1、概念
MongoDB復制集的主要意義在于實現服務高可用,類似于Redis中的哨兵模式
2、功能
1. 數據寫入主節點時將數據復制到另一個副本節點上
2. 主節點發生故障時自動選舉出一個新的替代節點
在實現高可用的同時,復制集實現了其他幾個作用
數據分發:將數據從一個區域復制到另一個區域,減少另一個區域的讀延遲
讀寫分離:不同類型的壓力分別在不同的節點上執行
異地容災:在數據中心故障時快速切換到異地
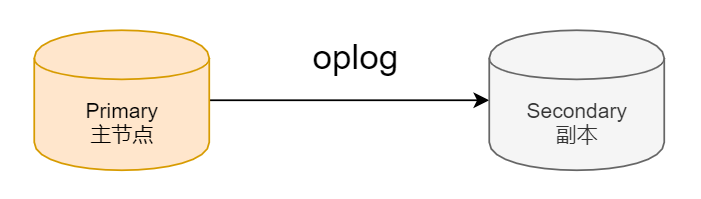
1、典型復制集結構
一個典型的復制集由三個或三個以上具有投票權的節點組成
其中一個主節點(Primary):接收寫入操作,讀操作和選舉時投票
兩個或多個從節點(Secondary):復制主節點上的新數據和選舉時投票
2、數據是如何復制的?
當一個修改操作,無論是插入,更新或刪除,到達主節點時,它對數據的操作將被記錄下來(經過一些必要的轉換)。這些記錄稱為oplog
從節點通過從主節點上不斷獲取新進入主節點的oplog,并在自己的數據上回放,以此保持跟主節點的數據一致。
1、什么是oplog
- MongoDB oplog 是 Local 庫下的一個集合,用來保存寫操作所產生的增量日志(類似于 MySQL 中 的 Binlog)。
- 它是一個 Capped Collection(固定集合),即超出配置的最大值后,會自動刪除最老的歷史數據,MongoDB 針對 oplog 的刪除有特殊優化,以提升刪除效率。
- 主節點產生新的 oplog Entry,從節點通過復制 oplog 并應用來保持和主節點的狀態一致;
2、查看oplog
use local
db.oplog.rs.find().sort({$natural:-1}).pretty()local.system.replset:用來記錄當前復制集的成員。
local.startup_log:用來記錄本地數據庫的啟動日志信息。
local.replset.minvalid:用來記錄復制集的跟蹤信息,如初始化同步需要的字段。
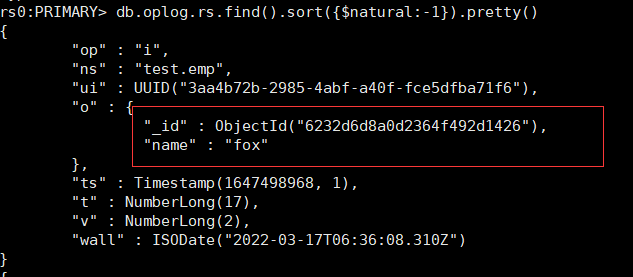
- ts: 操作時間,當前timestamp + 計數器,計數器每秒都被重置
- v:oplog版本信息
- op:操作類型:
- i:插?操作
- u:更新操作
- d:刪除操作
- c:執?命令(如createDatabase,dropDatabase)
- n:空操作,特殊?途
- ns:操作針對的集合
- o:操作內容
- o2:操作查詢條件,僅update操作包含該字段
ts字段描述了oplog產生的時間戳,可稱之為optime。optime是備節點實現增量日志同步的關鍵,它保證了oplog是節點有序的,其由兩部分組成:
- 當前的系統時間,即UNIX時間至現在的秒數,32位。
- 整數計時器,不同時間值會將計數器進行重置,32位。
optime屬于BSON的Timestamp類型,這個類型一般在MongoDB內部使用。既然oplog保證了節點級有序,那么備節點便可以通過輪詢的方式進行拉取,這里會用到可持續追蹤的游標(tailable cursor)技術。
3、oplog集合的大小
oplog集合的大小可以通過參數replication.oplogSizeMB設置,對于64位系統來說,oplog的默認值為:
plogSizeMB = min(磁盤可用空間*5%,50GB)對于大多數業務場景來說,很難在一開始評估出一個合適的oplogSize,所幸的是MongoDB在4.0版本之后提供了replSetResizeOplog命令,可以實現動態修改oplogSize而不需要重啟服務器。
# 將復制集成員的oplog大小修改為60g 指定大小必須大于990M
db.adminCommand({replSetResizeOplog: 1, size: 60000})# 查看oplog大小
use local
