存總量 = batch_size × 序列長度 × 模型層數 × 2 × d_model × sizeof(float16) ???
因此VLLM部署Qwen3-4B的在--max-model-len 10000GPU的情況下模型占用的GPU資源是,8.13GB+1.37GB=9.5GB
如果是默認情況--max-model-len 40960,模型占用的GPU資源是,8.13GB+5.62GB=13.75GB
小技巧,如果你不相信AI計算的結果,可以執行默認的最長輸入命令。
vllm serve /root/lanyun-tmp/modle/Qwen3-4B? --gpu-memory-utilization 0.5?
發現報錯
?raise ValueError( ValueError: To serve at least one request with the models's max seq len (40960), (5.62 GiB KV cache is needed, which is larger than the available KV cache memory (2.39 GiB). Based on the available memory, Try increasing `gpu_memory_utilization` or decreasing `max_model_len` when initializing the engine.?
?錯誤提示顯示5.62 GiB KV cache is needed,而當前可用顯存僅2.39 GiB。KV緩存用于存儲Transformer模型中各層的鍵值向量。
我們就可以自己計算,10000的token所占用的應該KV緩存的GPU大小,10000/40960*5.62GB=1.37GB。說明AI計算的是正確的。
四、解決問題3
問題3:VLLM框架預留更多的GPU資源對模型推理速度影響多大?
使用下面代碼進行測試分配不同的GPU,推理時間變化多少。因為每次生成的token數量不一樣,所以我們主要是以tokens/s為衡量標準進行測試。
import time
from openai import OpenAI# 初始化客戶端
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"client = OpenAI(
? ? api_key=openai_api_key,
? ? base_url=openai_api_base,
)# 使用高精度計時器
start_time = time.perf_counter() ?# 比time.time()精度更高[3](@ref)chat_response = client.chat.completions.create(
