今天我們來探討一個綜合性但至關重要的話題:給你一個微服務應用,你該如何系統性地保證其高可用性?
在互聯網技術崗的面試中,高并發、高可用和大數據通常被視為衡量候選人經驗的三大黃金標準。但說實話,是否擁有真正的高并發和大數據項目經驗,往往帶有一些“運氣”成分。如果你不是在頭部大廠的核心業務部門,確實很難接觸到那種動輒千萬QPS或PB級數據的真實場景。
然而,高可用則完全不同。它是一種普適性的工程能力。即便你維護的系統月活只有一萬人,你依然可以、也應該將它打造成一個高可用的系統。因此,相比于另外兩者,高可用是我們可以在面試中主動出擊、重點發力的方向。
當然,我們也必須清醒地認識到,一個淘寶量級的系統所談論的高可用,和一個簡單的后臺管理系統的高可用,其技術復雜度和含金量是截然不同的。但話又說回來,又有多少人真的有機會去親手構建淘寶那樣的項目呢?所以,如果你正苦于如何將自己看似平凡的項目經歷講出亮點和深度,那么今天的內容,希望能為你提供一套行之有效的思路和話術。
1. 高可用的基石:四大核心原則
在開始構建我們的高可用體系之前,我們首先要理解其內涵。我們通常使用SLA(Service Level Agreement,服務等級協議)來衡量可用性,并用“N個9”來表示。例如,當我們說一個服務的可用性是“3個9”,即99.9%,意味著在一年(365天)的時間里,該服務的不可用時間不能超過8.76小時。
那么,如何才能構建一個高可用的系統呢?其核心思想可以歸結為四大原則:
- 容錯設計 (Design for Failure):接受失敗是常態,并為此進行設計。
- 故障域隔離 (Blast Radius Limitation):限制故障的影響范圍,避免雪崩。
- 快速響應 (Fast Detection & Recovery):快速發現故障,并快速從中恢復。
- 規范化變更 (Standardized Change Process):控制由變更引入的風險。
