溫馨提示:
本篇文章已同步至"AI專題精講" CacheBlend:結合緩存知識融合的快速RAG大語言模型推理服務
摘要
大語言模型(LLMs)通常在輸入中包含多個文本片段,以提供必要的上下文。為了加速對較長LLM輸入的預填充(prefill),可以預先計算文本的KV緩存,并在該上下文作為另一個LLM輸入前綴時復用KV緩存。然而,被復用的文本片段并不總是作為輸入前綴,這導致預計算的KV緩存無法直接使用,因為它們忽略了該文本與前置文本之間的交叉注意力。因此,KV緩存復用的優勢在很大程度上尚未被實現。
本文聚焦于一個核心挑戰:當LLM輸入包含多個文本片段時,如何快速組合它們的預計算KV緩存,以實現與昂貴的完整預填充(即不復用KV緩存)相同的生成質量?該挑戰在檢索增強生成(RAG)中尤為常見,其中輸入通常包含多個作為上下文的檢索文本。我們提出了CacheBlend,這是一種可以復用預計算KV緩存的方案,無論其是否為前綴,并通過選擇性地重新計算一小部分token的KV值來對每個復用的KV緩存進行部分更新。同時,重新計算部分token所需的輕微延遲可以與KV緩存的檢索過程在同一任務中進行流水線化,從而使CacheBlend能夠將KV緩存存儲在更慢但容量更大的設備上,并在不增加推理延遲的前提下完成檢索。
我們在三個不同規模的開源LLM和四個主流基準任務上,將CacheBlend與當前最先進的KV緩存復用方案進行比較。結果表明,CacheBlend在不降低生成質量的情況下,將首token生成時間(TTFT)減少了2.2–3.3倍,推理吞吐量提高了2.8–5倍。代碼開源地址:https://github.com/LMCache/LMCache
CCS 分類概念 ? 計算方法 → 自然語言處理;? 網絡 → 云計算;? 信息系統 → 數據管理系統。
關鍵詞 大語言模型,KV緩存,檢索增強生成(RAG)
1 引言
由于其卓越的能力,大語言模型(LLMs)被廣泛應用于個人助理、人工智能醫療和問答系統中 [1, 3, 4, 9]。為了確保高質量和一致性的響應,應用程序通常會在用戶查詢中添加額外文本,以提供必要的領域知識或用戶特定信息。一個典型的例子是檢索增強生成(RAG),其中用戶查詢前會添加多個從數據庫中檢索的文本片段,以構成LLM輸入。
然而,這些上下文文本片段會顯著降低LLM的推理速度。這是因為,在生成任何token之前,LLM首先需要通過預填充處理整個輸入,以生成KV緩存——這是一個與每個輸入token相關的張量的拼接,表示該token與其前序token之間的“注意力”關系。因此,預填充的延遲決定了首token生成時間(TTFT)。我們將其稱為完整KV重計算(如圖1(a)所示)。盡管已有許多優化手段,預填充的延遲和計算成本仍隨著輸入長度的增加呈超線性增長,在處理較長的LLM輸入(例如RAG場景)時,這種開銷很容易成為性能瓶頸 [11, 53, 60]。
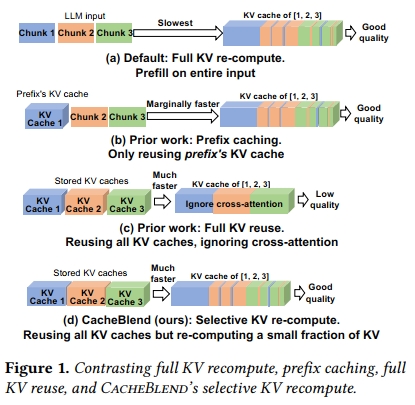
那么,我們該如何加速LLM輸入的預填充過程呢?近期的優化方法利用了一個事實:相同的上下文文本通常會被多個LLM輸入重復使用。因此,可以預先計算這些文本的KV緩存,并在之后復用這些已存儲的KV緩存,以避免在這些復用文本上重復進行預填充操作。
現有方法的局限性: 目前關于KV緩存復用的方案主要有兩類,但它們都存在一定的限制。
第一種,前綴緩存(prefix caching),只存儲并復用LLM輸入前綴的KV緩存 [33, 36, 41, 42, 59](見圖1(b))。由于前綴的KV緩存不依賴后續文本,因此這種方法不會影響生成質量。然而,許多應用(如RAG)在LLM輸入中包含多個文本片段,而不僅僅是一個,以提供所有必要的上下文信息,確保良好的響應質量。因此,只有第一個文本片段是前綴,其他被復用的文本的KV緩存則無法復用。結果是,當輸入中包含許多復用文本片段時,前綴緩存的推理速度幾乎與完整KV重計算一樣慢。
