表的增刪改查
表的增加
語法:
INSERT [INTO] table_name
[(column [, column] ...)]
VALUES (value_list) [, (value_list)] ...
value_list: value, [, value] ...
全列插入和指定列插入
//創建一張學生表
CREATE TABLE students (id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,sn INT NOT NULL UNIQUE COMMENT '學號',name VARCHAR(20) NOT NULL,qq VARCHAR(20)
);
全列插入:
插入的一行數據中, value_list 數量 必須和 定義表的列 的數量及順序一致.
INSERT INTO students VALUES (100, 10000, '唐三藏', NULL);
指定列插入
注意, 這里在插入的時候, 由于id是primary key 且 auto_increment, 所以也可以不用指定 id , 這時就需要明確插入數據到那些列了, 那么mysql會使用默認的值進行自增
INSERT INTO students (id, sn, name) VALUES (101, 20001, '曹孟德');
單行插入和多行插入
單行插入
之前就是單行插入, 略.
多行插入
多行插入就是在單行插入后用逗號分隔多條 value_list:
INSERT INTO students (id, sn, name) VALUES
(102, 20001, '劉玄德'),
(103, 20002, '孫仲謀');
插入否則更新 和 替換
ON DUPLICATE KEY UPDATE 和 REPLACE 都是在插入數據時處理 主鍵或唯一鍵沖突 的兩種機制, 但它們有行為差別.
1. ON DUPLICATE KEY UPDATE
INSERT INTO table_name (col1, col2, ...)
VALUES (val1, val2, ...)
ON DUPLICATE KEY UPDATE colX = valX, colY = valY, ...;
ON DUPLICATE KEY UPDATE 是 INSERT 語句的一種擴展, 用于在插入時如果發生主鍵或唯一鍵沖突時, 自動轉為更新已有記錄, 它并不會刪除舊的記錄.
所以如果希望保留記錄的其他字段, 只更新部分內容, 可以使用這個.
假如現在有這樣一個商品表:
CREATE TABLE cart (-> user_id INT,-> product_id INT,-> quantity INT DEFAULT 1,-> PRIMARY KEY (user_id, product_id)-> );
- 0 row affected: 表中有沖突數據,但沖突數據的值和 update 的值相等
- 1 row affected: 表中沒有沖突數據,數據被插入
- 2 row affected: 表中有沖突數據,并且數據已經被更新
同一個用戶添加相同商品時, 應該是更新數量, 而不是重復記錄:
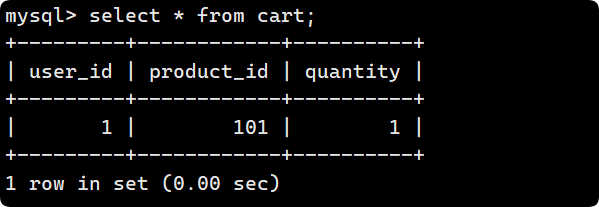
- 第一次插入, 1 row affected 說明表中沒有沖突數據:
mysql> insert into cart values (1, 101, 1) on duplicate key update quantity = quantity + 1;
Query OK, 1 row affected (0.01 sec)
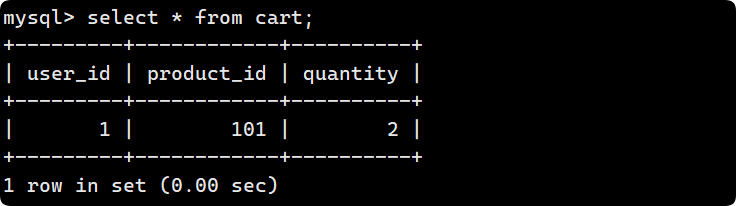
- 第二次插入, 2 rows affected 說明表中有沖突數據, 數據被更新:
mysql> insert into cart values (1, 101, 1) on duplicate key update quantity = quantity + 1;
Query OK, 2 rows affected (0.00 sec)
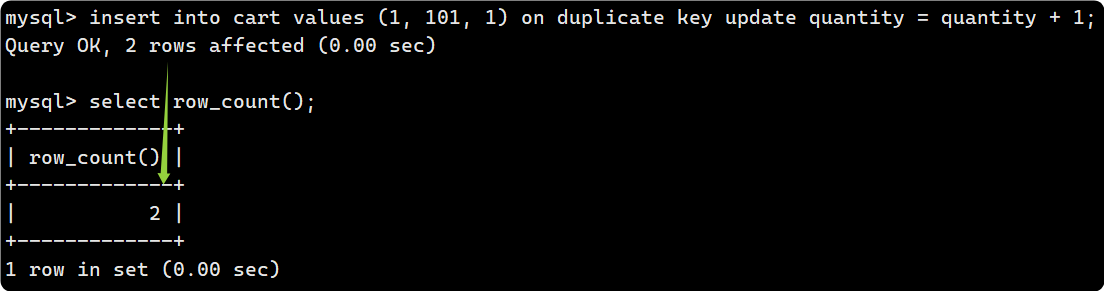
使用select row_count()可以查看被影響的行數:
2. replace
REPLACE INTO table_name (col1, col2, ...)
VALUES (val1, val2, ...);
- 1 row affected: 表中沒有沖突數據,數據被插入
- 2 row affected: 表中有沖突數據,刪除后重新插入. MySQL會先 delete 原有行, 后 insert 新行.
由于replace會進行delete和insert操作, 所以可能會有一些副作用:
- auto_increment的字段會出現跳號的情況.
- ON DELETE 約束會被觸發
舉個例子:
create table temp_stock_cache(-> product_id int primary key auto_increment,-> product_name varchar(100) unique, -> stock int-> );
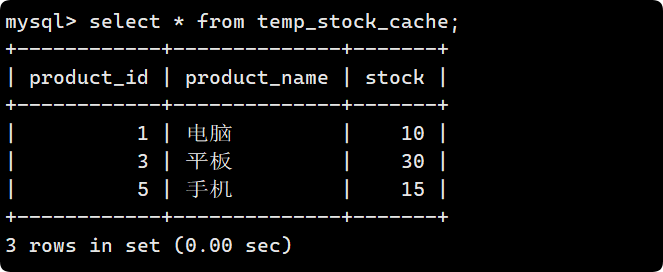
現在插入幾條數據, 都是 1 row affected, 說明表中沒有沖突數據,數據被插入:
replace into temp_stock_cache (product_name, stock) values ('電腦', 10);
Query OK, 1 row affected (0.00 sec)
replace into temp_stock_cache (product_name, stock) values ('手機', 20);
Query OK, 1 row affected (0.01 sec)
replace into temp_stock_cache (product_name, stock) values ('平板', 30);
Query OK, 1 row affected (0.01 sec)
再插入一條數據, 此時 2 row affected, 此時product_name唯一鍵沖突, 需要被替換:
replace into temp_stock_cache (product_name, stock) values ('手機', 15);
Query OK, 2 rows affected (0.00 sec)
可以看到 第二行被刪除, 并且新增了一行, 但是會跳號
所以如果不在乎是否丟失原來的主鍵和記錄, 也就是舊數據無效, 那就可以使用replace進行覆蓋式更新.
插入查詢結果(insert + select)
這里我們的最終目的是將一個帶有重復數據的 duplicate_table 表去重, 我們的整體思路是通過 tmp文件 + 重命名的方式, 保證原子性地替換文件. insert+select是用在構建 tmp文件(此處名為no_duplicate_table) 的.
