
筆者鏈接:撲克中的黑桃A
專欄鏈接:論文精讀
本文關鍵詞:知識圖譜;?表示學習;?鏈接預測;?多元關系;?超關系
引
諸位技術同仁:
本系列將系統精讀的方式,深入剖析計算機科學頂級期刊/會議論文,聚焦前沿突破的核心機理與工程實現。
通過嚴謹的學術剖析,解耦研究范式、技術方案及實證方法,揭示創新本質。我們重點關注理論-工程交匯點的技術躍遷,提煉可遷移的方法論錨點,助力諸位的技術實踐與復雜問題攻堅,共推領域持續演進。

每日一句
所有的憂傷都是過往,
當時間慢慢沉淀,
你會發現,
自己的快樂比想象的多得多。

目錄
引
每日一句
文獻來源
一.知識圖譜與鏈接預測的基礎認知
1.知識圖譜:結構化的 “知識通訊錄”
2. 鏈接預測:補全 “知識地圖” 的核心任務
對稱關系
反對稱關系
傳遞關系
3. 表示學習:讓計算機 “理解” 知識的橋梁
二.知識表示形式:從簡單到復雜的 “知識編碼” 演進
1. 二元關系:知識表示的 “基礎句型”
數學建模
優缺點分析
2. 多元關系:表達復雜知識的 “長句型”
數學建模
優缺點分析
3. 超關系:主次分明的復雜知識表示
數學建模
優缺點分析
與知識超圖的區別
三.面向二元關系的表示學習模型:四類經典 “建模方法”
1. 平移距離模型:基于 “空間平移” 的語義建模
(1)?經典模型:TransE
(2)?優化方向與衍生模型
拓展映射空間
改進映射方式
區分向量表示
附加約束信息
2. 張量分解模型:基于 “矩陣分解” 的關聯捕捉
(1)?經典模型:RESCAL
(2)?優化方向與衍生模型
施加矩陣約束
優化分解形式
3. 傳統神經網絡模型:基于 “特征提取” 的非線性建模
(1)?卷積神經網絡(CNN)
(2)?其他神經網絡模型
4. 圖神經網絡模型:基于 “信息傳播” 的結構建模
(1)?核心思想
(2)?經典模型
(3)?與其他模型的區別
四.面向多元化關系的表示學習模型:從二元到多元的擴展
1. 多元關系的表示學習模型
(1)?平移距離模型的擴展
(2)?張量分解模型的擴展
(3)?傳統神經網絡模型的擴展
2. 超關系的表示學習模型
(1)?傳統神經網絡模型的擴展
(2)?圖神經網絡模型的擴展
五.實驗對比與分析:不同模型的 “實戰表現”
1. 常用數據集
(1)?二元關系數據集
(2)?多元關系數據集
(3)?超關系數據集
2. 評測指標
3. 實驗結果分析
(1)?二元關系模型對比
(2)?多元關系模型對比
(3)?超關系模型對比
(4)?關鍵結論
六.未來研究方向:挑戰與機遇
1. 模型優化:提升可解釋性與可擴展性
2. 知識表示形式:融合更多結構與信息
3. 問題作用域:針對特定場景定制模型
七.總結
尾
文獻來源
?杜雪盈,?劉名威,?沈立煒,?彭鑫.?面向鏈接預測的知識圖譜表示學習方法綜述.?
DOI:10.13328/j.cnki.jos.006902
軟件學報, 2024, 35(1): 87–117.
已標明出處,如有侵權請聯系筆者。
在信息爆炸的時代,我們每天都會接觸到海量數據,但這些數據大多以零散的文字、圖片等形式存在,就像散落的拼圖碎片。知識圖譜(Knowledge Graph, KG)的出現,將這些碎片拼接成一張結構化的 “知識地圖”—— 實體是地圖上的城市,關系是連接城市的道路,讓我們能清晰看到知識之間的關聯。然而,這張 “地圖” 卻常常存在 “道路缺失” 的問題:全球知名的知識圖譜 FreeBase 中,70% 的人物實體沒有出生地信息,99% 缺失種族信息;Wikidata 雖覆蓋更廣,但仍有大量復雜關系未被記錄。這種不完整性就像地圖上關鍵路段的缺失,嚴重影響了知識的應用價值 —— 在信息檢索中,可能漏掉相關結果;在問答系統中,無法回答涉及未記錄關系的問題
為了補全這張 “知識地圖”,鏈接預測(Link Prediction)技術應運而生。它能根據已有 “道路” 推測缺失的 “連接”,比如根據 “(北京,是首都,中國)” 和 “(中國,位于,亞洲)”,推測出 “(北京,位于,亞洲)” 這一缺失關系。而實現鏈接預測的核心,是知識圖譜表示學習(Knowledge Graph Representation Learning)—— 將實體和關系從文字符號轉換為計算機可計算的數值向量,就像把地圖上的城市坐標化,讓計算機能通過坐標計算距離和方向,從而推測未知的 “道路”
就像量子計算系統有 “應用→系統軟件→體系結構→硬件” 的完整鏈條,知識圖譜要從 “零散數據” 變成 “可用工具”,也離不開 “構建圖譜→發現缺失→補全鏈接” 的核心流程。咱們沿著 “是什么→缺什么→怎么補” 的思路,逐個拆解。
本文將系統解讀面向鏈接預測的知識圖譜表示學習方法,從知識圖譜的基本構成與鏈接預測的核心目標出發,拆解二元關系、多元關系、超關系三種知識表示形式,詳解平移距離、張量分解、傳統神經網絡、圖神經網絡四類表示學習模型的原理與演化,并通過實驗對比揭示不同模型的性能差異,最后展望未來研究方向。通過本文,讀者將全面掌握知識圖譜補全的核心技術,理解計算機如何 “讀懂” 知識并推測未知關聯。
一.知識圖譜與鏈接預測的基礎認知
1.知識圖譜:結構化的 “知識通訊錄”
知識圖譜本質是存 “誰與誰有啥關聯” 的數據庫,由實體(圖的節點)和關系(圖的邊)組成,比如 “(李白,創作,《靜夜思》)”“(《靜夜思》,屬于,詩歌)”。
- 經典類比:就像經典計算機里的 “關系型數據庫”,實體是 “數據表的行”,關系是 “數據表的列”,存的是結構化的 “實體 - 關系 - 實體” 三元組,而非雜亂的文本段落。
- 人話類比:就像你手機里的通訊錄 ——“張三”“李四” 是聯系人(實體),“同事”“大學同學”“同住一個小區” 是關系,你能一眼看清誰和誰有關聯,而不是把所有名字堆在無分類的備忘錄里。
目前,學術界和工業界已構建了多個大規模知識圖譜:
?FreeBase
由谷歌構建的開放知識圖譜,包含大量實體和關系,但存在嚴重的信息缺失,如前文所述的人物屬性缺失問題。
Wikidata
維基百科支持的協作式知識圖譜,數據更全面,且允許用戶持續編輯補充,就像一張不斷更新的 “活地圖”。
DBpedia
從維基百科中抽取結構化知識形成的圖譜,聚焦于實體的屬性和分類,如 “(北京,首都,中國)”“(北京,人口,2154 萬)”。
YAGO
融合維基百科和 WordNet 的知識圖譜,強調實體的時間和空間屬性,如 “(愛因斯坦,出生于,1879 年)”。?
但現有圖譜都有 “通訊錄備注不全” 的問題:
?FreeBase 中 70% 的人物實體沒 “出生地” 信息,99% 缺失 “種族” 信息;
連 “(魚,生活在,水)” 這種常識,Wikidata 都可能漏記。?
……
?這就像你通訊錄里有人沒填手機號、有人沒標 “所屬部門”,真要聯系或找人時,總會 “卡殼”。?