第二種,完整KV復用(full KV reuse),試圖解決上述問題(見圖1?)。當一個復用文本不是輸入前綴時,它仍然可以通過調整其位置嵌入(positional embedding)來復用KV緩存,以使LLM生成出有意義的輸出 [24]。然而,這種方法忽略了一個重要的因素——跨注意力(cross-attention),即一個片段中的token與其前序片段中的token之間的注意力關系。由于前置片段在預計算階段并不確定,跨注意力信息無法預計算。但這種注意力對于某些需要綜合多個片段信息的問題(例如關于地緣政治的問題,其中包含地理和政治內容的片段)是至關重要的。§3.3部分提供了具體示例,說明為何前綴緩存和模塊化緩存在某些場景下不足以滿足需求。
我們的方法: 本文聚焦于一個問題:當LLM輸入包含多個文本片段時,如何快速組合它們各自的預計算KV緩存,以達到與完整預填充相同的生成質量?換句話說,我們希望兼具完整KV復用的速度和完整KV重計算的生成質量。
我們提出CacheBlend,這是一個系統,能夠融合多個已預計算的KV緩存,無論這些緩存是否來自前綴。具體而言,CacheBlend會根據當前LLM輸入中的前序文本,選擇性地重新計算一小部分token的KV緩存,我們稱之為選擇性KV重計算(selective KV recompute)(見圖1(d))。從高層次來看,選擇性KV重計算在每一層中以傳統的方式對輸入文本進行預填充;但在每一層內,它只更新一小部分token的KV,而復用其余token的KV。
與完整KV重計算相比,更新比例小于15%通常就足以生成相同質量的輸出,這是基于我們的實證經驗。之所以只需更新少量KV就能維持生成質量,其根本原因在于注意力矩陣的稀疏性(詳見§4.3)。
與完整KV復用相比,CacheBlend在僅增加少量KV更新計算的情況下獲得了更高的生成質量。而且,這些額外的計算并不會增加推理延遲,因為CacheBlend會將一層中的部分KV更新與下一層KV緩存從磁盤加載到GPU內存的過程并行化。這種流水線處理使得CacheBlend可以將KV緩存存儲在速度較慢但容量更大的非易失性設備(如磁盤)上,而不會帶來額外延遲,從而實現更多KV緩存的存儲與復用。
從整體貢獻來看,CacheBlend實現了在單個LLM輸入中復用多個文本片段KV緩存的能力,而不犧牲生成質量。這一方法補充了近期在減少KV緩存存儲大小 [28, 35, 42, 43, 45, 58] 和優化KV緩存訪問模式 [33, 59] 方面的研究。
我們在vLLM之上實現了CacheBlend,并在三個不同規模的開源LLM和三個主流基準數據集上的兩個任務(RAG和問答)上,對CacheBlend與當前最先進的KV緩存復用方案進行了比較。結果表明,與前綴緩存相比,CacheBlend將首token生成時間(TTFT)降低了2.2–3.3倍,推理吞吐量提高了2.8–5倍,同時不降低生成質量,也不增加存儲開銷。與完整KV復用相比,CacheBlend在保持幾乎相同TTFT的同時,在問答任務上提升了0.1–0.2的F1絕對分數,在摘要任務中提升了0.03–0.25的Rouge-L絕對分數。
2 背景
目前大多數LLM服務使用的是transformer架構 [13, 16, 52]。在接收到輸入token后,LLM首先通過預填充階段(prefill phase,稍后解釋)將這些token轉換為key(K)和value(V)向量,即KV緩存。完成預填充后,LLM再使用當前的KV緩存迭代式地解碼(生成)下一個token,并將新生成token的K和V向量追加進KV緩存,以供下一輪生成使用。
預填充階段按層計算KV緩存。每一層中,輸入token的embedding會先被轉換為query(Q)、key(K)和value(V)向量,其中K和V向量構成當前層的KV緩存。然后,LLM會將Q和K向量進行乘法運算,得到注意力矩陣,即每個token與其前序token之間的注意力關系;隨后再對該注意力矩陣(經歸一化和掩碼處理)與V向量進行點積,得到的結果將通過多個神經網絡層,最終用于生成下一層的token embedding。
當某段前綴的KV緩存已存在時,預填充階段只需要在每一層計算后綴token與前綴token之間的前向注意力矩陣(forward attention),這些注意力會直接影響生成token的輸出。
