【2025版】44、第十四節 機器終身學習 一 為什么今日的人工智能A_嗶哩嗶哩_bilibili
【2025版】42、第十三節 神經網絡壓縮 一 類神經網絡剪枝PruA_嗶哩嗶哩_bilibili
【2025版】30、第九節 機器學習的可解釋性 上 – 為什么神經網絡可以正_嗶哩嗶哩_bilibili
目錄
1. 終生學習
1.1 災難性遺忘
1.2?終身學習評估方法
1.3 解決災難性遺忘
2.?網絡壓縮
2.1?網絡剪枝(減少連邊 / 神經元)
2.2?知識蒸餾(學習老師的分布)
2.3?參數量化 (用更少的空間存儲參數)
2.4?網絡架構設計(改變結構優化參數)
2.5?動態計算(根據計算資源調整工作量)
3.?可解釋性人工智能
3.1 局部可解釋(為什么判斷是一只貓?中間層得到了什么?)
3.2 全局可解釋(什么樣的圖片叫做貓)
1. 終生學習
1. 模型學會解決一個task后 繼續學習別的task(一個會多個task的模型)
2.?模型上線后 收到來自使用者的反饋 并且得到新的訓練數據更新模型
1.1 災難性遺忘
比如有task1 和 task2,如果最開始直接把task1 和 task2的目標和訓練數據一起給模型 模型可以學得很好。但是如果先學task1,再學task2,task1的正確率會低很多(遺忘)
- 如果要重新學一遍task1 每次有新任務了就要把之前的重新學一遍 效率太低。
- 如果每個任務都分別一個模型:一是存儲量會大很多,二是任務之間可能有共通之處,讓一個模型學多個task會更有幫助。
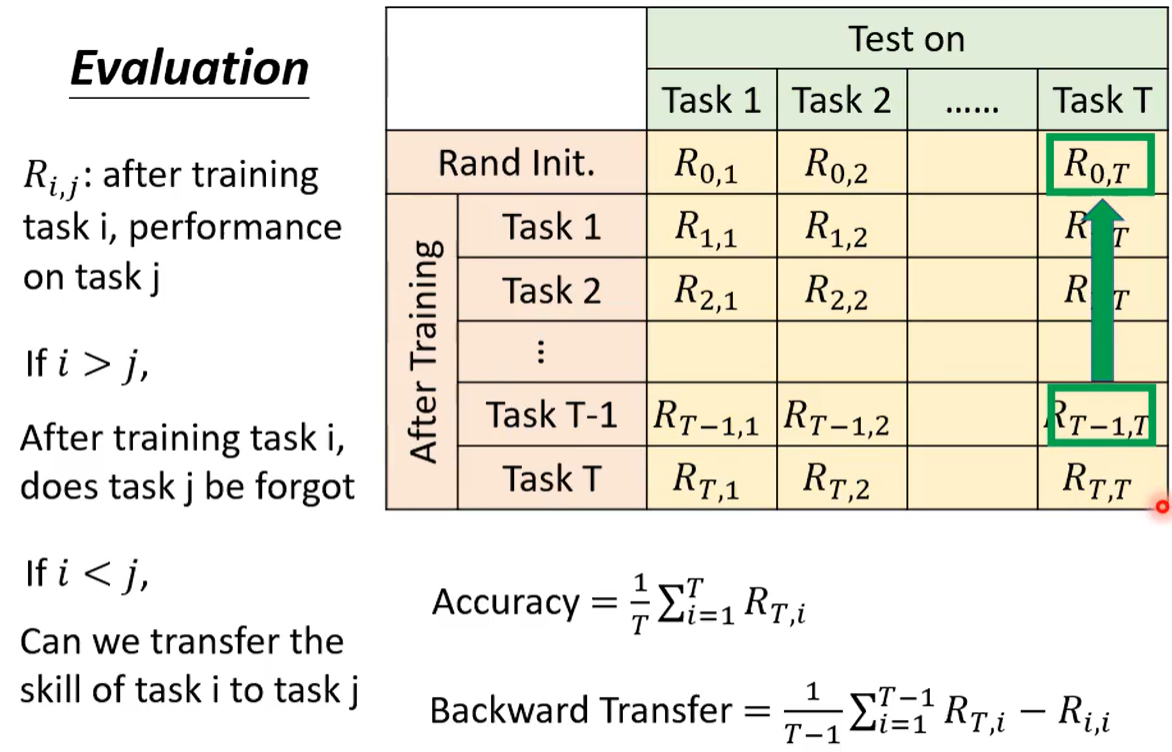
1.2?終身學習評估方法
一個矩陣 Ri,j 代表學習 i 個任務后 在任務 j 的表現
j 在 i?前?可以看出 j 有沒有被遺忘; j 在 i 后 可以看出 任務 i 能否遷移到任務 j
準確率則用 T 個任務都學完后的數據; 后向遷移為 所有模型(最終 - 剛學的時候)的均值
1.3 解決災難性遺忘
遺忘的主要原因: 最適合 task2 的參數沒那么使用與 task1。參數需要綜合前后。
選擇性的突觸可塑性:盡量學對新任務比較重要的參數,對過去任務很重要的參數盡量不改變。
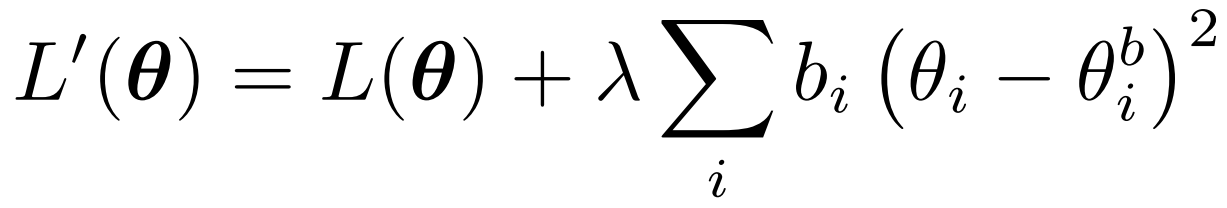
現在的參數為 θ? 只考慮當前最新的參數的損失為 L(θ)
