點一下關注吧!!!非常感謝!!持續更新!!!
🚀 AI篇持續更新中!(長期更新)
AI煉丹日志-31- 千呼萬喚始出來 GPT-5 發布!“快的模型 + 深度思考模型 + 實時路由”,持續打造實用AI工具指南!📐🤖
💻 Java篇正式開啟!(300篇)
目前2025年08月11日更新到:
Java-94 深入淺出 MySQL EXPLAIN詳解:索引分析與查詢優化詳解
MyBatis 已完結,Spring 已完結,Nginx已完結,Tomcat已完結,分布式服務正在更新!深入淺出助你打牢基礎!
📊 大數據板塊已完成多項干貨更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余項核心組件,覆蓋離線+實時數倉全棧!
大數據-278 Spark MLib - 基礎介紹 機器學習算法 梯度提升樹 GBDT案例 詳解

MySQL 索引與排序機制詳解
兩種排序方式概述
MySQL 查詢處理排序時主要支持兩種方式:filesort 和 index 排序。這兩種方式在性能上有顯著差異,理解它們的區別對于數據庫優化至關重要。
filesort 排序方式
filesort 是 MySQL 的通用排序算法,當無法使用索引排序時就會采用這種方式。其工作流程如下:
- 數據獲取階段:首先執行查詢獲取滿足條件的記錄
- 排序處理階段:將結果集放入排序緩沖區(sort buffer)
- 如果數據量小,完全在內存中完成排序
- 如果數據量大,會使用臨時文件進行多輪歸并排序
- 結果返回階段:將排序后的結果返回給客戶端
典型的使用 filesort 的場景包括:
- 對沒有索引的列進行排序
- 使用了 ORDER BY 與 GROUP BY 不同的表達式
- 排序方向與索引定義方向不一致(如索引是 ASC 但查詢要求 DESC)
index 排序方式
index 排序是利用索引本身的有序特性來避免額外的排序操作,其優勢包括:
- 直接利用索引:按照索引順序讀取數據,天然有序
- 無額外開銷:省去了排序緩沖區的分配和排序計算過程
- 性能優勢:特別是對于大型結果集,性能提升顯著
使用 index 排序的條件:
- ORDER BY 子句中的列必須與索引列順序完全匹配
- 排序方向(ASC/DESC)必須與索引定義一致
- 不能跳過索引中的列(遵循最左前綴原則)
性能對比示例
假設有一個包含百萬條記錄的用戶表:
-- 情況1:filesort
SELECT * FROM users WHERE status = 'active' ORDER BY registration_date;-- 情況2:index排序
SELECT * FROM users WHERE status = 'active' ORDER BY id; -- id是主鍵
在這個例子中,第一種查詢可能需要進行完整的 filesort 操作,而第二種查詢可以直接利用主鍵索引的有序性,性能差異可能達到幾個數量級。
優化建議
- 為常用排序條件創建合適的索引
- 盡量讓排序條件與索引定義完全匹配
- 監控慢查詢日志中的"Using filesort"警告
- 適當增大 sort_buffer_size 參數可以減少磁盤臨時文件的使用
- 考慮使用覆蓋索引避免回表操作