1.1 容錯設計 - 優雅地“湊合”
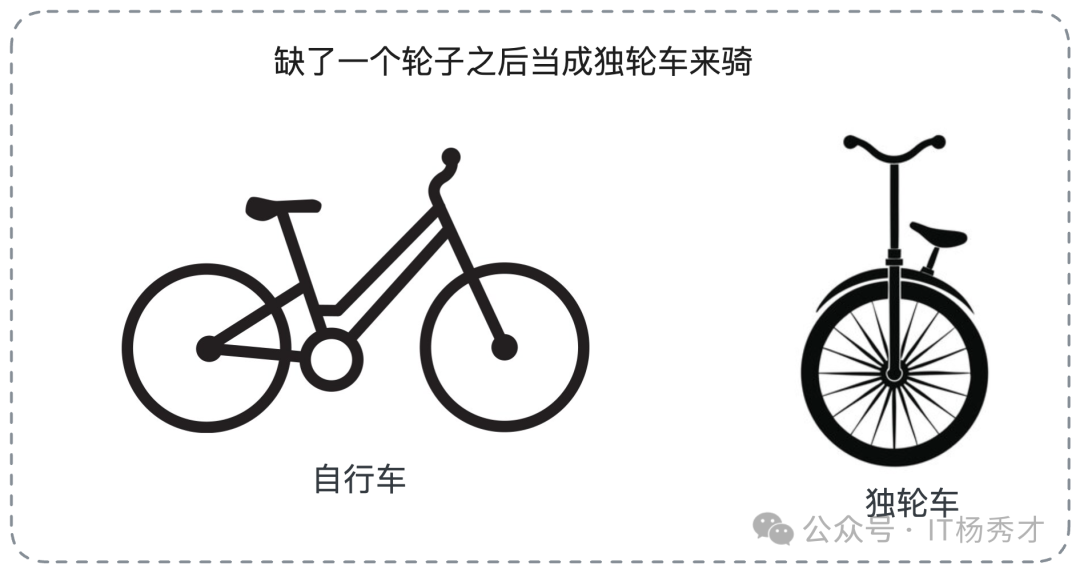
容錯的核心理念是:無論系統中發生了什么意想不到的故障,你的系統整體上依然能夠為用戶提供服務,哪怕是降級后的、有損的服務。用一句通俗的話講,就是“湊合著用”。
就像一輛自行車,如果掉了一個輪子,一個優秀的騎手會立刻把它當成獨輪車來騎,而不是直接癱倒在地。我們的系統也應該具備這種能力。
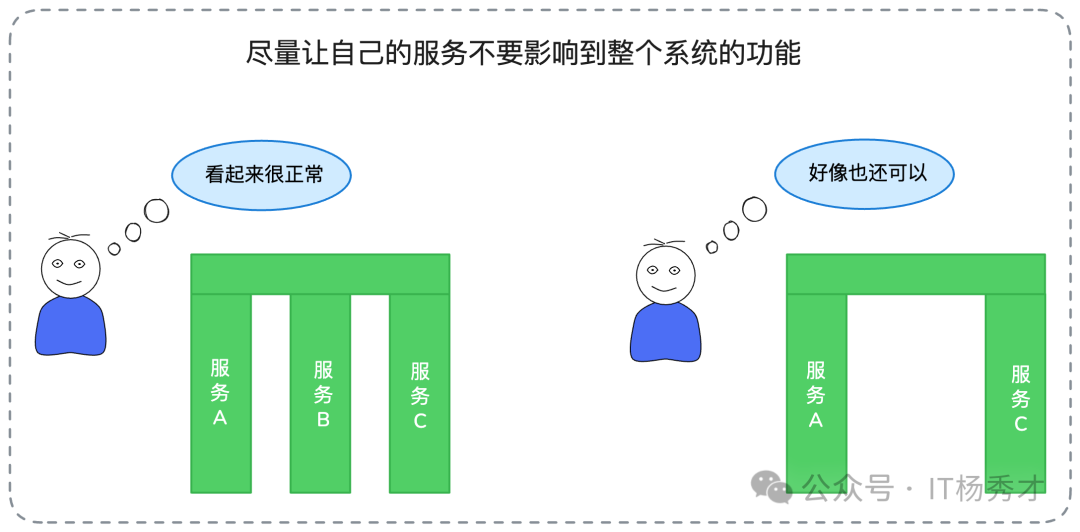
系統中的故障源多種多樣,可能來自你的服務本身、你依賴的其他服務,也可能來自底層的硬件和軟件基礎設施。在面試中,最重要的是描述如何保證你自己的服務在遇到故障時,不會拖垮整個系統。
其次,你需要考慮當軟件基礎設施(如Redis、MySQL、消息隊列)出問題時,你的服務該如何自處。這里主要有兩個層面的思考:
- 采用高可用方案:在公司內部,優先使用基礎設施的高可用部署方案。例如,使用Redis Cluster或云廠商提供的多可用區Redis實例,而不是單機Redis。
- 設計兜底容錯手段:做好最壞的打算。比如,我們之前討論過,如果Redis集群整體崩潰,你的服務可以通過限流來保護后端的數據庫不被瞬間涌入的流量打垮,保證核心功能可用。
至于硬件故障和第三方供應商故障,除了上一講提到的特殊場景外,在常規面試中出現頻率較低,我們在此不作過多展開。容錯設計的核心在于接受不完美,但無論你怎么容錯,故障終究還是會發生。當它真的發生時,我們就需要第二個原則來發揮作用。
1.2 故障域隔離 - 將火勢控制在最小范圍
限制故障影響范圍,或者說“縮小爆炸半徑”,指的是萬一故障真的發生了,我們要盡一切可能減輕它所帶來的負面影響。這個影響范圍可以從三個維度來考量:造成的業務損失更小、被影響的用戶數量更少、被波及的其他關聯組件更少。
