源自:https://github.com/RAMshades/AcousticsM
特征提取
特征是可測量的屬性,作為系統的輸入。這些輸入與特定數據樣本相關,機器學習模型可通過解讀這些特征來提供預測。特征通常具有獨立性,并能提供樣本的具體細節。音頻特征示例包括(但不限于):
- 音高
- 強度
- 能量
- 包絡
- 音色
- 過零率
- 節奏
- 旋律
- 和弦
除上述特征外,還存在其他提取有效相關信息的方法。例如,可使用快速傅里葉變換或梅爾頻率倒譜系數(下文將重點介紹)進行特征提取。
更廣義而言,任何可作為輸入的信息都可視為特征。這些特征類似于能引導我們得出詞匯/解決方案/或任何有助于預測的描述要素。本筆記本將深入探討維度令人困惑的特征提取世界及其重要性,主要涵蓋以下主題:
- 特征示例
- 為何需要關注特征?
- 特征提取方法示例
- 一維特征提取
- 二維特征提取
- 參考文獻
我們將在其他筆記本中討論特征評估方法及如何選擇最佳特征。
創建者:Ryan A. McCarthy
Import packages
# import packages
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from scipy import statsimport librosa
import librosa.display
import IPython.display as ipdfrom glob import glob
import opendatasets as od
特征示例
讓我們看看Spotify熱門歌曲提取的音頻特征。
od.download('https://www.kaggle.com/datasets/julianoorlandi/spotify-top-songs-and-audio-features')
df = pd.read_csv("spotify-top-songs-and-audio-features/spotify_top_songs_audio_features.csv")
df
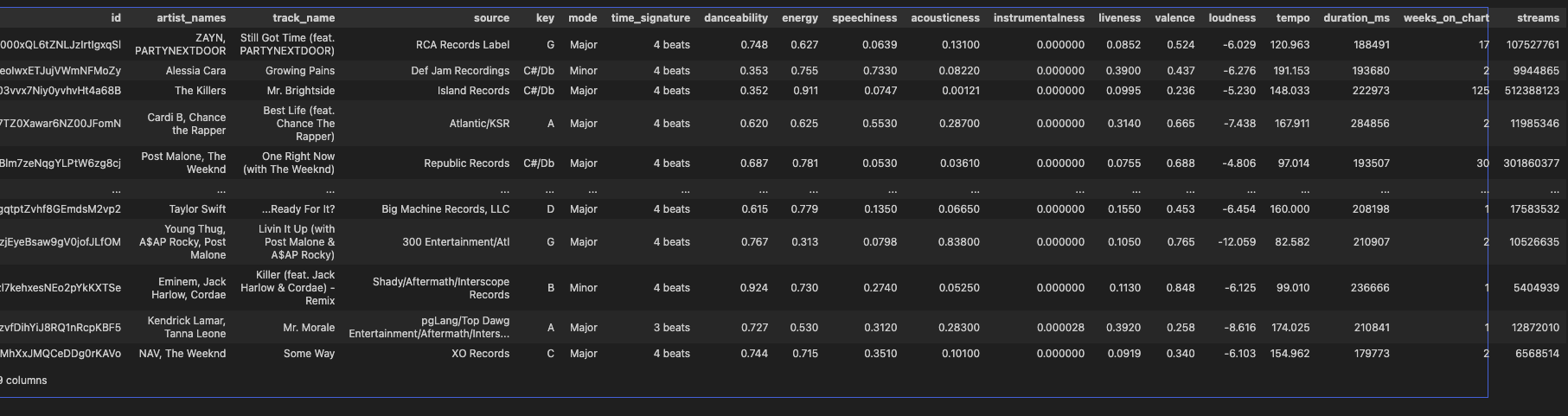
我們可以看到,這些特征可能包含數值型數據、分類型數據、布爾值等。需要注意的是,并非所有特征都有助于預測輸出。某些特征可能會對模型造成干擾或存在模糊性。讓我們以上述示例為基礎,繪制特征間的相互關系圖。這將幫助我們直觀考察變量之間的協同變化情況。
# Plot
plt.figure(figsize=(10,8), dpi= 80)
sns.pairplot(df, kind="scatter", hue="key", plot_kws=dict(s=80, edgecolor="white", linewidth=2.5))
plt.title('Feature Comparisons')
plt.show()
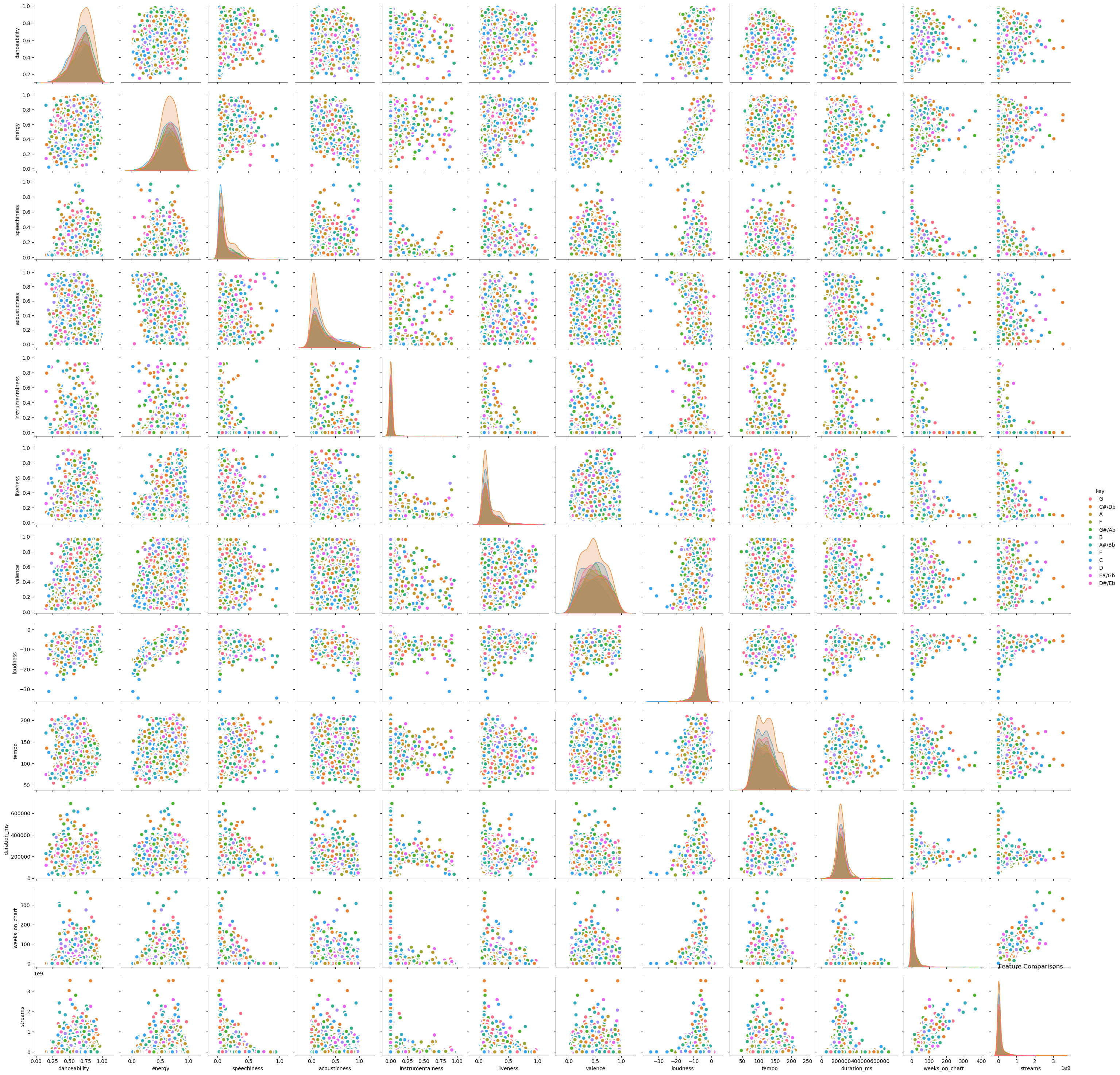
在許多情況下,我們希望移除線性相關的特征,因為它們無法提供顯著獨特的信息。然而,線性相關變量有時也可能具有價值,保留或移除這些特征的決定權在于機器學習模型的開發者。
為何需要關注特征?