算法對比
MySQL 文件排序(filesort)算法詳解
雙路排序(Two-pass sorting)
雙路排序是 MySQL 中的傳統排序算法,其工作流程如下:
- 第一次磁盤掃描:只讀取排序字段(ORDER BY 子句中指定的列)和行指針(row pointer)
- 排序階段:在 sort buffer 中對這些排序鍵進行排序
- 第二次磁盤掃描:根據排序后的行指針回表讀取完整的數據行
- 結果返回:將排序后的完整數據返回給客戶端
適用場景:
- 當查詢的列很多,或者列數據很大時
- 當 max_length_for_sort_data 參數值設置較小時
- 特別是當使用 SELECT * 查詢大量列時
優點:減少了內存使用,因為只需要緩存排序鍵而非整行數據
單路排序(Single-pass sorting)
單路排序是 MySQL 優化的排序算法,其工作流程如下:
- 單次磁盤掃描:一次性讀取查詢需要的所有列(包括排序字段和其他字段)
- 內存排序:在 sort buffer 中對這些數據進行排序
- 結果返回:直接返回已排序的結果集
潛在問題:
- 如果查詢數據超出 sort buffer 大小(由 sort_buffer_size 參數控制)
- 會導致多次磁盤讀取操作
- 可能需要創建臨時表
- 最終產生多次 I/O 操作,反而降低性能
優化建議:
- 避免使用
SELECT *,只查詢必要的列 - 適當增加 sort_buffer_size 參數值
- 調整 max_length_for_sort_data 參數值(控制單行數據最大長度)
示例場景:
-- 不推薦的寫法(可能導致單路排序性能問題)
SELECT * FROM large_table ORDER BY create_time DESC;-- 推薦的寫法(減少數據傳輸量)
SELECT id, name, create_time FROM large_table ORDER BY create_time DESC;
參數調整示例:
-- 增加排序緩沖區大小(默認通常為256KB)
SET sort_buffer_size = 4 * 1024 * 1024; -- 設置為4MB-- 調整單行排序數據最大長度(默認1024字節)
SET max_length_for_sort_data = 8192; -- 設置為8KB
EXPLAIN
如果我們使用 EXPLAIN 命令分析 SQL 查詢的執行計劃時:
在結果集的 Extra 列中,如果出現"Using filesort"的提示,這表示 MySQL 在執行查詢時使用了文件排序(filesort)操作。filesort 是一種成本較高的排序方式,當不能使用索引排序時,MySQL 會將結果集放入臨時表并進行排序。這種情況下,我們應該考慮優化查詢或添加適當的索引來提高性能。
優化 filesort 的常見方法包括:
- 為 ORDER BY 子句中的列創建合適的索引
- 確保 WHERE 條件中的列和 ORDER BY 列使用相同的索引
- 減少查詢返回的數據量
相反,如果 Extra 列顯示"Using Index",這表示查詢使用了覆蓋索引(Covering Index),即查詢所需的所有數據都可以從索引中獲取,而不需要回表查詢數據行。這種情況是最理想的:
- 查詢性能最優,因為完全避免了訪問數據表
- 可以使用 index 排序方式,效率遠高于 filesort
- 減少了 I/O 操作,降低了內存使用
在實際開發中,我們應盡量設計查詢使其能夠使用覆蓋索引,具體方法包括:
- 創建包含所有查詢字段的復合索引
- 避免 SELECT * 查詢,只選擇必要的列
- 確保 WHERE、ORDER BY 和 GROUP BY 子句中的列被索引覆蓋
例如,對于查詢:
SELECT id, name FROM users WHERE status = 1 ORDER BY create_time;
創建索引 (status, create_time, id, name) 就能實現覆蓋索引,避免 filesort 操作。
index方式
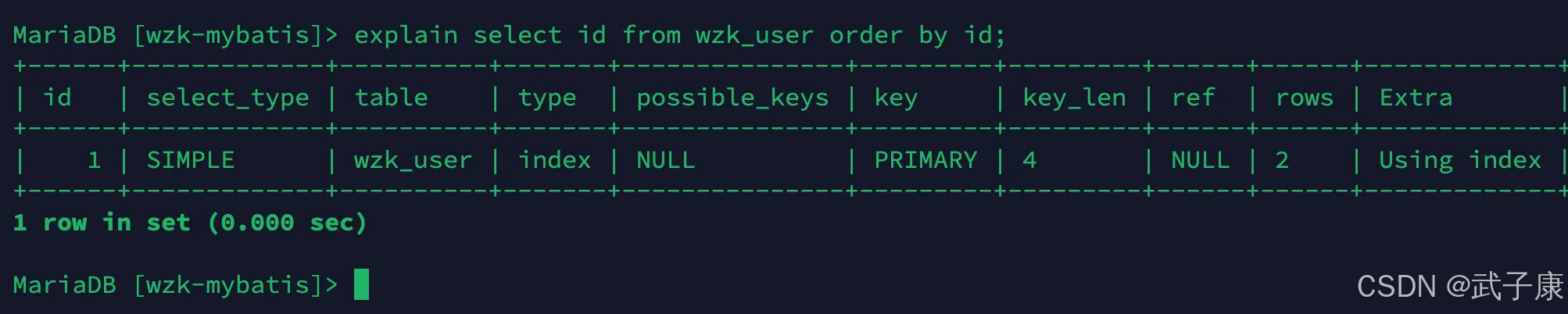
當我們使用 order by 子句索引組合滿足索引最左前列的時候:
explain select id from wzk_user order by id;
執行結果如下所示:
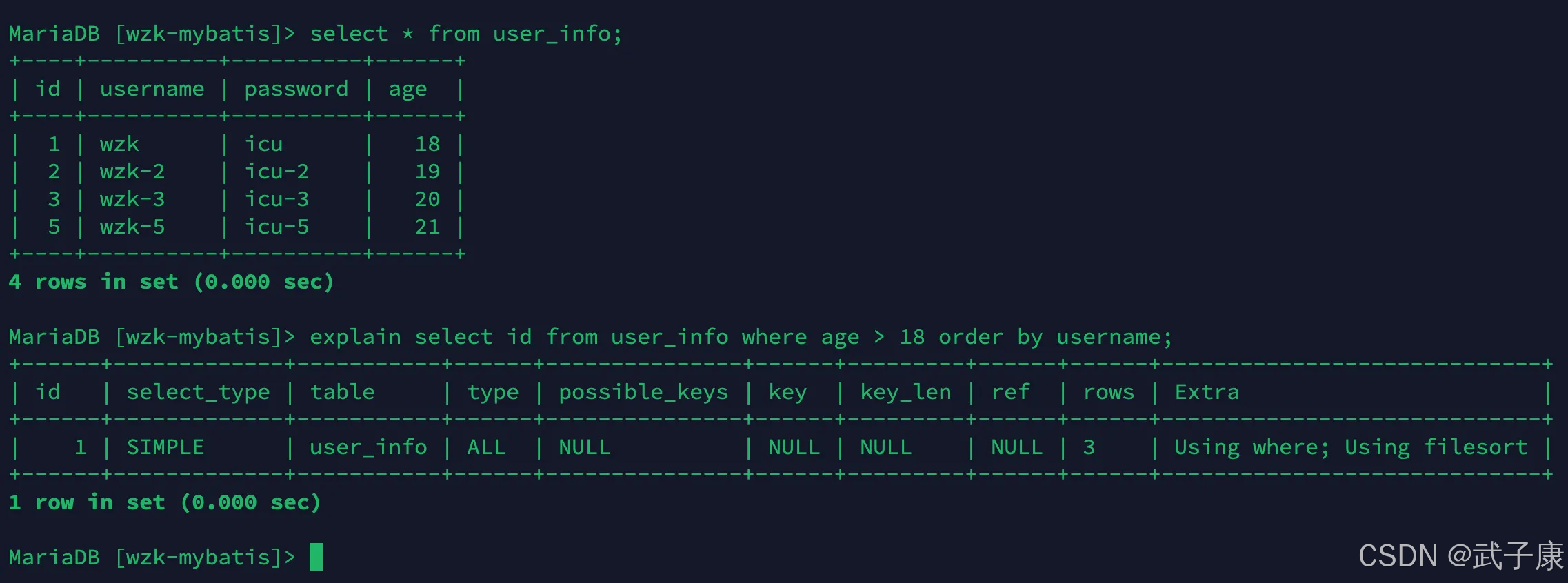
當我們使用 where 子句 + order by子句 索引組合列滿足索引最左前列的時候:
explain select id from user_info where age > 18 order by username;
對應的結果如下所示:
filesort方式
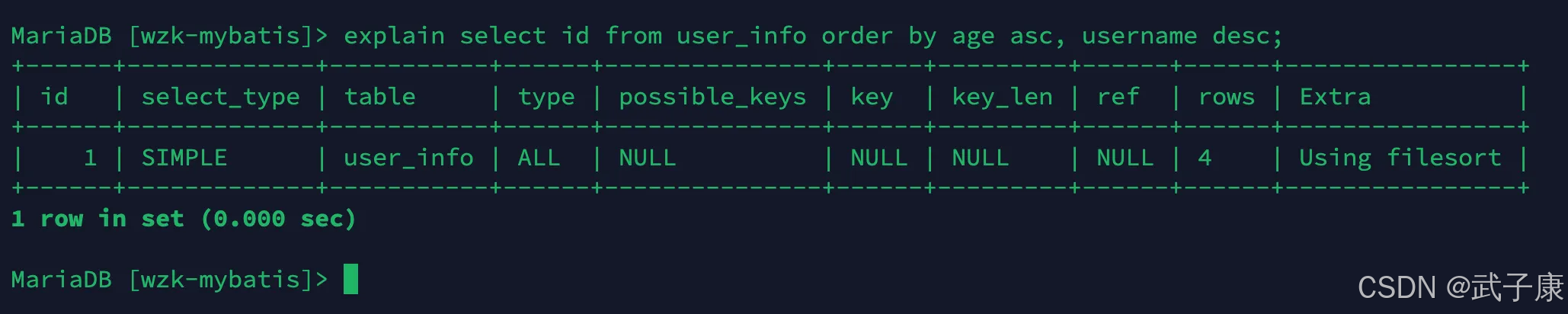
對索引列同時使用了 ASC 和 DESC:
explain select id from user_info order by age asc, username desc;
對應的結果如下所示:
where 子句和order by子句滿足最左前綴,但where 子句使用了范圍查詢:
explain select id from user_info where age > 10 order by username;
對應的結果如下所示:

order by 或者 where + order by 索引沒有滿足索引最左前列:
explain select id from user_info order by username;
執行結果如下所示:

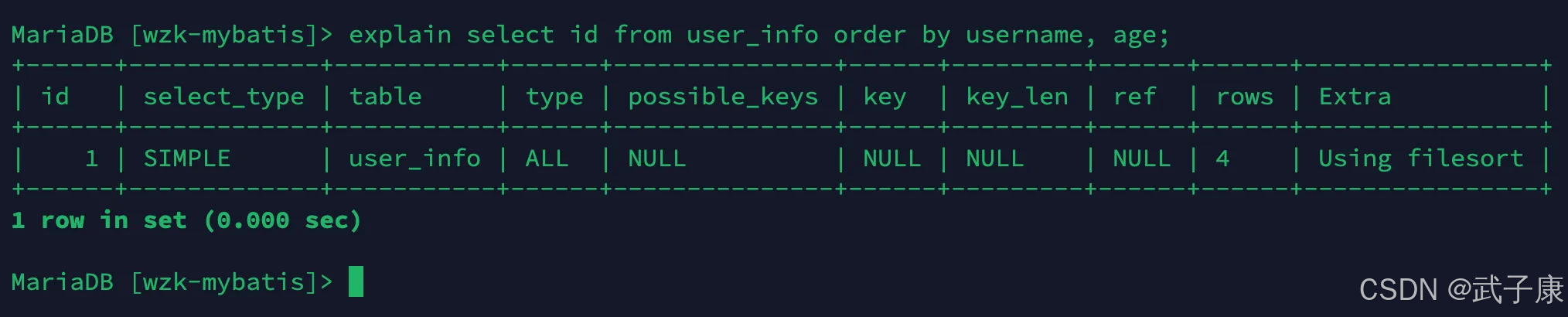
使用了不同的索引,MySQL每次只采用一個索引,order by涉及了兩個索引:
explain select id from user_info order by username, age;
對應的結果如下所示:
where 子句與order by子句,使用了不同的索引:
explain select id from user_info order by abs(age);
對應的結果如下所示:

ASC DESC
- ASC:升序(Ascending),從小到大。
- DESC:降序(Descending),從大到小。
- SQL 中默認是 ASC,顯式寫 DESC 會反轉結果順序。
