01數據結構-Prim算法
- 1.普利姆(Prim)算法
- 1.1Prim算法定義
- 1.2Prim算法邏輯
- 1.3Prim代碼分析
- 2.Prim算法代碼實現
1.普利姆(Prim)算法
1.1Prim算法定義
Prim算法在找最小生成樹的時候,將頂點分為兩類,一類是在查找的過程中已經包含在生成樹中的頂點(假設為A類),剩下的另一類為B類。
對于給定的連通圖,起始狀態全部頂點都為B類。在找最小生成樹時,選定任意一個頂點作為起始點,并將之從B類移至A類;然后找出B類中到A類中的頂點之間權值最小的頂點,將之從B類移至A類,如此重復,直到B類中沒有頂點為止。所走過的頂點和邊就是該連通圖的最小生成樹。(簡單對比一下:上一節課的Kruskal是找邊,這幾棵的Prim算法是找頂點。)
1.2Prim算法邏輯
動態維護一個所有待激活的頂點數組,從圖中任意選取一個頂點激活它,激活了后就能發現新的邊,找到權值數組里最小的邊,激活另外一個頂點,更新權值數組,再來找權值數組里最小的邊,激活另外的頂點,以此重復,直到所有頂點都激活。
如圖1我們先激活A,激活后發現新的邊,更新權值數組里的值,A連著B,F,G,所以很明顯我們需要更新B,F,G下的權值,其他沒有直接連接的我們暫時認為權值無窮大,找到權值數組里面最小的邊是AB這條,激活B頂點,發現新的邊,更新權值數組里的邊,B連著A,F,C,由于A和B已激活,我們看需不需要更新F和C下的權值,發現B到F的這條邊的權值是7<16,我們更新F下的權值為7,C下的權值為10,激活F頂點。
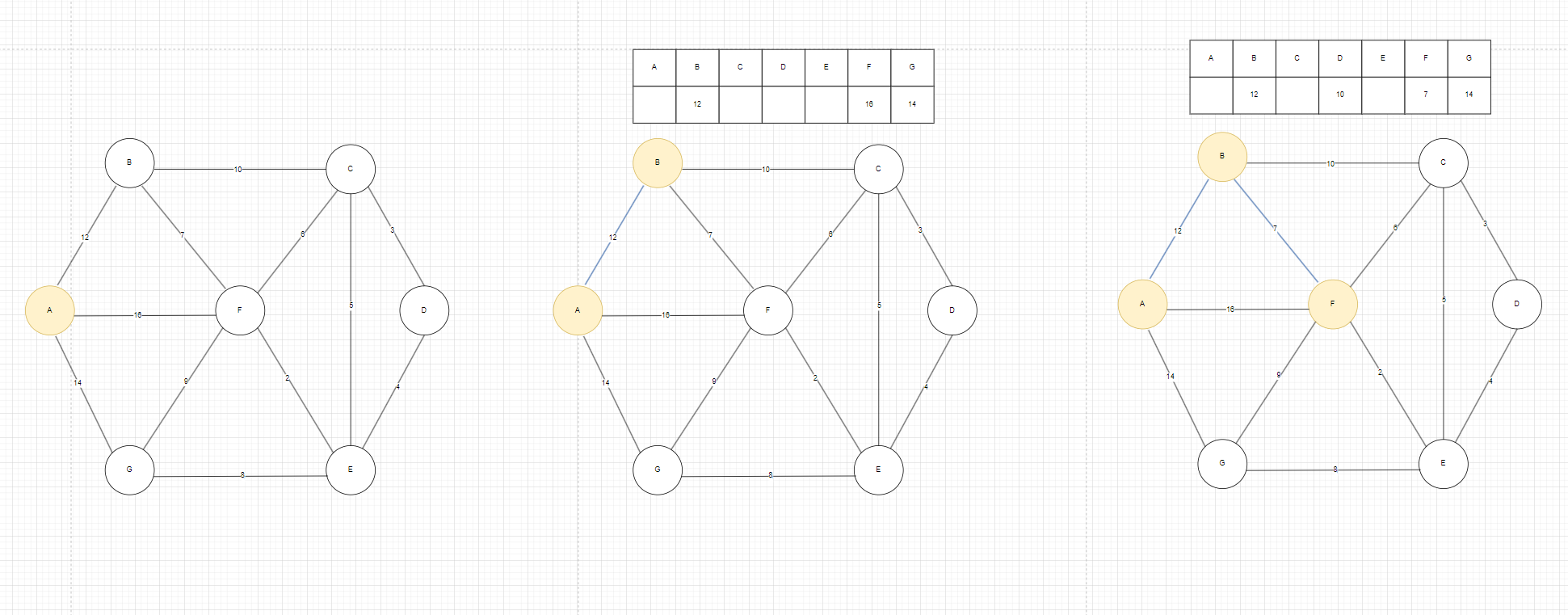
圖1
以此重復這個過程,最終結果如圖2,在找到C之后,就只有G沒有激活了,G的有三條邊,選取最小的那條邊8作為權值數組里面的值。
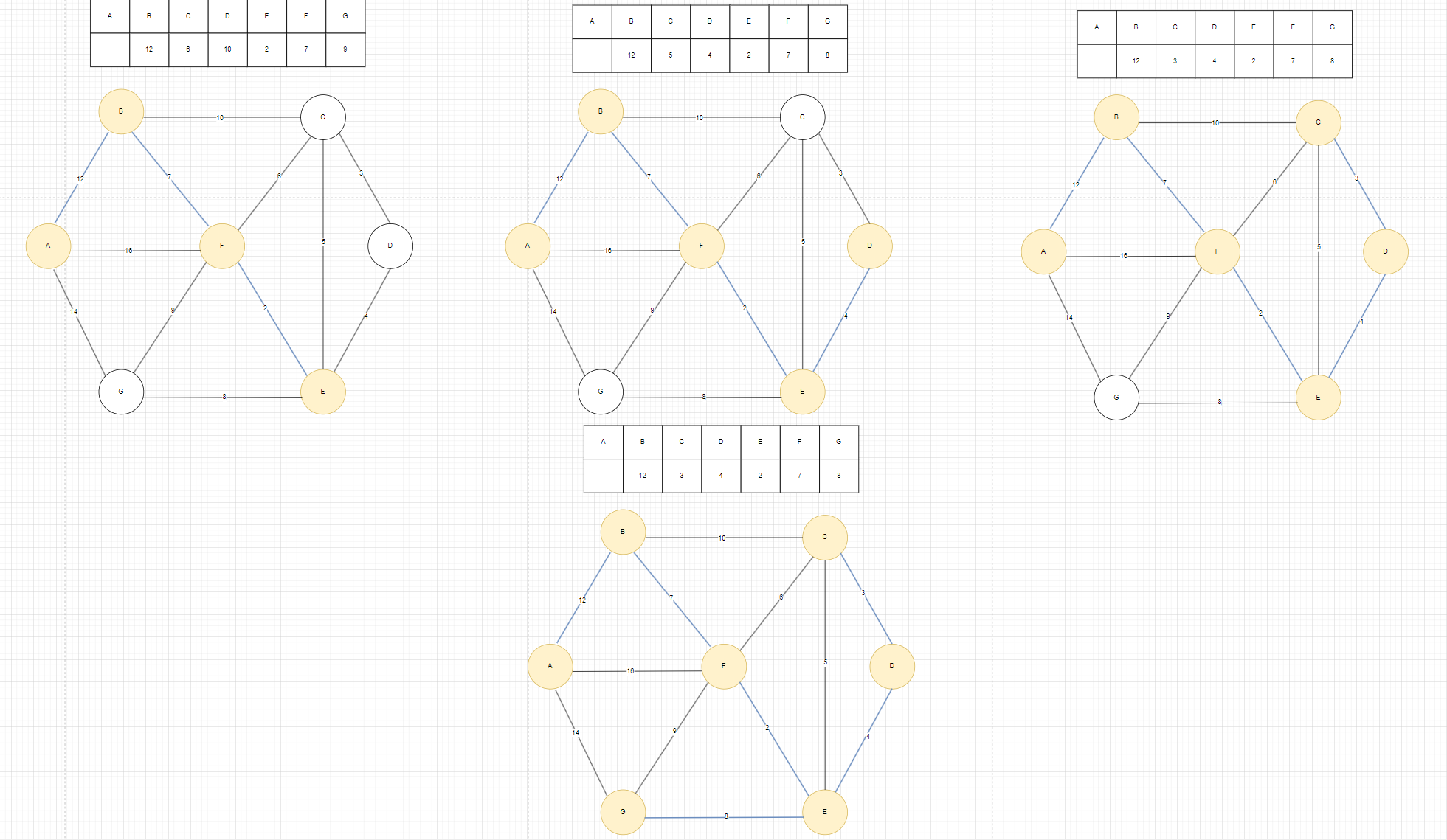 圖2
圖2
如圖3,注意在這里Kruskal算法和Prim算法最后構成的最小生成樹一樣,但在實際過程中,這兩種算法構建出來的最小生成樹可能不一樣。
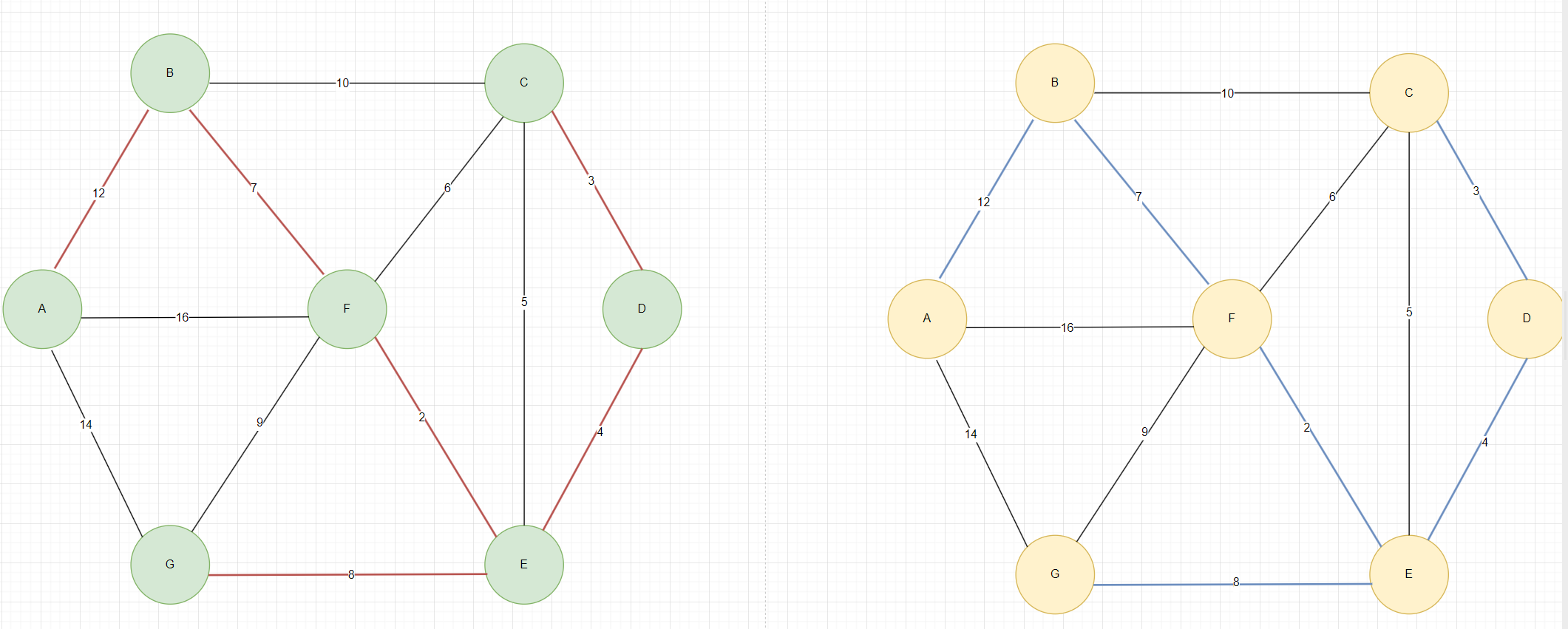
圖3