特征選擇對機器學習至關重要,錯誤的特征會導致模型預測出錯誤的分類或數值。此外,提供模糊信息可能產生誤導性結果。例如,若我用毛發、耳朵、尾巴和兩只眼睛來描述某個生物,很多人可能會認為我在描述貓或狗,但若缺乏更多信息則難以準確判斷——這正是特征的作用所在:通過提供關鍵信息來消除模糊性,實現具體識別。
這種模糊性在聲學機器學習中同樣存在。使用特定頻率的振幅等基礎信息,可能有助于解決僅聚焦于該頻率或特定場景的問題。例如在檢測特定頻率的蜂鳴聲時,這種方法完全適用,因為只需關注該頻率下的聲音特征。但若需要識別具有相同頻率的海豚咔嗒聲與汽車鳴笛聲,僅靠單一頻率特征就顯得不足。請注意,雖然存在大量特征與特征提取技術,但為簡潔起見,下文僅重點介紹部分特征提取方法。
# Example Sound
filename = librosa.ex('trumpet')
y, sr = librosa.load(filename)# Play audio file
ipd.Audio(data=y,rate = sr)plt.figure(figsize = (8, 2))
librosa.display.waveshow(y = y, sr = sr);
plt.title("Sound Wave", fontsize = 23);
plt.ylabel('Amplitude')
plt.show()
一維特征
一維特征提取可包含從時間序列或信號中提取的數值型、分類型、時間序列等值。針對上述音頻,我們將演示如何通過將數據分割成不同段落(具體采用2048個樣本的窗口)來提取信息。這些方法可輕松應用于整個音頻文件、半段音頻或分段處理。
plt.figure(figsize = (8, 2))
librosa.display.waveshow(y = y, sr = sr);
for i in range(2048,len(y),2048):plt.axvline(x=i/sr,color='r')
plt.title("Sound Wave Split Up", fontsize = 23);
plt.ylabel('Amplitude')
plt.show()
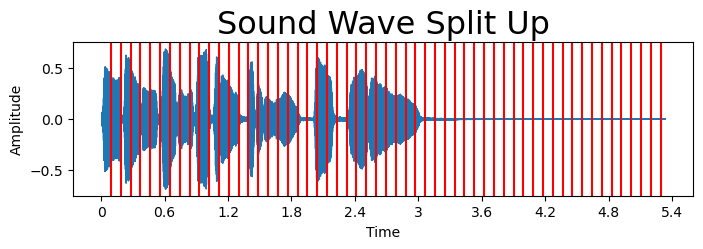
將數據分割成若干段落后,我們可以計算統計指標、通過一維卷積神經網絡提取信息,或應用降維/擴維變換。
統計特征
統計特征可包含從數據中計算均值、方差、均方根、能量等指標。這些計算可作為特征提取的有效初步方法,因為(在許多情況下)機器學習模型需要借助數學規律來確定給定輸入對應的輸出概率。下文我們將探討幾種可提取的特征類型。
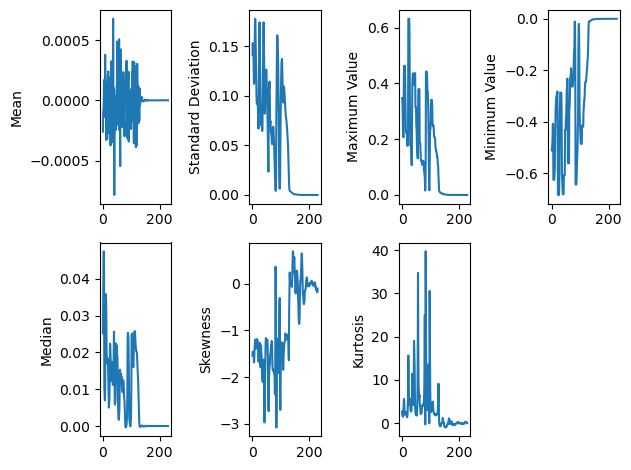
基礎統計量
假設我們有一個長度為nnn(樣本數量)的信號xxx,需要提取特征AAA。可采用的一種方法是計算信號平均值:
Aμ=∑i=1n(xi)n.A{\mu} = \frac{\sum_{i=1}^n(x_i)}{n}.
Aμ=n∑i=1n?(xi?)?.
信號平均值有助于提取潛在趨勢并消除信號中的隨機噪聲,這對模型具有意義。在某些情況下,均值可能因受數據異常值影響過大而成為過于嚴苛的指標。此時可采用中位數計算:
Amedian={x[n+12]x,若n為奇數x[n2]+x[n2+1]2,若n為偶數A_{median}=
\begin{cases}\frac{x[\frac{n+1}{2}]}{x},& \text{若n為奇數} \\\frac{x[\frac{n}{2}]+x[\frac{n}{2}+1]}{2}, & \text{若n為偶數}
\end{cases}
Amedian?={xx[2n+1?]?,2x[2n?]+x[2n?+1]?,?若n為奇數若n為偶數?
中位數受異常數據影響較小,但預測效用可能相對有限。為考察信號變異程度,可提取標準差:
Aσ=∑i=1n(xi?μ)2n,A{\sigma} = \sqrt{\frac{\sum_{i=1}^n(x_i-\mu)^2}{n}},
Aσ=n∑i=1n?(xi??μ)2??,
其中μ\muμ是信號xxx的均值。標準差有助于理解信號的變異性。另一種特征提取方法是獲取信號的最大值或最小值:
Amax=max?x:x=1,...,n,A_{max} = \max{x} : x = 1,...,n,
Amax?=maxx:x=1,...,n,
Amin=min?x:x=1,...,n.A_{min} = \min{x} : x = 1,...,n.
Amin?=minx:x=1,...,n.
在基于振幅的分析中(例如判斷聲音是否超過閾值),最大值或最小值可能具有識別價值。對于后續兩個特征,需要描述信號的矩。矩被定義為分布的定量特征,計算公式為:
mr=1n∑i=1n(xi?μ)r,m_r = \frac{1}{n}\sum^n_{i=1}(x_i - \mu)^r,
mr?=n1?i=1∑n?(xi??μ)r,
其中rrr為所計算的矩階數[9]。若數據在均值附近存在偏斜(例如區分輕聲音與響亮聲音),可計算信號的偏度:
A偏度=m3m23/2A_{偏度}=\frac{m_3}{m_2^{3/2}}
A偏度?=m23/2?m3??
偏度可視為信號的第三標準化矩[9]。與此互補的峰度用于衡量信號分布的峰值特征:
A峰度=m4m22A_{峰度} = \frac{m_4}{m_2^2}
A峰度?=m22?m4??