bi 為之前任務的重要性系數? θ_b 為之前的參數。? ? 需要設定 λ和b 的系數。
GEM 梯度回合記憶:存下歷史任務對應的梯度方向,用(當前任務梯度方向 + 歷史梯度方向) 作為更新方向。
2.?網絡壓縮
不降低多少性能的情況下 減少網絡參數。
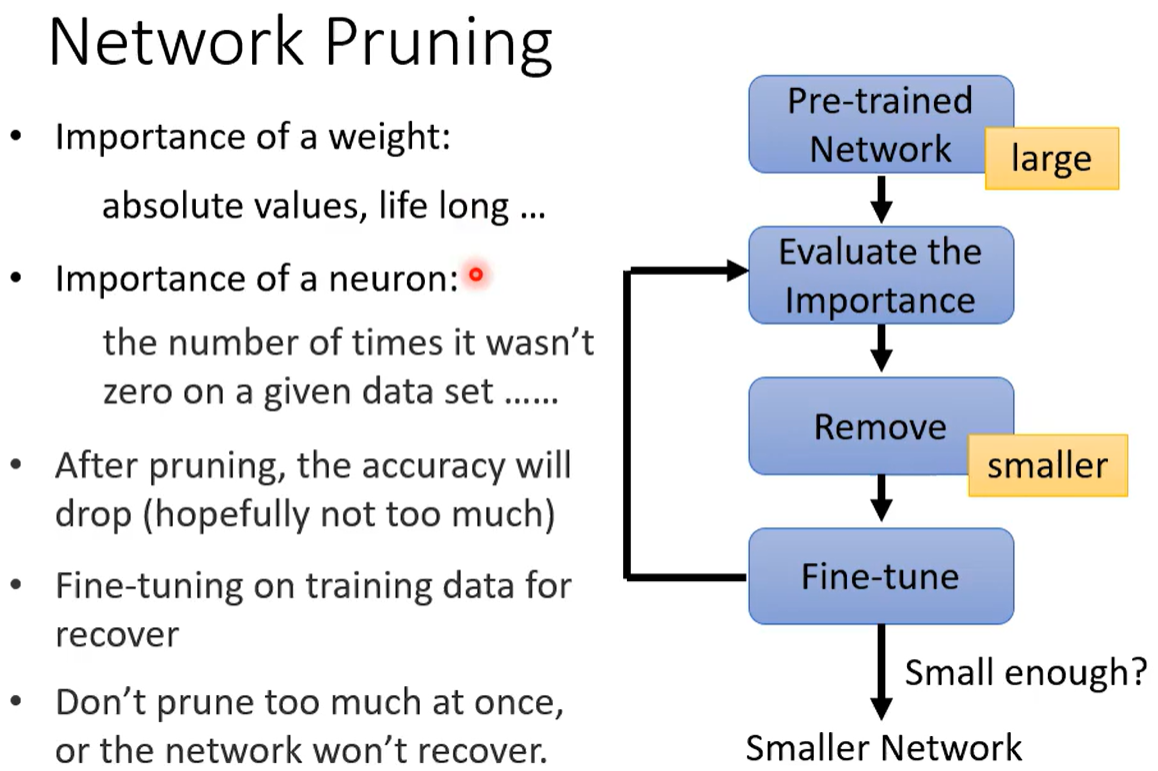
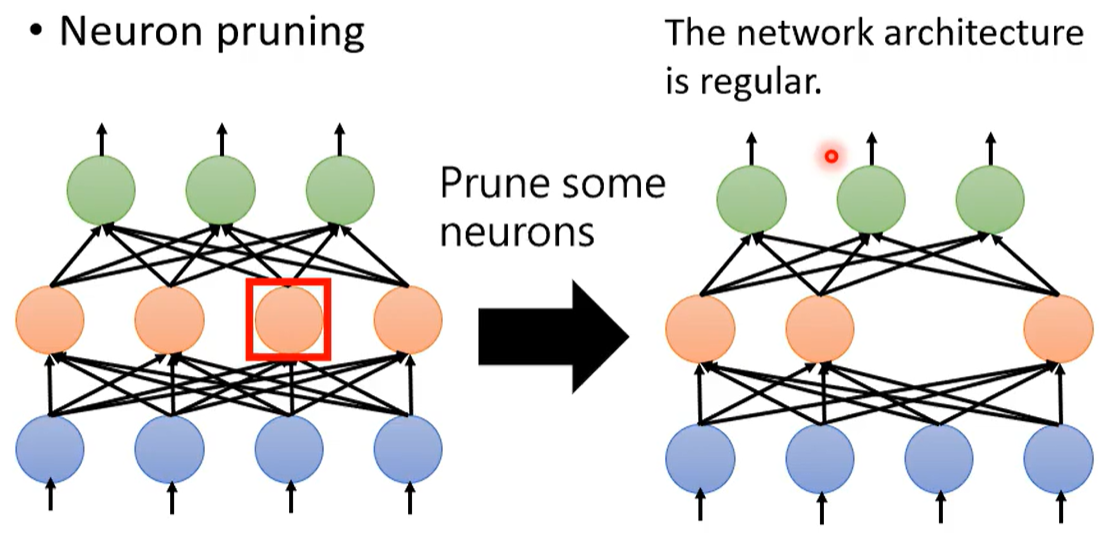
2.1?網絡剪枝(減少連邊 / 神經元)
- 評估網絡中 神經元/權重的 重要性
- 剪枝掉10%(一小部分)不太重要的參數? ?(一下子剪枝太多會對正確率損壞太大)
- 微調保障準確率
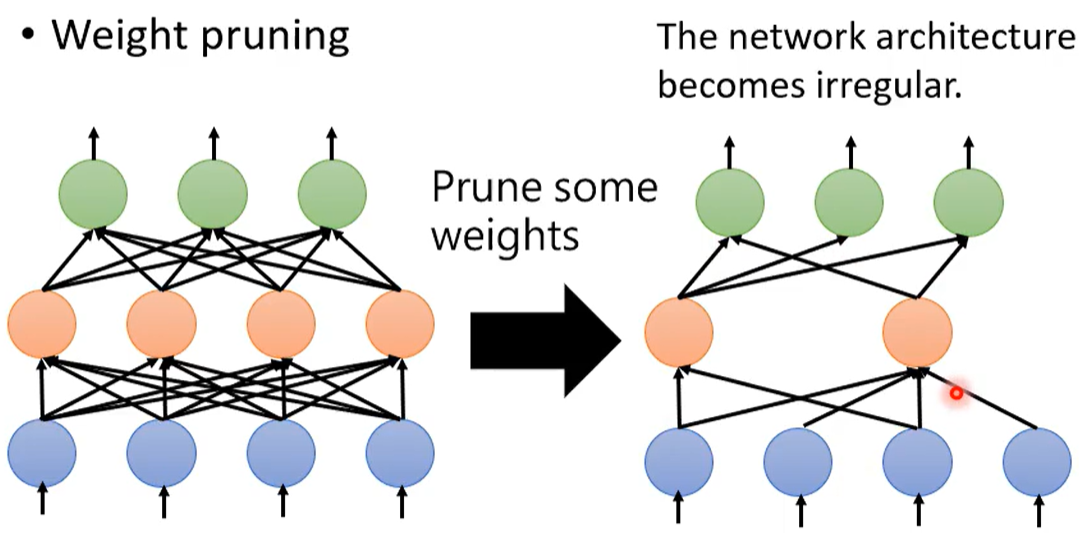
但是剪枝掉一些權重 會使得網絡結構不規則。
在Pytorch中定義網絡:每層幾個神經元 多少 多長輸入輸出;GPU加速 把網絡看做矩陣乘法。
?網絡不規則 會使得難以構建&訓練網絡。
刪去權重 只是把權重調為零。但如果把剪掉的權重設為0 會使得網絡沒有真正減小。
相比而言 刪去神經元會更方便一些。
