概述
傳統BI的三大核心瓶頸:
- 問數之難:不同用戶往往存在個性化的分析邏輯,盡管企業內部已經創建大量報表和看板,但仍然無法完全滿足業務部門對數據的個性化需求。但傳統BI門檻較高,非技術人員在統一培訓前,往往難以自行使用BI進行個性化分析。
- 問知之遲:傳統BI的分析流程需預先定義數據模型、依賴技術團隊支持,從需求提出到洞察生成存在顯著延遲,不同的業務方,不同時間點,不同場景下,可能是同一個取數需求,都需要重新排期進行,不僅耗費精力,更難以支撐瞬息萬變的實時決策場景。
- 問策之限:分析深度受限于預設指標與固定邏輯,傳統BI缺乏動態探索與深度推理能力,難以主動揭示復雜業務場景中的隱性關聯與根因,制約策略生成。
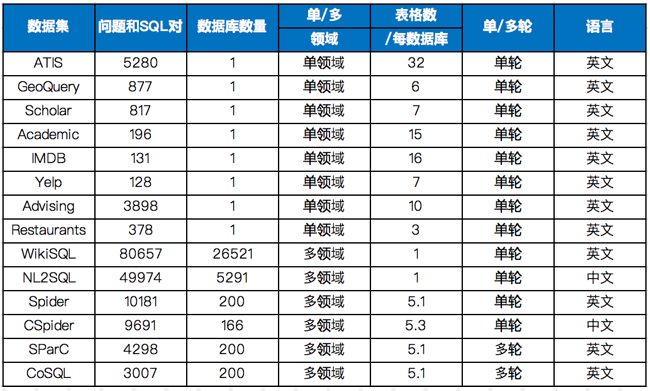
Text-to-SQL,Text2SQL,把自然語言轉化為SQL,也叫文本到SQL,自然語言到SQL,Text2SQL、T2S、NL2SQL、Natural2SQL、Text2Query、Chat2Query。
早在LLM之前已有大量專注于此任務的機器學習項目。在大模型出現以后,憑借其強大的自然語言理解和推理能力,讓T2S得到大力的推進。
在RAG中QA對,在text2sql中,便是query-sql對。
最佳實踐:
- 清楚描述數據庫上下文;
- 限制數據查詢輸出的大小;
- 在執行之前驗證和檢查生成的SQL語句。
引申:
- Text2DSL:Domain Specific Language,領域特定語言
- Text2GQL:Graph Query Language,圖查詢語言
- Text2API:
- Text2Vis:論文
供參考的T2S問題分類:
- 常規指標查詢
- 進階指標查詢
- 時間變種
- 實體信息變種
- 多設備查詢
- 多意圖拆解
- 嵌套查詢
- 圖表輸出
提示詞策略
- Informal Schema:非正式模式策略,簡稱IS,以自然語言提供表及其關聯列的描述,模式信息以不太正式的方式表達;
- API Docs:API文檔,簡稱AD,相比之下,Rajkumar(2022)等人進行的評估中概述的AD策略,遵循OpenAI文檔中提供的默認SQL翻譯提示。此提示遵循稍微更正式的數據庫模式定義。
- Select 3:包括數據庫中每個表的三個示例行。此附加信息旨在提供每個表中包含的數據的具體示例,以補充模式描述;
- 1SL:1 Shot Learning,在提示中提供1個黃金示例;
- 5SL:5 Shot Learning,在提示中提供5個黃金示例。
T2S與ChatBI
