使用 Jieba 庫進行 TF-IDF 關鍵詞提取(以《紅樓夢》為例)
在中文文本分析中,TF-IDF(Term Frequency - Inverse Document Frequency) 是最常用的關鍵詞提取方法之一。它通過評估詞在單個文檔中的出現頻率和在所有文檔中的稀有程度,來衡量該詞的重要性。
本文將以《紅樓夢》分卷文本為例,演示如何使用 jieba 庫完成分詞、停用詞過濾,并最終進行 TF-IDF 關鍵詞提取。
一、TF-IDF 的定義
TF-IDF(Term Frequency-Inverse Document Frequency,詞頻 - 逆文檔頻率)是文本挖掘領域中一種常用技術,其核心作用是評估某個詞語在特定文檔中的重要程度。該指標由兩部分構成:
- 詞頻(TF):指一個詞語在當前文檔中出現的頻率。
- 逆文檔頻率(IDF):用于衡量該詞語在整個文檔集合中的普遍重要性(即該詞是否在多數文檔中都頻繁出現)。
通常來說,一個詞語的 TF-IDF 值越高,就意味著它在當前文檔中的重要性越高。
二、選擇 jieba 庫的原因
jieba 是一款優秀的中文分詞工具庫,其突出特點使其成為眾多場景下的優選,包括:
- 支持三種不同的分詞模式,可適應多樣化的分詞需求。
- 允許用戶導入自定義詞典,提升對特定領域詞匯的分詞準確性。
- 具備高效的詞性標注功能,能快速為詞語標注所屬詞性。
- 內置 TF-IDF 關鍵詞提取功能,方便直接從文本中提取關鍵信息。
- 整體設計輕量,且操作簡單易懂,易于上手使用。
代碼一:準備數據
我們將準備?./紅樓夢?文件夾,其中:
紅樓夢正文:
紅樓夢.txt用戶自定義詞典:
紅樓夢詞庫.txt(保證人名、地名等專業詞匯的分詞準確性)中文停用詞表:
StopwordsCN.txt(去除“的”“了”等無意義的高頻詞)?空文件夾
./紅樓夢/分卷:用于存放代碼產生分卷
《紅樓夢》按卷分割文本代碼詳解
import os# 打開整本紅樓夢文本
file = open('.\\紅樓夢\\紅樓夢.txt', encoding='utf-8')flag = 0 # 標記是否已打開分卷文件# 遍歷整本小說每一行
for line in file:# 如果該行包含“卷 第”,表示這是卷的開頭if '卷 第' in line:juan_name = line.strip() + '.txt' # 用該行作為分卷文件名path = os.path.join('.\\紅樓夢\\分卷', juan_name)print(path)if flag == 0:# 第一次遇到卷標題,打開分卷文件準備寫入juan_file = open(path, 'w', encoding='utf-8')flag = 1else:# 遇到新的卷標題時,先關閉之前的分卷文件,再打開新的juan_file.close()juan_file = open(path, 'w', encoding='utf-8')continue# 過濾空行和廣告信息(如“手機電子書·大學生小說網”)if line.strip() != "" and "手機電子書·大學生小說網" not in line:juan_file.write(line) # 寫入當前分卷文件# 最后關閉最后一個分卷文件及整本書文件
juan_file.close()
file.close()
代碼流程說明
打開整本《紅樓夢》文本文件
使用
open以 utf-8 編碼打開.\\紅樓夢\\紅樓夢.txt文件,準備逐行讀取。
初始化標記變量
flagflag = 0表示還沒有打開分卷文件。
逐行讀取整本小說內容
使用
for line in file:依次處理每一行文本。
判斷是否遇到新分卷開頭
通過判斷字符串
'卷 第'是否在當前行中,識別分卷標題行。例如“卷 第1卷”,代表這是一個新的分卷開始。
新卷文件的創建與切換
如果是第一次遇到分卷標題(
flag == 0),則新建一個對應的分卷文件,準備寫入。如果之前已經打開了分卷文件,先關閉舊文件,再打開新分卷文件。
文件名以當前行內容加
.txt后綴命名,并保存在.\\紅樓夢\\分卷目錄下。
非分卷標題行內容處理
過濾空行(
line.strip() != "")和廣告信息(不包含"手機電子書·大學生小說網")。合格的行寫入當前打開的分卷文件中。
結束時關閉所有文件
循環結束后,關閉當前分卷文件和整本小說文件。
運行效果
將
紅樓夢.txt按照“卷 第X卷”的行作為分界點,生成多個如“卷 第1卷.txt”、“卷 第2卷.txt”等文件,分別保存在紅樓夢\分卷文件夾中。每個分卷文件包含對應的章節內容,便于后續的分詞和關鍵詞分析。
代碼二:對每個分卷提取詞典
1. 導入必要庫
import pandas as pd
import os
import jieba
pandas用于創建和操作結構化數據(DataFrame),方便后續處理。os用于遍歷文件夾,獲取分卷文件路徑。jieba是一個常用的中文分詞庫,用于將連續文本切分成詞語。
2. 讀取分卷文本
filePaths = []
fileContents = []