這種缺失會導致知識圖譜在應用中 “力不從心”—— 比如智能問答系統無法回答 “魚生活在哪里?”,推薦系統無法基于未記錄的關系推薦相關內容。
2. 鏈接預測:補全 “知識地圖” 的核心任務
鏈接預測是知識圖譜補全(Knowledge Graph Completion)的核心任務,目標是根據知識圖譜中已有的實體和關系,預測缺失的實體或關系。具體可分為兩類子任務:
- 實體預測:已知關系和部分實體,預測缺失的實體。例如已知 “(?, 創作,《靜夜思》)”,預測頭實體 “李白”;已知 “(李白,創作,?)”,預測尾實體 “《靜夜思》”。這就像已知 “航線” 和 “終點”,推測 “起點”;或已知 “起點” 和 “航線”,推測 “終點”。
- 關系預測:已知頭實體和尾實體,預測它們之間的關系。例如已知 “(李白,?, 《靜夜思》)”,預測關系 “創作”;已知 “(北京,?, 中國)”,預測關系 “是首都”。這就像已知 “起點” 和 “終點”,推測連接它們的 “航線類型”。
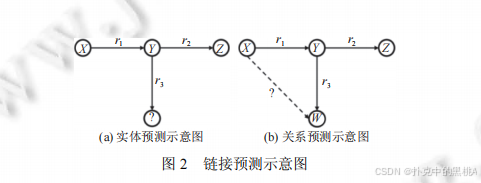
圖2左側展示實體預測場景(用 “?” 標記缺失的頭實體),右側展示關系預測場景(用 “?” 標記缺失的關系),通過具體案例(如 “(?,導演,《流浪地球》)” 預測 “郭帆”)直觀呈現兩類任務的區別。
鏈接預測的實現依賴于對知識圖譜中 “關系模式” 的挖掘。知識圖譜中存在多種典型的關系模式,例如:
對稱關系
若 “(A,朋友,B)” 成立,則 “(B,朋友,A)” 也成立,如 “朋友”“同事”。
反對稱關系
若 “(A,父親,B)” 成立,則 “(B,父親,A)” 一定不成立,如 “父子”“上下級”。
傳遞關系
若 “(A,屬于,B)” 和 “(B,屬于,C)” 成立,則 “(A,屬于,C)” 也成立,如 “國家 - 省份 - 城市” 的隸屬關系。
表示學習模型通過捕捉這些模式,實現對缺失鏈接的預測。例如,對于傳遞關系,模型會學習到 “頭實體向量 + 關系向量 1 + 關系向量 2 ≈ 尾實體向量” 的規律,從而推測多步關系。
3. 表示學習:讓計算機 “理解” 知識的橋梁
知識圖譜中的實體和關系以符號形式存在(如 “李白”“創作”),而計算機無法直接處理符號之間的語義關聯。表示學習的作用,就是將這些符號轉換為低維稠密的數值向量(Embedding),讓向量之間的運算能夠反映語義關系,就像用經緯度表示城市位置,通過經緯度計算距離來反映城市間的實際距離。
表示學習的核心目標是:對于知識圖譜中存在的三元組(h, r, t),其向量表示應滿足某種 “合理性條件”,而對于不存在的三元組,則不滿足該條件。例如,TransE 模型要求 “h + r ≈ t”,即頭實體向量與關系向量的和應接近尾實體向量;ComplEx 模型則通過復數向量的運算捕捉實體與關系的交互。
表示學習與鏈接預測的關系密不可分:
- 表示學習是鏈接預測的基礎:只有將實體和關系轉換為向量,計算機才能通過數值計算推測缺失鏈接,就像只有將城市坐標化,才能通過坐標計算路線。
- 鏈接預測是表示學習的重要應用:表示學習的效果通常通過鏈接預測的準確率來評估,一個好的表示模型應能準確預測缺失的實體或關系,就像準確的坐標系統能幫助我們找到最短路線。
通過表示學習,知識圖譜的符號化知識被轉化為向量空間中的數值關系,為鏈接預測、知識推理、信息檢索等任務提供了可計算的基礎。
二.知識表示形式:從簡單到復雜的 “知識編碼” 演進
知識的復雜性決定了其表示形式的多樣性。從最初的二元關系,到能表達復雜關聯的多元關系和超關系,知識表示形式的演進反映了對現實世界知識的更精準刻畫。
1. 二元關系:知識表示的 “基礎句型”
二元關系是知識圖譜中最基本、最常用的表示形式,用三元組(h, r, t)描述 “頭實體 - 關系 - 尾實體” 的關聯,就像語言中的 “主謂賓” 短句,結構簡單且易于處理。例如:
- “(北京,是首都,中國)”:頭實體 “北京”,關系 “是首都”,尾實體 “中國”。
- “(愛因斯坦,提出,相對論)”:頭實體 “愛因斯坦”,關系 “提出”,尾實體 “相對論”。
數學建模
在二元關系中,鏈接預測的目標是補全不完整的三元組,具體分為三種情況:
- 頭實體缺失:(?, r, t),需預測 h,如 “(?, 發明,電燈)”→“愛迪生”。
- 尾實體缺失:(h, r, ?),需預測 t,如 “(牛頓,發現,?)”→“萬有引力”。
- 關系缺失:(h, ?, t),需預測 r,如 “(地球,?, 太陽系)”→“屬于”。
模型通過學習實體和關系的向量表示,對所有可能的候選實體或關系進行評分,評分最高的即為預測結果。例如,對于(?, 發明,電燈),模型會計算每個實體 h 的向量與 “發明” 向量 r 的和,與 “電燈” 向量 t 的距離,距離最小的 h 即為預測答案。
優缺點分析
- 優點:結構簡單,易于建模和計算,是目前知識圖譜中最主流的表示形式。現有大多數表示學習模型都是基于二元關系設計的,如 TransE、DistMult 等。
- 缺點:表達能力有限,無法刻畫包含多個實體或關系的復雜知識。例如,“在 2023 年的電影《流浪地球 2》中,吳京飾演劉培強” 這一事實,包含實體 “吳京”“《流浪地球 2》”“2023 年”“劉培強” 和關系 “參演”“上映時間”“飾演角色”,若拆分為多個二元三元組:
- (吳京,參演,《流浪地球 2》)
- (《流浪地球 2》,上映時間,2023 年)
- (吳京,飾演角色,劉培強)
會丟失 “參演電影”“上映時間”“飾演角色” 之間的關聯信息,就像把一個完整的長句拆成零散的短句,失去了上下文聯系。
2. 多元關系:表達復雜知識的 “長句型”
為了表達包含 3 個及以上實體或多個關系的復雜知識,多元關系(N-ary Relations)表示形式應運而生。它用一組 “角色 - 鍵值對”(Role-Value Pairs)描述知識,其中 “角色” 對應關系,“鍵值” 對應實體,就像帶多個修飾語的長句,能完整呈現知識的細節。例如,上述電影案例的多元關系表示為:
{演員:吳京,電影: 《流浪地球 2》, 上映時間: 2023 年,飾演角色:劉培強}
數學建模
多元關系的一般形式為 {r?: v?, r?: v?, ..., r?: v?},其中 n≥3(元數)。鏈接預測任務需補全缺失的角色或鍵值:
- 角色缺失:{r?: v?, ..., ?: v?},需預測缺失的角色 r,如 {演員:吳京,電影: 《流浪地球 2》, ?: 劉培強}→“飾演角色”。
- 鍵值缺失:{r?: v?, ..., r?: ?},需預測缺失的鍵值 v,如 {演員:吳京,電影: ?, 飾演角色:劉培強}→《流浪地球 2》。
多元關系的建模需考慮角色與鍵值之間的關聯,以及不同角色 - 鍵值對之間的交互。例如,“演員” 和 “飾演角色” 的鍵值通常存在對應關系(特定演員在特定電影中飾演特定角色),模型需捕捉這種關聯以提高預測準確率。
優缺點分析
- 優點:能完整表達復雜知識,保留多個實體和關系之間的關聯信息,避免了二元關系拆分導致的語義丟失。
- 缺點:破壞了三元組的結構化形式,所有角色 - 鍵值對平行存儲,缺少主次之分。例如,在 {演員:吳京,電影: 《流浪地球 2》, 上映時間: 2023 年} 中,“演員 - 電影” 是核心關系,“上映時間” 是輔助信息,但多元關系將它們平等對待,可能導致模型無法聚焦核心關聯,就像長句中修飾語過多掩蓋了主干意思。
3. 超關系:主次分明的復雜知識表示
超關系(Hyper-relations)是多元關系的優化形式,它保留一個主三元組(h, r, t)作為核心知識,其余信息作為 “限定詞鍵值對”(Qualifier Pairs)附加在主三元組上,整體表示為(h, r, t, Q),其中 Q={(q?: v?), ..., (q?: v?)} 是輔助信息,就像 “主題句 + 注釋” 的結構,主次分明。例如,上述電影案例的超關系表示為:
(吳京,參演,《流浪地球 2》,{上映時間: 2023 年,飾演角色:劉培強})
數學建模
超關系以主三元組為核心,限定詞為輔助,鏈接預測主要針對主三元組的缺失進行補全,同時利用限定詞信息提高預測精度:
- 頭實體缺失:(?, r, t, Q),如(?, 參演,《流浪地球 2》, {飾演角色:劉培強})→“吳京”。
- 尾實體缺失:(h, r, ?, Q),如(吳京,參演,?, {上映時間: 2023 年})→《流浪地球 2》。
- 關系缺失:(h, ?, t, Q),如(吳京,?, 《流浪地球 2》, {飾演角色:劉培強})→“參演”。
限定詞的作用是提供上下文約束,縮小預測范圍。例如,預測 “(?, 參演,《流浪地球 2》)” 時,若已知限定詞 “飾演角色:劉培強”,模型可更精準地定位到 “吳京”,而不是其他參演演員。
優缺點分析
- 優點:既保留了核心語義(主三元組),又包含了輔助信息(限定詞),知識表示的準確性和完整性優于二元關系和多元關系。同時,主三元組的結構與現有二元關系模型兼容,便于模型擴展。
- 缺點:對模型的建模能力要求更高,需要區分主三元組與限定詞的關聯,以及不同限定詞之間的交互。例如,模型需理解 “飾演角色” 限定詞與主三元組 “參演” 關系的強關聯性,而 “上映時間” 限定詞的關聯性較弱。

圖三,以 “本尼迪克特?康伯巴奇在《模仿游戲》中飾演阿蘭?圖靈并獲奧斯卡提名” 為例,分別展示二元關系(拆分為 3 個三元組)、多元關系(4 個角色 - 鍵值對)、超關系(主三元組 + 2 個限定詞)的表示方式,直觀呈現三者在語義保留和結構清晰度上的差異。
與知識超圖的區別
超圖(Hypergraph)中每條邊可連接多個節點,知識超圖用一條超邊連接多元知識中的所有實體,但未區分主次關系,更接近多元關系的表示形式。而超關系通過主三元組明確核心關聯,限定詞輔助描述,在語義表達上更精準,因此更適合鏈接預測任務。
三.面向二元關系的表示學習模型:四類經典 “建模方法”
在深入剖析各類表示學習模型的細節前,我們先通過 “知識圖譜表示學習技術劃分框架”,從時間線與模型類別兩個角度,直觀把握技術發展的整體脈絡與分類邏輯。
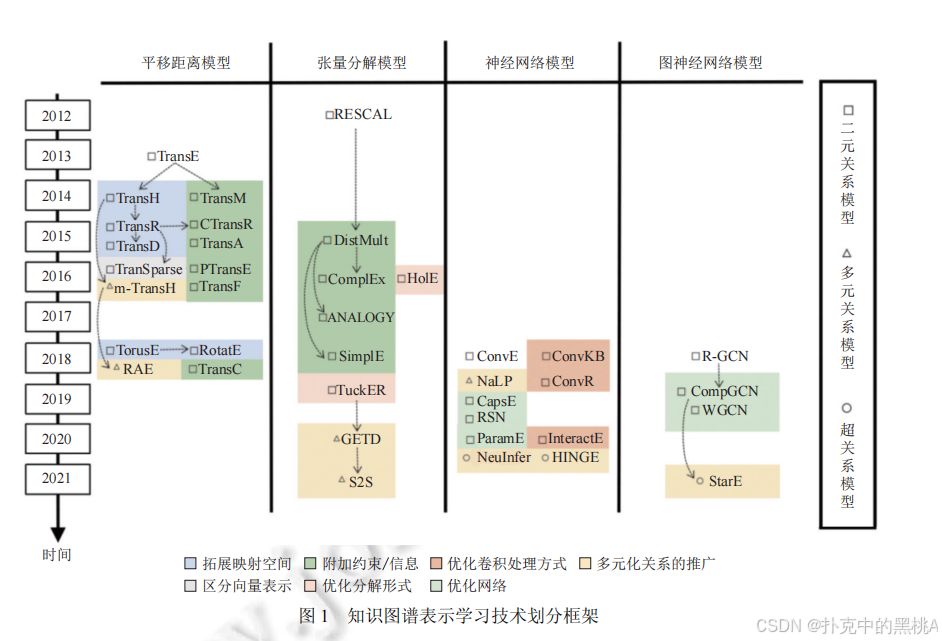
圖 1橫向劃分 “平移距離模型”“張量分解模型”“神經網絡模型”“圖神經網絡模型” 四大類,縱向按年份(2012—2021)排列關鍵模型,并通過符號(方塊、三角形、圓形)區分 “二元關系模型”“多元關系模型”“超關系模型”,同時用顏色標注 “拓展映射空間”“附加約束 / 信息”“優化卷積處理方式” 等技術優化方向,為后續具體模型的講解提供全局視角。
接下來,我們將依次詳解這四類面向二元關系的表示學習模型的原理、優化與衍生。
二元關系是知識圖譜的基礎,針對二元關系的表示學習模型已形成四大類:平移距離模型、張量分解模型、傳統神經網絡模型和圖神經網絡模型。這些模型從不同角度建模實體與關系的關聯,各有優劣。
1. 平移距離模型:基于 “空間平移” 的語義建模
平移距離模型受詞向量(Word2Vec)中 “平移不變性” 現象的啟發,將關系視為頭實體到尾實體的 “平移向量”,核心思想是 “頭實體向量 + 關系向量 ≈ 尾實體向量”,就像在地圖上,“起點坐標 + 路線向量 ≈ 終點坐標”。
(1)?經典模型:TransE
TransE 是 2013 年提出的首個平移距離模型,它將每個實體和關系映射到低維向量空間,對于三元組(h, r, t),要求 h + r ≈ t。其評分函數定義為:
f(h,r,t)=∣∣h+r?t∣∣L1?/L2??
其中,||?|| 表示 L?或 L?范數(距離),評分越低,三元組越合理。例如,對于 “(北京,到,上海)”,TransE 學習到的向量應滿足 “北京 + 到 ≈ 上海”。
TransE 的優點是簡單高效,參數少,適合大規模知識圖譜;但缺點是無法處理復雜關系,如 1-N(一個頭實體對應多個尾實體,如 “母親 - 子女”)、N-1(多個頭實體對應一個尾實體,如 “子女 - 父親”)和 N-N(多對多關系,如 “學生 - 老師”)。例如,對于 “(小明,母親,李華)” 和 “(小紅,母親,李華)”,TransE 會要求 “小明 + 母親 ≈ 李華” 和 “小紅 + 母親 ≈ 李華”,導致 “小明 ≈ 小紅”,顯然不合理。
(2)?優化方向與衍生模型
為解決 TransE 的缺陷,研究者從多個方向進行優化:
拓展映射空間
- TransH(2014):將實體和關系映射到關系專屬的超平面上,頭實體 h 和尾實體 t 在超平面上的投影 h⊥、t⊥滿足 h⊥ + d? ≈ t⊥(d?是超平面上的平移向量)。超平面通過法線向量 w?定義,投影計算為:
h⊥?=h?wrT?h?wr?
t⊥?=t?wrT?t?wr?
評分函數為:f(h,r,t)=∣∣h⊥?+dr??t⊥?∣∣22?