LLM的迅猛發展使得T2S的準確率得到不少提升,也催生出一大批開源或付費ChatBI系統。
ChatBI=NLU模塊+T2S引擎+數據庫連接+可視化引擎+對話管理。
Benchmark
T2S任務的評價主要有兩種:精確匹配率(Exact Match,EM)、執行正確率(Execution Accuracy,EX,也叫EA)
- EM:計算模型生成的SQL和標注SQL的匹配程度,結果存在低估的可能。
- EX:計算SQL執行結果正確的數量在數據集中的比例,結果存在高估的可能。
EM,為了處理由成分順序帶來的匹配錯誤,當前精確匹配評估將預測的SQL語句和標準SQL語句按著SQL關鍵詞分成多個子句,每個子句中的成分表示為集合,當兩個子句對應的集合相同則兩個子句相同,當兩個SQL所有子句相同則兩個SQL精確匹配成功。
評價指標另有VES:Valid Efficiency Score。VES旨在衡量模型生成的有效SQL的效率。有效SQL,指的是預測的SQL查詢,其結果集與基準SQL的結果集一致。任何無法執行正確值的SQL查詢都將被聲明為無效。VES指標可以考慮執行結果的效率和準確性,提供對模型性能的全面評估。
評估數據集有很多
Spider
有兩個版本:
- Spider 1.0:官網,論文;
- Spider 2.0:官網,論文,GitHub。
Spider 1.0是耶魯大學推出,包含10181個問題和5693個SQL,涉及200個數據庫
Spider 2.0是由香港大學、Salesforce Research等團隊提出的T2S Benchmark框架,用來LLMs在真實企業級數據工作流中的能力。Spider 1.0和BIRD存在數據庫規模小、SQL復雜度低、缺乏多方言支持等局限性,而企業級場景涉及超大規模模式(平均812列)、多數據庫系統(BigQuery/Snowflake/SQLite等)和復雜數據工程流程。Spider 2.0通過以下創新點突破現有框架:
- 真實數據源:基于Google Analytics、Salesforce等企業數據庫,包含213個數據庫和632個任務;
- 跨方言支持:覆蓋6種SQL方言的多種特殊函數;
- 項目級交互:整合代碼庫(如DBT項目)和文檔,模擬真實開發環境;
- 長上下文處理:平均每個SQL包含148.3個token,遠超BIRD的30.9和Spider 1.0的18.5。
實驗表明,o1-preview在Spider 2.0上的成功率僅20%左右,遠低于其在Spider 1.0上90%+和BIRD上70%+的表現。揭示現有模型在模式鏈接、方言適配和多步推理上的瓶頸。
