前沿重器
欄目主要給大家分享各種大廠、頂會的論文和分享,從中抽取關鍵精華的部分和大家分享,和大家一起把握前沿技術。具體介紹:倉頡專項:飛機大炮我都會,利器心法我還有。(算起來,專項啟動已經是20年的事了!)
2024年文章合集最新發布!在這里:再添近20萬字-CS的陋室2024年文章合集更新
往期回顧
前沿重器[69] | 源碼拆解:deepSearcher動態子查詢+循環搜索優化RAG流程
前沿重器[70] | Query優化前沿綜述:核心方法解讀與個人實戰啟示
前沿重器[71] Context Engineering深度解讀:范式躍遷,還是概念包裝
前沿重器[72] 大模型“外腦”揭秘:Context Engineering綜述
前沿重器[73] | 深入技術深水區:RAG與Agent如何實現精準個性化
大概半年前,我寫了一篇大模型在淘寶電商推薦系統中的應用(前沿重器[59] | 淘寶LLM落地電商推薦實踐啟示),盡管文章已經比較早,但里面的應用思路還是比較值得參考的,最近淘寶直接寫了一篇完整的技術報告,和之前我分享的這篇文章(前沿重器[59] | 淘寶LLM落地電商推薦實踐啟示)有很多相似之處,然而也針對具體實現做了很多有用的改進,實踐性更強,文章詳細地講述了大模型和推薦系統之間的協作,并給出了很多訓練和對齊策略,今天就來給大家介紹一下這篇文章。
論文:RecGPT Technical Report
鏈接:https://arxiv.org/pdf/2507.22879
目錄:
聊一聊引言
具體實現
用戶興趣挖掘
商品標簽預測
商品搜索
個性化推薦解釋生成
人類-LLM協同評判器
實驗
個人小結
聊一聊引言
引言中有透露作者在這方向上的研究,所以我還是想講一講。
理想的推薦系統應把用戶的(通常是隱含的)意圖與最相關的商品或內容匹配,讓用戶以最小的努力獲得最大的體驗價值,所以其核心的目標便是表征和匹配,之前的核心思路都是通過特征工程和模型架構的優化來實現,而這些優化的核心目標都是通過點擊等行為作為媒介來實現的,這種媒介缺少更為深入的理解,只能強化已有行為相關的內容,這會放大信息繭房效應,馬太效應,因此迫切需要能突破這種比較淺層的相關性的模式,實現更為深入的用戶興趣理解和挖掘。
沒錯,說到深層,說到理解,便要說今年以來的大模型了。大模型能基于他的推理能力,分析并推理出用戶更為深層的偏好信息,這便是引入大模型的核心邏輯,無論是逐漸替代傳統推薦系統中各模塊的主要工作,還是直接端到端甚至是生成式的推薦系統,其生效的基點也很大程度在于此。
基于這個核心邏輯,文章構造了一套框架RecGPT,旨在讓大模型能真正應用到推薦系統的生產環境中,并帶來有效收益。
要想一個東西在某個場景有用,需要盡量理解到,這個東西能解決這個場景下的哪些問題,此時才能真正的有用,強行套用可能是創新,但有沒有效,有多大效,就變得并不明確。
具體實現
RecGPT 的核心思想是:在推薦鏈路的各個階段引入大語言模型,實現用戶興趣理解、商品預測,并為最終結果生成用戶友好的推薦解釋。根據這個思想,作者把RecGPT分為4個模塊。
用戶興趣挖掘。對用戶的終身多行為序列進行顯式興趣挖掘,以識別多樣化的用戶興趣模式。
商品標簽預測。基于用戶興趣挖掘結果,預測代表用戶潛在偏好分布的商品標簽。
商品檢索。標簽感知語義檢索方法將預測標簽映射到具體商品,同時引入用戶行為協同信號,平衡語義與協同相關性。
推薦解釋生成。綜合用戶興趣與推薦商品,生成貼近個體用戶偏好的個性化、友好解釋,提升系統透明度與用戶體驗。
這個流程設計有兩個優勢。
可對各階段中間過程及模型性能進行可解釋監控。
