前言
? ? ? ? 我們通過提示詞工程提升了通用LLM的專業知識水平,并結合Function Calling構建了私有業務能力。為了在實際應用中有效維護私有領域的專有數據,我們進一步采用大模型微調或RAG檢索增強技術,使LLM能夠充分掌握私有知識庫的內容。
一、微調和RAG選擇
①?知識靜態 vs 動態
????????如果企業知識庫在短期內變化較少,更傾向長期積累,且更關心對話流暢度和風格統一,可優先考慮微調大模型;
????????如果知識庫更新頻率很高、內容格式多樣、需要保證用戶問到最新信息推薦,則RAG更適合。
②?資源與能力
????????微調:需要有訓練基礎設施(GPU 服務器或云上 GPU ),有標注能力、MLOps 經驗;后續每次版本迭代需額外算力。
????????RAG:需要有向量數據庫(如 Milvus、Faiss、Pinecone 等),并熟悉向量檢索與 Prompt 工程;大模型可直接調用 API,無需訓練資源投入。
③?用戶體驗與業務目標
????????一致性與口徑統一:微調后的模型在同一領域內輸出風格更穩定,適合有統一口徑要求的內部文檔問答、內部知識助手;
????????最新信息與引用可查:RAG 可以隨時引用最新文檔,適合外部客服或知識庫更新頻繁的場景。
④ 區別一覽
| 對比維度 | 微調大模型(Fine-Tuning) | 檢索增強生成(RAG) |
|---|---|---|
| 響應流程 | 只需模型一次前向推理 | 先檢索→再拼接Prompt→大模型推理 |
| 部署與基礎設施 | 需要大規模微調訓練環境與推理環境(專用 GPU) | 需要向量索引系統 + 通用大模型推理環境 |
| 知識更新成本 | 高——每次新增/修改都需重新微調 | 低——只需更新向量索引,無需再訓練大模型 |
| 生成連貫度 | 通常更連貫、更具連貫的領域風格 | 依賴檢索質量,可能出現回答片段化或上下文脫節 |
| 可解釋性 | 較差——知識藏在模型權重中,難以追蹤具體來源 | 較好——可展示檢索到的文檔片段及來源 |
| 資源與成本 | 高——訓練耗時長、顯存占用大;需要專門的 MLOps 流程 | 中等——嵌入生成與檢索占用資源有限,但需維護索引服務 |
| 維護與迭代 | 復雜——每次迭代都要全流程跑一遍,包括采集、標注、微調、評估 | 靈活——只要索引數據新增/修改即可 |
| 實時性要求 | 對于在線部署模型推理,延遲相對較低;但更新頻率低時難以實時應答新知識 | 延遲略高,需要檢索階段;索引規模大時需要做性能優化 |
| 應用場景 | 知識更新頻率較低,且對回答一致性、完整性要求高的場景;企業內訓庫、FAQ 穩定版本 | 知識庫內容頻繁更新,且需兼容多種文檔類型場景;在線文檔檢索問答、動態資料庫 |
二、RAG介紹
????????RAG 全稱為 Retrieval-Augmented Generation(檢索增強生成)。簡單來說,RAG 是一種將「文檔/知識庫檢索」與「大語言模型(LLM)生成」相結合的技術架構。
? ? ? ? 大致流程是:當用戶提出問題時,先檢索相關的知識片段(通常是私有文檔庫或公開文檔庫中與問題最相關的片段),然后將這些檢索到的片段拼接到提示(prompt)里,交給大語言模型進行生成式回答。
????????通過“先檢索、再生成”的思路,RAG 能將模型回答更加“基于事實”,同時又保留了 LLM 在自然語言生成(NLG)方面的優勢。
三、RAG具體實現流程
使用 Sora 文生圖 功能獲得的基本流程圖
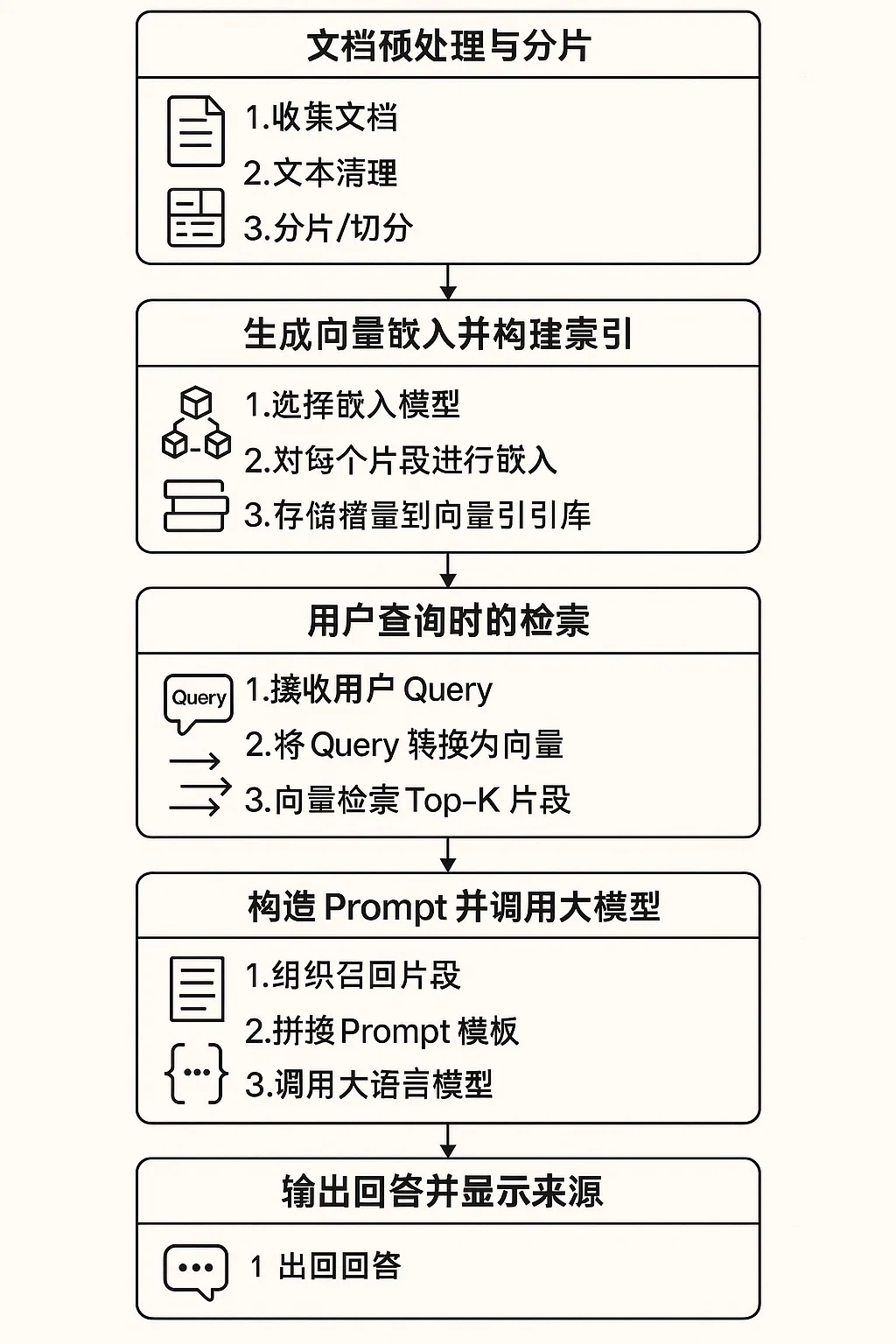
①?文檔預處理與分片(Shard/Chunk)
(1)?收集文檔
????????將所有要納入私有知識庫的內容(如內部手冊、技術文檔、FAQ、報表說明、法律條款等)集中到一個來源。
(2)?文本清理
????????對不同格式的文檔(PDF、Word、HTML)進行 OCR(如果是圖片內文字)或直接提取純文本,去除多余空行、頁眉頁腳等無關信息。
(3)?分片/切分
????????將一整篇長文檔按“章節”、“段落”,或按固定 Token/字符長度(比如每 500-1,000 字)切分成一個個小單元(“片段”)。
????????理想情況下,每個片段要保證“語義完整”,既不能太短導致斷句,也不能太長讓后續檢索浪費上下文。
② 生成向量嵌入并構建索引
(1)?選擇嵌入模型
????????常用的文本嵌入模型包括 OpenAI 的 text-embedding-ada-002、Sentence-BERT(SBERT)、MiniLM 、阿里 的 multimodal-embedding-v1等。
(2)?對每個片段進行嵌入
????????把每個文本片段輸入嵌入模型,得到一個定長向量(通常維度在 512~1,536 之間)。
(3)?存儲向量到向量索引庫
????????選擇一個向量數據庫(如 Faiss、Milvus、Pinecone、ChromaDB 等)來存儲這些向量,同時保留與原文本片段的映射關系(ID、文檔來源、頁碼/段落號等元信息)。
????????同時可為每個向量關聯額外的元數據,以便后續檢索后快速知道“這個片段來自哪個文檔、哪個位置”。
③?用戶查詢時的檢索
(1)?接收用戶 Query
????????用戶在對話界面/API 接口中輸入一個自然語言問題。
(2)?將 Query 轉換為向量
????????同樣使用上面嵌入模型對用戶 query 進行編碼,得到一個“查詢向量”。
(3)?向量檢索 Top-K 片段
????????在向量索引庫中,以查詢向量為基準,按照余弦相似度(或內積)檢索出與之最相近的 Top-K 個文檔片段。
????????通常 K 的值在 3~10 之間,可根據知識庫規模與實時性要求做實驗調優。
④?構造 Prompt(提示)并調用大模型
(1)?組織召回片段
????????根據檢索結果,取到的每個片段都會包含原文短句;此時可以將最相關的 3~5 條片段按“重要性”排序。
(2)?拼接 Prompt 模板
? ? ? ? 類似以下:
你是公司的智能知識問答助手。以下是與用戶問題相關的文檔片段,請基于這些片段來回答用戶問題,并在回答末尾以 “[來源:文檔名, 段落編號]” 的方式注明出處。
=== 檢索到的文檔片段開始 ===
[片段1文字內容]
[片段2文字內容]
…
=== 文檔片段結束 ===用戶提問:{用戶原始問題}
回答要點:?