for root, dirs, files in os.walk(r"./紅樓夢/分卷"):for name in files:filePath = os.path.join(root, name) # 獲取每個分卷的完整路徑print(filePath)filePaths.append(filePath) # 記錄該路徑到filePaths列表f = open(filePath, 'r', encoding='utf-8')fileContent = f.read() # 讀取整個文件內容為字符串f.close()fileContents.append(fileContent) # 把內容加入列表
使用
os.walk遞歸遍歷./紅樓夢/分卷文件夾,獲取所有分卷文本文件路徑和名稱。將每個分卷文件的路徑和對應的文本內容分別存儲到
filePaths和fileContents兩個列表中。讀取文件時用 UTF-8 編碼,保證中文字符正確讀取。
3. 構建 pandas DataFrame
corpos = pd.DataFrame({'filePath': filePaths,'fileContent': fileContents
})
將分卷的路徑和內容以字典形式傳入,生成一個二維表格結構的 DataFrame。
每一行對應一個分卷文件,包含:
filePath:該分卷的文件路徑fileContent:該分卷對應的文本內容(字符串)
這樣方便后續批量處理。
4. 加載用戶自定義詞典和停用詞表
jieba.load_userdict(r"./紅樓夢/紅樓夢詞庫.txt")
stopwords = pd.read_csv(r"./紅樓夢/StopwordsCN.txt",encoding='utf-8', engine='python', index_col=False)
jieba.load_userdict()用來加載用戶定義的詞典,解決默認詞庫中可能沒有的專有名詞、人名地名、書中特殊詞匯的分詞準確度問題。stopwords讀取停用詞文件,一般是高頻無實際含義的詞(如“的”、“了”、“在”等),需要過濾掉,避免影響后續分析。
stopwords是一個 DataFrame,其中一列(假設列名為stopword)包含所有停用詞。
5. 創建分詞輸出文件
file_to_jieba = open(r"./紅樓夢/分詞后匯總.txt", 'w', encoding='utf-8')
打開一個新的文本文件,用來存儲所有分卷的分詞結果。
使用寫入模式,每個分卷分詞結果寫入一行,方便后續分析。
6. 對每個分卷逐條處理
for index, row in corpos.iterrows():juan_ci = ''filePath = row['filePath']fileContent = row['fileContent']segs = jieba.cut(fileContent) # 對該卷內容進行分詞,返回一個生成器for seg in segs:# 如果分詞結果不是停用詞且不是空字符串if seg not in stopwords.stopword.values and len(seg.strip()) > 0:juan_ci += seg + ' ' # 詞語之間用空格分開file_to_jieba.write(juan_ci + '\n') # 寫入該卷分詞結果,換行區分不同卷
corpos.iterrows()按行遍歷 DataFrame,每行對應一個分卷。取出文本內容后,用
jieba.cut()對文本分詞,得到一個可迭代的詞語序列。對每個詞:
判斷它是否為停用詞(通過停用詞列表過濾)
判斷是否為空白(防止多余空格或特殊符號)
過濾后的詞匯拼接成字符串,用空格分隔,形成分詞后的“句子”。
每個分卷的分詞結果寫入一行,方便后續按行讀取、TF-IDF等分析。
7. 關閉文件
file_to_jieba.close()
關閉分詞結果文件,保證寫入完整。
運行結果:
代碼三:計算 TF-IDF
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd1. 讀取分詞后的匯總文本
File = open(r".\紅樓夢\分詞后匯總.txt", 'r', encoding='utf-8')
corpus = File.readlines() # 每行作為一個文檔內容
每行對應一卷(或一回)的分詞結果。
corpus 是一個列表,
corpus[i]表示第 i 卷的文本。
2. 初始化并計算 TF-IDF
from sklearn.feature_extraction.text import TfidfVectorizer vectorizer = TfidfVectorizer()
tfidf = vectorizer.fit_transform(corpus)
wordlist = vectorizer.get_feature_names()
TfidfVectorizer()自動執行:統計每個詞的詞頻(TF)
計算逆文檔頻率(IDF)
得到每個詞在每個文檔中的 TF-IDF 值
wordlist是詞匯表(所有出現的詞)。
3. 構建 DataFrame 存儲結果
df = pd.DataFrame(tfidf.T.todense(), index=wordlist)
tfidf是稀疏矩陣(需要.todense()轉成稠密矩陣才能放進 DataFrame)。轉置
.T后:行(index)是詞匯
列是文檔(每卷)
?
