概述
微調,Fine-Tuning,簡稱FT,可理解為對LLM的定制,目的是增強專業領域知識,并優化特定任務的性能。通過在特定數據集上微調一個預訓練模型,可實現:
- 更新知識:引入新的領域專屬信息;
- 定制行為:調整模型的語氣、個性或響應風格;
- 優化任務:提升針對特定任務場景的準確性和相關性;
- 降低成本:避免從頭訓練模型。
可將微調后的模型視為一個專門優化的Agent,更高效地執行特定任務。
優勢:通過修改模型參數,永久地提高模型能力。
劣勢:若處理不當,很可能造成模型原始能力的災難性遺忘,即導致模型原始能力丟失,對于復雜模型尤其如此。因此需小心謹慎地設計模型微調數據集和微調訓練流程,并經過反復多次訓練驗證,得到最佳模型。
應用場景:
- 風格微調:適用于客服系統、虛擬助理等場景,微調得到不同語氣、情感表達、禮貌程度、回答方式、對話策略等。
- 知識灌注:微調可將外部知識或領域特定的信息快速集成到已有的預訓練模型中。
- 多輪推理:微調能更高效地理解長文本、推理隱含信息,或從數據中提取邏輯關系。
- 能力提升:在MAS系統或工具調用(Function Call,FC)場景中,微調能顯著提升Agent能力,使得模型能夠學會更精準的功能調用策略、參數解析和操作指令,進而有效地與其他系統進行交互、調用外部API或執行特定任務。
策略
Supervised FT,SFT,有監督微調,指使用帶標簽的目標任務數據集對預訓練模型進行訓練,通過模型預測結果與真實標簽的誤差反向傳播,更新模型參數的過程。
核心特點:依賴高質量標注數據;訓練過程有明確監督信號,模型收斂方向更明確。
全量微調(Full FT,FFT)和參數高效微調(Parameter-Efficient FT,PEFT)
| 維度 | FFT | PEFT |
|---|---|---|
| 定義 | 對預訓練模型所有參數進行更新,無參數凍結 | 僅更新模型一小部分參數,通常<1%,其余參數凍結 |
| 參數更新范圍 | 100%模型參數 | 0.1%~1%參數,依方法不同略有差異 |
| 計算/存儲成本 | 極高,需支持全量參數反向傳播,千億級模型需多卡集群 | 極低,僅更新小部分參數,單卡GPU即可支持 |
| 數據依賴 | 需大量標注數據,通常數萬~十萬條,否則易過擬合 | 數據需求低,數千~萬條即可,抗過擬合能力更強 |
| 性能上限 | 理論性能最高,可充分適配任務 | 性能接近全量微調,多數場景下差距<5%,部分任務可持平 |
| 適用場景 | 數據量充足、計算資源雄厚 | 資源有限、數據量少、多任務快速適配 |
FFT優勢:無參數凍結,模型可充分學習任務特性,在數據量充足時能達到最優性能。
劣勢
- 成本極高:以千億參數模型為例,全量微調需數十張H100,單日訓練成本可達數萬元;
- 數據需求高:若標注數據不足,易導致過擬合,模型記住訓練數據,泛化能力差;
- 存儲壓力大:訓練過程中需保存大量中間參數(如梯度、優化器狀態),對存儲容量要求極高。
主流PEFT方法:
- LoRA:Low-Rank Adaptation:低秩適應。一個超大話題,需另起一篇。
- Instruction Tuning:指令微調
- Prompt Tuning:提示詞微調
- Prefix Tuning:前綴微調
- Adapter Tuning:適配器微調
| 數據量/資源 | 推薦方法 | 適用場景 |
|---|---|---|
| 數據量充足>10萬條、計算資源雄厚 | FFT | 大廠核心業務,如電商平臺情感分析、機器翻譯 |
| 數據量中等1~萬條、資源有限 | LoRA | 中小企業領域適配,如醫療對話、法律文檔問答 |
| 數據量少<1萬條、資源有限 | 其他 | 小樣本任務,如特定領域NER、少量標注分類任務 |
LoRA憑借低成本+高性能的平衡,已成為當前LLM微調的主流選擇。