(3)?調用大語言模型
????????將上述拼接好的完整 Prompt(包括檢索到的內容和用戶問題)發送給通用大模型(如 GPT-4、LLaMA-2、Claude 2、內部自研大模型等)。模型會“參照”這些真實片段內容,生成一段連貫且有憑據的回答。如果需要極高的可解釋性,還可以在 Prompt 中要求“請在回答中引用片段編號”。
⑤?輸出回答并顯示來源
????????返回的文本通常包括完整自然語言回答,有時也會帶上“參考來源”或“原文段落編號”。
四、RAG自定義優化方案
①?分片策略
????????按語義切分:優先按“章節/小節”或“自然段落”分片,保證每個片段內部邏輯連貫。
????????重疊分片:相鄰片段可以有少量上下文重疊(比如前后 50 字重疊),避免切分邊界導致信息丟失。
②?檢索召回策略
????????向量 + 關鍵詞混合檢索:先用布爾檢索或 BM25 做粗召回,再用向量檢索做精排,提高召回準確率。
????????多輪檢索:當用戶問得非常籠統時,可先做一級檢索(廣泛召回),再基于用戶反饋精選 Top-K 片段做二級檢索。
③?Prompt 長度管理
????????如果 Top-K 片段拼接后超過 LLM 的上下文窗口(如 GPT-4 32K Token 限制),需要先對每個片段做摘要壓縮,只截取最關鍵的句子。或者優先保留與用戶 query 余弦相似度最高的那幾段,再拼接到 prompt 里。
④?動態更新
????????文檔新增/變更:需對新增文檔切分并生成嵌入,插入向量索引;若某個文檔更新,先在索引里刪除對應向量,再重新切分生成插入。