db.oplog.rs.stats().maxSize4、冪等性
每一條oplog記錄都描述了一次數據的原子性變更,對于oplog來說,必須保證是冪等性的。
也就是說,對于同一個oplog,無論進行多少次回放操作,數據的最終狀態都會保持不變。
某文檔x字段當前值為100,用戶向Primary發送一條{$inc: {x: 1}},記錄oplog時會轉化為一條{$set: {x: 101}的操作,才能保證冪等性。
5、oplog的寫入被放大,導致同步追不上——大數組更新
當數組非常大時,對數組的一個小更新,可能就需要把整個數組的內容記錄到oplog里,我遇到一個實際的生產環境案例,用戶的文檔內包含一個很大的數組字段,1000個元素總大小在64KB左右,這個數組里的元素按時間反序存儲,新插入的元素會放到數組的最前面($position: 0),然后保留數組的前1000個元素($slice: 1000)。
上述場景導致,Primary上的每次往數組里插入一個新元素(請求大概幾百字節),oplog里就要記錄整個數組的內容,Secondary同步時會拉取oplog并重放,Primary到Secondary同步oplog的流量是客戶端到Primary網絡流量的上百倍,導致主備間網卡流量跑滿,而且由于oplog的量太大,舊的內容很快被刪除掉,最終導致Secondary追不上,轉換為RECOVERING狀態。
在文檔里使用數組時,一定得注意上述問題,避免數組的更新導致同步開銷被無限放大的問題。使用數組時,盡量注意:
- 數組的元素個數不要太多,總的大小也不要太大
- 盡量避免對數組進行更新操作
- 如果一定要更新,盡量只在尾部插入元素,復雜的邏輯可以考慮在業務層面上來支持
3、通過選舉完成故障恢復
具有投票權的節點之間兩兩互相發送心跳;
當5次心跳未收到時判斷為節點失聯
如果失聯的是主機點,從節點會發起選舉,選出新的主節點
如果失聯的是從節點則不會產生新的選舉
選舉基于RAFT一致性算法實現,選舉成功的必要條件是大多數投票節點存活
復制集中最多可以有50個節點,但具有投票權的節點最多7個
4、影響選舉的因素
整個集群必須有大多數節點存活,被選舉為主節點的節點必須:
1.能夠與多數節點建立連接
2.具有較新的oplog
3.具有較高的優先級(如果有配置)
5、復制集節點有以下的選配項
(1)是否具有投票權(v 參數)
有則參與投票
(2)優先級(priority參數)
優先級越高的節點越優先成為主節點。優先級為0的節點無法成為主節點,默認值為1。
(3)隱藏(hidden參數)
復制數據,但對應用不可見。隱藏節點可以具有投票權,但優先級必須為0
(4)延遲(slaveDelay參數)
復制 n 秒之前的數據,保持與主節點的時間差,有點備份的意思
從節點不建立索引
6、復制集注意事項
硬件:
因為正常的復制集節點都有可能成為主節點,它們的地位是一樣的,因此硬件配置上必須一致
為了保證節點不會同時宕機,各節點的硬件必須具有獨立性。
軟件:
復制集各節點軟件版本必須一致,以避免出現不可預知的問題
增加節點不會增加系統寫性能
3、分片集群
每個分片本身就是一個復制集
將數據水平拆分到不同的服務器上
原因:
- 數據量突破單機瓶頸,數據量大,恢復很慢,不利于數據管理
- 并發量突破單機性能瓶頸
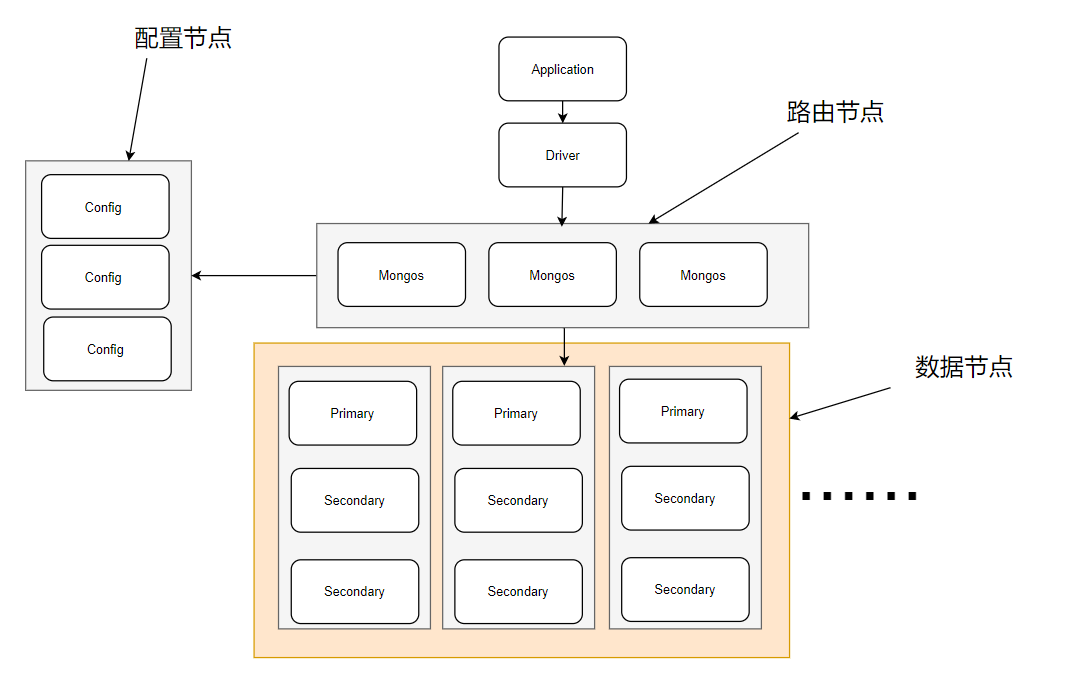
1、分片集群由一下幾部分組成
2、分片集群角色
1、路由節點
mongos提供集群單一入口,轉發應用端請求,選擇合適的數據節點進行讀寫,合并多個數據節點的返回。
無狀態,建議 mongos節點集群部署以提供高可用性。客戶請求應發給mongos,而不是分片服務器,當查詢包含分片鍵時,mongos將查詢發送到指定分片,否則,mongos將查詢發送到所有分片,并匯總所有查詢結果。
2、配置節點
就是普通的mongod進程, 建議以復制集部署,提供高可用。
提供集群元數據存儲分片數據分布的數據。主節點故障時,配置服務器進入只讀模式,只讀模式下,數據段分裂和集群平衡都不可執行。整個復制集故障時,分片集群不可用。