TransH 通過超平面區分不同關系的映射空間,能更好處理 1-N 等復雜關系,就像為不同類型的路線(如公路、鐵路)設置不同的平面地圖。 - TransR(2015):進一步將實體空間與關系空間分離,每個關系 r 對應一個投影矩陣 M?,實體向量通過 M?投影到關系空間后再進行平移:
hr?=h?Mr?
tr?=t?Mr?
評分函數為:f(h,r,t)=∣∣hr?+r?tr?∣∣22?
例如,“蘋果” 作為水果和公司時,在 “屬于 - 水果” 和 “屬于 - 公司” 關系空間中的投影不同,避免了語義混淆。 - TransD(2015):針對 TransR 中頭尾實體共享投影矩陣的問題,為頭實體和尾實體分別設計投影矩陣 M??和 M??,提高建模靈活性:
hr?=h?Mrh?
tr?=t?Mrt?
評分函數與 TransR 類似。
改進映射方式
- TorusE(2018):將向量空間從歐氏空間改為環形曲面(Torus),利用環形空間的周期性解決長距離平移問題,評分函數考慮環形空間中的最短距離。
- RotatE(2019):將向量空間擴展到復數域,將關系視為旋轉操作,即 h ⊙ r ≈ t(⊙為元素級乘法),其中 r 的模長為 1(旋轉向量特性)。這種旋轉操作能自然建模對稱關系(旋轉 0 度)、反對稱關系(旋轉 180 度)和逆關系(旋轉相反角度),例如 “朋友” 關系是對稱的(r 旋轉 0 度,h⊙r = h ≈ t,t⊙r = t ≈ h),“父子” 關系是反對稱的(r 旋轉 180 度,h⊙r ≈ t 則 t⊙r ≈ -h ≠ h)。
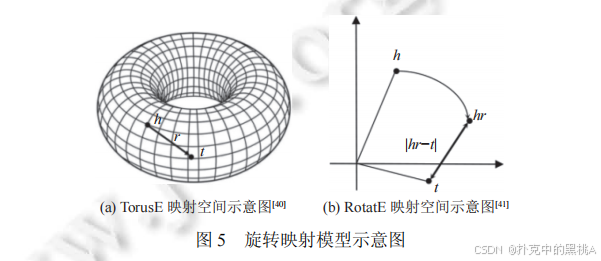
圖 5 為 “旋轉映射模型示意圖”,其中(a)是TorusE 的環形映射空間示意圖,展示實體向量在圓環表面的分布與平移邏輯;(b)是RotatE 的復數域旋轉示意圖,直觀呈現 “頭實體向量h經關系r旋轉后得到hr,且hr與尾實體向量t的距離越近,三元組越合理” 的核心思想。通過示意圖,能更清晰理解 TorusE 的 “環形空間平移” 與 RotatE 的 “復數域旋轉” 技術細節。
區分向量表示
- TranSparse(2016):針對關系的異質性(不同關系連接的實體對數差異大),用稀疏度不同的矩陣表示關系,復雜關系(連接實體多)用稠密矩陣,簡單關系用稀疏矩陣,減少參數冗余。
附加約束信息
- CTransR(2015):將同一關系的實體對聚類,為每個聚類學習專屬關系向量,增強對關系細分語義的建模。
- PTransE(2015):引入關系路徑信息,例如 “h → r1 → e → r2 → t” 可推出 “h → r → t”,通過路徑約束增強預測準確性。
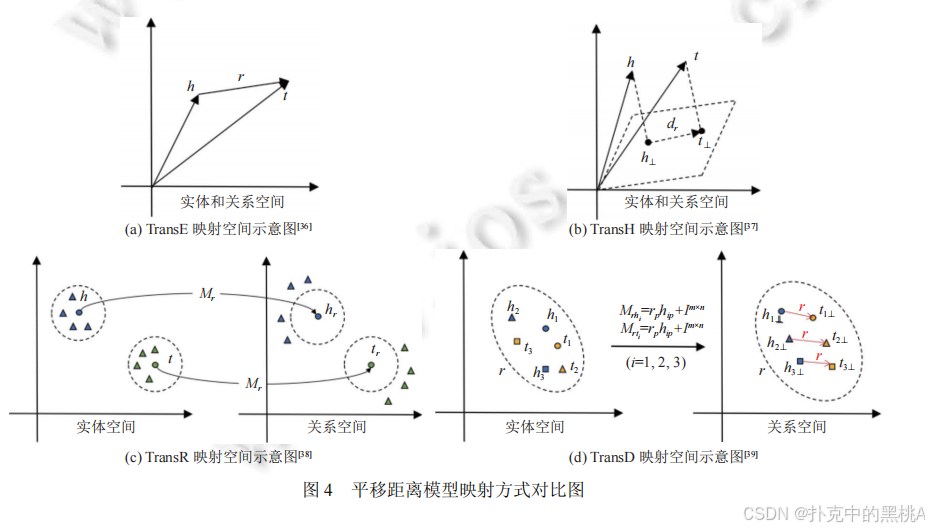
圖 4直觀展示 TransE(同一空間平移)、TransH(超平面投影)、TransR(實體 - 關系空間分離)、TransD(頭尾實體分別投影)的空間映射差異,幫助理解模型的演進邏輯。
2. 張量分解模型:基于 “矩陣分解” 的關聯捕捉
張量分解模型將知識圖譜視為一個三維張量(實體 × 實體 × 關系),其中張量元素 T (h, r, t)=1 表示三元組(h, r, t)存在,T (h, r, t)=0 表示不存在。通過分解張量,得到實體和關系的低維向量表示,就像將一個復雜的魔方拆成小方塊,通過小方塊的組合還原魔方結構。
(1)?經典模型:RESCAL
RESCAL 是 2011 年提出的首個張量分解模型,它將三元組(h, r, t)表示為實體向量與關系矩陣的雙線性乘積:
f(h,r,t)=hTMr?t
其中,M?是關系 r 的 d×d 矩陣,h 和 t 是 d 維實體向量。該模型通過矩陣 M?捕捉實體 h 和 t 之間的交互強度,評分越高,三元組越合理。
RESCAL 的優點是表達能力強,能建模多種關系類型;但缺點是參數多(每個關系有 d2 個參數),計算復雜度高,難以應用于大規模知識圖譜。
(2)?優化方向與衍生模型
為降低復雜度并增強建模能力,研究者提出了多種優化模型:
施加矩陣約束
- DistMult(2015):簡化 M?為對角矩陣(M?=diag (r)),評分函數變為:
f(h,r,t)=hTdiag(r)t=∑i=1d?hi?ri?ti?
參數數量從 d2 減少到 d,計算效率大幅提升。但對角矩陣的對稱性導致模型只能處理對稱關系(h^T diag (r) t = t^T diag (r) h),無法建模反對稱關系(如 “父子”)。 - ComplEx(2016):引入復數向量解決 DistMult 的對稱性問題,實體和關系向量為復數域向量,評分函數為:
f(h,r,t)=Re(hTdiag(r)tˉ)
其中,tˉ是 t 的共軛復數,Re (?) 表示取實部。復數運算打破了對稱性(h^T diag (r)?tˉ?≠ t^T diag(r)?hˉ),使模型能處理反對稱關系。 - ANALOGY(2017):要求關系矩陣 M?是正規矩陣(M?M?? = M??M?),并滿足關系組合的可交換性,增強對類比推理的支持,例如 “國王 - 男人 = 女王 - 女人” 的類比關系。
優化分解形式
- HolE(2016):用循環關聯運算(Circular Correlation)壓縮實體交互,h * t 的結果與關系向量 r 做點積:
f(h,r,t)=(h?t)Tr
循環關聯運算可視為矩陣乘法的壓縮形式,參數數量少且表達能力接近 RESCAL。 - SimplE(2018):為每個實體 e 設置頭嵌入 e?和尾嵌入 e?,每個關系 r 設置正向嵌入 r 和逆向嵌入 r?1,評分函數為正向和逆向三元組的平均:
f(h,r,t)=21?(hhT?diag(r)tt?+htT?diag(r?1)th?)