1.3Prim代碼分析
如圖4我們定義一個cost數組,里面存的是權值數組,初始時,每個邊都是INF(無窮大),一個visited數組存已經被激活的點,由于我不想只打印出最后的權值大小,我還想打印打出對應選取了哪些邊在最小生成樹中,初始化時全部設為-1,意味著沒有激活前,沒有其他的頂點到自己。
第一次激活A點,A連著有三條邊,分別對應的頂點是B,F,G,在cost中A激活那一行填寫對應的權值,在該行中找到最小的權值,標黃,cost標了黃色的格子意味著是當前一行權值數組中最小的邊,激活它,后面在更新權值數組的時候就可以不用管黃色的那一列了。在visited數組中,由于A的激活,我們發現三條邊對應的是B,F,G,說明A能到B,F,G我們就在A激活那一行中填寫A到了這三個頂點,但我們一次只能確定一個誰可以被保留,因為我們在costA激活的那一行中,一次只能找到一個最小權值,有的同學可能會問,為什么要把visited中A激活那一行F和G下的A也暫時保留呢,由上1.2分析得后面B是要連F得,但如果連接BF的那條邊很大,比連接AF下的邊大,那么我們就不是B到F,而是A到F,如果不保留的話就找不到了。由于我們激活的是B,又開始對B執行上述邏輯操作,一直到所有頂點被激活。
visited中A激活那里B列下的A要標黃,意味著確定了最小生成樹中其中某一條邊的頂點是這兩個
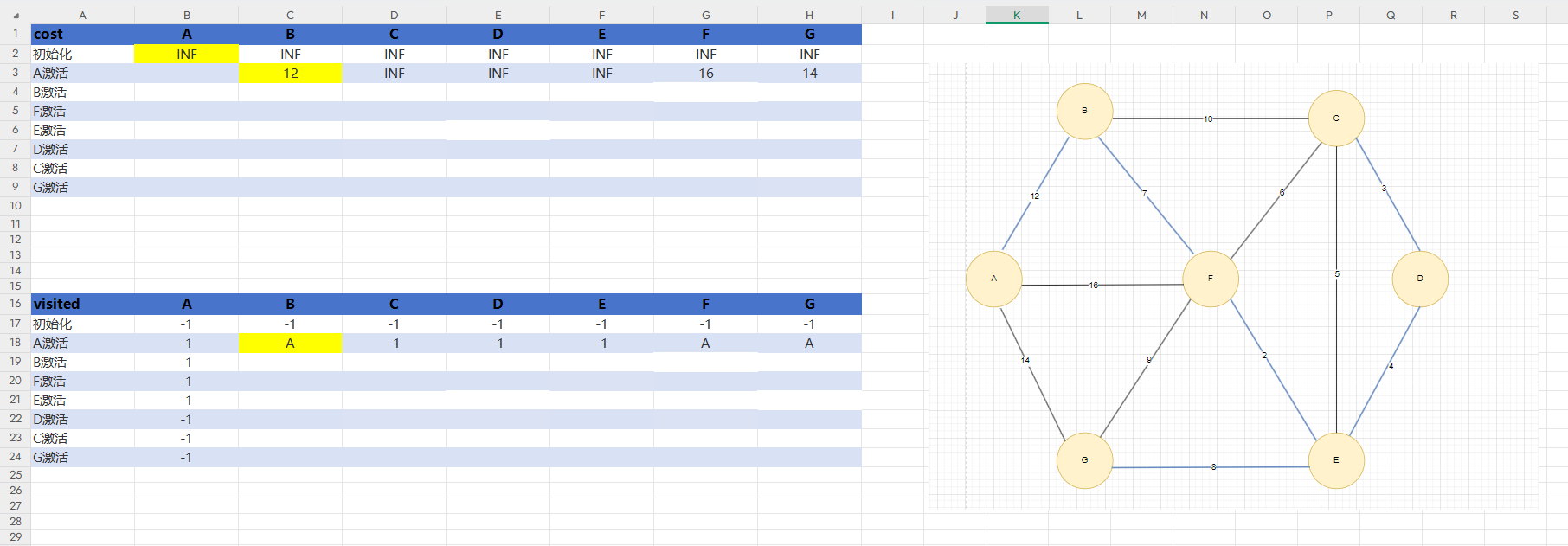
圖4
過程和結果如圖5:
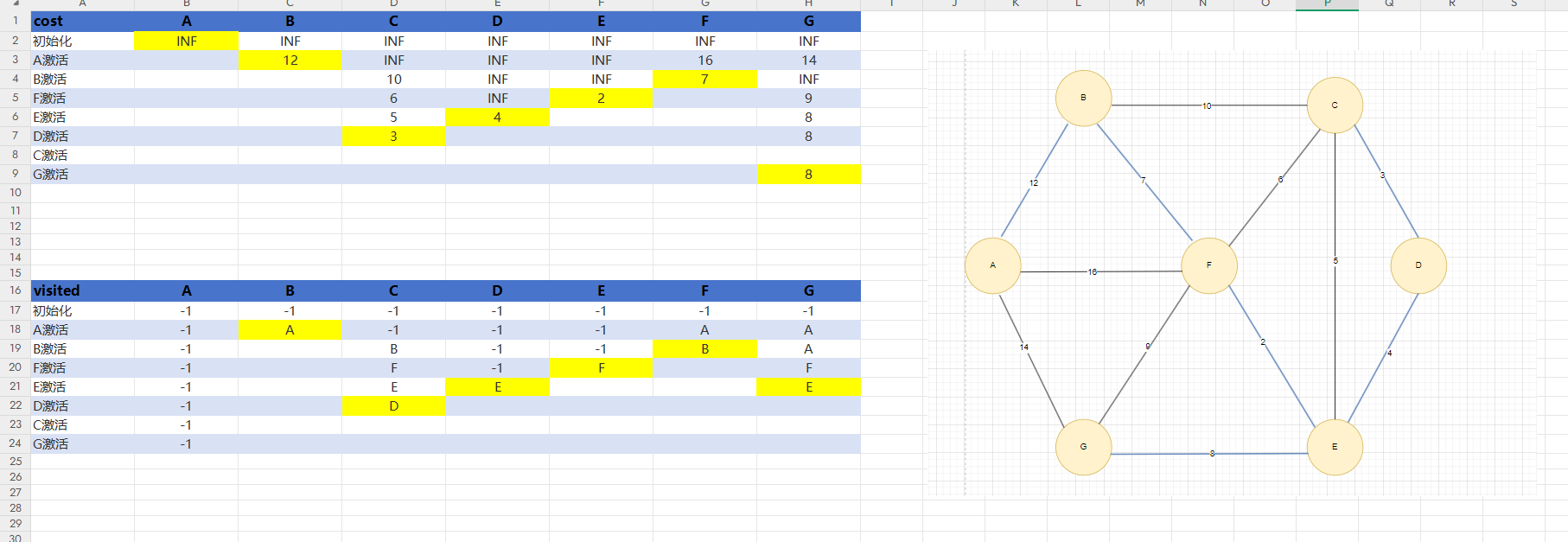
圖5
注意實際代碼實現的時候并不是二維數組,而是意味數組,我這里畫成二維數組只是方便看過程。
2.Prim算法代碼實現
先來看測試的接口:
void setupMGraph(MatrixGraph *graph, int edgeValue) {// 0 1 2 3 4 5 6char *names[] = {"A", "B", "C", "D", "E", "F", "G"};initMatrixGraph(graph, names, sizeof(names)/sizeof(names[0]), 