文章目錄
前言
一、底層數據結構總覽
二、核心組成部分詳解
1. 數組(哈希表)
2. 節點(Node)
3. 紅黑樹(TreeNode)
三、哈希函數與索引計算
四、哈希沖突的解決
五、擴容機制
六、關鍵特性與注意事項
總結
前言
????????在 Java 開發中,HashMap 是高頻使用的集合類,從業務緩存到框架底層都離不開它,但多數開發者對其理解僅停留在 “鍵值對存儲”,對 “為何高效”“為何踩坑” 的底層邏輯一知半解。
????????面試中 “JDK1.7 與 1.8 的 HashMap 有何不同”“鏈表為何轉紅黑樹”,開發中 “擴容導致性能波動”“哈希沖突引發查詢變慢”,這些問題的答案,都藏在 HashMap 的底層設計里。它不是簡單的 “數組 + 鏈表”,而是融合哈希算法、動態擴容、紅黑樹的復雜體系,每處細節都是 “時間與空間的權衡”。
????????本文將拆解 HashMap 的核心設計:從結構演進(數組 + 鏈表→數組 + 鏈表 + 紅黑樹),到哈希沖突解決、擴容邏輯、紅黑樹轉換,再到 key 的規范細節。無論你是新手還是資深工程師,都能理清設計邏輯,既應對面試考點,也能在開發中合理調優,寫出更高效的代碼。接下來,我們從 HashMap 的底層結構開始,逐層剖析。
HashMap 是 Java 集合框架中常用的實現類(實現?Map?接口),用于存儲鍵值對(key-value)數據,其核心特點是查詢、插入、刪除效率高(平均時間復雜度為 O (1)),底層通過數組 + 鏈表 + 紅黑樹的復合數據結構實現,這種設計是為了平衡哈希沖突帶來的性能問題。
一、底層數據結構總覽
HashMap 在 JDK 1.8 中進行了重大優化,核心差異如下:
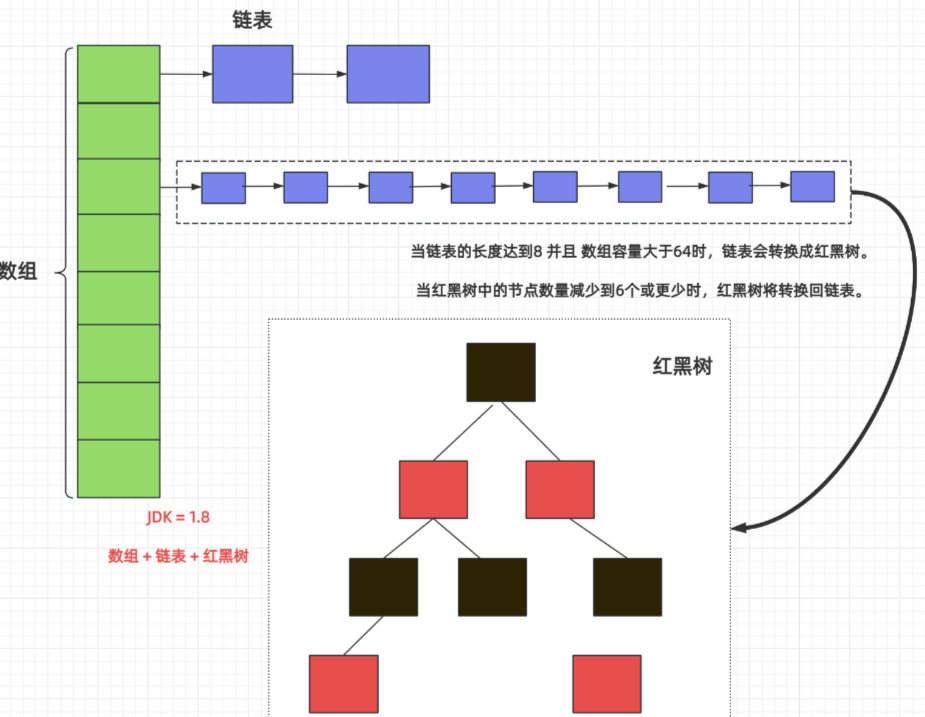
JDK 1.8 及之后,HashMap 的底層結構由三部分組成:
| 特性 | JDK 1.7 | JDK 1.8 |
|---|---|---|
| 底層結構 | 數組 + 鏈表 | 數組 + 鏈表 + 紅黑樹 |
| 鏈表插入方式 | 頭插法(新節點插入鏈表頭部) | 尾插法(新節點插入鏈表尾部) |
| 擴容時的 rehash | 需要重新計算所有節點的索引 | 利用高位判斷,減少計算量 |
| 沖突處理效率 | 鏈表查詢時間復雜度 O (n) | 紅黑樹查詢時間復雜度 O (log n) |
| 關鍵常量 | 無紅黑樹相關閾值 | 引入樹化閾值(8)、鏈化閾值(6) |
- 數組(核心容器):稱為「哈希表」或「桶(Bucket)」,是 HashMap 的主體,數組中的每個元素是一個「節點」(Node)。
- 鏈表:當哈希沖突時,相同索引位置的節點會以鏈表形式存儲。
- 紅黑樹:當鏈表長度超過閾值(默認 8)且數組長度 ≥ 64 時,鏈表會轉為紅黑樹,以優化查詢效率(紅黑樹查詢時間復雜度為 O (log n),優于鏈表的 O (n))。
結構示意圖如下:
數組索引: 0 1 2 3 ... n-1| | | |v v v v
節點: Node Node Node -> Node -> ... Node|vTreeNode (紅黑樹節點)
二、核心組成部分詳解
1. 數組(哈希表)
- 作用:作為底層容器,直接存儲節點(Node),數組的長度稱為「容量(Capacity)」。