????????索引重建或離線批量更新:對于文檔量劇增、檢索效果下降時,可定期做一次全量索引重建,或者做分庫分片。
⑤?來源可視化
????????一般會把“文檔名+頁碼/段落號”作為元信息存入索引里,最終在回答中把它寫成 “[來源:XXX 文檔,第 12 頁,第 3 段]”,讓用戶確認事實依據。
五、前置準備-開通向量庫
① 注冊賬號
? ? ? ? 可以免費使用 2G 容量的向量數據庫:pinecone
自由選擇方式注冊即可
選擇個人使用
選擇使用方式,我們用于AI智能體,文件大小都在1-10m之間即可
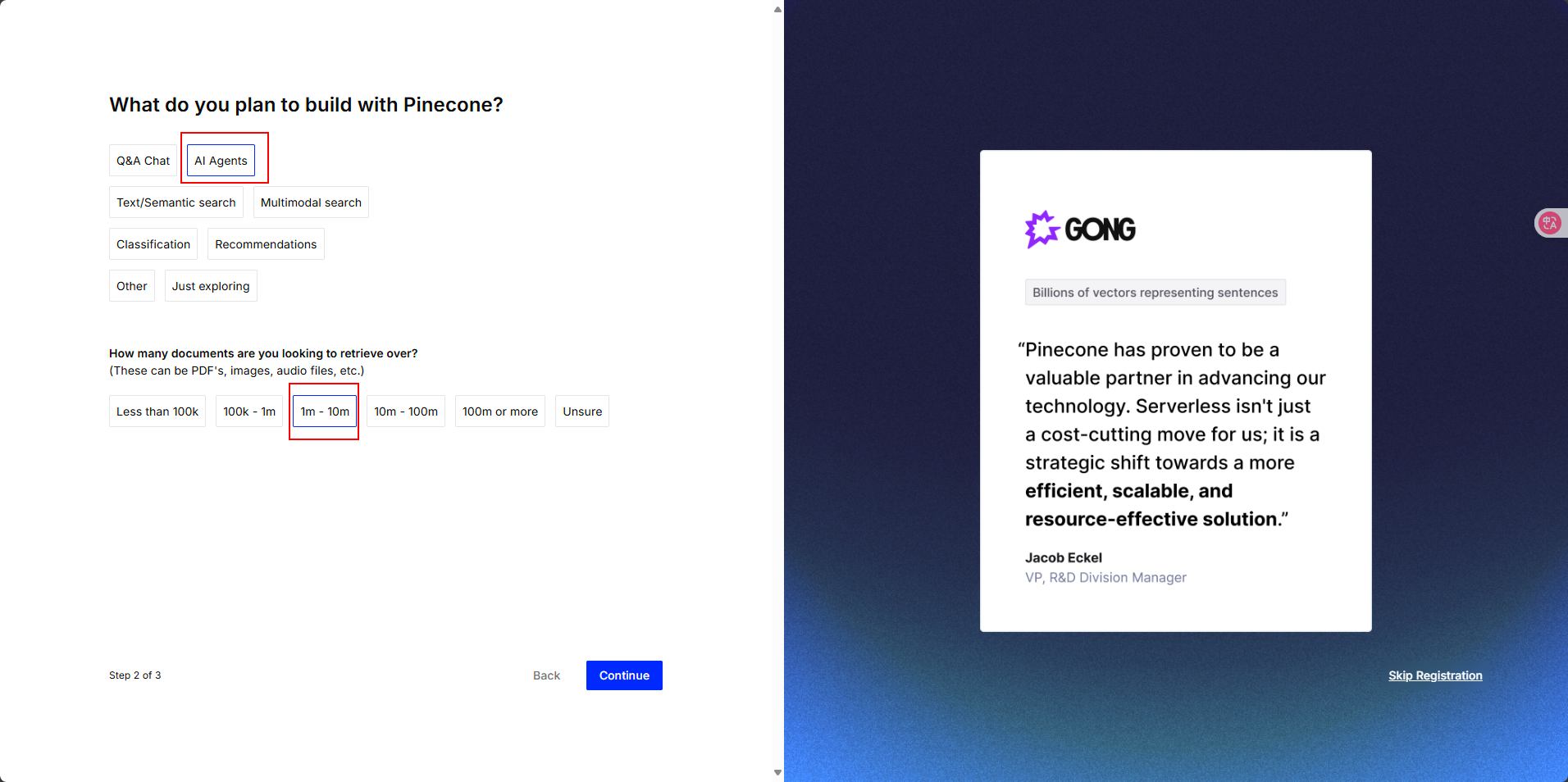
選擇初次使用向量數據庫
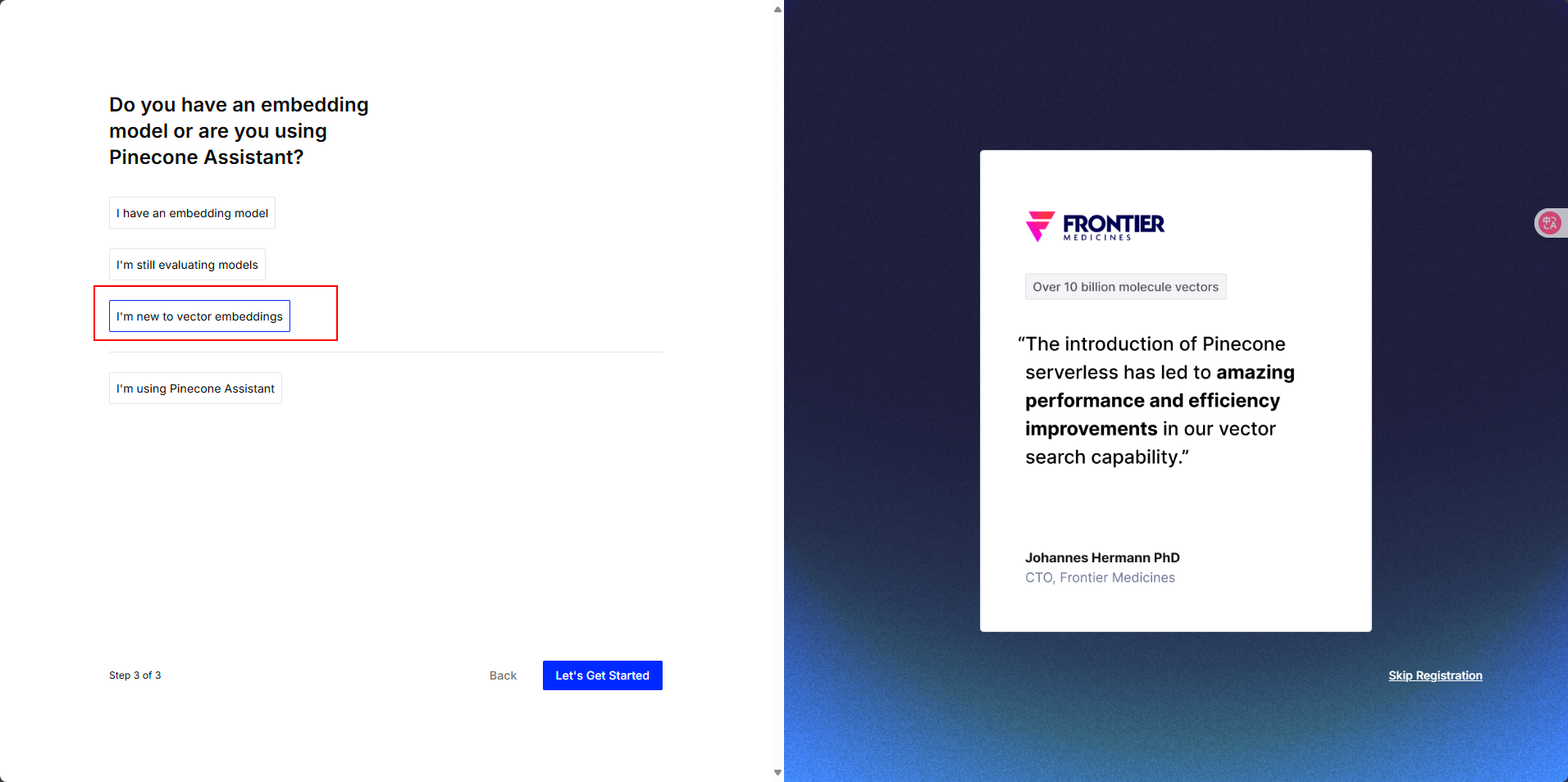
彈出提示自己的key,一定要記下來,保存好
② 創建向量數據庫
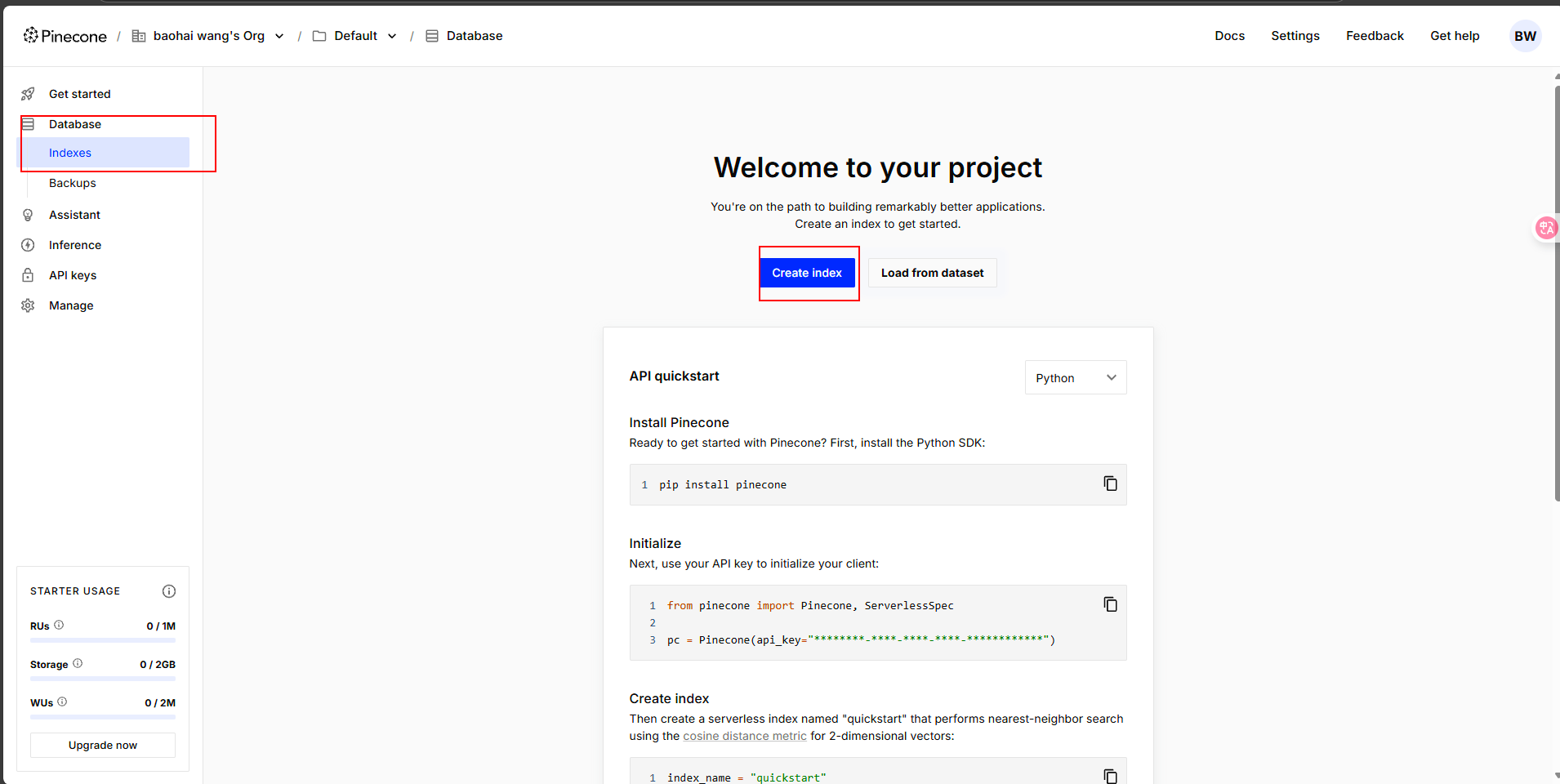
輸入數據庫名字,其他默認即可
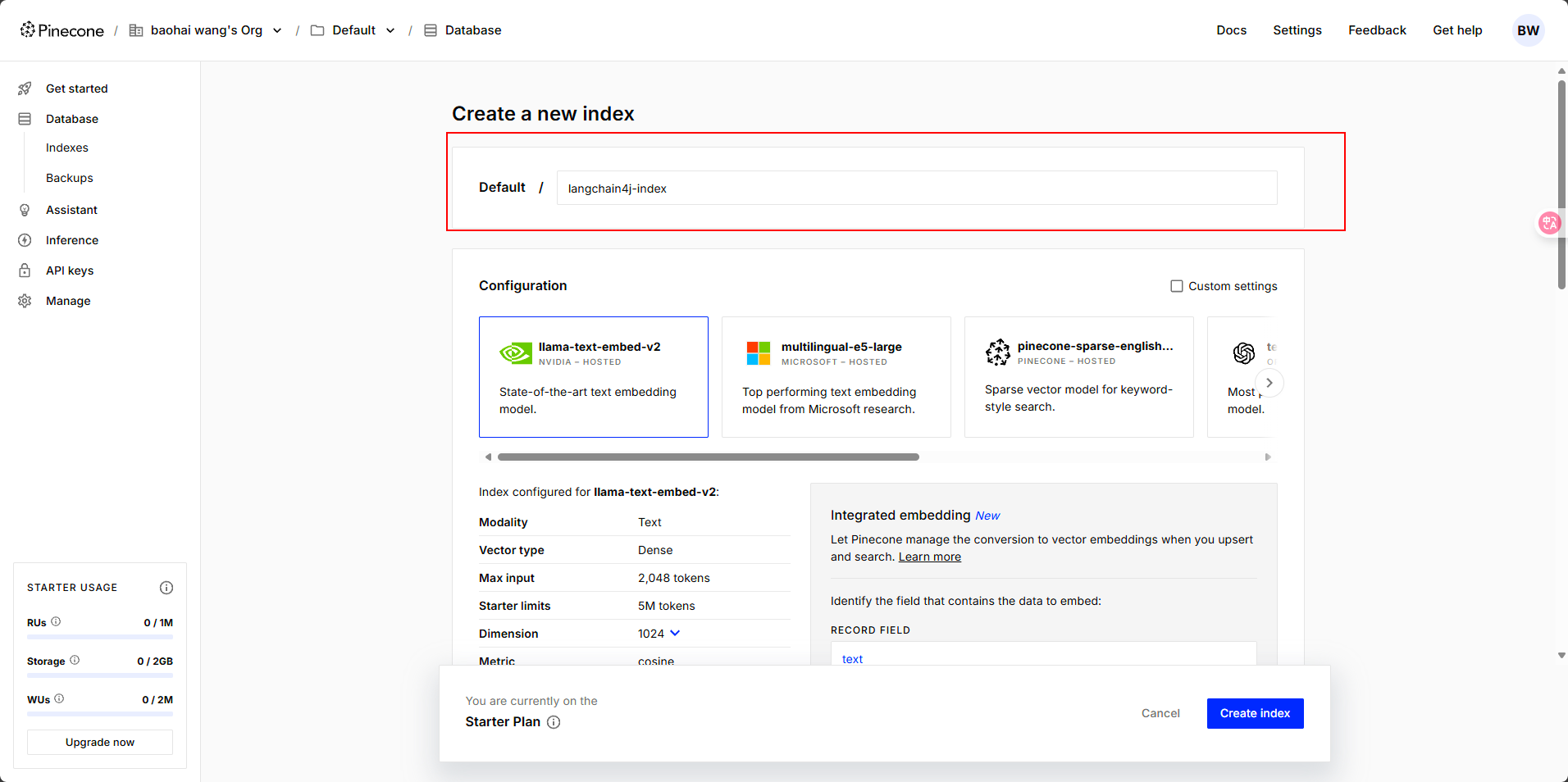
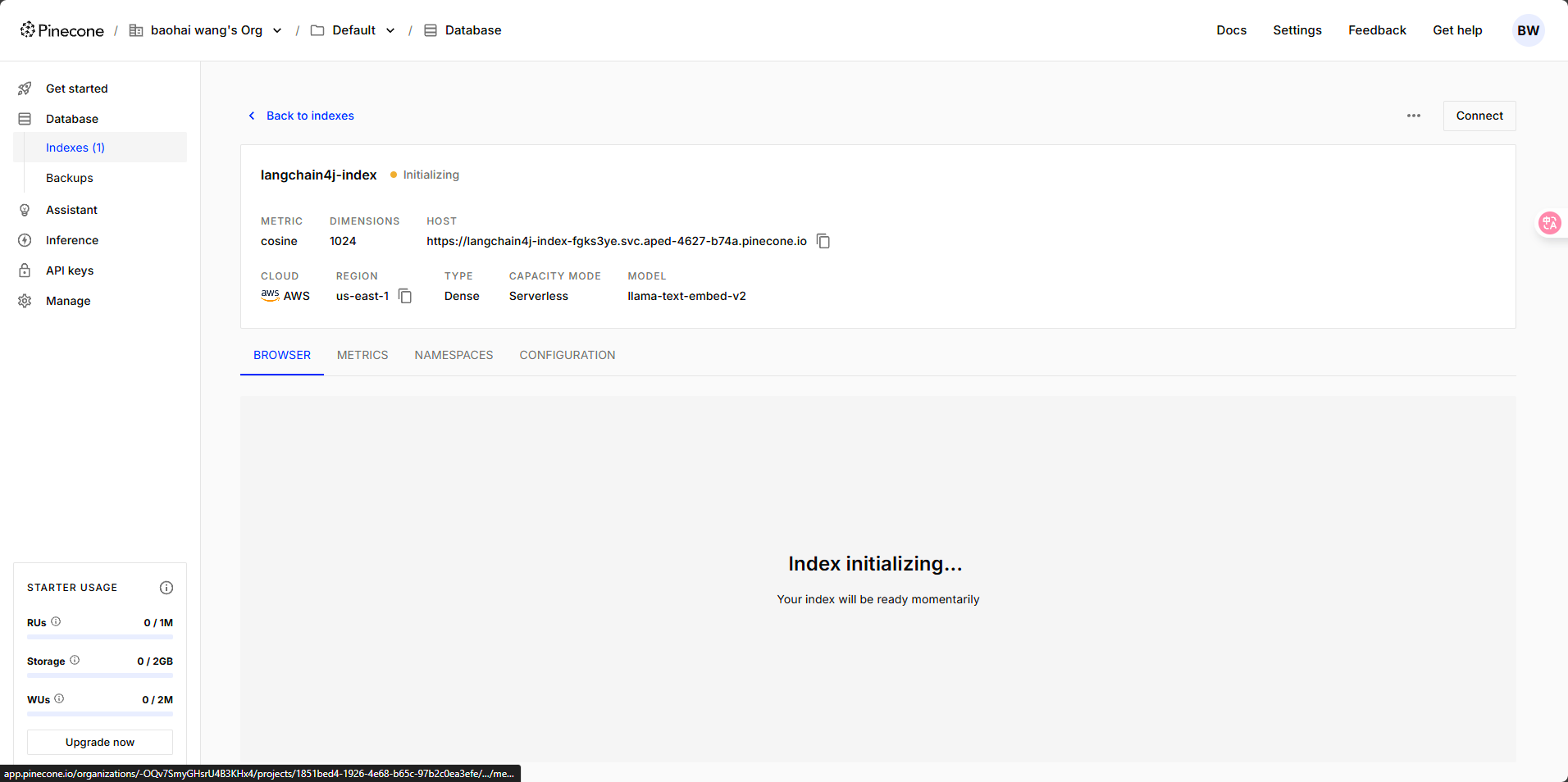
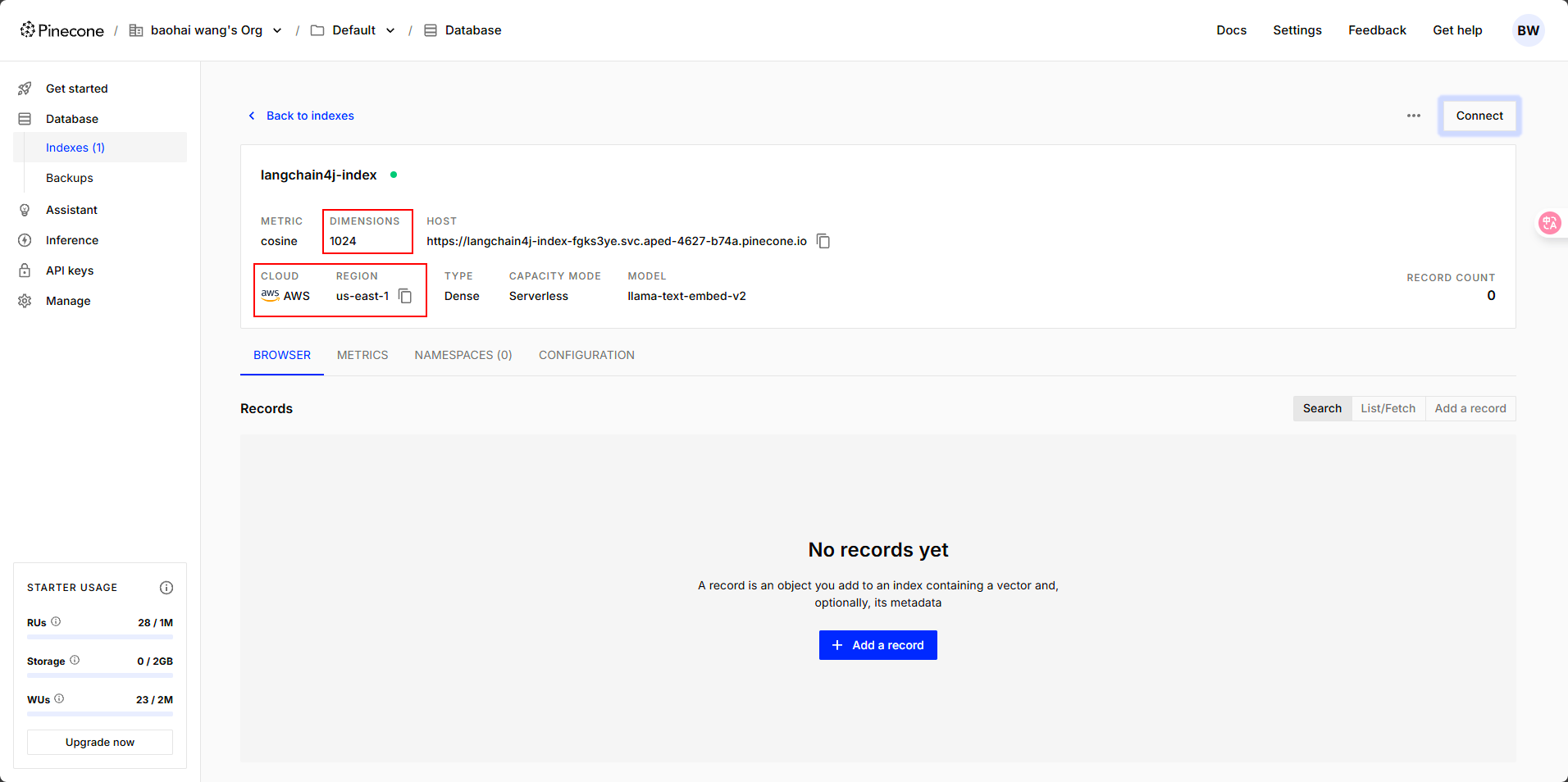
? ? ? ? 這里有一點需要注意,數據庫中的?Dimensions 是向量維度的意思,這里默認的維度是 1024。我們在選擇向量模型的時候,維度數值需要保持一致。
六、向量維度解讀
①?什么是“向量”?