而限制影響范圍的最佳策略,就是隔離。微服務架構本身就是一種隔離思想的體現,它將一個復雜的單體系統,按業務領域劃分成多個獨立的服務。在服務內部,我們還可以進一步細分核心模塊與非核心模塊、核心服務與非核心服務,盡可能降低它們之間的耦合和相互影響。
然而,在實踐中,想要做到徹底的隔離,通常面臨兩大現實難題:
- 服務間的強依賴:這種依賴一部分源于業務邏輯本身的復雜性,另一部分則源于不合理的架構設計。我們可以通過優化設計來解耦(比如后面會提到的異步化改造),但不可能做到完全沒有依賴。
- 共享基礎設施:理論上,只要資金允許,我們可以為每一個服務都提供一套完全獨立的數據庫、緩存和消息隊列。但現實是,大部分公司出于成本考慮,連多部署一套Redis集群都可能猶豫再三。因此,我們經常聽到某某公司因為一個非核心業務的錯誤操作,拖垮了共享的數據庫,導致全站核心業務崩潰的慘痛事故。
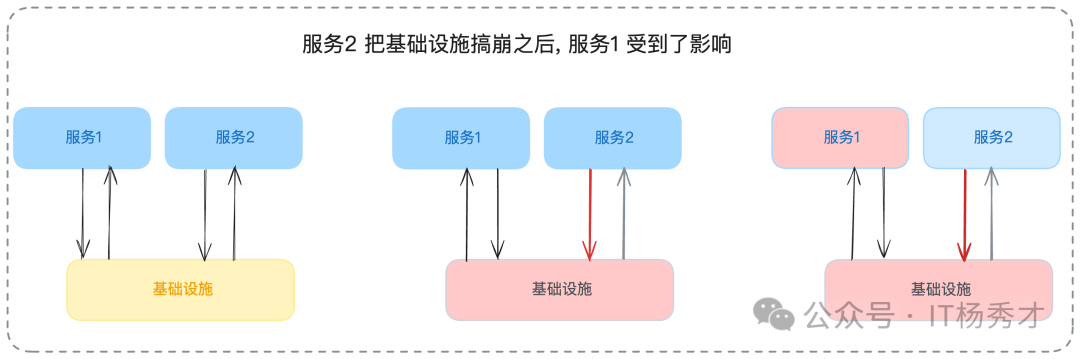
在做好了隔離,限制了故障影響范圍之后,下一步就是如何快速地從故障中恢復。
1.3 快速響應 - 發現與恢復的速度之戰
快速發現,強調的是建立一套完備的、全方位的觀測(Observability)和告警(Alerting)系統。觀測的對象不僅包括服務本身,更要覆蓋它所依賴的各種基礎設施和第三方服務。尤其是在核心業務鏈路上的每一個依賴點,都需要進行無死角的觀測。而沒有告警的觀測是沒有靈魂的,設置合理、精準、分級的告警,是快速發現問題的前提。
快速恢復,則旨在盡可能縮短服務的不可用時間(MTTR - Mean Time To Recover)。但這與其說是一個純粹的工程技術問題,不如說是一個組織建設和自動化的問題。它要求每個技術團隊都需要有24小時的On-Call(值班)機制。但更深層次的挑戰是,你不可能要求每一個值班人員都對組內所有項目的技術細節了如指掌。很多時候,告警響了,值班人員卻不知道如何處理,或者不敢處理。
