1. 引言
智能體架構(agent architecture)是一份藍圖,它定義了AI智能體各組件的組織方式和交互機制,使智能體能夠感知環境、進行推理并采取行動。本質上,它就像是智能體的數字大腦——整合了“眼睛”(傳感器)、“大腦”(決策邏輯)和“手”(執行器)來處理信息并行動。
選擇合適的架構對于構建有效的AI智能體至關重要。架構決定了智能體的各項能力,包括響應速度、處理復雜性的能力、學習適應性以及資源需求。例如,一個基于簡單反射的智能體可能擅長實時反應,但在長期規劃上表現不佳;而一個慎思型(deliberative)智能體或許能處理復雜目標,但計算成本更高。理解這些權衡取舍能讓工程師根據應用領域匹配最合適的架構,從而實現最佳性能和可靠性。
2. 智能體架構
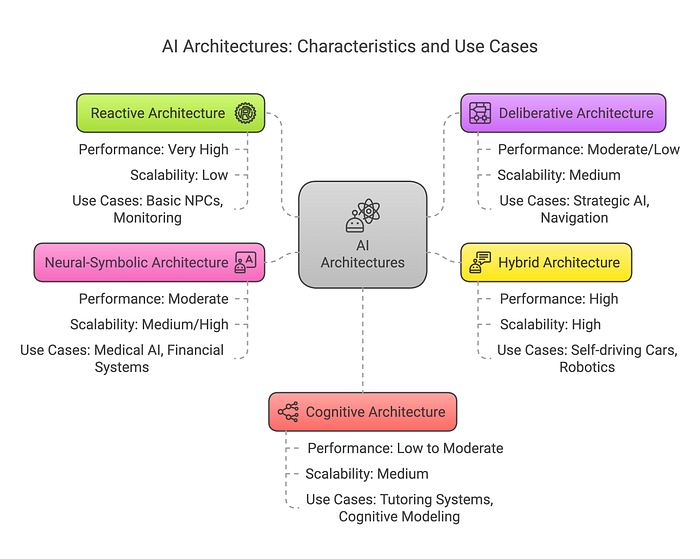
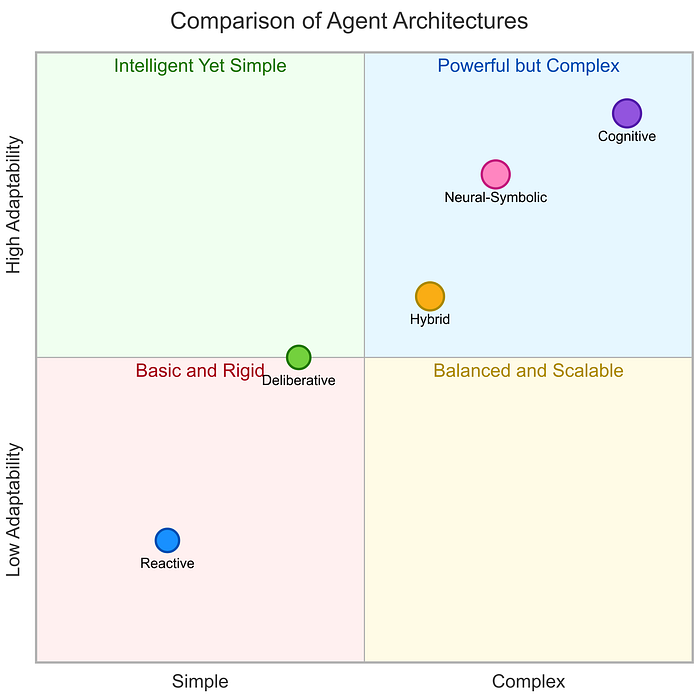
智能體架構大致可分為以下幾類:
- 反應式 (Reactive)
- 慎思式 (Deliberative)
- 混合式 (Hybrid)
- 神經符號式 (Neural-Symbolic)
- 認知式 (Cognitive)
2.1 反應式架構
最直接的AI智能體設計模式被稱為ReAct(思考-行動)。在這種方法中,一個大語言模型(LLM)首先分析情況并決定下一步要采取的行動。然后,該行動在環境中執行,并生成一個觀察結果作為反饋。LLM處理這個觀察結果,重新評估其下一步行動,選擇另一個動作,并持續這個循環,直到它認為任務完成。
2.1.1 用例
-
反應式架構非常適合需要瞬間決策且響應可預測、定義明確的領域。經典的例子包括機器人和游戲:例如,一旦傳感器檢測到障礙物就能反射性避障的掃地機器人或無人機,或者電子游戲中針對玩家動作有預設即時反應的非玩家角色(NPC)(例如,敵人守衛一看到玩家就攻擊)。
-
在工業環境中,簡單的監控智能體可能在傳感器讀數超出范圍時觸發警報或關閉系統。這些智能體在實時控制系統中表現出色,但由于缺乏全局規劃,它們被用于相對簡單或嚴格受限的任務,這些任務的所有情況規則都可以預先定義。
對于簡單的任務,可以輕松地用純代碼構建ReAct設計模式,而無需使用框架。
首先,我們需要一個大語言模型作為智能體的大腦:
from dotenv import load_dotenv
from openai import OpenAI_ = load_dotenv()
client = OpenAI()
然后,我們可以將簡單的智能體構建為一個類來響應我們的消息:
class Agent:def __init__(self, system=""):self.system = systemself.messages = []if self.system:self.messages.append({"role": "system", "content": system})def __call__(self, message):self.messages.append({"role": "user", "content": message})result = self.execute()self.messages.append({"role": "assistant", "content": result})return resultdef execute(self):completion = client.chat.completions.create(model="gpt-4o",temperature=0,messages=self.messages)return completion.choices[0].message.content
接著,我們需要一個系統提示(system prompt)來指導我們的智能體使用另外兩個工具完成任務:一個用于數學計算,另一個用于查找給定犬種的平均體重。
import openai
import re
import httpx
import osprompt = """
You run in a loop of Thought, Action, PAUSE, Observation.
At the end of the loop you output an Answer
Use Thought to describe your thoughts about the question you have been asked.