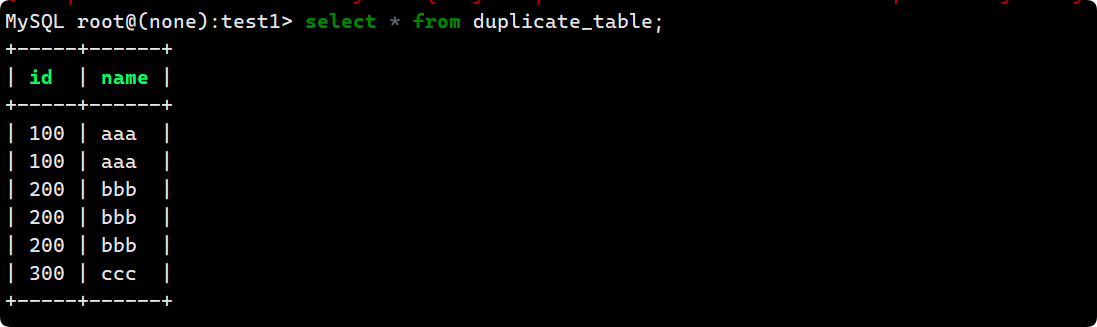
- 首先創建一個帶有重復數據的表, 并插入一些重復數據:
create table duplicate_table (id int, name varchar(20));
insert into duplicate_table values (100, 'aaa'),
-> (100, 'aaa'),
-> (200, 'bbb'),
-> (200, 'bbb'),
-> (200, 'bbb'),
-> (300, 'ccc');
2. 然后創建一個和 duplicate_table 結構一模一樣的新表 no_duplicate_table,
create table no_duplicate_table like duplicate_table;
- 關鍵是這一步: 將 duplicate_table 的去重數據插入到 no_duplicate_table
可以利用insert ... select ...將 select 的查詢結果插入到 no_duplicate_table:
insert into no_duplicate_table select distinct * from duplicate_table;
- 最后對新表和舊表進行重命名即可 (主要是新表):
rename table duplicate_table to old_duplicate_table,
no_duplicate_table to duplicate_table;
在 Linux 上傳或寫入大文件時, 為了保證原子性和一致性, 防止系統崩潰 or 斷電 or 磁盤滿 等原因, 導致目標文件"一半新, 一半舊". 也能保證文件的使用者不會讀到正在被修改的數據, 讀者只能看到兩態: 原文件和新文件.
方法是: 通常會先將數據寫入一個臨時文件, 再通過重命名(mv)來“原子替換”目標文件, 因為 mv 在 同一個文件系統內不會復制數據, 而是直接修改 inode 的映射, 這個操作是原子的.
表的查詢
查詢操作的語法:
SELECT
[DISTINCT] {* | {column [, column] ...}
[FROM table_name]
[WHERE ...]
[ORDER BY column [ASC | DESC], ...]
LIMIT ...
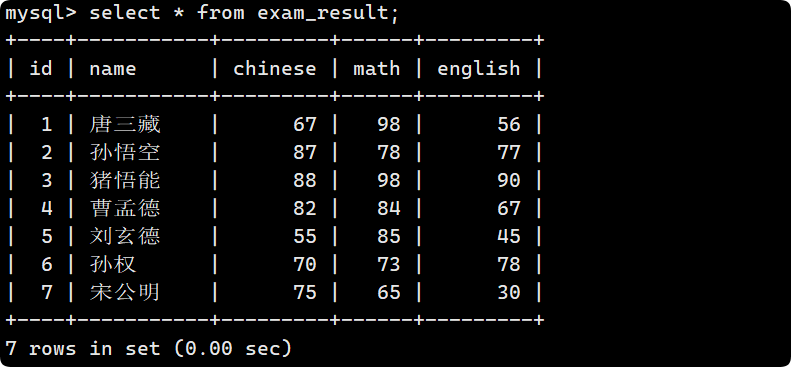
先以這個表為例子:
-- 創建表結構
CREATE TABLE exam_result (
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL COMMENT '同學姓名',
chinese float DEFAULT 0.0 COMMENT '語文成績',
math float DEFAULT 0.0 COMMENT '數學成績',
english float DEFAULT 0.0 COMMENT '英語成績'
);
-- 插入測試數據
INSERT INTO exam_result (name, chinese, math, english) VALUES
('唐三藏', 67, 98, 56),
('孫悟空', 87, 78, 77),
('豬悟能', 88, 98, 90),
('曹孟德', 82, 84, 67),
('劉玄德', 55, 85, 45),
('孫權', 70, 73, 78),
('宋公明', 75, 65, 30);
1. SELECT 列
全列查詢
select * from table_name;
這樣所有的列屬性全部顯示出來了:
通常情況下不建議使用 * 進行全列查詢
– 1. 查詢的列越多, 意味著需要傳輸的數據量越大, 而一個數據庫中的數據量往往很大;
– 2. 可能會影響到索引的使用.
指定列查詢
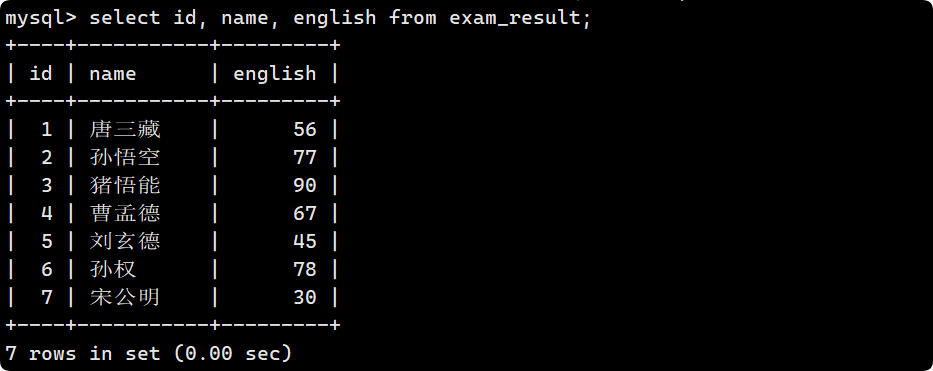
指定列查詢更為常用.
假如我只想查詢某些特定的列屬性, 比如我只想知道英語成績:
select id, name, english from exam_result;
查詢字段為表達式
a. 表達式不包含字段, 只是 常數 or 函數:
- 表達式為常數, 則結果中所有的列值都為這個常數:
SELECT id, name, 10 FROM exam_result;
+----+--------+----+
| id | name | 10 |
+----+--------+----+
| 1 | 唐三藏 | 10 |
| 2 | 孫悟空 | 10 |
| 3 | 豬悟能 | 10 |
| 4 | 曹孟德 | 10 |
| 5 | 劉玄德 | 10 |
| 6 | 孫權 | 10 |
| 7 | 宋公明 | 10 |
+----+--------+----+
- 表達式為 mysql 的函數, 比如常用的 database(), 或者 當前時間 now()
select database();
+------------+
| database() |
+------------+
| test1 |
+------------+
select now();
+---------------------+
| now() |
+---------------------+
| 2025-05-14 22:07:49 |
+---------------------+
b.表達式包含 1個 or 多個 字段:
SELECT id, name, english + 10 FROM exam_result;
+----+--------+--------------+
| id | name | english + 10 |
+----+--------+--------------+
| 1 | 唐三藏 | 66.0 |
| 2 | 孫悟空 | 87.0 |
| 3 | 豬悟能 | 100.0 |
| 4 | 曹孟德 | 77.0 |
| 5 | 劉玄德 | 55.0 |
| 6 | 孫權 | 88.0 |
| 7 | 宋公明 | 40.0 |
+----+--------+--------------+
SELECT id, name, english + chinese + math FROM exam_result;
+----+--------+--------------------------+
| id | name | english + chinese + math |
+----+--------+--------------------------+
| 1 | 唐三藏 | 221.0 |
| 2 | 孫悟空 | 242.0 |
| 3 | 豬悟能 | 276.0 |
| 4 | 曹孟德 | 233.0 |
| 5 | 劉玄德 | 185.0 |
| 6 | 孫權 | 221.0 |
| 7 | 宋公明 | 170.0 |
+----+--------+--------------------------+查詢結果指定別名 (as)
語法: 在 select 后指定的字段后添加 as 別名 即可, 其中as可以省略:
SELECT column [AS] alias_name [...] FROM table_name;
舉個例子, 把表達式 chinese + math + english 取別名為 總分
SELECT id, name, chinese + math + english 總分 FROM exam_result;
+----+--------+-------+
| id | name | 總分 |
+----+--------+-------+
| 1 | 唐三藏 | 221.0 |
| 2 | 孫悟空 | 242.0 |
| 3 | 豬悟能 | 276.0 |
| 4 | 曹孟德 | 233.0 |
| 5 | 劉玄德 | 185.0 |
| 6 | 孫權 | 221.0 |
| 7 | 宋公明 | 170.0 |
+----+--------+-------+
結果去重 distinct
要對查詢的結果去重, 只需要在 select 后加一個 distinct即可:
SELECT DISTINCT math FROM exam_result;
+------+
| math |
+------+
| 98.0 |
| 78.0 |
| 84.0 |
| 85.0 |
| 73.0 |
| 65.0 |
+------+
2. where 條件
一. 比較運算符:
| 運算符 | 說明 |
|---|---|
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 等于, 注意 NULL 不安全, 例如 NULL = NULL 的結果是 NULL |
| !=, <> | 不等于, 注意NULL 不安全, NULL != NULL 的結果是 NULL |
| <=> | 等于, NULL 安全, 例如 NULL <=> NULL 的結果是 TRUE(1) |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| BETWEEN a0 AND a1 | 范圍匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1) |
| IN (option, …) | 集合匹配, 如果是 option 中的任意一個, 返回 TRUE(1) |
| LIKE | 模糊匹配。% 表示任意多個(包括 0 個)任意字符;_ 表示任意一個字符 |
- 關于NULL的判斷
where 中, 用=和 != 判斷NULL 都是 NULL 不安全, 所以判斷是否為 NULL 一般不用<=>, 改用 IS NULL 和 IS NOT NULL.