0, edgeValue);addMGraphEdge(graph, 0, 1, 12);addMGraphEdge(graph, 0, 5, 16);addMGraphEdge(graph, 0, 6, 14);addMGraphEdge(graph, 1, 2, 10);addMGraphEdge(graph, 1, 5, 7);addMGraphEdge(graph, 2, 3, 3);addMGraphEdge(graph, 2, 4, 5);addMGraphEdge(graph, 2, 5, 6);addMGraphEdge(graph, 3, 4, 4);addMGraphEdge(graph, 4, 5, 2);addMGraphEdge(graph, 4, 6, 8);addMGraphEdge(graph, 5, 6, 9);
}void test02() {MatrixGraph graph;EdgeSet *result;int sumWeight = 0;setupMGraph(&graph, INF);result = malloc(sizeof(EdgeSet) * (graph.edgeNum - 1));if (result == NULL) {return;}sumWeight = PrimMGraph(&graph, 0, result);printf("sumWeight = %d\n", sumWeight);for (int i = 0; i < graph.nodeNum - 1; ++i) {printf("edge %d: <%s> ---- <%d> ---- <%s>\n", i + 1,graph.vex[result[i].begin].show, result[i].weight,graph.vex[result[i].end].show);}
}我們在void setupMGraph(MatrixGraph *graph, int edgeValue)中沒有相連的兩個頂點之間的權值賦為INF,相連的兩個頂點間賦值相應的權值,在void test02()中用PrimMGraph(&graph, 0, result);得到權值總和并隨后打印出邊和頂點的信息
