當前大型語言模型(LLM)通過思維鏈(CoT)提升復雜任務推理能力,但研究表明其推理路徑存在嚴重冗余——例如反復驗證或無效思維跳躍,導致計算資源浪費和“幻覺”增加。

論文:Test-time Prompt Intervention
鏈接:https://arxiv.org/pdf/2508.02511
本文提出的測試時提示干預框架PI(π),首次實現了在推理過程中動態調控模型思維路徑。如同為AI配備“認知教練”,通過《When/How/Which》三模塊協同,將人類專家經驗融入AI推理過程,在多個STEM基準測試中實現推理步驟縮減50%的同時提升準確率。
問題發現:大模型推理的冗余陷阱
作者通過可視化技術揭示核心問題:
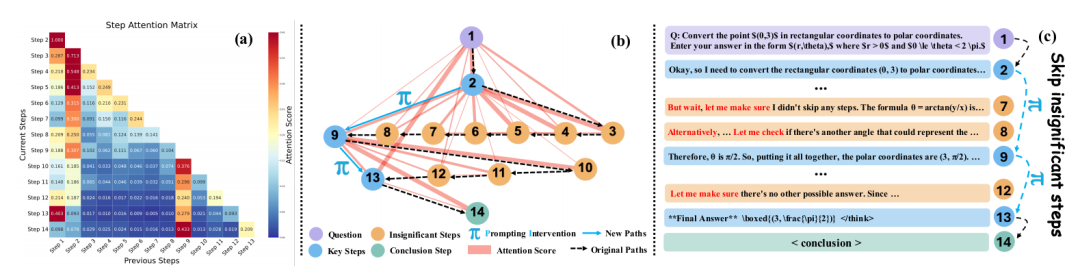
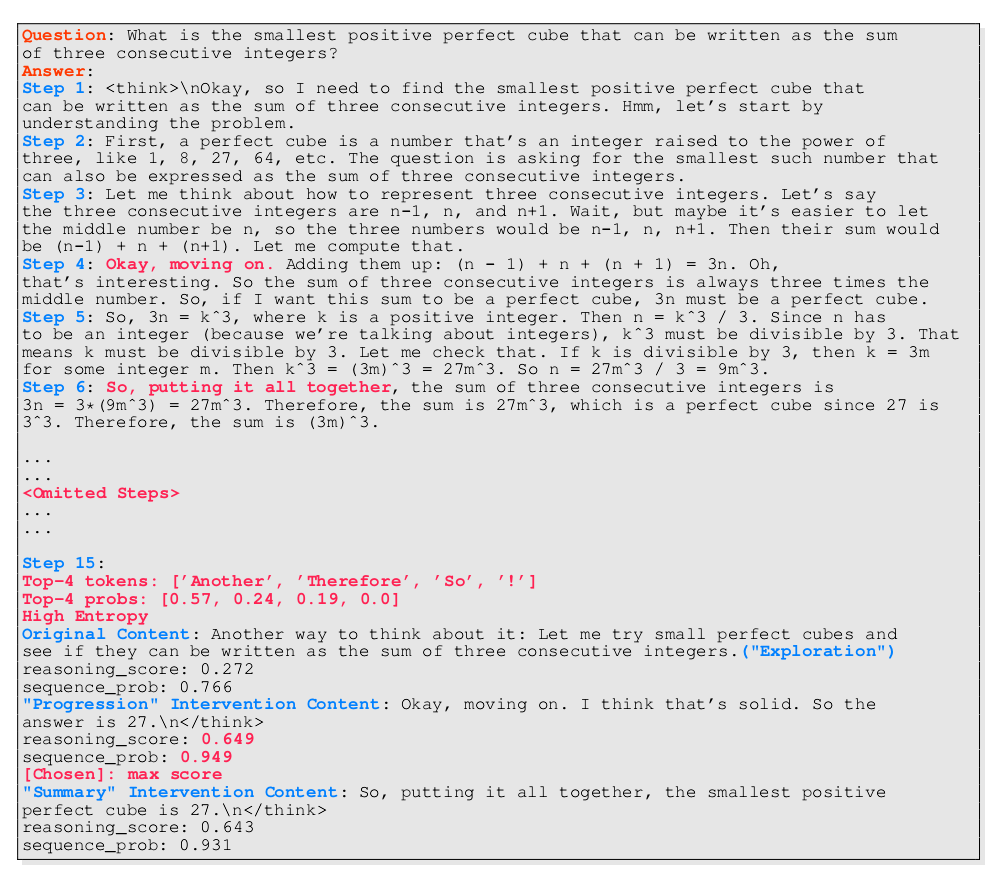
注意力漂移現象:如圖2所示,模型在關鍵決策后仍生成低注意力步驟(如步驟12),這些冗余步驟占比高達75%