? ? model="/root/lanyun-tmp/modle/Qwen3-4B",
? ? messages=[
? ? ? ? {"role": "user", "content": "你有什么功能"},
? ? ],
? ? max_tokens=8192,
? ? temperature=0.7,
? ? top_p=0.8,
? ? presence_penalty=1.5,
? ? extra_body={
? ? ? ? "top_k": 20,?
? ? ? ? "chat_template_kwargs": {"enable_thinking": True},
? ? },
)end_time = time.perf_counter()
elapsed = end_time - start_timeprint("Chat response:", chat_response)
print(f"\n[性能報告] 請求耗時: {elapsed:.4f}秒")
print(f"生成token數: {chat_response.usage.completion_tokens} tokens")
print(f"每秒生成速度: {chat_response.usage.completion_tokens/elapsed:.2f} tokens/s")
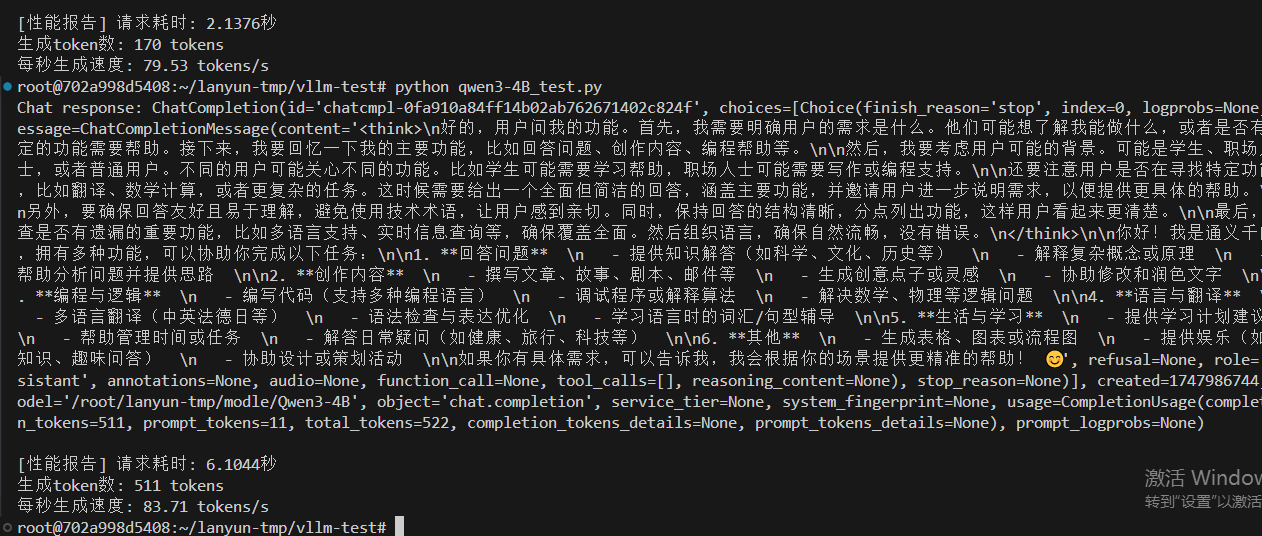
情況一,設置最大10000token數量,分配0.5GPU,12.7GB給VLLM服務,除去大模型的啟動占用9.5GB,還給VLLM服務預留空間為3.2GB。
vllm serve /root/lanyun-tmp/modle/Qwen3-4B --max-model-len 10000 --gpu-memory-utilization 0.5?
有思考83.71 tokens/s,無思考79.53 tokens/s
情況二,設置最大10000token數量,分配0.8GPU,20GB給VLLM服務,除去大模型的啟動占用9.5GB,還給VLLM服務預留空間為10.5GB。
vllm serve /root/lanyun-tmp/modle/Qwen3-4B --max-model-len 10000 --gpu-memory-utilization 0.8
有思考77.09 tokens/s,無思考?78.18 tokens/s
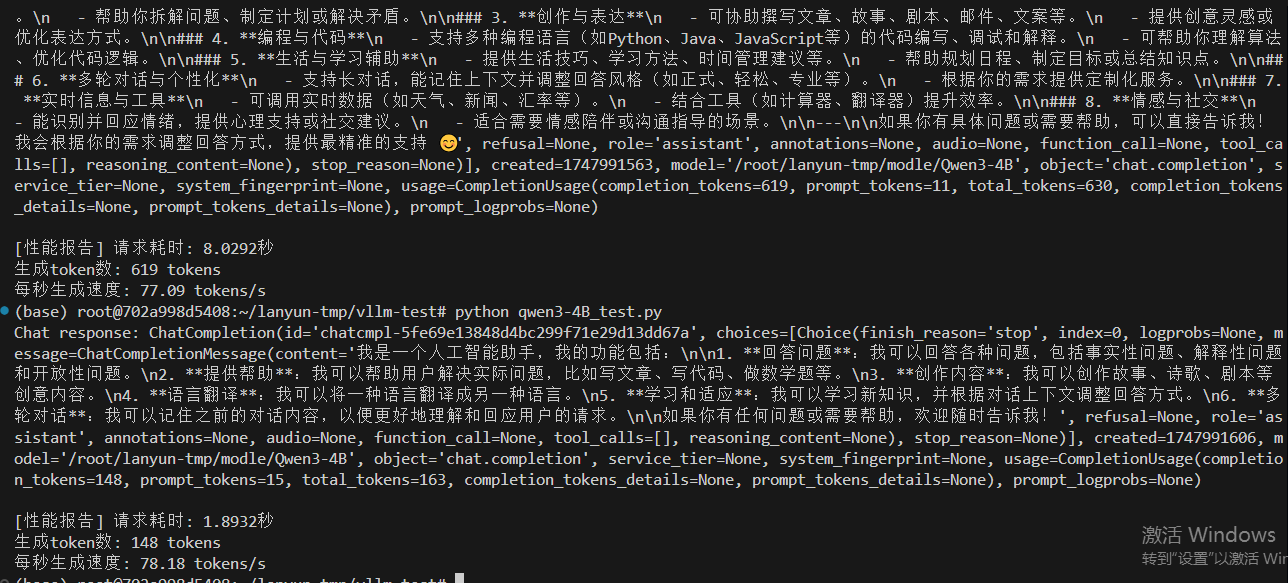
通過兩個情況的對比,預留給VLLM服務的GPU空間大小沒有對速度有太大影響,甚至空間小一定,生成速度還更多,但是多運行幾次,發現速度是差不多的。?