????????在二維平面里,一個點的位置可以用 (x, y) 來表示:向右走 x 個單位、向上走 y 個單位,就到達了這個點。這個 (x, y) 就是一個二元向量,或者說“二維向量”。
????????在數學上,向量(vector)是一個在空間里既有大小(length/長度)又有方向(direction)的量。用數值來表示時,向量就變成了“數字的有序列表”——比如 (3, 4)、(-1, 7, 2) 等。
②?向量維度(dimension)究竟指的是什么?
(1)?在幾何空間里的維度
????????二維向量:如 (x, y),維度為 2,代表在平面上的位置或方向。
????????三維向量:如 (x, y, z),維度為 3,代表在三維空間里的位置。比如我們在現實中生活的空間就可以用三維向量表示:向右/左、向前/后、向上/下。
????????一維向量:如 (x),維度為 1,本質上是一個數值。比如在數軸上某一點的位置就可以看作一維。
????????維度(dimension)在幾何里就是“空間的自由度”或“坐標數量”,對應我們給定一個點需要多少個數值來描述。
(2)?在機器學習/嵌入(Embedding)里的維度
????????當我們把一段文字、一張圖片、一個聲音等“復雜對象”轉成向量時,并不再局限于“2 維”或“3 維”這樣直觀幾何意義上的維度,而是會用“更高維度”的數值列表來表達更豐富的語義或特征。比如一個文本句子可能被編碼成一個 512 維、768 維、甚至 1536 維的向量。這里的“維度數(512、768、1536……)”并不是“幾何中的坐標長度”,而是“特征空間(feature space)”中“特征維度”的數量。
????????舉個例子:如果我們把一段簡單句子看作一個“物品”,然后把它拆分成若干個“語義屬性”(比如:情感傾向、有無否定、主題領域、句子長度、關鍵詞出現頻次……)這些屬性越多,就需要更多的維度去表示。于是就產生了“高維向量”。
????????在深度學習模型(如 BERT、GPT、Sentence-BERT 等)中,模型會在訓練時學習到一個“映射函數”,將任意一句話或文檔映射到一個固定長度的向量(例如 768 維)。這個 768 維的向量里,每一維都是一個“抽象的特征值”,它并不代表人眼能直觀理解的“‘顏色’、‘長度’”之類的東西,而是“模型通過數千萬篇文本學習后抽象出的特征分量”。
(3)?為什么要用高維向量?
????????信息容量:高維向量能承載更多的“語義信息”或“特征組合”。在 2 維/3 維中我們很難用數字表示復雜的句子含義,但在幾百維里,模型可以把“情感”、“主題”“相似度”等不同層面混合編碼。
????????區分度更高:假設我們用 2 維向量去表示所有中文句子,那么很多不同意思的句子就可能擠在非常相近的位置、相互混淆。高維空間更容易把不一樣的句子拉開距離,讓相似的句子聚在一起,而與它無關的句子距離更遠。
