本論文研究了能否利用一個“凍結”的LLM,直接理解視覺信號(即圖片),而不用在多模態數據集上進行微調。核心思想是把圖片看作一種“語言實體”,把圖片轉換成一組離散詞匯,這些詞匯來自LLM自己的詞表。為此,作者提出了Vision-to-Language Tokenizer(V2T Tokenizer),通過編碼器-解碼器、LLM詞表和CLIP模型的結合,把圖像轉化成一種“外語”。這樣編碼后,LLM不僅能夠理解視覺內容,還能做圖像去噪和修復,而且完全不用微調(只用凍結的LLM)。
Abstract
問題:關注如何讓LLM直接理解視覺信號(如圖像),不依賴于多模態數據集的微調。方法核心:
- 將圖像看作語言實體,將圖像編碼為LLM詞表中的離散token(單詞)。
- 設計了Vision-to-Language Tokenizer(V2L Tokenizer):通過encoder-decoder架構、LLM詞表和CLIP模型將圖像翻譯成LLM可解釋token。
- 轉換后,凍結的LLM不僅能做圖像理解類任務,還能做圖像去噪和修復任務(自回歸生成),全程無需fine-tuning。
- 支持的任務包括分類、caption、VQA以及inpainting、outpainting、deblurring等去噪/修復任務。
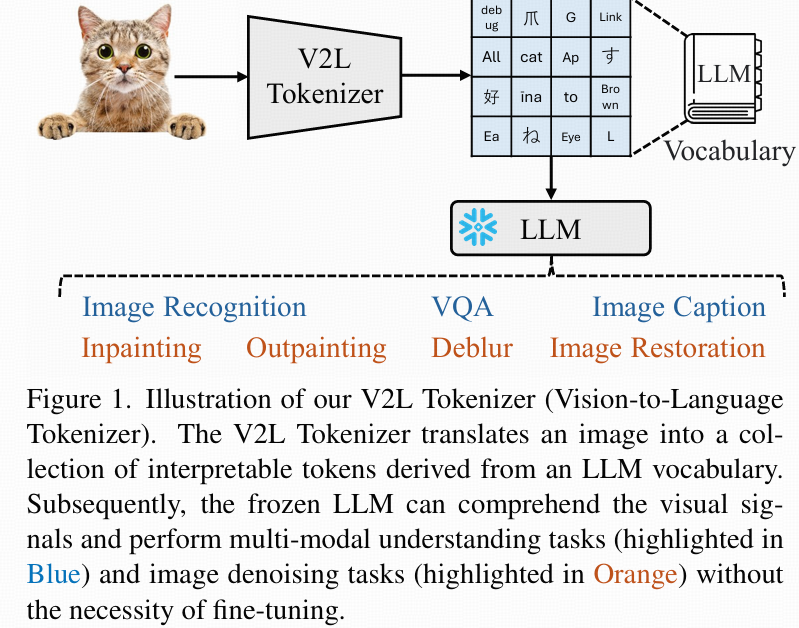
V2L Tokenizer的主要流程。把圖像轉成一組可解釋的token(詞元),這些token直接來自LLM的詞表。LLM凍結后,它通過這些token就能理解視覺信號,能執行多模態相關任務(藍色標記部分),也能做圖像去噪修復類任務(橙色標記部分),而無需微調。
Introduction
背景
當前多模態模型如GPT、PaLM、LLaMA正從單一NLP任務向視覺-語言任務擴展。一般做法是:在語言模型基礎上增加視覺模塊。然后通過多模態數據集聯合訓練(fine-tuning),使視覺和語言latent space對齊。
局限性