2.2?知識蒸餾(學習老師的分布)
比如手寫數字 監督學習學這張圖片是“1” 太難了(分布要是 “1”為1 其余都為0)
我先訓練一個大網絡作為老師網絡(得到圖片“1” 輸出的分布)?學生小網絡去學那個輸出分布
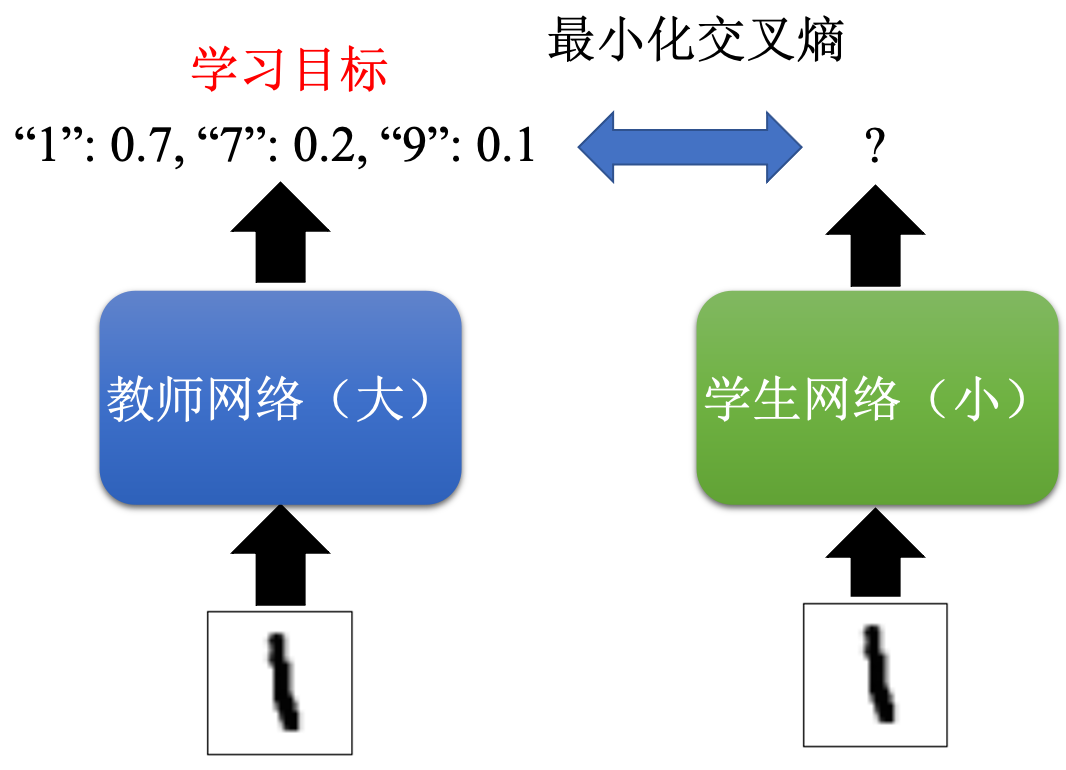
大網絡 可以通過集成學習 一些高質量分類器平均值
還可以幫助小網絡學到 “1”比較像“7” 的知識
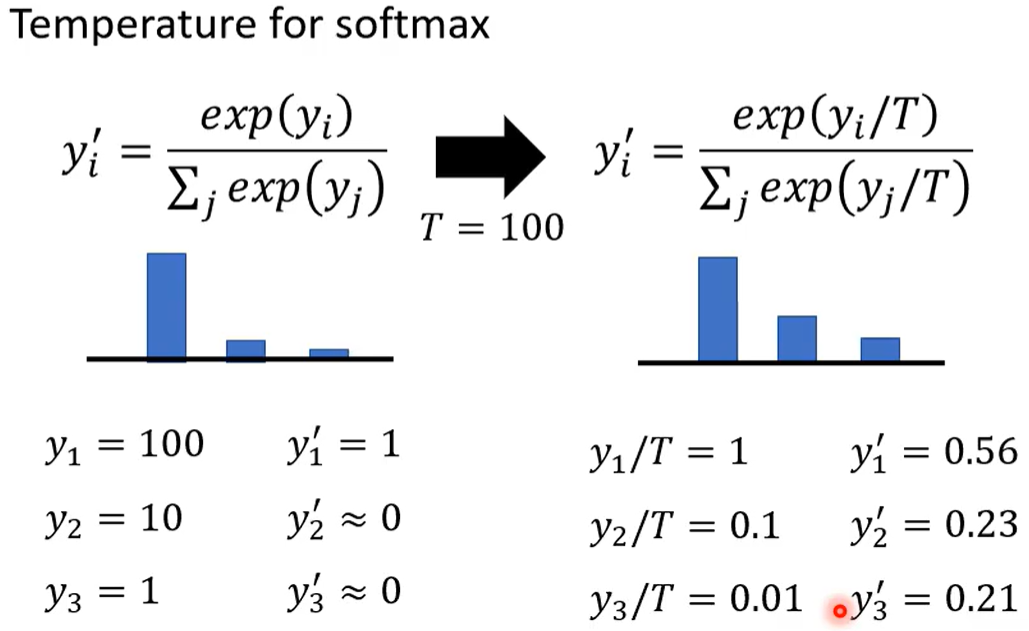
小技巧:在softmax除以溫度
T=1時不變? ?大一些的T可以拉近e^y 之間的距離
不改變老師分類器的結果 但可以使訓練更平滑
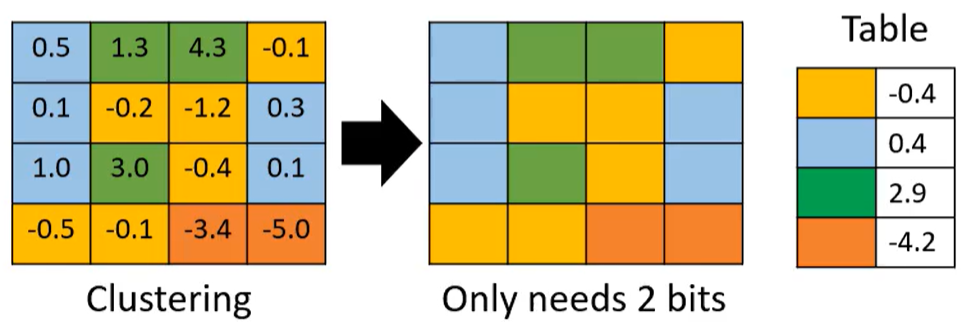
2.3?參數量化 (用更少的空間存儲參數)
法1:權重聚類? 聚類完把一個類別中的值設為他們的平均值(如下表中的顏色)
只需記錄每個參數屬于哪個類別群;每個群平均數是多少
本來存一個參數要8/16位 現在只需2位
還可以用 huffman編碼? ? 二值網絡(參數只有±1) 等技巧壓縮
2.4?網絡架構設計(改變結構優化參數)