預填充階段在輸入很長時會變得很慢。例如,在包含4000個token的輸入上(這在RAG場景中很常見 [33]),Llama-34B(或Llama-70B)在一張A40 GPU上運行預填充可能需要3秒(或6秒)。這將導致用戶在看到第一個生成詞之前不得不等待較長時間。近期的研究還顯示,預填充階段可能成為推理吞吐量的瓶頸——研究表明移除預填充階段可以使LLM推理系統的吞吐量翻倍 [60]。
3 動機
3.1 復用KV緩存的機會
近期的系統嘗試通過觀察許多LLM使用場景中相同文本在不同輸入中被反復使用的現象,以此緩解預填充階段的開銷。這使得我們可以復用這些重復文本的KV緩存(下面會具體解釋)。
文本復用在許多LLM應用中十分常見,因為同樣的文本通常被包含在LLM輸入中,作為提供必要上下文的手段,以確保回答質量高且一致。為了更具體地說明,我們來看兩個場景:
-
在一個利用LLM管理內部記錄的公司中,有兩個查詢可能分別是:“誰在最近的全員大會上提議使用RAG來優化客戶服務X?”以及“IT部門中有哪些人畢業于Y大學?”這兩個問題看似不同,但都涉及“IT部門員工列表”這一上下文,只有提供這一信息,LLM才能給出正確答案。
-
同樣地,在一個基于LLM的Arxiv論文摘要應用中,有兩個問題可能是:“當前在Arxiv上流行的RAG技術有哪些?”以及“最近有哪些數據集被用于評估RAG相關論文?”這兩個問題都需要LLM讀入關于RAG的Arxiv論文作為上下文,才能生成準確答案。
由于被復用的上下文通常比用戶的查詢更長、更復雜,因此在輸入中的“上下文”部分會占據預填充計算的絕大部分開銷 [22, 33]。因此,理想的做法是存儲并復用這些上下文的KV緩存,以避免在它們被再次用于不同LLM輸入時重復進行預填充計算。
3.2 為什么前綴緩存不夠用?
確實,已有一些系統被設計出來以通過復用KV緩存來減少預填充延遲。例如,在**前綴緩存(prefix caching)**中,可復用的文本片段的KV緩存會預先計算好;如果該片段出現在LLM輸入的前綴位置,那么這段KV緩存就可以直接復用,省去該部分的預填充。前綴緩存的好處是,這段KV緩存不受后續文本的影響,因此其生成結果與完全不使用KV緩存、重新計算得到的結果是一致的。多個系統采用了這種方式,如vLLM [36]、SGLang [59] 和 RAGCache [33]。
然而,前綴緩存也有明顯的局限性。在回答某個查詢時,諸如RAG等應用往往會在LLM輸入中前置多個文本片段,以提供回答問題所需的多重上下文。結果是,除了第一個片段外,其他片段都不是輸入的前綴,它們的KV緩存便無法被復用。
我們回顧一下§3.1中的例子:要回答“誰在最近的全員大會上提議使用RAG來優化客戶服務X?”,LLM需要來自多個信息源的上下文,包括IT部門員工的信息、客戶服務X的相關內容、全員大會的會議紀要等。同樣地,在Arxiv摘要應用中,要回答示例問題也需要LLM讀取幾篇RAG相關的Arxiv論文作為上下文。由于這些上下文涉及的主題不同,它們不太可能出現在同一個文本片段中,而是在回答具體查詢時才被臨時組合使用。
為了實證LLM輸入中包含多個文本片段的需求,我們使用了兩個流行的多跳問答數據集:Musique和2WikiMQA。這些數據集中包含了多個查詢以及對應多個必要上下文文本。我們遵循RAG的常見做法,首先將上下文分割為長度為128 token的片段(這個長度很常見 [29]),使用Langchain中的文本切片機制 [5]。對每個查詢,我們使用SentenceTransformers [49]對其進行embedding,然后基于查詢embedding與每個chunk embedding的L2距離,從向量數據庫中選取前k個最相關的chunk。圖2展示了隨著選擇的文本片段數量增加,生成質量(以標準F1分數衡量)如何變化。可以看到,當檢索到更多文本片段補充LLM輸入時,質量顯著提升,但當片段過多時,質量反而下降,這源于廣為人知的“middle token被忽視(lost-in-the-middle)”問題 [40, 54]。
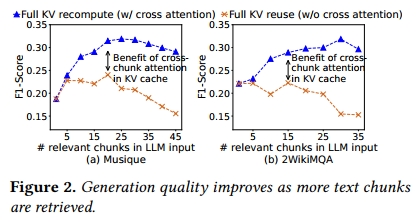
簡而言之,前綴緩存只能節省第一個文本片段的預填充開銷,因此當LLM輸入包含多個文本片段時,即使這些片段被重復使用,節省的計算量也只是微不足道的。
3.3 為什么 full KV reuse 不足?