提供兩種任務設置:
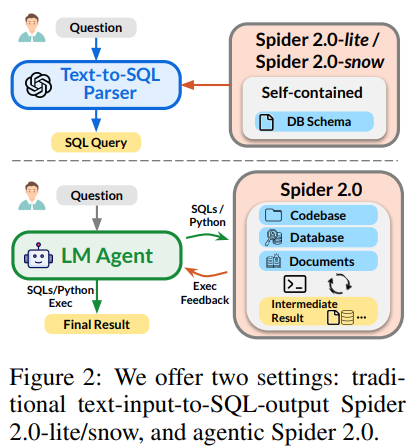
提供兩個簡化版數據集:
- Spider 2.0-Lite:托管在BigQuery、Snowflake和SQLite上;
- Spider 2.0-Snow:全部托管在Snowflake上。
| 維度 | Spider 2.0 | Spider 2.0-Lite | Spider 2.0-Snow |
|---|---|---|---|
| 任務類型 | 代碼代理任務,多輪交互 | 純文本到SQL,單輪生成 | 純文本到SQL,單輪生成 |
| 數據庫支持 | 6種,含BigQuery/Snowflake/PG | BigQuery/Snowflake/SQLite | 僅Snowflake |
| 示例數量 | 632 | 547 | 547 |
| 復雜度 | 極高(動態環境交互+多方言) | 高(跨數據庫適配) | 中(單一方言聚焦) |
| 成本 | 需付費(云資源消耗) | 需付費(BigQuery使用費) | 完全免費(Snowflake提供配額) |
| 核心挑戰 | 復雜數據工程流程(清洗→轉換→分析) | 跨數據庫模式鏈接與函數適配 | Snowflake方言深度優化 |
| 適用場景 | 企業級代碼代理研究 | 跨平臺模型泛化能力評估 | 單一云數據庫性能基準測試 |
Spider-Agent框架
官方提供的基于ReAct構建的解決方案,專為數據庫任務設計的代理框架,針對SQL和數據庫交互設計一套動作空間,支持:
- 多動作空間:支持SQL執行、文件編輯、命令行操作等;
- 迭代調試:通過執行反饋不斷改進解決方案;
- 上下文管理:有效整合代碼庫、文檔等多源信息
動作空間是Spider-Agent的核心,定義模型可執行的操作:
- Bash:運行shell命令,例如查看文件或執行
dbt run; - CreateFile:創建新的SQL腳本文件;
- EditFile:修改或覆蓋現有文件內容;
- ExecuteSQL:在數據庫上執行SQL查詢,并可選擇保存結果;
- GetTables:獲取數據庫中的表名和模式;
- GetTableInfo:查詢指定表的列信息;
- SampleRows:從表中采樣數據并保存為JSON格式;
- FAIL:任務失敗;
- Terminate:任務已成功完成。
這些動作賦予模型靈活性,使其能夠與數據庫和代碼環境無縫交互。
Bird
官網,論文,GitHub