- 現有做法依賴大規模數據和計算資源。
- 多模態對齊通常在latent特征空間層面,訓練成本高。
本論文貢獻
- 在輸入token空間對齊視覺和語言信息(不是特征空間),避免了多模態訓練/微調。
- 操作流程:
- 通過V2L Tokenizer把圖像轉為LLM詞表內的離散token(用encoder-quantizer-decoder架構)。
- 凍結LLM可直接接收、處理這些token,實現視覺理解、生成和恢復等任務。
- 詞表擴展(bigrams/trigrams)方式提高了視覺到語言token的表達力。
- 用CLIP篩選最具語義信息的組合token作為最終codebook,加強與視覺內容的語義對齊。
- 采用in-context learning,無需LLM訓練,僅靠prompt即可做zero-shot視覺任務。
Method
3.1 Problem Formulation and Overview
- 圖像作為“外語”:設定LLM詞表為T={t1, t2, ..., tN}。目標是將圖像編碼為K個LLM詞表內的token(屬于T)。
- 實現:V2L Tokenizer將圖像編碼為Kg個全局token(語義類任務,如分類、caption、VQA等)和Kl個局部token(細節類任務,如denoising、patch level編輯等)。K總數=Kg+Kl。
- 使用:將(任務說明+in-context學習樣本+全局或局部token)一起輸入LLM,實現各種自回歸視覺任務。
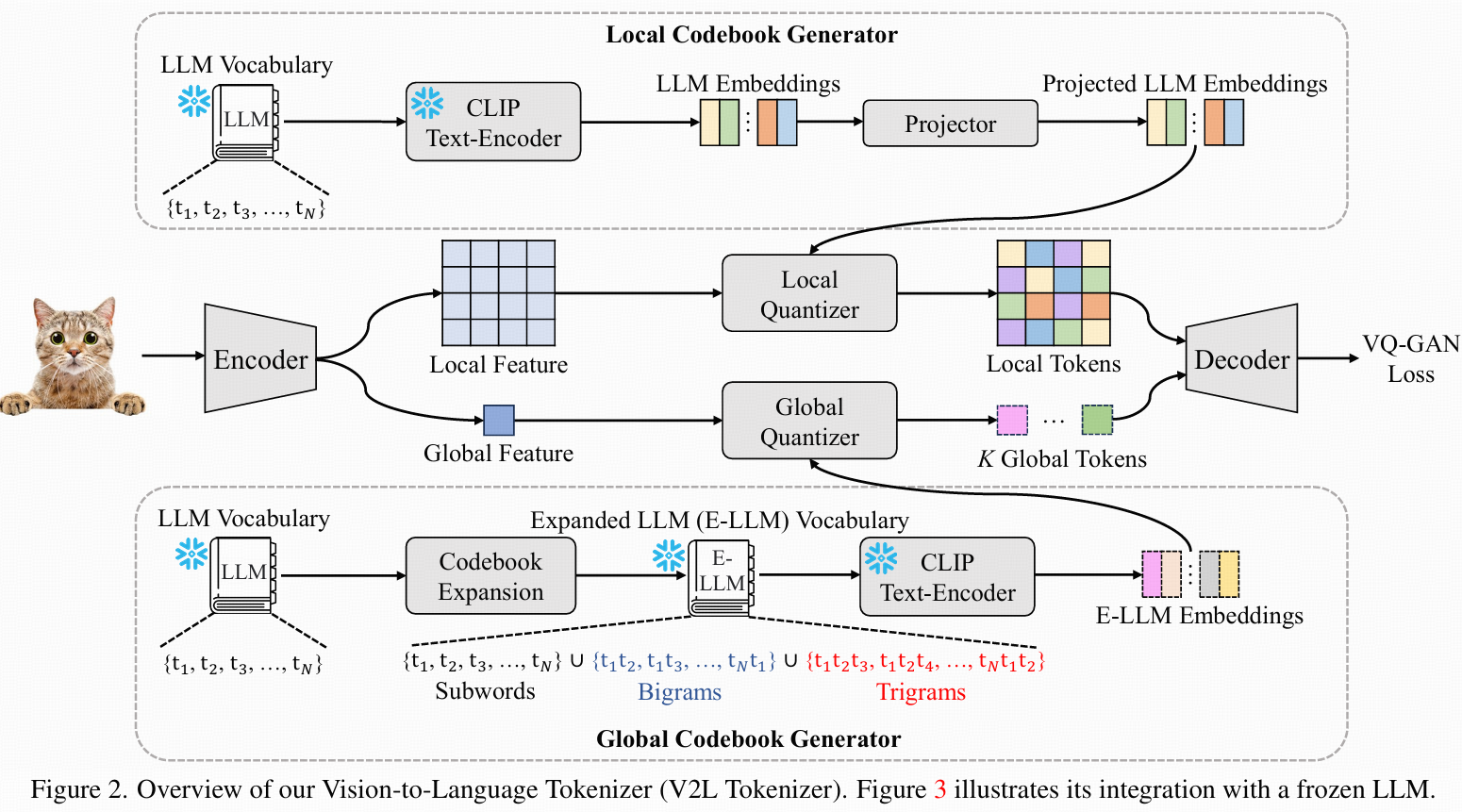
3.2 Vision-to-Language Tokenizer
整體架構
- 采用encoder-quantizer-decoder結構。
- 有兩個獨立量化器:全局量化器(對應全局codebook),局部量化器(對應局部codebook)。
Global Codebook
- LLM詞表為一組subword token(如BPE/SentencePiece)。