深度可分離卷積
一般CNN 參數量為 K*K*I*O
深度卷積 每個濾波器對應一個通道,輸入跟輸出的通道數量相同。? K*K*I
點卷積 濾波器的核都是1*1? ? ?上只關注通道內,下只關注通道間。? 1*1*I*O
?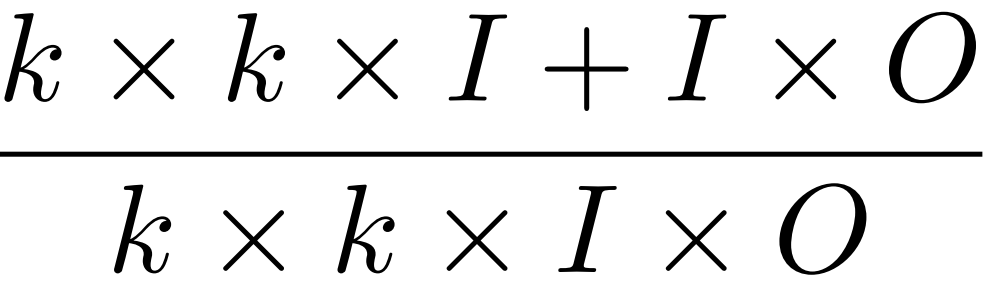
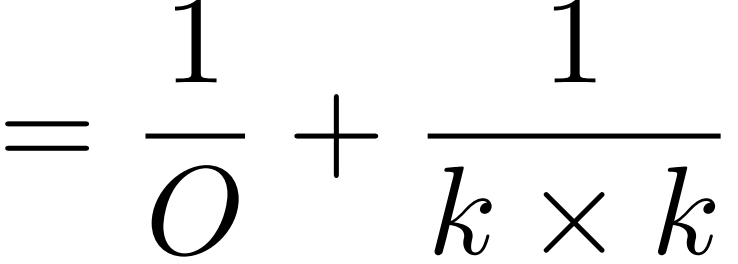
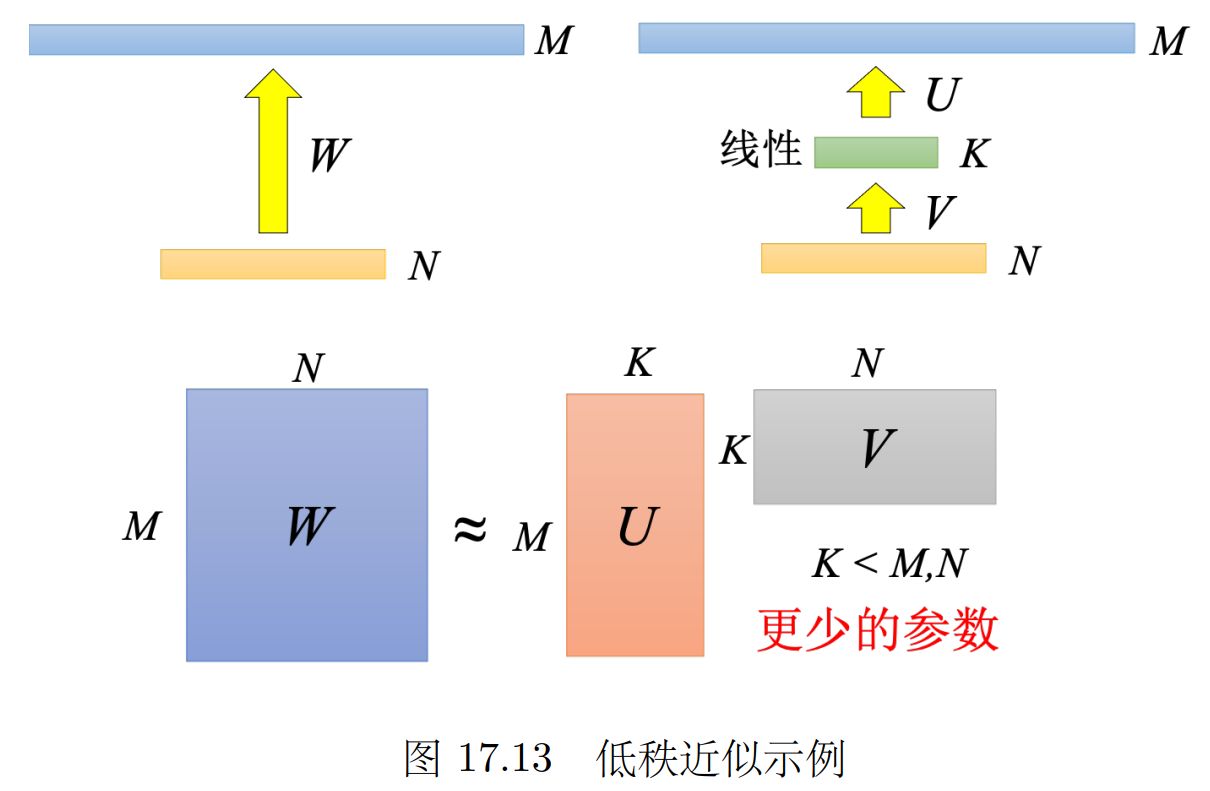
低秩近似 用矩陣乘法? ?m*n = m*k?*?k*n
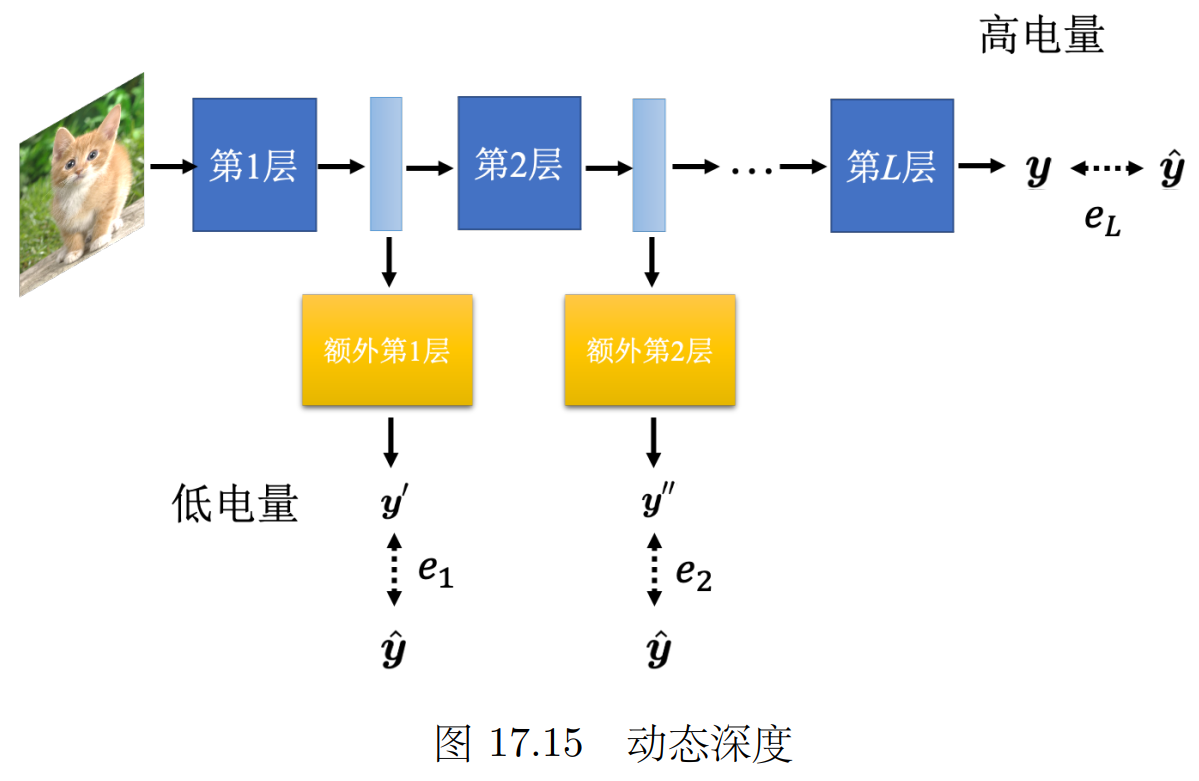
2.5?動態計算(根據計算資源調整工作量)
計算資源多/問題難度大 就充分利用計算資源;? ?根據現有計算資源 自由調整對計算量的需求。
(就像手機的省電模式一樣)
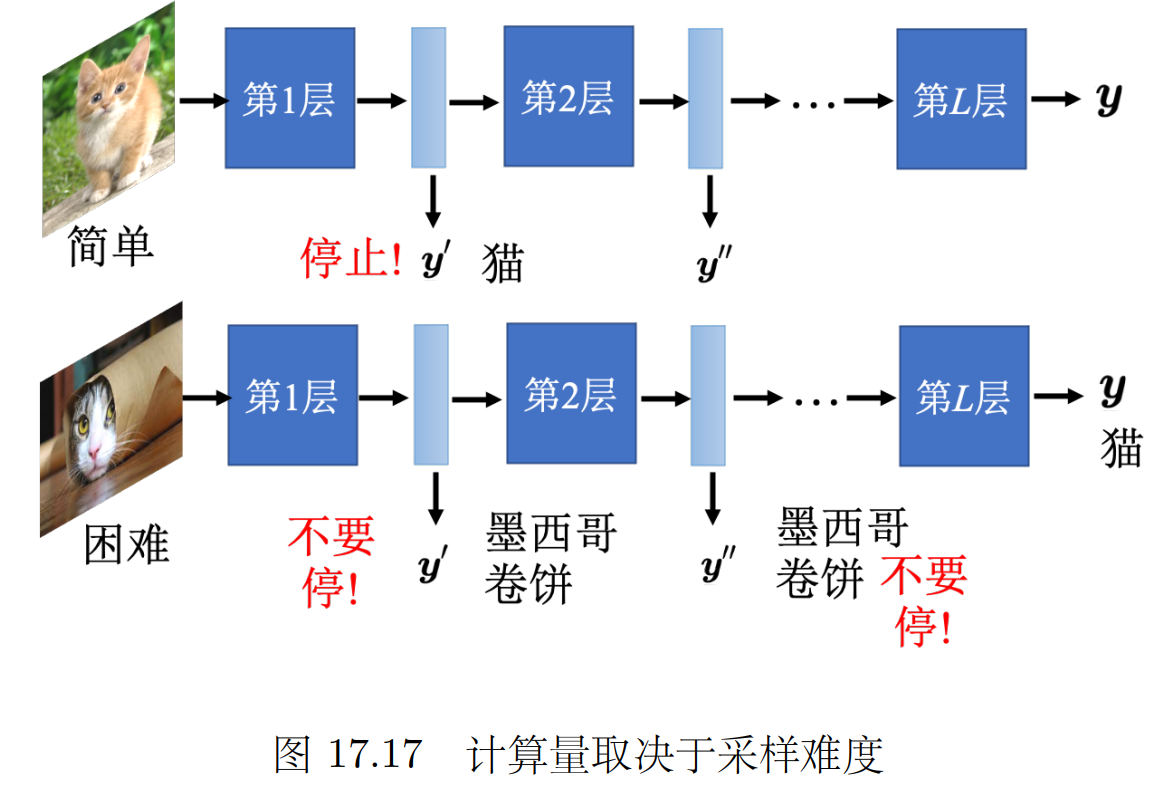
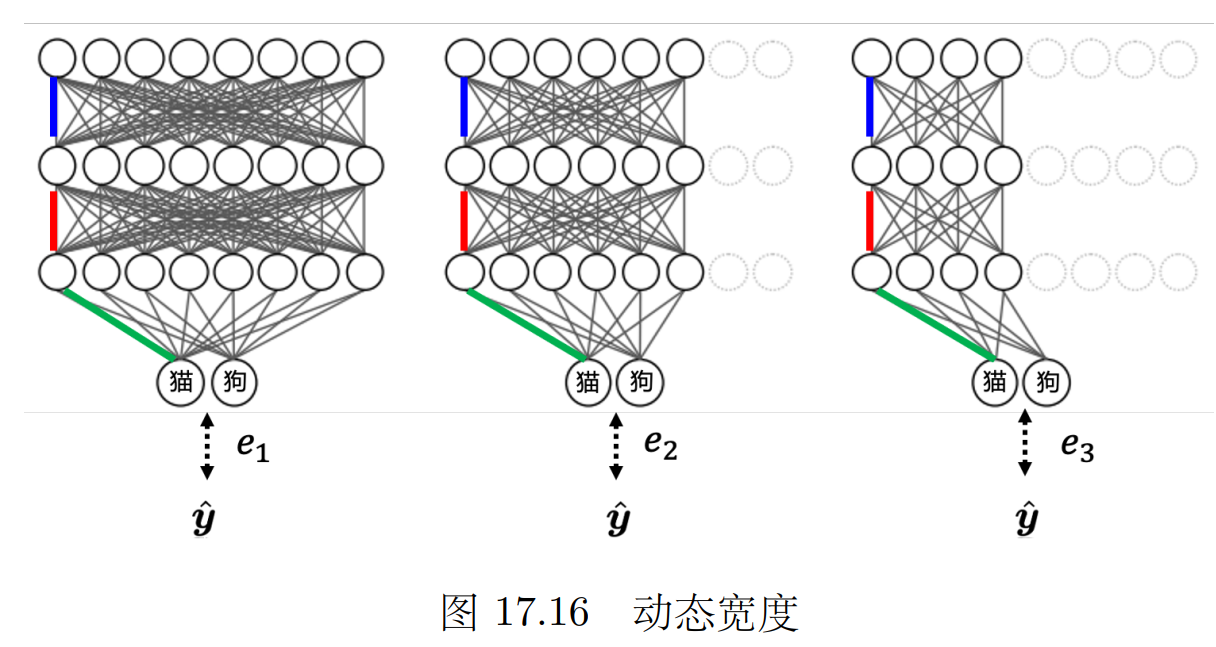
可以自行調整 神經網絡的深度(幾層)寬度(一層幾個神經元)
