繼續研究一下大佬的RAG項目。開始我的碎碎念。
RAG可以分成兩部分:一個是問答,一個是數據處理。
問答是人提問,然后查數據庫,把查的東西用大模型組織成人話,回答人的提問。
數據處理是把當下知識庫里的東西(不管是什么類型的數據),全弄成計算機話(代碼能明白的格式)存到數據庫,然后方便人提問的時候(也就是問答)給出可以回答的知識。
如果想讓項目跑起來,必須把ES服務啟動起來,該項目是用ES存的數據。
項目啟動時,會先運行LoadStartup(在Springboot應用啟動時),初始化向量存儲(具體初始化向量存儲用vectorstorage的initCollection()方法,指定名稱和維度,向量維度是1024為了適配智譜AI)。總之就是自動初始化一個向量數據庫的集合(Collection),用于存儲后續的向量數據(如文本嵌入向量)。
我們看到LoadStartup類有一個注解@Component
所以@Service、@Repository等等這些注解,本質上都是@Component。只是根據層次有不同叫法。




這個collection是森馬樣子?回頭再寫吧。
首先,就是輸入的問題。我們要存的知識不一定是什么類型,可能使txt,可能是word,甚至是pdf。那我們就需要把輸入的東西先變成文本。
項目運行起來之前,點擊運行下載好的es的bin文件夾下elasticsearch.bat,啟動服務。
此時可以再終端看到可交互的shell命令行。這個應該是通過spring shell工具包實現的,項目的pom.xml文件里可以看到已經配置了shell的起步依賴。怎么用這個shell包呢?可以通過自己編寫java類,自己做命令。前面說過把RAG分成兩部分:問答,數據處理。使用add命令完成數據處理部分的工作,使用chat命令完成問答部分的工作。新建command文件夾來存放這兩個類:add命令類,chat命令類。