Use Action to run one of the actions available to you - then return PAUSE.
Observation will be the result of running those actions.Your available actions are:calculate:
e.g. calculate: 4 * 7 / 3
Runs a calculation and returns the number - uses Python so be sure to use floating point syntax if necessaryaverage_dog_weight:
e.g. average_dog_weight: Collie
returns average weight of a dog when given the breedExample session:Question: How much does a Bulldog weigh?
Thought: I should look the dogs weight using average_dog_weight
Action: average_dog_weight: Bulldog
PAUSEYou will be called again with this:Observation: A Bulldog weights 51 lbsYou then output:Answer: A bulldog weights 51 lbs
""".strip()def calculate(what):return eval(what)def average_dog_weight(name):if name in "Scottish Terrier": return("Scottish Terriers average 20 lbs")elif name in "Border Collie":return("a Border Collies average weight is 37 lbs")elif name in "Toy Poodle":return("a toy poodles average weight is 7 lbs")else:return("An average dog weights 50 lbs")known_actions = {"calculate": calculate,"average_dog_weight": average_dog_weight
}prompt = """
You run in a loop of Thought, Action, PAUSE, Observation.
At the end of the loop you output an Answer
Use Thought to describe your thoughts about the question you have been asked.
Use Action to run one of the actions available to you - then return PAUSE.
Observation will be the result of running those actions.
現在,我們可以通過一個循環來構建我們的智能體,使其能夠進行多步工作:
abot = Agent(prompt)def query(question, max_turns=5):i = 0bot = Agent(prompt)next_prompt = questionwhile i < max_turns:i += 1result = bot(next_prompt)print(result)actions = [action_re.match(a) for a in result.split('\\n') if action_re.match(a)]if actions:# There is an action to runaction, action_input = actions[0].groups()if action not in known_actions:raise Exception("Unknown action: {}: {}".format(action, action_input))print(" -- running {} {}".format(action, action_input))observation = known_actions[action](action_input)print("Observation:", observation)next_prompt = "Observation: {}".format(observation)else:returnquestion = """I have 2 dogs, a border collie and a scottish terrier. \\
What is their combined weight"""
query(question)
Thought: I need to find the average weight of a Border Collie and a Scottish Terrier, then add them together to get the combined weight.
Action: average_dog_weight: Border Collie
PAUSE-- running average_dog_weight Border Collie
Observation: a Border Collies average weight is 37 lbs
Action: average_dog_weight: Scottish Terrier
PAUSE-- running average_dog_weight Scottish Terrier
Observation: Scottish Terriers average 20 lbs
Thought: Now that I have the average weights of both dogs, I can calculate their combined weight by adding them together.
Action: calculate: 37 + 20
PAUSE-- running calculate 37 + 20
Observation: 57
Answer: The combined weight of a Border Collie and a Scottish Terrier is 57 lbst
如上所示,該智能體成功地使用兩種不同的工具確定了邊境牧羊犬和蘇格蘭梗的平均體重,然后對結果求和。
2.1.2 優勢與局限性
-
反應式架構的主要優勢是速度。沒有復雜的推理開銷,決策在恒定時間內完成,這對于實時機器人或高頻交易等毫秒級響應至關重要的領域非常理想。
-
反應式智能體的設計和驗證也相對簡單,因為它們的行為由規則明確定義。
-
缺點在于它們的適應性有限,因為它們不學習或規劃,無法輕松處理不可預見的場景或解決需要為實現目標而執行一系列動作的問題。