- 問題:單詞token通常語義有限。
- 策略:詞表擴展為bigrams/trigrams,提升語義表達力。但組合詞可能語義雜亂(如符號)。
- 解決:用CLIP計算每個圖片與所有擴展token的相似性,選top-5最相關token。聚合全圖片的top-5組合,形成最終全局codebook。
Local Codebook
- 用于局部patch編碼細節,直接用LLM原始詞表,無需擴展。
Embedding表示
- global/local codebook分別通過CLIP text-encoder轉化為embedding:LLM embedding(local)、E-LLM embedding(global)。
- 增設用戶可訓練的線性投影器,實現語義空間與視覺空間對齊。
Encoder
- 包括可訓練CNN encoder和凍結CLIP-vision-encoder。
- CNN encoder:類似VQ-GAN,提取local特征,空間downsample rate為8。
- CLIP-vision-encoder:提取global語義特征。
- 空間特征F∈Rh×w×dl,global特征f∈Rdg。
Quantizer
- local quantizer(patch級):對每個F(i,j),選距離最近的局部codebook embedding,獲得Kl個token。
- global quantizer:對global特征f,選最近的全局codebook embedding,獲得Kg個token。
- 兩類embedding全程凍結。
Decoder
- 基于VQ-GAN解碼器結構,stacked transposed卷積+自注意力層+cross-attention層(輸入f,空間信息F為query,f為key),實現全局信息對局部還原的輔助重建。
Loss
- 僅優化編碼器、解碼器、投影層。LLM/E-LLM embedding/vocab及CLIP模型全程凍結。