- 容量特性:默認初始容量為 16,且始終保持為 2 的冪次方(如 16、32、64...)。這是為了通過「與運算」高效計算索引(替代取模運算),同時保證哈希值分布更均勻。
- 索引計算:數組索引由 key 的哈希值通過計算得到,公式簡化為:
index = (n - 1) & hash(n 為數組長度,hash 為 key 的哈希值經過擾動處理后的值)。
2. 節點(Node)
數組中的元素是?Node?對象,實現?Map.Entry?接口,包含四個核心字段:
static class Node<K,V> implements Map.Entry<K,V> {final int hash; // key 的哈希值(經過擾動處理)final K key; // 鍵(不可變)V value; // 值(可變)Node<K,V> next; // 下一個節點的引用(用于鏈表)
}
hash:用于定位節點在數組中的索引。next:當發生哈希沖突時,通過該字段形成鏈表(指向同索引下的下一個節點)。
3. 紅黑樹(TreeNode)
當鏈表長度超過閾值(默認 8)且數組長度 ≥ 64 時,鏈表會轉為紅黑樹(TreeNode?繼承?Node),以優化查詢性能。TreeNode?額外包含紅黑樹的核心字段:
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {TreeNode<K,V> parent; // 父節點TreeNode<K,V> left; // 左子節點TreeNode<K,V> right; // 右子節點TreeNode<K,V> prev; // 前一個節點(用于回退為鏈表)boolean red; // 節點顏色(紅/黑)
}
- 紅黑樹是一種自平衡二叉搜索樹,通過保持「黑色平衡」確保樹的高度穩定(約為 log n),避免鏈表過長導致的查詢效率下降。
- 當紅黑樹節點數減少到 6 時,會重新轉為鏈表(平衡查詢和插入效率)。
三、哈希函數與索引計算
HashMap 通過哈希函數將 key 映射到數組索引,核心目的是讓 key 均勻分布在數組中,減少哈希沖突。步驟如下:
-
計算 key 的原始哈希值:調用?
key.hashCode(),得到一個 32 位整數(不同 key 可能返回相同值,即「哈希碰撞」)。 -
擾動處理(哈希值優化):對原始哈希值進行二次處理,讓高位參與運算,減少碰撞概率。
JDK 1.8 中的實現:
?static final int hash(Object key) {int h;// 若 key 為 null,哈希值為 0;否則,將 hashCode 的高 16 位與低 16 位異或return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }作用:將高位信息融入低位,避免因數組長度較小時,高位無法參與索引計算導致的分布不均。
-
計算數組索引:用處理后的哈希值與「數組長度 - 1」進行「與運算」:
?index = (n - 1) & hash; // n 為數組容量(2的冪次方)由于 n 是 2 的冪次方,
n - 1?的二進制為「全 1」(如 15 是 1111),與運算等價于「取模運算」,但效率更高。
四、哈希沖突的解決
哈希沖突指不同 key 經過計算得到相同的數組索引。HashMap 采用鏈地址法(拉鏈法)?解決:
- 當沖突發生時,新節點會被添加到該索引位置的鏈表尾部(JDK 1.8 后)。
- 若鏈表長度超過閾值(默認 8)且數組長度 ≥ 64,鏈表轉為紅黑樹;若數組長度 < 64,則先觸發擴容(而非轉樹),避免數組較小時頻繁樹化。
五、擴容機制
當 HashMap 中的元素數量(size)超過「閾值(threshold)」時,會觸發擴容(resize),以減少哈希沖突。
-
閾值計算:
threshold = 容量(n) × 負載因子(loadFactor)。- 負載因子默認 0.75(JDK 設計的平衡值:既避免空間浪費,又減少沖突)。
- 例:初始容量 16,閾值 = 16 × 0.75 = 12,當元素數 > 12 時觸發擴容。
-
擴容過程:
- 新容量 = 原容量 × 2(始終保持 2 的冪次方)。
- 重新計算閾值(新容量 × 負載因子)。
- 重建哈希表:將原數組中的所有節點重新計算索引,遷移到新數組中(此過程稱為 rehash)。
- JDK 1.8 優化:rehash 時,節點新索引要么是原索引,要么是原索引 + 原容量(無需重新計算哈希值,僅通過判斷高位即可),減少計算開銷。
六、關鍵特性與注意事項
- 無序性:節點存儲位置由哈希值決定,遍歷順序與插入順序無關(如需有序,可使用?
LinkedHashMap)。 - 線程不安全:多線程環境下可能出現死循環(擴容時)或數據不一致,需使用?
ConcurrentHashMap?替代。 - key 特性:
- 允許 key 為 null(僅允許一個,索引固定為 0)。
- key 需重寫?
hashCode()?和?equals()?方法(否則可能導致無法正確查詢、刪除元素)。
- 性能影響因素:容量、負載因子、哈希函數的優劣直接影響沖突率,進而影響性能。
七、key 的 hashCode () 和 equals () 規范
HashMap 對 key 的兩個方法有嚴格要求,否則會導致數據異常(如無法查詢到已插入的元素):
-
equals () 相等的對象,hashCode () 必須相等
若?a.equals(b) == true,則?a.hashCode() == b.hashCode()?必須成立。否則會導致兩個相等的 key 被映射到不同索引,無法正確查詢。 -
hashCode () 相等的對象,equals () 可以不相等
這會導致哈希沖突,此時通過 equals () 區分節點(遍歷鏈表 / 紅黑樹時,需用 equals () 比較 key 是否真正相等)。 -
最佳實踐
重寫 hashCode () 時,應結合對象的關鍵屬性,且保證:- 屬性不變時,hashCode () 返回值不變。
- 盡量讓不同對象的 hashCode () 分布均勻(減少沖突)。
總結
????????HashMap 是「數組 + 鏈表 + 紅黑樹」的復合結構,通過哈希函數定位元素,鏈地址法解決沖突,擴容機制平衡空間與性能,最終實現高效的 key-value 存儲與訪問。其設計體現了時間復雜度與空間復雜度的權衡,是 Java 中最常用的集合類之一。


![基于ssm的小橘子出行客戶體驗評價系統[SSM]-計算機畢業設計源碼+LW文檔](http://pic.xiahunao.cn/基于ssm的小橘子出行客戶體驗評價系統[SSM]-計算機畢業設計源碼+LW文檔)

算法——形象化講解)

:是否有市場空間?)




與源碼)



)

)