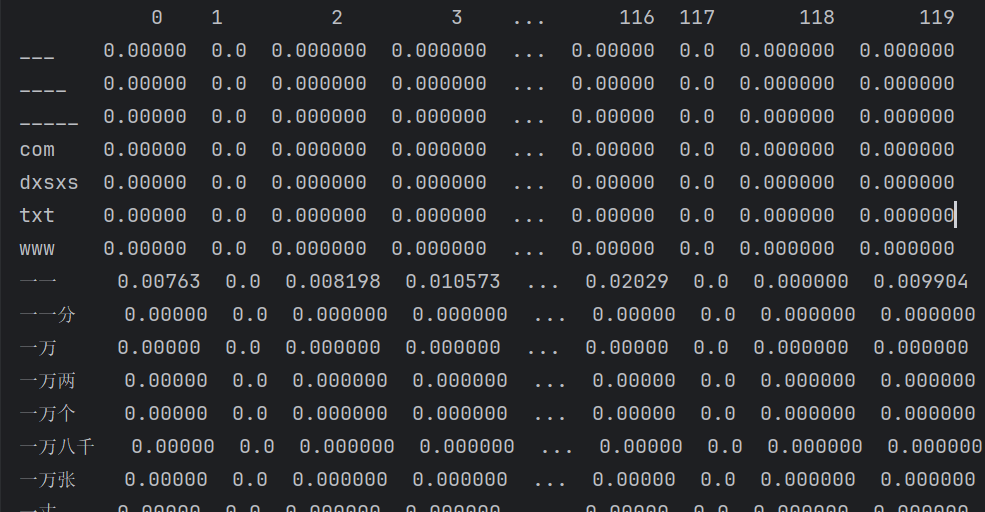
?可以打印出部分數據直觀理解:
print(wordlist) print(tfidf) # print(tfidf.todense()) print(df.head(20))wordlist:詞匯表
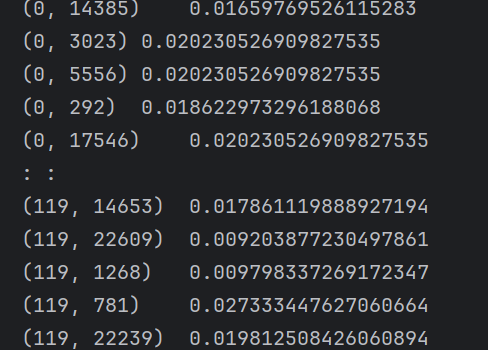
tfidf:
(0,14385)即表示一個二維坐標
0/119→ 這是文檔編號(row index),表示這是第 1 篇文檔(編號從 0 開始)。14385→ 這是詞在詞匯表(vocabulary)中的編號(column index),對應某個特定的單詞,比如可能是
"machine"或"learning"(具體要看vectorizer.get_feature_names_out()對應表)。
0.01659769526115283→ 這是這個單詞在該文檔中的 TF-IDF 權重,數值越大,說明這個單詞在這篇文章中越重要(出現頻率高,但在其他文檔中不常見)。df:
行索引(index):
___、____、txt、一一等是分詞后的詞語。列索引(0, 1, 2, ...):表示第幾卷(文檔),從
0列到119列,說明總共有 120 卷/文檔。單元格的數值:該詞在該卷里的 TF-IDF 權重(越大表示該詞在這卷中越重要)。
?