- 損失包括LVQ、感知損失LPerceptual和GAN損失LGAN,各權重λ1=1.0, λ2=0.1。
- 具體損失計算參考VQ-GAN。
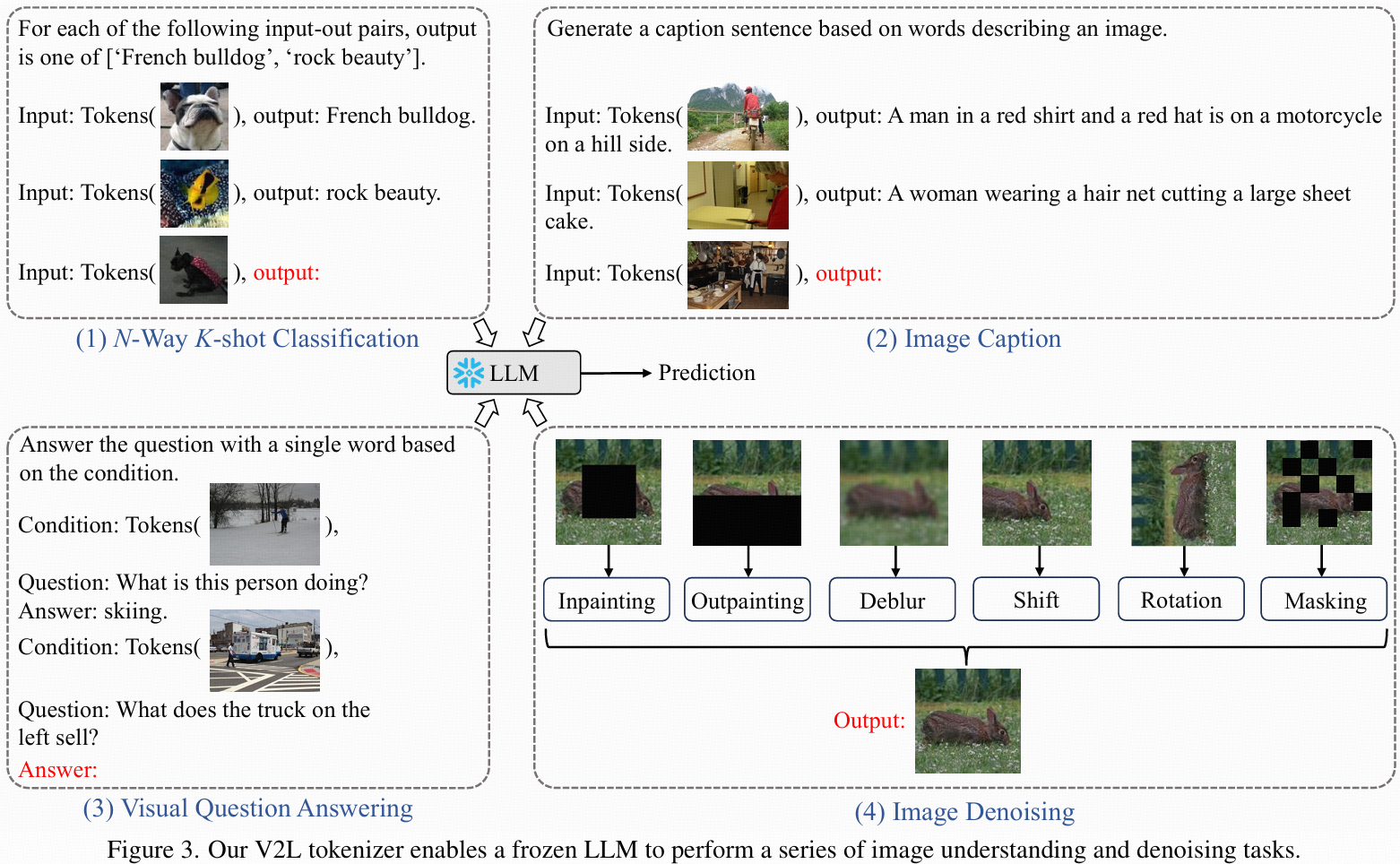
3.3 Visual Signal Comprehension
- 圖像處理后得到全局token Tg和局部token Tl(flatten后Kl=hw)。
- 結合任務prompt、樣例和token,一起輸入LLM即可實現多樣視覺任務。
- 具體任務prompt設計:
- N-way K-shot分類:[任務說明,樣例:“Input:Tg, output:類別”],最后輸入待測Tg,LLM輸出類別。
- Image Caption:[提示,樣例:“Input:Tg, output:caption”],測樣輸入Tg,LLM自回歸生成caption,遇到句號停止。
- VQA:[說明+樣例:“Condition:Tg. Question:Q. Answer:A”],測樣輸入Tg和問題,LLM輸出答案。
- Image Denoising:參考SPAE,補全、去模糊、outpainting等均設計相應prompt,輸入token與要求,輸出重構token。
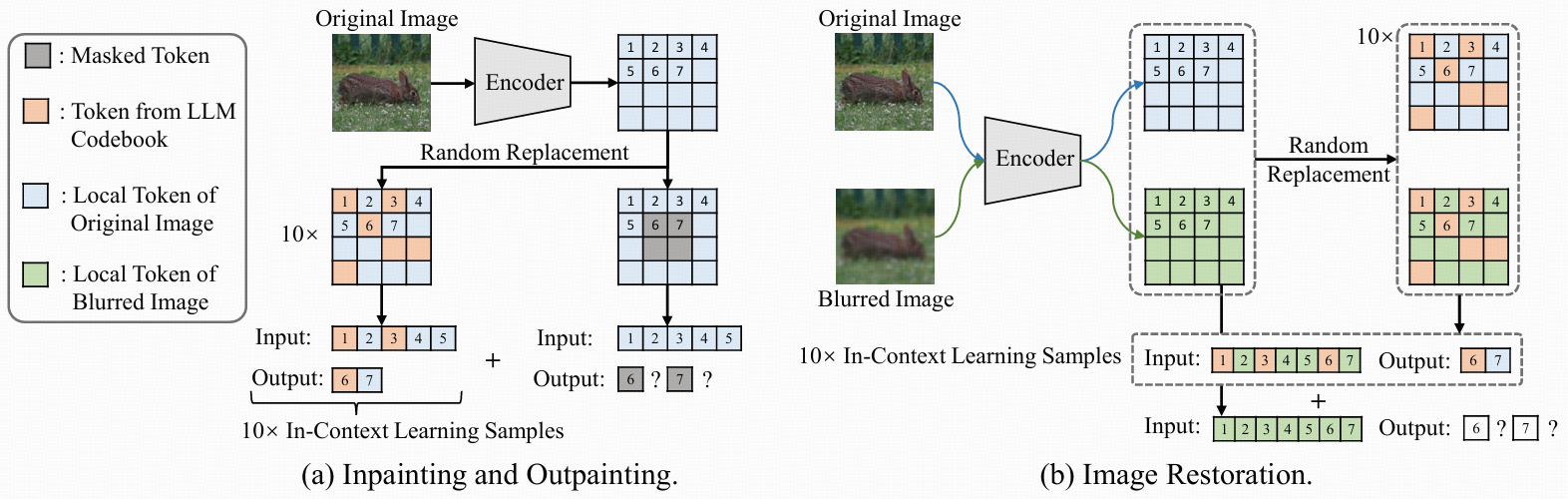
(a) Inpainting/Outpainting
提取local tokens:給定一張圖片,首先用V2L Tokenizer提取它的局部token(記為Tl),每個token對應圖片的一個小塊。
生成token變體
按照SPAE的做法,基于Tl生成10份變體(記為{T??}1????)。
每份變體都是把Tl里的部分token隨機換成LLM詞表里的其它token,形成不同程度“污染”的版本。
替換比例按 [23%, 50%; 3%]生成,從23%到50%之間每次遞增3%,形成不同難度的樣本。
應用掩碼
對于inpainting任務,在Tl的中心加一個8×8掩碼區域(即中間小塊都遮住,需要去恢復)。