Full KV reuse 被提出是為了應對這個問題。該方法最近由 PromptCache [24] 首創。它通過緩沖區來維護每個文本塊的位置準確性,從而將獨立預計算的重復文本塊的 KV 緩存進行拼接。例如,為了拼接文本塊 𝐶? 和 𝐶? 的 KV 緩存,PromptCache 首先需要通過在一個假設輸入上運行 prefill 來預計算 𝐶? 的 KV 緩存,該輸入在 𝐶? 前添加了一個長度大于等于 𝐶? 的虛擬前綴。通過這種方式,即使 𝐶? 不是輸入的 prefix,我們仍然可以正確保留 𝐶? 的 KV 緩存中的位置信息,盡管每個塊的 KV 緩存可能不得不被多次預計算。
然而,即便位置信息被保留,一個更根本的問題是,非 prefix 的文本塊(如 𝐶?)在其 KV 緩存中會忽略該塊與其前面文本塊(如 𝐶?)之間的重要 cross-attention。這是因為在預計算 KV 緩存時,前面的文本塊是未知的。
忽略 cross-attention 會導致錯誤的響應。圖3 展示了一個說明性示例,其中一個用戶查詢 “How many goals did Messi score more than Cristiano Ronaldo at FIFA World Cups?” 被兩個關于球員職業統計數據的文本塊所預置。使用 full prefill 或 prefix caching 時,結果是明確且正確的。而在使用 full KV reuse 的情況下,這兩個文本塊的 KV 緩存已被預計算,每個文本塊具有正確的 positional embedding,然后被拼接形成最終 KV 緩存。然而,如果 LLM 使用這個 KV 緩存來生成答案,它將開始胡言亂語,且無法得出正確答案。
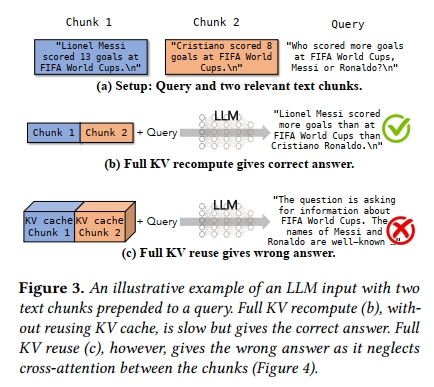
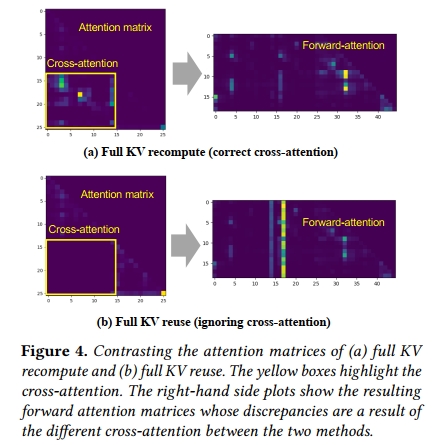
為了理解其中原因,我們進一步觀察 attention matrix(在 §2 中解釋),尤其是涉及兩段關于球員數據的文本塊之間的 cross-attention。圖4 可視化了由原始(full)prefill 所產生的 attention matrix 以及由 full KV reuse 所產生的 attention matrix。由于 full KV reuse 是分別預計算每個文本塊的,因此在預計算 KV 緩存時,這兩個文本塊之間的 cross-attention 完全被遺漏(從未被計算)。在本示例中,第一個文本塊包含 Messi 的進球數,第二個文本塊包含 Ronaldo 的。LLM 被查詢以比較 Messi 和 Ronaldo 的進球數。如果忽略這兩個文本塊之間的交互(cross-attention),將會導致一個有缺陷的答案。
公平地說,在文本塊之間的 cross-attention 較弱時,full KV reuse 確實可以發揮作用。這種情況通常出現在 prompt templates 中,而這正是 PromptCache [24] 的主要目標應用場景。
full KV reuse 中缺乏 cross-attention 會在 forward attention matrix(在 §2 中解釋)中造成顯著差異,該矩陣描述了上下文 tokens 與最后幾個 tokens 之間的注意力關系,并會直接影響生成的 tokens。
