作者:來自 Elastic?Carlos Delgado

僅執行向量搜索以找到與查詢最相似的結果是不夠的。通常需要過濾來縮小搜索結果。本文解釋了在 Elasticsearch 和 Apache Lucene 中向量搜索的過濾是如何工作的。
Elasticsearch 擁有豐富的新功能,幫助你為自己的用例構建最佳搜索解決方案。深入查看我們的示例筆記本以了解更多,開始免費的云試用,或在本地機器上嘗試 Elastic。
向量搜索并不足以找到相關結果。使用過濾條件來縮小搜索結果、排除無關結果是非常常見的。
理解過濾在向量搜索中的工作方式將幫助你平衡性能與召回率之間的取舍,同時還能發現一些在使用過濾時提升向量搜索性能的優化方法。
為什么要過濾?
向量搜索(Vector search)徹底改變了我們在大型數據集中查找相關信息的方式,使我們能夠發現與查詢在語義上相似的項目。
然而,僅僅找到相似項目還不夠。我們常常需要根據特定條件或屬性來縮小搜索結果。
想象一下你在電商商店中搜索某個商品。純粹的向量搜索可能會顯示與你在視覺上相似的商品,但你可能還想按價格范圍、品牌、庫存情況或用戶評分來過濾。如果沒有過濾,你將會看到一大堆相似的商品,很難找到你真正需要的。
過濾使搜索結果的控制更加精確,確保檢索到的項目不僅在語義上匹配,而且滿足所有必要的要求。這帶來了更加準確、高效且用戶友好的搜索體驗。
這正是 Elasticsearch 和 Apache Lucene 的優勢所在 —— 在各種數據類型上使用有效過濾,是它們與其他向量數據庫的關鍵區別之一。
精確向量搜索的過濾
執行精確向量搜索有兩種主要方式:
-
對 dense_vector 字段使用 flat 索引類型。這會讓 knn 搜索使用精確搜索而不是近似搜索。
-
使用 script_score 查詢,通過向量函數計算得分。這可以與任意索引類型一起使用。
當執行精確向量搜索時,所有向量都會與查詢進行比較。在這種情況下,過濾會提升性能,因為只有通過過濾的向量才需要比較。
這不會影響結果質量,因為無論如何所有向量都會被考慮。我們只是提前過濾掉不感興趣的結果,從而減少運算次數。
這點非常重要,因為當應用的過濾條件使結果文檔數量很少時,執行精確搜索可能比執行近似搜索更高效。
經驗法則是:當過濾后少于 10k 文檔時使用精確搜索。BBQ 索引在比較時要快得多,所以對于基于該索引的情況,如果少于 100k,也很適合使用精確搜索。更多細節請查看這篇博客文章。
如果你的過濾條件總是非常嚴格,可以考慮通過使用 flat 索引類型而不是基于 HNSW 的類型,讓索引專注于精確搜索而不是近似搜索。更多細節見 index_options 的屬性。
近似向量搜索的過濾
在執行近似向量搜索時,我們以結果的準確性換取性能。像 HNSW 這樣的向量搜索數據結構能高效地在數百萬向量中搜索近似最近鄰。它們專注于通過最少的向量比較(計算代價高昂)來檢索最相似的向量。
這意味著其他過濾屬性并不是向量數據的一部分。不同的數據類型有各自高效的索引結構來查找和過濾,例如 terms 字典、posting lists 和 doc values。
由于這些數據結構與向量搜索機制是分開的,那么如何將過濾應用到向量搜索呢?有兩種選擇:在向量搜索之后應用過濾(后過濾,postfiltering)或在向量搜索之前應用過濾(前過濾,prefiltering)。
這兩種方式各有優缺點。下面我們深入看看!
后過濾(Postfiltering)
后過濾是在向量搜索完成后再應用過濾。這意味著過濾在找到 top k 個最相似的向量結果之后才會執行。
顯然,在應用過濾后我們可能會得到少于 k 的結果。當然,我們可以從向量搜索中檢索更多結果(更高的 k 值),但我們不能確定在應用過濾后一定能得到 k 個或更多結果。
后過濾的優點是它不會改變向量搜索的運行行為 —— 向量搜索對過濾毫不知情。但它會改變最終檢索到的結果數量。
下面是一個使用 knn 查詢進行后過濾的示例。注意過濾子句與 knn 查詢是分開的:
{"query": {"bool": {"must": {"knn": {"field": "image-vector","query_vector": [54, 10, -2],"k": 5,"num_candidates": 50}},"filter": {"term": {"file-type": "png"}}}}
}后過濾也可以通過在 knn 搜索中使用 post-filter 來實現:
{"knn": {"field": "image-vector","query_vector": [54, 10, 2],"k": 5,"num_candidates": 50},"post_filter": {"term": {"file-type": "png"}}
}請記住,在 knn 搜索中你需要使用顯式的 post-filter 部分。如果你不使用 post-filter,knn 搜索會把最近鄰結果與其他查詢或過濾條件組合,而不是執行后過濾。
前過濾(Prefiltering)
在向量搜索之前應用過濾會先檢索滿足過濾條件的文檔,然后把這些信息傳遞給向量搜索。
Lucene 使用 BitSet 來高效存儲滿足過濾條件的文檔。向量搜索隨后遍歷 HNSW 圖,同時考慮滿足條件的文檔。在把候選項加入結果之前,它會檢查該候選項是否包含在有效文檔的 BitSet 中。
但是,即使候選項不是有效文檔,它也必須被探索并與查詢比較。HNSW 的有效性依賴于圖中向量之間的連接 —— 如果我們停止探索某個候選項,就可能會錯過它的鄰居。
這就像開車去加油站。如果你丟棄所有沒有加油站的道路,你很可能到不了目的地。其他道路可能不是你需要的,但它們能把你連接到目的地。HNSW 圖上的向量也是同樣的道理!