五、解決問題4
問題4:如何測試多人并發訪問大模型服務,多少人是上限,生成的速度變化是怎么樣的?
我們可以創建一個并發測試的代碼concurrency_test.py
# concurrency_test.py
import argparse
import threading
import time
from queue import Queue
# qwen3-4B_test.py
import time
from openai import OpenAI
def send_request(prompt="你有什么功能", max_tokens=8192, temperature=0.7):
? ? """單次請求測試函數"""
? ? client = OpenAI(
? ? ? ? api_key="EMPTY",
? ? ? ? base_url="http://localhost:8000/v1",
? ? )
? ?
? ? start_time = time.perf_counter()
? ? try:
? ? ? ? response = client.chat.completions.create(
? ? ? ? ? ? model="/root/lanyun-tmp/modle/Qwen3-4B",
? ? ? ? ? ? messages=[{"role": "user", "content": prompt}],
? ? ? ? ? ? max_tokens=max_tokens,
? ? ? ? ? ? temperature=temperature,
? ? ? ? ? ? extra_body={"top_k": 20}
? ? ? ? )
? ? ? ? elapsed = time.perf_counter() - start_time
? ? ? ? return {
? ? ? ? ? ? "success": True,
? ? ? ? ? ? "time": elapsed,
? ? ? ? ? ? "tokens": response.usage.completion_tokens,
? ? ? ? ? ? "speed": response.usage.completion_tokens/elapsed,
? ? ? ? ? ? "response": response.choices[0].message.content
? ? ? ? }
? ? except Exception as e:
? ? ? ? return {
? ? ? ? ? ? "success": False,
? ? ? ? ? ? "error": str(e),
? ? ? ? ? ? "time": time.perf_counter() - start_time
? ? ? ? }
class ConcurrentTester:
? ? def __init__(self, num_users):
? ? ? ? self.num_users = num_users
? ? ? ? self.results = Queue()
? ? ? ? self.start_barrier = threading.Barrier(num_users + 1) ?# 同步所有線程同時啟動
? ? ? ?
? ? def _worker(self, user_id):
? ? ? ? """單個用戶的請求線程"""
? ? ? ? self.start_barrier.wait() ?# 等待所有線程就緒
? ? ? ? result = send_request(prompt=f"測試用戶{user_id}的并發請求")
? ? ? ? self.results.put((user_id, result))
? ? def run(self):
? ? ? ? # 創建并啟動所有線程
? ? ? ? threads = []
? ? ? ? for i in range(self.num_users):
? ? ? ? ? ? t = threading.Thread(target=self._worker, args=(i+1,))
? ? ? ? ? ? t.start()
? ? ? ? ? ? threads.append(t)
? ? ? ?
? ? ? ? # 等待所有線程準備就緒
? ? ? ? self.start_barrier.wait()
? ? ? ? start_time = time.perf_counter()
? ? ? ?
? ? ? ? # 等待所有線程完成
? ? ? ? for t in threads:
? ? ? ? ? ? t.join()
? ? ? ? ? ?
? ? ? ? total_time = time.perf_counter() - start_time
? ? ? ?
? ? ? ? # 統計結果
? ? ? ? success = 0
? ? ? ? total_tokens = 0
? ? ? ? speeds = []
? ? ? ? errors = []
? ? ? ?