// = 和 !=、<> 兩側只要涉及到NULL, 結果就是NULL.
SELECT NULL = NULL, NULL = 1, NULL != 0;
+-------------+----------+----------+
| NULL = NULL | NULL = 1 | NULL != 0 |
+-------------+----------+----------+
| <null> | <null> | <null> |
+-------------+----------+----------+
// <=> 可以進行 NULL 的比較.
SELECT NULL <=> NULL, NULL <=> 1, NULL <=> 0;
+---------------+------------+------------+
| NULL <=> NULL | NULL <=> 1 | NULL <=> 0 |
+---------------+------------+------------+
| 1 | 0 | 0 |
+---------------+------------+------------+
- 范圍匹配
范圍查找如果是左閉右閉區間, 可以用 between and 去替換 >= and <=. 比如:
//下面這兩句的查詢效果是一樣的
select * from exam_result where math>=60 and math<=80;
select * from exam_result where math between 60 and 80;
- in 的使用舉例
數學成績是 58 或者 59 或者 98 或者 99 分的同學及數學成績
select * from exam_result where math in (58,59,98,99);
+----+--------+---------+------+---------+
| id | name | chinese | math | english |
+----+--------+---------+------+---------+
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| 3 | 豬悟能 | 88.0 | 98.0 | 90.0 |
+----+--------+---------+------+---------+
- LIKE 模糊匹配
模糊匹配 like 有兩種特殊的占位符:
- _ : 嚴格匹配1個字符
- %: 匹配[0, n]個字符
舉例: 姓孫的同學 及 孫某同學
//查找姓孫的同學, 所以名字長度不限制, 用%
select * from exam_result where name like '孫%';
+----+--------+---------+------+---------+
| id | name | chinese | math | english |
+----+--------+---------+------+---------+
| 2 | 孫悟空 | 87.0 | 78.0 | 77.0 |
| 6 | 孫權 | 70.0 | 73.0 | 78.0 |
+----+--------+---------+------+---------+
//孫某同學, 嚴格要求名字總長度為 2
select * from exam_result where name like '孫_';
+----+------+---------+------+---------+
| id | name | chinese | math | english |
+----+------+---------+------+---------+
| 6 | 孫權 | 70.0 | 73.0 | 78.0 |
+----+------+---------+------+---------+
二. 邏輯運算符:
| 運算符 | 說明 |
|---|---|
| AND | 多個條件必須都為 TRUE(1), 結果才是 TRUE(1) |
| OR | 任意一個條件為 TRUE(1), 結果為 TRUE(1) |
| NOT | 條件為 TRUE(1), 結果為 FALSE(0) |
沒什么可說的, 直接看例子.
- 語文成績 > 英語成績 并且不姓孫的同學
select * from exam_result
where chinese > english and name not like '孫%'+----+--------+---------+------+---------+
| id | name | chinese | math | english |
+----+--------+---------+------+---------+
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
| 5 | 劉玄德 | 55.0 | 85.0 | 45.0 |
| 7 | 宋公明 | 75.0 | 65.0 | 30.0 |
+----+--------+---------+------+---------+
- 孫某同學, 否則要求總成績 > 200 并且 語文成績 < 數學成績 并且 英語成績 > 80
select id, name, chinese+math+english as total
from exam_result
where name like '孫_' or chinese+math+english > 200 and chinese < math and english > 80;
+----+--------+-------+
| id | name | total |
+----+--------+-------+
| 3 | 豬悟能 | 276.0 |
| 6 | 孫權 | 221.0 |
+----+--------+-------+
補充: where兩邊可以都是字段名, 但是它不能使用別名去進行比較.
因為 select 的執行順序是 1. from 2. where 3. select, 所以別名不能用于where中, 也不能在where里起別名.
比如這里用別名去進行比較:

可以理解為別名是屬于"顯示"的范疇, 只是最后數據拿到之后改個名而已, 注意只能在 select 中起別名.
3. order by 排序
語法:
-- ASC 為升序(從小到大)
-- DESC 為降序(從大到小)
-- 默認為 ASC
SELECT ... FROM table_name [WHERE ...]
ORDER BY column [ASC|DESC], [...];
注意: 沒有 ORDER BY 子句的查詢, 返回的順序是未定義的, 永遠不要依賴這個順序.