Prompt Tuning
思想:不改變模型原始權重,僅通過優化輸入提示詞本身來引導模型輸出期望結果;提示詞可以是離散的(人工設計模板)或連續的(可訓練的向量,如P-Tuning)。
微調對象:只微調與輸入提示相關的少量參數(如Prompt Embedding),不改變語言模型主體參數。
典型方法:P-Tuning、P-Tuning v2。
Instruction Tuning
思想:通過在大量指令-輸入-輸出對數據上微調整個模型(或部分參數),讓模型學會理解和執行各種自然語言指令。
微調對象:模型參數本身(全參數微調,或部分參數微調)。
特點:
- 目標是增強模型對自然語言指令的泛化能力,使其能直接按照用戶指令執行任務。
- 微調后模型對提示工程依賴較低,輸出更自然、一致。
- 需大量標注數據,計算成本相對較高。
Prefix Tuning
思想:與Prompt Tuning類似,在輸入序列前添加一段可訓練的連續向量(即前綴Token,會參與模型的注意力計算),僅優化這些前綴參數,其余模型參數凍結。
微調對象:僅前綴參數(通常占模型總參數的0.1%)。
特點:
- 適用于生成類任務;
- 前綴長度可調,長度越長效果通常越好,但推理速度幾乎不受影響。
Adapter Tuning
論文,
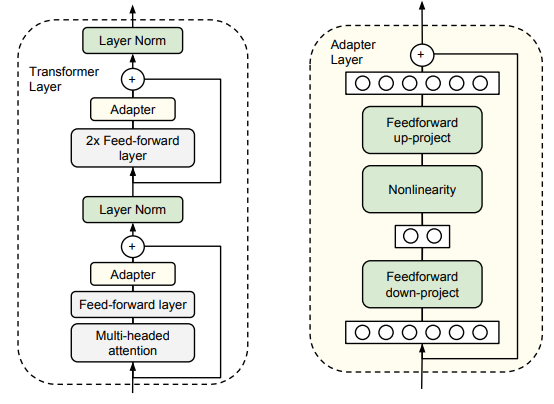
思想:在預訓練模型的每一層(或部分層)插入小型適配器模塊(通常由兩層MLP構成,如BottleNeck結構:降維→激活→升維),僅訓練這些適配器參數,模型主體凍結。
微調對象:適配器模塊參數(通常占模型總參數的3~5%)。
特點:
- 幾乎不影響原模型結構,推理時只需額外計算適配器部分;
- 適配器模塊可針對不同任務分別訓練,靈活性強;
- 參數量比Prefix Tuning大,但通常效果更穩定。
其他微調方法對比
| 方法 | 微調對象 | 是否改模型權重 | 參數占比 | 適用場景 | 優點 | 缺點 |
|---|---|---|---|---|---|---|
| Prompt Tuning | 輸入提示(連續/離散) | 否 | 極低 | 資源受限、快速適配 | 高效、極低計算開銷 | 依賴提示工程,效果有限 |
| Instruction Tuning | 模型參數(全/部分) | 是 | 較高 | 通用指令執行、多任務 | 輸出自然、泛化強 | 需大量標注數據、開銷大 |
| Prefix Tuning | 輸入前綴(連續向量) | 否 | 極低 | 生成任務 | 參數極省、推理快 | 僅適合生成類任務 |
| Adapter Tuning | 插入適配器模塊 | 否 | 低 | 理解+生成任務 | 靈活、穩定、可插拔 | 參數略多,訓練略復雜 |
對比RAG
參考RAG概述。
- 針對特定任務的專業性
微調讓模型深入理解某個特定領域或任務,使其能精準處理結構化、重復性高或具有復雜背景的查詢,這是RAG無法獨立完成的 - 推理速度更快
微調后的模型直接生成答案,無需額外的檢索步驟,適用于對響應速度要求極高的場景。 - 個性化行為與風格
微調可精準控制模型的表達方式,確保其符合品牌風格、行業規范或特定約束。 - 為模型添加新知識
微調的核心目標之一,讓模型掌握全新的概念或知識,只要數據集中包含相關信息。
RAG+微調:結合兩者,以發揮最大優勢:
- RAG讓系統具備動態獲取最新外部知識的能力;
- 微調讓模型掌握核心專業知識,即使沒有外部檢索也能穩定發揮作用;還能幫助模型更好地理解和整合檢索回來的信息;
- 任務專業性:微調擅長特定任務,RAG提供最新外部知識,兩者互補;
- 適應性:當檢索失敗時,微調后的模型依然能維持高水平的性能,RAG讓系統無需頻繁重新訓練也能保持知識更新;