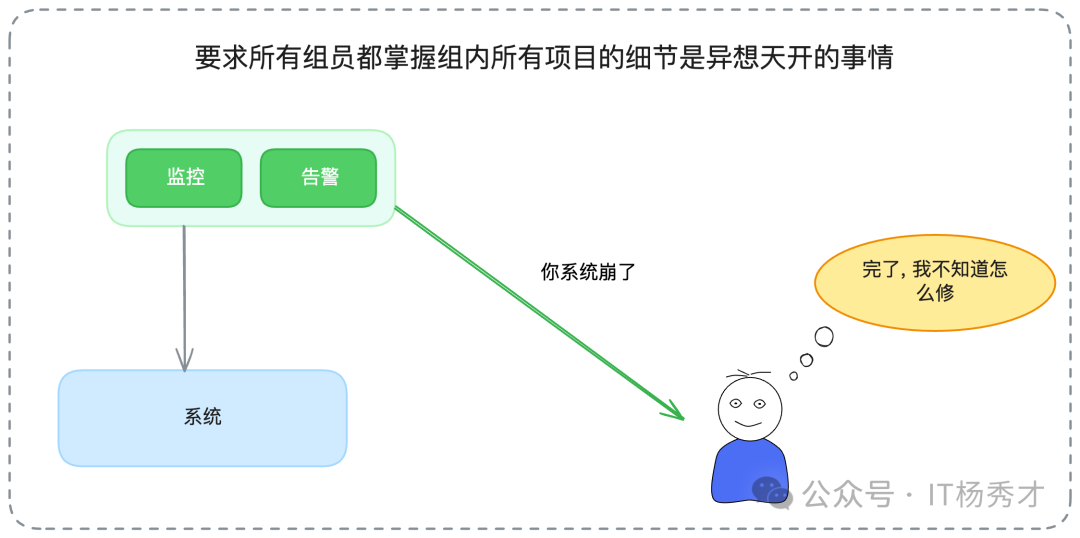
因此,要想真正做到快速修復,不能僅僅依賴于研發人員的個人能力和自覺性,而必須依賴于自動化的故障處理機制。這一點我們稍后會詳細介紹。
1.4 規范化變更 - 敬畏每一次上線
統計數據表明,線上絕大多數的故障都是由“變更”引起的。因此,規范變更流程,指的是任何人都不能隨意地發布新版本,也不能隨意地修改生產環境的配置。任何一個變更,都必須經過嚴格的審查(Review),并準備好詳盡的回滾預案。
在實踐中,我們最害怕的場景莫過于:系統原本運行得好好的,但為了修復一個非緊急的Bug或者上線一個小功能,在沒有充分測試的情況下就匆忙發布,結果不僅老問題沒解決,還引入了新的、更嚴重的問題,導致系統崩潰。
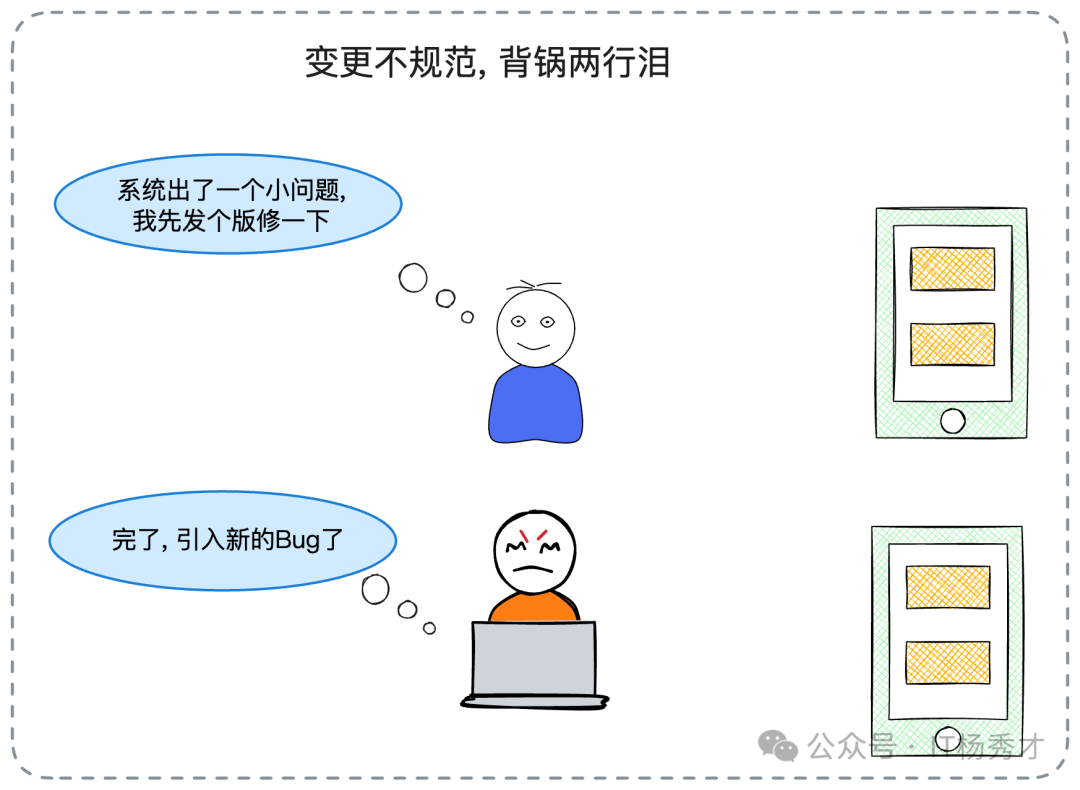
因此,建立一套完善的變更流程,是大幅提升系統可用性的關鍵舉措。但這和快速修復一樣,很大程度上也是一個組織管理和文化建設的問題。
2. 面試攻略
2.1 如何打造你的高可用故事線
在面試前,你需要圍繞你最熟悉的項目,準備一個從前端到后端、全方位、系統性的高可用方案。你需要仔細思考并能清晰闡述以下幾個環節:
- 入口防護:面向前端用戶的接口,是否有限流、防刷等措施,以防止惡意攻擊者將系統搞垮?
- 依賴高可用:你所依賴的第三方組件,包括緩存(Redis)、數據庫(MySQL)、消息隊列(Kafka)等,是否都采用了高可用的部署方案?
- 依賴故障容錯:如果你依賴的某個第三方組件(如Redis)整體崩潰了,你維護的服務會發生什么?整個系統是否還能對外提供有損服務?
- 服務間治理:你的所有服務之間,是否選擇了合適的負載均衡算法?是否全面實施了熔斷、降級、限流和超時控制等治理措施?
- 流程規范:你所在公司的上線流程、配置變更流程是怎樣的?你認為這些流程對系統可用性產生了哪些影響?