- 查詢同學各門成績,依次按 數學降序,英語升序,語文升序的方式顯示
-- 多字段排序,排序優先級隨書寫順序
SELECT name, math, english, chinese FROM exam_result
ORDER BY math DESC, english, chinese;
+--------+------+---------+---------+
| name | math | english | chinese |
+--------+------+---------+---------+
| 唐三藏 | 98.0 | 56.0 | 67.0 |
| 豬悟能 | 98.0 | 90.0 | 88.0 |
| 劉玄德 | 85.0 | 45.0 | 55.0 |
| 曹孟德 | 84.0 | 67.0 | 82.0 |
| 孫悟空 | 78.0 | 77.0 | 87.0 |
| 孫權 | 73.0 | 78.0 | 70.0 |
| 宋公明 | 65.0 | 30.0 | 75.0 |
+--------+------+---------+---------+- 同學及 qq 號, 按 qq 號排序顯示
-- NULL 視為比任何值都小, 升序出現在最上面, 降序出現在最下面
//升序
select * from students order by qq;
+----+------+--------+
| id | name | qq |
+----+------+--------+
| 1 | 張三 | <null> |
| 4 | 田七 | <null> |
| 3 | 王五 | 111111 |
| 2 | 李四 | 123456 |
+----+------+--------+
//降序
select * from students order by qq desc;
+----+------+--------+
| id | name | qq |
+----+------+--------+
| 2 | 李四 | 123456 |
| 3 | 王五 | 111111 |
| 1 | 張三 | <null> |
| 4 | 田七 | <null> |
+----+------+--------+
4. LIMIT 篩選分頁結果
limit 的用法分為兩種:
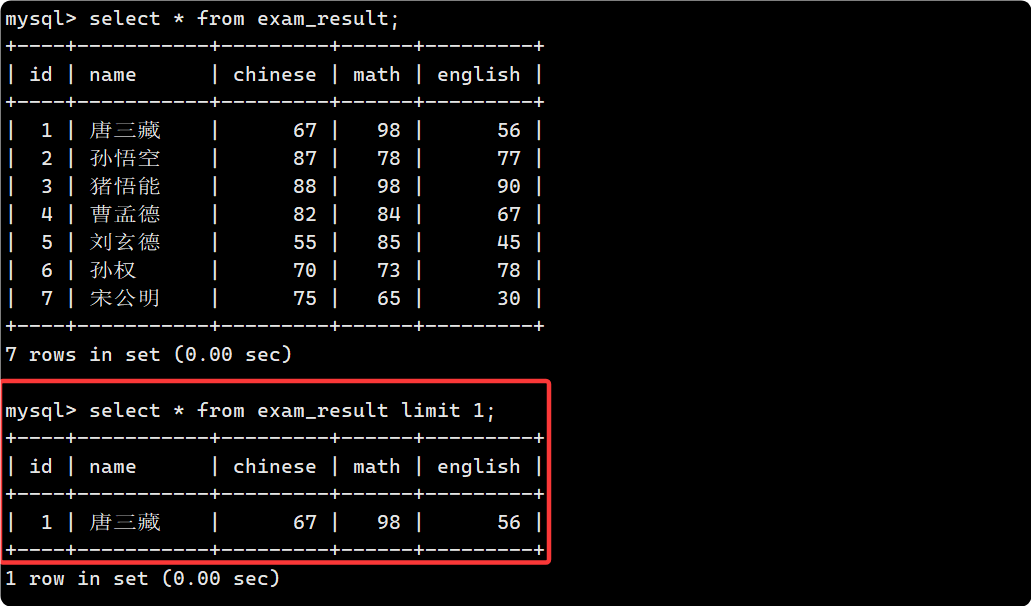
LIMIT n
SELECT ... LIMIT n; --從 0 開始, 連續讀出 n 條數據
LIMIT s, n或LIMIT n OFFSET s
//含義都是從下標 s 開始, 連續讀出 n 條結果. 其中 s 從 0 開始SELECT ... LIMIT s, n;
--或者
SELECT ... LIMIT n OFFSET s; --含義更明確一些
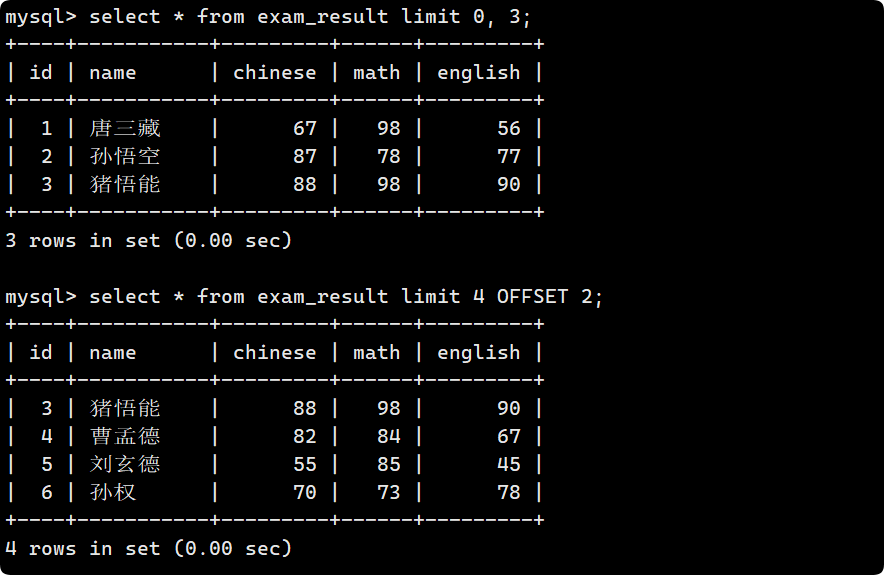
建議: 對未知表進行查詢時, 最好加一條 LIMIT 1, 避免因為表中數據過大, 查詢全表數據導致數據庫卡死
例子: 比如我想查詢總分大于200分的學生里的最高分:
select id, name, chinese+math+english as total from exam_result
where chinese+math+english > 200
order by total desc
limit 1;
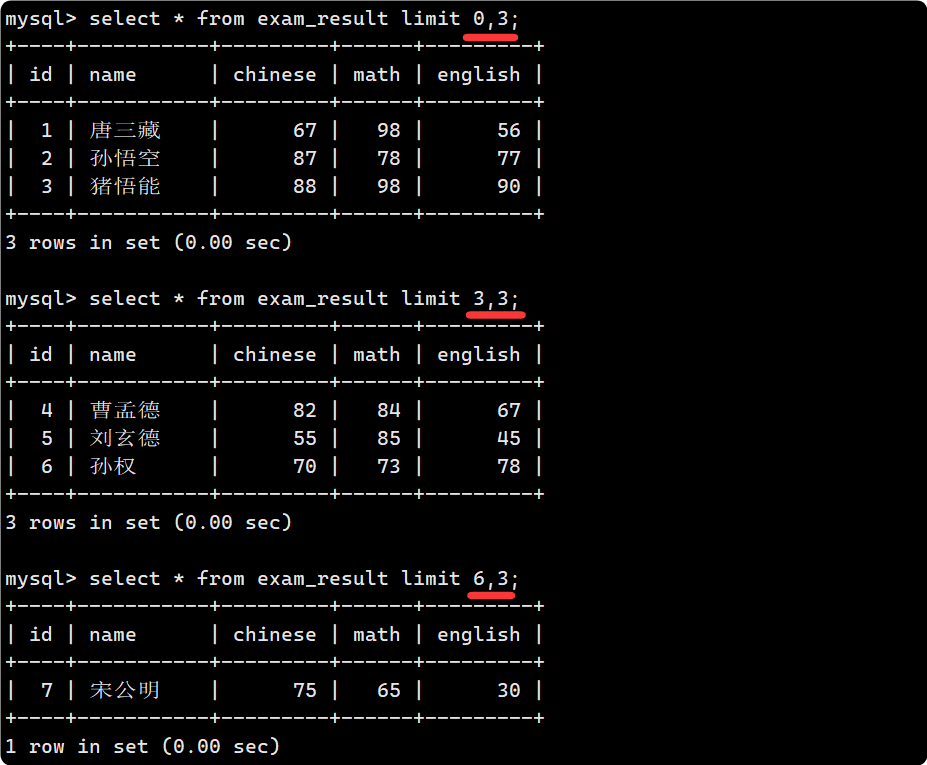
limit 還可以實現分頁: 比如按 id 進行分頁, 每頁 3 條記錄, 分別顯示 第 1、2、3 頁:
表的更新
update
語法:
UPDATE table_name SET column = expr [, column = expr ...]
[WHERE ...]
[ORDER BY ...]
[LIMIT ...]
update 是對查詢到的結果進行列值更新, 也就是在查詢的基礎上多了一步修改.
注意: 由于 update 會對表進行更新, 所以where的限制很重要, 否則可能會對一些意外的行進行修改. 所以更新全表的語句慎用.