- 效率:微調建立穩定的基礎,RAG則減少對大規模訓練的需求,僅在必要時提供額外信息。
實戰
一些建議:
- 微調沒有單一的最佳方式,只有適用于不同場景的最佳實踐;
- 使用Unsloth等易入門的開源框架;
- 從4比特QLoRA量化入手;
- 使用免費云服務器資源如Google Colab和Kaggle Notebook。
數據集
微調流程中,數據集質量直接決定微調效果,尤其是當模型需具備復雜功能(如FC、混合推理)或應用于特定領域任務時。
模型通過特殊字符標記識別輸入類型、系統提示和輸出邊界,數據集需遵循模型的格式規范。以Qwen3為例:
<|im_start|>:標記文本開始,后跟角色,如user/assistant/system;<|im_end|>:標記文本結束。
標記可在模型的tokenizer_config.json文件中查看完整定義。
常見微調數據集格式
- 基礎問答:Alpaca風格,適用于簡單指令微調,包含instruction、input和output三個核心字段。示例:
{"instruction": "識別并解釋給定的科學理論","input": "細胞理論","output": "細胞理論是生物科學的基礎理論,認為所有生命體由細胞構成,細胞是生物的基本結構和功能單位。"
}
微調時,腳本會自動將其轉換為Qwen3等模型兼容的標記格式:
<|im_start|>user
識別并解釋給定的科學理論:細胞理論<|im_end|>
<|im_start|>assistant
細胞理論是生物科學的基礎理論...<|im_end|>
- 帶系統提示和FC:若需提升模型的FC能力,數據集需包含系統提示、工具定義和調用示例。系統提示:明確FC規則;工具定義:通過
<tools>描述函數參數。對話示例:
<|im_start|>system
你是天氣助手,查詢天氣時需調用get_weather函數。
<tools>[{"name":"get_weather","parameters":{"location":"城市名稱"}}]</tools><|im_end|>
<|im_start|>user
北京天氣如何?<|im_end|>
<|im_start|>assistant
<tool_call>{"name":"get_weather","arguments":{"location":"北京"}}</tool_call><|im_end|>
高效微調僅能優化現有FC能力,無法讓模型從無到有學會該功能。
- 帶思考過程:為提升模型推理能力,數據集需包含中間思考步驟,用特殊標記分隔思考過程與最終輸出。例如:
<|im_start|>system
你是數學助手,需展示解題步驟。<|im_end|>
<|im_start|>user
計算3+5×2的結果。<|im_end|>
<|im_start|>assistant
<think>用戶問的是3加5乘2,先算乘法再算加法,5乘2等于10,再加3就是13。/think>3+5×2=3+10=13<|im_end|>
作為示例和思路,為混合推理模型構造微調數據集,采用多數據集拼接策略,核心步驟:
- 選擇基礎數據集
- 普通對話數據:如FineTome-100k(含10萬條多輪對話,ShareGPT風格),用于保留模型的自然交互能力。
- 推理類數據:如OpenMathReasoning(含54萬道數學題及詳細解題步驟),用于強化邏輯推理能力。
- 數據集配比調整:需根據微調目標平衡不同類型數據的比例:
- 若側重數學推理:可按7:3比例混合;
- 若需均衡能力:可按5:5比例混合,避免模型過度偏向單一任務。
- 格式統一與清洗:確保所有數據轉換為Qwen3兼容的標記格式;過濾重復樣本、錯誤標注和低質量內容,避免模型學習噪聲數據。
數據集下載渠道:HF、ModelScope(魔搭社區,簡稱MS)
