近日,快手正式發布了多模態大語言模型Keye-VL-1.5-8B。
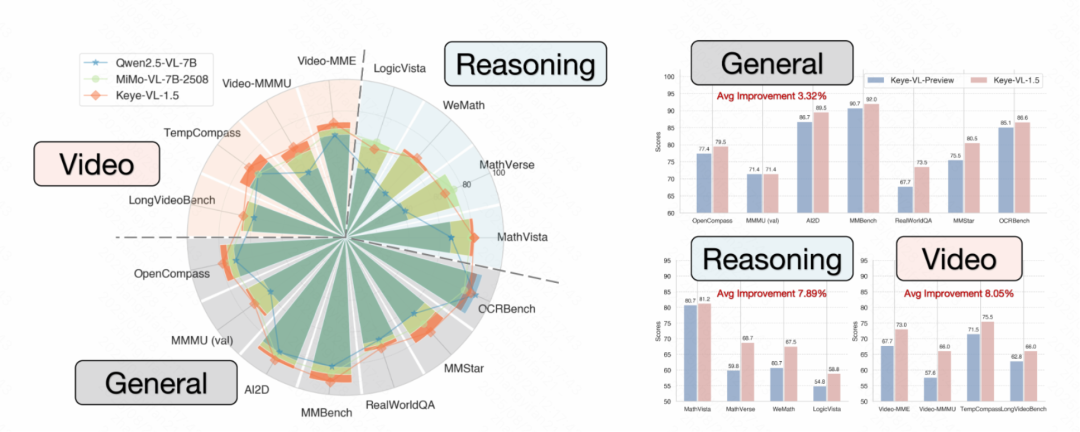
與之前的版本相比,Keye-VL-1.5的綜合性能實現顯著提升,尤其在基礎視覺理解能力方面,包括視覺元素識別、推理能力以及對時序信息的理—表現尤為突出。Keye-VL-1.5在同等規模的模型中表現出色,甚至超越了一些閉源模型如GPT-4o。
Keye-VL-1.5-8B在技術上實現了三項關鍵創新:
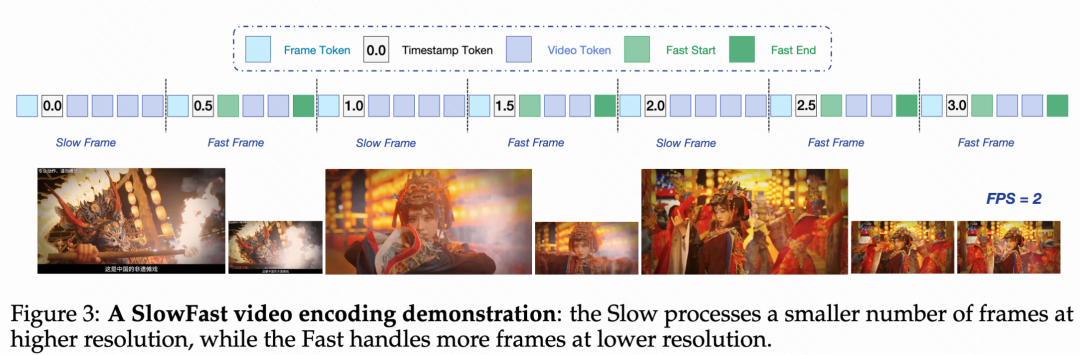
- 引入慢快編碼策略(Slow-Fast):該策略基于相似性算法自動區分慢幀與快幀,并將快幀的 token 預算控制為慢幀的 30%。同時,通過引入特殊 token 和時間戳標記幀邊界,有效平衡了性能與計算成本。
- 采用漸進式四階段預訓練方法:從跨模態對齊與多任務預訓練起步,在退火階段將模型上下文長度從 8K 擴展至 128K,使其能夠處理更長視頻和更復雜的視覺內容,大幅增強視頻理解能力。最終的模型融合階段通過使用不同數據混合訓練的模型進行組合,以提高魯棒性并減少偏差。
- 全面優化后訓練流程:提出五步自動化數據構造流水線,基于 GSPO 算法迭代通用強化學習與對齊階段,全面提升模型的推理能力并與人類偏好對齊。
在多個公開的視頻基準測試中,Keye-VL 1.5 8B在同等規模的模型中性能最優,并在MMMUval和AI2D等大規模基準測試中,Keye-VL 1.5 8B取得了業界最佳成績!