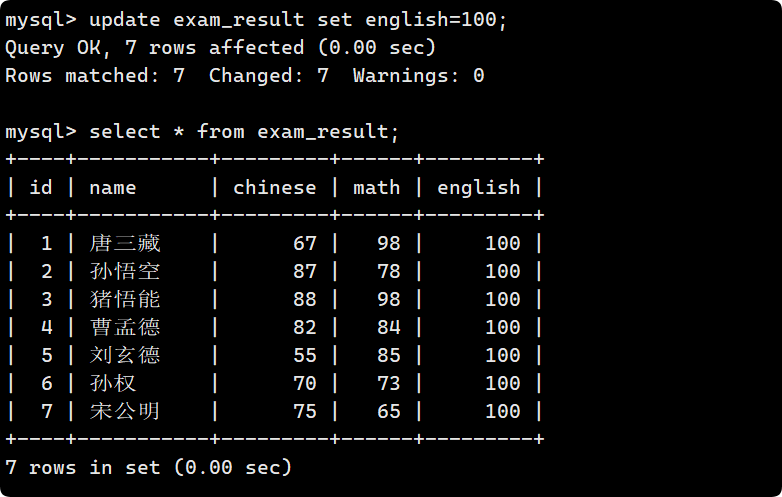
因此 update 語句一般都要添加 where 或 limit 限制:
- 修改單列屬性
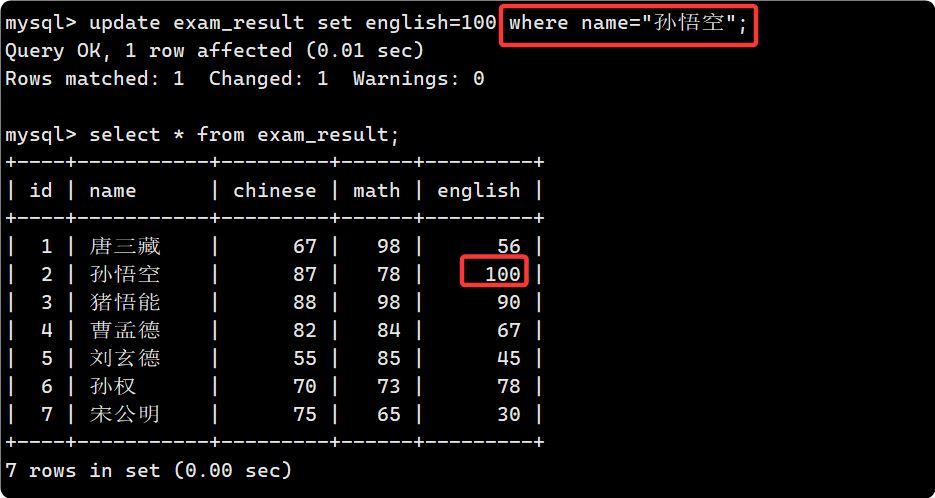
- 也可以一次更新多個列屬性:
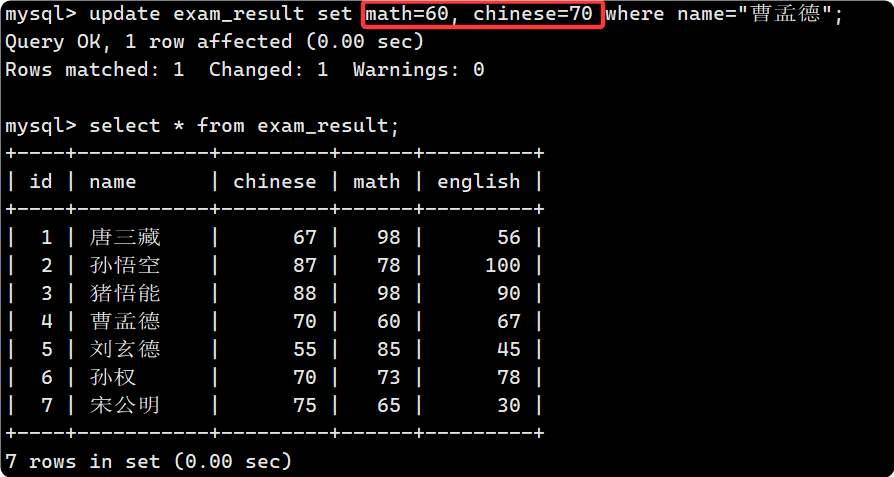
- 用 order by + limit 也可以達到篩選的目的
比如: 將總成績倒數前三的 3 位同學的數學成績加上 30 分:
update exam_result set math = math + 30
order by chinese+math+english asc
limit 3;Query OK, 3 rows affected (0.00 sec)
Rows matched: 3 Changed: 3 Warnings: 0
這樣做看上去有些奇怪, 但是也可以理解, 因為update其實是先進行了一次select操作, 因此可以理解為對select的結果進行更新.
驗證一下結果:
update 之前:
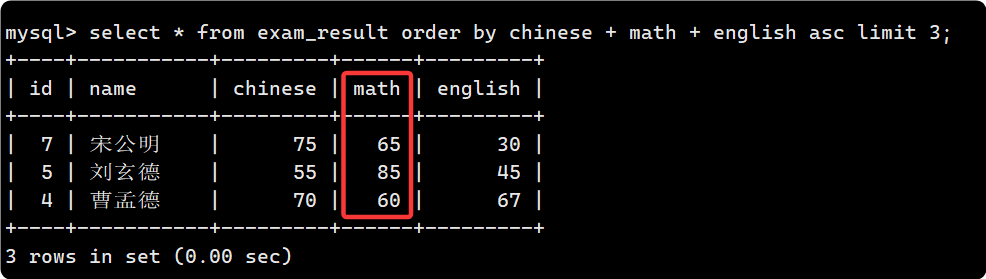
update之后, 注意由于math已經更改, 總成績發生變化, 所以要修改查詢的限制條件:
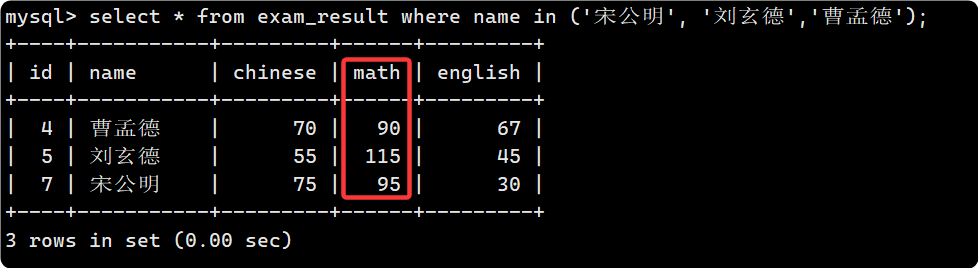
不過普通一般也沒有權限直接對數據庫進行增刪改查操作, 也不會直接在命令行去操作.
表的刪除
delete
語法:
DELETE FROM table_name
[WHERE ...]
[ORDER BY ...]
[LIMIT ...]
delete的主要功能概括來說是: 刪除表中指定條件的數據行
所以 delete 一般都要搭配 where 或 order by, limit 子句去使用, 如果直接 delete from table_name 是全表刪除, 要謹慎使用, 且 delete 全表刪除 和 truncate 有一些區別, 下面再說.
