vmalloc流程
1. 背景:vmalloc() 要解決的問題
kmalloc()要求 虛擬地址連續,物理頁也連續。大塊內存分配可能失敗。vmalloc()只保證 虛擬地址連續,物理內存可以由很多不連續的頁拼接。
實現的關鍵就是:
- 在 vmalloc 區域 找一塊空閑的虛擬地址。
- 分配若干物理頁(可能不連續)。
- 建立虛擬地址 → 物理頁的映射。
這三個步驟里,數據結構的角色就是:
**vmap_area**:負責管理 vmalloc 區域里的虛擬地址范圍。**vm_struct**:描述一個具體的 vmalloc 內存塊(和用戶返回的addr對應)。
2. 關鍵數據結構解析
struct vmap_area
表示 vmalloc 區域中的一個虛擬地址段。
struct vmap_area {unsigned long va_start;unsigned long va_end;unsigned long flags;struct rb_node rb_node; /* address sorted rbtree */struct list_head list; /* address sorted list */struct llist_node purge_list; /* "lazy purge" list */struct vm_struct *vm;struct rcu_head rcu_head;
};
- 內核全局維護一棵紅黑樹和鏈表來管理所有的
vmap_area,保證虛擬地址分配不沖突。 - 每次
vmalloc()會新建一個vmap_area,掛到這棵樹里。
struct vm_struct
表示 一個具體的 vmalloc 塊,用戶代碼拿到的就是 vm_struct->addr。
struct vm_struct {struct vm_struct *next;void *addr;unsigned long size;unsigned long flags;struct page **pages;unsigned int nr_pages;phys_addr_t phys_addr;const void *caller;
};
**pages[]**** 是核心**:記錄了 vmalloc 這片區域實際映射到哪些物理頁。addr是vmap_area->va_start,兩者一一對應。vm_struct通過vmap_area->vm與虛擬地址區間關聯。
3. vmalloc() 的流程
以 vmalloc(size) 為例,流程大致是:
(1) 計算所需頁數
nr_pages = (size + PAGE_SIZE - 1) >> PAGE_SHIFT;
(2) 在 vmalloc 區域找虛擬地址
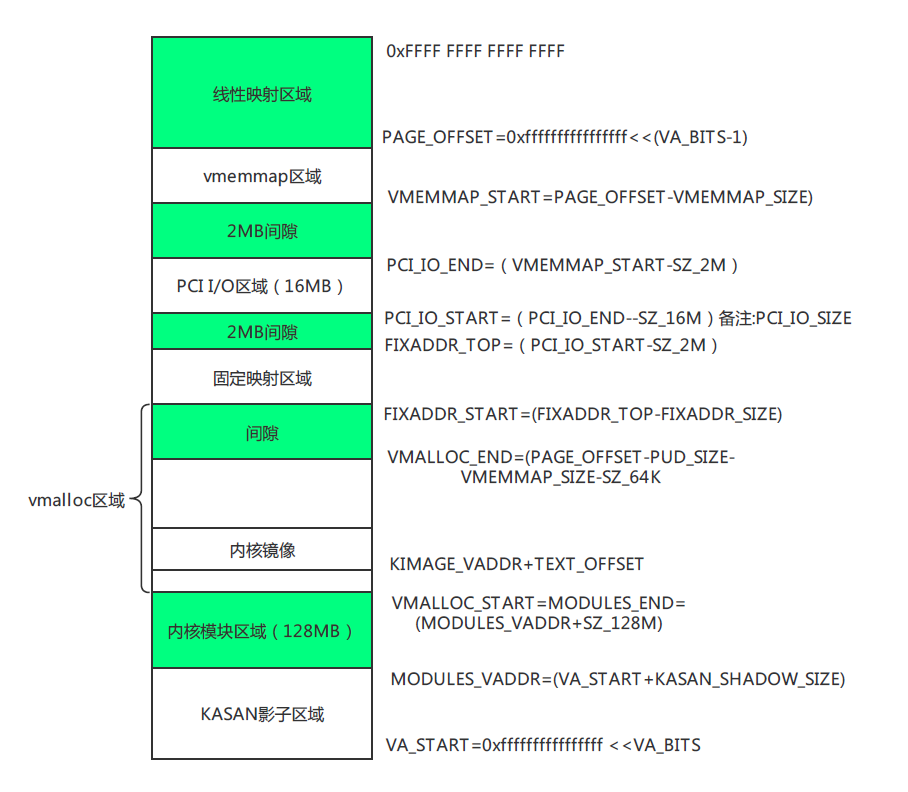
- 調用
alloc_vmap_area():- 通過 紅黑樹,在vmalloc區域中查找一塊足夠大的空閑虛擬地址區間;
- 建立一個新的
struct vmap_area,填好va_start/va_end; - 掛到全局紅黑樹/鏈表里。
這一步解決:虛擬地址空間的分配。
(3) 分配物理頁
- 調用
alloc_page()(實際走伙伴系統),分配nr_pages個物理頁。 - 這些頁可能離散。
- 把它們存進
vm_struct->pages[]。
這一步解決:物理內存的獲取。
(4) 建立映射
- 調用
map_vm_area()或更底層的vmap_page_range():- 遍歷
pages[]; - 在頁表里把
va_start ~ va_end的虛擬頁,依次映射到對應的物理頁。
- 遍歷
這樣,就實現了 虛擬地址連續 → 物理頁不連續 的映射。
如何找到內核線程的頁表?后面解釋
(5) 返回給用戶
vm_struct->addr = (void *)vmap_area->va_start- 返回給調用者。
調用者得到的是一段看起來“連續”的內存。