Prim算法核心:int PrimMGraph(const MatrixGraph* graph, int startV, EdgeSet* result);
/* graph: 表示指向鄰接矩陣的圖結構* startV:表示激活的第一個頂點坐標* result:表示最小生成樹的邊的激活情況*/
int PrimMGraph(const MatrixGraph* graph, int startV, EdgeSet* result) {int *cost = malloc(sizeof(int) * graph->nodeNum); // 圖中各頂點的權值數組int *mark = malloc(sizeof(int) * graph->nodeNum); // 圖中頂點激活的狀態int *visited = malloc(sizeof(int) * graph->nodeNum); // 從哪個頂點開始訪問,-1表示沒有被訪問到int sum = 0;// 1. 更新第一個節點激活的狀態for (int i = 0; i < graph->nodeNum; i++) {cost[i] = graph->edges[startV][i];mark[i] = 0;// 1.1 更新visit信息,從哪個節點可以訪問if (cost[i] < INF) {visited[i] = startV;} else {visited[i] = -1;}}mark[startV] = 1;int k = 0;// 2. 動態激活節點,找最小值for (int i = 0; i < graph->nodeNum - 1; ++i) {// 找未加入樹且cost最小的頂點kint min = INF;k = 0;for (int j = 0; j < graph->nodeNum; ++j) {if (mark[j] == 0 && cost[j] < min) {min = cost[j];k = j;}}// 將k加入樹,記錄邊信息mark[k] = 1;result[i].begin = visited[k];result[i].end = k;result[i].weight = min;sum += min;// 每激活一個頂點,需要更新cost數組for (int j = 0; j < graph->nodeNum; ++j) {if (mark[j] == 0 && graph->edges[k][j] < cost[j]) {cost[j] = graph->edges[k][j];visited[j] = k;}}}free(cost);free(mark);free(visited);return sum;
}我們需要申請三個空間分別用來存圖中各頂點的權值數組,圖中頂點激活的狀態和對應帶權邊的兩個頂點信息。
先來看1.更新第一個節點激活的狀態,在cost里面存放激活的第一個頂點與圖中其他頂點間的邊的權值大小,并默認所有頂點還未被訪問,然后更新visited數組中的信息,如果cost里面存的權值大小小于INF,則把對應visited數組下的值填成starV,說明兩個頂點之間有邊,否則就認為starV頂點與其無邊,在對應visited數組下設為-1,初始化完我們認為starV已被訪問:mark[startV] = 1;此時三個數組如圖6:
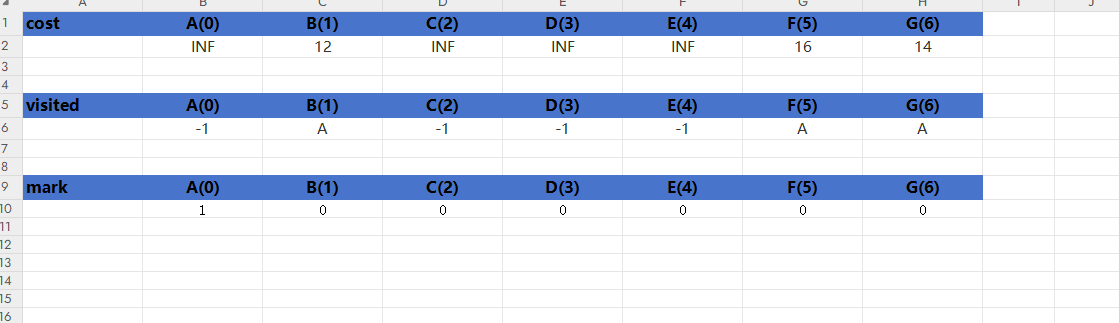
圖6
定義一個k標記待加入的頂點:
在每次循環中,程序會遍歷所有未加入生成樹的頂點(mark[j] == 0),找到 cost[j] 最小的頂點,并用 k 記錄該頂點的索引。這個頂點 k 就是本次要加入生成樹的頂點。
作為新頂點更新后續狀態:
當 k 被標記為 “已加入生成樹”(mark[k] = 1)后,程序會以 k 為新的起點,更新其他未加入頂點的 cost 和 visited 數組。此時 k 成為 “已生成樹” 的一部分,用于后續計算其他頂點與樹的最小連接邊權。