3、數據節點
以復制集為單位,橫向擴展最大1024分片,分片之間數據不重復,所有數據在一起才可以完整工作。
3、分片鍵
分片鍵是 MongoDB 中用于將數據分割成塊(Chunks)并分布到分片集群(Sharded Cluster)不同分片(Shard)上的一個或多個字段。選擇合適的分片鍵對于分片集群的性能和擴展性至關重要。
可以是單個字段, 也可以是復合字段。
1. 范圍分片
比如key的值從min~max,可以把數據進行范圍分片
2. hash 分片
通過 hash(key)進行數據分段
片鍵值用來將集合中的文檔劃分為數據段,片鍵必須對應一個索引或索引前綴(單鍵、復合鍵),可以使用片鍵的值或者片鍵值的哈希值進行分片
4、選擇片鍵
1. 片鍵值的范圍更廣(可以使用復合片鍵擴大范圍)
2. 片鍵值的分布更平衡(可使用復合片鍵平衡分布)
3. 片鍵值不要單向增大、減小(可使用哈希片鍵)
5、數據段的分裂
當數據段尺寸過大,或者包含過多文檔時,觸發數據段分裂
只有新增、更新文檔時才可能自動觸發數據段分裂,數據段分裂通過更新元數據來實現
6、集群的平衡
后臺運行的平衡器負責監視和調整集群的平衡,當最大和最小分片集之間的數據段數量相差過大時觸發,集群中添加或移除分片時也會自動觸發
7、分片集群特點
1.應用全透明
2.數據自動均衡
3.動態擴容,無需下線
8、數據回滾
由于復制延遲是不可避免的,這意味著主備節點之間的數據無法保持絕對的同步。當復制集中的主節點宕機時,備節點會重新選舉成為新的主節點。那么,當舊的主節點重新加入時,必須回滾掉之前的一些“臟日志數據”,以保證數據集與新的主節點一致。主備復制集合的差距越大,發生大量數據回滾的風險就越高。
對于寫入的業務數據來說,如果已經被復制到了復制集的大多數節點,則可以避免被回滾的風險。應用上可以通過設定更高的寫入級別(writeConcern:majority)來保證數據的持久性。這些由舊主節點回滾的數據會被寫到單獨的rollback目錄下,必要的情況下仍然可以恢復這些數據。
當rollback發生時,MongoDB將把rollback的數據以BSON格式存放到dbpath路徑下rollback文件夾中,BSON文件的命名格式如下:...bson
mongorestore --host 192.168.192:27018 --db test --collection emp -ufox -pfox
--authenticationDatabase=admin rollback/emp_rollback.bson9、同步源選擇
MongoDB是允許通過從節點進行復制的,這會發生在以下的情況中:
效果??:
所有從節點將直接與主節點同步
減少復制延遲
增加主節點負載
- 在settings.chainingAllowed開啟的情況下,備節點自動選擇一個最近的節點(ping命令時延最小)進行同步。settings.chainingAllowed選項默認是開啟的,也就是說默認情況下從節點并不一定會選擇主節點進行同步,這個副作用就是會帶來延遲的增加,你可以通過下面的操作進行關閉:
//將settings.chainingAllowed設置為false,強制從節點直接從主節點同步數據,可以降低同步延遲 cfg = rs.config() cfg.settings.chainingAllowed = false rs.reconfig(cfg)
- 使用replSetSyncFrom命令臨時更改當前節點的同步源,比如在初始化同步時將同步源指向從節點來降低對主節點的影響。
db.adminCommand( { replSetSyncFrom: "hostname:port" })





 視頻教程 - 微博輿情數據可視化分析-熱詞情感趨勢柱狀圖)


 與 :where ():簡化復雜選擇器的 “語法糖”)


——圖像本質、數字矩陣、RGB + 基本操作(實戰一))




信息)