驗證依賴陷阱:錯誤答案的驗證步驟數量是正確答案的12.5倍(MATH-500數據集),且驗證頻率與準確率呈負相關
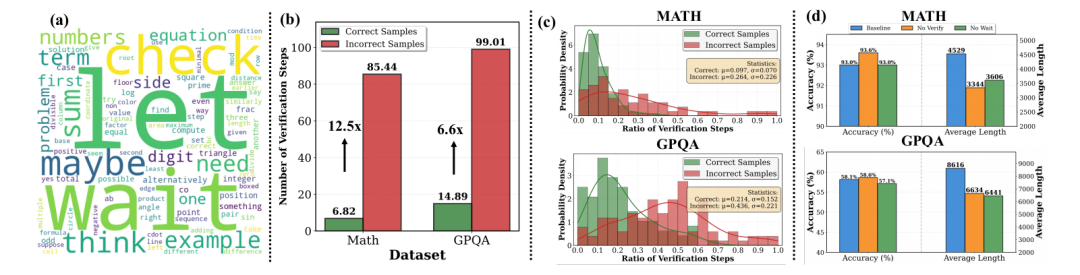
詞匯模式證據:詞云分析顯示高頻詞集中于“Wait/Check”等驗證詞匯(圖3a),暴露模型自我懷疑傾向
關鍵實驗佐證:當強制屏蔽驗證詞(如“Wait”→“So”),模型在保持90%+準確率時節省38%計算量(圖3d),證明冗余步驟可壓縮性。
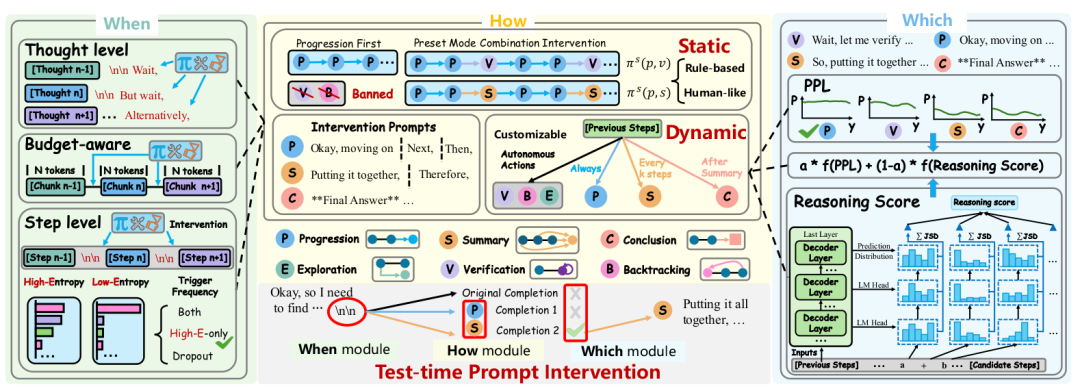
方法核心:PI框架的三模塊設計
How模塊:六類推理行為與干預策略
創新性定義推理行為圖譜:
Progression(推進): "Next, then..."?
Summary(總結): "Putting it together"
Exploration(探索): "Alternatively..."
Verification(驗證): "Wait, check..."