峰度測量的是數據分布的第四中心矩[9]。
meanfeatures = []
stdfeatures = []
maxv = []
minv = []
median = []
skew = []
kurt = []
framelength = 2048
step = 512
for i in range(0,len(y),step):meanfeatures.append(np.mean(y[i:i+framelength]))stdfeatures.append(np.std(y[i:i+framelength]))maxv.append(np.max(y[i:i+framelength]))minv.append(np.min(y[i:i+framelength]))median.append(np.median(y[i:i+framelength]))skew.append(stats.skew(y[i:i+framelength]))kurt.append(stats.kurtosis(y[i:i+framelength]))plt.subplot(2,4,1)
plt.plot(meanfeatures)
plt.ylabel('Mean')plt.subplot(2,4,2)
plt.plot(stdfeatures)
plt.ylabel('Standard Deviation')plt.subplot(2,4,3)
plt.plot(maxv)
plt.ylabel('Maximum Value')plt.subplot(2,4,4)
plt.plot(minv)
plt.ylabel('Minimum Value')plt.subplot(2,4,5)
plt.plot(median)
plt.ylabel('Median')plt.subplot(2,4,6)
plt.plot(skew)
plt.ylabel('Skewness')plt.subplot(2,4,7)
plt.plot(kurt)
plt.ylabel('Kurtosis')plt.tight_layout()
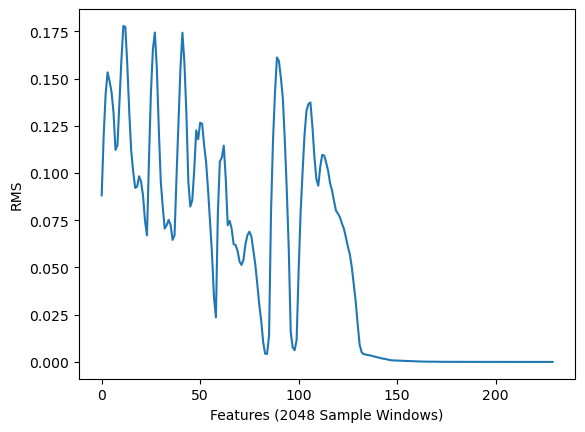
均方根
均方根(RMS)對應于信號的響度特性。長度為nnn(樣本數量)的信號xxx的計算公式如下:
Xrms=x12+x22+...+xn2n.X_{rms} = \sqrt{\frac{x_1^2+x_2^2+...+x_n^2}{n}}.
Xrms?=nx12?+x22?+...+xn2???.
均方根能夠提供信號能量隨時間波動的重要信息[10]。
# Loudness
rmsfeat = librosa.feature.rms(y=y,frame_length=2048)
plt.plot(rmsfeat[0])
plt.ylabel('RMS')
plt.xlabel('Features (2048 Sample Windows)')
plt.show()
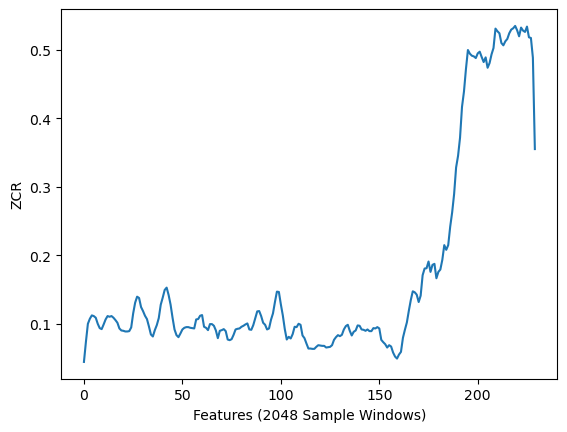
過零率
過零率(ZCR)定義為信號穿過零值的次數[11]。其計算公式如下:
zcr(A)=12∑i=2n∣sgn(x(i))?sgn(x(i?1))∣,zcr(A) = \frac{1}{2}\sum^{n}_{i=2}|sgn(x(i))-sgn(x(i-1))|,
zcr(A)=21?i=2∑n?∣sgn(x(i))?sgn(x(i?1))∣,
其中sgnsgnsgn表示數字的符號函數。負數值返回?1-1?1,零值返回000,正數值則返回111。
# Zeros Crossing Rate
zcrfeat = librosa.feature.zero_crossing_rate(y=y,frame_length=2048)
plt.plot(zcrfeat[0])
plt.ylabel('ZCR')
plt.xlabel('Features (2048 Sample Windows)')
plt.show()
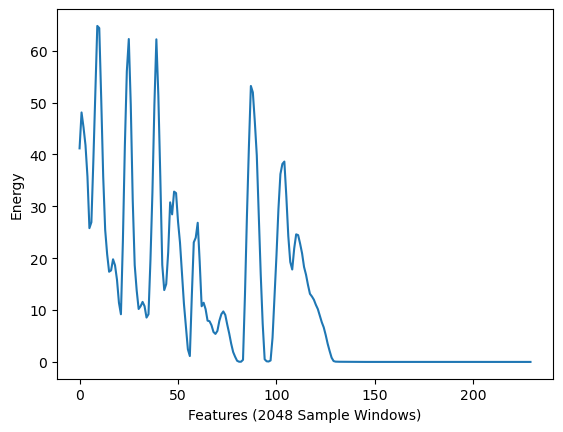
能量
信號的能量是指信號的總幅度,與信號的響度相關,其定義為:
E=∑i=1n∣x(i)∣2.E = \sum^n_{i=1}|x(i)|^2.
E=i=1∑n?∣x(i)∣2.
# Energy of a signal
energy = []
framelength = 2048
step = 512
for i in range(0,len(y),step):energy.append(np.sum(y[i:i+framelength]**2))
plt.plot(energy)
plt.ylabel('Energy')
plt.xlabel('Features (2048 Sample Windows)')
plt.show()
變換方法
變換是一種通過縮減或擴展信號維度的方法,通過修改信號使其更適用于分析和模型訓練。從統計學角度,變換可體現為對數、平方、指數等運算,這些運算將改變信號特性。另一種變換方法是通過卷積運算提取可用于模型訓練的關鍵特征。下文我們將定義幾種可實現信號擴展或縮減的變換方法。雖然未演示數據對數變換或平方變換的具體操作,但我們建議讀者參閱文獻[11]獲取詳細信息。
小波變換
小波是持續時間短、非對稱且不規則的數學函數,能夠將數據分解為不同頻率和尺度分量[12]。雖然我們不會完整闡述小波理論,但建議讀者參閱文獻[12,13,14]。通常采用短時離散小波變換(DWT),通過一系列濾波器(如高通和低通濾波器)處理信號。
其數學表達式可寫為:
Tm,n=a0?m/2∫x[t]ψ(a0?m[t]?nb0)dt,T_{m,n} = a_0^{-m/2} \int x[t]\psi (a_0^{-m}[t]-nb_0) dt,
Tm,n?=a0?m/2?∫x[t]ψ(a0?m?[t]?nb0?)dt,
其中ψ\psiψ為小波函數,aaa為伸縮參數,bbb為平移參數,mmm決定小波寬度(即高頻或低頻分量)。關于DWT的進一步說明可參閱文獻[15]。小波變換具有多種應用場景,從數據壓縮到特征提取均可適用。小波通過一族正交函數集來分解非周期連續函數。下文我們將使用PyWavelets包[6]演示小波變換及其不同函數族。
from scipy import signal
import pywt
pywt.families()
['haar','db','sym','coif','bior','rbio','dmey','gaus','mexh','morl','cgau','shan','fbsp','cmor']
哈爾小波
哈爾小波(以阿爾弗雷德·哈爾命名)的定義式為:
ψhaar(t)={1,0<t<12?1,12<t<10,其他情況\psi_{haar}(t)=
\begin{cases}1,& 0<t<\frac{1}{2} \\-1, & \frac{1}{2}<t<1\\0, & \text{其他情況}
\end{cases}
ψhaar?(t)=????1,?1,0,?0<t<21?21?<t<1其他情況?
這是一個在其支撐集上均值為零的分段常數函數。通過上述函數的伸縮和平移可構建標準正交基,其定義為:
ψj,n(t)=12jψ(t?2jn2j)\psi_{j,n}(t) = \frac{1}{\sqrt{2^j}}\psi(\frac{t-2^jn}{2^j})
ψj,n?(t)=2j?1?ψ(2jt?2jn?)
