1.LatentSync: Taming Audio-Conditioned Latent Diffusion Models for Lip Sync with SyncNet Supervision 字節 2024
文章地址:https://arxiv.org/pdf/2412.09262
代碼地址:https://github.com/bytedance/LatentSync? ? 訓練推理都有
2.wan2.2-s2v 阿里通義 20250826
文章:[2508.18621] Wan-S2V: Audio-Driven Cinematic Video Generation
代碼:https://github.com/Wan-Video/Wan2.2?只有推理
3.Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation 中山大學an美團20250528
文章:https://arxiv.org/pdf/2505.22647
代碼:https://github.com/MeiGen-AI/MultiTalk?只有推理
4.Loopy: Taming Audio-Driven Portrait Avatar with Long-Term Motion Dependency
字節and浙大?支持Singing
文章:https://arxiv.org/pdf/2409.02634? ?ICLR2025
代碼:只有demo?Loopy: Taming Audio-Driven Portrait Avatar with Long-Term Motion Dependency
5.EchoMimic: Lifelike Audio-Driven Portrait Animations through Editable Landmark Conditioning
AAAI 2025 20240711 螞蟻?Pretrained models with better sing performance to be released
項目EchoMimic: Lifelike Audio-Driven Portrait Animations
文章[2407.08136] EchoMimic: Lifelike Audio-Driven Portrait Animations through Editable Landmark Conditions
代碼https://github.com/antgroup/echomimic?只有推理
EchoMimicV2: Towards Striking, Simplified, and Semi-Body Human Animation.?GitHub
20250227?CVPR 2025
EchoMimicV3: 1.3B Parameters are All You Need for Unified Multi-Modal and Multi-Task Human Animation.?GitHub? 20250708