一個開創性的跨領域數據集,包含超過12751個獨特的問題-SQL對,95個大型數據庫,達33.4GB。涵蓋超過37個專業領域,如區塊鏈、曲棍球、醫療保健和教育等。
GPT-3.5-turbo在BIRD數據集上的表現進行詳細的錯誤分析與分類:
- 錯誤的模式鏈接(Wrong Schema Linking,占41.6%):模型能準確地理解數據庫的結構,但錯誤地將其與不適當的列和表關聯起來。表明schema linking仍然是T2S模型的一個重大障礙。
- 誤解數據庫內容(Misunderstanding Database Content,占40.8%):當ChatGPT無法回憶起正確的數據庫結構(如rtype不屬于satscores表)或生成假的schema項(如lap_records沒有出現在formula_1數據庫中)時,尤其是當數據庫非常大時,就會發生這種情況。如何使模型真正理解數據庫結構和內容仍然是LLMs中的痛點話題。
- 誤解知識證據(Misunderstanding Knowledge Evidence,占17.6%):沒有準確解釋人類注釋的證據的情況。如直接復制公式
DIVIDE(SUM(spent),COUNT(spent))。表明ChatGPT在面對不熟悉的提示或知識時,缺乏魯棒性,導致它直接復制公式,而不考慮SQL語法。這種脆弱性可能會導致安全問題。例如如果故意通過一個不熟悉的公式引入一個毒藥知識證據,GPT可能會在沒有驗證的情況下無意中將其復制到輸出中,從而使系統暴露于潛在的數據安全風險中。 - 語法錯誤(Syntax Error,占3.0%):比例較小,表明ChatGPT在語義解析方面表現良好,少部分錯誤體現在一些特殊的關鍵詞,如混淆使用MySQL的
year()和SQLite中的STRFTIME()。
IJCKG2025 Archer
Archer包含三種推理類型:算術推理、常識推理和假設推理。算術推理在SQL的具體應用場景中占有重要比例。常識推理是指基于隱含的常識知識進行推理的能力,Archer包含一些需要理解數據庫才能推斷出缺失細節的問題;假設推理要求模型具備反事實思維能力,即根據可見事實和反事實假設對未見情況進行想象和推理的能力。
Archer包含1042個中文問題、1042個英文問題以及521條對應的SQL查詢,覆蓋20個不同領域的20個數據庫。其中8個數據庫用作訓練集,2個數據庫用作驗證集,10個數據庫用作測試集。數據集及排行榜地址:https://sig4kg.github.io/archer-bench/
評估指標:
- VA:VAlid SQL,成功執行的預測SQL語句的比例,無論答案是否正確;