對于outpainting,則在圖片底部加一個8×16掩碼區域(需要補全圖片下方)。
預測被遮蓋token
目標是一次預測m個被掩碼的token,利用它們前面的n個token信息。
Prompt結構為:[學習新語言,按示例推測后面的m個token。{Input: T??[n], output: T??[m]}1????. Input: Tl[n], output:]
意思是:有10個樣例,每個輸入是前n個token,輸出是接下來的m個token。
實際推理時,LLM先用n個未被掩碼token,連續生成m個被掩碼token;每次預測完成后,把新生成的token補上,繼續預測下一個m個,直到所有被遮蓋token都恢復出來。
拼接token還原圖片
最后把生成的token(恢復的掩碼區域)和剩下未被遮蓋的token一起拼成完整token map,然后送入解碼器還原圖片。
(b) Deblurring(去模糊)、Shift/Rotation Restoration
任務原理相似:Deblurring、Shift和Rotation恢復原理都類似,也是“輸入一部分token,預測剩下的token”。
prompt結構差別
prompt結構是:[學習新語言,按示例推測后面的m個token。{Input: T??[n + m], output: T??[m]}1????. Input: Tl[n + m], output:]
這里,輸入是n+m個token,預測的還是m個token。
T?是模糊/位移/旋轉過的圖片對應的token序列;T??表示經過隨機token替換后的版本。T??也對應原圖的random變體。
默認n=16, m=2,即每次輸入16+2個token預測2個目標token。
關鍵思路:用局部token表示圖片,把一部分設為掩碼/異常/模糊等狀態,然后通過預設“few-shot prompt”(即帶10個有答案的示例,樣例都經過隨機擾動),讓凍結的LLM逐步恢復被遮蓋或污染的token,再用解碼器還原整圖。