可通過過程級監督引入專家知識,實現對各組件的有針對性優化。
用戶興趣挖掘
傳統的用戶畫像建模基本是使用固定、統計的隱式用戶特征,難以形成顯式、動態的興趣,而生成式用戶畫像(Generative User Profiling)可以解決這個問題。
但是生成式用戶畫像會面臨兩個難題。
上下文窗口限制。推薦系統的用戶行為多樣且復雜,大模型并不能吃下超長序列。對此,文章開發了可靠行為序列壓縮(Reliable Behavioral Sequence Compression),保留關鍵信息。
領域知識缺口。這個可以通過多階段任務對齊框架來補充領域知識。
可靠行為序列壓縮主要有幾個流程。
可靠行為提取。關注高參與度的意圖反饋行為,如“收藏”、“購買”、“加購”,以及主動性強的行為,如“搜索查詢”,而不關注點擊這種噪音比較多的行為。
分層行為壓縮。對超長用戶序列,將多源異構行為壓縮為統一序列格式,商品主要保留商品名稱、類別、品牌等核心屬性,序列級根據不同時間段進行聚合。
為增強用戶興趣大模型在興趣挖掘任務上的能力,此處使用了多階段任務對齊,分階段訓練出和人類對齊的興趣模型。
設計16個預備子任務,增強通用 LLM 在領域基礎上的關鍵能力,如關鍵信息提取、復雜用戶畫像分析、因果推理等。受課程學習啟發,按難度與依賴關系拓撲排序子任務,逐步引導模型掌握復雜任務。
推理增強預對齊。利用DeepSeek-R1的先進推理能力生成高質量興趣挖掘訓練數據,經人工精心篩選,將初始 9.0 萬樣本精煉為 1.9 萬高質量數據集,用于知識蒸餾。
自訓練演化。為進一步提升模型能力上限,我們提出自訓練范式,模型自我生成訓練數據并用于迭代優化,形成能力增強反饋環。為高效過濾自生成輸出并低成本評估模型性能,采用人類-LLM協同范式,利用LLM-as-a-Judge能力進行數據質量管理與評估,顯著提升整理效率并降低人工標注成本。
這里有個細節,如何避免大模型的幻覺問題,這里進行了多維度的拒絕采樣。
意愿性:興趣是否真實反映用戶自發性偏好,而非外部義務。
合理性:興趣是否有充分行為證據支持,分為強相關、弱相關、無相關、幻覺四類。
至于部署上,離線使用模型預測用戶興趣偏好,平均每用戶預測 16.1 個興趣。在線部署中,每兩周迭代優化模型并刷新用戶興趣,確保興趣時效性并精準捕捉用戶個性化動態變化。
商品標簽預測
標題是簡單的,但實際的任務和標題存在偏差:利用大語言模型基于推斷出的用戶畫像指導商品標簽預測。注意,用戶畫像指導的商品預測標簽,后續是需要進行搜索的,因此這里讓兩者的語義空間盡可能接近,這樣后續的檢索就會更簡單。這里的思路是,首先對商品標簽進行多階段任務對齊,確保其有效理解商品相關上下文,然后接著引入增量學習方法,使模型持續適應用戶興趣與新品趨勢。
首先是商品標簽預測任務對齊,這里的對齊,是要增強大模型對商品的理解能力,強化大模型在應用于個性化商品預測任務時,在領域需求差異中的體現能力。這里比較突出的一點是提示詞的設計。提示中會引入以下約束,通過這些多約束提示,大模型會輸出(標簽,關聯興趣,理由)三元組列表,用于后續商品檢索。
興趣一致性:標簽與用戶興趣保持對齊。
多樣性:至少生成 50 個標簽,保證跨類目多樣性。
語義精度:避免模糊或過于寬泛描述。
時效性:優先新品,避免近一月已交互商品。
季節性:結合時間戳生成季節相關標簽。
當然,這一步也需要考慮幻覺和噪音的問題,這里引入多維度拒絕采樣,評估標準包括相關性、一致性、具體性、有效性。僅當標簽滿足所有標準時才視為合格樣本,否則標記為不合格。
然后是增量學習,這是為適應在線環境中用戶興趣與數據分布的動態變化(如季節變化),文章采用每兩周一次的增量學習。每次更新周期內,選取過去 14 天用戶在線交互記錄(點擊、購買等)作為增量訓練數據源。