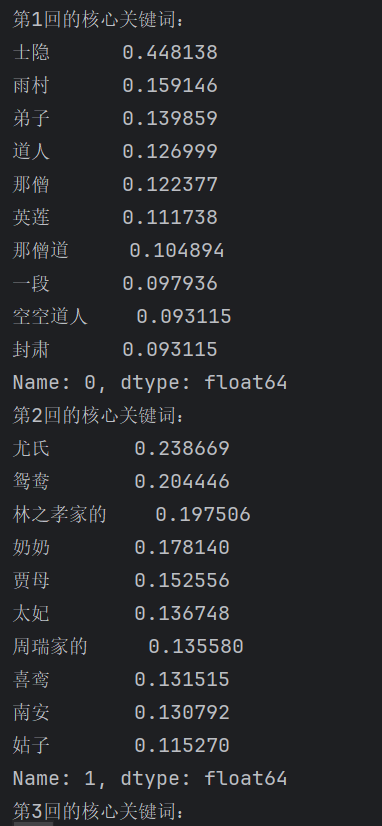
4. 提取每卷的 Top 10 關鍵詞
for i in range(len(corpus)):top_keywords = df.iloc[:, i].sort_values(ascending=False).head(10)print(f'第{i+1}回的核心關鍵詞:\n{top_keywords}')
取第
i列(即第 i 卷的所有詞的 TF-IDF 值)sort_values(ascending=False)降序排列head(10)取權重最高的 10 個關鍵詞
結果:
擴展:可視化每卷 Top 10 關鍵詞
以第 1 卷為例,繪制柱狀圖:
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# [:, 0]取第1回,[:, 119]取第120回
top_keywords = df.iloc[:, 0].sort_values(ascending=False).head(10)plt.figure(figsize=(8,5))
plt.barh(top_keywords.index, top_keywords.values, color='skyblue')
plt.gca().invert_yaxis() # 倒序
plt.title("第1回的TF-IDF關鍵詞")
plt.xlabel("TF-IDF權重")
plt.show()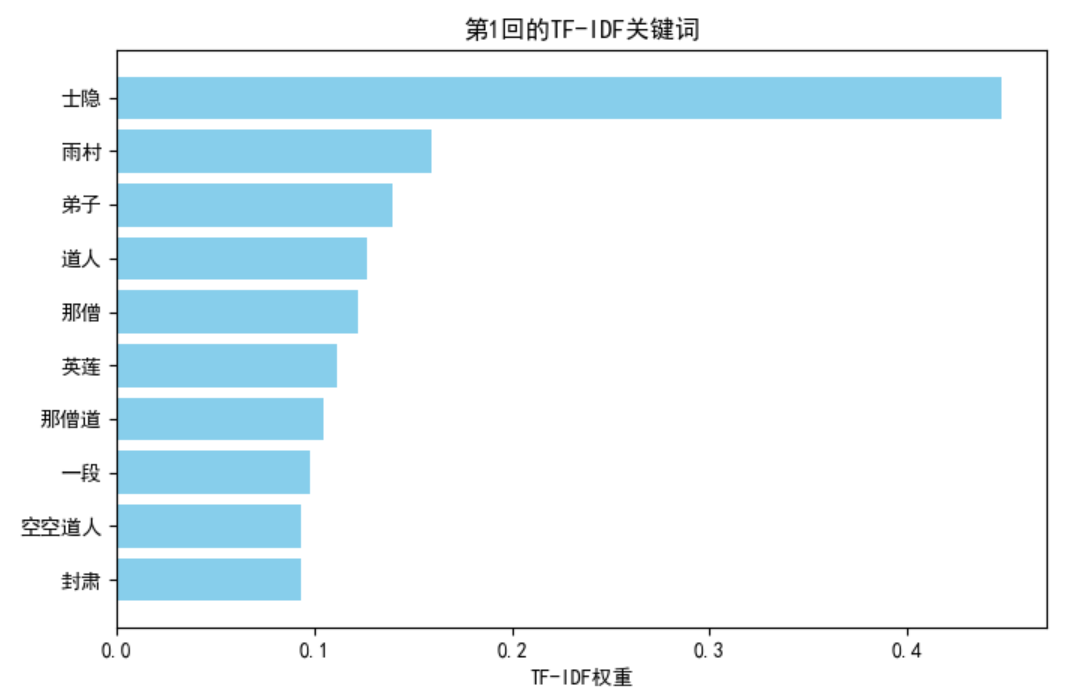
改進建議
自動去掉空行
corpus = [line.strip() for line in corpus if line.strip()]避免空文檔導致向量化器報錯。
指定分隔符
因為你的分詞結果是用空格分隔的,可以告訴TfidfVectorizer:vectorizer = TfidfVectorizer(token_pattern=r"(?u)\b\w+\b")保存結果
直接把每卷關鍵詞存到 CSV,便于后續分析:all_keywords = {} for i in range(len(corpus)):all_keywords[f"第{i+1}回"] = df.iloc[:, i].sort_values(ascending=False).head(10).index.tolist() pd.DataFrame.from_dict(all_keywords, orient='index').to_csv("紅樓夢_TF-IDF關鍵詞.csv", encoding="utf-8-sig")
總結
本文實現了從原始《紅樓夢》文本到關鍵詞提取的完整流程:
對正文進行分卷
讀取分卷內容
自定義詞典 + 停用詞過濾
分詞并保存
使用
jieba.analyse.extract_tags進行 TF-IDF 關鍵詞提取TfidfVectorizer計算 TF-IDF
擴展:可視化權重排序
通過這種方式,我們不僅能提取整本書的主題關鍵詞,還能按卷分析主題變化,為文本挖掘、主題建模、人物關系分析等工作打下基礎。







![Rust 項目編譯故障排查:從 ‘onnxruntime‘ 鏈接失敗到 ‘#![feature]‘ 工具鏈不兼容錯誤](http://pic.xiahunao.cn/Rust 項目編譯故障排查:從 ‘onnxruntime‘ 鏈接失敗到 ‘#![feature]‘ 工具鏈不兼容錯誤)

)





)