其中(j,n)∈Z2(j,n)\in \mathbb{Z}^2(j,n)∈Z2[14]。通過調整分解層級,可如下可視化哈爾小波的分解過程。
for n in range(1,4):plt.subplot(1,3,n)[phi, psi, x] = pywt.Wavelet('haar').wavefun(level=n**2)plt.plot(x,psi)plt.title(f'Level {n**2}')plt.ylim(-2,2)if n==1:plt.ylabel('Haar')
plt.tight_layout()
plt.show()
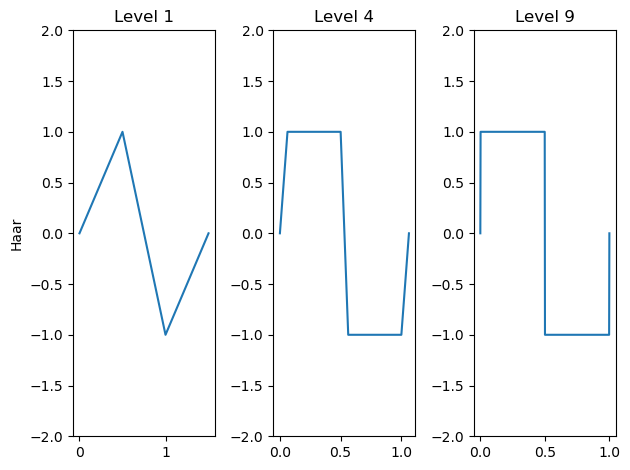
在上例中我們可以看到,使用的哈爾小波層級越高,小波就越趨于矩形波狀形態。
道貝奇斯小波
道貝奇斯小波(以英格麗·道貝奇斯命名)以具有最多消失矩而著稱。這類小波具有正交或雙正交特性,且不具備對稱性。其通常通過尺度函數表示為:
ψ(t)=2∑k=0N?1ck?(2t?k),\psi(t) = \sqrt{2}\sum_{k=0}^{N-1} c_k \phi(2t - k),
ψ(t)=2?k=0∑N?1?ck??(2t?k),
其中?\phi?為尺度函數,N表示階數[15]。下文我們將展示不同階數和層級的道貝奇斯小波示例。
for n in range(1,4):plt.subplot(4,3,n)[phi, psi, x] = pywt.Wavelet('db2').wavefun(level=n**2)plt.plot(x,psi)plt.title(f'Level {n**2}')plt.ylim(-2,2)if n==1:plt.ylabel('db2')
plt.tight_layout()
plt.show()for n in range(1,4):plt.subplot(4,3,n+3)[phi, psi, x] = pywt.Wavelet('db4').wavefun(level=n**2)plt.plot(x,psi)plt.ylim(-2,2)if n==1:plt.ylabel('db4')
plt.tight_layout()
plt.show()for n in range(1,4):plt.subplot(4,3,n+6)[phi, psi, x] = pywt.Wavelet('db6').wavefun(level=n**2)plt.plot(x,psi)plt.ylim(-2,2)if n==1:plt.ylabel('db6')
plt.tight_layout()
plt.show()for n in range(1,4):plt.subplot(4,3,n+9)[phi, psi, x] = pywt.Wavelet('db8').wavefun(level=n**2)plt.plot(x,psi)plt.ylim(-2,2)if n==1:plt.ylabel('db8')
plt.tight_layout()
plt.show()
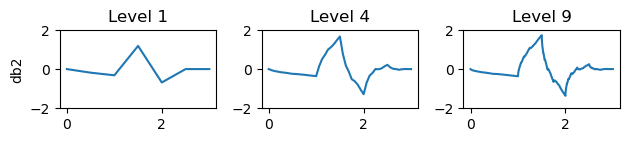
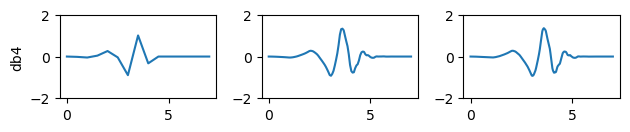
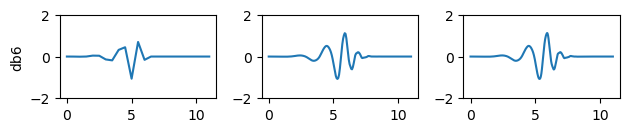
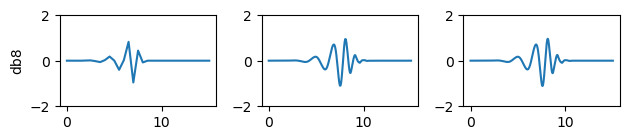
梅耶小波
梅耶小波(以伊夫·梅耶命名)是一種正交小波基,具有連續可微特性但不具備緊支撐性[16]。這類小波在頻域中的定義為:
ψ梅耶(w)={12πcos?(π2V(3w2π?1))ejω/2,若?2π3≤w≤4π312πcos?(π2V(3w4π?1))ejω/2,若?4π3≤w≤8π30,其他情況\psi_{梅耶}(w)=
\begin{cases}\frac{1}{\sqrt{2\pi}}\cos{(\frac{\pi}{2}V(\frac{3w}{2\pi}-1))}e^{j\omega/2},& \text{若 }\frac{2\pi}{3}\leq w\leq\frac{4\pi}{3} \\\frac{1}{\sqrt{2\pi}}\cos{(\frac{\pi}{2}V(\frac{3w}{4\pi}-1))}e^{j\omega/2}, & \text{若 }\frac{4\pi}{3}\leq w\leq \frac{8\pi}{3}\\0, & \text{其他情況}
\end{cases}
ψ梅耶?(w)=????2π?1?cos(2π?V(2π3w??1))ejω/2,2π?1?cos(2π?V(4π3w??1))ejω/2,0,?若?32π?≤w≤34π?若?34π?≤w≤38π?其他情況?
其中V函數定義為:
V(x)={0,若?x<0x,若?0<x<11,若?x>1V(x)=
\begin{cases}0,& \text{若 }x<0 \\x, & \text{若 }0<x<1\\1, & \text{若 }x>1
\end{cases}
V(x)=????0,x,1,?若?x<0若?0<x<1若?x>1?