????????線性可分性:在高維空間里,數據往往更容易通過“線性變換”或“簡單幾何操作”分離開來。許多經典機器學習理論(比如支持向量機的核函數方法)都基于“在高維空間里更容易找到分界面”這一思路。
③?如何理解“向量維度”在 RAG 中的作用?
(1)?從文本到向量(Embedding)
????????在 RAG 架構里,我們會把文檔或句子“嵌入(Embedding)”為一個定長向量。比如我們選擇了 768 維的嵌入模型(常見的 BERT、SBERT、OpenAI 的 text-embedding-ada-002 等),那么每個文檔片段就會被編碼成一個有 768 個數字組成的列表。
????????維度越多模型理論上能表達越豐富的特征細節,但計算量、存儲量也更大。
????????維度越少越節省存儲、速度越快,但信息可能被壓縮得過于粗糙,表示能力下降。
????????所以選擇向量維度時往往需要折中:比如 512、768、1024、1536 這樣的常見設置。
(2)?高維空間的“距離”與“相似度”
????????當我們有了若干個高維向量(比如多個文檔片段),要知道用戶提問與哪個片段“最相關”,就需要“在高維空間里量距離”。
????????常見的相似度度量:余弦相似度——衡量兩個向量之間的夾角余弦值,范圍在 -1 到 +1 之間。值越接近 1 表示兩者方向越一致(即語義越相似)。歐氏距離——直觀地計算高維空間里的距離長度,距離越短意味著越相似。
????????在高維空間里,語義相近的句子會在許多維度上的數值都比較接近,形成“高維鄰居”——這樣用余弦或歐式距離衡量時,就更容易找到真正語義最相近的文檔片段。如果維度過低(比如只有 2 維或 3 維),那么許多不同含義的句子就會被擠在“視圖”里相互重疊,檢索效果會變差。
④ 通俗比喻
????????以“菜的味道”做比喻:一道菜的“味道特點”可以由“咸度、甜度、酸度、辣度、鮮味”……等多個指標來衡量,每個指標就是一個“維度”。如果只拿“咸度”一個指標(1 維)判斷兩道菜是否類似,很容易出錯。但如果有 5、10 個維度,就能更準確。
六、使用向量數據庫
① 添加依賴
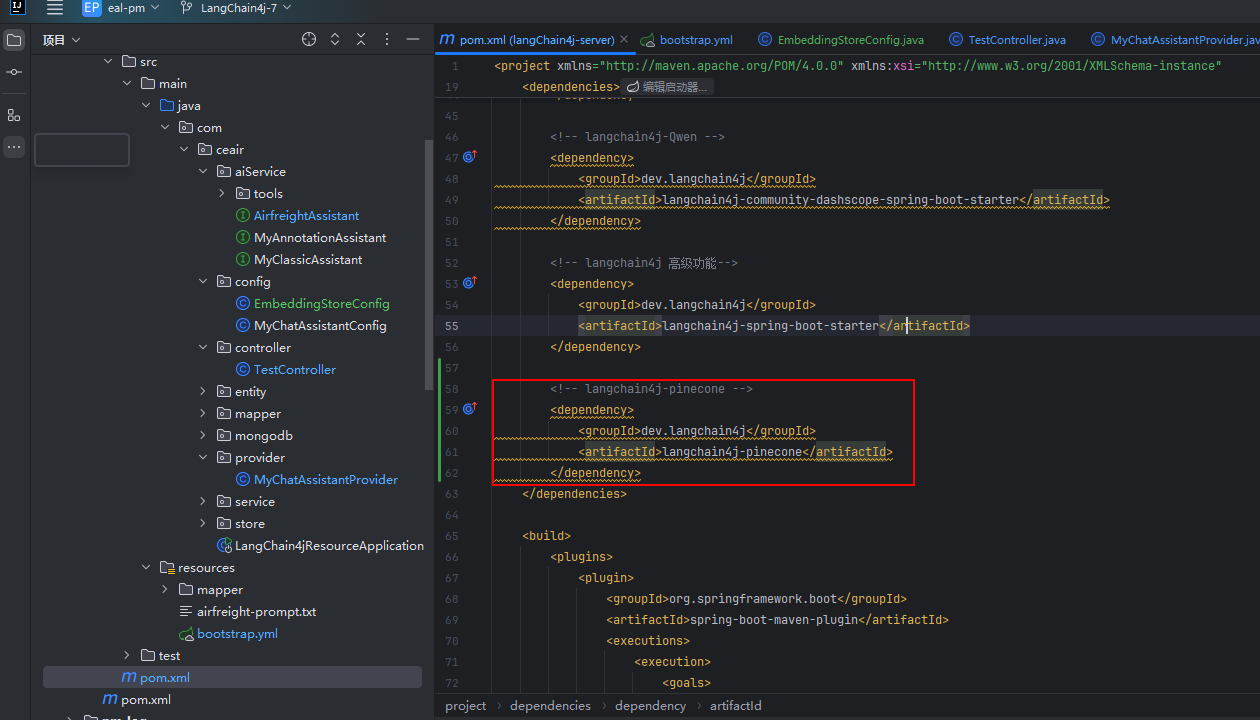
<!-- langchain4j-pinecone -->
<dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-pinecone</artifactId>
</dependency>② 添加配置文件
????????我們需要添加通義向量模型的配置,以及向量數據庫的配置。
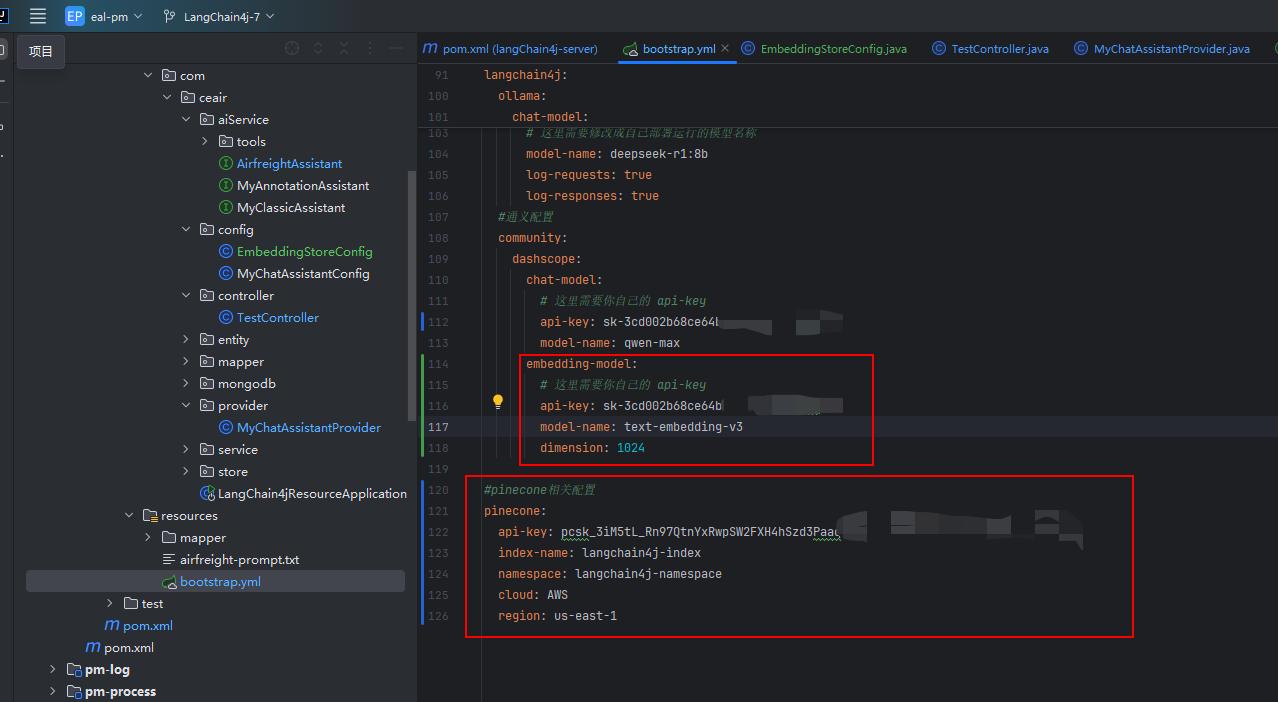
(1) 通義的向量模型配置說明
通義向量模型清單
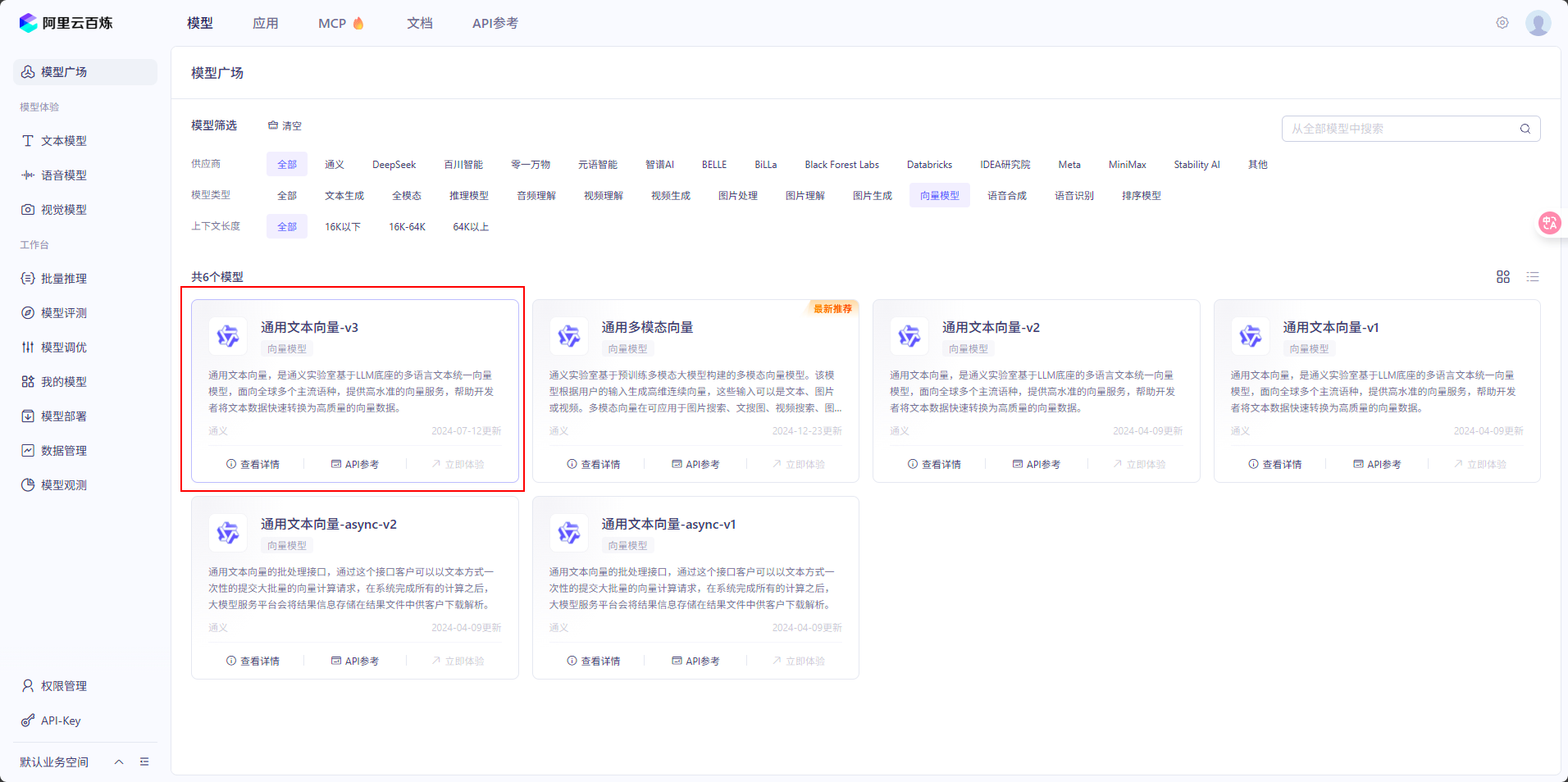
我們選擇第一個,進入API參考,可以看到向量維度支持 1024
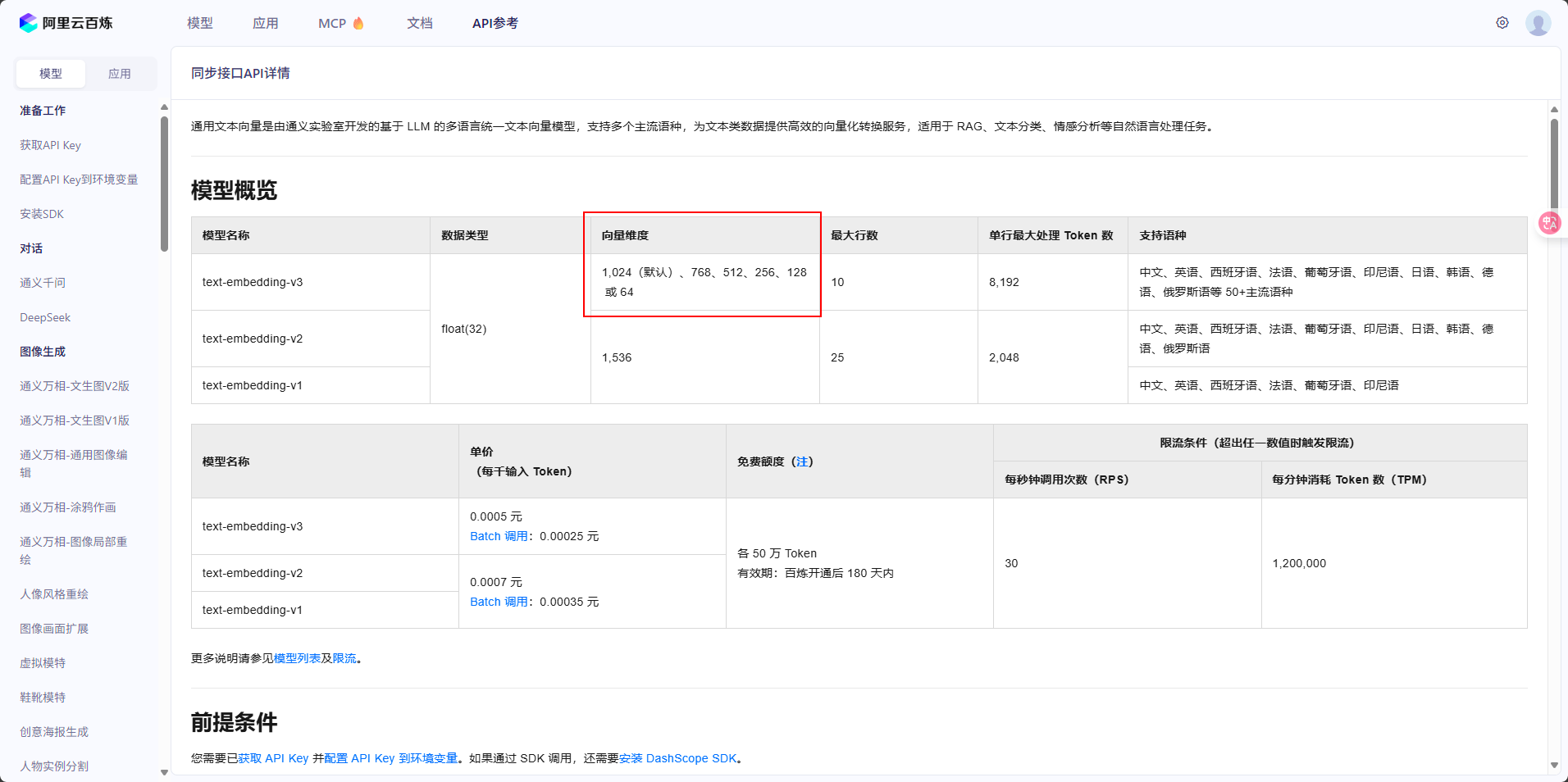
(2)?向量數據庫的配置說明
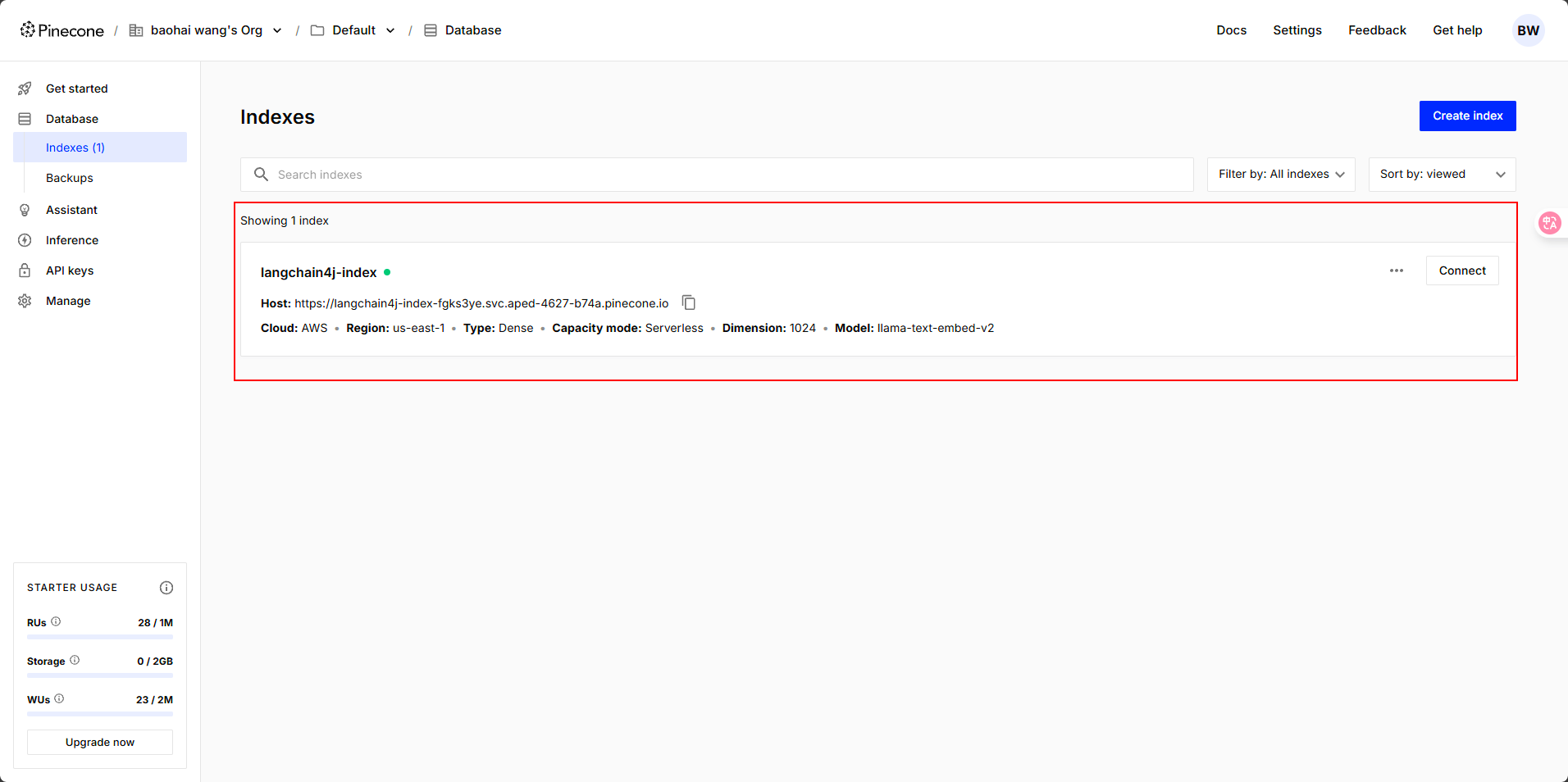
