🔥從 GPT 到 LLaMA:解密 LLM 的核心架構——Decoder-Only 模型
“為什么所有大模型(LLM)都長一個樣?”
因為它們都有一個共同的“基因”——Decoder-Only 架構。
在前面兩節中,我們學習了:
- BERT:Encoder-Only,擅長“理解語言”
- T5:Encoder-Decoder,統一“理解+生成”
而今天,我們要進入真正引爆 AI 浪潮的主角世界——
🚀 Decoder-Only 模型,也就是當前所有大語言模型(LLM)的“母體”。
從 GPT-1 到 ChatGPT,從 LLaMA 到 GLM,它們雖然名字不同,但都基于同一個核心架構:僅由 Decoder 堆疊而成的 Transformer。
本文將帶你深入理解:
- Decoder-Only 是什么?
- GPT 系列如何一步步引爆 LLM 時代?
- LLaMA 和 GLM 又做了哪些關鍵改進?
準備好了嗎?我們出發!
🧬 一、什么是 Decoder-Only 架構?
在原始 Transformer 中,Decoder 本是用于“生成目標語言”的部分,它包含兩個注意力機制:
- Masked Self-Attention:只能看到前面的 token(防止“偷看答案”)
- Encoder-Decoder Attention:接收 Encoder 的語義信息
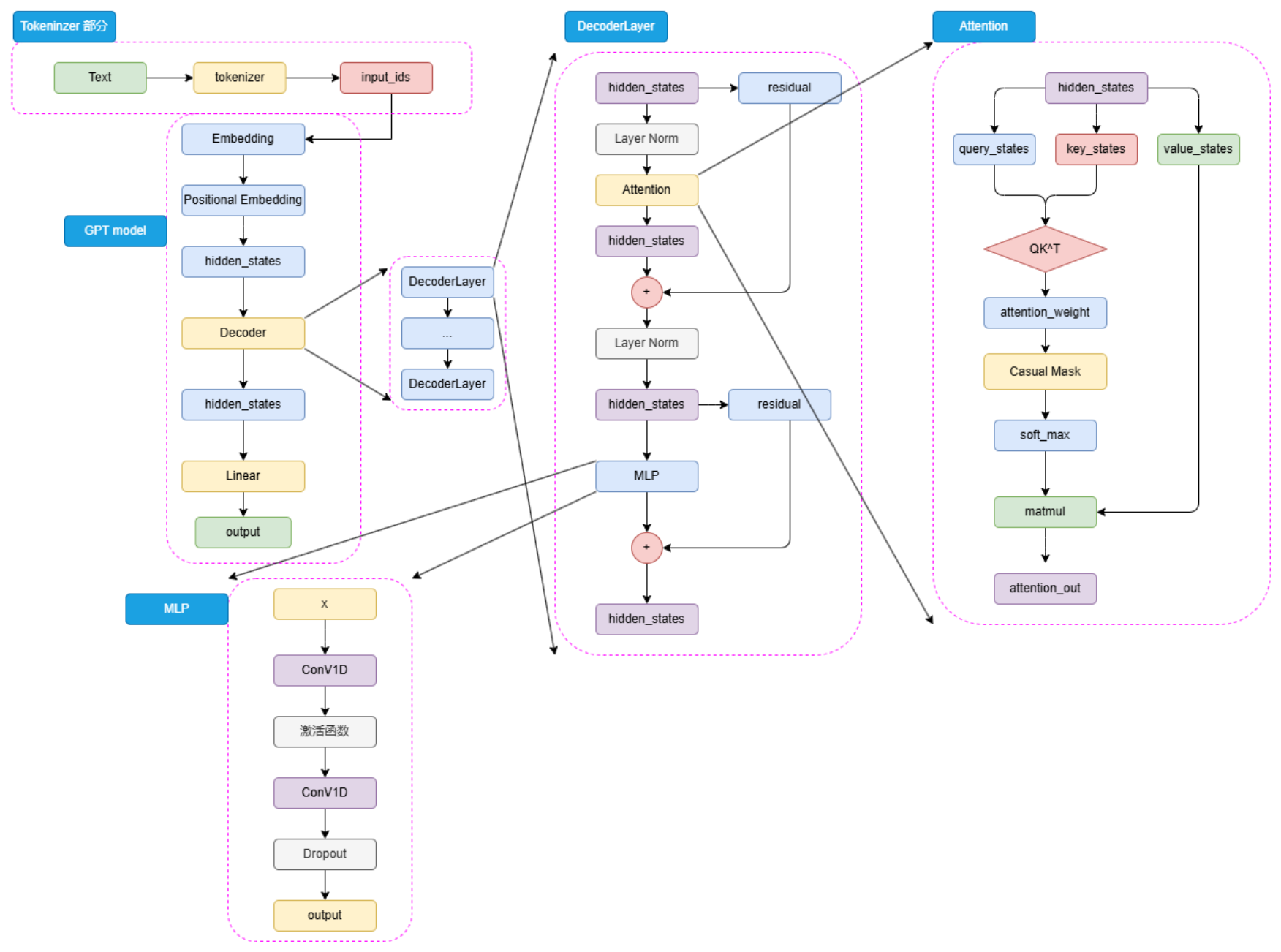
上圖為Decoder-Only 模型的模型架構圖,Decoder-Only 模型(如 GPT)做了一個大膽的決定:
? 去掉 Encoder
? 去掉 Encoder-Decoder Attention
? 只保留 Masked Self-Attention,自己理解、自己生成
輸入文本 → Tokenizer → Embedding → N 層 Decoder → 輸出文本這種架構天生適合 自回歸生成(Autoregressive Generation):
- 輸入:“今天天氣”
- 模型預測:“好”
- 接著輸入:“今天天氣好”,預測下一個詞……
- 如此循環,生成完整句子。
? 優勢:簡單、高效、可無限生成文本
? 缺點:無法雙向理解(但大模型通過“體量”彌補了這一點)
🚀 二、GPT:Decoder-Only 的開山鼻祖
1. 模型架構:Pre-LN + Masked Self-Attention
GPT 的結構與 BERT 類似,但關鍵區別在于:
| 組件 | GPT 做法 |
|---|---|
| 位置編碼 | 使用 Transformer 原始的?Sinusoidal 編碼(非可學習) |
| LayerNorm | 采用?Pre-Norm:先歸一化再進注意力(更穩定) |
