文章目錄
- 前言
- 一、題目和摘要
- 二、引言
- 三、相關工作
- 四、方法
- 五、訓練
前言
開沖,清華大學的,帶HDmap的端論文,用的Query,和UniAD一樣。
一、題目和摘要
ViP3D: End-to-end Visual Trajectory Prediction via 3D Agent Queries
ViP3D:通過三維智能體查詢進行端到端視覺軌跡預測
注意,這篇論文要輸入HDMap
PS:Query 是 Transformer 框架里的“查詢向量”
Agent Query 的核心想法是:
給場景中每一個潛在的交通參與者分配一個可學習的 Query 向量(就像是給每個人一個“跟蹤編號”)
這個向量在網絡計算時會主動去從傳感器特征(比如圖像特征)里抓取與自己對應的那個人/車的相關信息。
它和傳統的密集 BEV 特征不一樣:
傳統:先生成一張密密麻麻的地圖,再用算法去找人 → 中間有 NMS、關聯匹配等不可微步驟。
Agent Query:一開始就假設“我有 N 個對象”,每個對象一個 Query,全程跟蹤 → 不需要 NMS 或匹配,過程可微。
感知和預測如果分離,預測作為下游模塊,只能從感知模塊接收有限的信息。更糟糕的是,感知模塊的誤差會傳播和累積,對預測結果產生不利影響。
在這項工作中,我們提出了ViP3D,這是一種基于查詢的視覺軌跡預測管道,它利用原始視頻中的豐富信息直接預測場景中代理的未來軌跡。ViP3D采用稀疏代理查詢來檢測、跟蹤和分析,并在整個管道中進行預測,使其成為第一種完全可微的基于視覺的軌跡預測方法。
與使用歷史特征圖和軌跡不同,來自先前時間戳的有用信息被編碼在Agent Queries中,這使得ViP3D成為一種簡潔的流式預測方法。此外,在nuScenes數據集上的大量實驗結果表明,ViP3D在基于視覺的預測方面比傳統管道和之前的端到端模型具有更強的性能。
二、引言
感知和預測是現有自動駕駛軟件管道中的兩個獨立模塊,它們之間的接口通常被定義為手工挑選的幾何和語義特征,如歷史目標軌跡、目標類型、目標大小等。
缺點:導致可用于軌跡預測的有用感知信息的丟失。例如,尾燈和剎車燈指示車輛的意圖,行人的頭部姿勢和身體姿勢則表明他們的注意力。
基于激光雷達的軌跡預測的端到端模型缺點:
(1)無法利用來自相機的豐富細粒度視覺信息;
(2)這些模型使用卷積特征圖作為幀內和幀間的中間表示,因此受到不可微操作的影響,如對象解碼中的非最大抑制和多對象跟蹤中的對象關聯。
為了解決這些缺點,我們提出了一種新的管道,該管道利用以查詢為中心的模型設計來預測未來的軌跡,稱為ViP3D(通過3D目標查詢進行視覺軌跡預測)。
如何做:ViP3D消耗來自周圍攝像機和高清地圖的多視圖視頻,并以端到端和簡潔的流式方式進行代理級未來軌跡預測,如圖1所示。

ViP3D使用3D目標查詢作為流水線的主線,從原始視頻幀輸入中實現端到端的未來軌跡預測。這種新穎的設計通過有效地利用細粒度的視覺信息(如車輛的轉向信號)來提高軌跡預測性能。
具體而言,ViP3D利用3D代理查詢作為整個管道的接口,其中每個查詢最多可以mapping到環境中的一個目標。
在每個時間步,查詢從多視圖圖像中聚合視覺特征,學習代理的時間動態,對代理之間的關系進行建模,并最終為每個代理生成可能的未來軌跡。隨著時間的推移,3D代理查詢被保存在一個內存庫中,可以對其進行初始化、更新和丟棄,以跟蹤環境中的代理。
此外,與以前利用歷史代理軌跡和來自多個歷史幀的特征圖的預測方法不同,ViP3D只使用來自一個先前時間戳的3D代理查詢和來自當前時間戳的傳感器特征,使其成為一種簡潔的流式方法。
三點核心貢獻:
- ViP3D是第一種完全可微分的基于視覺的方法,用于預測自動駕駛目標的未來軌跡。而不是使用手工挑選的特征,像是歷史軌跡和目標大小,ViP3D利用了原始圖像中豐富而精細的視覺特征,這些特征對軌跡預測任務很有用。
- ViP3D以3D Agent Queries為接口,顯式地對目標級檢測、跟蹤和預測進行建模,使其具有可解釋性和可調試性。
- 我們實驗最jb屌
三、相關工作
目前端到端的痛點:它們都依賴于BEV特征圖或熱圖作為中間表示,這導致從密集特征圖到實例級特征時不可避免的不可微操作,例如檢測中的非最大抑制(NMS)和跟蹤中的關聯。
我們牛逼,HDmap,把稀疏目標查詢作為表示,大大提高了可微性和可解釋性。真的有用嗎?