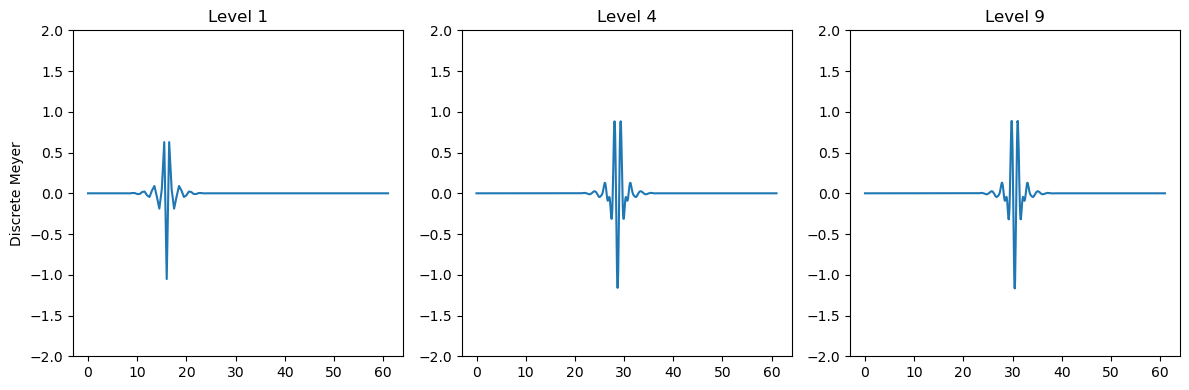
梅耶小波具有如下所示的波形特征。
plt.figure(figsize=(12, 4))
for n in range(1,4):plt.subplot(1,3,n)[phi, psi, x] = pywt.Wavelet('dmey').wavefun(level=n**2)plt.plot(x,psi)plt.title(f'Level {n**2}')plt.ylim(-2,2)if n==1:plt.ylabel('Discrete Meyer')
plt.tight_layout()
plt.show()
小波在時間序列中的應用示例
在回顧上述幾種小波族后,我們將探討這些小波提取的信息特征,特別是近似系數與細節系數。近似系數對應信號的低頻分量,類似于聲音中的低頻成分;反之,細節系數則對應信號的高頻分量。這些系數(與母小波共同)有助于定義被分解的信號特征。下文將通過具體演示展現小波分解過程及其提取的近似系數與細節系數數值。
# Robin bird example
filename = librosa.ex('robin')
y, sr = librosa.load(filename)# Apply DWT
coeffs = pywt.dwt(y, 'db1')
cA, cD = coeffs# Plot the original signal and the approximation and detail coefficients
fig, axs = plt.subplots(len(coeffs) + 1, 1, figsize=(10, 8))
lim = np.max(abs(y))
axs[0].plot(y)
axs[0].set_title('Original Signal')
axs[0].set_ylim(-lim,lim)axs[1].plot(cA)
axs[1].set_title('Approximation (Level 1)')
axs[1].set_ylim(-lim,lim)axs[2].plot(cD)
axs[2].set_title('Coefficients (Level 1)')
axs[2].set_ylim(-lim,lim)plt.tight_layout()
plt.show()
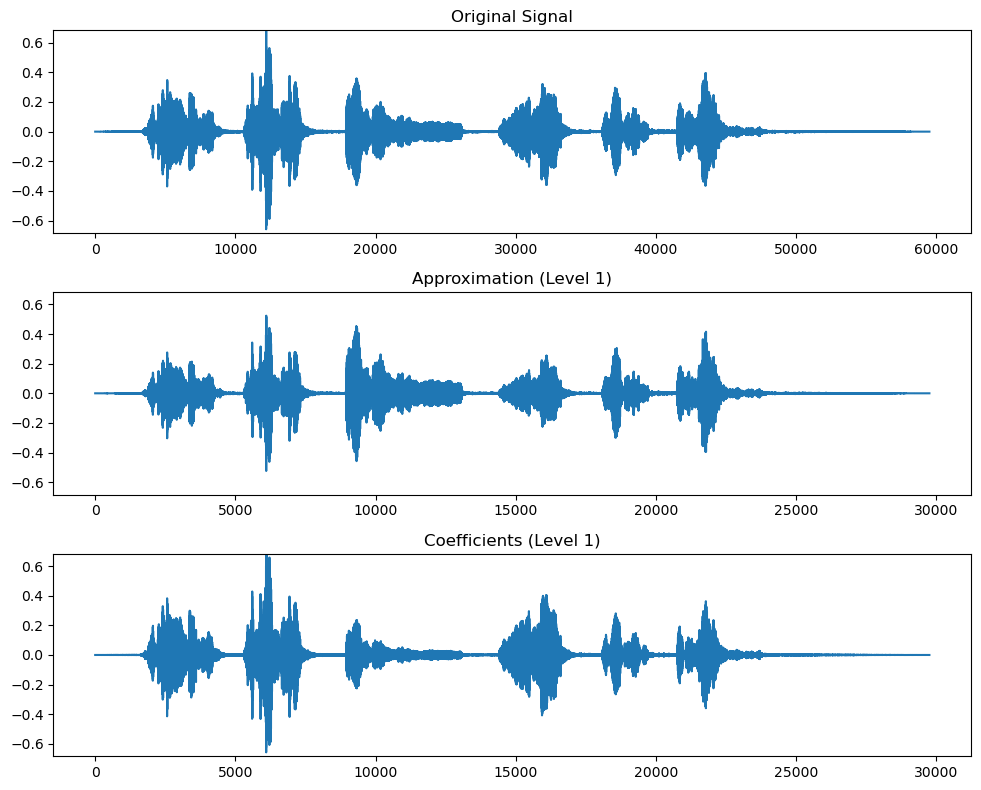
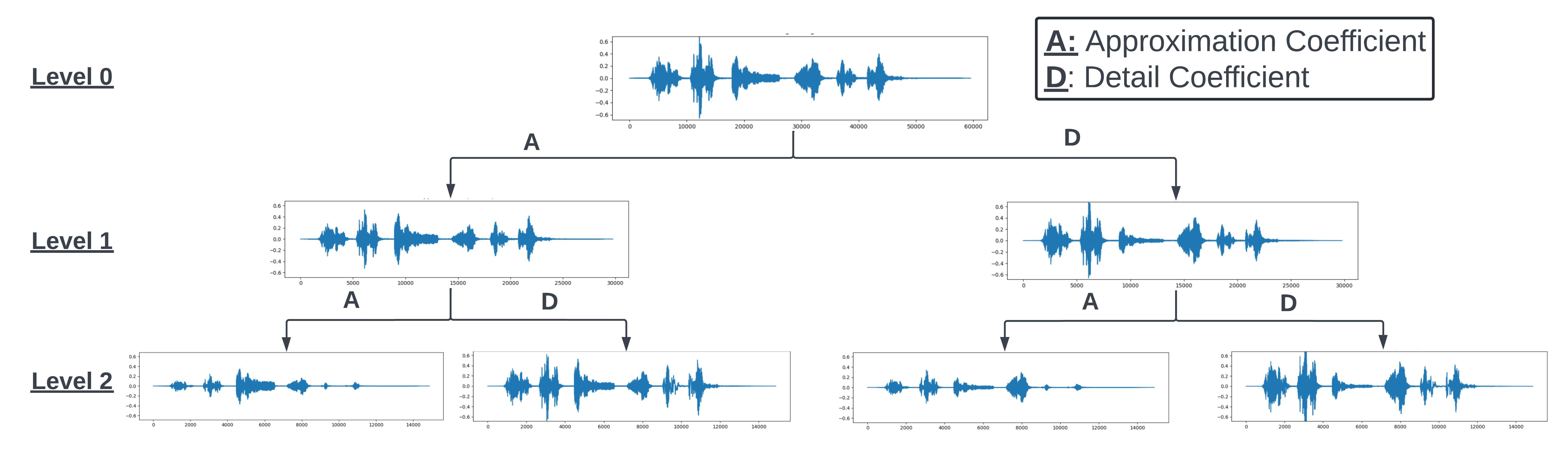
上例展示了使用小波變換后得到的近似系數與細節系數結果。這些輸出值既可直接作為特征輸入,也可用于進一步提取特征。需要特別注意的是,所得近似系數與細節系數的長度約為原始信號的一半——這與實施過程中對信號進行下采樣的濾波處理有關。這些數值可按下圖所示方式進行進一步分解。通過這種分層分解方式,可以在每個層級控制噪聲和頻率,從而實現在不同層級對信號進行處理。
from IPython.display import Image
Image(url="Wavelet_decomp.jpeg", width=1500, height=1500)
形狀片段
形狀片段轉換算法(Shapelet Transform)從時間序列數據集中提取形狀片段,并返回形狀片段與時間序列之間的距離值。形狀片段是指時間序列中連續時間點組成的子序列。為提升基于形狀片段的分類效果,算法會篩選出最具判別性的形狀片段。關于形狀片段轉換及其實現細節可參閱文獻https://pyts.readthedocs.io/en/stable/auto_examples/transformation/plot_shapelet_transform.html,同時我們也提供了分割兩種聲學信號的示例以演示其工作原理。該算法從時間序列集合TTT中識別長度為lll的候選序列:
Wl={W1,l∪...∪Wn,l}W_l = \{W_{1,l}\cup ... \cup W_{n,l}\}
Wl?={W1,l?∪...∪Wn,l?}
其中n代表數據集中數據集的數量(即信號或音頻記錄的數量)。形狀片段與長度為lll的時間序列TiT_iTi?子序列之間的最小距離定義為:
DS=min?d(S,Til)D_S = \min d(S,T_i^l)
DS?=mind(S,Til?)