這樣就實現了不用微調,僅靠文本推理能力恢復(修補、補全、去模糊等)損壞圖片的效果。
4. Experiments?
4.1 Settings
- 采用了LLaMA2作為LLM,有三種參數規模版本,分別為7B(70億)、13B(130億)、70B(700億),詞表為32,000個詞元。
- 局部碼本(local codebook)用的是LLaMA2原始詞表,global codebook擴展并過濾后規模是11,908。
- CLIP模型用的是ViT-L/14結構。
- 圖片統一resize成128×128像素,然后用V2L Tokenizer編碼成16×16的token map。
- 訓練數據用的是ImageNet-1K,共訓練100個epoch,使用32張NVIDIA V100顯卡進行訓練。
- 優化器選Adam,初始學習率5e-4,前5個epoch線性升溫,然后采用半周期余弦衰減。
4.2 Image Comprehension
Few-Shot Classification(小樣本分類)
- 實驗在Mini-ImageNet的2-way和5-way分類基準上做圖像理解。
- 所有樣本和測試圖像都用V2L Tokenizer轉成Kg個global token。
- 按照3.3節和圖3設計prompt輸入LLM做分類預測,LLM輸出文本形式的類別(必須所有token跟類別名完全吻合才算正確)。
- 在表1比較了不同LLaMA2版本(7B/13B/70B)、以及同行的LQAE[25]、SPAE[54]、和另一個基線方法。
- 影響分類精度的因素有:(1)分類類別N、(2)每類樣本K、(3)任務描述、(4)few-shot樣本重復次數。
- 主要發現:①本方法在各種場景下都超過了SPAE(盡管用更小的LLM和更精簡的詞表);②代表圖片的token數量越多,性能越高,這是因為詞表擴展使得可選語義token更豐富。