-
它們也往往是短視的,優化即時響應但不考慮長期后果(如果規則中沒有包含一些戰略邏輯,一個反應式機器人可能會在一個小循環里無休止地徘徊)。這些局限性推動了更先進的、包含內部狀態和推理能力的架構的發展。
研究表明,不同的設計模式更適合不同的任務。我們無需從頭構建這些架構,而是可以利用現有的、經過充分測試的、針對特定問題的解決方案。例如,LangGraph 在其文檔中提供了一系列多智能體架構。
在本文中,我們將探討這些架構以及如何將它們應用到我們的用例中。
2.2 慎思式架構
慎思式(Deliberative)智能體是基于模型的、目標驅動的智能體,它們在行動前進行推理。與即時響應的反應式智能體不同,慎思式智能體提前思考,使用內部模型評估多個可能的動作,并選擇實現其目標的最佳計劃。
感知(Sense)→ 建模(Model)→ 規劃(Plan)→ 行動(Act)
-
感知:從環境接收新的輸入。
-
建模:更新內部世界模型(例如符號狀態、語義地圖)。
-
慎思:生成可能的計劃并模擬/評估其結果。
-
行動:執行最佳計劃或實現目標的下一步。
這種方法類似于象棋AI如何提前規劃好幾步棋,而不是一步一步地反應。
示例偽代碼:一個簡化的慎思式智能體循環(受BDI原則啟發)可能如下所示:
# Pseudocode for a deliberative agent with goal-oriented planning
initialize_state()
while True:perceive_environment(state)options = generate_options(state) # possible plans or actionsbest_option = evaluate_options(options) # deliberation: select best plancommit_to_plan(best_option, state) # update intentionsexecute_next_action(best_option)if goal_achieved(state):break
在這個循環中,generate_options?可以根據當前狀態和目標產生可能的動作或計劃,evaluate_options?應用推理或規劃(例如,模擬結果或使用啟發式方法來選擇一個好的計劃),智能體一步一步地執行動作,并在每次需要時重新評估。這反映了一個慎思式智能體如何考慮未來后果并優化長期目標。例如,在一個路線規劃智能體中,generate_options?可能會創建幾條路線路徑,而?evaluate_options?選擇最短的安全路徑。
2.3 混合架構
混合智能體架構(Hybrid agent architectures)結合了反應式和慎思式系統,以在動態環境中同時實現速度和智能。
- 反應層:對感官輸入做出即時響應(例如,避障)。
- 慎思層:使用內部模型執行目標驅動的規劃(例如,路線規劃)。
- 這些層通常并行運作,以平衡快速響應和長期策略。
該架構通常分層結構:
- 底層:反應式(本能響應)
- 中間層(可選):排序/協調
- 頂層:慎思式(目標推理和規劃)
- 一個協調機制(如監督器或優先級規則)決定哪一層的輸出優先。
percept = sense_environment()if is_urgent(percept): action = reactive_module(percept) # Quick reflex