4. vmalloc() 與 vmap() 的關系
vmalloc()= 自動分配物理頁 + 申請虛擬地址 + 調用 vmap 建立映射。vmap(pages[], nr_pages, ...)= 自己提供物理頁數組,直接建立虛擬映射。
所以:
**vmalloc()**** 面向使用者**(只要給我一段內存);**vmap()**** 面向更底層**(我已有頁,幫我拼接)。
5. 小結
vmalloc() 的機制可以歸納為三步:
- 地址管理:
vmap_area負責在 vmalloc 區域找一段空閑虛擬地址,并放到全局紅黑樹。 - 塊描述:
vm_struct保存這段虛擬內存的元數據(起始地址、大小、物理頁數組)。 - 頁表映射:
把虛擬地址區間映射到vm_struct->pages[]里記錄的實際物理頁。
vfree釋放過程
當 vfree() 被調用時:
- 根據
addr找到對應的vmap_area。 - 從紅黑樹和鏈表刪除。
- 把物理頁釋放回伙伴系統。
- 延遲釋放
vmap_area(放到purge_list,用 RCU 機制安全回收)。
linux中常用內存分配函數
用戶態 vs 內核態
- 用戶態 API:
malloc(),brk(),mmap()
這是 C 庫(glibc)或系統調用提供的接口,進程使用。
本質上是通過 VMA 管理 + 缺頁時分配物理頁。 - 內核態 API:
alloc_pages(),kmalloc(),vmalloc()
這是 Linux 內核給自己用的內存分配器接口,驅動/內核子系統用。
本質上是 直接操作伙伴系統/SLAB/vmalloc 子系統。
各方法機制對比
| 接口 | 使用場景 | 內核實現方式 | 地址連續性 | 使用者 |
|---|---|---|---|---|
| malloc() | 用戶程序最常用的內存申請 | glibc 封裝,底層調用 brk()或 mmap()擴展堆/映射匿名頁 | 用戶虛擬地址連續(物理不一定連續) | 用戶空間 |
| brk() | 擴展/收縮 heap(sbrk系統調用) | 修改進程的堆 VMA 邊界,缺頁時由 alloc_pages()分配物理頁 | 用戶虛擬地址連續(物理不一定連續) | 用戶空間 |
| mmap() | 大塊內存/文件映射/共享內存 | 創建新的 VMA,缺頁時用 alloc_pages()或從文件讀取到物理頁 | 用戶虛擬地址連續(物理不一定連續) | 用戶空間 |
| alloc_pages() | 分配頁粒度內存 | 伙伴系統分配 struct page | 物理連續,內核虛擬地址也連續(線性映射區) | 內核 |
| kmalloc() | 內核小塊內存(字節/KB 級) | SLAB/SLUB 分配器,底層基于 alloc_pages() | 物理連續 + 內核虛擬連續 | 內核 |
| vmalloc() | 內核大塊內存(MB 級) | 從 vmalloc 區找虛擬地址區間,分配不連續物理頁(底層基于alloc_pages()),建立頁表映射 | 虛擬地址連續,物理地址不連續 | 內核 |
關系梳理
- 用戶空間
malloc()→ 封裝,可能走brk()或mmap();brk()/mmap()→ 修改mm_struct和 VMA;- 缺頁時 → 最終用
alloc_pages()分配物理頁。
- 內核空間
alloc_pages()→ 最底層接口,直接伙伴系統;kmalloc()→ 面向小對象,使用slab分配器,底層用alloc_pages();vmalloc()→ 面向大塊虛擬地址空間,物理頁不連續。底層用alloc_pages()。
總結
- 用戶態用
malloc()(底層 brk/mmap),本質是修改虛擬內存布局,缺頁時通過 **伙伴系統 ****alloc_pages()**分配物理頁; - 內核態直接用
alloc_pages()、kmalloc()(小塊)、vmalloc()(大塊,物理不連續)。
如何找到內核線程的頁表?