來看2,先定義一個最小值,這個最小值存的是INF,這樣比這個最小值小就可以加入cost里了,找未加入樹且cost最小的頂點k,找到過后將k加入樹,記錄邊信息并把k加入mark標記中說明已被訪問。每次激活一個頂點,需要更新cost里面的權值當然更新的時候只更新沒有訪問過的頂點,因為已被訪問過的頂點已經被我們納入了最小生成樹中,即我們不需要更新圖4,圖5中cost和visited里面標黃的部分。循環 graph->nodeNum - 1次,因為先前已經加入了starV頂點,初始時有 1 個頂點,循環 graph->nodeNum - 1 次后,新增 graph->nodeNum - 1 個頂點,總共加入的頂點數為graph->nodeNum個。
最后測一下:
#include <stdio.h>
#include <stdlib.h>
#include "Kruskal.h"
#include "Prim.h"void setupMGraph(MatrixGraph *graph, int edgeValue) {// 0 1 2 3 4 5 6char *names[] = {"A", "B", "C", "D", "E", "F", "G"};initMatrixGraph(graph, names, sizeof(names)/sizeof(names[0]), 0, edgeValue);addMGraphEdge(graph, 0, 1, 12);addMGraphEdge(graph, 0, 5, 16);addMGraphEdge(graph, 0, 6, 14);addMGraphEdge(graph, 1, 2, 10);addMGraphEdge(graph, 1, 5, 7);addMGraphEdge(graph, 2, 3, 3);addMGraphEdge(graph, 2, 4, 5);addMGraphEdge(graph, 2, 5, 6);addMGraphEdge(graph, 3, 4, 4);addMGraphEdge(graph, 4, 5, 2);addMGraphEdge(graph, 4, 6, 8);addMGraphEdge(graph, 5, 6, 9);