Keye-VL-1.5-8B現已開源,并公布了公開技術報告,歡迎各位開發者前往體驗和交流。
項目主頁:https://kwai-keye.github.io/
技術報告:https://arxiv.org/pdf/2509.01563
Github:https://github.com/Kwai-Keye/Keye
Model:https://huggingface.co/Kwai-Keye/Keye-VL-1.5-8B
先來看三個案例:
案例一:時序信息理解
demo1
Prompt:視頻中包出現的時間段是多少?
Keye:視頻中包出現的時間段是22.3秒至23.8秒。
案例二:推理能力
demo2
Prompt:視頻里大狗咬小狗的耳朵是為什么?
keye:視頻中,小狗試圖扒著桌子夠取食物,大狗(狗爸)通過輕咬小狗耳朵的行為,實則是在**糾正小狗的不當行為**。這種輕咬是狗群中常見的“教育”方式,成年狗會用它告訴幼崽“這樣做不對”,需遵守規則。當小狗收到這一信號后,便從站立夠食的狀態逐漸坐下來,最終躺下服從管理,說明大狗的行為成功傳遞了“不能偷食桌上食物”的警告。 \boxed{大狗咬小狗耳朵是糾正其試圖偷吃桌上食物的錯誤行為,通過輕咬傳遞警告讓小狗服從管理。}
案例三:描述能力
demo3
Prompt:請仔細描述視頻中的場景內容?