從密集特征圖 → 實例級信息,一般會經歷兩個關鍵步驟:
檢測里的 NMS(非最大抑制)
檢測會生成一堆可能的框,然后 NMS 會把重疊度高的框合并掉,只保留一個最可能的。
這個過程是基于“比較大小、硬決策”的,不可導(即在梯度反傳時沒法平滑計算)。
跟蹤里的關聯
跟蹤要把“這一幀的車”和“下一幀的車”對應起來,這通常用匈牙利算法等匹配方法,也屬于硬匹配,不可導。
四、方法
ViP3D利用以查詢為中心的模型設計。
被跟蹤的Agent Queries可能包含許多有用的視覺信息,包括目標的運動動力學和視覺特征。
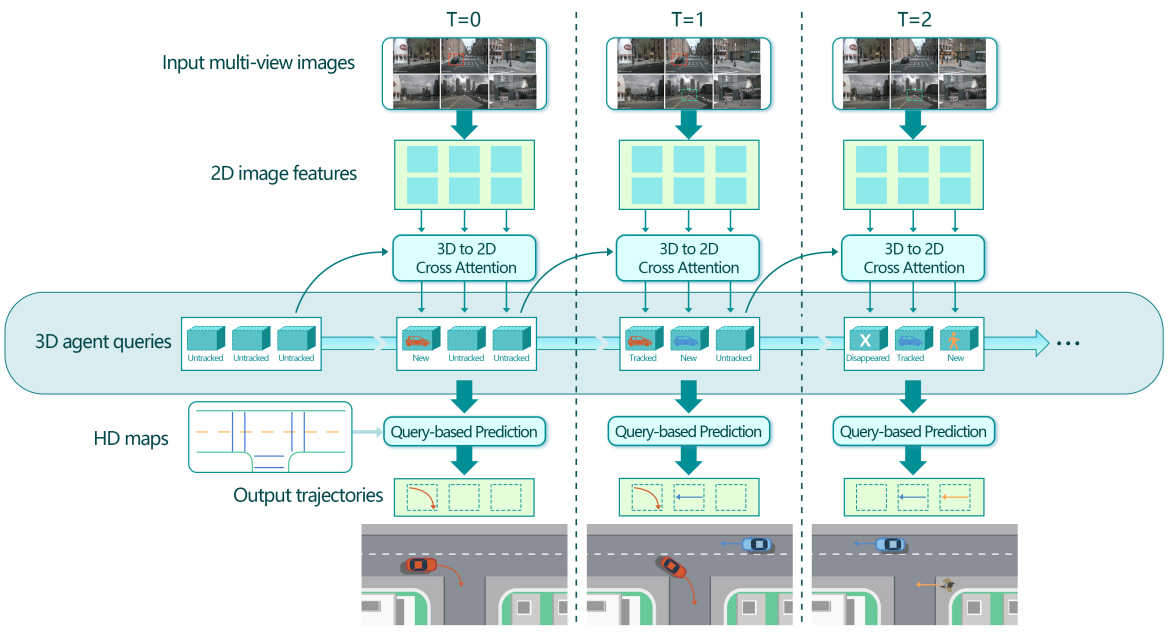
感知:
輸入:多視圖cam
輸出:跟蹤agent query集合,這包含許多視覺信息,包括agent的運動特性和視覺特征
預測:
輸入:跟蹤query和HDmap
輸出:agent的未來軌跡。
初始的3D agent query更新和丟棄,在一個query存儲庫里完成。
模型介紹:這里提取圖像用的是ResNet50和FPN,不是ViT系列。然后用相機內參和外參矩陣把3D查詢參考點映射到圖像的2D坐標上,然后將上面得到的向量作為Q,圖像特征L,經過W映射,得到三個QKV矩陣,然后計算跨注意力,最后經過一個帶層歸一化的兩層感知機FFN,更新agent query。
作者設計了兩個query來更新和移除agent,一個是匹配query,一個是空query。如果出現一個未匹配query,說明是新出現的agent,如果一個agent消失了,就分配一個未匹配且空的標簽,留待后用。對于匹配query,那就說明還在視野里,正在處理。
針對二分匹配,使用了一個query解碼器輸出每個query的中心坐標,損失函數有類別損失和坐標回歸損失,即bbox的L1損失。
Query存儲庫是一個單進單出的隊列,大小為S,僅在每個query和它的歷史狀態之間進行注意力計算,沒有多agent交互,每個query對應一個agent。
以往的軌跡預測模型分為三部分,agent編碼器,地圖編碼器和軌跡解碼器。
agent編碼器:基于查詢的檢測和跟蹤輸出被跟蹤的agent查詢,這相當于agent編碼器的輸出。因此,基于查詢的預測模塊僅由地圖編碼器和軌跡解碼器組成
地圖編碼器:采用VectorNet。
軌跡解碼器:框架級設計,基于回歸的方法(Regression-based)、基于目標的方法(Goal-based)、基于熱圖的方法(Heatmap-based)都能用。
五、訓練
模型的loss是聯合訓練的,包括前面的分類和坐標回歸loss。提出了一個新指標,EPA,端到端預測精度。數據集是nuscenes。
這里提到一個trick,就是把agent的最后一個位置作為原始值和方向作為y軸,可以使預測模型集中于未來模態預測,而不是坐標變換。
)
使用循環QSC和QKD的量子區塊鏈架構,提高交易安全性和透明度)







)