使用很簡單, 舉 3 個例子:
- 用 where 去刪除特定行
delete from exam_result where name='孫悟空';
Query OK, 1 row affected (0.00 sec)SELECT * FROM exam_result WHERE name = '孫悟空';
Empty set (0.00 sec)
- order by + limit
刪除總成績最高的同學的數據:
delete from exam_result
order by chinese+math+english asc
limit 1;Query OK, 1 row affected (0.00 sec)
- delete from 全表刪除
全表刪除的效果就是清空表的所有行:
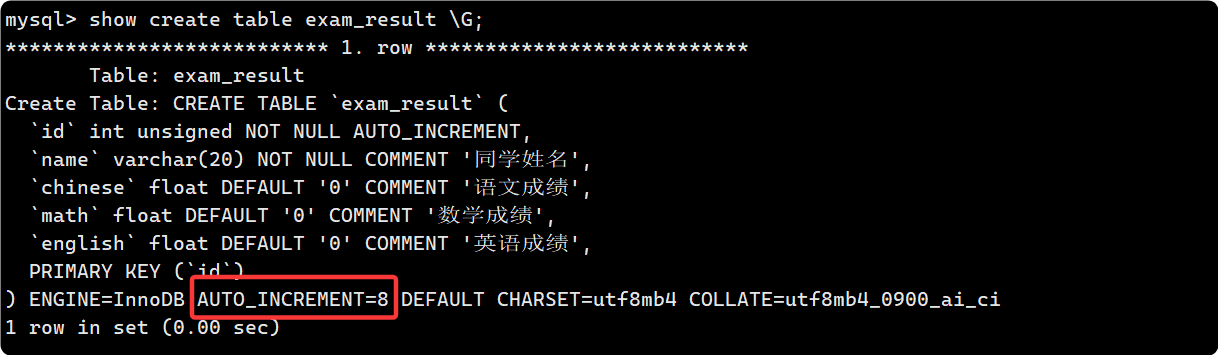
注意看這里全表刪除前后 auto_increment 的值沒有發生變化, 而 truncate 則會重置:
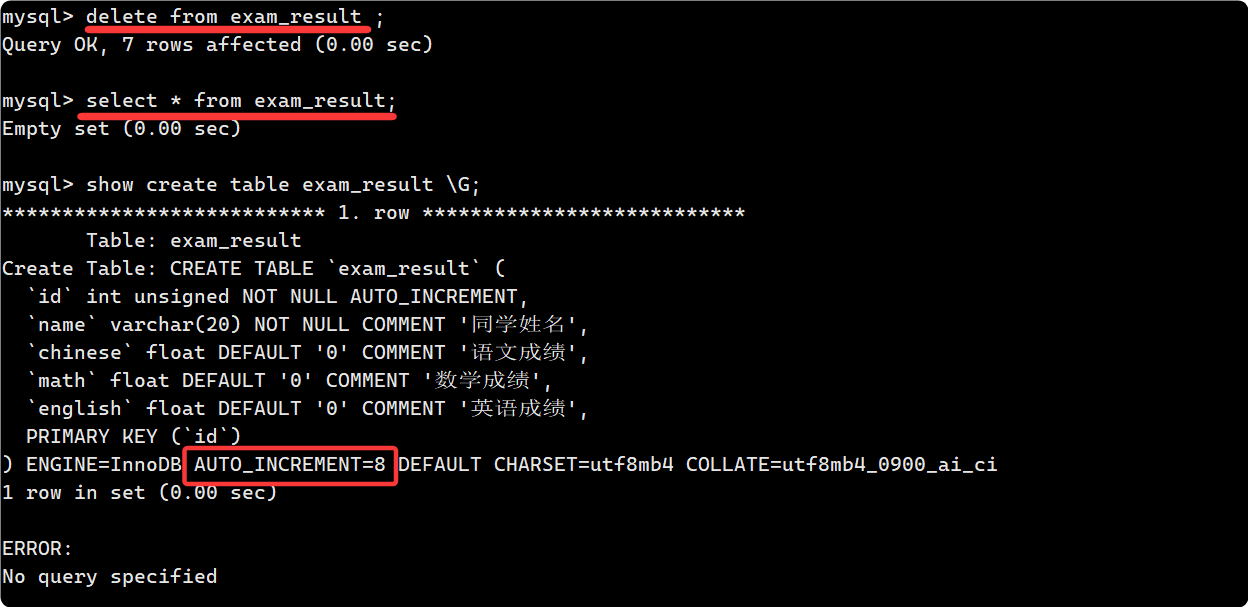
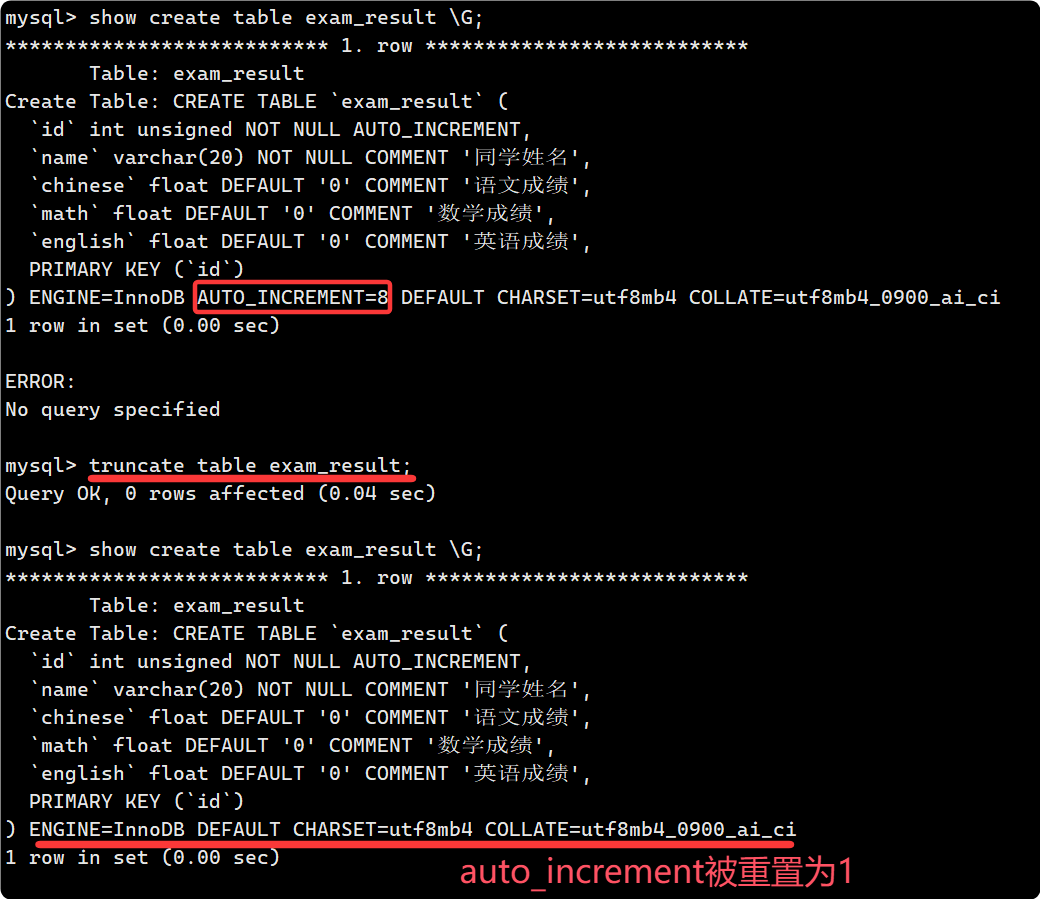
truncate
truncate 只用來刪除整張表的所有數據, 所以它的語法很簡單:
TRUNCATE [TABLE] table_name
主要來看它和 delete from 的區別:
- truncate 只能對整表操作, 不能像 DELETE 一樣針對部分數據操作.
- truncate 會重置 AUTO_INCREMENT 項, 所以可以邏輯上理解為 drop 舊表+ create 新表.
- 事務控制也有區別, 因為實際上 truncate 本質上不是DML 語句, 而是 DDL語句, 它不對數據操作, 因此 truncate 是隱式提交事務, 不能回滾;
而 DELETE 是 DML 操作, 屬于事務的一部分, 可以在需要時進行回滾.
本質是因為 delete 會為每一行被刪除的數據生成 Undo 日志, 所以可以被回滾
- 效率上, 也正是由于 TRUNCATE 是直接釋放整個數據頁, 沒有記錄每行的刪除日志, 因此在性能上遠優于逐行處理并記錄日志的 DELETE.
總結: delete from 是邏輯刪除, 記錄每行的變更, 適用于事務處理, 可以回滾; truncate 是物理刪除, 刪除整表的數據, 不可回滾.
但是 delete from 和 truncate 都需要謹慎使用.