? ? ? ? while not self.results.empty():
? ? ? ? ? ? user_id, res = self.results.get()
? ? ? ? ? ? if res['success']:
? ? ? ? ? ? ? ? success += 1
? ? ? ? ? ? ? ? total_tokens += res['tokens']
? ? ? ? ? ? ? ? speeds.append(res['speed'])
? ? ? ? ? ? else:
? ? ? ? ? ? ? ? errors.append(f"用戶{user_id}錯誤:{res['error']}")
? ? ? ?
? ? ? ? return {
? ? ? ? ? ? "total_time": total_time,
? ? ? ? ? ? "success_rate": success/self.num_users,
? ? ? ? ? ? "avg_speed": sum(speeds)/len(speeds) if speeds else 0,
? ? ? ? ? ? "total_tokens": total_tokens,
? ? ? ? ? ? "errors": errors
? ? ? ? }
if __name__ == "__main__":
? ? parser = argparse.ArgumentParser()
? ? parser.add_argument("--users", type=int, required=True,
? ? ? ? ? ? ? ? ? ? ? ?help="并發用戶數量")
? ? args = parser.parse_args()
? ?
? ? tester = ConcurrentTester(args.users)
? ? print(f"開始{args.users}用戶并發測試...")
? ? results = tester.run()
? ?
? ? print("\n測試報告:")