Keye:視頻的主要場景是一個被茂密森林環繞的潮濕角落,畫面中間是一條破損的老舊石階,石板的石板有裂,表面長滿綠色苔蘚和雜草,顯得斑駁滄桑。周圍是高大的深色樹木,樹枝上掛著鮮綠色的樹葉,樹葉間透出柔和的散射光,給場景增添了一層朦朧感。地面上散落著許多小白花或菌類,與綠色苔蘚交織,形成生機盎然的地面覆蓋。背景中森林延伸至遠方,樹木逐漸模糊,展示出場景的深度與神秘感。空氣中似乎帶著細密的雨霧,地面和石階都顯得潮濕,偶爾有雨滴落下,進一步強化了潮濕的氣氛。整體色調綠色和棕色為主,呈現出一種靜謐。自然且略帶荒涼的原始森林景象。
「核心技術架構全公開」
Keye-VL-1.5采用經典的多模態大語言模型架構,由三個核心組件構成:視覺Transformer(ViT)、MLP投影器和語言解碼器。該模型使用SigLIP-400M-384-14作為視覺編碼器,Qwen3-8B作為語言解碼器。在Vision encoder方面,采取了原生分辨率ViT,2D ROPE增強高分圖像理解,使用了500B Token的多源數據進行預訓練。在視覺特征處理方面,針對不同視覺輸入采用差異化編碼策略。對于圖像,每張圖像使用20,480個token來保證細節捕獲。
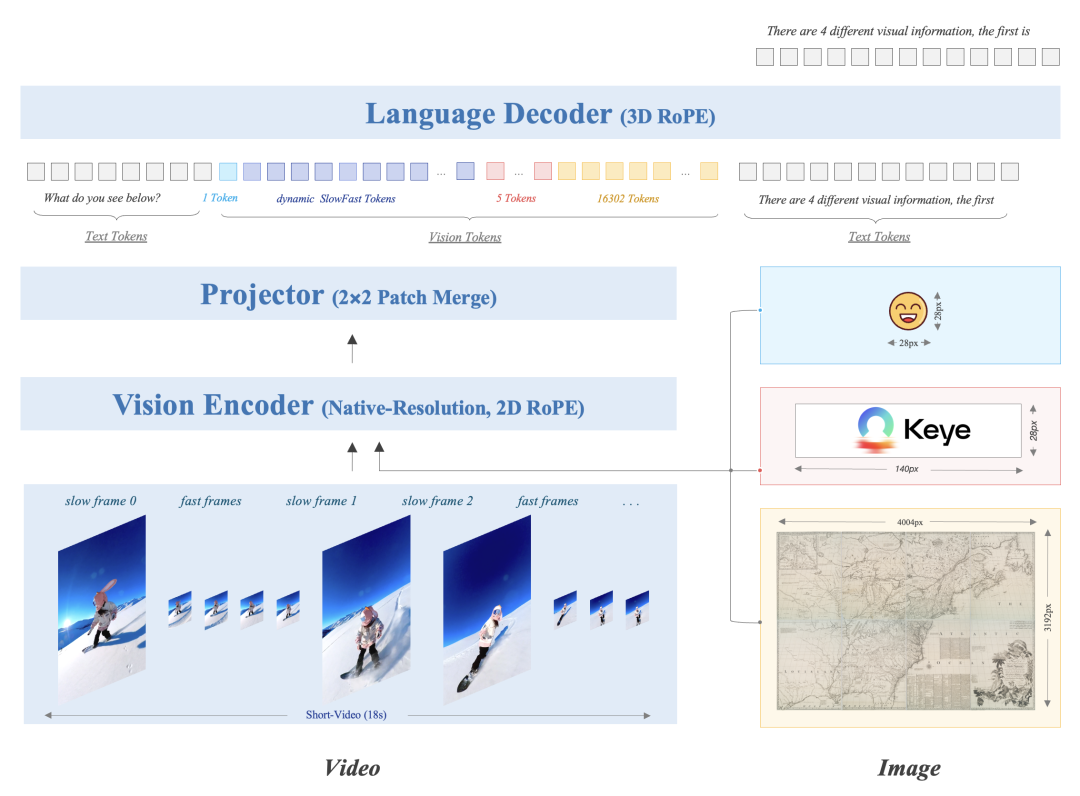
一、慢快編碼策略:兼顧性能與成本
視頻內容通常包含兩種類型的畫面:一種是快速變化、富含細節的畫面(如運動場景),另一種是相對靜態的畫面(如靜止風景)。為了在短視頻理解任務中同時實現高準確性與高效率。Keye-VL-1.5 創新性地提出了慢快編碼策略 (slow-fast),該策略設置慢通路處理快速變化幀(低幀數-高分辨率),快通路處理靜態幀(高幀數-低分辨率),從而在節省計算資源的同時保留關鍵信息。