通過區分頭 / 尾嵌入和正 / 逆向關系,在低參數復雜度下實現對非對稱關系的建模。 - TuckER(2019):引入核心張量 W,將三元組表示為多線性乘積:
f(h,r,t)=W×1?h×2?r×3?t
其中 ×?表示第 k 維的張量乘積。核心張量 W 是共享參數,實體和關系向量維度可獨立設置,靈活性高且表達能力強。
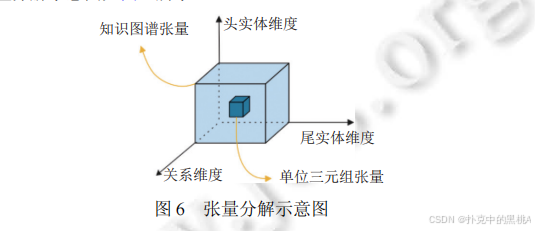
圖 6展示三維知識圖譜張量如何分解為頭實體向量、關系矩陣 / 向量、尾實體向量,直觀呈現 “整體分解為局部” 的過程,幫助理解張量分解的核心思想。
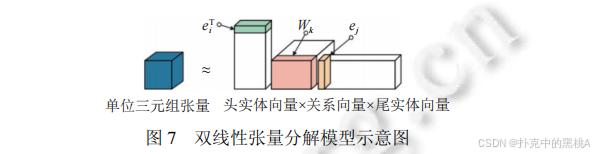
圖 7 直觀展示 “頭實體向量 × 關系向量 × 尾實體向量” 的雙線性交互,與 RESCAL、DistMult 等雙線性張量分解模型的核心思想(通過矩陣 / 張量乘積捕捉實體 - 關系關聯)高度匹配,輔助解釋這類模型的 “雙線性關聯” 本質。
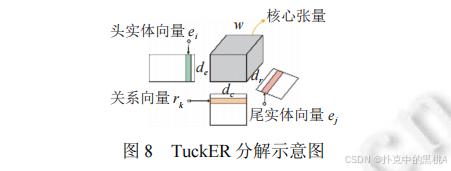
在圖8中,TuckER 通過 “核心張量 + 多線性乘積” 增強表示能力,圖 8 清晰展示頭實體、關系、尾實體向量與核心張量的交互方式,能直觀解釋 TuckER “用共享核心張量建模多維度關聯” 的創新點。
3. 傳統神經網絡模型:基于 “特征提取” 的非線性建模
傳統神經網絡模型通過非線性變換提取三元組的深層特征,捕捉實體與關系的復雜關聯,就像用高精度掃描儀提取 “實體 - 關系” 圖案的細節特征,再通過特征匹配進行預測。
(1)?卷積神經網絡(CNN)
卷積神經網絡擅長提取局部特征,在知識圖譜表示學習中,通過卷積層捕捉實體與關系向量的局部交互模式:
- ConvE(2018):將頭實體 h 和關系 r 的向量拼接后重塑為二維矩陣(如 d×k),用多個卷積核提取特征,經全連接層轉換后與尾實體 t 的向量做點積:
f(h,r,t)=g(W?g([h;r]°ω)+b)?t
其中 [h; r] 是向量拼接,°是卷積運算,g 是激活函數。ConvE 首次將 CNN 用于鏈接預測,通過二維卷積捕捉局部特征,效果優于傳統平移和張量模型。 - ConvKB(2018):直接拼接頭實體 h、關系 r、尾實體 t 的向量為 d×3 矩陣,用卷積層提取三者的整體關聯特征,避免 ConvE 僅關注 h 和 r 的缺陷:
f(h,r,t)=g(W?g([h;r;t]°ω)+b) - ConvR(2019):將關系 r 的向量作為卷積核,對頭實體 h 的向量進行卷積,增強 h 和 r 的交互:
f(h,r,t)=g(W?g(h°ωr?)+b)?t - InteractE(2020):優化向量拼接方式,通過循環交替、元素交叉等方式增強 h 和 r 的交互,并使用循環卷積進一步提取特征,提升特征利用率。
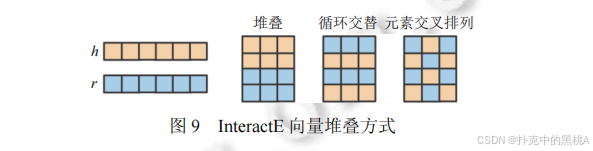
InteractE 的核心優化點是 “增強實體與關系的向量交互”,圖 9 對比了不同的向量堆疊策略(堆疊、循環交替、元素交叉),能輔助解釋該模型如何通過更精細的向量排列,提升卷積層對特征的提取能力。
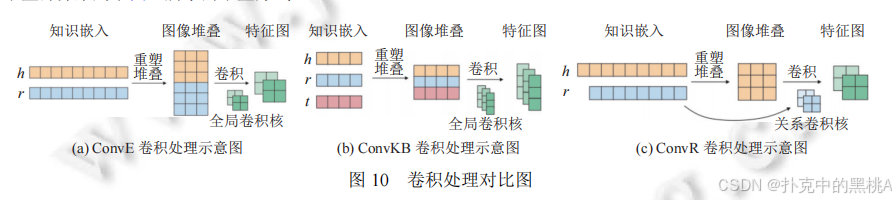
圖 10展示 ConvE(h 和 r 拼接卷積)、ConvKB(h、r、t 拼接卷積)、ConvR(用 r 作為卷積核)的不同卷積操作,直觀呈現特征提取方式的演進。
(2)?其他神經網絡模型
- CapsE(2019):引入膠囊網絡(Capsule Network),用向量輸出的膠囊代替傳統神經元的標量輸出,更好捕捉特征的空間關系和層次結構,評分函數基于膠囊網絡的輸出向量 norm:
f(h,r,t)=∣∣capsnet(g([h,r,t]?ω))∣∣ - RSN(2019):結合循環神經網絡(RNN)和殘差學習,捕捉知識圖譜中的長路徑依賴,通過多步關系路徑的上下文信息輔助預測:
f(h,r,t)=σ(rsn(h,p,r)?t)
其中 p 是關系路徑,rsn 是循環殘差網絡模塊。
4. 圖神經網絡模型:基于 “信息傳播” 的結構建模
圖神經網絡(GNN)專為圖結構數據設計,通過 “信息傳播” 機制聚合鄰居節點的信息,更新節點表示,能有效捕捉知識圖譜的局部結構特征,就像一個人通過朋友的反饋和評價,不斷完善對另一個人的認識。
(1)?核心思想
GNN 的核心是迭代更新實體向量:每個實體通過聚合其鄰居實體(與該實體有直接關系的實體)的信息,更新自身向量。對于知識圖譜,鄰居信息不僅包括實體,還包括連接它們的關系,因此模型需同時建模實體和關系的交互。
(2)?經典模型
- R-GCN(2017):首個用于知識圖譜的圖卷積網絡,為每個關系 r 設計轉換矩陣 W?,實體向量更新公式為:
hv(k)?=f(∑(u,r)∈N(v)?Wr(k)?hu(k?1)?+W0(k)?hv(k?1)?)
其中 N (v) 是實體 v 的鄰居,W?是自環矩陣(保留自身信息)。R-GCN 通過關系轉換矩陣建模關系信息,但關系數量增多時會導致參數爆炸。 - CompGCN(2020):優化 R-GCN 的參數問題,用基向量組合表示關系轉換矩陣,并通過減法、乘法等組合函數 φ(h?, r) 聚合鄰居信息:
hv(k)?=f(∑(u,r)∈N(v)?Wλ(r)(k)??(hu(k?1)?,hr(k?1)?))