框架
LLaMA-Factory
57.5K Star,7K Fork。參考LLaMA-Factory。
Unsloth
參考Unsloth實戰。45.1K Star,3.6K Fork。
ColossalAI
GitHub,41.1K Star,4.5K Fork。一個高效的分布式人工智能訓練系統,旨在最大化提升AI訓練效率,最小化訓練成本。作為DL框架內核,提供自動超高維并行、大規模優化庫等前沿技術。
優勢表現:與英偉達Megatron-LM相比,僅需一半數量的GPU即可完成GPT-3訓練,半小時內預訓練ViT-Base/32,并在兩天內訓練完15億參數的GPT模型。提供多種并行技術,如數據并行、流水線并行和張量并行,以加速模型訓練。
強化學習訓練,則推薦veRL和OpenRLHF等框架。
MS-Swift
MS社區推出,GitHub,9.7K Star,851 Fork。
XTuner
上海AI實驗室的InternLM團隊推出的開源(4.7K Star,354 Fork)輕量化LLM微調工具庫,支持LLM多模態圖文模型的預訓練及輕量級微調。
特點:
- 高效:僅需8GB顯存即可微調7B模型,支持多節點跨設備微調70B+ LLM。通過自動分發FlashAttention、Triton kernels等高性能算子加速訓練,兼容DeepSpeed,能輕松應用ZeRO優化策略提升訓練效率;
- 靈活:兼容InternLM等多種主流LLMs和LLaVA多模態圖文模型,支持預訓練與微調。數據管道設計靈活,兼容任意數據格式,支持QLoRA、LoRA及全量參數微調等多種算法;
- 全能:支持增量預訓練、指令微調與Agent微調,提供豐富的開源對話模板便于與模型交互。訓練所得模型可無縫接入部署工具庫LMDeploy、評測工具庫OpenCompass及VLMEvalKit,實現從訓練到部署的全流程支持。
安裝
# 環境準備
conda create --name xtuner-env python=3.10 -y
conda activate xtuner-env
# 源碼安裝
git clone https://github.com/InternLM/xtuner.git
cd xtuner
pip install -e '.[deepspeed]'
# 驗證
xtuner list-cfg
XTuner支持增量預訓練、單輪對話、多輪對話三種數據集格式:
- 增量預訓練數據集用于提升模型在特定領域或任務的能力;
- 單輪對話和多輪對話數據集則經常用于指令微調階段,以提升模型回復特定指令的能力。
MindSpeed LLM
GitHub。
對比選型
| 維度 | LLaMA-Factory | Unsloth | MS-Swift | MindSpeed LLM |
|---|---|---|---|---|
| 定位 | 微調,主打模塊化與多場景適配 | 微調+加速,聚焦性能與效率優化,顯存優化型訓練加速引擎 | 多模態全棧工具鏈 | 昇騰硬件深度優化框架 |
| 社區生態 | 中文社區活躍,提供Web UI工具 | HF生態兼容,開發者論壇活躍 | MS框架,整合天池/魔搭社區資源 | 華為昇騰社區雙軌支持,兼容MindSpore/PyTorch雙后端 |
| 優勢 | 模塊化設計、多硬件自適應、量化技術 | 高速微調、低內存占用、主流模型兼容、顯存效率極致優化 | 多模態DPO訓練,推理吞吐量提升20倍 | 昇騰910B訓練速度超A100 2.3倍,支持千億參數模型分布式訓練 |
| 局限 | 全參微調速度較慢,存在歷史安全漏洞 | 社區較新文檔不完善,依賴Triton內核經驗 | 生態依賴性強,脫離MS擴展性受限 | 硬件適配單一,非昇騰環境支持有限 |