else:update(world_model, percept)action = deliberative_planner(world_model, current_goal)execute(action)
這種邏輯確保了安全性和效率,既能適應即時威脅,也能適應長期目標。
2.4 神經符號架構
神經符號(Neural-Symbolic 或 Neurosymbolic)架構結合了神經網絡(用于從數據中學習)和符號AI(用于基于規則的推理),使智能體既能夠感知復雜環境,又能對其進行推理。
- 神經網絡:擅長模式識別(例如,圖像、語音)。
- 符號系統:擅長邏輯、推理和可解釋性。
- 結合目標:利用神經感知和符號理解來做出智能的、可解釋的決策。
有兩種主要的集成策略:
-
順序式:神經模塊處理原始輸入(例如,檢測物體);符號模塊對解釋后的輸出進行推理。
-
并行式:神經和符號模塊同時工作,決策模塊融合兩者的輸出。
示例偽代碼:
percept = get_sensor_data()
nn_insights = neural_module.predict(percept) # Perception (e.g., detect anomaly)
sym_facts = symbolic_module.update(percept) # Translate data to logical facts
sym_conclusions = symbolic_module.infer(sym_facts) # Apply domain knowledge
decision = policy_module.decide(nn_insights, sym_conclusions)
execute(decision)
這使得學習到的洞察和指導行動的顯式規則得以結合。
2.5 認知架構
認知架構(Cognitive architectures)是旨在模擬類人通用智能的綜合框架,通過將感知、記憶、推理和學習集成到一個統一的智能體系統中。
- 受人類認知啟發。
- 遵循感知-思考-行動(Sense–Think–Act)循環:
- 感知環境
- 更新工作記憶
- 使用產生式規則進行推理和決策
- 通過執行器行動
- 旨在構建能夠像人類一樣學習、規劃、解決問題和適應的智能體。
2.5.1 SOAR 架構
- 開發于20世紀80年代,用于實現通用智能行為。
- 工作記憶:保存當前情境。
- 產生式記憶:存儲“如果-那么”規則。
- 使用通用子目標(universal subgoaling)——在遇到困難時設定子目標。
- 學習:使用“組塊化(chunking)”——將經驗轉化為新規則。
- 示例用例:AI飛行員、人形機器人、決策智能體。
2.5.2 ACT-R 架構
- 根植于認知心理學。
- 由專用模塊組成(例如,視覺、運動、記憶)。
- 每個模塊使用自己的緩沖區作為臨時工作記憶。
- 產生式規則管理緩沖區之間的數據流。
- 結合了符號推理和亞符號機制(如記憶激活)。
共同特點
- 模塊化設計(感知、記憶、動作模塊)。
- 多記憶系統:
- 陳述性記憶(事實)
- 程序性記憶(技能/規則)
- 有時包括情景記憶(過去事件)
- 內置學習(Soar的組塊化,ACT-R的調優)。
簡化認知循環:
percept = perceive_environment()
update_working_memory(percept)
action = cognitive_reasoner.decide(working_memory)
execute(action)
像 SOAR 和 ACT-R 這樣的認知架構提供了一個整體性的智能模型,集成了感知、記憶、決策和學習。它們不僅用于構建智能體——還幫助我們理解人類思維的工作方式。這些系統非常適合需要隨時間學習、處理多樣化任務并能像人類一樣推理的智能體。