其中 λ(r) 是關系 r 的基向量索引,φ 是實體 - 關系組合函數。CompGCN 參數更少且表達能力更強。 - WGCN(2019):引入關系權重,為不同關系的鄰居分配不同聚合權重,權重由關系類型決定,增強對重要關系的關注。
- KBGAT(2019):結合圖注意力機制(GAT),通過注意力層計算鄰居的權重,重要鄰居(對當前實體影響大的鄰居)的信息權重更高,就像在朋友評價中,更重視親密朋友的意見。
(3)?與其他模型的區別
圖神經網絡模型采用 “編碼 - 解碼” 結構:編碼階段通過信息傳播學習實體向量,解碼階段用評分函數(如 TransE、DistMult)進行鏈接預測。這種分離架構使 GNN 的表示學習更靈活,可適配不同的預測任務,而平移距離、張量分解等模型的表示學習與預測過程通過同一評分函數綁定。

表 1像 “二元關系模型對比表”,匯總四類模型的代表模型、評分函數、優化方向和核心優缺點,例如 TransE 的評分函數為 L?/L?范數,優化方向是拓展映射空間,優點是簡單高效,缺點是無法處理復雜關系。
四.面向多元化關系的表示學習模型:從二元到多元的擴展
現實世界的知識往往包含多個實體和關系,因此需要將二元關系模型擴展到多元關系和超關系場景。這種擴展不僅是表示形式的變化,更需要調整建模邏輯以捕捉復雜關聯。
1. 多元關系的表示學習模型
多元關系用角色 - 鍵值對表示,模型需處理多個實體和關系的交互,其核心挑戰是如何聚合多個角色 - 鍵值對的信息,并保持它們之間的關聯。
(1)?平移距離模型的擴展
- m-TransH(2016):將 TransH 擴展到多元關系,為每個角色 - 鍵值對(r?, v?)定義超平面,實體 v?在超平面上的投影與角色向量 r?滿足平移約束。通過元關系(Meta-relation)聚合所有角色 - 鍵值對的信息,整體評分函數為:
f(r,t)=?∑ρ∈M(Rr?)?ar?(ρ)Pnr??(t(ρ))+br??2
其中 M (R?) 是角色集合,a?(ρ) 是權重,P 是投影函數。m-TransH 是首個多元關系模型,但嚴格的位置約束導致信息丟失,且無法預測關系。 - RAE(2018):在 m-TransH 中引入多層感知器(MLP)建模實體相關性,將實體向量輸入 MLP 得到關聯特征,再融入評分函數。RAE 支持多實體缺失預測,但仍局限于實體預測,無法處理關系缺失。
(2)?張量分解模型的擴展
- GETD(2020):將 TuckER 的三階張量擴展為(N+1)階張量(N 為元數),用張量環分解(Tensor Ring Decomposition)簡化核心張量,降低計算復雜度。例如,三元關系(N=3)的評分函數為:
f(ir?,i1?,...,in?)=W^×1?rir??×2?ei1??×3?...×n+1?ein??
GETD 需為不同元數的知識單獨訓練模型,泛化性差。 - S2S(2021):將實體和關系向量分割為 N 個片段(N 為最大元數),不同元數的知識共享片段,通過稀疏核心張量聚合信息。例如,實體 e 的向量為 [e?, e?, ..., e?],元數為 k 的知識使用前 k 個片段。S2S 支持混合元數訓練,但無法區分核心與輔助關系。
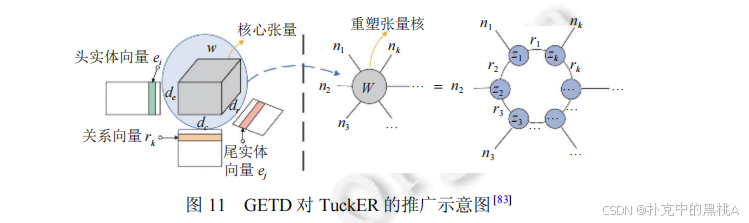
GETD 是針對多元關系的張量分解擴展,核心是將 TuckER 的 “三階張量” 推廣到 “N+1 階張量”(N 為多元關系元數)。圖 11 展示了 GETD 如何基于 TuckER 的核心張量進行擴展,輔助解釋 “多元關系下的張量分解邏輯”。
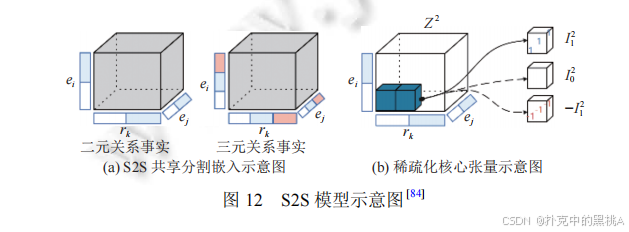
S2S 的創新點是 “共享嵌入片段 + 稀疏核心張量”,支持混合元數的多元關系建模。圖 12(a)展示二元 / 三元關系的 “共享分割嵌入”,圖 12(b)展示 “稀疏化核心張量”,能直觀解釋 S2S 如何在多元場景下優化參數與提升泛化性。
(3)?傳統神經網絡模型的擴展
- NaLP(2019):將角色 - 鍵值對的向量拼接后輸入卷積層,提取特征后用全連接層輸出評分。NaLP 首次將 CNN 用于多元關系,但平等對待所有角色 - 鍵值對,忽略核心關聯。
- NaLP-Fix(2020):在 NaLP 基礎上優化負采樣策略,提高模型穩定性,但未解決核心關聯缺失問題。
- HypE(2021):為不同元數設計專用卷積核,增強對特定元數知識的建模,但靈活性不足,無法處理可變元數。
2. 超關系的表示學習模型
超關系保留主三元組和限定詞,模型需區分核心與輔助信息,其核心挑戰是如何有效融合主三元組與限定詞的關聯。
(1)?傳統神經網絡模型的擴展
- NeuInfer(2020):分別計算主三元組的有效性得分和主三元組與限定詞的兼容性得分,加權求和得到總評分:
f(h,r,t,Q)=α?fmain?(h,r,t)+(1?α)?fcomp?(h,r,t,Q)
其中 f????是主三元組評分,f???是兼容性評分(主三元組與每個限定詞的交互得分)。NeuInfer 首次建模超關系,但特征提取較簡單。 - HINGE(2020):將主三元組(h, r, t)與每個限定詞(q?, q?)拼接為五元組(h, r, q?, q?, t),用卷積層提取特征后進行最小池化,聚合所有限定詞的信息:
f(h,r,t,Q)=minq∈Q?fconv?(h,r,qn?,qv?,t)
HINGE 通過卷積捕捉主三元組與限定詞的交互,但卷積操作和順序訓練導致時間復雜度高,難以應用于大規模圖譜。
(2)?圖神經網絡模型的擴展
- StarE(2021):擴展 CompGCN,將限定詞信息納入實體向量更新過程,實體 v 的向量更新公式為:
hv?=f(∑(u,r)∈N(v)?Wλ(r)??r?(hu?,γ(hr?,hq?)vu?))