我們平時是 只把神經網絡的最后一層的輸出當作最后的結果。
可以把每一層神經網絡的輸出都可以當成最后的分類結果,根據計算資源計算到哪一層。
讓標準答案跟每一個額外層的輸出越接近越好,把所有的輸出跟標準答案的交叉熵都加起來得到 L
![]()
3.?可解釋性人工智能
為什么需要可解釋性:
1.機器學習模型往往是一個黑盒子,無法解釋這個黑盒子中是如何通過輸入得到輸出的。但模型的安全性在行業落地時十分重要,醫療診斷不給出診斷理由,自動駕駛不給出操作理由,很難相信。
2.知道模型錯在什么樣的地方,為什么犯錯,可以有更好的、更有效率的方法來提升模型
線性模型 可解釋性強 但功能比較有限;模型越強越難解釋(二者需要平衡)
決策樹 每個節點向左/向右 直到葉子結點。具有一些可解釋性,但特征變多,變復雜到隨機森林之類又變得比較難解釋。
我們期望的可解釋是什么樣的?就像人腦也是一個黑盒,但我們可以相信另一個人的判斷。
心理學實驗:想要插隊,相比直接說,和前面的人說“我趕時間”別人接受的程度會提高很多。
相似的,機器學習好的解釋就是人能接受的解釋。
3.1 局部可解釋(為什么判斷是一只貓?中間層得到了什么?)