? ? ? ? api-key就是我們注冊的時候平臺發放給我們的,其他信息在我們創建好的向量數據庫里可以查看到。
③ 添加配置類
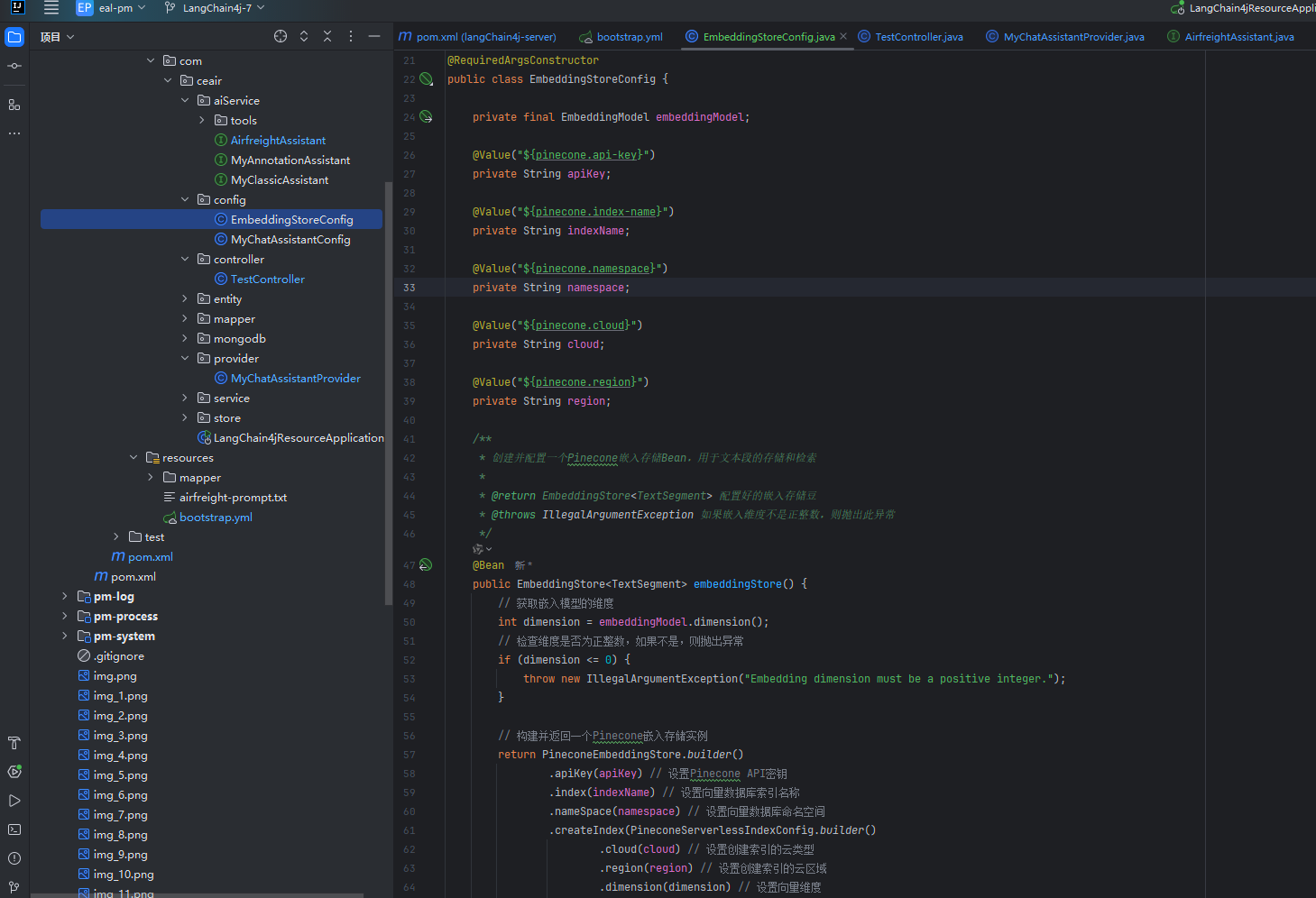
package com.ceair.config;import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.pinecone.PineconeEmbeddingStore;
import dev.langchain4j.store.embedding.pinecone.PineconeServerlessIndexConfig;
import lombok.RequiredArgsConstructor;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;/*** @author wangbaohai* @ClassName EmbeddingStoreConfig* @description: 向量數據庫配置文件* @date 2025年05月23日* @version: 1.0.0*/
@Configuration
@RequiredArgsConstructor
public class EmbeddingStoreConfig {private final EmbeddingModel embeddingModel;@Value("${pinecone.api-key}")private String apiKey;@Value("${pinecone.index-name}")private String indexName;@Value("${pinecone.namespace}")private String namespace;@Value("${pinecone.cloud}")private String cloud;@Value("${pinecone.region}")private String region;/*** 創建并配置一個Pinecone嵌入存儲Bean,用于文本段的存儲和檢索** @return EmbeddingStore<TextSegment> 配置好的嵌入存儲豆* @throws IllegalArgumentException 如果嵌入維度不是正整數,則拋出此異常*/@Beanpublic EmbeddingStore<TextSegment> embeddingStore() {// 獲取嵌入模型的維度int dimension = embeddingModel.dimension();// 檢查維度是否為正整數,如果不是,則拋出異常if (dimension <= 0) {throw new IllegalArgumentException("Embedding dimension must be a positive integer.");}// 