接下來,我將為你提供一套非常全面的高可用改造話術模板。你要做的,就是根據你的真實項目經歷,對這套模板進行個性化的改造,并用你自己的語言重新組織。
我在這里使用的都是一些比較普適的例子,這意味著即使你在中小型企業,也能找到可以借鑒的地方。但如果你在頭部大廠,有機會接觸到像全鏈路壓測、混沌工程、故障演練等更高級的高可用方案,你應該優先使用那些更亮眼的例子。
強烈建議你在面試前,將整個故事線寫下來并反復演練。面試講究的是有備無患,千萬不要寄希望于自己的臨場發揮。
最佳的面試策略,就是在自我介紹時就主動拋出引子,例如提到自己在“高可用微服務架構”方面的豐富經驗,然后在介紹項目時,著重展示你在入職后,是如何大幅度提高了系統的可用性。之后,面試官大概率會順著你的話,詳細追問這個項目以及你是如何做的。這時,你就可以從容地展開下面的故事線了。
故事線構建整個思路可以拆解成五個步驟:
發現問題 -> 規劃方案 -> 落地實施 -> 成果展示 -> 持續改進
并且通過“發現問題”和“取得效果”這兩個環節的前后對比,來有力地凸顯你在這個過程中的核心作用和價值。
2.1.1 第一步:發現問題(描繪“過去時”)
這個部分由“項目的核心挑戰”、“挑戰的具體體現”和“問題的根源分析”三部分組成。
“我之前負責的XX業務,是我們公司的核心變現業務,因此它的核心挑戰就是必須保證極高的可用性。但在我剛入職的時候,我發現這個系統的可用性是比較低的,穩定性問題頻發。舉個例子,我入職的第一個月,就經歷了一次比較嚴重的線上故障:當時另一個業務組突然上線了一個新功能,里面包含了大量的Redis大Key操作,導致我們共享的Redis集群響應變得非常慢,最終拖垮了我們的核心服務,造成了長時間的業務中斷。”
“這次故障之后,我牽頭做了一次深入的復盤和調研。我總結下來,系統可用性之所以不高,主要有三個根源性的原因:”
- “首先,是缺乏有效的監控和告警。 這導致我們很多時候都是‘瞎子’,難以在第一時間發現問題;即便發現了,也因為信息不足,難以快速定位問題;最終導致難以高效地解決問題。”
- “其次,是服務治理體系的缺失。 服務之間調用混亂,缺乏熔斷、限流等保護機制,導致任何一個非核心服務出現故障,都可能像推倒多米諾骨牌一樣,引發整個系統的雪崩。”
- “最后,是缺乏合理的變更流程。 我們每次復盤線上事故時,回過頭看,都覺得如果當時能有一個更嚴謹的上線和變更流程,那么大部分事故其實都是可以避免的。”
2.1.2 第二步:規劃方案(展現“藍圖”)
這里有一個常見的誤區:你在現實中可能確實做過類似的事情,但往往是“東一榔頭,西一棒槌”,缺乏系統性規劃。但在面試時,你必須將這些零散的工作,組織成一個非常有條理、有計劃的整體方案。
你要給面試官留下的印象,不僅僅是“你能解決問題”,更是“你能有章法、有策略地解決復雜問題”。
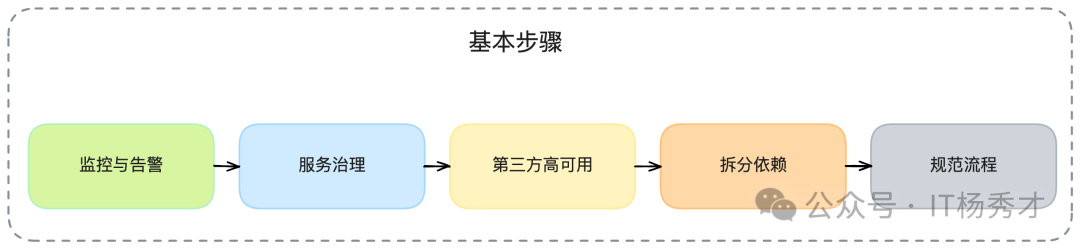
針對上面分析出的這幾個具體痛點,我制定了一套分階段、可落地的可用性改進計劃,主要分成了以下幾個步驟:
- “第一步,補齊短板:引入全方位的監控與告警。 這是所有工作的基礎,目標是讓我們具備快速發現和定位問題的能力。”
- “第二步,構建防線:引入全套的服務治理措施。 這一步是為了提高服務本身的健壯性,并有效隔離不同服務間的故障影響。”
- “第三步,加固地基:為所有第三方依賴引入高可用方案。 這一步是為了從根源上減少由外部依賴不穩所帶來的風險。”
- “第四步,核心隔離:拆分核心業務與非核心業務的共同依賴。 這一步是為了進一步提高核心業務的可用性,確保在極端情況下,核心功能不受非核心業務的拖累。”
- “第五步,規范流程:推動建立標準化的變更流程。 這一步是為了從制度上,降低因人為變更而引入Bug的可能性。”
2.1.3 第三步:落地實施(講述“進行時”的挑戰與思考)
接下來,你需要詳細講述方案的落地過程。在講述時,要補充技術細節,同時也可以巧妙地摻雜一些在落地過程中遇到的真實痛點和阻力,這會讓你的陳述顯得更加真實可信。
“在第一個步驟中,就監控告警來說,我們不僅為所有業務服務都添加了核心業務指標的監控和告警,還為所有的第三方依賴,比如數據庫、Redis和消息隊列,都增加了基礎設施層面的監控。在告警方面,我們綜合考慮了告警的頻率、分級和通知方式,并不斷優化告警信息的內容,確保信息的充足性,以減少誤報和“告警疲勞”。這個過程本身技術難度不高,但非常瑣碎,需要我們一個鏈路一個鏈路地去梳理,一個業務一個業務地去查漏補缺。”
“在第二個步驟中,服務治理的范圍比較廣,我主導引入了包括限流、熔斷、降級、超時控制、線程池隔離在內的一整套方案。”
“第三個步驟在推行時,遇到了一些阻力。主要是因為大部分第三方依賴的高可用方案,都需要額外的資源投入。比如,我們最開始使用的Redis就是一個單機實例,后面我推動改造成Redis Cluster時,就需要申請更多的機器實例,這需要和領導以及運維團隊進行多輪的溝通和成本效益分析。”
“第四個步驟,拆分共同依賴,也是執行得不徹底。我們目前的策略是,所有新上線的核心業務,都會使用獨立的數據庫和Redis集群。但是對于一些歷史悠久的老核心業務,由于改造成本巨大,目前還是維持原狀,共享基礎設施。”
你可能發現了,我在談到第三和第四點時,都坦誠地表示執行得并不完美。這會給面試官留下不好的印象嗎?