因此,應用前過濾的性能會比不使用過濾更差。我們需要對搜索中訪問的所有向量進行處理,并丟棄那些不匹配過濾條件的。這意味著要做更多工作,花更多時間才能得到 top k 結果。
下面是 Elasticsearch Query DSL 中前過濾的示例。注意過濾子句現在是 knn 部分的一部分:
{"knn": {"field": "image-vector","query_vector": [54, 10, -2],"k": 5,"num_candidates": 50,"filter": {"term": {"file-type": "png"}}}
}前過濾可用于 knn 搜索和 knn 查詢:
{"query": {"knn": {"field": "image-vector","query_vector": [-5, 9, -12],"k": 5,"filter": {"term": {"file-type": "png"}}}}
}前過濾優化
有一些優化方法可以確保前過濾的性能:
-
如果過濾條件非常嚴格,可以切換到精確搜索。當需要比較的向量很少時,在滿足過濾條件的少量文檔上執行精確搜索會更快。
這種優化在 Lucene 和 Elasticsearch 中是自動應用的。 -
另一種優化方法是忽略不滿足過濾條件的向量。相反,該方法檢查通過過濾的向量的鄰居。這樣有效減少了比較次數,因為不滿足條件的向量不會被考慮,同時仍會繼續探索與當前路徑相連的向量。? ? ? ? ? ??
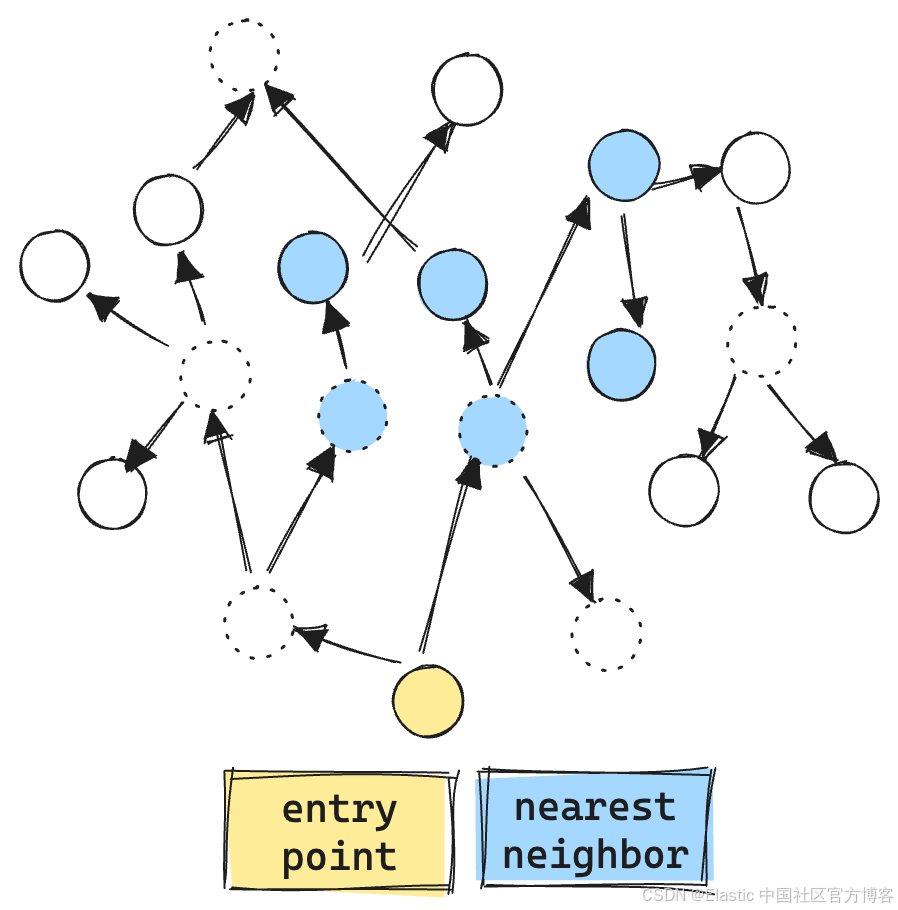
這種算法稱為 ACORN-1,具體過程在這篇博客文章中有詳細描述。
使用文檔級安全進行過濾
文檔級安全(DLS)是 Elasticsearch 的一項功能,用于指定用戶角色可以檢索的文檔。
DLS 通過查詢執行。角色可以與索引關聯一個查詢,這有效限制了屬于該角色的用戶可以從索引中檢索的文檔。