具體來說,通過基于圖片相似性的算法自動識別慢快幀,快幀的token預算設為慢幀的30%,并引入特殊token和時間戳來標識幀邊界,實現了性能與計算成本的有效平衡。
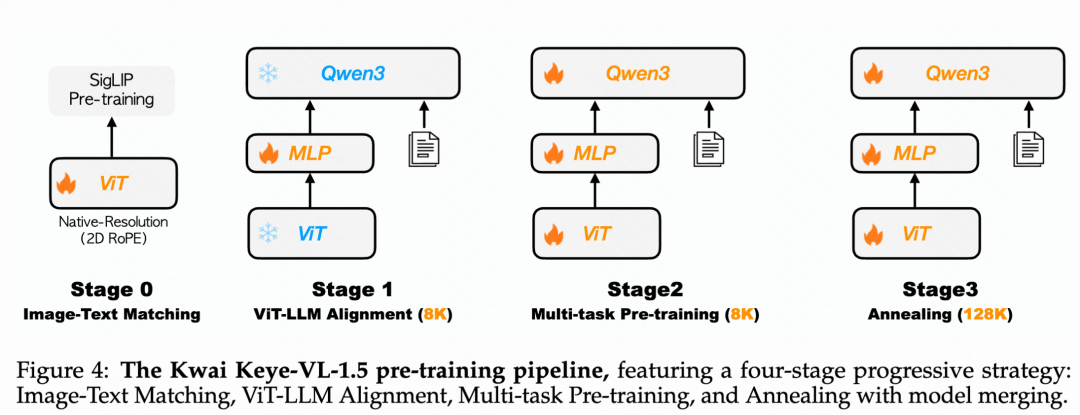
二、Pretrain 策略:漸進式四階段預訓練方法
Keye-VL-1.5采用精心設計的四階段漸進式訓練流水線,確保每個階段都有清晰且相互關聯的目標。
視覺編碼器預訓練:使用SigLIP-400M權重初始化ViT,通過SigLIP對比損失函數進行持續預訓練,適應內部數據分布。
第一階段 - 跨模態對齊:專注優化投影MLP層,建立跨模態特征的穩固對齊基礎。
第二階段 - 多任務預訓練:解凍所有模型參數進行端到端優化,顯著增強模型的基礎視覺理解能力。
第三階段 - 退火訓練:在精選高質量數據上進行微調,解決第二階段大規模訓練中高質量樣本接觸不足的問題。同時將序列長度從8K擴展至128K,RoPE逆頻率從100萬重置為800萬,并引入長視頻、長文本和大尺度圖像等長上下文模態數據。
模型融合:為減少固定數據比例帶來的內在偏差,在預訓練最終階段采用同質-異質融合技術,對不同數據混合比例下退火訓練的模型權重進行平均,保持多樣化能力的同時減少整體偏差,增強模型魯棒性。