式中d為距離計算公式(通常采用歐幾里得距離)。算法通過該原理確定需要使用的顯著形狀片段。
from pyts.datasets import load_gunpoint
from pyts.transformation import ShapeletTransform# Toy dataset
X_train, _, y_train, _ = load_gunpoint(return_X_y=True)# Shapelet transformation
st = ShapeletTransform(window_sizes=[12, 24, 36, 48],random_state=42, sort=True)
X_new = st.fit_transform(X_train, y_train)# Visualize the four most discriminative shapelets
plt.figure(figsize=(6, 4))
for i, index in enumerate(st.indices_[:4]):idx, start, end = indexplt.plot(X_train[idx], color='C{}'.format(i),label='Sample {}'.format(idx))plt.plot(np.arange(start, end), X_train[idx, start:end],lw=5, color='C{}'.format(i))plt.xlabel('Time', fontsize=12)
plt.title('The four most discriminative shapelets', fontsize=14)
plt.legend(loc='best', fontsize=8)
plt.show()
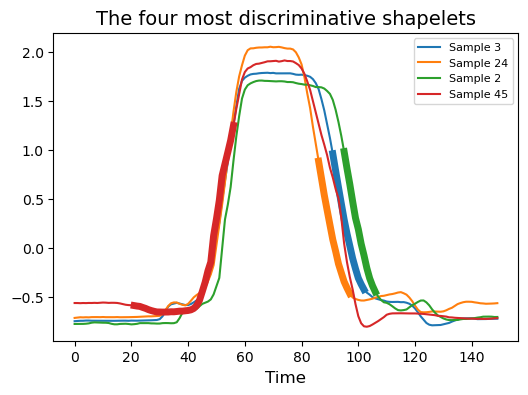
在上圖中,我們可以看到四個最具區分度的形狀片段,這些片段能夠有效區分數據。通過計算時間序列與每個形狀片段之間的距離,我們可以對數據進行轉換,從而最終提升分類準確率。
使用兩種聲音的示例
假設我們有兩種聲音(小號與知更鳥鳴叫),需要找出這兩種聲學信號的區分特征。我們可以利用形狀片段識別它們時間序列中的關鍵區段,從而實現分類與區分。
def split_array_equally(arr, n):"""Splits an array into equal parts and removes any unequal part."""size = len(arr) // nreturn [arr[i:i + size] for i in range(0, size * n, size)]# generate a dataset for classifciation based on examples
# trumpet example
filename = librosa.ex('trumpet')
y, sr = librosa.load(filename)data1 = np.vstack(split_array_equally(y,200)).T# Robin bird example
filename = librosa.ex('robin')
y, sr = librosa.load(filename)data2 = np.vstack(split_array_equally(y,200)).Tinputs = np.vstack([data1,data2])
outputs = np.vstack([np.ones((data1.shape[0],1)),2*np.ones((data2.shape[0],1))]).ravel()# Shapelet transformation
# transform the data using shapelets to
st = ShapeletTransform(window_sizes=[12, 24, 36, 48],random_state=42, sort=True)
X_new = st.fit_transform(inputs,outputs)# Visualize the four most discriminative shapelets
plt.figure(figsize=(6, 4))
for i, index in enumerate(st.indices_[:4]):idx, start, end = indexplt.plot(inputs[idx], color='C{}'.format(i),label='Sample {}'.format(idx))plt.plot(np.arange(start, end), inputs[idx, start:end],lw=5, color='C{}'.format(i))plt.xlabel('Time', fontsize=12)
plt.title('The four most discriminative shapelets', fontsize=14)
plt.legend(loc='best', fontsize=8)
plt.show()
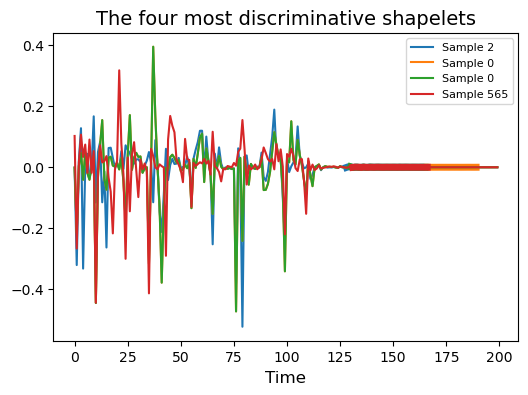
卷積核方法
隨機卷積核變換(ROCKET)通過隨機生成的卷積核進行特征提取,并為每個卷積核生成兩個特征:最大值與正值比例[1]。ROCKET可通過兩種方式運行:一是采用無監督技術,在不了解輸出標簽的情況下提取信息;二是采用有監督方法,識別能在數據中產生區分性的卷積核。下文我們以分段處理的小號與知更鳥鳴叫兩種聲音為例,演示ROCKET如何區分這兩類聲學片段。
from pyts.transformation import ROCKETdef split_array_equally(arr, n):"""Splits an array into equal parts and removes any unequal part."""size = len(arr) // nreturn [arr[i:i + size] for i in range(0, size * n, size)]# generate a dataset for classifciation based on examples
# trumpet example
filename = librosa.ex('trumpet')
y, sr = librosa.load(filename)data1 = np.vstack(split_array_equally(y,200)).T# Robin bird example
filename = librosa.ex('robin')
y, sr = librosa.load(filename)data2 = np.vstack(split_array_equally(y,200)).Tinputs = np.vstack([data1,data2])
outputs = np.vstack([np.ones((data1.shape[0],1)),2*np.ones((data2.shape[0],1))]).ravel()rocket = ROCKET(n_kernels=200, random_state=42)
x_rocket = rocket.fit_transform(X = inputs,y = outputs)# import PCA to decompose the data to plot
from sklearn.decomposition import PCApca = PCA(n_components=2)
X_r = pca.fit_transform(x_rocket)# Percentage of variance explained for each components
print("explained variance ratio (first two components): %s"% str(pca.explained_variance_ratio_)
)plt.figure()
target_name = ["trumpet","robin"]for i, target_name in zip([1, 2], target_names):plt.scatter(X_r[outputs == i, 0], X_r[outputs== i, 1], alpha=0.8, lw=lw, label=target_name)
plt.legend(loc="best", shadow=False, scatterpoints=1)
plt.title("PCA of ROCKET Transformed Data")plt.show()
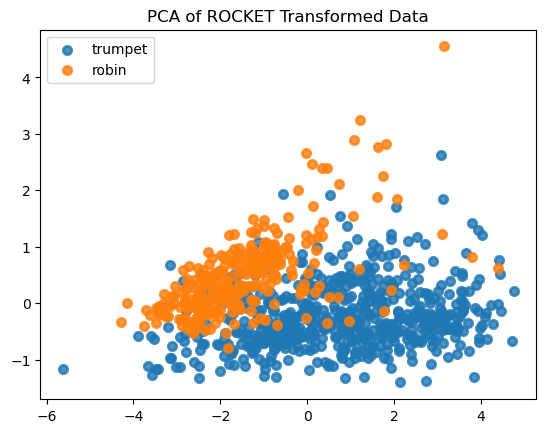
通過主成分分析結果可以看出,使用ROCKET變換后兩類聲音數據呈現出一定分離趨勢,這種特征可用于訓練預測模型。該方法雖然能快速獲得結果,但難以解釋從信號中提取的特征含義。
2D Features
頻譜特征
讓我們從一個簡單的合成信號開始分析:
Y(t)=2cos?(f0t)+4sin?(f1t)+cos?(f2t)+2sin?(f3t)Y(t) = 2\cos(f_0t) + 4\sin(f_1t) + \cos(f_2t) + 2\sin(f_3t)
Y(t)=2cos(f0?t)+4sin(f1?t)+cos(f2?t)+2sin(f3?t)
其中fNf_NfN?表示特定頻率
# generate signal
sr = 25000x = np.arange(0,5,1/sr)f0 = 10
f1 = 10000
f2 = 5000
f3 = 2000
y = 2*np.sin(f0* 2*np.pi*x)+4*np.cos(f1* 2*np.pi*x)+.5*np.cos(f2* 2*np.pi*x)+3*np.cos(f3* 2*np.pi*x)plt.plot(x,y)
plt.xlabel('Time (s)')
plt.ylabel('Amplitude')
plt.show()
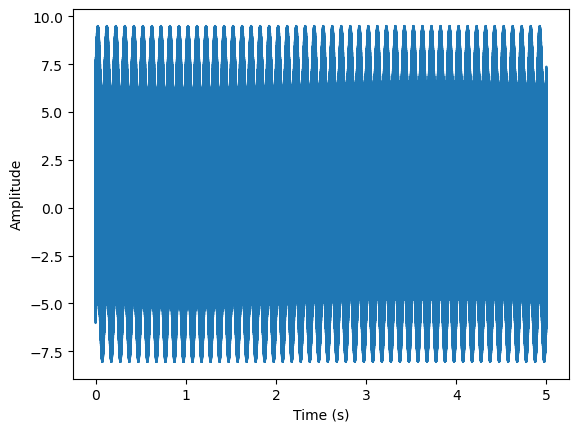
快速傅里葉變換與短時傅里葉變換
基于生成的信號,我們將計算單邊快速傅里葉變換(FFT)與短時傅里葉變換(STFT)。首先簡要定義FFT:給定長度為N的信號x[n]x[n]x[n],其FFT計算公式定義為:
X[k]=∑n=0N?1x[n]e?j2πknNX[k] = \sum^{N-1}_{n=0} x[n]e^{\frac{-j2\pi kn}{N}}
X[k]=n=0∑N?1?x[n]eN?j2πkn?