“內核線程沒有用戶空間”就會懷疑:那頁表怎么辦?是不是有個“內核專用頁表”?
其實 Linux 內核線程并不是共享一個“內核頁表”,而是借用普通進程的頁表。
1. 頁表的基本事實
- 在 x86/ARM 等架構上,CPU 訪問內存都要走頁表轉換。頁表的基地址存放在控制寄存器(x86 的
CR3,ARM64 的TTBR0/TTBR1)。 - Linux 設計:所有進程的頁表都包含了同一份內核態映射(高地址部分的 linear mapping、vmalloc 等)。
- 換句話說,每個進程的
mm_struct->pgd不同,但其中“內核地址區”是一致的。 - 所以,只要有一份用戶進程的頁表,就能保證內核地址區始終可用。
- 換句話說,每個進程的
2. 普通進程 vs 內核線程
普通用戶進程
- 每個進程有自己的
mm_struct,里面有獨立的pgd(頁全局目錄)。 - 切換進程時,調度器會把
mm->pgd加載到CR3。 - 這樣用戶態地址空間不同,但內核態地址映射相同。
內核線程
task_struct->mm = NULL,說明它沒有獨立的mm_struct和pgd。- 調度器在切換到內核線程時:
- 如果發現
mm == NULL,會把prev->active_mm借給內核線程,保存到next->active_mm。 - 并且在切換時 不會切換 CR3,繼續使用原進程的頁表。
- 如果發現
- 內核線程只在內核態執行,不會訪問用戶空間地址,所以根本不在意用戶空間頁表部分。
3. 也就是說:
- 每個內核線程并沒有單獨的頁表。
- 它們 借用上一個普通進程的頁表,只是用其中的內核映射部分。
- 這就是
task_struct->active_mm的意義。
4. “內核頁表”的保存與使用
- 并不存在一個獨立的“全局內核頁表”。
- 取而代之:每個進程的頁表都自帶了內核映射部分。
- 內核線程調度時,就繼續使用借來的頁表的內核部分。
總結
內核線程沒有獨立的頁表,它們不會切換到某個“內核專用頁表”。調度到內核線程時,Linux 內核會讓它們 借用上一個進程的頁表(通過 active_mm),只使用其中的內核地址映射部分。由于所有進程的內核區頁表一致,內核線程就能安全運行。
測試驗證
代碼實現
實現一個最小可運行的 內核模塊 示例,專門用來測試 vmalloc() 申請和釋放內存。代碼如下:
#include <linux/module.h>
#include <linux/init.h>
#include <linux/vmalloc.h> // vmalloc/vfree
#include <linux/kernel.h>#define VMALLOC_SIZE (1024 * 1024) // 申請 1MBstatic void *vmalloc_area = NULL;static int __init vmalloc_test_init(void)
{pr_info("vmalloc_test: module loaded\n");// 使用 vmalloc 申請一塊連續虛擬地址的內存vmalloc_area = vmalloc(VMALLOC_SIZE);if (!vmalloc_area) {pr_err("vmalloc_test: vmalloc failed!\n");return -ENOMEM;}pr_info("vmalloc_test: allocated %d bytes at %pK\n",VMALLOC_SIZE, vmalloc_area);// 寫入測試數據memset(vmalloc_area, 0xAA, VMALLOC_SIZE);pr_info("vmalloc_test: memory initialized with 0xAA\n");return 0;
}static void __exit vmalloc_test_exit(void)
{if (vmalloc_area) {vfree(vmalloc_area);pr_info("vmalloc_test: freed memory at %pK\n", vmalloc_area);}pr_info("vmalloc_test: module unloaded\n");
}module_init(vmalloc_test_init);
module_exit(vmalloc_test_exit);MODULE_LICENSE("GPL");
MODULE_AUTHOR("congchp");
MODULE_DESCRIPTION("Simple vmalloc test module");obj-m += vmalloc_test.oall:make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modulesclean:make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean測試結果
dmesg結果:

/proc/vmallocinfo結果:

參考資料
- Professional Linux Kernel Architecture,Wolfgang Mauerer
- Linux內核深度解析,余華兵
- Linux設備驅動開發詳解,宋寶華
- linux kernel 4.12










的傳輸層設計、診斷服務器實現、事件與通信管理、生命周期與報告五大核心模塊)