通過 @ShellMethod 注解將 Java 方法暴露為 Shell 命令。
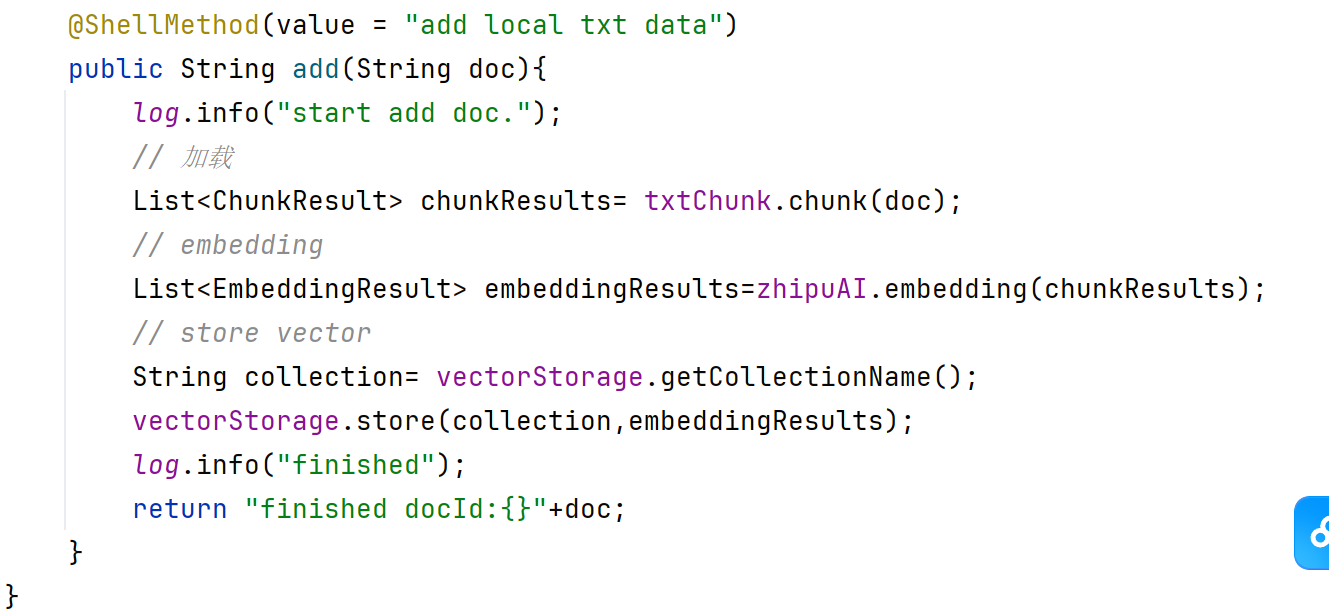
@ShellMethod(value = "add local txt data") // 聲明這是一個Shell命令,描述為"add local txt data"
public String add(String doc) { // 定義命令方法,接收一個字符串參數doc(文件路徑或文本內容)log.info("start add doc."); // 打印日志:開始處理文檔// 1. 文本分塊(Chunking)List<ChunkResult> chunkResults = txtChunk.chunk(doc); // 調用分塊工具,將文檔拆分為多個文本塊// 2. 向量化(Embedding)List<EmbeddingResult> embeddingResults = zhipuAI.embedding(chunkResults); // 使用智譜AI(或其他模型)將文本塊轉為向量// 3. 向量存儲String collection = vectorStorage.getCollectionName(); // 獲取向量數據庫的集合名(類似表名)vectorStorage.store(collection, embeddingResults); // 將向量存儲到數據庫中log.info("finished"); // 打印日志:處理完成return "finished docId:{}" + doc; // 返回處理結果(格式有誤,應為String.format)