SELECT * FROM users ORDER BY age ASC; -- 年齡小的在前
SELECT * FROM users ORDER BY age DESC; -- 年齡大的在前
聚簇索引(Clustered Index)與輔助索引(Secondary Index)
- 索引結構
- InnoDB 存儲引擎采用 B+ 樹作為索引結構
- 聚簇索引:
- 葉子節點存儲完整的數據記錄(數據即索引)
- 每個表只能有一個聚簇索引,通常建立在主鍵上
- 物理存儲順序與索引順序一致
- 輔助索引(二級索引):
- 葉子節點只存儲主鍵值,不包含完整數據
- 通過回表操作獲取完整數據
- 一個表可以有多個輔助索引
- 遍歷方式
- 升序遍歷:
- 從 B+ 樹最左葉子節點開始向右順序掃描
- 示例:SELECT * FROM table ORDER BY id ASC
- 降序遍歷:
- 從 B+ 樹最右葉子節點開始向左順序掃描
- 示例:SELECT * FROM table ORDER BY id DESC
- 性能特點
- 聚簇索引優勢:
- 范圍查詢效率高(數據物理連續)
- 主鍵查找只需一次IO
- 輔助索引特點:
- 需要兩次查找(先查輔助索引,再查聚簇索引)
- 覆蓋索引可避免回表(查詢字段都在索引中)
- 應用場景
- 聚簇索引:
- 主鍵查詢
- 范圍查詢(如 BETWEEN, >, <)
- 排序操作
- 輔助索引:
- 非主鍵字段查詢
- 多條件查詢(可建立復合索引)
- 頻繁查詢但更新少的字段聚簇索引(Clustered Index)與輔助索引(Secondary Index)
- 索引結構
- InnoDB 存儲引擎采用 B+ 樹作為索引結構
- 聚簇索引:
- 葉子節點存儲完整的數據記錄(數據即索引)
- 每個表只能有一個聚簇索引,通常建立在主鍵上
- 物理存儲順序與索引順序一致
- 輔助索引(二級索引):
- 葉子節點只存儲主鍵值,不包含完整數據
- 通過回表操作獲取完整數據
- 一個表可以有多個輔助索引
- 遍歷方式
- 升序遍歷:
- 從 B+ 樹最左葉子節點開始向右順序掃描
- 示例:SELECT * FROM table ORDER BY id ASC
- 降序遍歷:
- 從 B+ 樹最右葉子節點開始向左順序掃描
- 示例:SELECT * FROM table ORDER BY id DESC
- 性能特點
- 聚簇索引優勢:
- 范圍查詢效率高(數據物理連續)
- 主鍵查找只需一次IO
- 輔助索引特點:
- 需要兩次查找(先查輔助索引,再查聚簇索引)
- 覆蓋索引可避免回表(查詢字段都在索引中)
- 應用場景
- 聚簇索引:
- 主鍵查詢
- 范圍查詢(如 BETWEEN, >, <)
- 排序操作
- 輔助索引:
- 非主鍵字段查詢
- 多條件查詢(可建立復合索引)
- 頻繁查詢但更新少的字段
索引與排序的關系
索引排序的基本原理
當 ORDER BY 子句的字段順序與索引順序完全一致且排序方向相同時(都是 ASC 或都是 DESC),MySQL 優化器可以利用索引的有序特性直接返回已排序的結果集,這種優化稱為"索引排序"(Index Order By)。這種情況下,執行計劃中不會出現"Using filesort"的額外操作。
示例:
-- 假設有索引 idx_name_age (name, age)
-- 可以直接使用索引排序的情況
SELECT * FROM users ORDER BY name ASC, age ASC;
無法使用索引排序的情況
-
排序方向不一致:
- 當索引字段的排序方向與 ORDER BY 指定的方向不一致時
- 示例:
ORDER BY name ASC, age DESC(索引是 ASC,ASC)
-
字段順序不匹配:
- ORDER BY 字段的順序與索引定義的順序不同
- 示例:
ORDER BY age, name(索引是 name, age)
-
混合使用 ASC 和 DESC:
- 即使字段順序匹配,但排序方向混合時
- 示例:
ORDER BY name DESC, age ASC
-
包含非索引字段:
- ORDER BY 包含不在索引中的字段
- 示例:
ORDER BY name, email(email 不在索引中)
Filesort 操作
當無法使用索引排序時,MySQL 必須執行額外的排序操作(Filesort):
- 數據會被收集到排序緩沖區
- 使用快速排序算法在內存中排序
- 如果數據量太大,會使用臨時文件進行外部排序
- 在 EXPLAIN 結果中會顯示"Using filesort"
最佳實踐建議
-
設計匹配查詢的索引:
-- 為常見排序查詢創建專用索引 CREATE INDEX idx_users_sort ON users(last_name ASC, first_name ASC, hire_date DESC); -
使用覆蓋索引:
- 當查詢只需要索引列時,可以完全避免訪問表數據
- 示例:
SELECT user_id FROM users ORDER BY name(user_id 是主鍵)
-
**避免 SELECT ***:
- 只查詢需要的列,增加使用覆蓋索引的可能性
-
注意多列索引的順序:
- 確保索引列順序與常用 ORDER BY 子句一致
-
考慮使用 DESC 索引(MySQL 8.0+):
CREATE INDEX idx_desc ON table_name (column_name DESC);
特殊情況說明
-
LIMIT 優化:
- 即使需要 Filesort,帶有 LIMIT 的查詢可能只需要排序部分數據
-
索引跳躍掃描(MySQL 8.0+):
- 在某些情況下,即使 ORDER BY 不是索引的最左前綴,也可能使用索引
-
分區表排序:
- 在分區表上排序可能會有不同的性能特征# 索引與排序的關系
索引排序的基本原理
當 ORDER BY 子句的字段順序與索引順序完全一致且排序方向相同時(都是 ASC 或都是 DESC),MySQL 優化器可以利用索引的有序特性直接返回已排序的結果集,這種優化稱為"索引排序"(Index Order By)。這種情況下,執行計劃中不會出現"Using filesort"的額外操作。
示例:
-- 假設有索引 idx_name_age (name, age)
-- 可以直接使用索引排序的情況
SELECT * FROM users ORDER BY name ASC, age ASC;

)









)