但這里,真實數據會存在兩大挑戰:一個是噪聲(如誤點擊、促銷假象),另一個是固有不平衡,主導興趣標簽可能傾斜訓練,降低多樣性并加劇馬太效應。這里,在數據處理上,采取了3個措施。
數據凈化。依據相關性與時效性標準,使用 QwQ-32B 作為自動評判器進行數據清洗。相關性分析行為與興趣一致性,濾除低質量記錄;時效性判斷商品是否適合當前或即將到來的季節。
興趣補全。將有效交互映射為(標簽,關聯興趣,理由)三元組。使用QwQ-32B基于用戶畫像、歷史行為與需求提示進行深度推理,推斷底層興趣偏好及理由。商品標題直接作為標簽,從而將行為數據轉化為結構化訓練樣本。
數據平衡。設計兩階段重采樣策略:首先每用戶隨機選取 80 個商品標簽對應行為記錄,保證多樣性;其次使用預訓練Tag-to-Cate模型將標簽映射為類目,按類目二次采樣(每類最多 2 樣本),實現類別平衡。
商品搜索
大模型生成的標簽,雖然能提供豐富的語義信息,但是這個抽象的語義無法映射到對應的目標商品,因此,需要引入標簽感知方法,同時整合了協同過濾機制,提出統一的用戶-商品-標簽檢索框架,協同增強語義推理與協同行為洞察,最終提升在線推薦系統的準確性與效率。
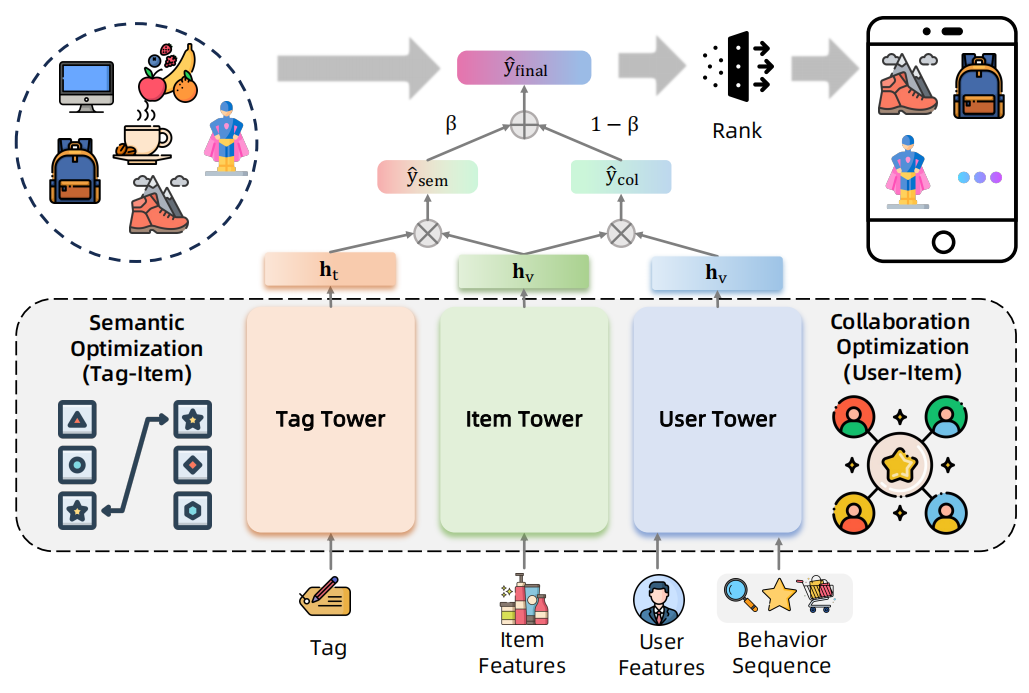
商品塔內是稀疏類別特征(ID、類目、品牌等)與連續數值特征(價格、銷量等),用戶塔內通過多行為序列建模捕捉用戶偏好,輸入包括用戶 ID 與多行為交互序列(點擊、購買等),標簽塔將商品標簽分詞后取均值池化。
這個模型會形成連個分數,標簽和商品的語義分數,用戶和商品的協同分數,優化也會分這兩個分別進行優化,協同優化師最大化正樣本用戶-商品交互似然,最小化負樣本似然,語義優化則是最大化基于用戶偏好生成的標簽與商品間語義相關性。
然后推理的話,動態融合用戶塔與標簽塔輸出,實現可控的協同-語義推薦,然后就可以去召回商品,這個訓練出來的模型能兼顧相關性與語義一致性。
個性化推薦解釋生成
最后一步是給用戶解釋為什么要給他推薦這個。這一步的重點是任務對齊與離線生產策略。
任務對齊需要經過兩階段訓練,首先使用DeepSeek-R1生成的推理增強數據集進行預對齊(推理增強預對齊),隨后在自生成數據上進行訓練,數據經人類或 LLM 評判器嚴格過濾(自訓練演化),最終實現與人類對齊的解釋生成性能。
提示工程上,給定用戶興趣與推薦商品信息(標題、標簽等),執行兩步生成合理推薦解釋:
上下文理解:分析輸入信息,理解用戶興趣與商品特征。
解釋生成:若商品與用戶興趣存在合理關聯,則生成對話風格短語呈現關聯;否則則基于商品本身特征生成解釋。
風格層面,提示模板要求解釋風格簡潔、有趣、網絡化,禁止夸大、虛假、套話、重復標題等。
這個解釋生成可以說是非常真實了,在內容可解釋時則直接解釋兩者的關聯,但是出現一些偶然情況,如庫內沒有,或者是顯式匹配度不足時,可以考慮直接解釋商品本身的特征,例如比較普適的優點。
然而,每個內容都進行詳細解釋,在在線環境下肯定不現實,耗時撐不住,因此需要用離線的方式進行。從用戶興趣出發,利用已收集的標簽-興趣關聯對,將商品標簽映射至對應類目,建立用戶興趣與商品類目間的關聯,此時就只對興趣-商品生成解釋,而不需要考慮用戶和所有商品的排列組合,生成后建表記錄,在線推薦時,通過當前推薦商品與用戶興趣匹配,直接查表獲取預生成解釋,實現毫秒級實時解釋返回。
人類-LLM協同評判器