}數據處理的三步:文本分塊、向量化、向量存儲。最后返回結果。
這幾步全調用方法,現在看是一個黑盒,知道輸入輸出和功能就行,后面再具體看黑盒里面的代碼。
doc參數是文件內容還是文件路徑搞不懂?試著輸出了doc,發現是文件名。但是,根據文件名就能找著??
![]()
發現有一個默認路徑/data,然后再默認路徑/data下找doc文件名。找一下哪里設置的默認路徑。
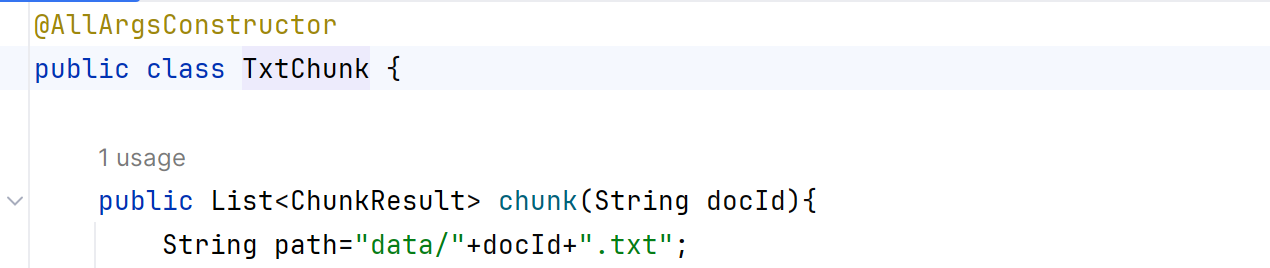
/data在chunk這里。
所以這個意思是,add 文件名。add這個方法就收到了參數doc文件名。然后進行文本分塊(數據處理的具體代碼放在/compoents文件夾),調用了chunk方法,然后根據默認路徑+文件名+.txt,就得到一條完整的路徑(相對路徑)。
讀取文件流classpathresource(path)


來回流轉的數據,封裝在對象中,而這些對象的代碼都放在/domain文件夾里。
明天再寫。
繼續這個chunk。
然后為什么要chunk?小塊文本比長文本更高效,節省計算資源。按照256個字符分割字符串。
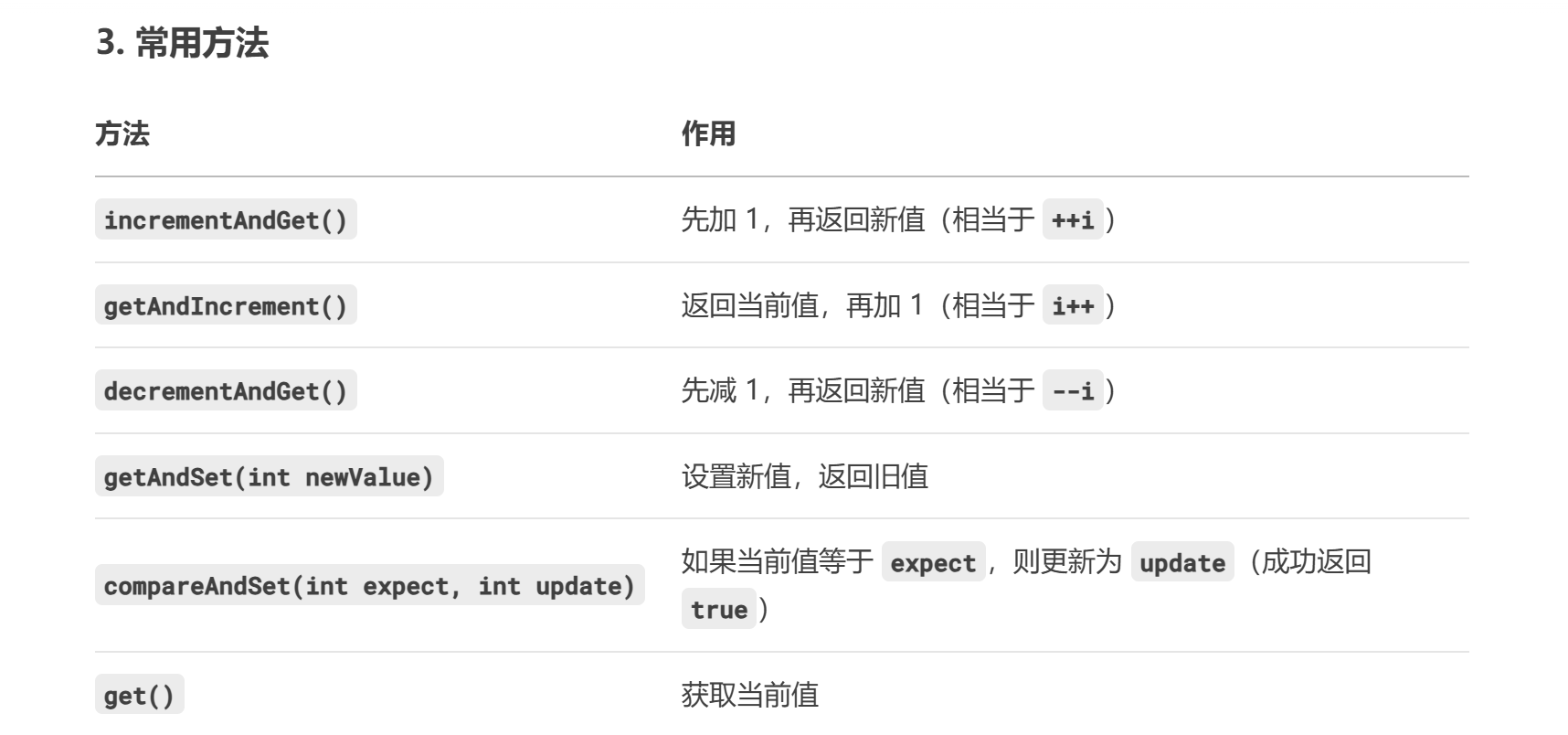
AtomicInteger是 Java 中一個線程安全的原子整數類,屬于java.util.concurrent.atomic包。它的核心作用是提供原子操作(不可中斷的單一操作),確保在多線程環境下對整數的操作(如遞增、遞減、賦值等)不會出現競態條件(Race Condition)。
很明顯,把每個chunk后的小塊文本封裝成一個chunkresult對象,然后返回這些對象構成的集合。