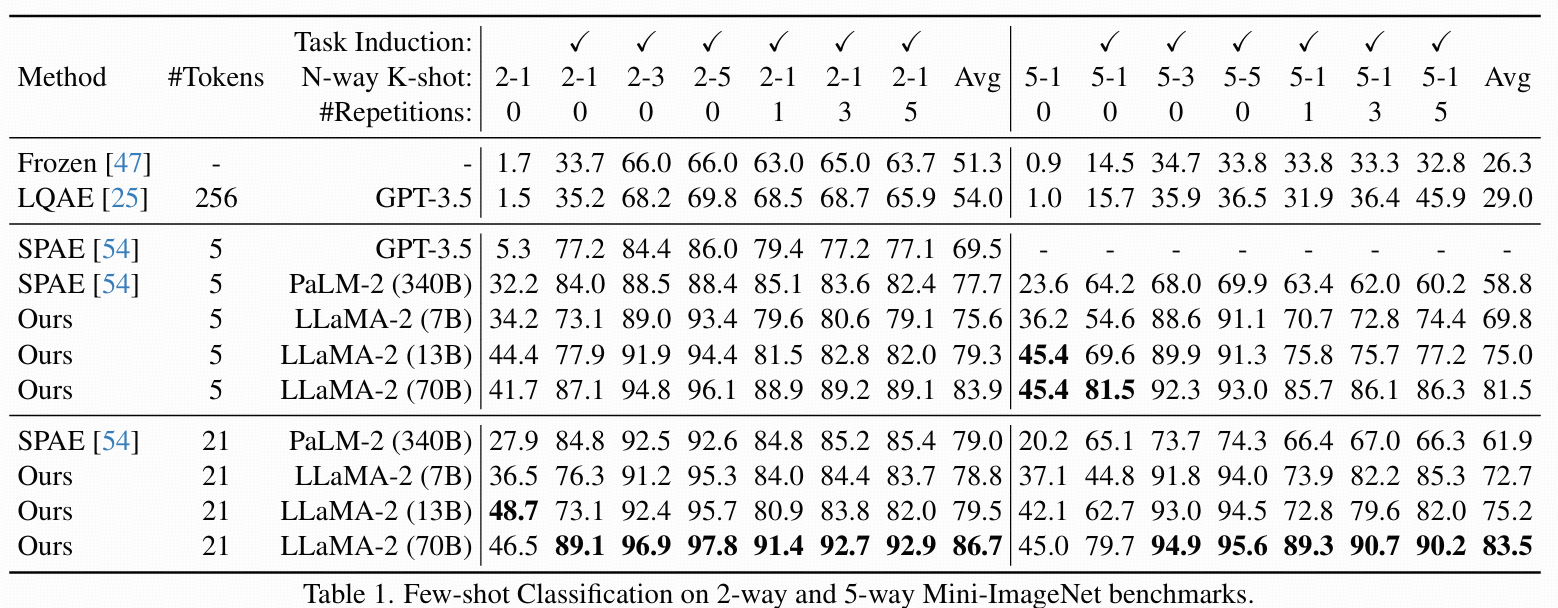
Image Caption & Visual Question Answering
- 按SPAE的流程,從COCO Caption和VQA數據集中隨機挑選10個樣本做in-context示例,默認每圖用21個global token表示。
- 圖5展示了一些可視化結果,還有更多結果在補充材料里。
Semantic Interpretation
- 圖6可視化了6張圖像各自得分最高的4個global token,可以看出詞表擴展明顯豐富了語義選擇空間(如bigrams、trigrams)。
- 表2則用CLIP分數和CLIP-R(相對分數)評價global token的語義質量,和SPAE對比,結果顯示本方法雖然詞表更小但語義質量更優。

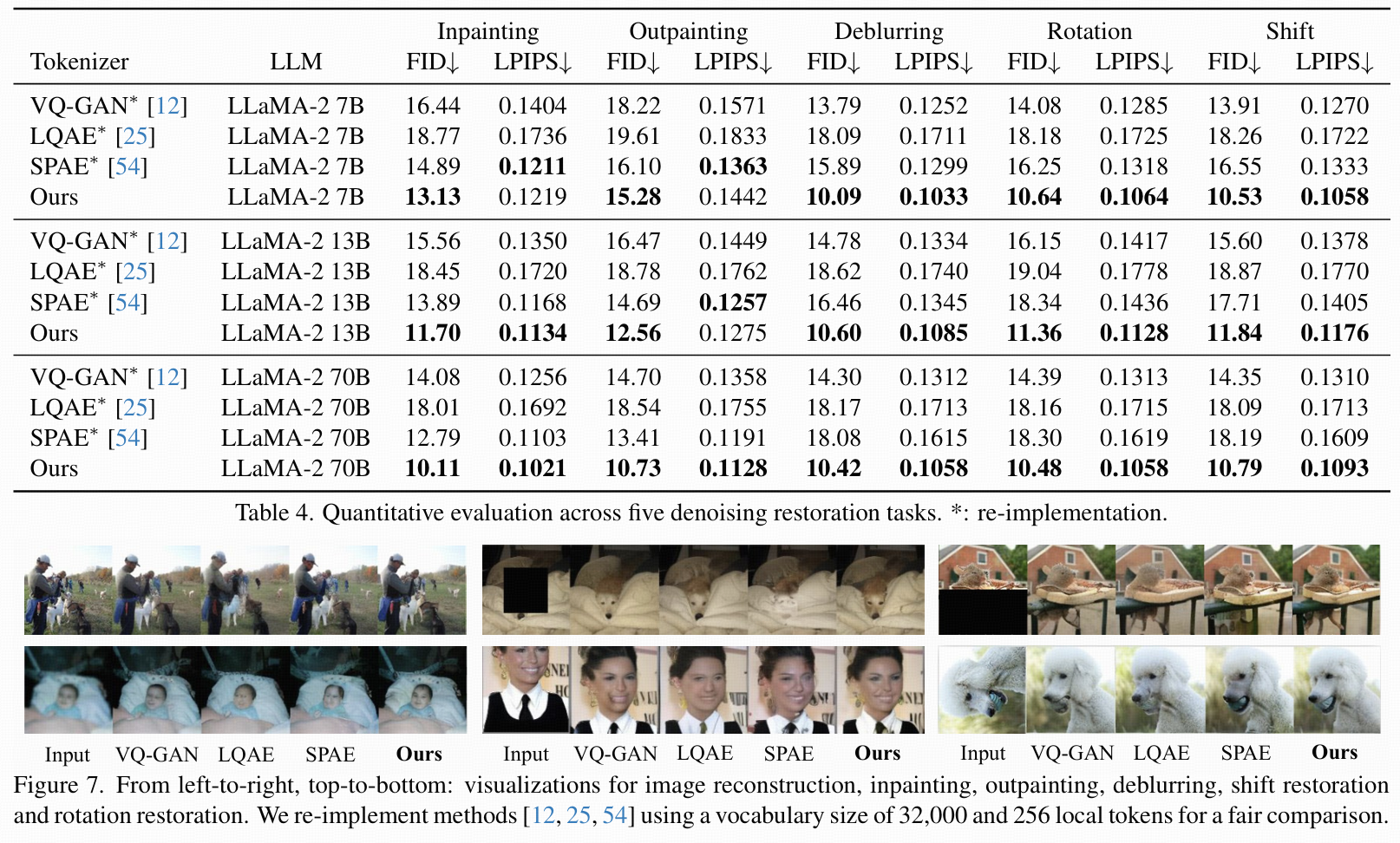
4.3 Image Reconstruction and Denoising
Reconstruction Evaluation(
- V2L Tokenizer把圖像編碼成LLM詞表上的local token,這些token要能充分表達圖像信息以便解碼器重建原圖或去除污染。
- 用FID、LPIPS、PSNR三種指標評估重建質量,結果見表3。
- 比較了兩種配置:①用VQ-GAN的解碼器不加global token;②用論文提出的帶global token解碼器(默認為section3.2配置)。
- 本方法在所有指標上都優于SPAE。
Image Denoising
- 介紹了prompt設置如何復原被污染(破壞)的圖片,包括修補、擴展、去模糊、位移、旋轉等任務,如圖4所示。