前文有大量提到需要進行樣本篩選、模型訓練等工作,這里需要對DeepSeek-R1或自訓練模型生成的樣本進行人工篩選,以對齊人類標準,受“LLM-as-a-Judge”在各類自然語言理解與生成任務中優異表現的啟發,我們采用該范式,讓LLM擔任智能評判器,實現自動化評估,從而降低成本、提高效率。(有關這塊的研究,我曾經寫過一篇綜述的解讀:前沿重器[65] | 大模型評判能力綜述)
但此處,存在兩個比較大的挑戰。
認知偏差:說白了,人對用戶偏好的理解和大模型的理解并不對齊。
時間錯位:推薦生態的動態性導致靜態LLM評判器與不斷演化的真實條件失配。主要是對用戶行為模式的演化、商品特征的動態變化、評價標準的更新不夠靈敏。
這些動態因素累積削弱靜態LLM評判器的評估能力,引入系統偏差,因此文章提出了人類-LLM協同評判系統(Human-LLM Cooperative Judge System),其核心思想是人類專家與LLM評判器的協同合作,在重大版本更新時引入人類在環監督,實時對齊演化數據分布與任務需求,這里有兩個關鍵任務,LLM-as-a-Judge與Human-in-the-Loop。
LLM-as-a-Judge中,需要構造人類標注的評估數據集用于LLM指令微調,這里主要是兩塊數據,一塊是二分類評估(相關性好壞)、另一塊是多級評估(真實性好中差)。數據的來源是DeepSeek-R1在預對齊階段生成的推理增強數據和任務專用LLM在自訓練迭代中自生成的樣本,這些是需要人工標注的。另外,由于都是分類問題,因此需要留意樣本均衡的問題,對少數類需要需要做額外的人工標注增加,也需要通過時間衰減策略優先保留最新評估樣本。
但是,LLM-as-a-Judge的可靠性會因為因動態數據分布漂移而面臨挑戰,在面對新商品、新特征的時候會失效,因此本文在每個重要版本更新的過程中,收集專家對近期生成樣本的標注,同時系統對比LLM評判結果與人工評估,當性能顯著下降時,使用新標注數據對LLM評判器進行持續微調,這便是Human-in-the-Loop的過程。
這里,借助LLM-as-a-Judge和Human-in-the-Loop兩者協同,能持續和演化的系統保持對齊,維持持續運營,但這里毫無疑問,無論是標注人力還是訓練資源,這個成本都不小。
實驗
推薦系統核心關注的還是業務指標,就是在線用戶的停留、成交等信息,因此都是做的AB實驗。
評價指標上,用戶體驗選擇的是停留時長、曝光多樣性和停留多樣性,平臺收益則是上面頁面瀏覽量、點擊率、點擊日活、和加購數。結果顯示多個方面的指標均有不同程度的提升,這個全面提升還挺少見的。
另外作者還做了深入的案例分析以及用戶調研,這個我就不贅述了。
有個遺憾,論文本身是一個完整的框架,內部很多部分都可以拆解應用到原有的推薦系統中的,消融實驗在這里做的并不完善。
個人小結
這篇文章相比最近比較火的生成式推薦,還是比較保守的,每一步都做了專門的設計,也很符合推薦系統上的模塊拆解。簡單聊聊我自己覺得這套方案的優勢吧。
因為是模塊化設計,支持每個模塊獨立優化,效果監控比較方便,后續的上限也可以分批分點上,再一點是,推薦系統中用戶和物料之間是存在更新的gap,兩者隔離,各自的更新解耦,最終整個系統的可維護性也會比較強。
可實操性和可解釋性更強,真正意義的結合了用戶和商品的顯式理解,充分發揮大模型自身優勢的同時,保留推薦系統原有信息和特征信息。
考慮到了冷啟動問題。對新產品、新用戶也有兼容。
考慮到了性能問題。現在大模型的核心壓力主要在文本生成,尤其是長文本層面的壓力,本文在推薦解釋那個部分,提供了一種提前計算緩存的模式,有效把在線的問題降級為了離線完成的問題。


的崛起——為什么“會寫Prompt”成了新技能?)

)


)