然后調用智譜AI的embedding方法。可以看到傳進去的參數是chunkresult對象的集合,返回的是embeddingresult的集合。具體看embedding方法里的代碼:觀察集合是否為空,空的話返回空集合;非空返回embedding后的集合(這里就有一個embedding方法了)。我們具體看這個embedding方法,上一個embedding返回的是集合,這個里面embedding方法返回的單個向量化后的結果。方法的重載,參數不同。說不明白,具體看代碼就懂了。
/*** 批量* @param chunkResults 批量文本* @return 向量*/public List<EmbeddingResult> embedding(List<ChunkResult> chunkResults){log.info("start embedding,size:{}",CollectionUtil.size(chunkResults));if (CollectionUtil.isEmpty(chunkResults)){return new ArrayList<>();}List<EmbeddingResult> embeddingResults=new ArrayList<>();for (ChunkResult chunkResult:chunkResults){embeddingResults.add(this.embedding(chunkResult));}return embeddingResults;}public EmbeddingResult embedding(ChunkResult chunkResult){String apiKey= this.getApiKey();//log.info("zp-key:{}",apiKey);OkHttpClient.Builder builder = new OkHttpClient.Builder().connectTimeout(20000, TimeUnit.MILLISECONDS).readTimeout(20000, TimeUnit.MILLISECONDS).writeTimeout(20000, TimeUnit.MILLISECONDS).addInterceptor(new ZhipuHeaderInterceptor(apiKey));OkHttpClient okHttpClient = builder.build();EmbeddingResult embedRequest=new EmbeddingResult();embedRequest.setPrompt(chunkResult.getContent());embedRequest.setRequestId(Objects.toString(chunkResult.getChunkId()));// 智譜embeddingRequest request = new Request.Builder().url("https://open.bigmodel.cn/api/paas/v3/model-api/text_embedding/invoke").post(RequestBody.create(MediaType.parse(ContentType.JSON.getValue()), GSON.toJson(embedRequest))).build();try {Response response= okHttpClient.newCall(request).execute();String result=response.body().string();ZhipuResult