為了展示在多文本塊 LLM 輸入中 cross-attention 的普遍性,圖2 對比了 full KV recompute(包含 cross-attention)與 full KV reuse(不包含 cross-attention)在響應質量(F1 分數)上的表現。可以看到,隨著相關文本塊數量的增加,full prefill 與 modular caching 之間的差距愈發明顯。這是因為隨著文本塊數量的增多,輸入中不同部分之間的交叉引用和相互依賴關系(即 cross-attention)也隨之增加。
4 快速 KV 緩存融合
鑒于 full KV recompute(即 full prefill 或 prefix caching)速度太慢,而 full KV reuse 生成質量較低,一個自然的問題是,如何既能擁有 full KV reuse 的速度,又能兼顧 full KV recompute 的質量。因此,我們的目標如下:
目標:當 LLM 輸入包含多個被重復使用的文本塊時,如何快速更新預先計算的 KV 緩存,使得生成的 forward attention matrix(以及隨后生成的文本)與 full KV recompute 所產生的結果之間的差異最小。
為實現這一目標,我們提出 CacheBlend,它在每一層中僅對部分 token 的 KV 進行選擇性地重新計算,同時復用其他 token 的 KV。本節將從三個方面介紹 CacheBlend 的方法。我們首先給出所用記號(§4.1),然后描述如何只重新計算一小部分 token 的 KV(§4.2),最后解釋如何在每一層選擇需要重新計算 KV 的 token(§4.3)。
4.1 術語說明
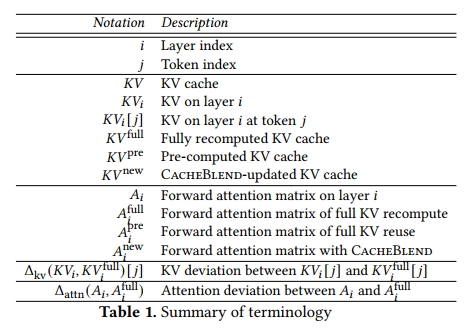
表1 總結了本節中使用的記號。對于一個包含 𝑁 個文本塊的列表,我們使用 𝐾𝑉^full 表示 full KV recompute 所產生的 KV 緩存,𝐾𝑉^pre 表示預計算的 KV 緩存,𝐾𝑉new𝐾𝑉^{new}KVnew 表示經過 CacheBlend 更新后的 KV 緩存。在這里,這些 KV 緩存都是由不同文本塊對應的 KV 緩存拼接而成的。每一層 𝑖 的 KV 緩存,記作 𝐾𝑉?,會生成該層的 forward attention matrix,記作 𝐴?。
溫馨提示:
閱讀全文請訪問"AI深語解構" CacheBlend:結合緩存知識融合的快速RAG大語言模型推理服務

![[激光原理與應用-264]:理論 - 幾何光學 - 什么是焦距,長焦與短焦的比較](http://pic.xiahunao.cn/[激光原理與應用-264]:理論 - 幾何光學 - 什么是焦距,長焦與短焦的比較)

)




)







![Rust 項目編譯故障排查:從 ‘onnxruntime‘ 鏈接失敗到 ‘#![feature]‘ 工具鏈不兼容錯誤](http://pic.xiahunao.cn/Rust 項目編譯故障排查:從 ‘onnxruntime‘ 鏈接失敗到 ‘#![feature]‘ 工具鏈不兼容錯誤)

)