- EX:EXecution accuracy,預測SQL語句執行結果與標準SQL語句執行結果相匹配的比例。
開源
Awesome Text2SQL
GitHub,關于LLMs、Text2SQL、Text2DSL、Text2API、Text2Vis等主題的精選教程資源。
Chat2db
旨在成為一個通用的開源SQL客戶端和報告工具,支持幾乎所有比較流行的數據庫、緩存。
7B開源模型:
https://github.com/CodePhiliaX/Chat2DB-GLM
https://huggingface.co/Chat2DB/Chat2DB-SQL-7B
部署
git clone https://github.com/CodePhiliaX/Chat2DB
cd Chat2DB/docker
docker compose up -d
瀏覽器打開http://localhost:10824,開始體驗。
輸入默認用戶名密碼chat2db。
設置API Key
創建數據庫連接
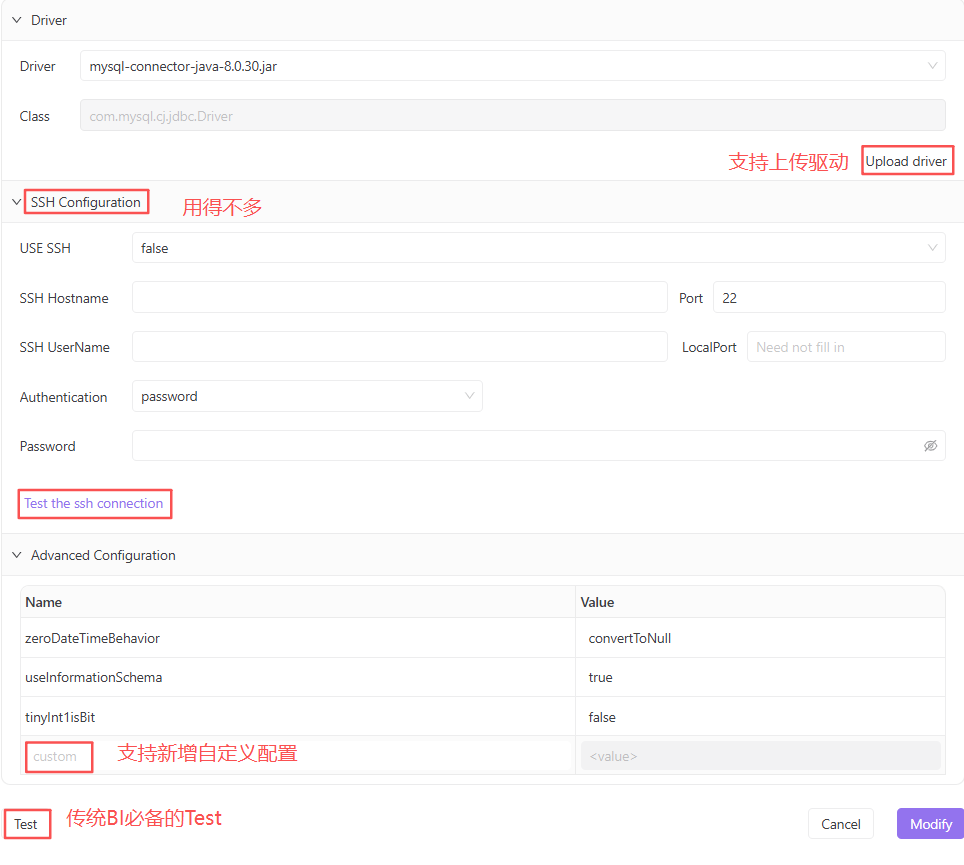
上面截圖沒體現出來,可新增多個自定義配置。
新增Dashboard:
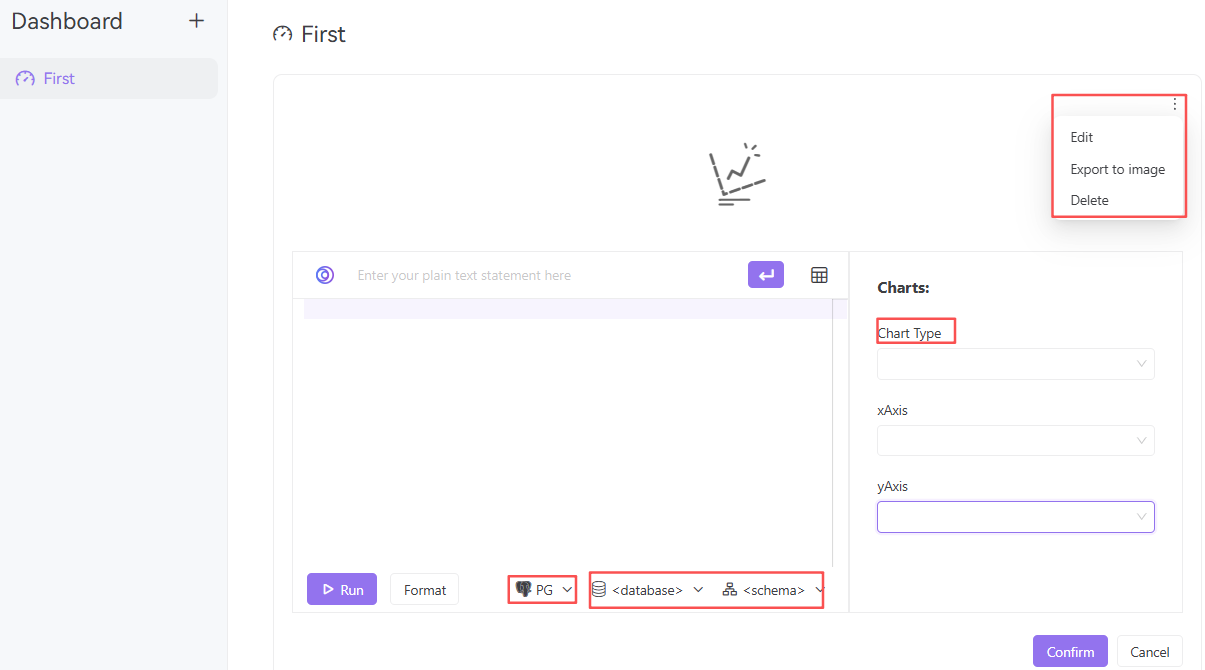
Chart Type支持3種
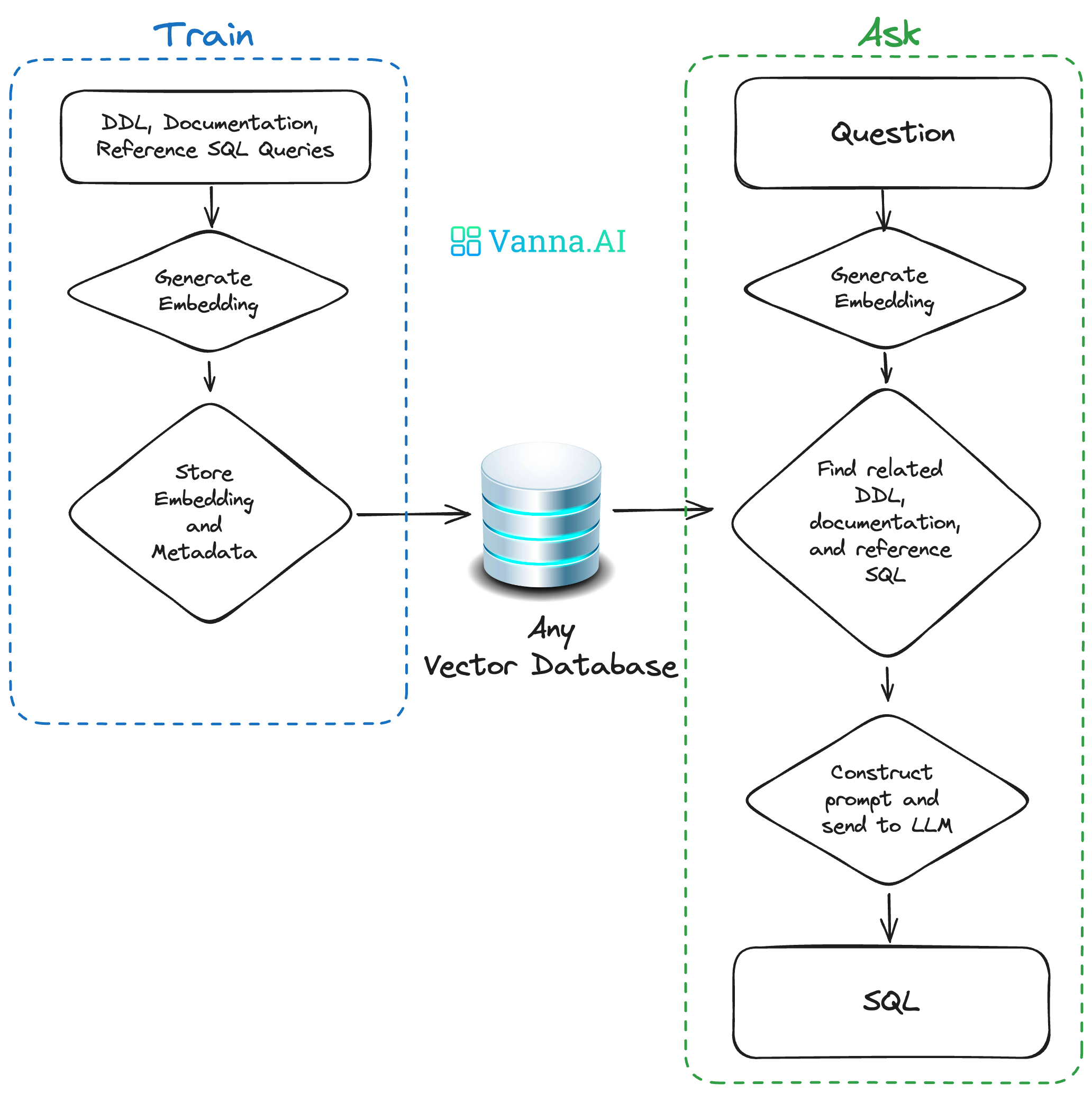
Vanna
一款開源AI SQL代理,能夠將自然語言問題轉化為可操作的數據庫洞察。該平臺提供了多種部署選項,以滿足不同的組織需求:
- Vanna Cloud:無需設置即可使用的企業級平臺,針對你的特定數據環境和行業背景進行訓練;
- Vanna Enterprise:本地部署,以實現完全的數據主權;
- Vanna API:具備集成能力,可將AI驅動的數據庫交互嵌入到現有應用程序中;
- 開源基礎:為希望構建自定義解決方案的開發者提供最大程度的靈活性。
支持Snowflake、BigQuery等主流數據庫,并可輕松創建連接器以支持其他數據庫。可通過多種前端部署,包括Jupyter Notebooks、Slack機器人、Web應用和Streamlit界面。
開源的開源Python RAG框架。Vanna通過整合上下文(元數據、定義、查詢等)以及領域知識文檔來訓練RAG模型。在Vanna框架的基礎上可以使用現有工具(例如Streamlit、Slack)構建自定義可視化UI,實現對話結果的可視化。
兩個步驟:
- 基于數據訓練RAG模型;