zhipuResult= GSON.fromJson(result, ZhipuResult.class);EmbeddingResult ret= zhipuResult.getData();ret.setPrompt(embedRequest.getPrompt());ret.setRequestId(embedRequest.getRequestId());return ret;} catch (IOException e) {throw new RuntimeException(e);}}前面embedding方法只是封裝成集合,就不看了。后面的embedding才是真正的向量化,重頭戲。(但是人家的API咱直接用就行,embedding具體回頭再看吧)
直接用的智譜的API,我們直接給參就好了。
先獲取密鑰。//咱們寫好的getapikey方法,而它里面是調用了LLmProperties里面的東西。(回頭再看吧,反正肯定這個注解指定有點東西//綁定前綴“llm”開頭的配置,然后再yaml配置文件里定義屬性)👇
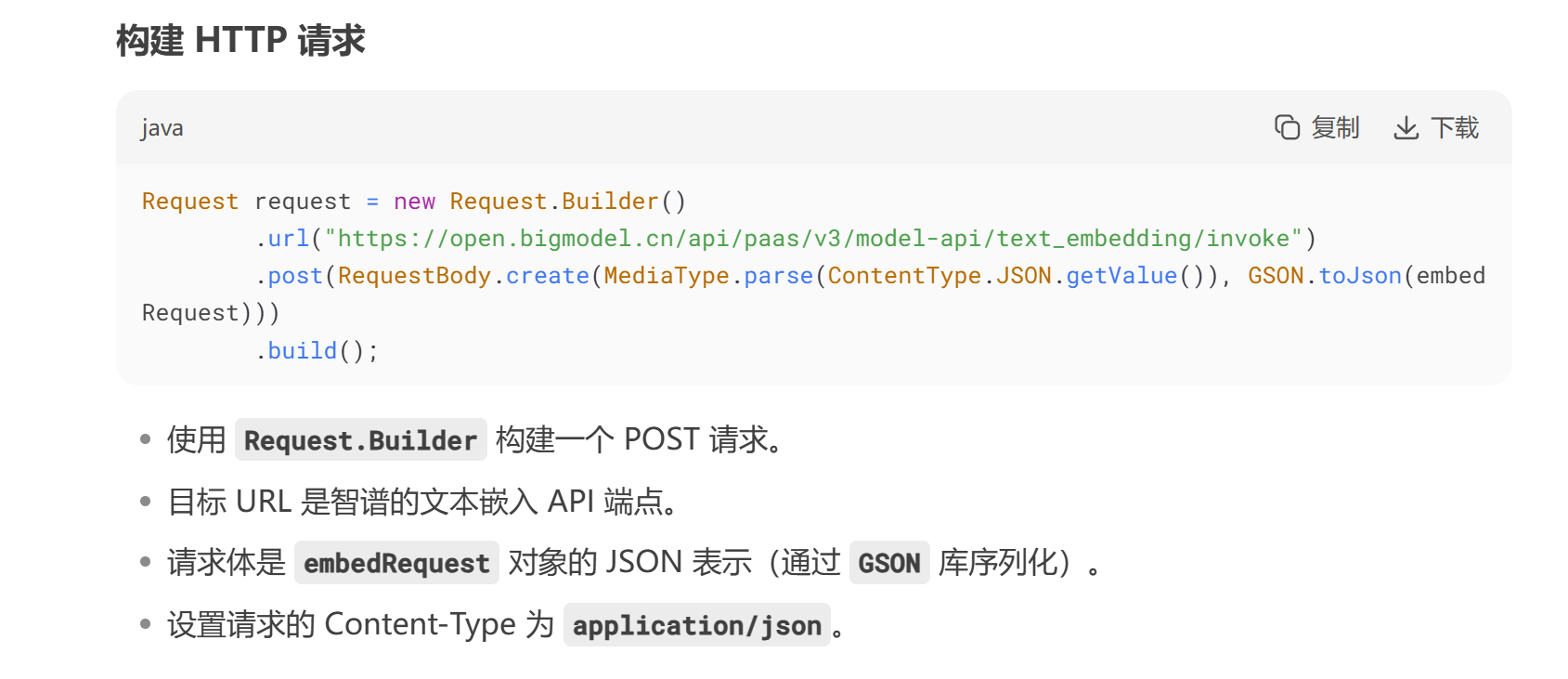
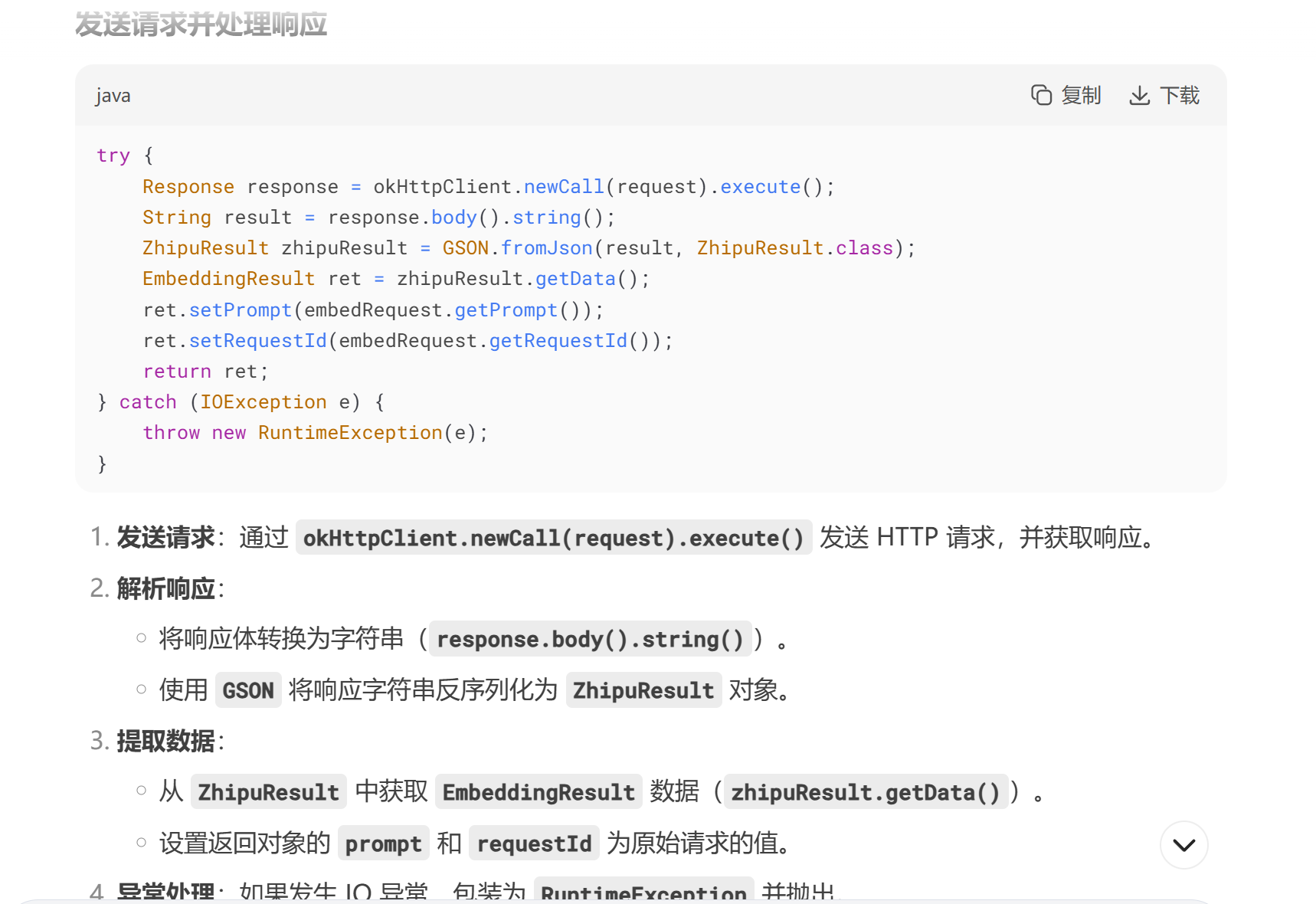
使用 OkHttpClient.Builder 構建一個 HTTP 客戶端,配置了連接、讀取和寫入的超時時間(均為 20 秒)。
添加了一個自定義攔截器 ZhipuHeaderInterceptor,用于在請求頭中添加 API 密鑰等認證信息。
創建一個?
EmbeddingResult?對象作為請求體。設置?
prompt?為輸入文本塊的內容(chunkResult.getContent())。設置?