3. LangGraph 中的智能體設計模式
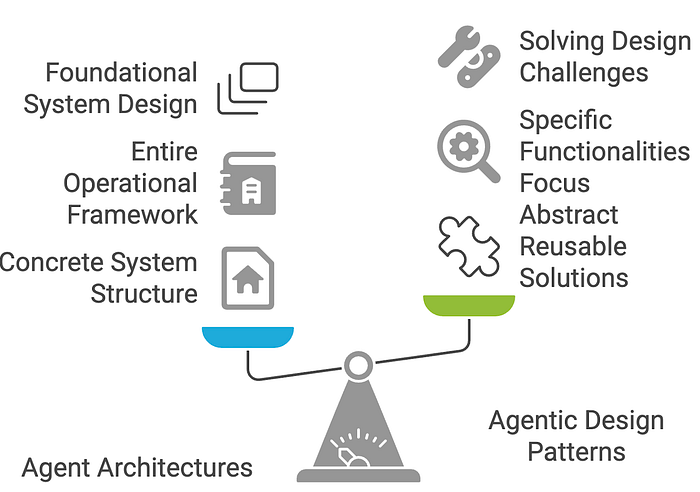
智能體架構(Agent architectures)和智能體設計模式(agentic design patterns)密切相關,但它們在AI智能體開發中處于不同的抽象層次。
智能體架構指的是結構框架或藍圖,定義了智能體如何構建和運作。它關乎核心組件及其組織方式——可以把它看作是智能體的“骨架”。一個架構規定了智能體如何感知環境、處理信息、做出決策并采取行動。
架構通常更多地關乎系統構建的“方式”——低層機制以及數據或控制流。
智能體設計模式則是更高層次、可復用的策略或模板,用于解決基于智能體的系統中的特定問題。它們較少關注智能體內部的具體細節,而更多地指導行為或交互方式,使其能夠適應不同的上下文。可以將它們視為實現某些結果的“配方”。
設計模式關注“什么”和“為什么”——你希望智能體表現出什么行為或能力,以及為什么這種模式對特定場景有效。
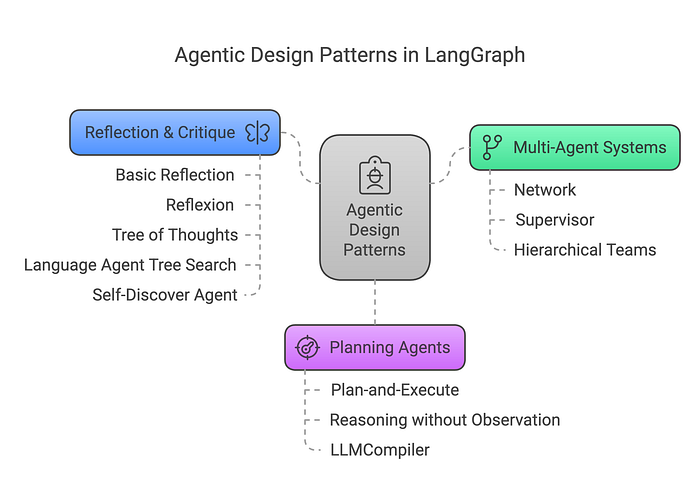
LangGraph 將這些智能體架構組織成三個主要組:
3.1 多智能體系統 (Multi-Agent Systems)
- 網絡 (Network)
- 監督者 (Supervisor)
- 分層團隊 (Hierarchical Teams)
3.2 規劃智能體 (Planning Agents)
- 規劃并執行 (Plan-and-Execute)
- 無觀察推理 (Reasoning without Observation)
- LLM編譯器 (LLMCompiler)
3.3 反思與批判 (Reflection & Critique)
- 基本反思 (Basic Reflection)
- Reflexion
- 思維樹 (Tree of Thoughts)
- 語言智能體樹搜索 (Language Agent Tree Search)
- 自我發現智能體 (Self-Discover Agent)
下面讓我們深入了解這些智能體設計模式。
4. 多智能體系統
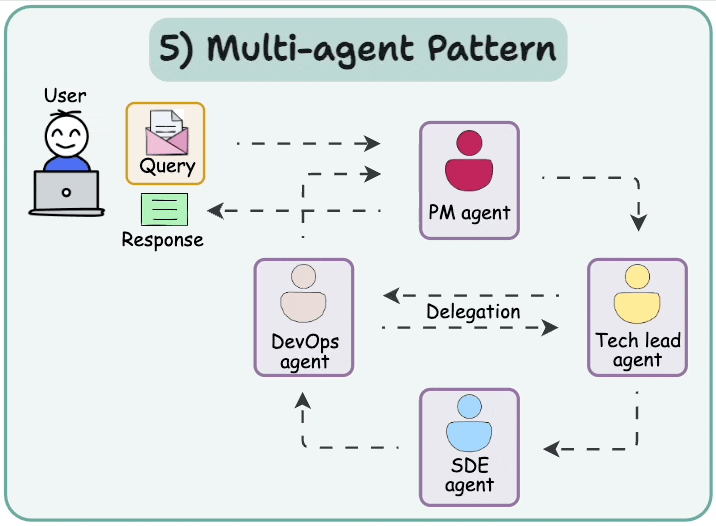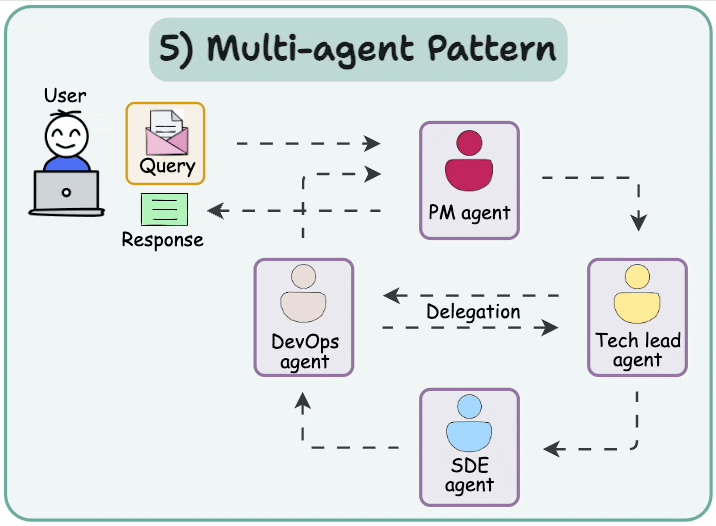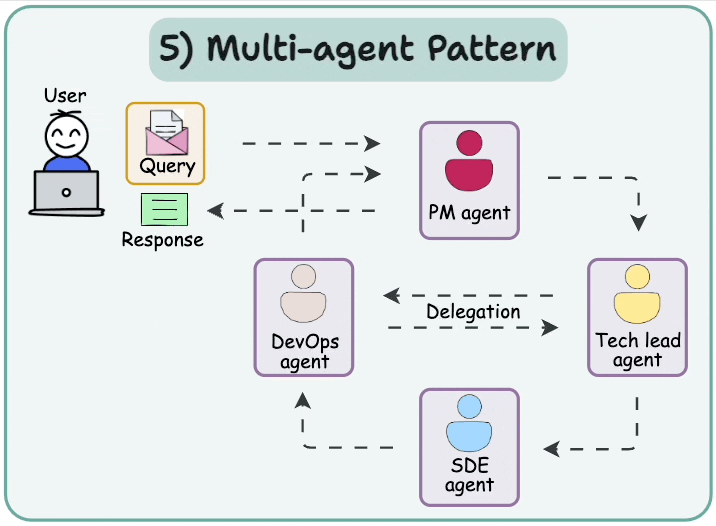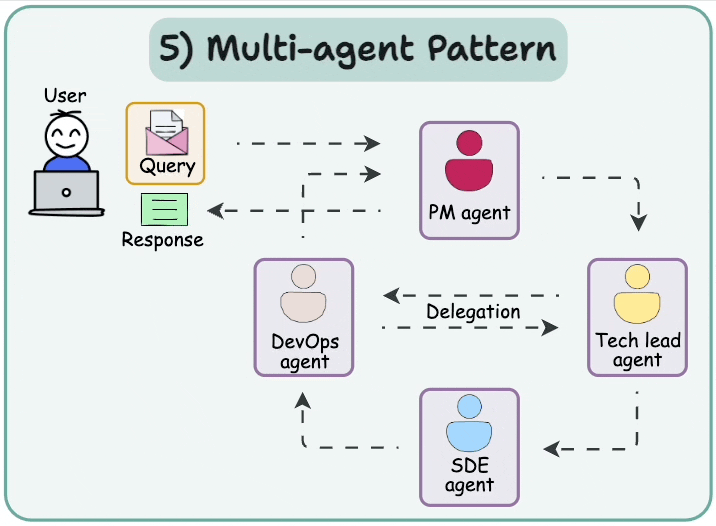
4.1 多智能體網絡 (Multi-agent Network)
解決復雜任務的一種方法是使用分而治之的策略。使用一個路由器(router),任務可以被路由到專門處理該特定任務的智能體。
這種架構稱為多智能體網絡架構。
4.2 多智能體監督者 (Multi-agent Supervisor)
這種架構與網絡架構非常相似,區別在于有一個監督者智能體(supervisor agent)來協調不同的智能體,而不是路由器。
4.3 分層智能體團隊 (Hierarchical Agent Teams)
分層團隊架構源于這樣一個想法:“如果單個智能體不足以解決特定任務怎么辦?”。在這種情況下,不是監督者智能體協調多個智能體,而是監督者智能體協調由多個智能體組成的幾個團隊。
5. 規劃智能體
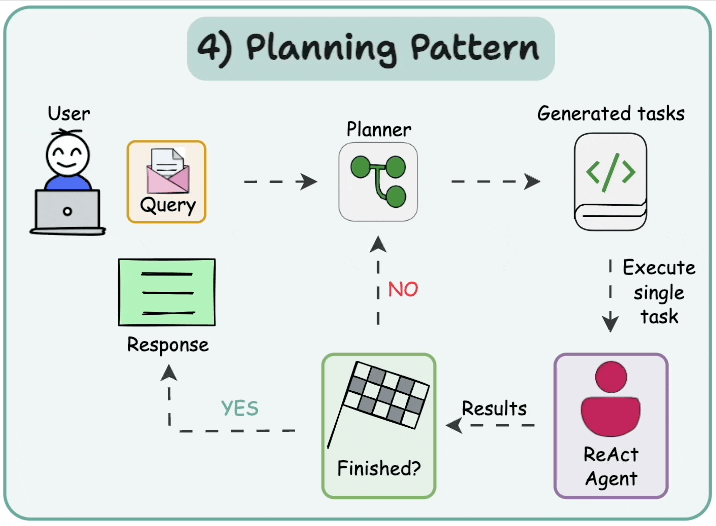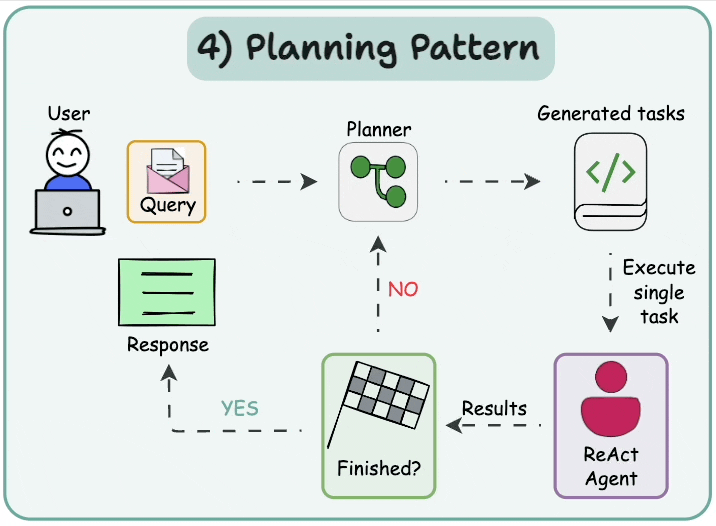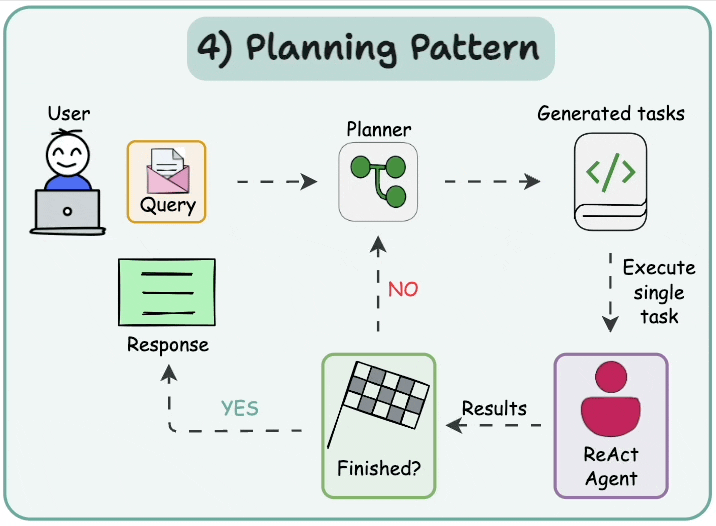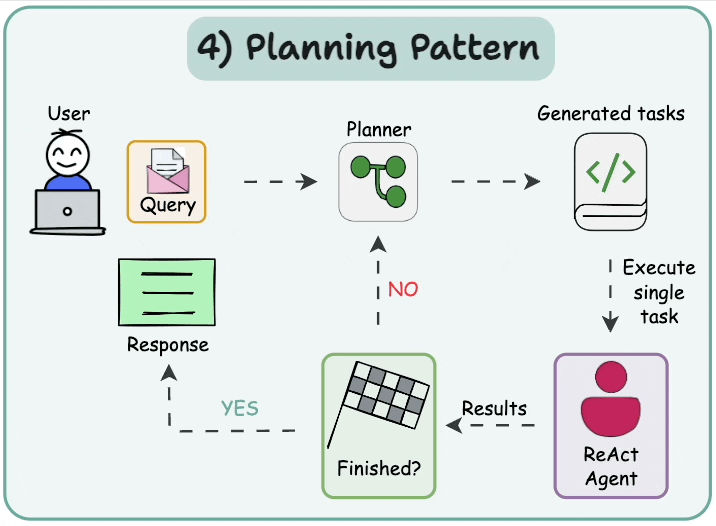