三、Post-training策略:全面提升推理能力與人類偏好對齊
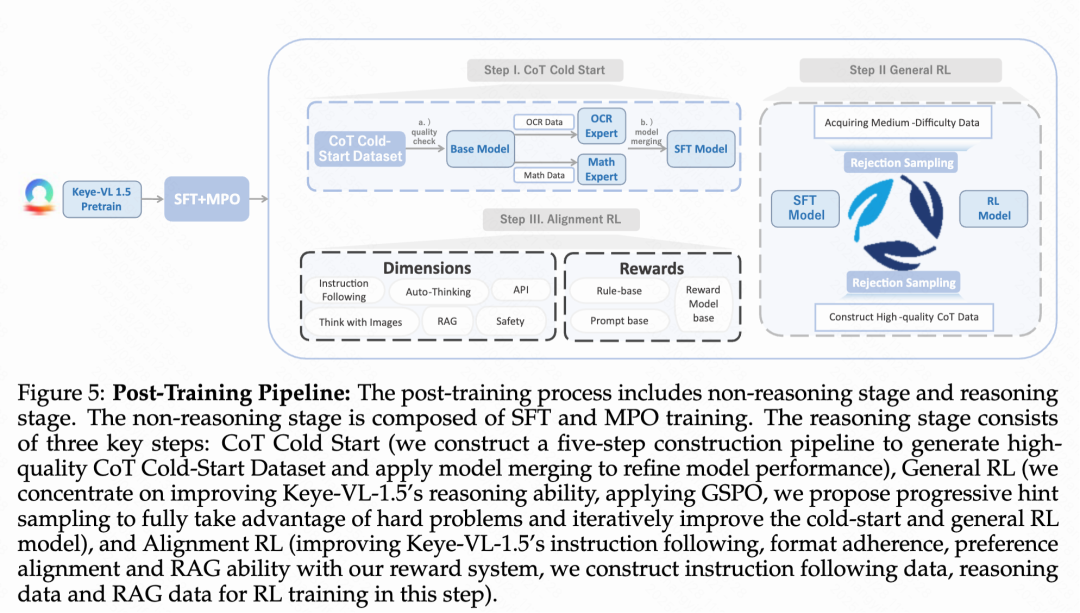
Keye-VL-1.5的訓練后處理包含四個主要階段:
Stage 1:監督微調與多偏好優化
使用750萬個多模態問答樣本進行監督微調,然后通過MPO算法進一步提升性能。
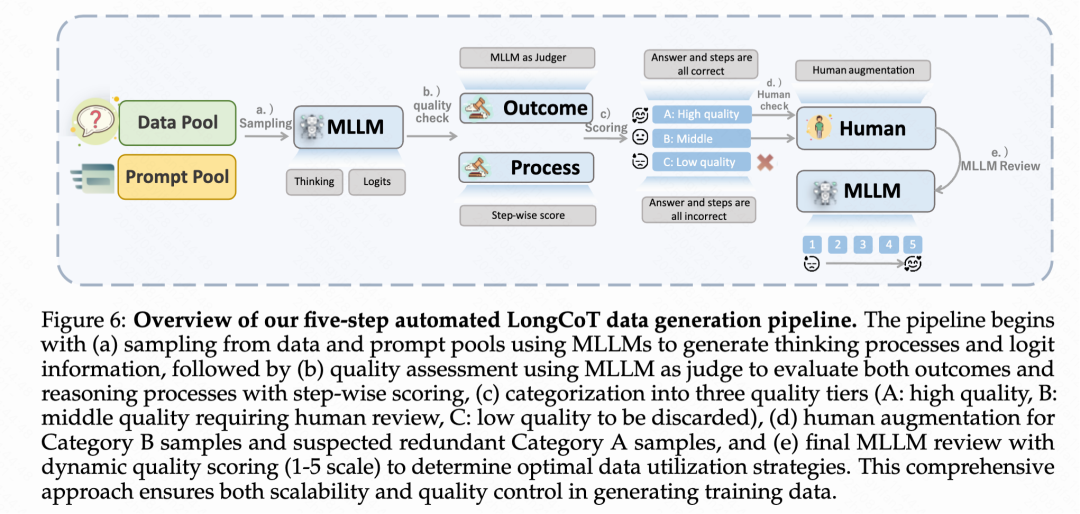
Stage 2:長鏈思考冷啟動
為了獲取高質量的冷啟動訓練數據,Keye-VL-1.5提出了一個全面的五步自動化流水線來生成高質量長鏈思考數據。首先從多個挑戰性領域收集多模態問答數據,并使用專有模型進行問題重寫和任務合并以增加復雜性;然后為每個問答對生成多個推理軌跡并量化模型置信度;接著實施雙層質量評估框架,同時評估答案正確性和推理過程有效性,將樣本分為高質量(A類)、中等質量(B類)和低質量(C類)三個等級;對于B類樣本和部分A類樣本,采用人工指導的改進過程來提升推理質量;最后實施五點質量評分系統和自適應數據利用策略,讓高質量樣本在訓練中被更頻繁使用。
Stage 3:迭代通用強化學習
使用GSPO算法進行可驗證獎勵強化學習訓練,采用漸進提示采樣處理困難樣本(對于模型多次rollout都回答不對的樣本,在prompt中給予不同程度的提示),通過多輪迭代持續優化模型推理能力。這個階段和long cot sft迭代進行,使用RL模型 rollout更好的response(reward model 打分)進行SFT,然后使用SFT模型進行下一階段的RL數據篩選與訓練。