}void test02() {MatrixGraph graph;EdgeSet *result;int sumWeight = 0;setupMGraph(&graph, INF);result = malloc(sizeof(EdgeSet) * (graph.edgeNum - 1));if (result == NULL) {return;}sumWeight = PrimMGraph(&graph, 0, result);printf("sumWeight = %d\n", sumWeight);for (int i = 0; i < graph.nodeNum - 1; ++i) {printf("edge %d: <%s> ---- <%d> ---- <%s>\n", i + 1,graph.vex[result[i].begin].show, result[i].weight,graph.vex[result[i].end].show);}
}int main() {test02();return 0;
}
結果:
D:\work\DataStruct\cmake-build-debug\03_GraphStruct\MiniTree.exe
sumWeight = 36
edge 1: <A> ---- <12> ---- <B>
edge 2: <B> ---- <7> ---- <F>
edge 3: <F> ---- <2> ---- <E>
edge 4: <E> ---- <4> ---- <D>
edge 5: <D> ---- <3> ---- <C>
edge 6: <E> ---- <8> ---- <G>進程已結束,退出代碼為 0大概先寫這些吧,今天的博客就先寫到這,謝謝您的觀看。


![[激光原理與應用-264]:理論 - 幾何光學 - 什么是焦距,長焦與短焦的比較](http://pic.xiahunao.cn/[激光原理與應用-264]:理論 - 幾何光學 - 什么是焦距,長焦與短焦的比較)

)




)







![Rust 項目編譯故障排查:從 ‘onnxruntime‘ 鏈接失敗到 ‘#![feature]‘ 工具鏈不兼容錯誤](http://pic.xiahunao.cn/Rust 項目編譯故障排查:從 ‘onnxruntime‘ 鏈接失敗到 ‘#![feature]‘ 工具鏈不兼容錯誤)

)