6.EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions 20250227 阿里 ECCV2024
項目EMO
文章:[2402.17485] EMO: Emote Portrait Alive -- Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions
代碼:沒內容GitHub - HumanAIGC/EMO: Emote Portrait Alive: Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions
EMO2: End-Effector Guided Audio-Driven Avatar Video Generation 20250118阿里
項目:EMO2。支持Singing
文章:[2501.10687] EMO2: End-Effector Guided Audio-Driven Avatar Video Generation
7.VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time
Microsoft Research Asia 20240416?NeurIPS 2024 (Oral)?
項目:https://www.microsoft.com/en-us/research/project/vasa-1/
文章:[2404.10667] VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time
8.FaceFormer: Speech-Driven 3D Facial Animation with Transformers,?CVPR 2022.
文章:https://arxiv.org/pdf/2112.05329
代碼:https://github.com/EvelynFan/FaceFormer?tab=readme-ov-file?有訓練代碼
9.SkyReels-Audio: Omni Audio-Conditioned Talking Portraits in Video Diffusion Transformers MimicMotion? ??SkyReels Team, Skywork AI 20250601 支持唱歌
項目SkyReels-Audio
文章https://arxiv.org/pdf/2506.00830
代碼https://skyworkai.github.io/skyreels-audio.github.io/?僅推理
SkyReels-A1: Expressive Portrait Animation in Video Diffusion Transformers
SkyReels-A2: Compose Anything in Video Diffusion Transformers