| 注意力機制 | 僅保留?Masked Self-Attention,無 Encoder 交互 |
| MLP 層 | 早期用卷積,后期改用全連接 |
🔍 Pre-Norm 是什么?
在殘差連接前做 LayerNorm,能有效緩解梯度消失,適合深層網絡。
2. 預訓練任務:CLM(因果語言模型)
GPT 使用 CLM(Causal Language Modeling),也就是:
根據前面的詞,預測下一個詞
例如:
- 輸入:
The cat sat on the - 輸出:
mat
這本質上是 N-gram 的神經網絡升級版,完全契合人類語言生成習慣。
? 優勢:
- 不需要標注數據,直接用文本訓練
- 與下游生成任務(如寫作、對話)完全一致
3. GPT 系列的“力大磚飛”之路
| 模型 | 參數量 | 隱藏層 | 層數 | 預訓練數據 | 關鍵突破 |
|---|---|---|---|---|---|
| GPT-1 | 0.12B | 768 | 12 | 5GB | 首提“預訓練+微調” |
| GPT-2 | 1.5B | 1600 | 48 | 40GB | 支持 zero-shot |
| GPT-3 | 175B | 12288 | 96 | 570GB | few-shot + 涌現能力 |
📌 GPT-3 的三大革命:
- 參數爆炸:1750億參數,首次展現“涌現能力”
- 上下文學習(In-context Learning):無需微調,只需給幾個例子(few-shot)就能學會新任務
- 稀疏注意力:應對長文本,提升訓練效率
💡 舉例:情感分類的 few-shot prompt
判斷情感:'這真是個絕佳機會' → 正向(1) 示例:'你太棒了' → 1;'太糟糕了' → 0;'好主意' → 1 問題:'這真是個絕佳機會' → ?
這種“提示即編程”的方式,直接催生了 Prompt Engineering 的興起。
🐫 三、LLaMA:開源 LLM 的標桿
如果說 GPT 是閉源王者,那 LLaMA 就是開源世界的“平民英雄”。
Meta 從 2023 年起陸續發布 LLaMA-1/2/3,成為當前開源 LLM 的事實標準架構。
1. 模型架構:GPT 的“優化版”
LLaMA 整體沿用 GPT 架構,但做了多項關鍵改進:
| 改進點 | 說明 |
|---|---|
| RoPE 位置編碼 | 旋轉式位置編碼,支持超長上下文(8K~32K) |
| RMSNorm | 替代 LayerNorm,訓練更穩定 |
| SwiGLU 激活函數 | 比 ReLU/GELU 更強的非線性能力 |
| GQA(分組查詢注意力) | 減少 KV Cache,提升推理速度 |
🔍 GQA 是什么?