5.1 規劃并執行 (Plan-and-execute)
在這種架構中,首先智能體根據給定任務按順序生成子任務。然后,單任務(專業化)智能體解決這些子任務,如果任務完成,結果將發送回規劃器智能體。規劃器智能體根據結果制定不同的計劃。如果任務完成,規劃器智能體則響應用戶。
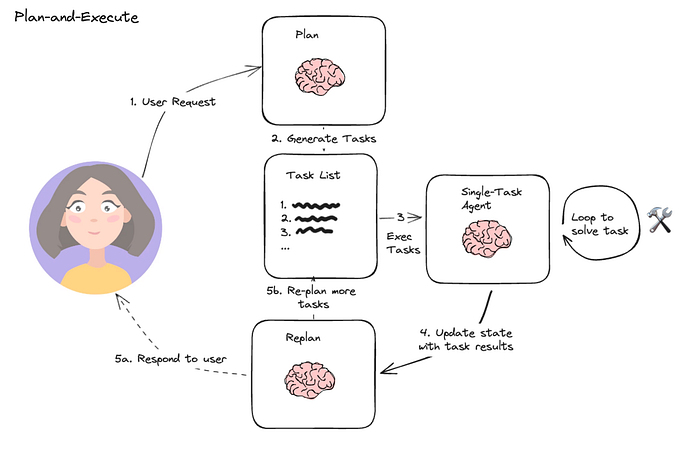
5.2 無觀察推理 (Reasoning without observation - ReWOO)
在 ReWOO 中,Xu et al.?等人提出了一種智能體,它集成了多步規劃器和變量替換來優化工具使用。這種方法非常類似于規劃并執行架構。然而,與傳統模型不同,ReWOO 架構在每個動作之后不包括觀察步驟。相反,整個計劃是預先創建的并且保持固定,不受任何后續觀察的影響。
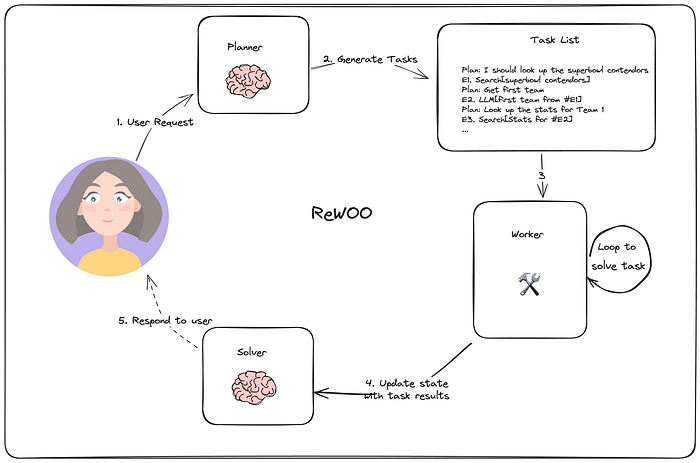
規劃器智能體構建一個包含子任務的計劃來解決任務,工作智能體(worker agents)只需完成子任務,然后響應用戶。
5.3 LLM編譯器 (LLMCompiler)
LLMCompiler 是一種智能體架構,旨在通過在有向無環圖(DAG)中急切執行(eagerly-executed)任務來加速智能體任務的執行。它還通過減少調用LLM的次數來節省冗余令牌使用的成本。以下是其計算圖的概述:
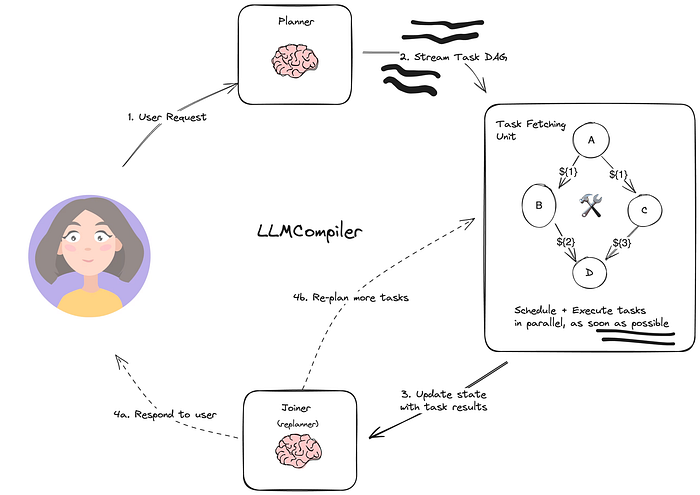
它具有三個主要組件:
- 規劃器 (Planner):流式處理一個任務DAG。
- 任務獲取單元 (Task Fetching Unit):一旦任務可執行,就立即調度和執行它們。
- 連接器 (Joiner):響應用戶或觸發第二個計劃。
6. 反思與批判
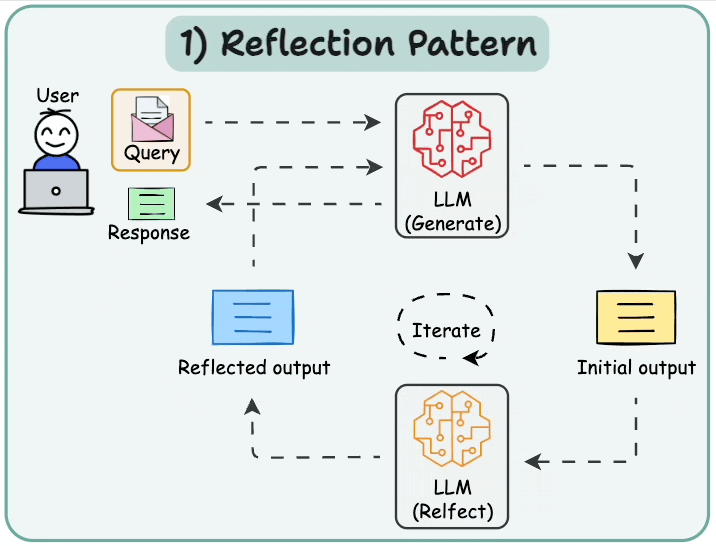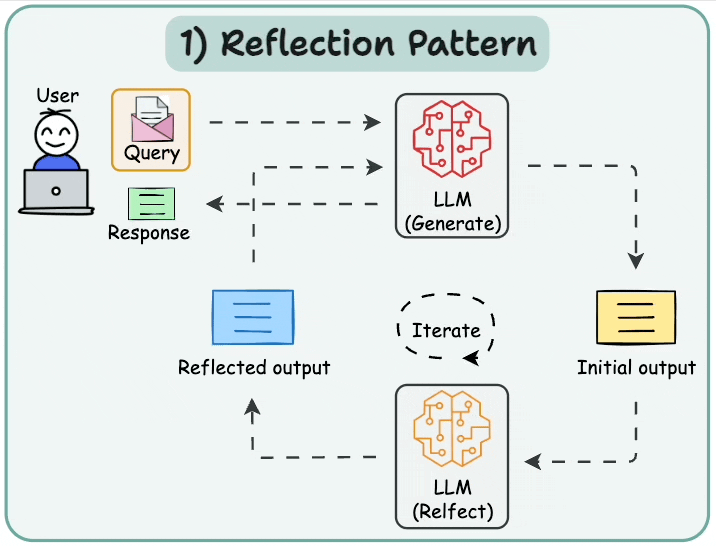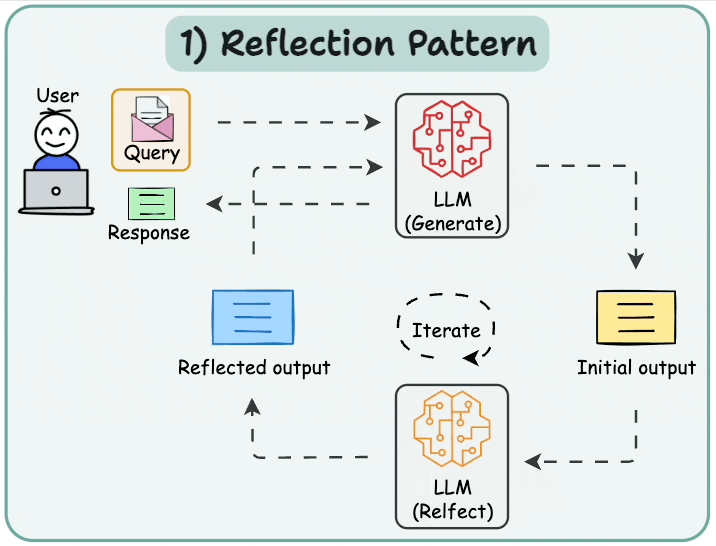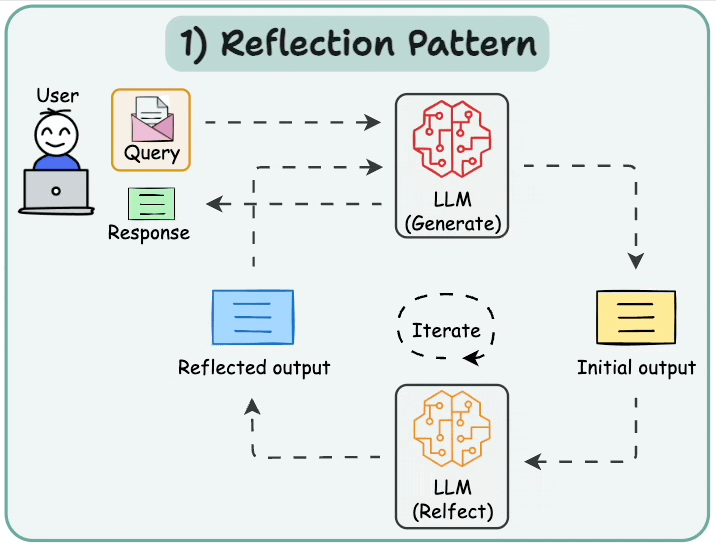
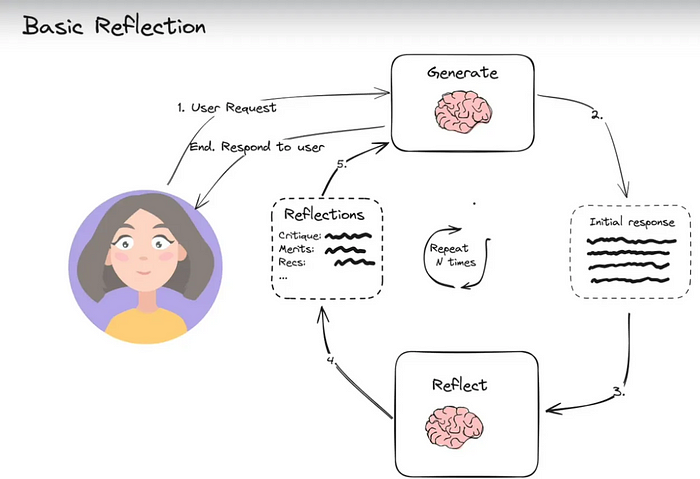
6.1 基本反思 (Basic Reflection)
反思智能體提示LLM對其過去的行動進行反思,使其能夠隨著時間學習改進。有兩個智能體:生成器(generator)和批判者(critique)。最簡單的例子可能是一個寫手和評論家。寫手根據用戶請求撰寫文本,評論家審查文本,然后將他們的反思發送回寫手。這個循環持續進行直到達到給定的迭代次數。
6.2 Reflexion
Reflexion(由 Shinn 等人提出)是一種旨在通過語言反饋和自我反思來學習的架構。該智能體明確地批判其任務響應,以生成更高質量的最終響應,但代價是更長的執行時間。與反思架構相比,Reflexion 智能體還包括工具執行。
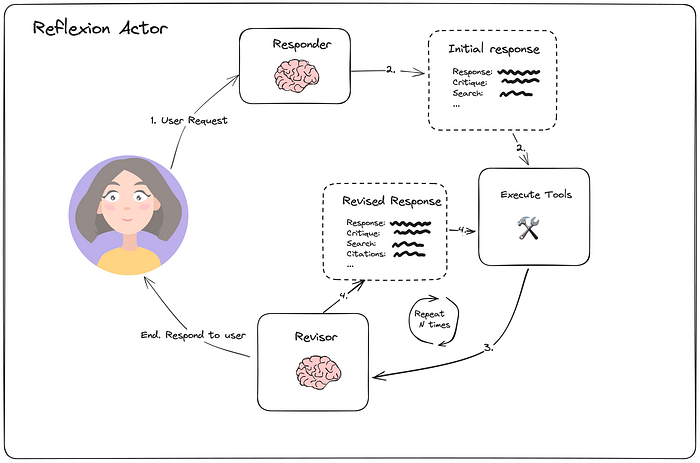
《Reflexion: Language Agents with Verbal Reinforcement Learning》
該論文概述了3個主要組件:
- 具有自我反思能力的執行者(Actor (agent))
- 外部評估器(External evaluator)(特定于任務,例如代碼編譯步驟)
- 情景記憶(Episodic memory),存儲來自(1)的反思。