哪些部分(token 片段 像素)判斷出來是一只貓?如何知道一個部分的重要性?
如果我們改造或刪除某一個部分以后,網絡的輸出有了巨大的變化 就說明很重要。(梯度)
梯度大的地方標白 構成的圖:顯著圖。

下方是原始顯著圖 有羚羊輪廓但如何使得顯著圖的效果更好呢?(降低噪聲點影響)

在圖片上面加上各種不同的噪音,接著在每一張圖片上計算顯著圖,再平均起來
網絡是如何去處理這個輸入的?
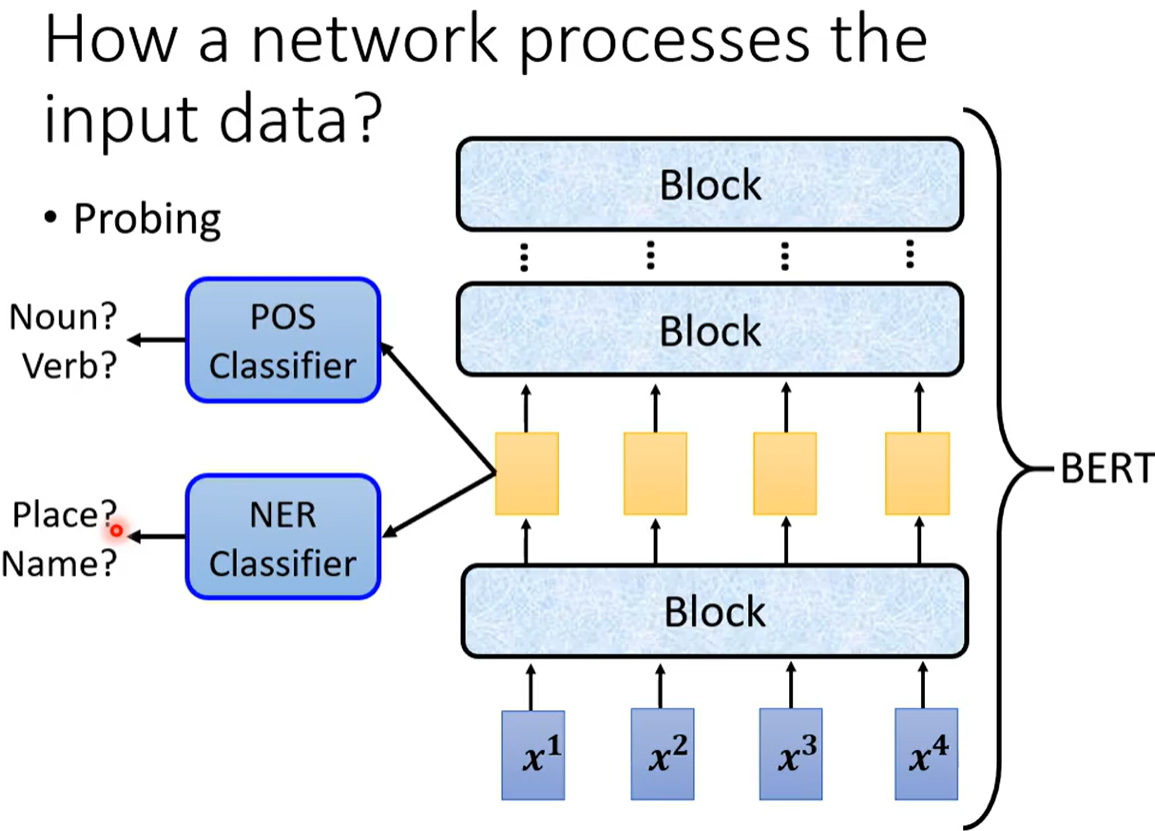
可以將隱藏層(中間層)網絡的輸出可視化 或者看其中有沒有和任務相關信息。
probing探針 插入network 把中間層的內容拎出來 看是否可以復現原任務。
例1. BERT 的某一層到底學到了什么? ? ?POS詞性分類問題? ?NER命名實體分類問題
把BERT 某一層的embedding??丟給一個POS分類器(分類器本身強度 不能太好也不能太差),