Stage 4:對齊強化學習
重點增強模型在指令遵循(生成滿足用戶內容、格式、長度要求的回應),instruction following(確保回應符合預定義格式如思考-回答等模式)和偏好對齊(提高開放式問題回應的可靠性和交互性)三個維度的能力。
四、實驗效果
Keye-VL在多模態AI領域取得突破性進展
在通用視覺語言任務中,該模型在思考模式下于MMMUval和OpenCompass等大規模基準測試中分別獲得71.4%和79.5%的同等scale的業界最佳成績,在ZeroBenchsub和MMVP等挑戰性測試中同樣表現卓越,并在HallusionBench中實現62.7%準確率,顯著降低AI幻覺現象。在視頻理解領域,Keye-VL表現更佳,在Video-MMMU測試中達到了66分,充分證明了其在視頻內容理解方面的技術優勢。
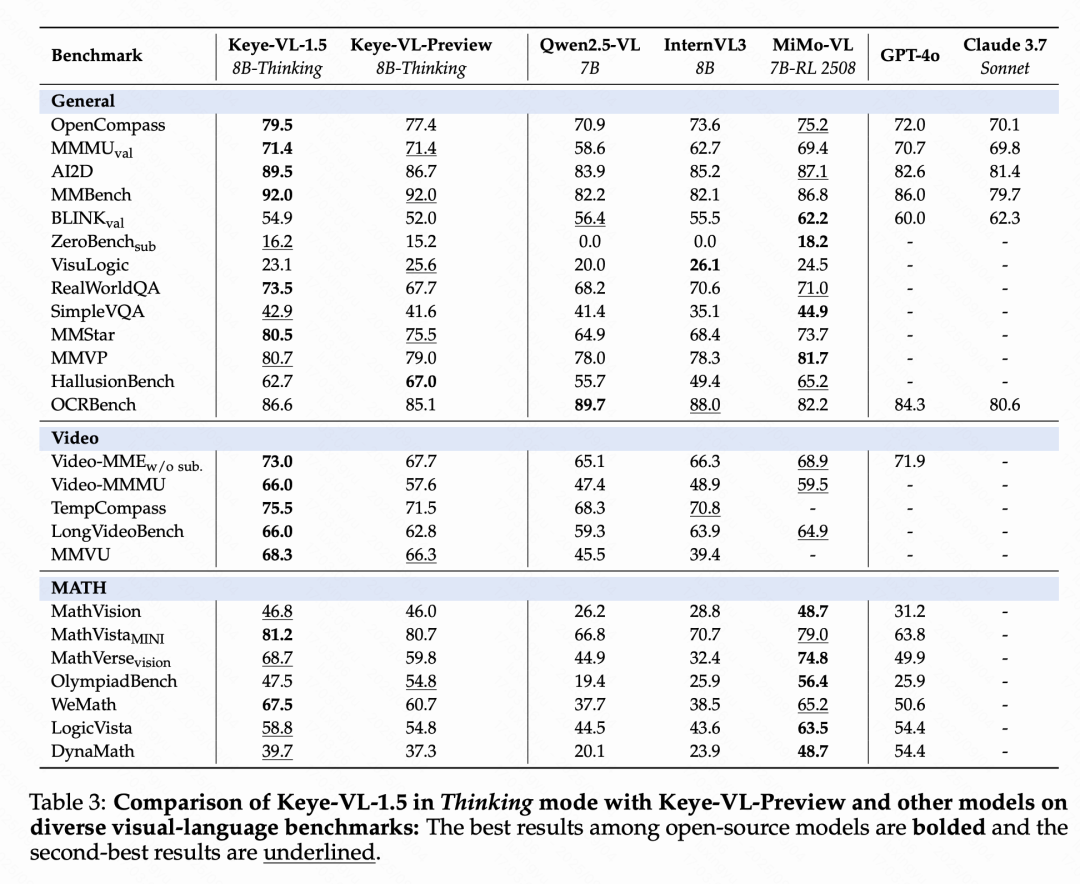
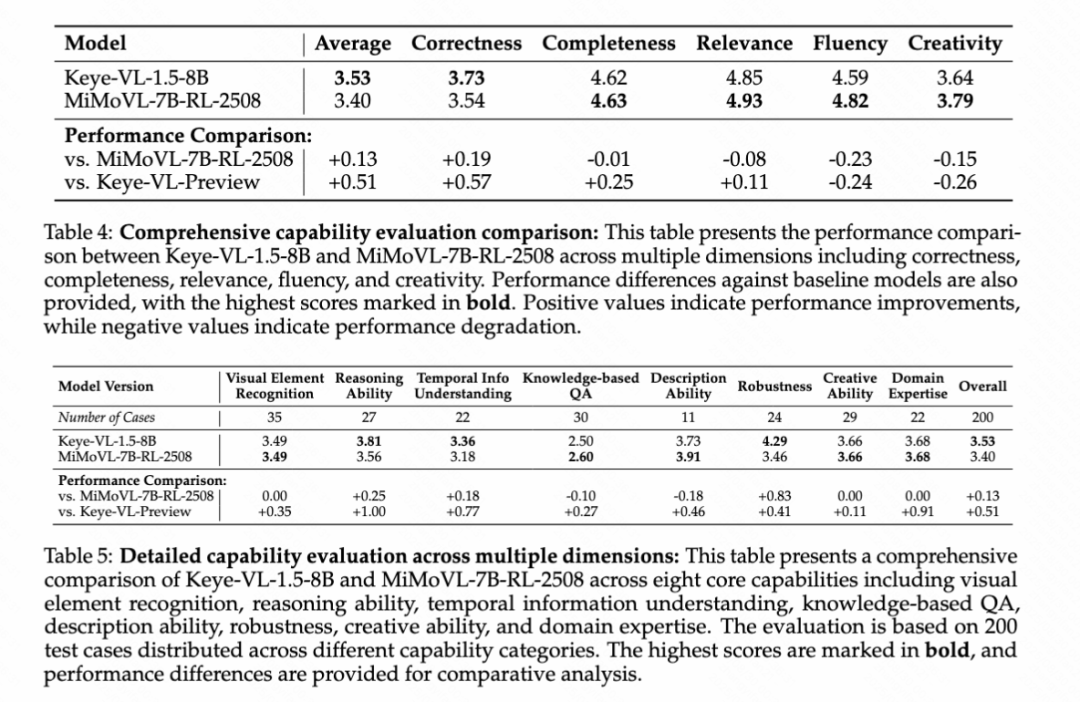
Keye-VL內部人工基準測試顯示顯著性能提升