Backtracking(回溯): 錯誤修正
Conclusion(結論): 輸出答案雙軌干預策略:
靜態干預:預定義規則(如優先推進+總結)
動態干預:實時生成多分支(公式1):
其中觸發詞𝐓_i ∈ {推進, 總結, 驗證...},通過組合不同行為(如π?(p,s))適配任務需求𝐒^{t+1} = {𝐒_i^{t+1}, 𝐒_i^{t+1}= LRM(𝐒^{≤t},𝐓_i)
Which模塊:路徑選擇的雙指標決策
核心公式解析:
PPL(困惑度):衡量文本流暢性(公式2)
RDS(推理深度分):通過Jensen-Shannon散度量化思考深度(公式3-4):
關鍵洞察:早期層概率分布q?(y?)與最終層p(y?)差異越大,說明該步驟進行越深度語義轉換(圖8證明)
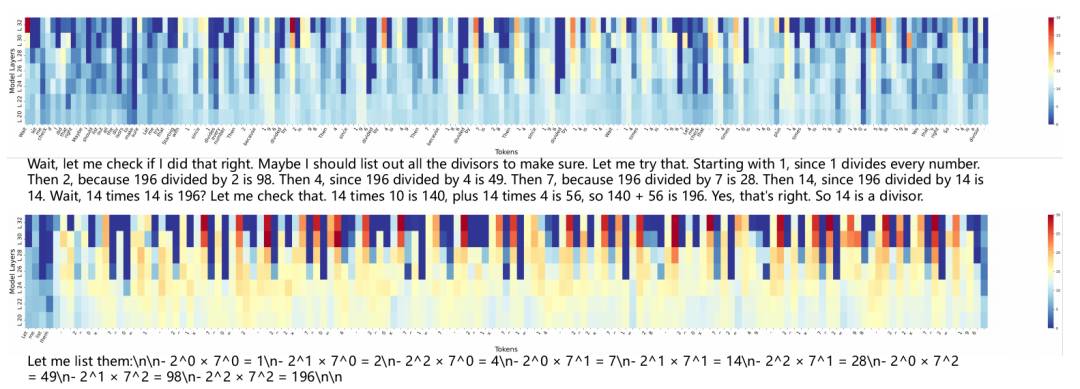
When模塊:熵值觸發的動態干預
基于信息論的觸發機制:
當首個token熵值>0.3時啟動干預(避免強制干預導致低質量內容)
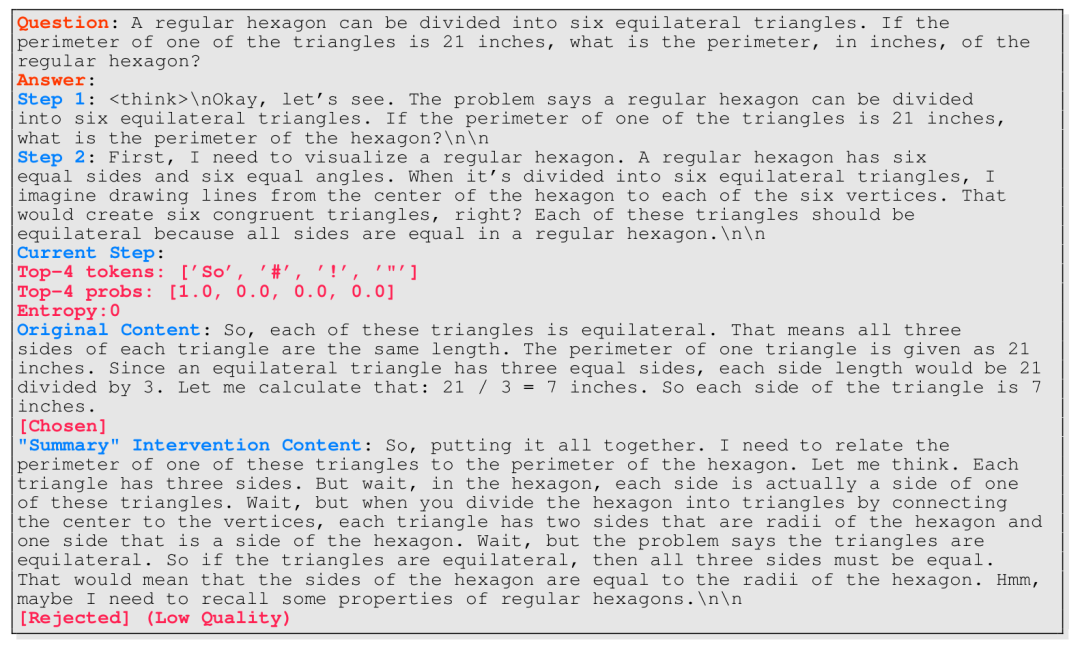
理論證明:高熵狀態干預價值VoI最大化(公式推導見附錄B)
框架全景:三模塊協同流程如圖10所示,在關鍵決策點生成多路徑并擇優
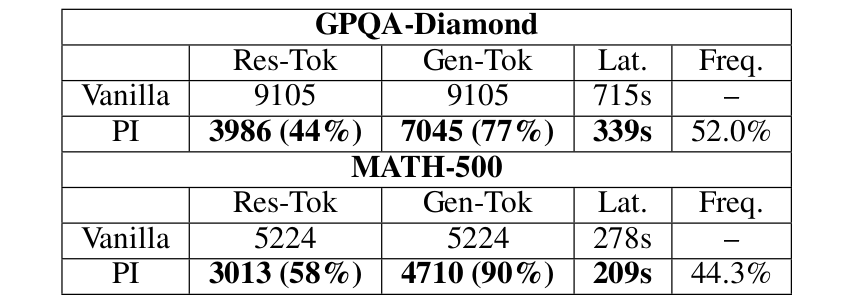
實驗驗證:效率與準確率的雙重突破
核心性能對比
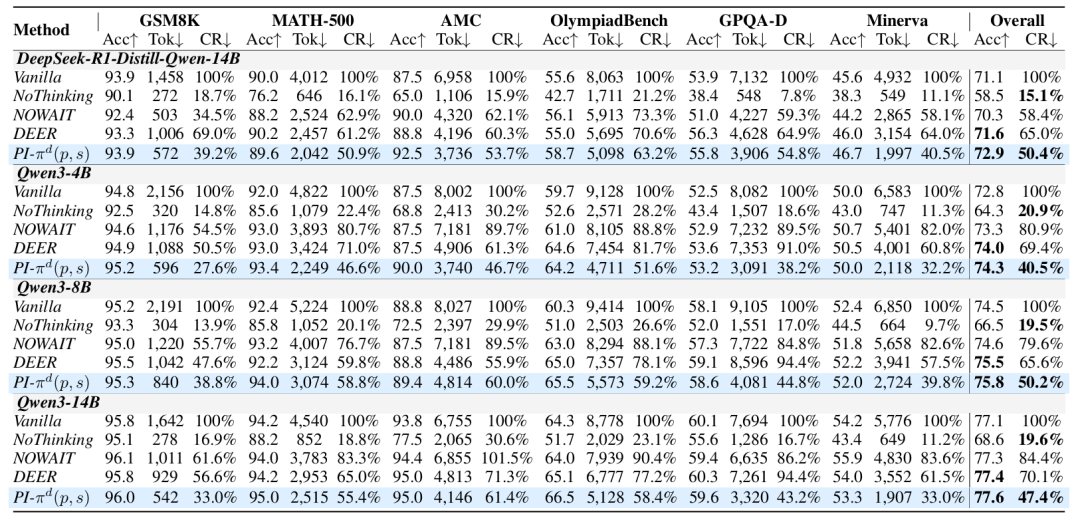
效率提升:在Qwen3-8B上,推理長度縮減至50.2%(GPQA僅需44.8% token)