如果分類器分類的正確率高 代表包含詞性信息 否則不包含詞性信息。
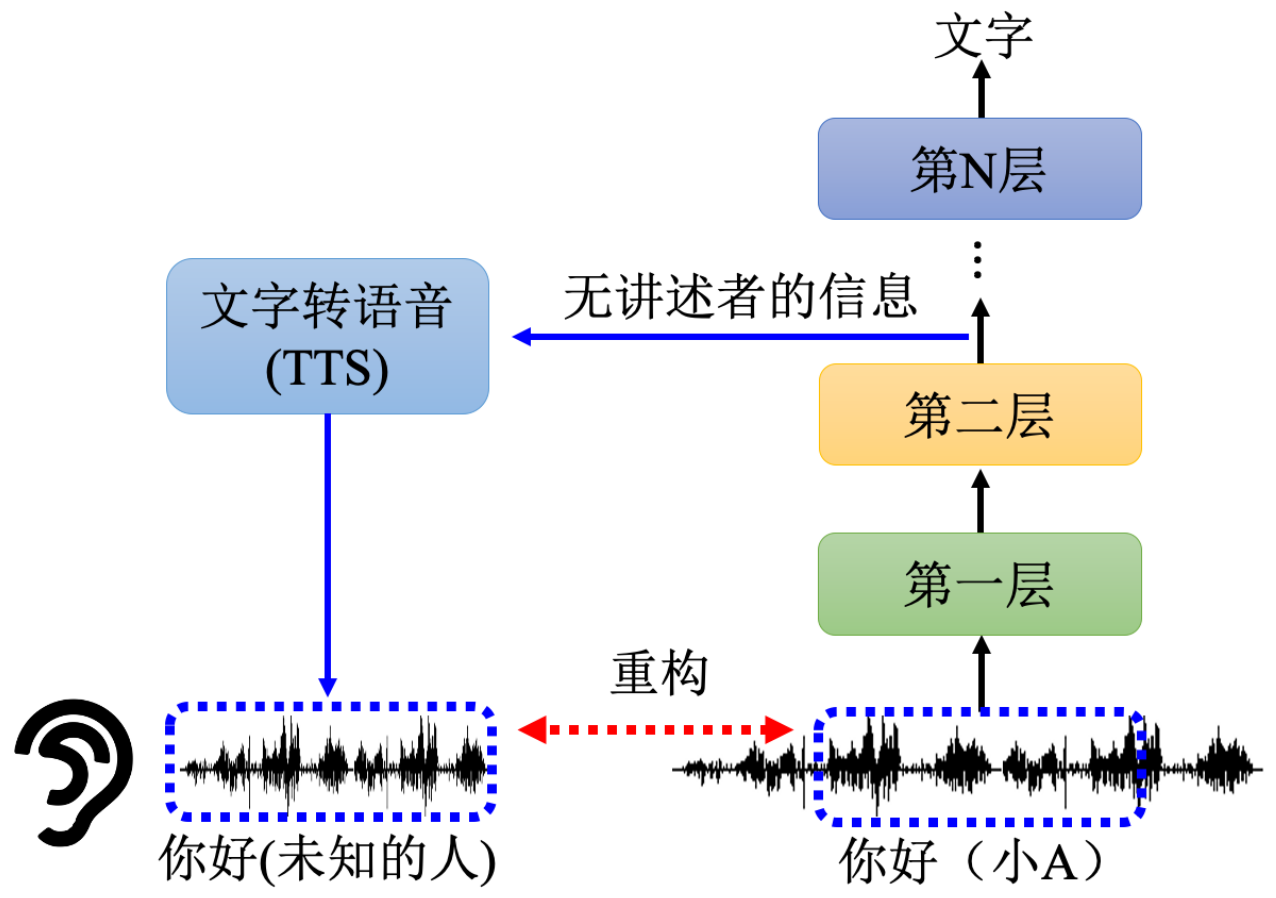
例2. 音頻轉文字? 中間層拿出來給TTS 看能否重構出原音頻
(一定要包含原音頻的信息 才會成功重構)
3.2 全局可解釋(什么樣的圖片叫做貓)
想知道某個濾波器主要是檢測哪個部分的?檢測到什么了什么部分說明是貓?
可以用梯度上升找使得這個濾波器得分最高的X 的樣子。
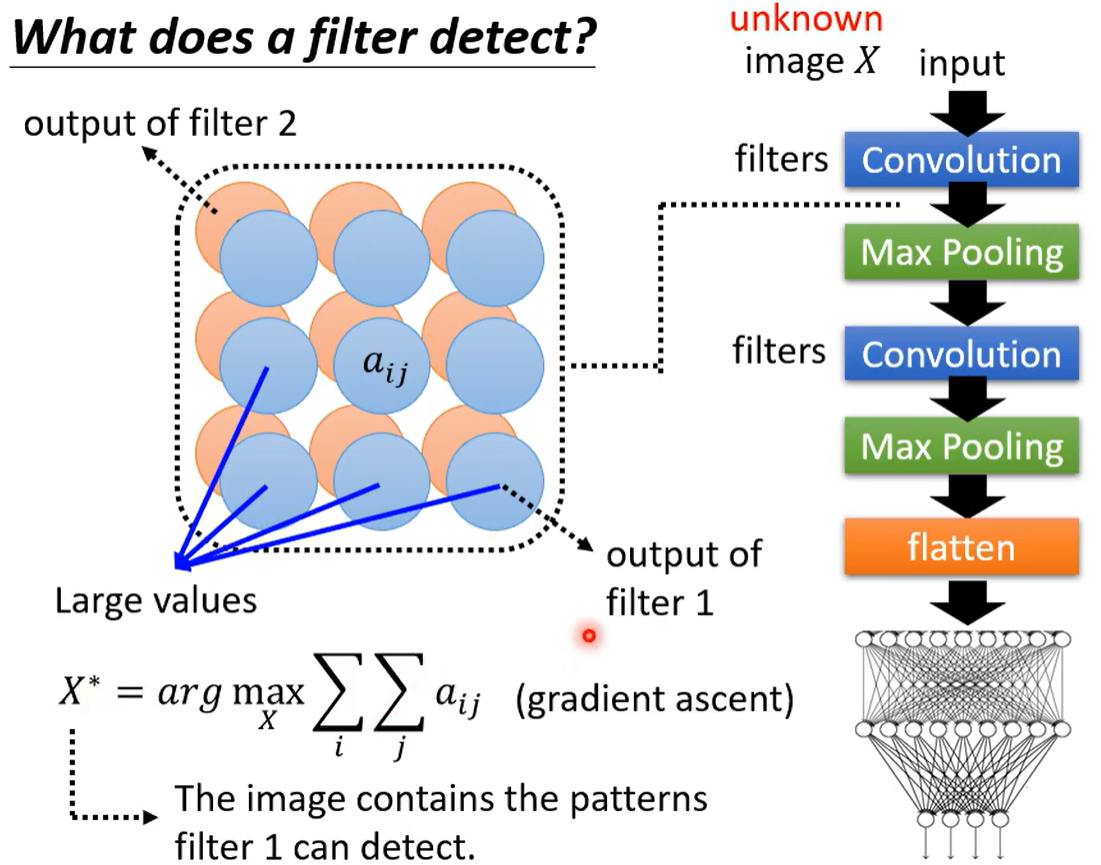
但是直接輸出得分最高的圖像(機器心目中最像的圖像)人眼不一定會認為
因為圖像需要一些噪聲 才能幫助看到所有的物體(一定魯棒性)
如果想讓圖片生成人所希望看到的 還需要進行一些正則化/GAN 之類的操作 減少無關量+生成更接近人心目中的圖像
















)