角色查詢用作過濾器以檢索匹配的文檔,并作為 BitSet 緩存。然后使用這個 BitSet 包裝底層的 Lucene reader,這樣只有查詢返回的文檔被視為有效 —— 也就是說,它們存在于索引中且未被刪除。
當從 reader 中檢索有效文檔以執行 knn 查詢時,只會考慮用戶可用的文檔。如果有前過濾,DLS 文檔將被添加到前過濾中。
這意味著 DLS 過濾作為近似向量搜索的前過濾,其性能影響和優化方法相同。
在精確搜索中使用 DLS 與應用任何過濾器具有相同的好處 —— 從 DLS 檢索的文檔越少,精確搜索的性能越高。同時還要考慮 DLS 返回的文檔數量 —— 如果 DLS 角色非常嚴格,你可以考慮使用精確搜索而不是近似搜索。
基準測試
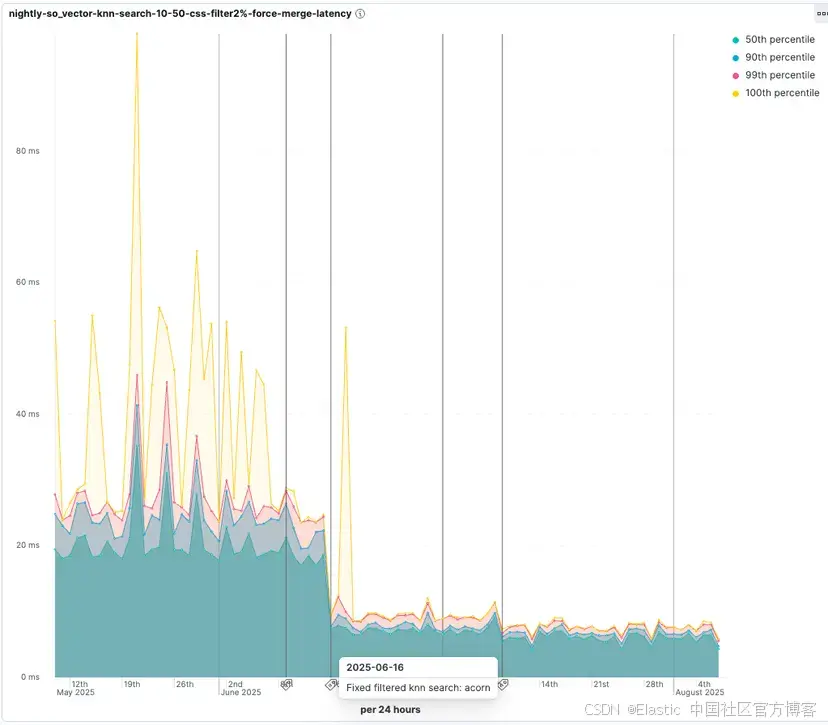
在 Elasticsearch,我們希望確保向量搜索過濾高效。我們有專門的向量過濾基準測試,它對不同的過濾條件執行近似向量搜索,以確保向量搜索盡可能快速地檢索相關結果。
查看 ACORN-1 引入時的改進。在測試中,只有 2% 的向量通過過濾,查詢延遲降低到原始時間的 55%:
結論
過濾是搜索的重要組成部分。確保向量搜索中過濾的高性能,并理解其權衡和優化,是實現高效且準確搜索的關鍵。
過濾會影響向量搜索的性能:
-
使用過濾時,精確搜索更快。如果你的過濾條件足夠嚴格,應考慮使用精確搜索而不是近似搜索。這在 Elasticsearch 中是自動優化的。
-
使用前過濾時,近似搜索會更慢。前過濾可以讓我們獲得符合過濾條件的 top k 結果,但代價是搜索速度變慢。
-
后過濾不一定能檢索到 top k 結果,因為應用過濾后部分結果可能被過濾掉。
祝過濾愉快!
原文:Vector search filtering: Keep it relevant - Elasticsearch Labs





的傳輸層設計、診斷服務器實現、事件與通信管理、生命周期與報告五大核心模塊)













)