在人工智能的浪潮中,神經網絡(Neural Networks)無疑是驅動核心技術的引擎,它賦予了計算機前所未有的學習和識別能力。而這一切的起點,是受到生物大腦中基本單元——神經元(Neurons)的深刻啟發。從一個微小的生物細胞到復雜的計算模型,神經元與神經網絡共同構成了人工智能的強大基石。
生物神經元:計算的原始模型
要理解人工神經網絡,我們必須首先回顧其生物學原型。人腦是一個由數十億個神經元組成的復雜網絡,這些神經元通過電化學信號相互交流。
一個典型的生物神經元主要由三部分構成:
- 樹突(Dendrites):像一棵樹的枝椏,負責接收來自其他神經元的輸入信號。
- 細胞體(Soma):神經元的核心部分,它整合所有樹突接收到的輸入信號。當這些信號的總和達到一個特定的閾值時,細胞體就會被“激活”。
- 軸突(Axon):一個長長的突起,當細胞體被激活后,它會沿著軸突向其他神經元傳遞一個輸出信號。
信號在神經元之間傳遞的連接點被稱為突觸(Synapses)。突觸的連接強度不是固定的,而是可塑的,會隨著學習和經驗而改變。這種并行處理和動態可塑性的特性,正是人腦能夠進行復雜認知、學習和記憶的根本原因。
人工神經元(感知機)
人工神經元,通常也稱為感知機(Perceptron),是對生物神經元功能的數學抽象和模擬。一個感知機的工作原理很簡單:
-
輸入(Inputs):接收來自外部或上一層神經元的多個輸入信號,x1,x2,…,xn。
-
權重(Weights):每個輸入都帶有一個權重,w1,w2,…,wn。這些權重就像生物突觸的連接強度,決定了每個輸入的重要性。
-
加權求和(Weighted Sum):將每個輸入與其對應的權重相乘,然后將所有結果相加。這個過程可以表示為:
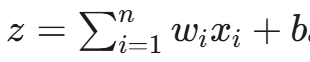
其中,b 是一個**偏置(bias)**項,可以理解為神經元更容易被激活的傾向。
-
激活函數(Activation Function):將加權求和的結果 z 輸入到一個非線性的函數中,得到最終的輸出。這個函數模仿了生物神經元的“激活”過程。早期的感知機使用簡單的階躍函數,而現代的神經網絡則常使用 ReLU(Rectified Linear Unit)或 Sigmoid 等函數,它們能讓網絡學習更復雜的模式。
感知機能夠解決簡單的線性分類問題,但其局限性在于無法處理非線性可分問題,例如著名的“異或”(XOR)問題。
從單個神經元到多層網絡:神經網絡的誕生
為了解決感知機的局限性,研究者開始將多個神經元組織成多層感知機(Multilayer Perceptron,MLP),這標志著現代神經網絡的誕生。一個典型的神經網絡通常由以下幾層組成:
- 輸入層(Input Layer):負責接收原始數據,例如一張圖片的像素值。
- 隱藏層(Hidden Layers):位于輸入層和輸出層之間,是網絡的“大腦”。它可以有一個或多個隱藏層,每一層都負責從上一層提取更高級、更抽象的特征。
- 輸出層(Output Layer):給出網絡的最終結果,例如預測的類別或數值。
當一個神經網絡擁有多個隱藏層時,我們稱之為深度神經網絡(Deep Neural Network)。深度學習(Deep Learning)正是指利用這類深度網絡進行學習和訓練的方法。
神經網絡的學習過程:反向傳播算法
神經網絡的“學習”過程,即通過數據自動調整權重以達到最優性能的過程,是一個核心難題。這個問題的解決,離不開**反向傳播(Backpropagation)**算法的發明。
訓練一個神經網絡通常包括以下幾個步驟:
- 前向傳播(Forward Propagation):輸入數據從輸入層開始,逐層向前傳遞,直到輸出層產生一個預測結果。
- 損失函數(Loss Function):用一個數學函數來衡量網絡的預測結果與真實標簽之間的差距。這個差距越大,損失值就越高。常見的損失函數包括均方誤差(Mean Squared Error)和交叉熵(Cross-Entropy)等。
- 反向傳播(Backpropagation):這是學習的核心。它利用梯度下降(Gradient Descent)的原理,從輸出層開始,將損失值逐層反向傳播到網絡中的每一個神經元。在傳播過程中,算法會計算出每個權重對總損失的貢獻,即梯度。
- 權重更新(Weight Update):根據反向傳播計算出的梯度,使用優化器(如 Adam、SGD 等)來微調網絡的權重。調整方向是朝著損失值減小的方向。
這個“前向傳播-計算損失-反向傳播-更新權重”的循環會重復成千上萬次,直到網絡在訓練數據上的表現達到預設的滿意水平。
神經網絡的類型與應用
隨著研究的深入,出現了多種適應不同任務的神經網絡架構,每一種都建立在基本的神經元和層結構之上:
- 卷積神經網絡(Convolutional Neural Network, CNN):特別適用于處理圖像、視頻等網格狀數據。它通過卷積層和池化層來自動提取圖像中的局部特征,并在計算機視覺領域取得了巨大成功。
- 循環神經網絡(Recurrent Neural Network, RNN):擅長處理序列數據,如文本、語音和時間序列。它的特點是神經元之間存在循環連接,使得網絡能夠記住之前的信息。
- 長短期記憶網絡(Long Short-Term Memory, LSTM):一種特殊的 RNN,通過“門”機制有效解決了傳統 RNN 的長期依賴問題,在自然語言處理中表現出色。
- 生成對抗網絡(Generative Adversarial Network, GAN):由兩個網絡(一個生成器和一個判別器)相互博弈,可以生成逼真的人臉、圖像等數據。
挑戰與展望
盡管神經網絡取得了非凡成就,但挑戰依然存在:
- 黑箱問題:深度神經網絡的決策過程通常難以解釋,我們很難理解模型為何做出某個預測。這在醫療診斷等高風險領域是一個嚴重問題。
- 數據依賴:神經網絡,尤其是深度學習模型,需要海量的高質量標注數據進行訓練,這在很多領域是昂貴且耗時的。
- 能耗問題:大型神經網絡模型的訓練和運行需要巨大的計算資源和電力。















![【LCA 樹上倍增】P9245 [藍橋杯 2023 省 B] 景區導游|普及+](http://pic.xiahunao.cn/【LCA 樹上倍增】P9245 [藍橋杯 2023 省 B] 景區導游|普及+)


:面向鏈接預測的知識圖譜表示學習方法綜述)
,規則(Rules))