恰恰相反。因為我陳述的,基本都是任何一個工程師在真實工作中都會遇到的困難,面試官能夠理解。另一方面,一個方案不可能十全十美,適當地暴露一些問題和妥協,能夠極大地增強你整個故事的說服力。
“第五個步驟則有些特殊,它取決于我在公司的角色和影響力。在我還是一個普通工程師的時候,我主要是通過技術分享、故障復盤等方式,多次向領導和團隊建議建立更規范的流程。后來,隨著我在團隊中承擔的責任越來越重,我就直接推動并和大家一起制定了新的上線規范,包括詳細的上線Checklist、Code Review流程以及必須具備的回滾計劃等等。”
2.1.4 第四步:取得效果(量化“完成時”的價值)
既然我們討論的是可用性,那么你取得的效果,最直接的體現就是可用性指標的提升。一般來說,我建議你說可用性達到了“3個9”,而不是“4-5個9”,因為后者對于絕大多數系統來說,都有些過于夸張了。
“經過這一系列組合拳的改進之后,我所維護的核心服務的可用性,從原來估算不足‘兩個9’,穩定提升到了‘三個9’以上。最直觀的感受是,半夜被電話告警叫醒的次數顯著減少了。”
或者,你也可以用一種更幽默的方式來回答
“現在我們團隊的Bug復盤會上,我已經不再是那個經常挨罵的人了,更多時候是坐在下面,看著別人挨罵了(笑)。”
“同時,你還可以補充一下,系統中超出你影響力范圍的部分,可用性依然有待提升:”
“不過,我的服務還依賴于一些其他團隊提供的服務,而他們的服務可用性還是比較差。對此,我這邊只能是盡量做好容錯,比如在他們服務不可用時,提供有損服務。后續要想進一步提高我們業務的整體可用性,還是得推動他們一起去提升。”
2.1.5 第五步:后續改進(展望“將來時”)
最后,你需要補充一下你對未來的改進計劃。一般來說,改進計劃都是針對現有方案的缺點和不足。
“目前,我的服務,尤其是一些歷史遺留的老服務,相互之間還是在共享一些基礎設施。比如,一個出問題就很容易牽連其他服務。所以我后續的一個重要規劃,就是進一步將這些老服務進行解耦,特別是要推動將它們依賴的數據庫實例進行拆分,省得因為別的業務組一條慢SQL,就牽連到我的核心業務。大家一起用一個東西,出了事,有時候連責任都很難界定清楚。”
講述改進方案有一個好處,就是它還沒有實施,你可以大膽地講,什么高大上、什么代表了未來的方向,你就可以講什么,以此來展現你的技術視野。