其中 γ(h?, h_q) 融合關系和限定詞向量,φ?是組合函數。StarE 在解碼階段可搭配 ConvE、Transformer 等模型,在超關系預測中效果最佳,證明了 GNN 對復雜結構的建模能力。
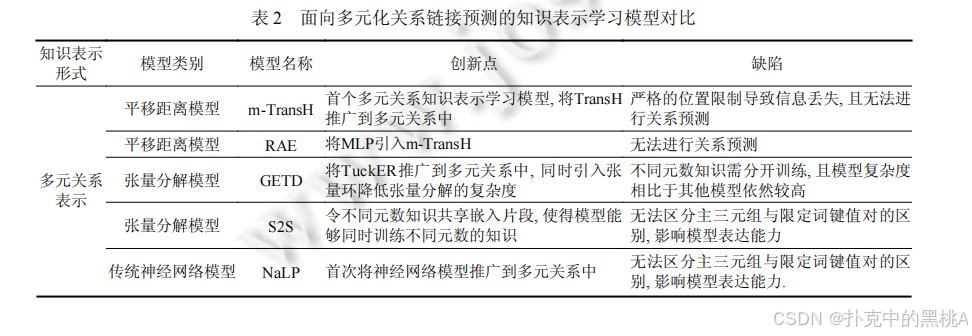
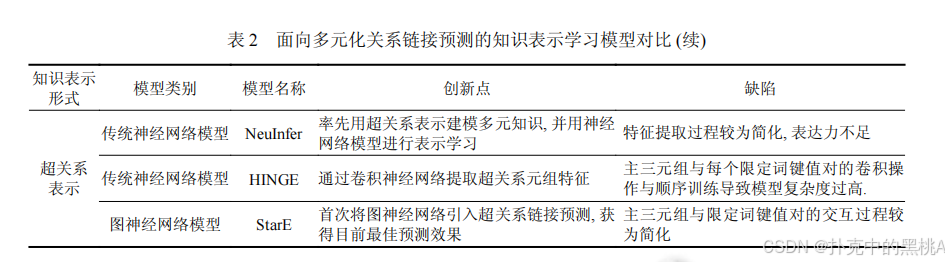
表 2這張表像 “多元化關系模型對比表”,匯總多元和超關系模型的知識表示形式、模型類別、創新點和缺陷,例如 StarE 的創新點是引入 GNN 處理超關系,缺陷是主三元組與限定詞的交互較簡單。
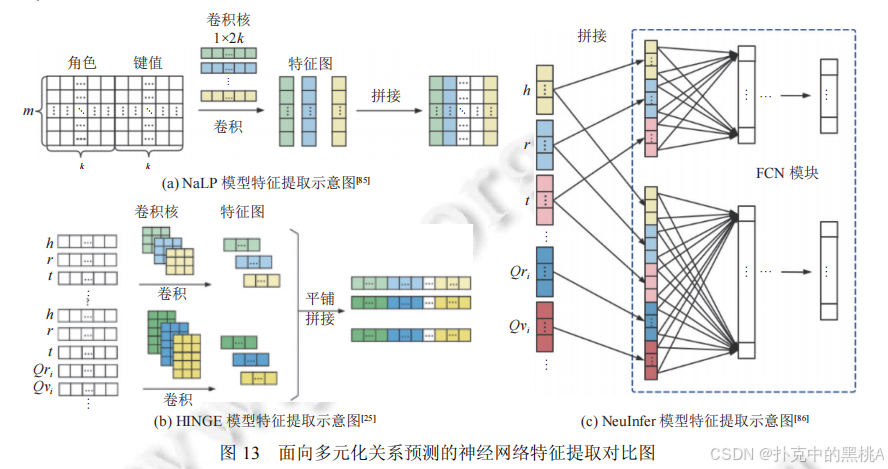
圖 13這張圖像 “多元化模型特征提取對比圖”,展示 NaLP(多元關系平等處理)、NeuInfer(主三元組 + 兼容性評分)、HINGE(主三元組與限定詞卷積)的特征提取流程,直觀呈現從多元到超關系的建模升級。
五.實驗對比與分析:不同模型的 “實戰表現”
為客觀評估模型性能,需在標準數據集上進行實驗,通過統一指標對比不同模型的鏈接預測效果。本節將介紹常用數據集、評測指標,并分析實驗結果。
1. 常用數據集
(1)?二元關系數據集
- FB15k:從 FreeBase 抽取,包含 14951 個實體、1245 個關系,訓練集 483142 個三元組。存在數據泄露(測試集含訓練集的逆向三元組)。
- WN18:從 WordNet 抽取,包含 40943 個實體、18 個關系,聚焦詞匯語義關系。同樣存在數據泄露。
- FB15k-237:FB15k 的優化版,刪除 237 個核心關系外的冗余關系,解決數據泄露問題。
- WN18RR:WN18 的優化版,刪除冗余關系,保留 11 個關系,難度更高。
- YAGO3-10:從 YAGO3 抽取,包含 123182 個實體、37 個關系,實體數多且含文本屬性,數據泄露少。
(2)?多元關系數據集
- JF17K:從 FreeBase 抽取,包含 28645 個實體、322 個關系,多元知識占比 45.9%,但存在嚴重數據泄露(測試集 44.5% 主三元組在訓練集)。
- Wikipeople:從 Wikidata 抽取,聚焦人物相關知識,多元知識占比僅 2.6%,測試不充分。
(3)?超關系數據集
- WD50K:從 Wikidata 抽取,包含 47156 個實體、532 個關系,超關系知識占比 13.6%,刪除泄露數據,更具挑戰性。其子集 WD50K (33)、WD50K (66)、WD50K (100) 的超關系占比分別為 31.2%、64.5%、100%,用于測試模型對超關系比例的適應性。
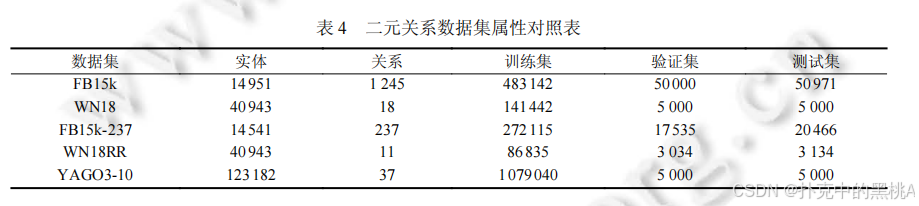
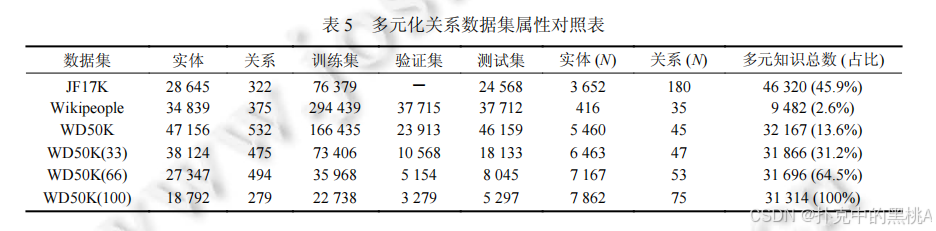
表 4、表 5:這兩張表像 “數據集屬性表”,匯總二元關系數據集(表 4)和多元化關系數據集(表 5)的實體數、關系數、訓練 / 驗證 / 測試集規模等關鍵屬性,方便對比數據集特點。
2. 評測指標
鏈接預測的核心是對候選實體或關系排序,常用指標包括:
- 平均秩(Mean Rank, MR):正確答案在預測結果中的平均排名,值越小越好。但對異常值敏感,例如一個排名 1000 的結果會大幅拉高平均值。
- 平均倒數秩(Mean Reciprocal Rank, MRR):正確答案排名倒數的平均值,值越大越好。MRR = (1/|Q|)Σ(1/rank (q)),對異常值更穩健。
- 命中比率(Hits@K):排名≤K 的正確答案比例,值越大越好。常用 K=1、3、5、10,Hits@1 更關注 top1 準確性。
例如,若預測結果中正確答案的排名為 3,則其倒數秩為 1/3,Hits@1=0,Hits@3=1。MRR 和 Hits@K 是目前最常用的指標,能較全面反映模型性能。
3. 實驗結果分析
(1)?二元關系模型對比
- 平移距離模型:RotatE 表現最佳,在 FB15k-237 的 Hits@1 達 0.426,MRR 達 0.336,旋轉操作使其能處理多種關系類型;TransE 因無法處理復雜關系,效果較差。
- 張量分解模型:ComplEx 和 TuckER 效果突出,TuckER 在 YAGO3-10 的 MRR 達 0.544,共享核心張量增強了表達能力;DistMult 因對稱性限制,在非對稱關系數據集上效果較差。
- 傳統神經網絡模型:ConvR 在多個數據集表現優異,ConvE 次之,ConvKB 因簡單卷積效果較差;CapsE 和 RSN 效果不穩定,仍需優化。