6.3 思維樹 (Tree of Thoughts - ToT)
思維樹(ToT,由 Yao, et. al?等人提出)是一種通用的LLM智能體搜索算法,它結合了反思/評估和簡單搜索(在這種情況下是廣度優先搜索BFS,但如果你愿意,也可以應用深度優先搜索DFS或其他算法)。
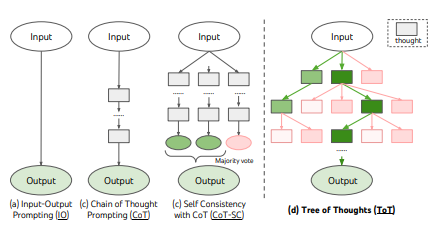
它具有三個主要步驟:
-
擴展 (Expand):生成問題的一個或多個候選解決方案。
-
評分 (Score):衡量響應的質量。
-
剪枝 (Prune):保留前K個最佳候選方案
如果未找到解決方案(或解決方案質量不足),則返回“擴展”步驟。
6.4 語言智能體樹搜索 (Language Agent Tree Search - LATS)
語言智能體樹搜索(LATS,由 Zhou, et. al?等人提出)是一種通用的LLM智能體搜索算法,它結合了反思/評估和搜索(特別是蒙特卡洛樹搜索 Monte-Carlo Tree Search),與 ReACT、Reflexion 或思維樹(ToT)等類似技術相比,實現了更好的整體任務性能。
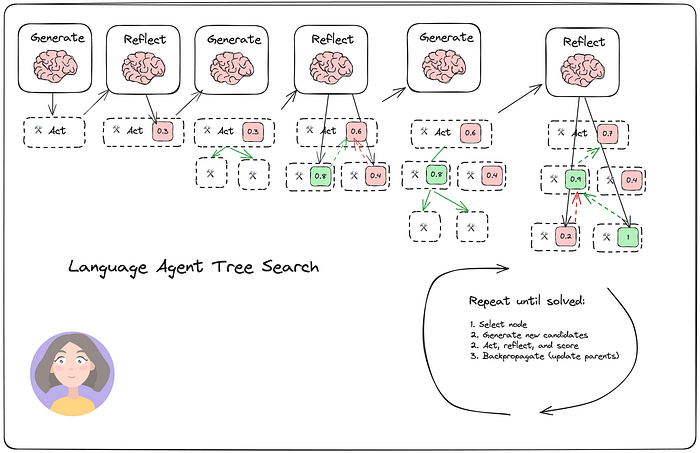
它具有四個主要步驟:
- 選擇 (Select):根據步驟(2)的聚合獎勵選擇最佳下一步動作。要么響應(如果找到解決方案或達到最大搜索深度),要么繼續搜索。
- 擴展和模擬 (Expand and simulate):選擇“最佳”的5個潛在動作并行執行。
- 反思 + 評估 (Reflect + Evaluate):觀察這些動作的結果,并根據反思(以及可能的外部反饋)對決策進行評分。
- 反向傳播 (Backpropagate):根據結果更新根軌跡(root trajectories)的分數。
6.5 自我發現智能體 (Self-Discover Agent)
自我發現(Self-discover)幫助大語言模型(LLMs)找出思考和解決復雜問題的最佳方式。
-
首先,它通過挑選和改變基本推理步驟來為每個問題找到一個獨特的計劃。
-
然后,它使用這個計劃一步一步地解決問題。
這樣,與只使用一種方法相比,LLM使用了不同的推理工具并適應問題,從而獲得更有效的解決方案。
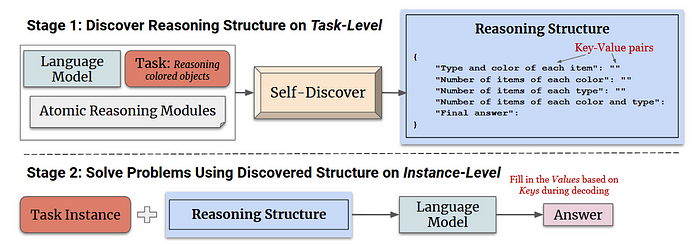
自我發現與其他規劃方法的不同之處在于它會自動為每個任務創建獨特的推理策略。以下是它的不同之處:
-
推理模塊 (Reasoning Modules):它使用基本推理步驟并按特定順序將它們組合起來。
-
無需人工幫助 (No Human Help):它自行找出這些策略,不需要人工標注任務。
-
適應任務 (Adapts to the Task):它找到解決每個問題的最佳方式,就像人類制定計劃一樣。
-
可遷移 (Transferable):它創建的推理策略可以被不同類型的語言模型使用。
簡而言之,自我發現的獨特之處在于它結合了不同的推理方法,無需特定的任務指令即可創建計劃。
7. 結語
在本篇博客中,我們探討了智能體架構不斷發展的面貌,從傳統的反應式和慎思式模型,到更先進的混合式、神經符號式和認知式系統。然后,我們將這些基本概念與使用 LangGraph 的現代實現聯系起來,展示了強大的智能體設計模式,如規劃、協作、反思和批判。隨著我們繼續構建越來越智能和自主的系統,理解和應用這些架構原則將是解鎖可擴展、模塊化和目標驅動的AI解決方案的關鍵。AI的未來不在于孤立的智能,而在于協調、反思和有目的的智能體共同合作解決復雜任務。




)






 實現)




)


