通過將說話人的聲音與數據庫中的記錄聲音進行比對,判斷說話人是否為數據庫白名單中的同一人,從而完成語音驗證。目前,3D-Speaker 聲紋驗證的效果較為出色。
3D-Speaker 是一個開源工具包,可用于單模態和多模態的說話人驗證、說話人識別以及說話人日志分割

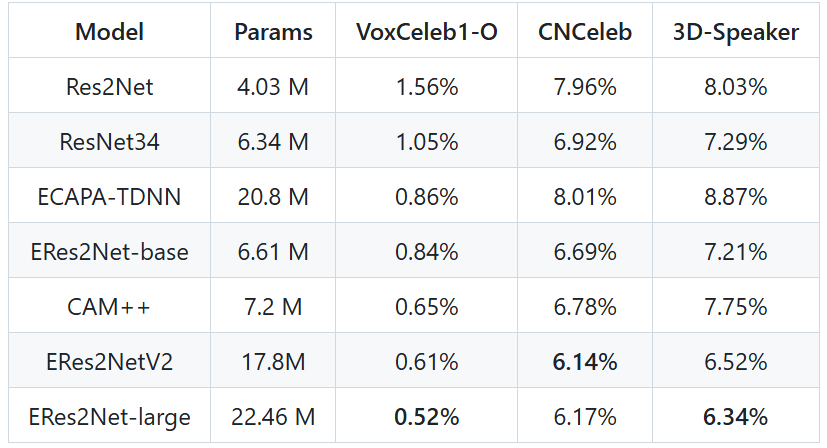
模型使用方法如下:
# 聲紋識別測試
# 采樣率要為16kfrom modelscope.pipelines import pipeline
sv_pipeline = pipeline(task='speaker-verification',model=r'D:\Downloads\speech_campplus_sv_zh-cn_3dspeaker_16k'
)
speaker1_a_wav = 'https://modelscope.cn/api/v1/models/damo/speech_campplus_sv_zh-cn_3dspeaker_16k/repo?Revision=master&FilePath=examples/speaker1_a_cn_16k.wav'
speaker1_b_wav = 'https://modelscope.cn/api/v1/models/damo/speech_campplus_sv_zh-cn_3dspeaker_16k/repo?Revision=master&FilePath=examples/speaker1_b_cn_16k.wav'
speaker2_a_wav = 'https://modelscope.cn/api/v1/models/damo/speech_campplus_sv_zh-cn_3dspeaker_16k/repo?Revision=master&FilePath=examples/speaker2_a_cn_16k.wav'# speaker1_a_wav = r'D:\Downloads\ASR-LLM-TTS-master\ASR-LLM-TTS-master\my_recording.wav'
# speaker1_b_wav = r'D:\Downloads\ASR-LLM-TTS-master\ASR-LLM-TTS-master\my_recording_1.wav'
# speaker2_a_wav = r'D:\Downloads\ASR-LLM-TTS-master\ASR-LLM-TTS-master\my_recording_2.wav'# 相同說話人語音
result = sv_pipeline([speaker1_a_wav, speaker1_b_wav])
print(result)
# 不同說話人語音
result = sv_pipeline([speaker1_a_wav, speaker2_a_wav])
print(result)
# 可以自定義得分閾值來進行識別
result = sv_pipeline([speaker1_a_wav, speaker2_a_wav], thr=0.6)
print(result)?





)





)


)




—— 內存優化)