- 圖神經網絡模型:CompGCN 在復雜數據集上優勢明顯,證明信息傳播機制能有效捕捉圖結構特征。
(2)?多元關系模型對比
- S2S 效果最佳,在 JF17K 的 MRR 達 0.528,共享嵌入片段解決了元數限制;GETD 在特定元數上表現好,但泛化性差;NaLP 因平等處理角色 - 鍵值對,效果最差。
(3)?超關系模型對比
- StarE(+Transformer)效果最優,在 WD50K (100) 的 Hits@1 達 0.588,MRR 達 0.654,超關系占比越高,優勢越明顯;HINGE 次之,但復雜度高;NaLP-Fix 因未區分主次關系,效果最差。
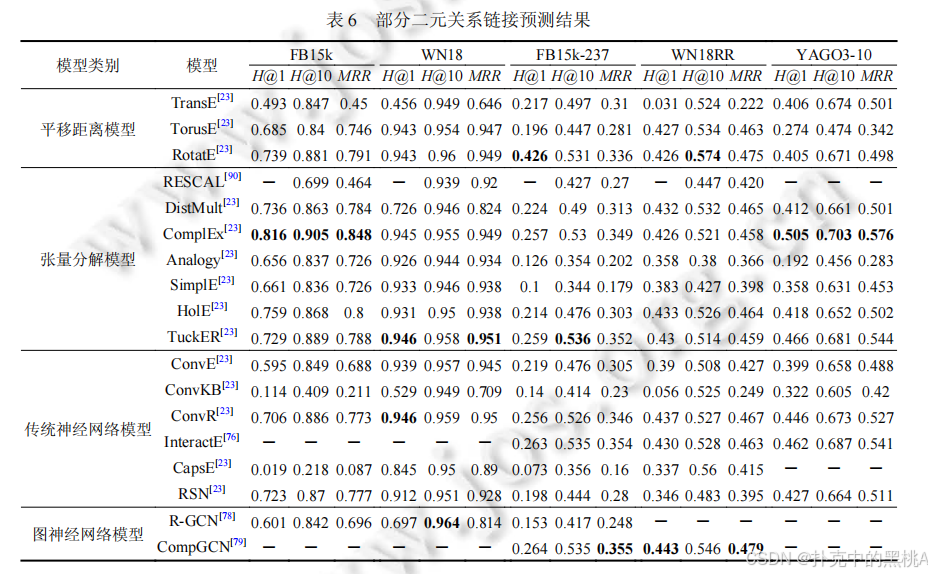
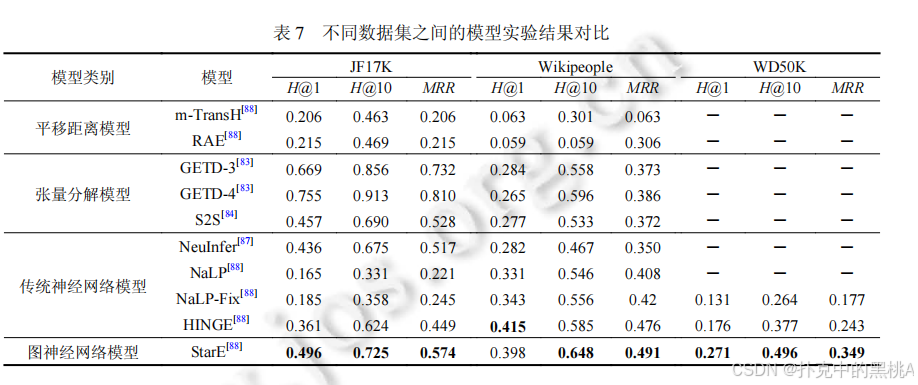
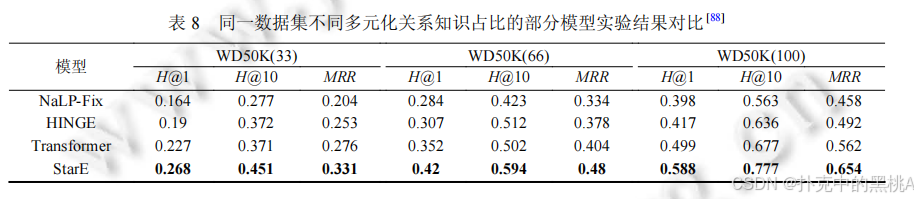
表 6、表 7、表 8:這些表像 “實驗結果對比表”,匯總不同模型在各數據集上的 MRR、Hits@1、Hits@10 指標,加粗數據為最優結果,直觀呈現模型性能差異。
(4)?關鍵結論
- 模型表達能力:圖神經網絡 > 傳統神經網絡 > 張量分解 > 平移距離(整體趨勢,具體因數據集而異)。
- 知識表示形式:超關系 > 多元關系 > 二元關系,更精準的知識表示能提升預測效果。
- 效率與效果平衡:平移距離模型效率最高,適合大規模圖譜;圖神經網絡效果最佳,但計算復雜度高。
六.未來研究方向:挑戰與機遇
盡管知識圖譜表示學習已取得顯著進展,但仍面臨諸多挑戰,未來可從以下方向突破:
1. 模型優化:提升可解釋性與可擴展性
(1)?增強可解釋性:現有神經網絡模型多為 “黑箱”,預測結果難以解釋。未來需結合邏輯規則(如將路徑約束融入 GNN),或設計可解釋的注意力機制,讓模型 “說明” 預測依據,就像導航軟件不僅給出路線,還解釋選擇理由。
(2)?提高可擴展性:大規模知識圖譜(實體數超百萬)對模型效率要求高。需研究稀疏參數化(如稀疏張量分解)、分布式訓練(如分塊處理實體)、在線學習(動態更新模型)等技術,降低計算復雜度。
2. 知識表示形式:融合更多結構與信息
(1)?融合層次與路徑信息:知識圖譜中的層次結構(如 “動物→哺乳動物→貓”)和關系路徑(如 “朋友的朋友”)蘊含豐富語義,未來需設計新表示形式整合這些信息,例如將層次約束作為正則項融入模型。
(2)?引入多模態信息:實體的文本描述、圖像等多模態信息可輔助關系預測,需設計跨模態表示學習模型,實現 “文本 - 圖像 - 知識” 的聯合建模。
3. 問題作用域:針對特定場景定制模型
(1)?低資源場景:小眾領域知識圖譜數據稀疏,需開發少樣本 / 零樣本學習模型,利用遷移學習(如從通用圖譜遷移知識)或元學習(快速適應新關系)提高預測效果。
(2)?動態知識圖譜:實體和關系隨時間變化(如 “總統” 關系的更替),需設計時序表示學習模型,捕捉知識的動態演化,就像實時更新的導航地圖。
(3)?跨語言知識圖譜:多語言知識圖譜的鏈接預測需解決語言差異,需設計跨語言表示模型,實現不同語言實體的對齊與關聯預測。
七.總結
知識圖譜表示學習是鏈接預測的核心技術,通過將實體和關系轉換為向量,實現了知識的可計算性。本文從知識表示形式和建模方法兩個維度,系統解讀了面向鏈接預測的表示學習方法:
- 知識表示形式:從二元關系到多元關系再到超關系,演進趨勢是更精準地刻畫復雜知識,保留更多語義關聯。
- 建模方法:平移距離模型基于空間平移,張量分解模型基于矩陣分解,傳統神經網絡模型基于特征提取,圖神經網絡模型基于信息傳播,四類模型各有優劣,圖神經網絡在復雜場景中表現最佳。
實驗結果表明,超關系表示形式結合圖神經網絡模型能取得最優預測效果,但模型的可解釋性和可擴展性仍需提升。未來,隨著技術的發展,知識圖譜表示學習將在低資源、動態、跨模態等場景中發揮更大作用,為智能系統提供更完整、更可靠的知識支撐。
通過不斷優化模型、豐富知識表示形式、拓展應用場景,知識圖譜這張 “知識地圖” 將越來越完善,為人工智能的認知智能發展奠定堅實基礎。
尾
本期技術解構至此。
論文揭示的方法論范式對跨領域技術實踐具有普適參考價值。下期將聚焦其他前沿成果,深入剖析其的突破路徑。敬請持續關注,共同深挖工程實現脈絡,淬煉創新底層邏輯,在學術與工程融合中洞見技術演進規律,推動領域范式持續進化。
,規則(Rules))

![前沿重器[74] | 淘寶RecGPT:大模型推薦框架,打破信息繭房](http://pic.xiahunao.cn/前沿重器[74] | 淘寶RecGPT:大模型推薦框架,打破信息繭房)

的崛起——為什么“會寫Prompt”成了新技能?)

)


)