| 硬件支持 | NVIDIA/AMD/Ascend GPU、Mac M系列芯片 | 主要支持NVIDIA GPU | NVIDIA GPU 為主,部分支持Ascend NPU(算子兼容問題) | 昇騰910B/910C NPU,支持訓推共卡 |
| 模型支持 | 支持主流 | 支持主流,兼容HuggingFace格式 | 支持主流,500+純文本模型、200+多模態模型 | 支持主流,新增MindSpore后端 |
| 訓練效率 | 全參微調速度較Unsloth慢30%,支持DeepSpeed分布式 | 40GB可處理70B模型,GRPO流程優化 | 多卡訓練效率提升40%(DDP+FSDP),集成vLLM加速 | 千億參數模型分布式訓練效率領先,GRPO訓練速度提升顯著 |
| 顯存優化 | 動態量化(2-8bit)+梯度檢查點,8B模型微調顯存10GB | 動態4bit量化+Triton內核重寫,顯存占用減少80% | PEFT技術+混合精度訓練,顯存占用降低70% | 算子融合+內存復用,70B模型訓練顯存32GB(GRPO優化后) |
| 微調策略 | 全參微調、LoRA、QLoRA,支持DPO、SimPO對齊 | LoRA、QLoRA、動態量化訓練,GRPO強化學習 | LoRA+、GaLore、Q-GaLore,多模態DPO訓練 | QLoRA、DPO、PPO,支持訓推共卡模式 |
| 易用性 | 低代碼Web UI,數據標注-訓練-部署一鍵式操作 | API簡潔,5分鐘上手,提供Colab一鍵啟動腳本 | 依賴MS數據工具,多模態任務配置模板化 | 需熟悉Ascend-CANN工具鏈,昇騰專用SDK |
| 典型場景 | 多模態內容生成、行業LLM私有化部署 | 資源受限環境快速迭代、學術研究原型開發 | 多模態對話系統、長文本生成(16K Token) | 昇騰集群部署的千億參數模型訓練、金融風控/政務合規場景 |
其他框架
| 框架 | 優勢 | 適用場景 |
|---|---|---|
| Hugging Face | 高度兼容,易用,文檔豐富 | 一般NLP任務,模型選擇豐富 |
| LoRA | 顯存節省,減少微調計算量 | 顯存有限的設備,微調大規模模型 |
| PEFT | 高效微調,低計算開銷 | 資源有限的環境,適合大規模預測級模型的微調 |
| DeepSpeed | 大規模分布式訓練,顯存優化 | 超大規模訓練,多卡分布式訓練 |
| AdapterHub | 低資源消耗,快速微調 | 多任務微調,資源有限的環境 |
| Alpaca-LoRA | 生成任務優化,LoRA技術結合 | 對話生成、文本生成 |
| FastChat | 對話系統微調,快速集成 | 對話生成任務,尤其是對ChatGPT等模型微調 |
| FairScale | 大規模分布式訓練優化,自動化優化 | 多卡分布式訓練,大規模微調 |
資料
Notebook
Unsloth AI開源Notebook,涵蓋:
- BERT、TTS、視覺等多模態;
- GRPO、DPO、SFT、CPT等方法論;
- 數據準備、評估、保存等微調階段;
- Llama、Gemma、Phi等模型;
- 其他:工具調用、分類、合成數據;
![【LCA 樹上倍增】P9245 [藍橋杯 2023 省 B] 景區導游|普及+](http://pic.xiahunao.cn/【LCA 樹上倍增】P9245 [藍橋杯 2023 省 B] 景區導游|普及+)


:面向鏈接預測的知識圖譜表示學習方法綜述)
,規則(Rules))

![前沿重器[74] | 淘寶RecGPT:大模型推薦框架,打破信息繭房](http://pic.xiahunao.cn/前沿重器[74] | 淘寶RecGPT:大模型推薦框架,打破信息繭房)

的崛起——為什么“會寫Prompt”成了新技能?)

)


)