? ? print(f"總耗時:{results['total_time']:.2f}秒")
? ? print(f"成功請求:{results['success_rate']*100:.1f}%")
? ? print(f"平均生成速度:{results['avg_speed']:.2f}tokens/s")
? ? print(f"總生成token數:{results['total_tokens']}")
? ?
? ? if results['errors']:
? ? ? ? print("\n錯誤列表:")
? ? ? ? for err in results['errors']:
? ? ? ? ? ? print(f"? {err}")
分別測試上述兩個情況:
情況一,設置最大10000token數量,分配0.5GPU,12.7GB給VLLM服務,除去大模型的啟動占用9.5GB,還給VLLM服務預留空間為3.2GB。
vllm serve /root/lanyun-tmp/modle/Qwen3-4B --max-model-len 10000 --gpu-memory-utilization 0.5?
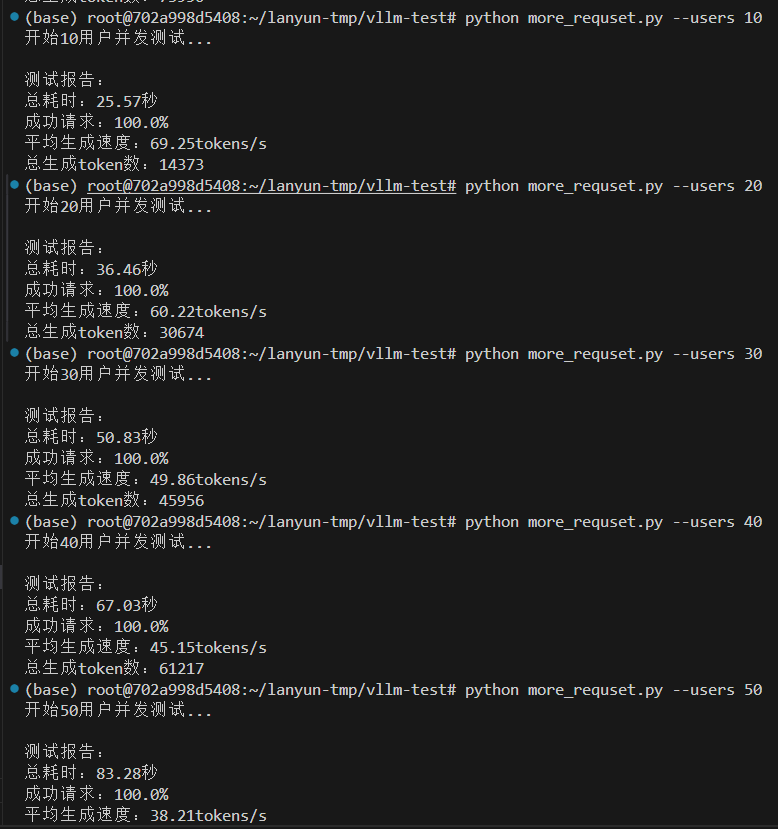
情況二,設置最大10000token數量,分配0.8GPU,20GB給VLLM服務,除去大模型的啟動占用9.5GB,還給VLLM服務預留空間為10.5GB。
vllm serve /root/lanyun-tmp/modle/Qwen3-4B --max-model-len 10000 --gpu-memory-utilization 0.8
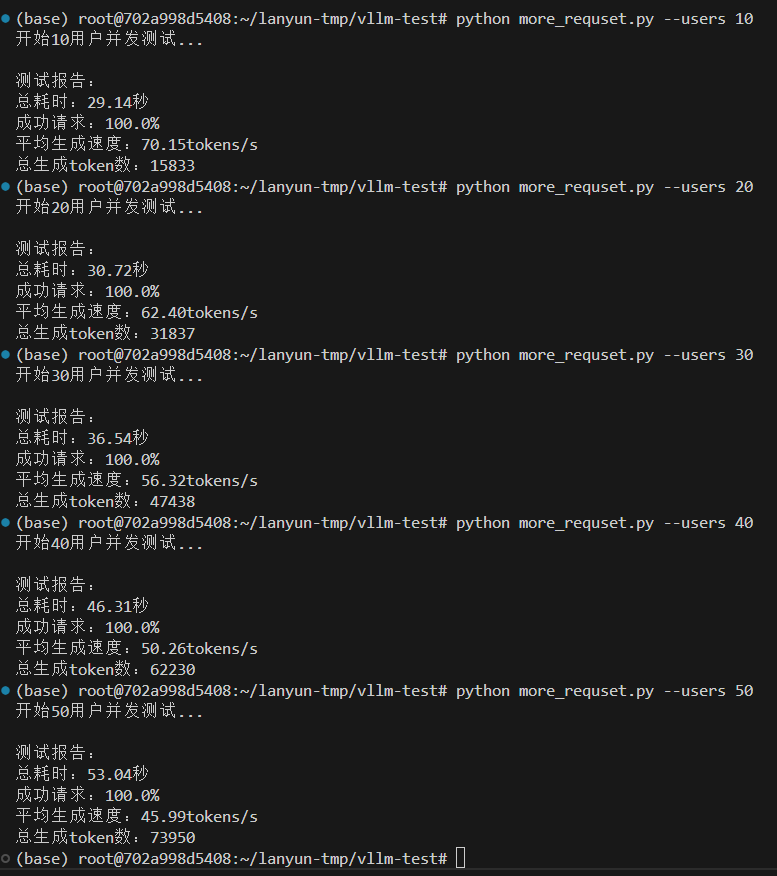 ?
?
情況三,設置最大10000token數量,分配0.5GPU,12.7GB給VLLM服務,除去大模型的啟動占用9.5GB,還給VLLM服務預留空間為3.2GB。
vllm serve /root/lanyun-tmp/modle/Qwen3-4B --max-model-len 10000 --gpu-memory-utilization 0.5?