將多個注意力頭共享 KV 向量,平衡 MQA(單KV)和 MHA(全KV)的性能與效率。
2. LLaMA 系列發展史
| 版本 | 參數 | 上下文 | 訓練數據 | 亮點 |
|---|---|---|---|---|
| LLaMA-1 | 7B~65B | 2K | 1T token | 開源,引爆社區 |
| LLaMA-2 | 7B~70B | 4K | 2T token | 支持對話微調 |
| LLaMA-3 | 8B~70B | 8K | 15T token | 128K詞表,接近GPT-4 |
? LLaMA-3 的 128K 詞表大幅提升多語言和代碼能力。
🇨🇳 四、GLM:中文 LLM 的獨特探索
由智譜 AI(Zhipu AI)開發的 GLM 系列,是中國最早開源的大模型之一。
1. 模型架構:Post-Norm + 簡潔設計
GLM 初期嘗試了一條不同于 GPT 的路徑:
| 特點 | 說明 |
|---|---|
| Post-Norm | 殘差連接后歸一化,增強魯棒性 |
| 單層輸出頭 | 減少參數,提升穩定性 |
| GELU 激活函數 | 平滑非線性,優于 ReLU |
?? 注意:主流模型多用 Pre-Norm,但 GLM 認為 Post-Norm 更穩定。
2. 預訓練任務:GLM(空白填充)
GLM 的核心創新是 GLM 預訓練任務——結合 MLM 和 CLM:
- 隨機遮蔽連續一段文本
- 模型需從上下文預測這段文本,并按順序生成其中每個 token
例如:
- 輸入:
I <MASK> because you <MASK> - 輸出:
love you?和?are a wonderful person
? 優勢:兼顧理解與生成
? 劣勢:訓練復雜,大模型時代被 CLM 取代
📌 現狀:從 ChatGLM2 起,GLM 系列也回歸 CLM + GPT 架構。
3. GLM 家族發展
| 模型 | 參數 | 上下文 | 關鍵能力 |
|---|---|---|---|
| ChatGLM-6B | 6B | 2K | 首個開源中文 LLM |
| ChatGLM2-6B | 6B | 32K | 支持長文本 |
| ChatGLM3-6B | 6B | 32K | 支持函數調用、代碼解釋器 |
| GLM-4 | 未開源 | 128K | 英文性能對標 GPT-4 |
| GLM-4-9B | 9B | 8K | 開源輕量版,支持工具調用 |
💡 ChatGLM3 開始支持 Agent 開發,可調用工具、執行代碼,邁向 AI 自主行動。
🆚 五、三大模型架構對比
| 模型 | 架構 | 預訓練任務 | 是否開源 | 代表能力 |
|---|---|---|---|---|
| GPT | Decoder-Only | CLM | ? 閉源 | 通用生成、few-shot |
| LLaMA | Decoder-Only | CLM | ? 開源 | 高效、可定制 |
| GLM | Decoder-Only | GLM → CLM | ? 開源 | 中文強、支持 Agent |
🌟 六、Decoder-Only 為何能統治 LLM 時代?
盡管 BERT 和 T5 在 NLU 任務上曾領先,但 Decoder-Only 最終勝出,原因如下:
-
生成即王道
大模型的核心價值是“對話”“寫作”“編程”,生成能力比理解更重要。 -
任務統一性
所有任務都可以轉化為“輸入提示 → 輸出答案”,無需復雜微調。 -
涌現能力(Emergent Ability)
當模型足夠大時,CLM 訓練的模型反而在理解任務上超越 BERT。 -
工程友好
架構簡單,易于分布式訓練和推理優化。
📣 結語:LLM 的未來,始于 Decoder-Only
從 GPT-1 的默默無聞,到 GPT-3 的橫空出世,再到 LLaMA 和 GLM 的開源繁榮,
Decoder-Only 架構 用十年時間證明了:
“簡單、專注、規模” 才是通向 AGI 的最短路徑。
如今,幾乎所有主流 LLM(包括 Qwen、Baichuan、Yi 等)都基于這一架構。
🔁 所以,要理解大模型,你必須先讀懂 GPT。
📚 參考資料:
- 《Language Models are Few-Shot Learners》(GPT-3)
- 《LLaMA: Open and Efficient Foundation Language Models》
- 《GLM: General Language Model Pretraining with Autoregressive Blank Infilling》
- HuggingFace、Meta AI、Zhipu AI 官方文檔
- https://github.com/datawhalechina/happy-llm
)
)
:構建自動化AI客服系統)










)

)
)
)
:神經元與神經網絡)