聚合函數
聚合函數的使用存在一定限制. 通常, 聚合函數( COUNT()、SUM()、AVG()、MAX()、MIN() 等) 在沒有分組的情況下 不能與 (逗號隔開的多個列)或 .(某些表達式語法) 隨意混用.
| 函數 | 說明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查詢到的數據的 數量 |
| SUM([DISTINCT] expr) | 返回查詢到的數據的 總和, 不是數字沒有意義 |
| AVG([DISTINCT] expr) | 返回查詢到的數據的 平均值. 不是數字沒有意義 |
| MAX([DISTINCT] expr) | 返回查詢到的數據的 最大值,不是數字沒有意義 |
| MIN([DISTINCT] expr) | 返回查詢到的數據的 最小值, 不是數字沒有意義 |
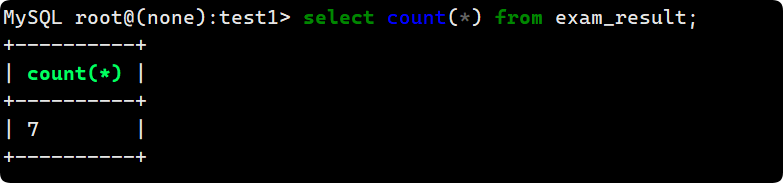
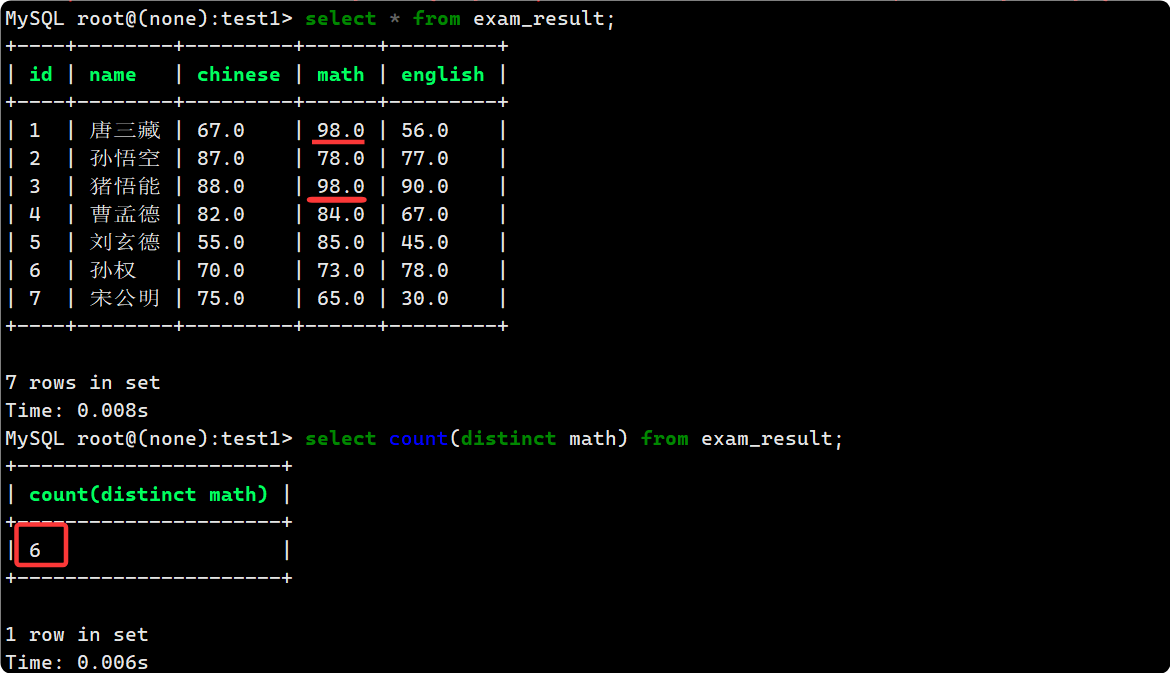
- count
統計 exam_result 表有多少行數據:
--兩種方式結果都一樣
//使用 * 做統計, 結果不受 NULL 的影響
select count(*) from exam_result;
//使用 表達式 做統計, 結果受 NULL 影響
select count(1) from exam_result; --1可以是任何常數
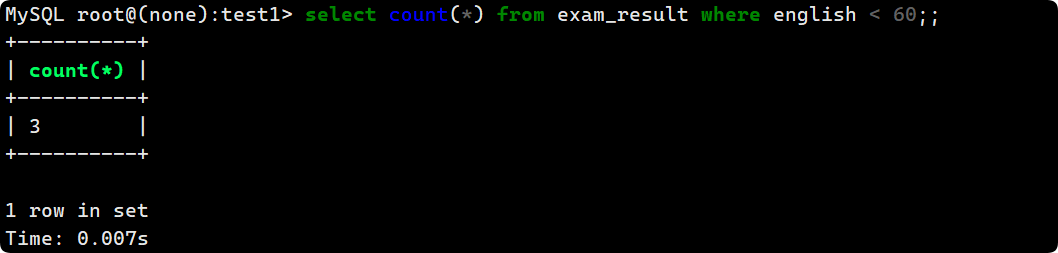
統計 表中有多少同學英語不及格:
select count(*) from exam_result where english < 60;
統計 exam_result 表中有多少不重復的數學成績:
select count(distinct math) from exam_result;
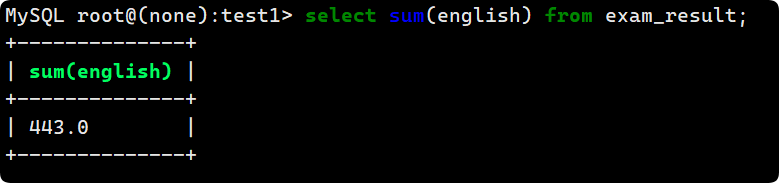
2. sum
統計所有同學的英語總成績:
select sum(english) from exam_result;
結合count, 可以統計班里同學的英語平均分:
select sum(english)/count(*) from exam_result;

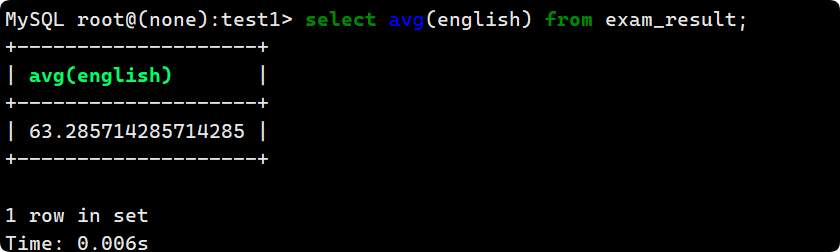
3. avg
與其 sum()/count() 統計平均分, 不如直接使用 avg 函數:
select avg(english) from exam_result;
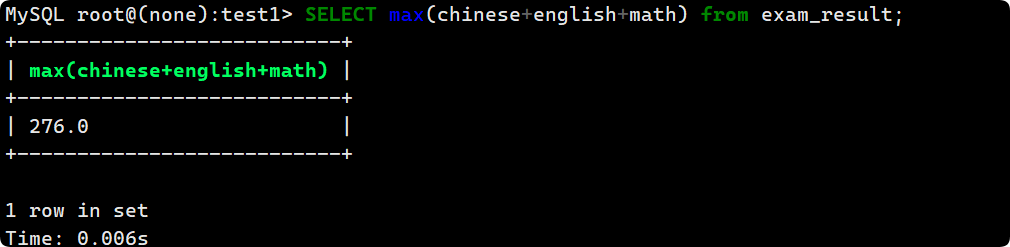
- max 和 min
統計班里同學總分的最高分:
SELECT max(chinese+english+math) from exam_result;
統計數學及格的同學里的最低分:
select min(math) from exam_result where math > 60;
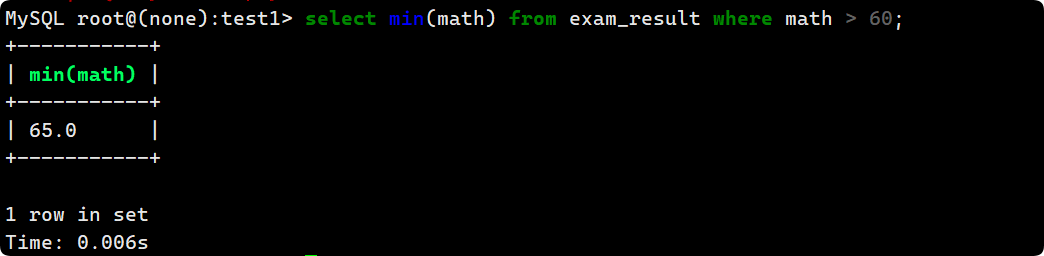
如果我們想知道這個分數的同學的更多信息(比如name) 呢 ?不能想當然的單純添加一個name:
// 錯誤寫法
select name, min(math) from exam_result where math > 60;
(1140, "In aggregated query without GROUP BY, expression #1 of SELECT list contains nonaggregated column 'test1.exam_result.name'; this is incompatible with sql_mode=only_full_group_by")
正確寫法必須借助其他手段:
比如:
- 常規的方法 使用 ORDER BY + LIMIT 1:
select name, math from exam_result where math > 60 order by math asc limit 1;

2. 使用子查詢:
select name, math from exam_result
where math =
(select min(math) from exam_result where math > 60);

對于大多數應用場景, 聚合函數主要用于對整張表或查詢結果進行簡單的整體統計, 也就是像上面一樣直接使用聚合函數. 在剩下的場景中, 聚合函數則通常結合 GROUP BY 子句使用, 先對數據按照某個維度進行分組, 再對每個分組分別進行統計分析.