準確率增益:OlympiadBench準確率從60.3%→65.5%,STEM任務平均提升1.8%
帕累托最優:全面超越基線方法(NoThinking犧牲精度,NOWAIT壓縮不足)
幻覺抑制
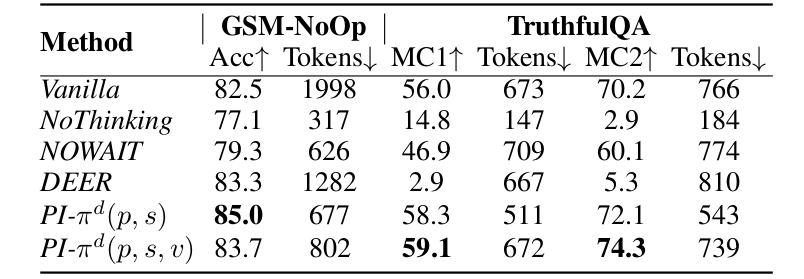
TruthfulQA的MC2指標從70.2%→74.3%
關鍵機制:驗證分支動態過濾錯誤知識(如英國國旗焚燒合法性案例)

消融實驗

移除熵觸發(-When(Ent)):準確率下降0.4%
移除RDS指標:深度思考減少導致GPQA準確率跌至55.3%
結論分支的取舍:簡單任務加速33%,復雜任務損害精度
計算成本分析:雖然多分支生成增加15% token,但總延遲降低53%(GPQA基準),因注意力計算復雜度從O(L2)降至O(α2L2)
結論與未來:可解釋推理的新方向
PI框架首次實現測試時推理路徑的動態調控,在STEM任務中達成效率與準確率的雙重突破。其價值不僅在于49.6%的平均計算節省,更開創了人機協同推理的新范式:通過《When/How/Which》模塊,人類認知智慧與AI計算能力深度耦合。未來可沿三個方向拓展:
行為深度建模:細化推理行為分類(如數學歸納/反證法)
訓練融合:將干預模式內化至模型參數(強化學習方向)
跨模態擴展:應用于多模態科學推理(如物理問題求解)
最后展望:如同AlphaGo的人類棋譜學習,PI使AI從“機械推導”邁向“受控思考”,為高風險領域提供可靠推理引擎。
備注:昵稱-學校/公司-方向/會議(eg.ACL),進入技術/投稿群

id:DLNLPer,記得備注呦










)



)
使用循環QSC和QKD的量子區塊鏈架構,提高交易安全性和透明度)



