為什么要講和學習決策樹呢?主要是決策樹(包括隨機森林算法)不需要數據的預處理。現實世界的數據往往“臟亂差”,決策樹讓你在數據準備上可以少花很多功夫,快速上手,用起來非常的“省心”。總之,決策樹是機器學習領域里最直觀易懂、解釋性最強、應用最廣泛的基礎模型之一,學會它,你就掌握了一把打開預測分析大門、理解更高級模型的金鑰匙。
下面開始我們的學習吧。
目錄
一、什么是決策樹
二、具體程序與不同參數運行效果對比
三、小結與建議
一、什么是決策樹
決策樹是一種在分類與回歸中都有非常廣泛應用的算法。它的原理是通過對一系列問題進行if/else 的推導,最終實現決策。學過C語言的知道,if/else使用來做判斷的,決策樹就是對樣本數據特征做一些列的判斷來實現決策的。
舉個例子: 假設要識別斯嘉麗· 約翰遜、泰勒斯威夫特、吳彥祖、威爾·史密斯4 個人中的一個,則決策樹的判斷流程為:
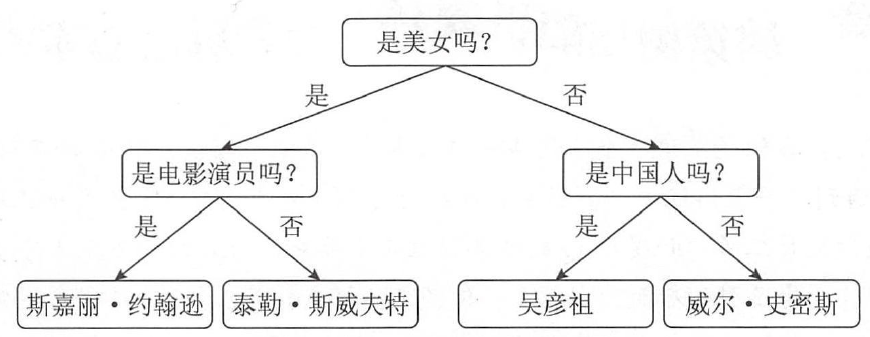
上圖中最終的4 個節點,也就是4 個人物的名字,被稱為決策樹的樹葉。例子中的這棵決策樹只有4 片樹葉,所以通過手動的方式就可以進行建模。但是如果樣本的特征特別多, 就不得不使用機器學習的辦法來進行建模了。


復制集和分片集群)





 視頻教程 - 微博輿情數據可視化分析-熱詞情感趨勢柱狀圖)


 與 :where ():簡化復雜選擇器的 “語法糖”)


——圖像本質、數字矩陣、RGB + 基本操作(實戰一))




信息)