- 提出問題返回SQL查詢,并且可以將查詢配置為在數據庫上自動運行。
WrenAI
開源,官網
數據庫內容不會傳輸到LLMs,確保數據安全。
部署
git clone https://github.com/Canner/WrenAI
cd WrenAI/docker/
cp .env.example .env
docker compose up -d
瀏覽器打開http://localhost:3000,比較貼心地給出自帶的數據源和數據集
上面提到RAG的QA對,WrenAI也能看到類似知識庫維護界面
API界面沒有維護入口,需要在.env文件里配置,然后重啟服務。

SQL Chat
GitHub,具備T2S聊天功能的SQL客戶端。
SuperSonic
參考SuperSonic部署實戰。
Dataherald
https://github.com/Dataherald/dataherald
一個T2S引擎,為在關系數據庫上的企業級問答而構建。
功能:
- 允許業務用戶從數據倉庫中獲得結果,而無需通過數據分析師;
- 在SaaS應用程序中啟用來自生產數據庫的Q+A
- 創建ChatGPT插件
包含四大模塊:引擎、管理控制臺、企業后端和Slackbot。其中,核心引擎模塊包含了LLM代理、向量存儲和數據庫連接器等關鍵組件。模塊化設計,將不同的功能模塊封裝成獨立的類和方法,便于代碼維護和擴展,可輕松地集成新的工具和功能。
database-build
https://github.com/supabase-community/database-build
一個基于WASM的瀏覽器內PostgreSQL沙盒,帶有AI輔助功能。它讓用戶可以直接在網頁瀏覽器中操作PostgreSQL,而無需在本地安裝或設置數據庫。
DuckDB-NSQL
https://github.com/NumbersStationAI/DuckDB-NSQL
一個由MontherDuck和Numbers Station為DuckDB SQL分析任務構建的T2S LLM。可以幫助用戶利用DuckDB的全部功能及其分析潛力,而不需要在DuckDB文檔和SQL shell之間來回切換。
EZQL
https://github.com/outerbase/ezql
開發商Outerbase已被Cloudflare收購。
付費/閉源
DataGrip
新版本能力:
- 使用自然語言請求查詢和信息
- 解釋復雜的SQL,例如存儲過程
- 優化架構和SQL
- 比較兩個數據庫對象的DDL
- 修復SQL錯誤
- 格式化和重寫SQL
觀遠
核心亮點:
- 知識庫冷啟動:快速構建精準問數體系
基于企業現有BI資產(儀表板、卡片、數據集等),觀遠ChatBI實現低門檻知識遷移與快速激活:
? 多源數據無縫接入:支持40+數據庫連接與文件類數據抽取,未來可擴展直連模式,確保數據來源的全面性與實時性,為問數場景提供堅實的數據底座。
? 業務知識高效萃取:自動從既有BI資產中提取業務邏輯與問答知識(如指標定義、分析維度關聯),加速知識庫初始化過程,避免從零開始的資源浪費。
? 問答準確率閉環檢測:上線前對主題進行自動化問答測試,確保準確率達90%+,通過“測試-優化-再測試”機制,保障問數結果的精準性與業務貼合度。
- 多端交互體驗:打破時空限制的智能問數
觀遠ChatBI深度適配PC端、移動端、OA系統(如飛書),構建全場景智能交互體系:
? 多端協同問數:業務人員可在辦公桌面、移動終端隨時隨地發起數據查詢,即時獲取可視化分析結果,實現“數據隨需而至”。
? OA集成深化場景:對接企業級協作平臺機器人(如飛書機器人),在日常辦公流中直接嵌入數據問答能力,提升辦公效率。
? 交互動作立體化:支持問答結果的收藏、點贊/踩、SQL復制與導出等操作,便于業務人員對優質分析內容進行沉淀復用,同時通過用戶反饋優化模型,形成“問數-反饋-迭代”的正向循環。
- 知識庫自迭代:打造個性化企業知識生態
通過知識自動沉淀、智能自檢、個性化學習,觀遠ChatBI構建可持續進化的企業級知識庫:
? 知識自動錄入:從歷史對話、用戶行為中挖掘新知識,提示用戶將其納入知識庫,實現業務知識的動態積累,避免人工維護的繁瑣與遺漏。
? 知識智能自檢:定期對知識庫進行沖突檢查與近似檢查,提醒用戶合并或更新知識,確保知識庫的純凈度與一致性。
? 個性化學習引擎:引入用戶行為數據,為不同角色建立個人知識庫,提供精細化問題推薦與指標口徑確認,實現“千人千面”的智能分析體驗。
SQLAI.ai
官網,劃分為多個SQL生成器,每個都服務于特定的目的:
- Explain SQL Queries:解釋SQL查詢,提供帶摘要、輸出可視化和詳細查詢分解的解釋;
- Format SQL Query:格式化SQL查詢,以提高可讀性并減少出錯的可能性;
- Analyze Your Data:允許上傳CSV數據并向AI提問;
- Generate SQL Query:
- Fix SQL Queries:
- Optimize SQL Query:
推薦閱讀
- NL2SQL


:如何通過Federated實現跨實例訪問表)










如何賦能全球分布式團隊協作)





)