2.2 亮點方案:從優秀到卓越的進階策略
掌握了上述的面試基本思路,你基本上就能給面試官留下一個相當不錯的印象了。在這里,我再額外補充一些可以讓你脫穎而出的亮點方案,你可以選擇其中一兩個,來進一步強化你在面試官心目中的專家形象。
2.2.1 異步化/解耦 - “少做不錯,不做不錯”
這個方案的核心思想是:仔細梳理你的業務流程,將其拆分成“必須同步執行成功的關鍵路徑”和“可以異步執行的非關鍵路徑”。
比如,在一個簡單的創建訂單的場景中,“扣減庫存”、“創建訂單”、“調用支付”這幾個步驟,是必須同步執行成功的核心路徑。但是,另外一些步驟,比如“給用戶發一封下單成功的郵件通知”、“為用戶增加本次購物的積分”,這些就屬于非關鍵路徑,它們允許延遲,甚至單次失敗后重試。
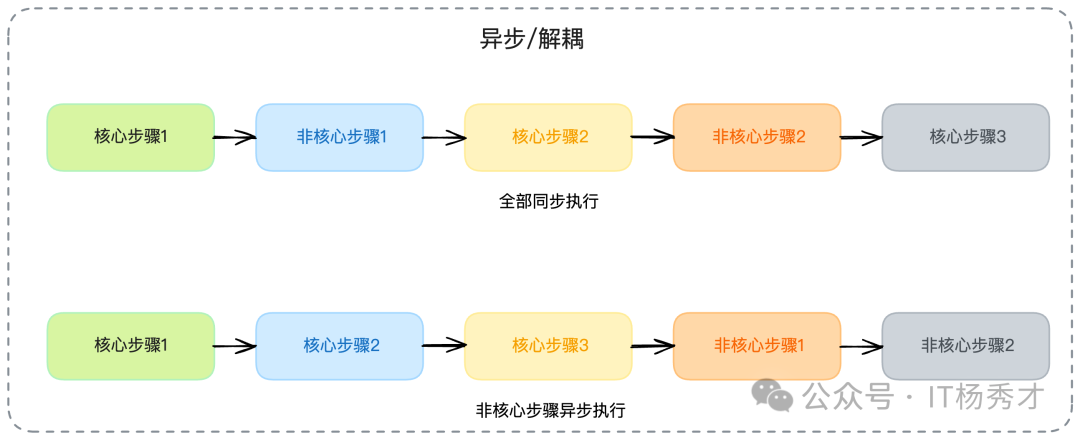
因此,在設計高可用微服務時,有一個重要的原則:能夠異步執行的,絕對要異步執行;能夠解耦的,必須想辦法解耦。
這種理念,用一句樸素的話來形容就是:“多做多錯,少做少錯,不做不錯”。你同步執行的步驟越少,你的主流程就越穩定,可用性自然就越高。
“在完成了基礎的服務治理之后,我還全面推行了核心業務的異步化和解耦改造。我將核心業務的邏輯,與產品經理一起,一個一個地重新梳理,最終將所有核心業務流程中,能夠異步執行的步驟,全部改造成了異步執行。這樣一來,我的業務中,需要同步執行的關鍵步驟就大大減少了。而后續異步執行的動作,即便失敗了,我們也可以通過消息隊列的重試機制來保證最終成功,所以整個系統的可用性都得到了大幅度的提升。”
“具體的實現方式是,在核心的A步驟成功執行之后,我們不再直接調用B步驟,而是發送一條消息到消息隊列。然后由另一個獨立的消費服務來監聽消息,并執行B步驟。”
2.2.2 自動化故障處理 - 邁向“四個9”的關鍵
嚴格來說,我們前面提到的熔斷、降級、限流,也屬于自動化的故障處理。但我這里說的是,構建一個獨立的、更高維度的系統,來自動處理業務系統發生的各類故障。
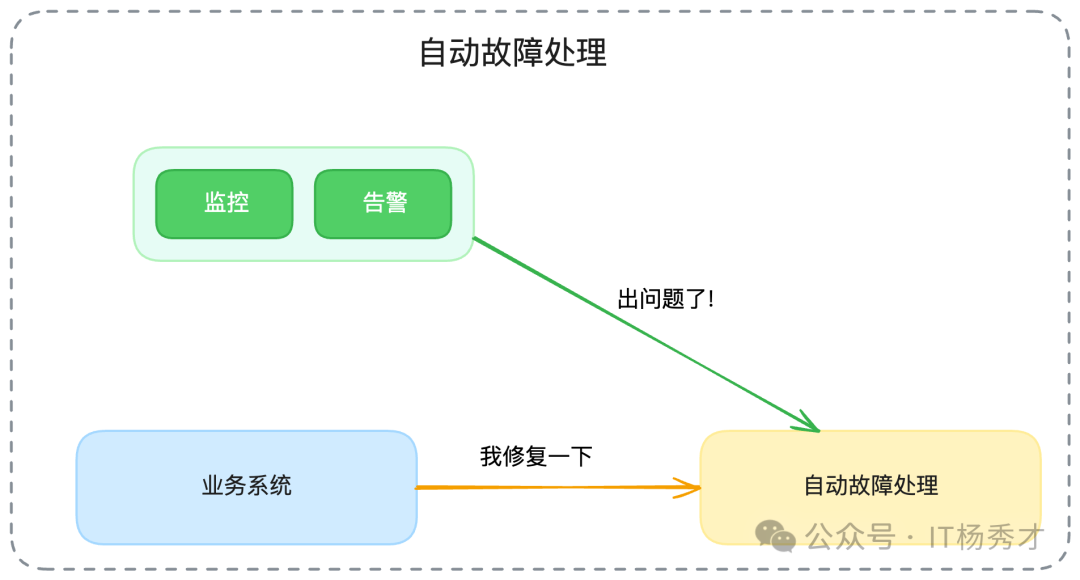
一個線上問題,從被發現,到找到臨時應對方案,再到付諸實施,一不留神一個小時就過去了。所以在可用性達到“三個9”以后,如果你還想進一步提升,就要么想辦法降低事故發生的概率,要么想辦法無限提高故障恢復的速度。