為了全面評估模型能力,快手Keye團隊構建了嚴格的內部視頻評估基準,解決了公開基準測試存在的任務覆蓋有限、問題格式過于簡化、答案方法受限、數據污染風險和語言文化偏見等問題。該基準涵蓋視覺元素識別、推理能力、時序信息理解、基于知識的問答、描述能力、魯棒性、創造能力和領域專業知識八個維度,采用多模型對比評估和GSB偏好選擇的評分方法。
評估結果顯示,Keye-VL-1.5-8B取得了顯著的性能提升:總體綜合得分達到3.53,相比Keye-VL-Preview提升0.51分,在正確性(+0.57)和完整性(+0.25)方面表現尤為突出。與行業基準MiMoVL-7B-RL-2508的直接對比中,Keye-VL-1.5-8B獲得更高的總體得分(3.53對3.40),在正確性方面領先0.19分。詳細能力分析顯示,該模型在推理能力(3.81)、時序信息理解(3.36)和魯棒性(4.29)方面表現卓越,其中魯棒性相比競品領先0.83分,充分證明了模型在處理復雜分析任務和保持穩定性能方面的強大優勢。相比前版本,模型在基礎視覺理解能力方面建立了堅實基礎,視覺元素識別提升0.35分,推理能力提升1.00分,時序信息理解提升0.77分,為處理復雜多模態推理任務提供了強大的技術支撐。
展望未來,依托快手在短視頻領域深厚的技術積累,Kwai Keye-VL 在視頻理解方面具備獨特優勢。該模型的發布與開源,標志著多模態大語言模型在視頻理解新紀元的探索邁出了堅實一步。
)


)






——使用okhttp網絡工具框架對接標準API接口)
)





: ARM 架構功耗仿真)