終極測試500個并發請求,可以看到VLLM框架一次性是處理11個請求,然后分批次排隊處理這么多的并發請求。然后越到后面處理的請求越少。
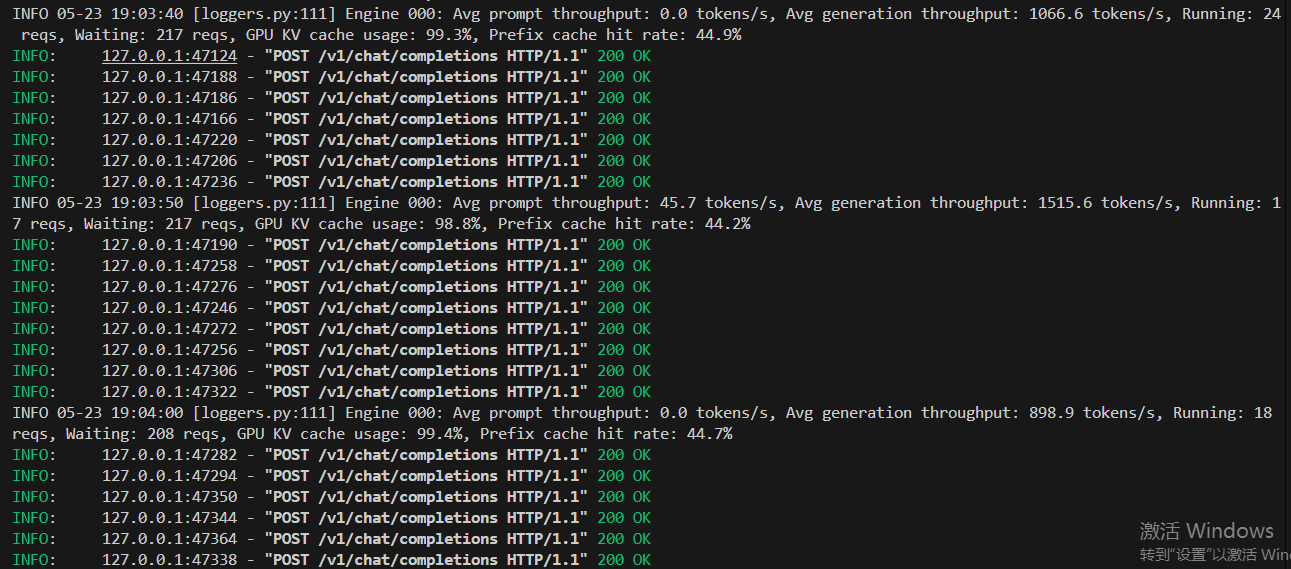
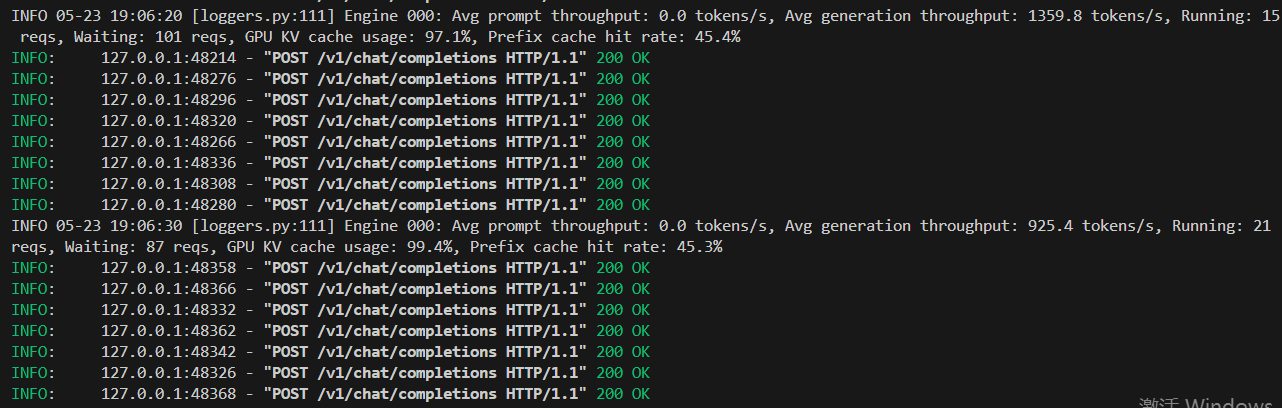
結論,VLLM處理框架處理并發的能力是可以的,它是通過并發處理11給請求,別的請求是排隊處理。所以只要模型通過VLLM部署起來,理論上它解決無上限的并發請求,就是要排隊等著大模型回復。?
)

)







技術規格解析:流媒體協議的新突破)
)