其中k = 0,…,n-1 表示FFT的變換長度。這是FFT的離散形式。可以看出,該信號通過自然對數及其不同頻率分量進行表征。
from scipy.fft import fft, fftfreq
N = len(x)
yf = fft(y)
xf = fftfreq(N, 1/sr)[:N//2]plt.plot(xf, 2.0/N * np.abs(yf[0:N//2]))
plt.grid()
plt.title('FFT')
plt.ylabel('Amplitude')
plt.xlabel('Hz')
plt.show()
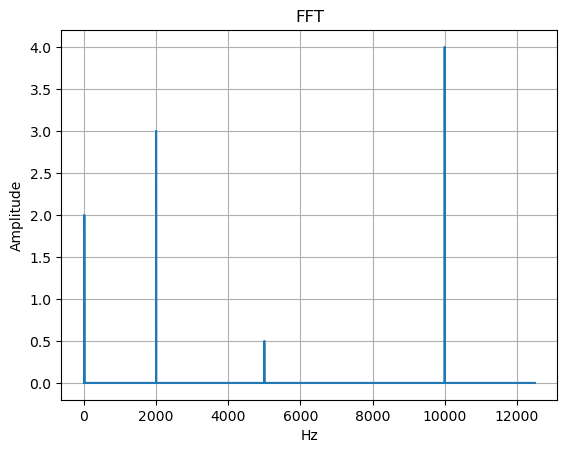
我們可以看到信號被分解為先前定義的頻率分量。FFT的問題在于當信號中存在瞬態聲音時,它無法捕捉局部瞬態特征且不包含任何時間分量。為解決這個問題,我們可以對信號進行分窗處理并應用FFT來捕捉瞬態聲音,這種方法稱為短時傅里葉變換(STFT)。下圖展示了生成信號的STFT處理結果。
# Pre-compute a global reference power from the input spectrum
D = librosa.stft(y) # STFT of y
S_db = librosa.amplitude_to_db(np.abs(D), ref=np.max)fig, ax = plt.subplots()
img = librosa.display.specshow(S_db, sr = sr,x_axis='time', y_axis='log', ax=ax)
ax.set(title='STFT')
fig.colorbar(img, ax=ax, format="%+2.f dB")
plt.show()
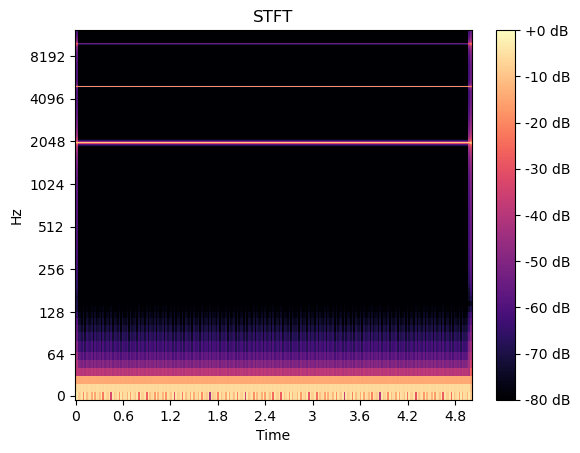
從上圖可以清晰看到信號yyy中包含的頻率成分及其對應的短時傅里葉變換結果。這類時頻圖像既可按頻率/時間維度進行分解,也可輸入大型卷積神經網絡(CNN)中對STFT中呈現的聲音特征進行分類。除短時頻變換外,我們還可采用其他幾種變換方法。
梅爾頻譜圖
另一種有效的二維表征方式是梅爾頻譜圖。其計算過程包括:對信號進行加窗處理,通過短時傅里葉變換(STFT)轉換數據,使得到的頻域表示通過梅爾濾波器組,最后對輸出的頻譜值進行求和與拼接。該濾波器組采用在梅爾刻度上等間隔排列的半重疊三角濾波器。更多技術細節可參閱https://ieeexplore.ieee.org/document/758101。
S = librosa.feature.melspectrogram(y=y, sr=sr, n_mels=128)fig, ax = plt.subplots()
S_dB = librosa.power_to_db(S, ref=np.max)
img = librosa.display.specshow(S_dB, x_axis='time',y_axis='mel', sr=sr, ax=ax)
fig.colorbar(img, ax=ax, format='%+2.0f dB')
ax.set(title='Mel-frequency spectrogram')
plt.show()
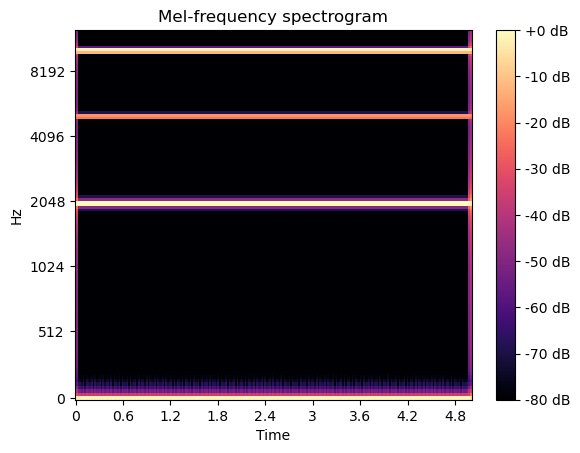
與短時傅里葉變換相似,梅爾頻譜顯示信號由頻率成分構成,這些頻率在頻域上的分布范圍略寬(即呈現更寬的頻帶)。
色譜圖
還可采用其他表征方式,例如色譜圖(chromagrams)——其將整個頻譜映射到音高類別。每個八度音階被劃分為代表半音的音箱,這些八度音階可用于區分音樂中的不同音高。
色譜圖通過短時傅里葉變換計算波形或功率譜,該實現方法源自文獻[7]。
filename = librosa.ex('trumpet')
y, sr = librosa.load(filename)# Chroma stft
S = librosa.feature.chroma_stft(y=y, sr=sr)fig, ax = plt.subplots()
S_dB = librosa.power_to_db(S, ref=np.max)
img = librosa.display.specshow(S_dB, y_axis='chroma', x_axis='time', sr=sr, ax=ax)
fig.colorbar(img, ax=ax, format='%+2.0f dB')
ax.set(title='Chroma STFT')
plt.show()
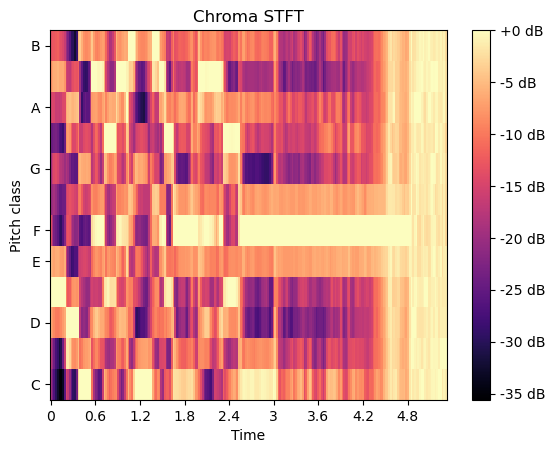
恒定Q值色譜圖與傅里葉變換及莫雷小波變換相關,其采用在頻率上按對數間隔排列的濾波器組實現。
# Chroma CQT
S = librosa.feature.chroma_cqt(y=y, sr=sr)fig, ax = plt.subplots()
S_dB = librosa.power_to_db(S, ref=np.max)
img = librosa.display.specshow(S_dB, y_axis='chroma', x_axis='time', sr=sr, ax=ax)
fig.colorbar(img, ax=ax, format='%+2.0f dB')
ax.set(title='Constant-Q Chromagram')
plt.show()
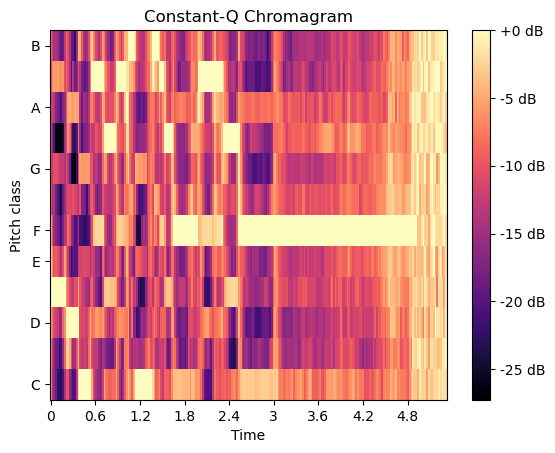
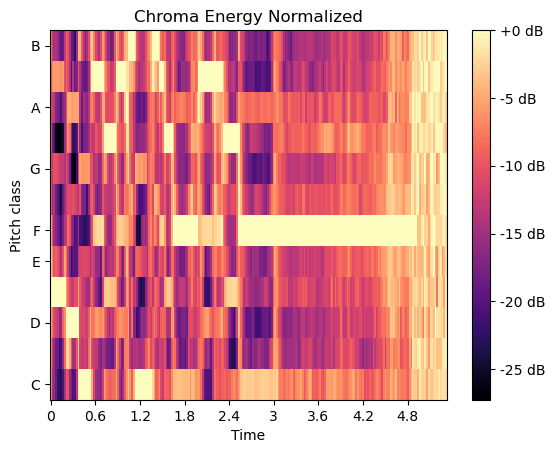
計算色譜變體“歸一化色譜能量”(CENS)
計算CENS特征時,在通過chroma_cqt獲取色譜向量后需執行以下步驟:
- 對每個色譜向量進行L1歸一化處理
- 基于“類對數”幅度閾值對振幅進行量化
# Chorma CENS
chromagram = librosa.feature.chroma_cens(y=y, sr=sr)fig, ax = plt.subplots()
S_dB = librosa.power_to_db(S, ref=np.max)
img = librosa.display.specshow(S_dB, y_axis='chroma', x_axis='time', sr=sr, ax=ax)
fig.colorbar(img, ax=ax, format='%+2.0f dB')
ax.set(title='Chroma Energy Normalized')
plt.show()
References
- A. Dempster, F. Petitjean and G. I. Webb, “ROCKET: Exceptionally fast and accurate time series classification using random convolutional kernels”. https://arxiv.org/abs/1910.13051.