分組 group by
在select中使用 group by 子句可以以指定列為分組依據 進行分組查詢
語法:
select column1, column2, .. from table group by column;
分組的目的是為了: 在分組之后, 更好的進行聚合統計.
因此我們使用 group by 的時候, 重要的是將 group by 本身的功能 和 我們的需求對應.
舉例: 事先創建一個雇員信息表(來自oracle 9i的經典測試表)
現在有 EMP員工表, DEPT部門表, SALGRADE工資等級表
desc dept;
+--------+--------------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+--------------------------+------+-----+---------+-------+
| deptno | int(2) unsigned zerofill | NO | | <null> | |
| dname | varchar(14) | YES | | <null> | |
| loc | varchar(13) | YES | | <null> | |
+--------+--------------------------+------+-----+---------+-------+
desc emp;
+----------+--------------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+--------------------------+------+-----+---------+-------+
| empno | int(6) unsigned zerofill | NO | | <null> | |
| ename | varchar(10) | YES | | <null> | |
| job | varchar(9) | YES | | <null> | |
| mgr | int(4) unsigned zerofill | YES | | <null> | |
| hiredate | datetime | YES | | <null> | |
| sal | decimal(7,2) | YES | | <null> | |
| comm | decimal(7,2) | YES | | <null> | |
| deptno | int(2) unsigned zerofill | YES | | <null> | |
+----------+--------------------------+------+-----+---------+-------+
desc salgrade;
+-------+------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+------+------+-----+---------+-------+
| grade | int | YES | | <null> | |
| losal | int | YES | | <null> | |
| hisal | int | YES | | <null> | |
+-------+------+------+-----+---------+-------+
- 顯示每個部門的平均工資和最高工資.
由于我們的需求中出現了"每個部門", 并且還要統計 avg 和 max 工資, 因此發現我們的需求和 group by 的功能相符, 這里可以用 group by deptno 將表按照部門劃分, 并進行聚合統計, 最終顯示的行數為分組的組數.
select deptno, avg(sal), max(sal) from emp group by deptno;
+--------+-------------+----------+
| deptno | avg(sal) | max(sal) |
+--------+-------------+----------+
| 20 | 2175.000000 | 3000.00 |
| 30 | 1566.666667 | 2850.00 |
| 10 | 2916.666667 | 5000.00 |
+--------+-------------+----------+
- 顯示每個部門的每種崗位的平均工資和最低工資.
可以發現我們的需求中出現了 “每個部門” 的 “每種崗位”, 所以這涉及到多次分組, 假設有 n 個部門, m 種 崗位, 最終顯示的崗位最大值為 n×m, 最終以實際數據為準.
select deptno, job, avg(sal),min(sal) from emp
group by deptno, job
order by deptno;
+--------+-----------+-------------+----------+
| deptno | job | avg(sal) | min(sal) |
+--------+-----------+-------------+----------+
| 10 | CLERK | 1300.000000 | 1300.00 |
| 10 | MANAGER | 2450.000000 | 2450.00 |
| 10 | PRESIDENT | 5000.000000 | 5000.00 |
| 20 | ANALYST | 3000.000000 | 3000.00 |
| 20 | CLERK | 950.000000 | 800.00 |
| 20 | MANAGER | 2975.000000 | 2975.00 |
| 30 | CLERK | 950.000000 | 950.00 |
| 30 | MANAGER | 2850.000000 | 2850.00 |
| 30 | SALESMAN | 1400.000000 | 1250.00 |
+--------+-----------+-------------+----------+
分組, 實際上是把整個表當成一個組, 然后按照條件拆成了多個組, 可以從邏輯上理解為將一個大表拆分為了多個子表, 從而能夠對各個子表分別進行聚合統計.
所以能出現在 select 子句后字段的一般都是group by 后出現的充當條件的字段 和聚合函數.
having
having 是對聚合后的統計數據進行條件篩選.
顯示平均工資低于2000的部門和它的平均工資
select deptno, avg(sal) as avg_sal
from emp
group by deptno
having avg_sal < 2000;
having vs where 區別理解?
having 和 where 都是進行條件篩選, 但是它們是完全不同的條件篩選.
- 語義是不同的, where 是對一整個表的具體的任意列進行條件篩選, 而 having 是對分組聚合之后的結果進行條件篩選.
- 篩選的階段是不同的,

綜合練習
- 查詢工資高于500或崗位為MANAGER的雇員,同時還要滿足他們的姓名首字母為大寫的J
//正常寫法
select * from emp
where (sal > 500 or job='MANAGER') and ename like 'J%';
//用字符串函數也可以
select * from emp
where (sal > 500 or job='MANAGER') and substring(ename, 1, 1) = 'J';--結果都正確:
+-------+-------+---------+------+---------------------+---------+--------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+-------+-------+---------+------+---------------------+---------+--------+--------+
| 7566 | JONES | MANAGER | 7839 | 1981-04-02 00:00:00 | 2975.00 | <null> | 20 |
| 7900 | JAMES | CLERK | 7698 | 1981-12-03 00:00:00 | 950.00 | <null> | 30 |
+-------+-------+---------+------+---------------------+---------+--------+--------+
- 按照部門號升序而雇員的工資降序排序
select * from emp order by deptno, sal desc;
- 使用年薪進行降序排序
這里值得說一下, 假設這里年薪的計算為: 12*月薪 + 獎金, 但是SQL里年薪的表達式不能直接這樣計算, 因為獎金 comm 可能為NULL, 導致表達式結果為NULL, 這里需要使用ifnull函數:
select empno, ename , 12*sal+ifnull(comm,0) as '年薪' from emp order by '年薪' desc;
+-------+--------+----------+
| empno | ename | 年薪 |
+-------+--------+----------+
| 7369 | SMITH | 9600.00 |
| 7499 | ALLEN | 19500.00 |
| 7521 | WARD | 15500.00 |
| 7566 | JONES | 35700.00 |
| 7654 | MARTIN | 16400.00 |
| 7698 | BLAKE | 34200.00 |
| 7782 | CLARK | 29400.00 |
| 7788 | SCOTT | 36000.00 |
| 7839 | KING | 60000.00 |
| 7844 | TURNER | 18000.00 |
| 7876 | ADAMS | 13200.00 |
| 7900 | JAMES | 11400.00 |
| 7902 | FORD | 36000.00 |
| 7934 | MILLER | 15600.00 |
+-------+--------+----------+
- 顯示工資最高的員工的名字和工作崗位, 這里需要用到子查詢去得到max(sal), 然作為where的一部分:
select ename, job from emp where sal = (select max(sal) from emp);
+-------+-----------+
| ename | job |
+-------+-----------+
| KING | PRESIDENT |
+-------+-----------+
- 顯示每個部門的平均工資和最高工資, 注意這里可以用 format 函數去限制小數點
select deptno, format(avg(sal), 2), max(sal) from emp group by deptno;
+--------+---------------------+----------+
| deptno | format(avg(sal), 2) | max(sal) |
+--------+---------------------+----------+
| 20 | 2,175.00 | 3000.00 |
| 30 | 1,566.67 | 2850.00 |
| 10 | 2,916.67 | 5000.00 |
+--------+---------------------+----------+
最后可以總結一下 select 子句中各個部分的執行順序:
SQL查詢中各個關鍵字的執行先后順序 from > on > join > where > group by > with > having > select > distinct > order by > limit


)




—— 內存優化)










:復習)