構建并返回一個Pinecone嵌入存儲實例return PineconeEmbeddingStore.builder().apiKey(apiKey) // 設置Pinecone API密鑰.index(indexName) // 設置向量數據庫索引名稱.nameSpace(namespace) // 設置向量數據庫命名空間.createIndex(PineconeServerlessIndexConfig.builder().cloud(cloud) // 設置創建索引的云類型.region(region) // 設置創建索引的云區域.dimension(dimension) // 設置向量維度.build()).build();}}
七、智能體添加RAG能力
① 添加向量檢索工具
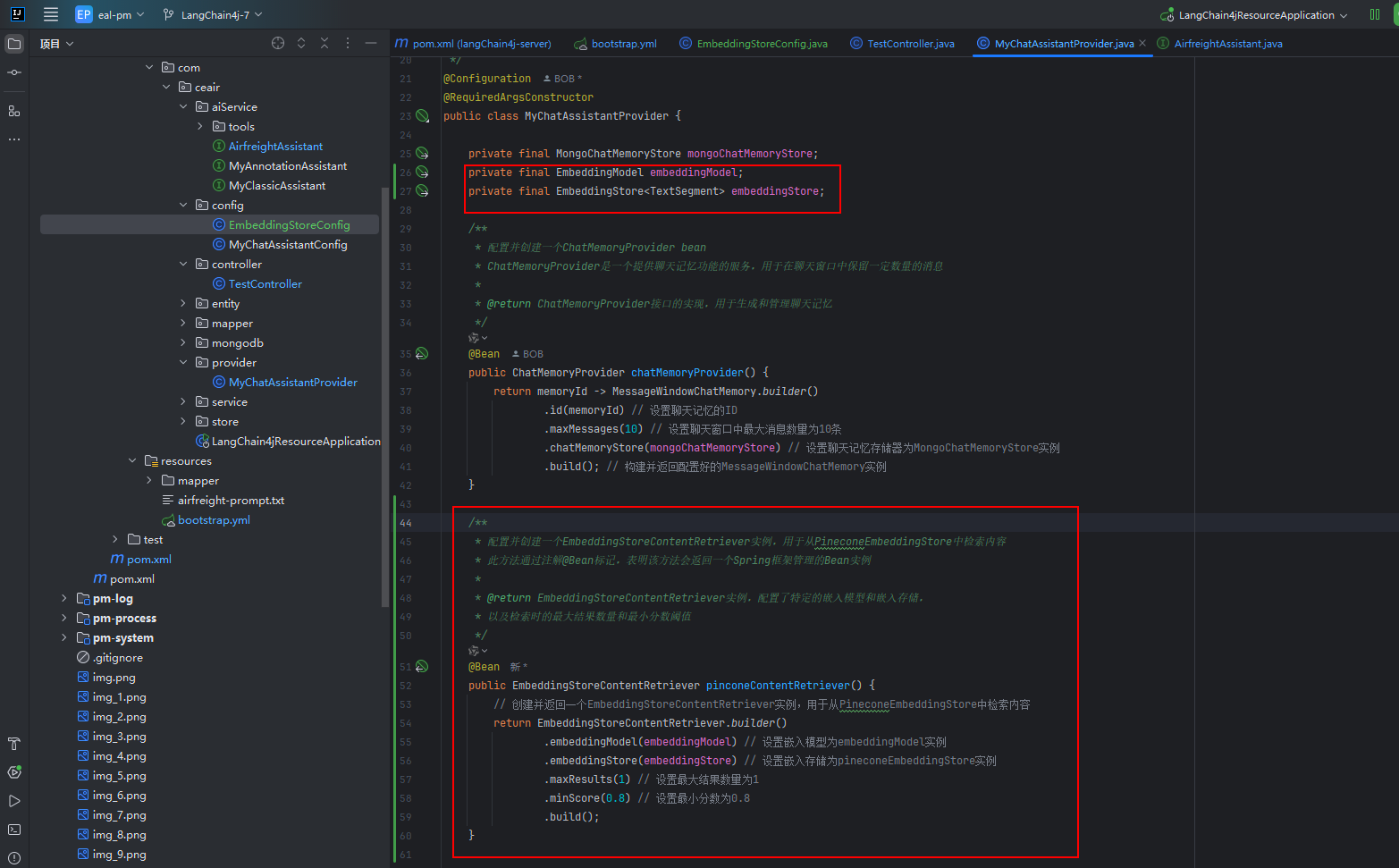
private final EmbeddingModel embeddingModel;
private final EmbeddingStore<TextSegment> embeddingStore;/*** 配置并創建一個EmbeddingStoreContentRetriever實例,用于從PineconeEmbeddingStore中檢索內容* 此方法通過注解@Bean標記,表明該方法會返回一個Spring框架管理的Bean實例** @return EmbeddingStoreContentRetriever實例,配置了特定的嵌入模型和嵌入存儲,* 以及檢索時的最大結果數量和最小分數閾值*/
@Bean
public EmbeddingStoreContentRetriever pinconeContentRetriever() {// 創建并返回一個EmbeddingStoreContentRetriever實例,用于從PineconeEmbeddingStore中檢索內容return EmbeddingStoreContentRetriever.builder().embeddingModel(embeddingModel) // 設置嵌入模型為embeddingModel實例.embeddingStore(embeddingStore) // 設置嵌入存儲為pineconeEmbeddingStore實例.maxResults(1) // 設置最大結果數量為1.minScore(0.8) // 設置最小分數為0.8.build();
}② 為Aiserver注冊檢索工具
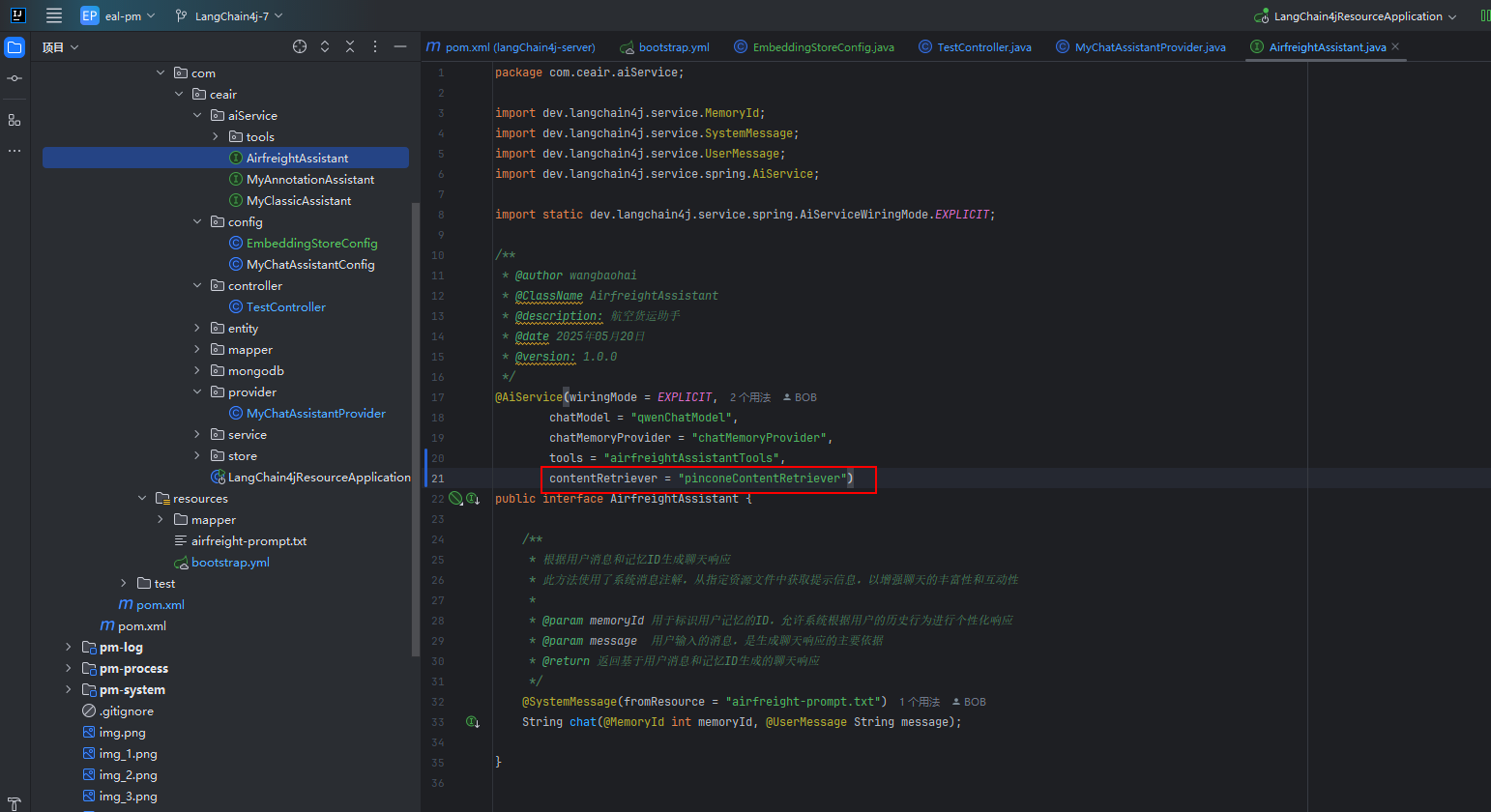
@AiService(wiringMode = EXPLICIT,chatModel = "qwenChatModel",chatMemoryProvider = "chatMemoryProvider",tools = "airfreightAssistantTools",contentRetriever = "pinconeContentRetriever")八、驗證功能