requestId?為文本塊的 ID(chunkResult.getChunkId()),轉換為字符串。EmbeddingResult embedRequest=new EmbeddingResult(); embedRequest.setPrompt(chunkResult.getContent()); embedRequest.setRequestId(Objects.toString(chunkResult.getChunkId()));
我們在這里用到了一個攔截器。回頭再仔細看。
Lombok 注解:簡化代碼。比如@AllArgsConstructor注解,就是默認全參構造。
具體見:Lombok-CSDN博客

向量化返回的結果👇是地址。。。
數組變成字符串打印出來👇變成這樣的向量了。
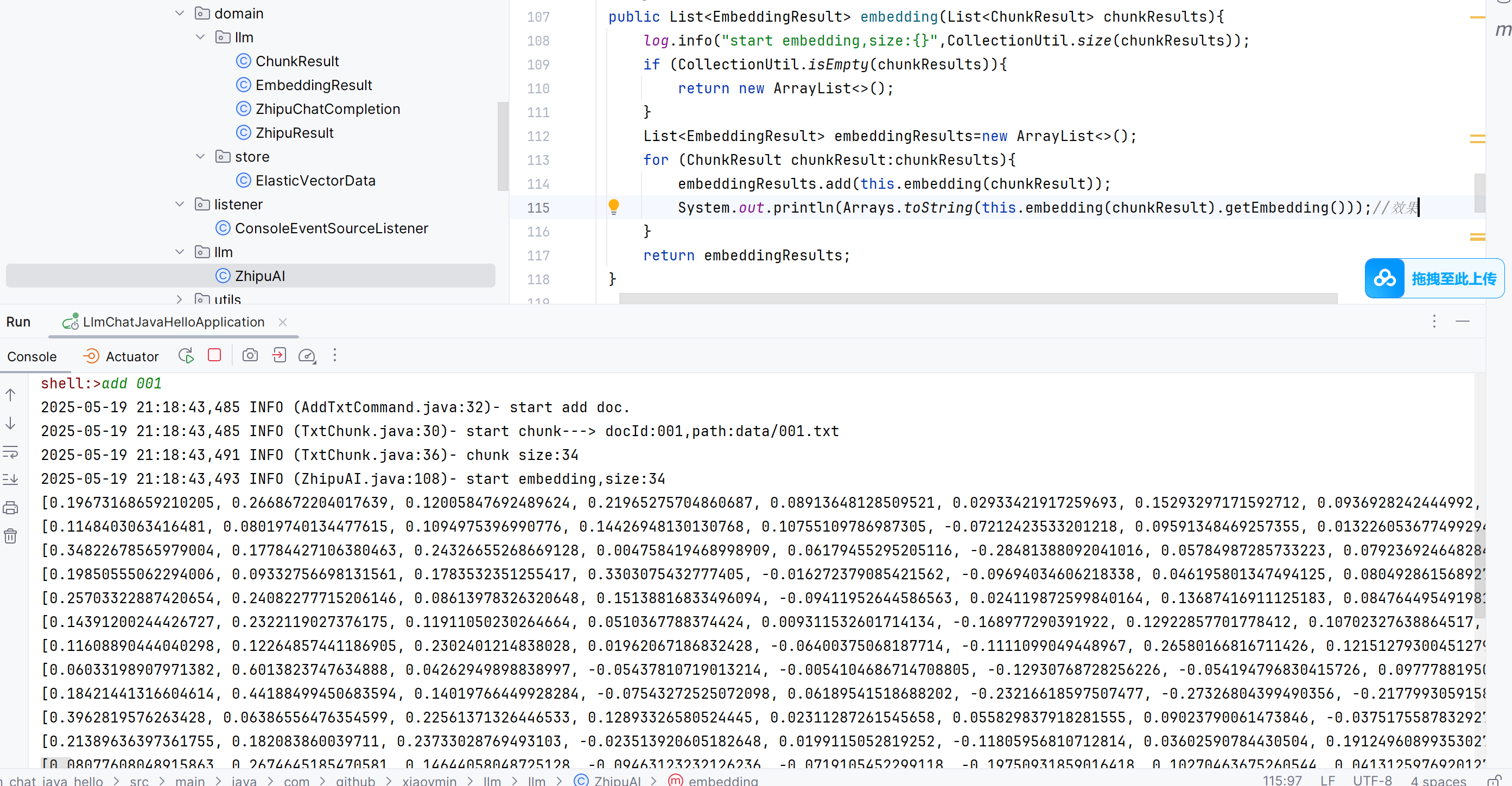
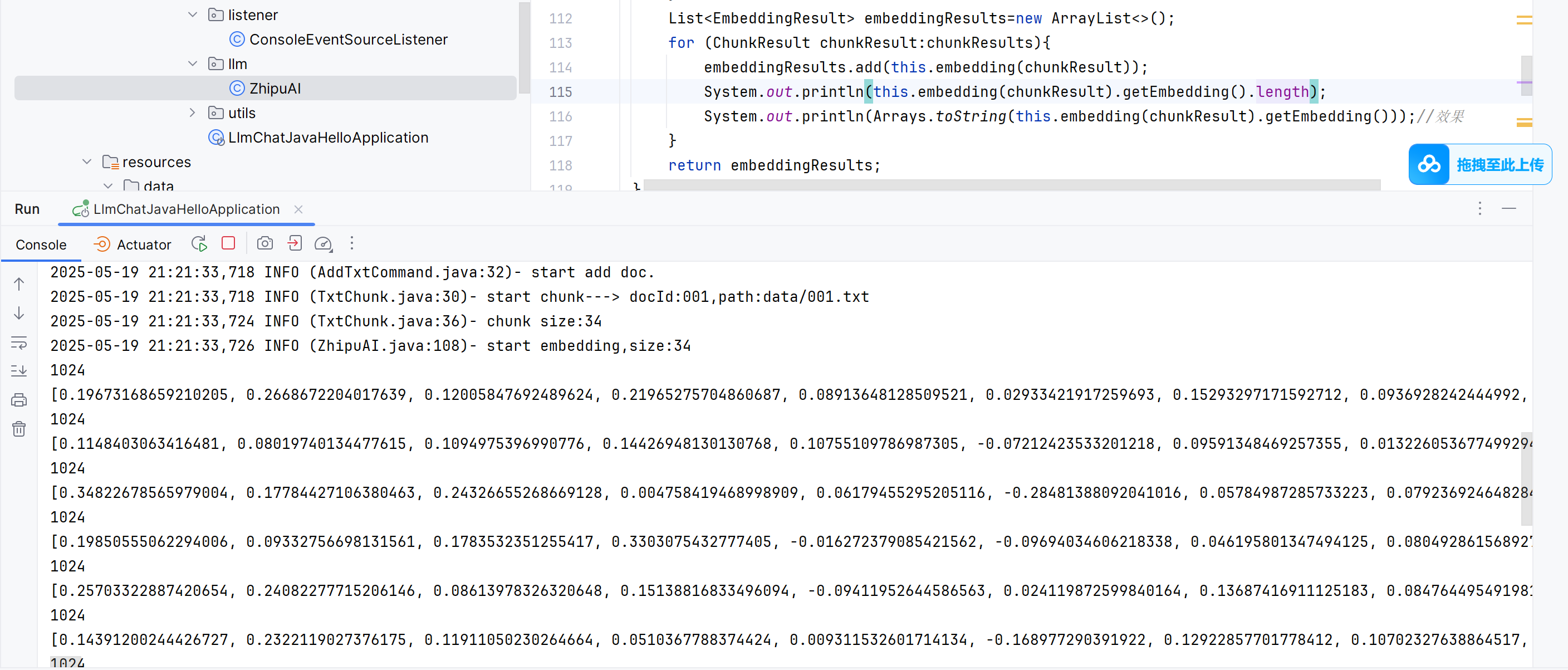
理論上每個數組大小為1024,事實上也是。具體向量怎么算的,回頭看。
接下來把這些向量存起來。存在哪?怎么存?可以看到這回用到了vectorStorage,調用了它的store,參數是collectionName(下面講//可以get得到)和embedding后的向量。(最開始我們說該項目是用ES存的)
可以看到initCollection方法的兩個參數,一個是名字(固定前綴+時間),另一個是維度。傳進去這倆參數,會返回一個布爾值(T or F)。

——攝像頭調用、攝像頭OCR)

)






)





)


)