- 表4分析了兩大影響因素:①圖片tokenizer編碼能力;②LLM預測local tokens能力(以VQ-GAN、LQAE、SPAE為對比方法)。
- 隨機挑選5000張ImageNet驗證集圖片做評測,指標為FID和LPIPS。
- V2L Tokenizer在五類任務上幾乎所有指標都優于對比方法,主要原因是圖片特征能更好地和LLM token空間對齊。
Masked Image Restoration
- 在ImageNet驗證集圖片上,先用V2L Tokenizer獲取global和local token,然后隨機把30% local token做掩碼(遮蓋)。
- 用LoRA微調過的LLaMa-2 7B模型來預測這些掩碼token(具體微調方法見補充材料)。
- 把預測的token與未被掩碼的token聯合輸入解碼器進行重建,定性結果見圖8。
- 圖中“input”是把未掩碼token拼實際像素,掩碼部分設為0送入解碼器。
Conclusion
- 把圖片視作“外語”,提出了V2L Tokenizer,將連續視覺信號映射到LLM的token空間,使凍結的LLM也能不經多模態微調理解視覺信息。
- V2L Tokenizer能生成全局和局部token:全局token通過詞表擴展做語義表達,支持識別、描述和問答任務;局部token則用于提取圖片細節,實現去噪、修復等任務
)




)

![[論文閱讀] 人工智能 + 軟件工程 | 告別冗余HTML與高算力消耗:EfficientUICoder如何破解UI2Code的token難題](http://pic.xiahunao.cn/[論文閱讀] 人工智能 + 軟件工程 | 告別冗余HTML與高算力消耗:EfficientUICoder如何破解UI2Code的token難題)




)
 返回什么類型?)



詳解)