SkyReels-A3:Towards Ultra-Long Audio-Conditioned Video Generation
10.InfiniteTalk: Audio-driven Video Generation for Sparse-Frame Video Dubbing
20250819 多家單位
項目InfiniteTalk
文章[2508.14033] InfiniteTalk: Audio-driven Video Generation for Sparse-Frame Video Dubbing
代碼:只有推理GitHub - MeiGen-AI/InfiniteTalk: ??Unlimited-length talking video generation?? that supports image-to-video and video-to-video generation
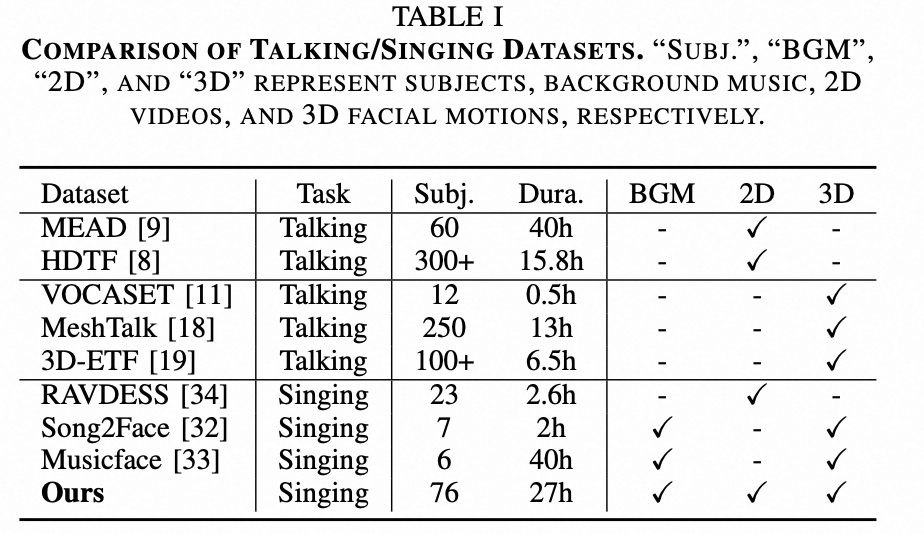
11.MusicFace: Music-driven expressive singing face synthesis
20240201 廈大 沒開源
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10897677&tag=1[2508.14033] InfiniteTalk: Audio-driven Video Generation for Sparse-Frame Video Dubbing
12.FantasyTalking: Realistic Talking Portrait Generation via Coherent Motion Synthesis
阿里 MM2025
文章https://arxiv.org/pdf/2504.04842
代碼 https://github.com/Fantasy-AMAP/fantasy-talking只有推理
13.HHunyuanVideo-Avatar: High-Fidelity Audio-Driven Human Animation for Multiple Characters騰訊混元 20250603
文章https://arxiv.org/pdf/2505.20156
代碼https://github.com/Tencent-Hunyuan/HunyuanVideo-Avatar?只有推理
14.DiffSynth-Studio
開源項目GitHub - modelscope/DiffSynth-Studio: Enjoy the magic of Diffusion models!
15.SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation??
CVPR2023
文章[2211.12194] SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation
代碼 僅推理GitHub - OpenTalker/SadTalker: [CVPR 2023] SadTalker:Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation
16.Speech2Vid
17.Wav2Lip
18.DeepFaceLive
19.Easy-Wav2
20.VideoReTalking
21.UniTalker: Conversational Speech-Visual Synthesis
20250807 MM2025
文章
代碼https://github.com/AI-S2-Lab/UniTalker?沒內容
數據集
1.VOCASET?VOCA
2.BIWI dataset?Biwi 3D Audiovisual Corpus of Affective Communication
3.Flow-guided One-shot Talking Face Generation with a High-resolution Audio-visual Dataset? 2021CVPR 網易伏羲
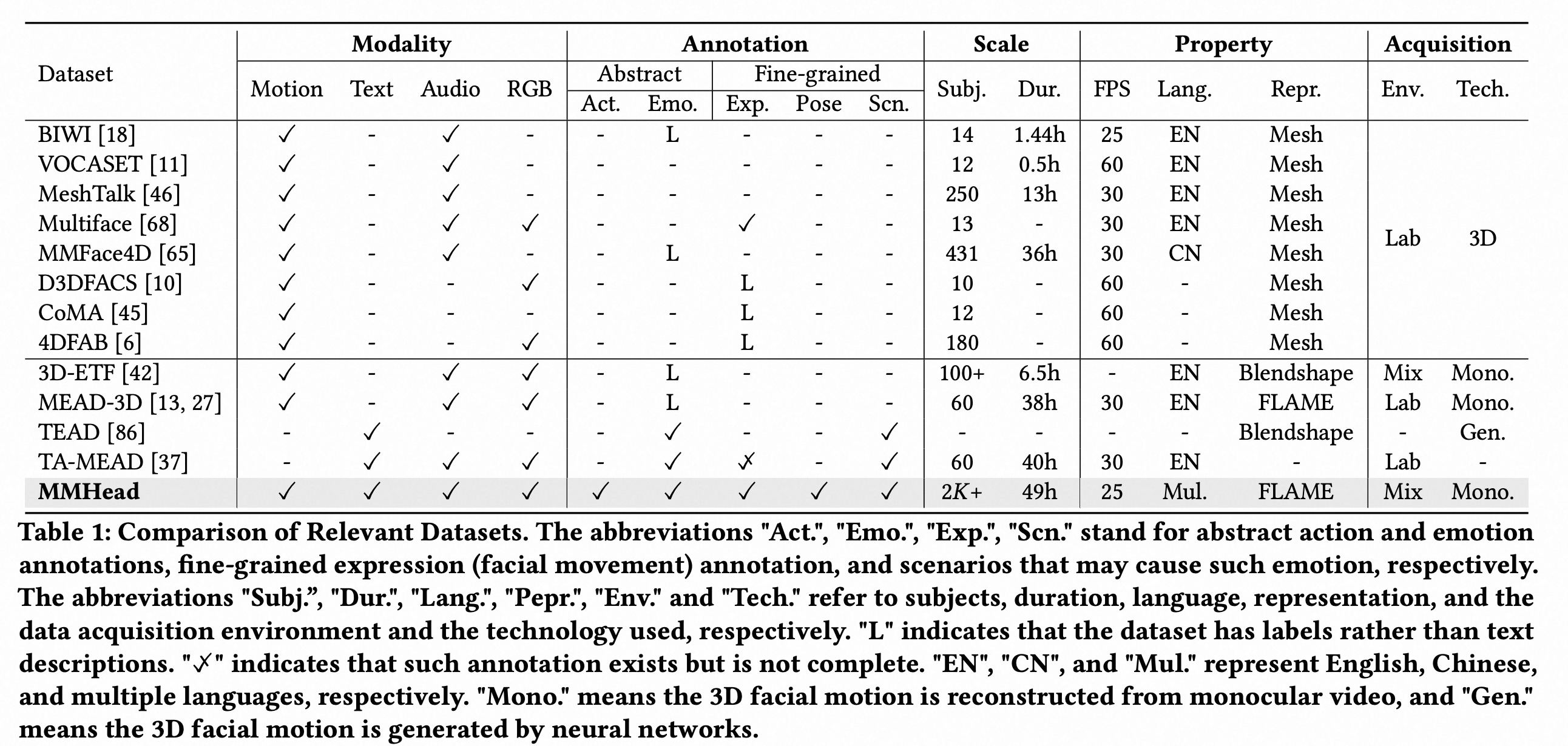
4.MMhead MM2025?https://openreview.net/pdf?id=L99kOQk12i
專門唱歌
1.SingAvatar: High-fidelity Audio-driven Singing Avatar Synthesis
ICME2024
文章https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10687925
說是會開源,實際沒開源
2.MusicFace: Music-driven Expressive?Singing?Face Synthesis 上面有 沒開源
數據集
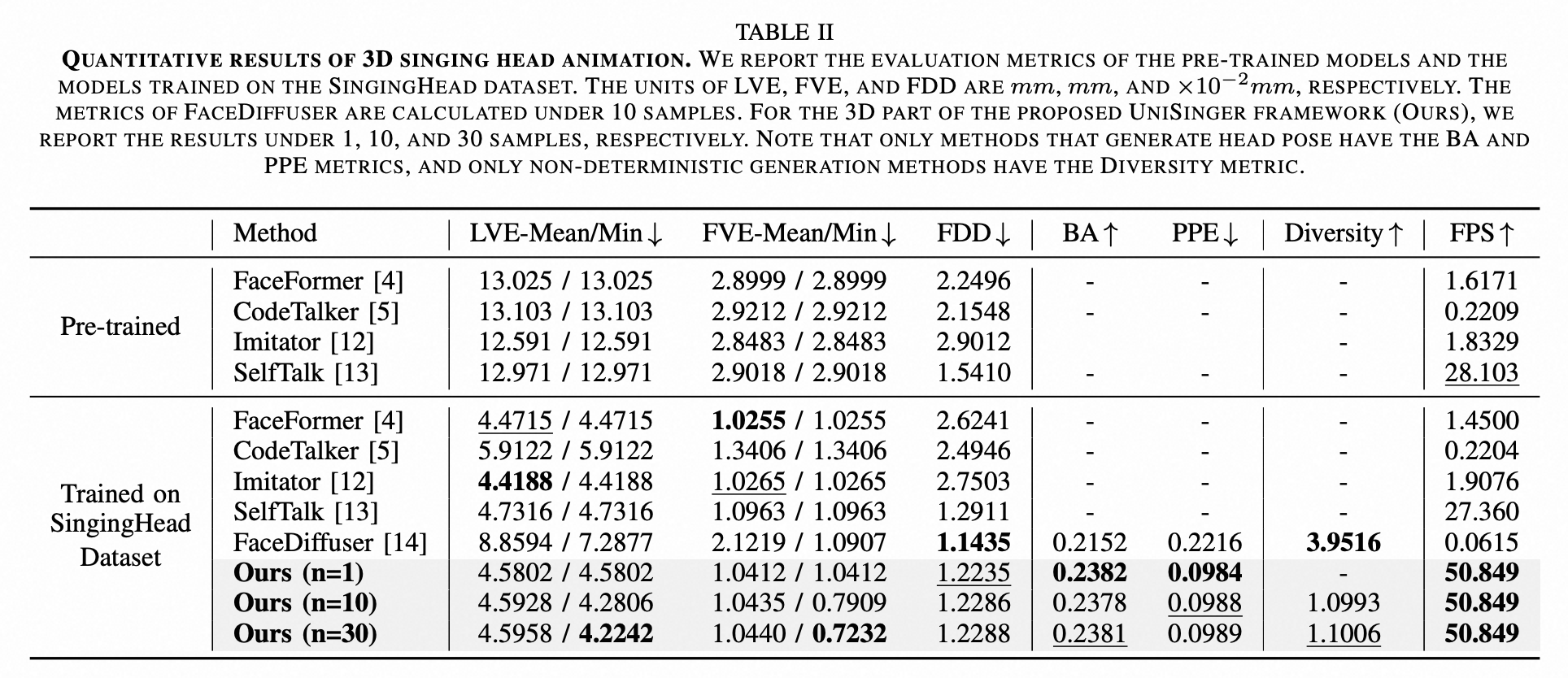
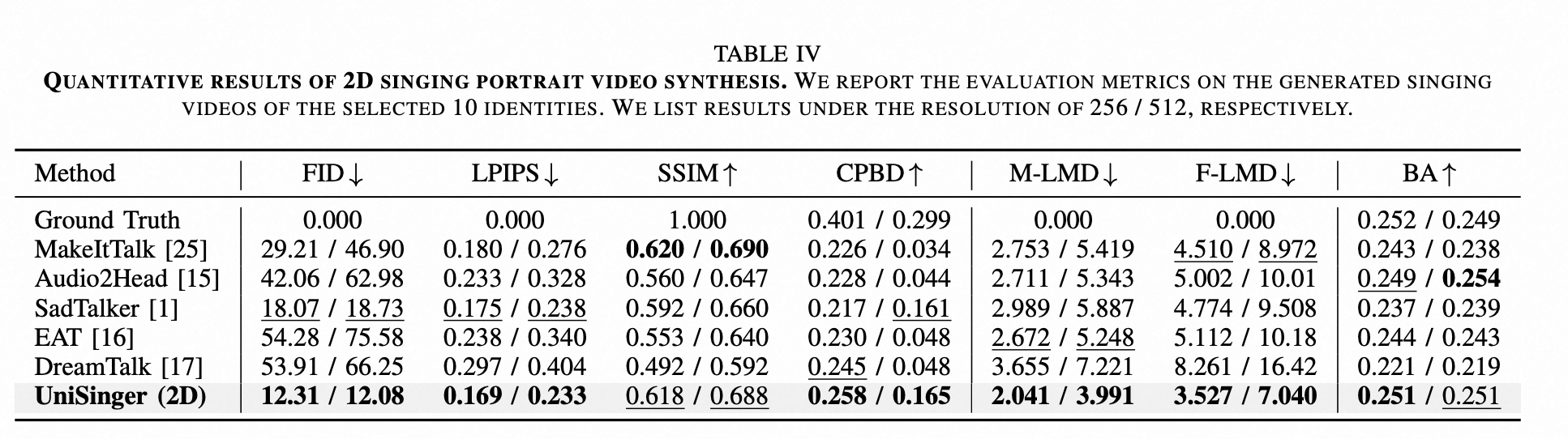
1.SingingHead: A Large-scale 4D Dataset for Singing Head Animation
20240714 上海交大?https://openreview.net/profile?id=~Sijing_Wu1
文章https://arxiv.org/pdf/2312.04369
地址GitHub - wsj-sjtu/SingingHead: Official implentation of SingingHead: A Large-scale 4D Dataset for Singing Head Animation. (TMM 25)

與過濾器(Filter)有什么區別?)


)


)






——使用okhttp網絡工具框架對接標準API接口)
)