① 添加上傳知識文檔測試工具
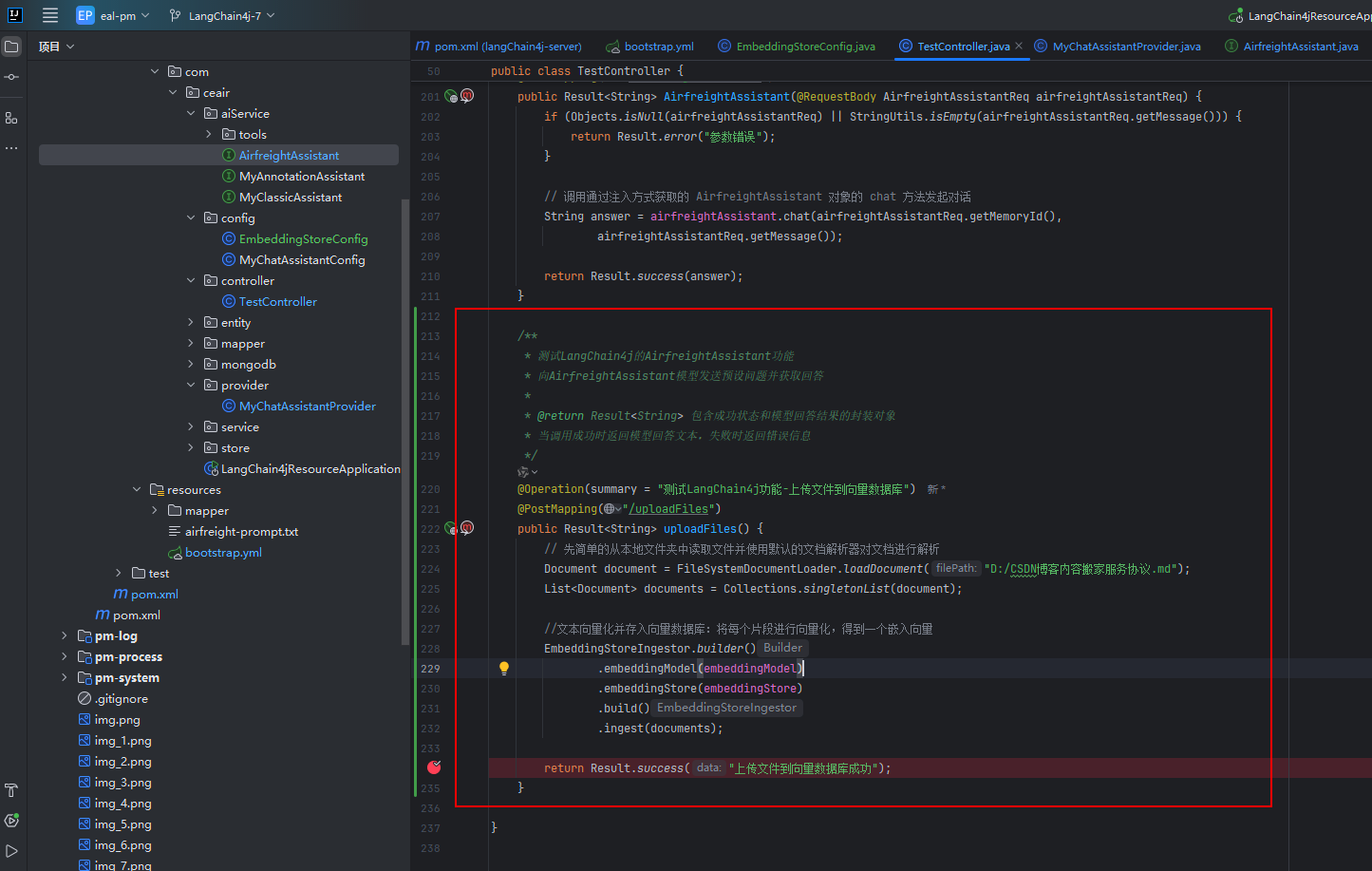
private final EmbeddingModel embeddingModel;
private final EmbeddingStore<TextSegment> embeddingStore;/*** 測試LangChain4j的AirfreightAssistant功能* 向AirfreightAssistant模型發送預設問題并獲取回答** @return Result<String> 包含成功狀態和模型回答結果的封裝對象* 當調用成功時返回模型回答文本,失敗時返回錯誤信息*/
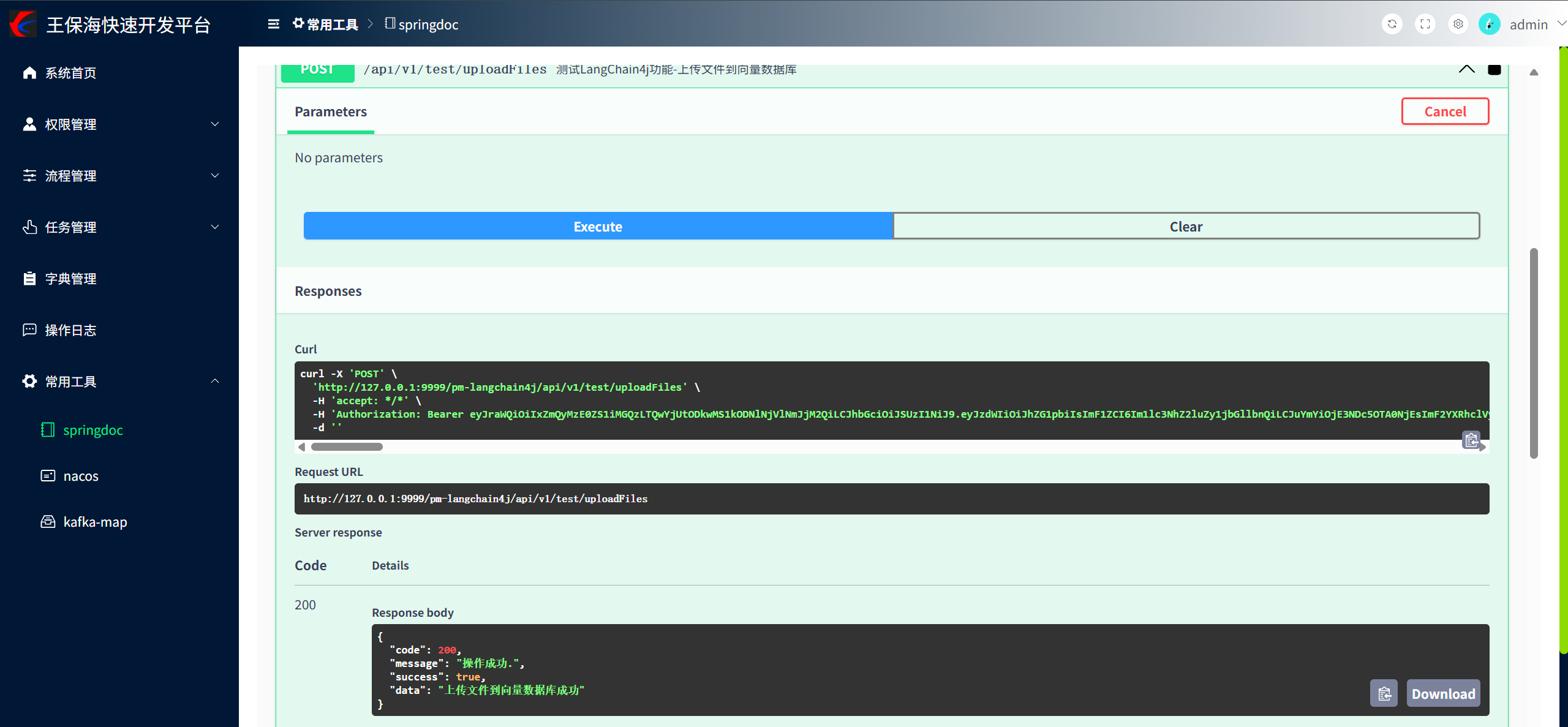
@Operation(summary = "測試LangChain4j功能-上傳文件到向量數據庫")
@PostMapping("/uploadFiles")
public Result<String> uploadFiles() {// 先簡單的從本地文件夾中讀取文件并使用默認的文檔解析器對文檔進行解析Document document = FileSystemDocumentLoader.loadDocument("D:/CSDN博客內容搬家服務協議.md");List<Document> documents = Collections.singletonList(document);//文本向量化并存入向量數據庫:將每個片段進行向量化,得到一個嵌入向量EmbeddingStoreIngestor.builder().embeddingModel(embeddingModel).embeddingStore(embeddingStore).build().ingest(documents);return Result.success("上傳文件到向量數據庫成功");
}② 準備知識文檔
????????知識文檔內容,將這個內容保存為md文件,放到D盤的根目錄。
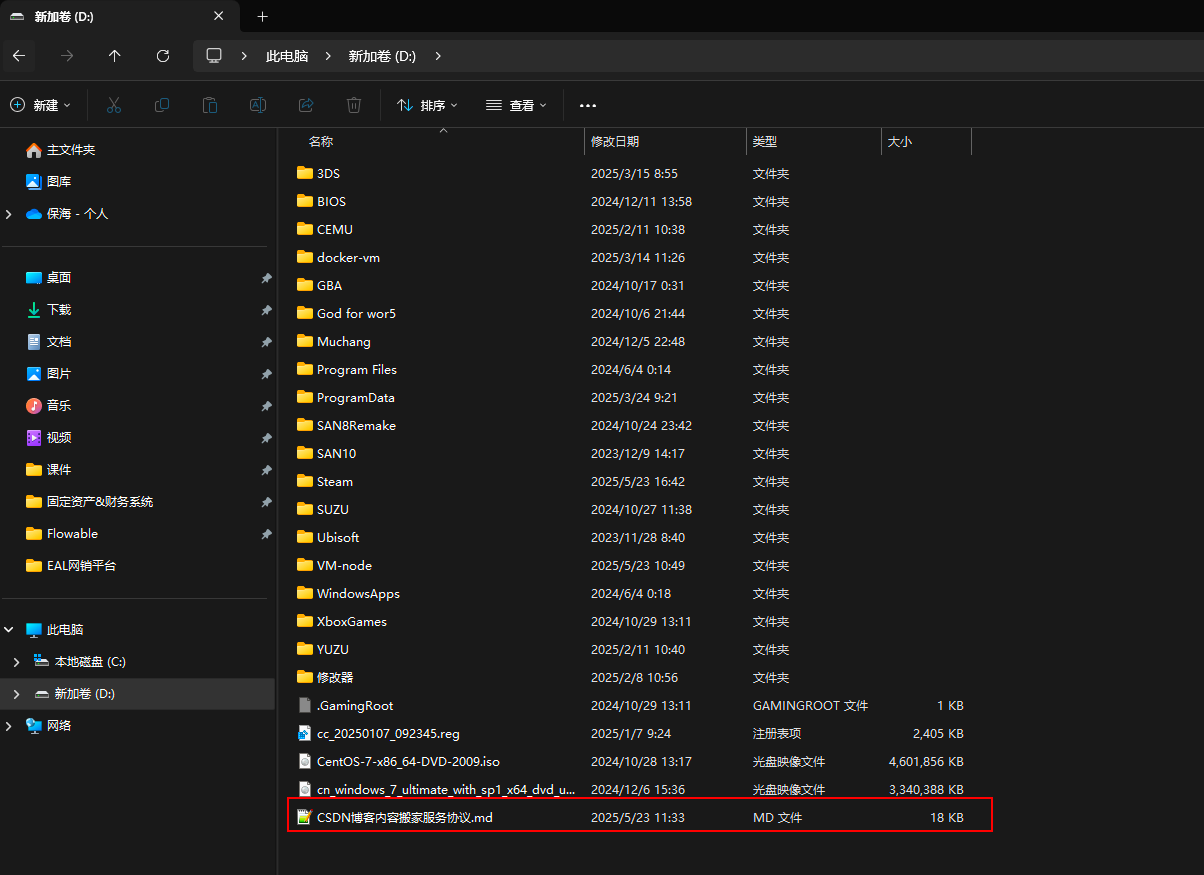
③ 調用接口上傳向量數據庫
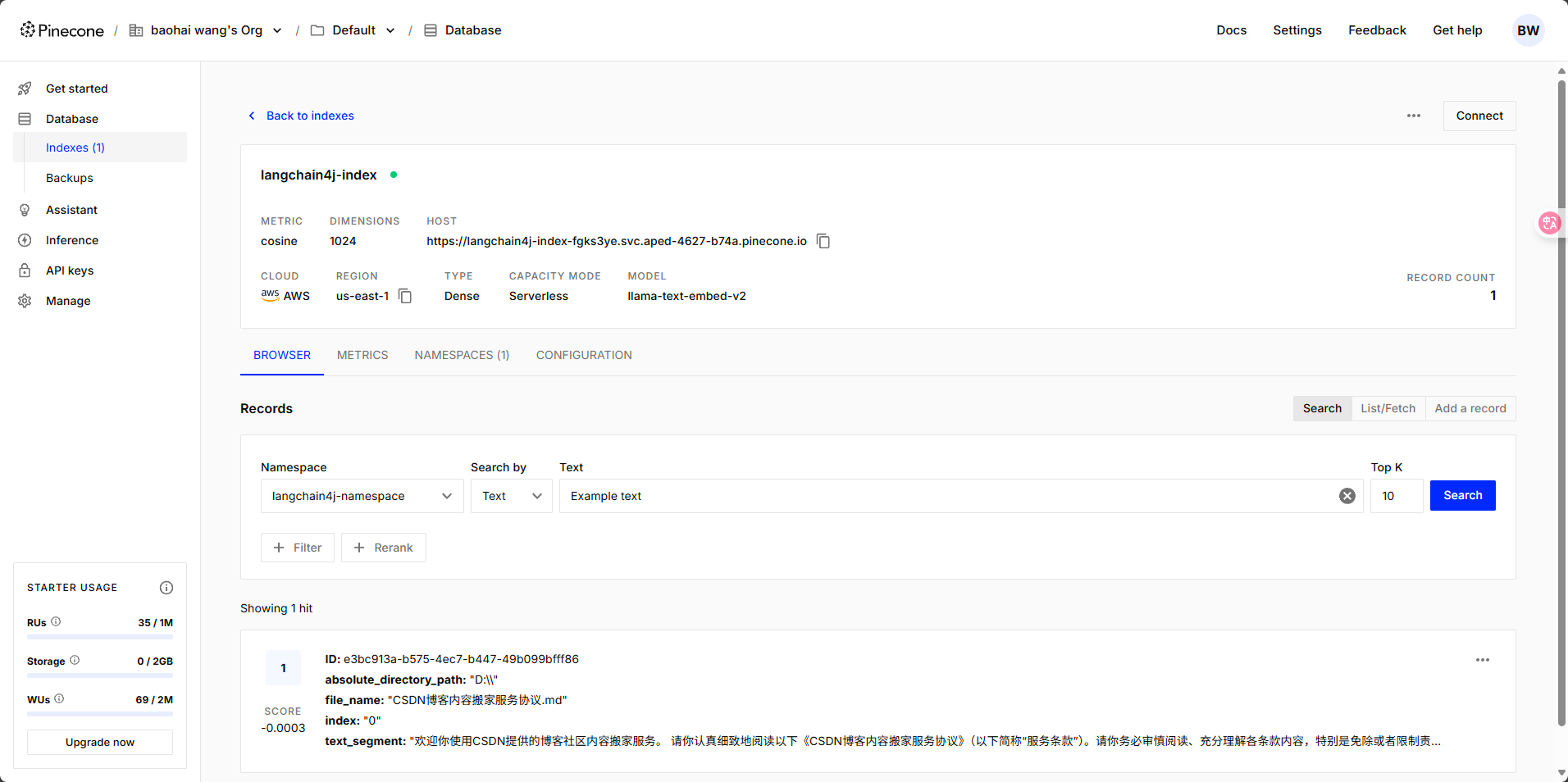
④ 調用AiService驗證RAG
? ? ? ? 提問:CSDN可以一天內發布文字信息總量超過50篇、圖片總量超過100兆嗎,可以看到回答中已經檢索到了私有的知識庫。
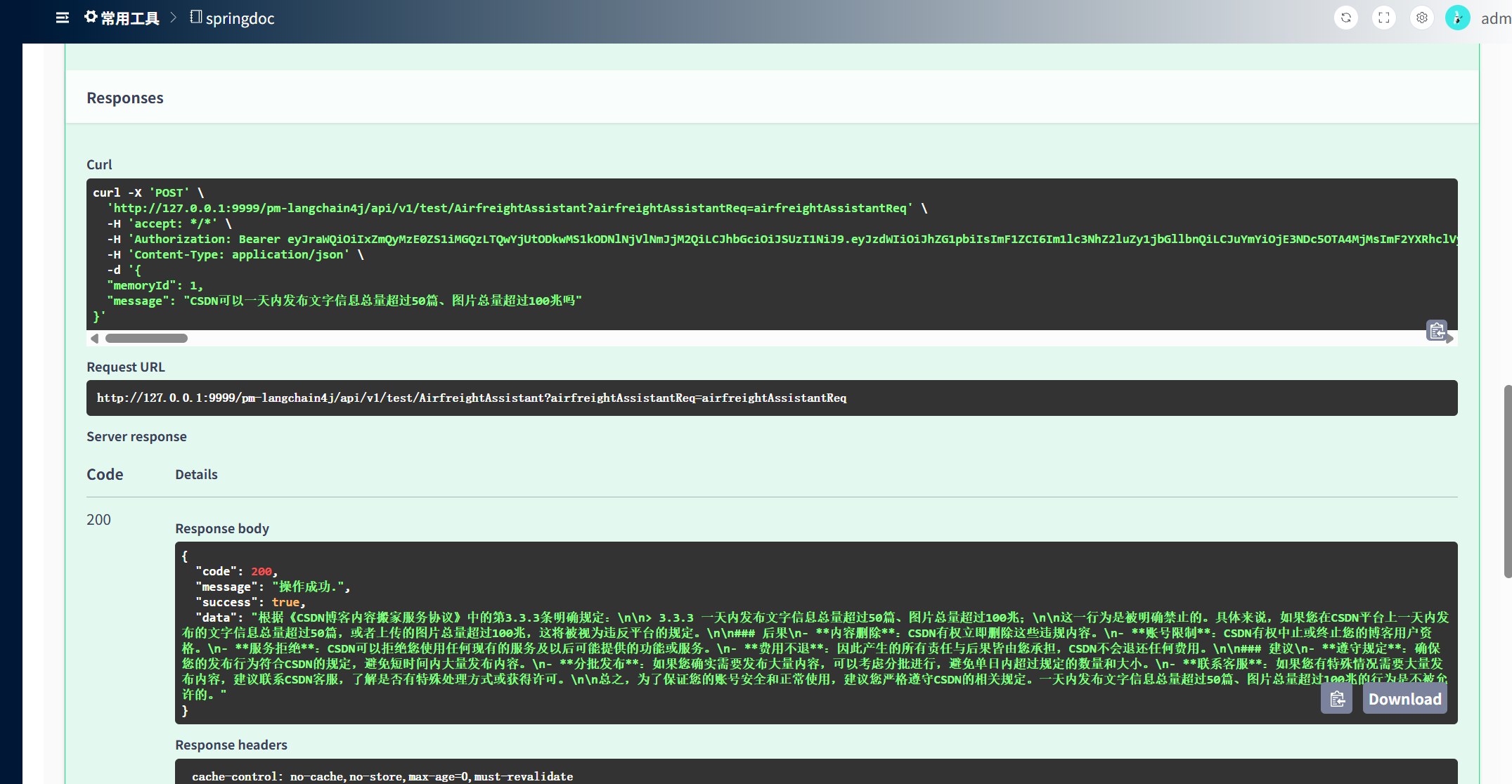
?后記
????????按照一篇文章一個代碼分支,本文的后端工程的分支都是?LangChain4j-7,前端工程的分支是 LangChain4j-1。
后端工程倉庫:后端工程
前端工程倉庫:前端工程



帶論文文檔1萬字以上,文末可獲取,系統界面在最后面。)

作為另一個http接口的請求參數)








)

)