- J. Lines, L. M. Davis, J. Hills and A. Bagnall, “A Shapelet Transform for Time Series Classification”. Data Mining and Knowledge Discovery, 289-297 (2012).
- Johann Faouzi and Hicham Janati. pyts: A python package for time series classification. Journal of Machine Learning Research, 21(46):1?6, 2020.
- Scikit-learn: Machine Learning in Python, Pedregosa et al., JMLR 12, pp. 2825-2830, 2011.
- McFee, Brian, Colin Raffel, Dawen Liang, Daniel PW Ellis, Matt McVicar, Eric Battenberg, and Oriol Nieto. “librosa: Audio and music signal analysis in python.” In Proceedings of the 14th python in science conference, pp. 18-25. 2015.
- Gregory R. Lee, Ralf Gommers, Filip Wasilewski, Kai Wohlfahrt, Aaron O’Leary (2019). PyWavelets: A Python package for wavelet analysis. Journal of Open Source Software, 4(36), 1237, https://doi.org/10.21105/joss.01237.
- Ellis, Daniel P.W. “Chroma feature analysis and synthesis” 2007/04/21 https://www.ee.columbia.edu/~dpwe/resources/matlab/chroma-ansyn/
- Meinard Müller and Sebastian Ewert “Chroma Toolbox: MATLAB implementations for extracting variants of chroma-based audio features” In Proceedings of the International Conference on Music Information Retrieval (ISMIR), 2011.
- Zwillinger, D. and Kokoska, S. (2000). CRC Standard Probability and Statistics Tables and Formulae. Chapman & Hall: New York. 2000.
- D.I. Crecraft, S. Gergely, in Analog Electronics: Circuits, Systems and Signal Processing, 2002
- Goswami, T., & Sinha, G. R. (Eds.). (2022). Statistical modeling in machine learning. San Diego, CA: Academic Press.
- A. Graps, “An introduction to wavelets,” in IEEE Computational Science and Engineering, vol. 2, no. 2, pp. 50-61, Summer 1995, doi: 10.1109/99.388960.
- T. Guo, T. Zhang, E. Lim, M. López-Benítez, F. Ma and L. Yu, “A Review of Wavelet Analysis and Its Applications: Challenges and Opportunities,” in IEEE Access, vol. 10, pp. 58869-58903, 2022, doi: 10.1109/ACCESS.2022.3179517.
- Mallat Stéphane, (2009). In A Wavelet Tour of Signal Processing (p. iv). doi:10.1016/b978-0-12-374370-1.00001-x
- Daubechies, I. Ten Lectures on Wavelets. CBMS-NSF Regional Conference Series in Applied Mathematics. Philadelphia, PA: Society for Industrial and Applied Mathematics, 1992.
- I. Meyer, Wavelets and operators. Vol.1. Cambridge University Press, 1995.
- Rabiner, Lawrence R., and Ronald W. Schafer. Theory and Applications of Digital Speech Processing. Upper Saddle River, NJ: Pearson, 2010.
- S. Umesh, L. Cohen and D. Nelson, “Fitting the Mel scale,” 1999 IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings. ICASSP99 (Cat. No.99CH36258), Phoenix, AZ, USA, 1999, pp. 217-220 vol.1, doi: 10.1109/ICASSP.1999.758101.

)




)

![[論文閱讀] 人工智能 + 軟件工程 | 告別冗余HTML與高算力消耗:EfficientUICoder如何破解UI2Code的token難題](http://pic.xiahunao.cn/[論文閱讀] 人工智能 + 軟件工程 | 告別冗余HTML與高算力消耗:EfficientUICoder如何破解UI2Code的token難題)




)
 返回什么類型?)



詳解)