人本身不可能做到24小時精神高度緊張地待命,也不可能對所有系統細節都了如指掌。所以,自動化故障處理機制,是通往“四個9”甚至更高可用性的必經之路。
這里,我給你一個最常見的例子:微服務集群自動擴容。它是指,對整個微服務集群的負載進行實時監控,如果發現集群整體負載過高,就自動增加新的服務實例。
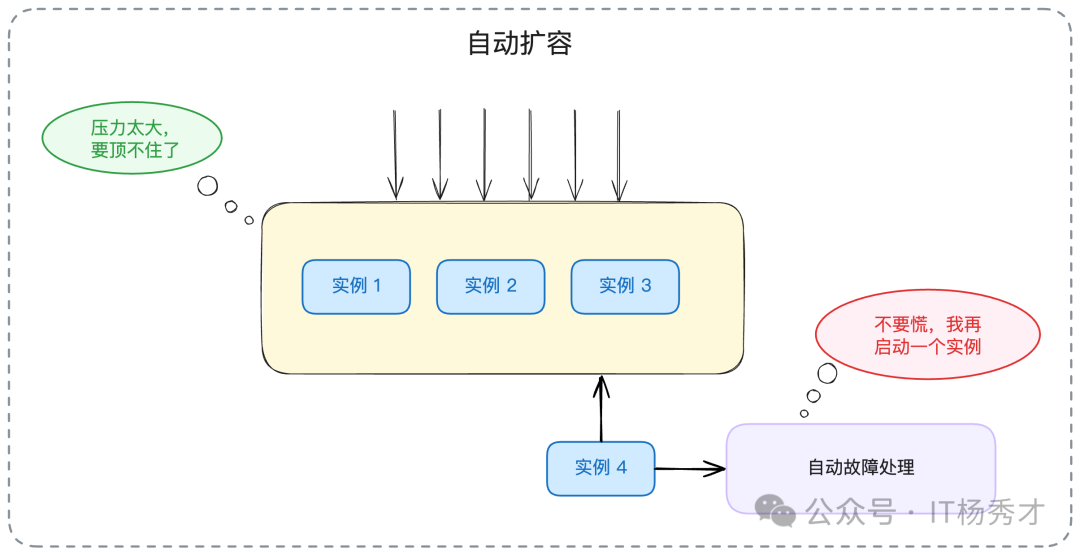
“為了進一步提高整個集群服務的可用性和彈性,我跟運維團隊進行了密切合作,共同設計并實現了服務的自動擴容機制。我們允許不同的業務方,根據自己服務的特性,設置不同的擴容觸發條件。比如,我為我的核心服務設置了‘CPU使用率’和‘內存使用率’兩個組合指標。如果我這個服務的所有節點,在持續一段時間內,平均CPU使用率都超過了90%,那么就會自動觸發擴容,每次擴容會新增一個節點,直到負載降到安全水位以下。”
這里我用的例子,決策理由也比較簡單。CPU使用率長期處于高位,基本上代表節點處于高負載狀態。并且,我特意強調了是“集群里面的所有節點都超過了某個指標”,這是為了防止因為負載均衡不均,導致單一節點過載而引起不必要的擴容。
還有一些常見的自動化故障處理方案,你可以參考:
- 自動修復數據:通過定時任務,比對不同系統或表中的數據,如果發現數據不一致,就發出告警,并同時觸發預設的自動修復程序。
- 自動補發消息:也是通過定時任務等機制,來掃描業務狀態,如果發現某個業務流程因為消息丟失而卡住了,就觸發告警,并自動進行消息補發。
但凡你的業務中,存在大量需要人工介入處理的數據不一致或流程中斷問題,你都應該思考,是否可以設計一個自動化的恢復程序,去自動地發現和修復它們。
3. 小結
這篇文章我們系統性地探討了如何保證微服務應用高可用的綜合性方案。當然,這里給出的整個話術和方案,是一個“框架”,面試的時候你需要根據你的實際項目經驗,來填充血肉。業界有非常多的高可用方案,你可以多學習幾種,將它們內化成你自己的知識體系,并整合進你的面試方案里。
同時,你也不需要掌握全部的高可用方案,因為實在太多,學不過來。你只需要重點掌握幾種,然后在面試的時候,學會主動引導和把控面試的節奏,將面試官的提問,巧妙地限制在你所了解和擅長的那幾種方案上,就足夠了。











)



)
使用循環QSC和QKD的量子區塊鏈架構,提高交易安全性和透明度)


