多模態大模型MLLMs 能夠處理高分辨率圖像、長視頻序列和冗長音頻輸入等復雜上下文,但自注意力機制的二次復雜度使得大量輸入 token 帶來了巨大的計算和內存需求。
如下圖,上:圖像、視頻和音頻數據類型可以在其表示維度上進行擴展,從
而導致 token 數量的相應增加。下:表現最佳的多模態大模型無法滿足
現實世界的需求,因為多模態輸入(尤其是視頻)的 token 數量遠遠超
過文本,并且大多數視覺 token 是冗余的。
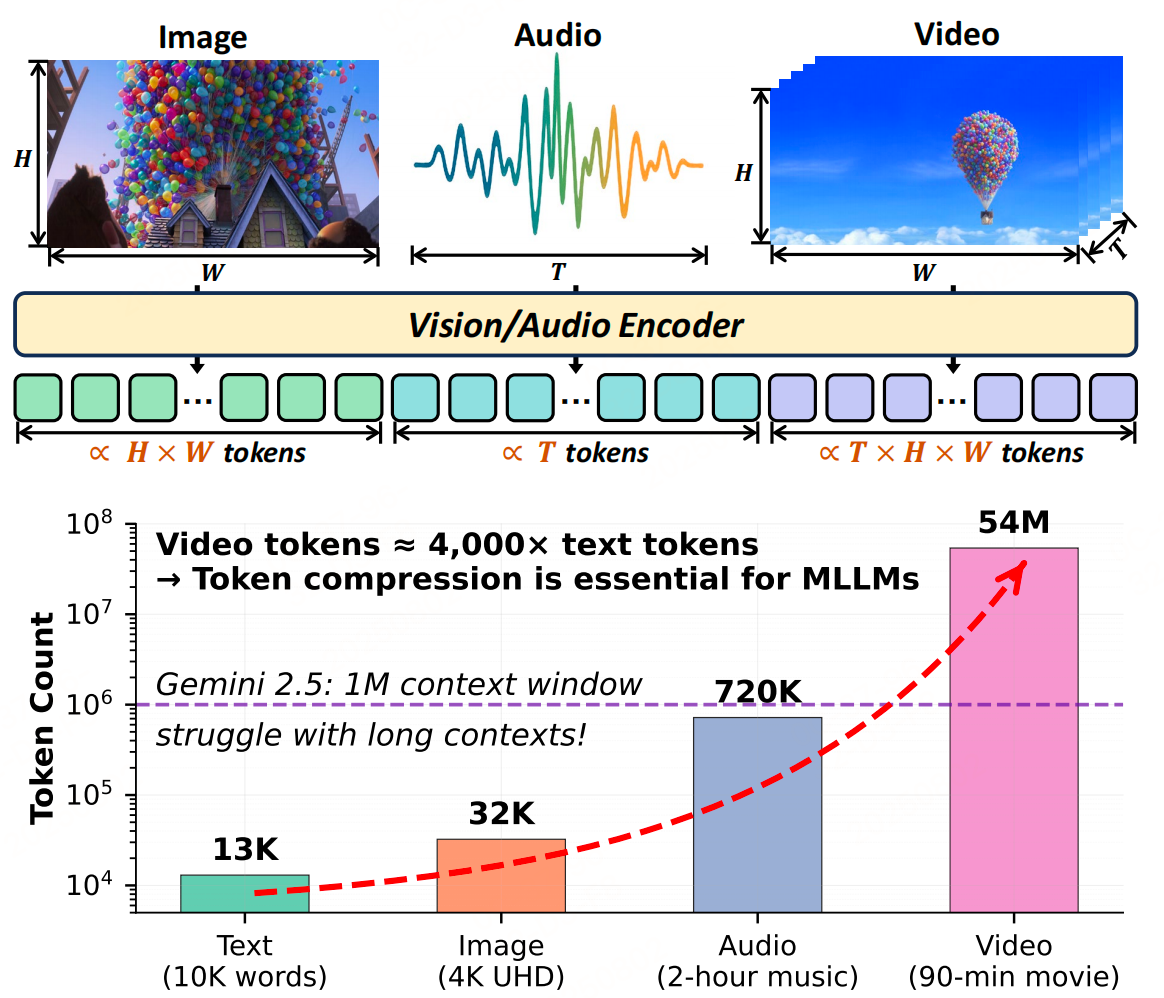
因此 token 壓縮對于解決這一限制至關重要。
一些概念
1、多模態結構
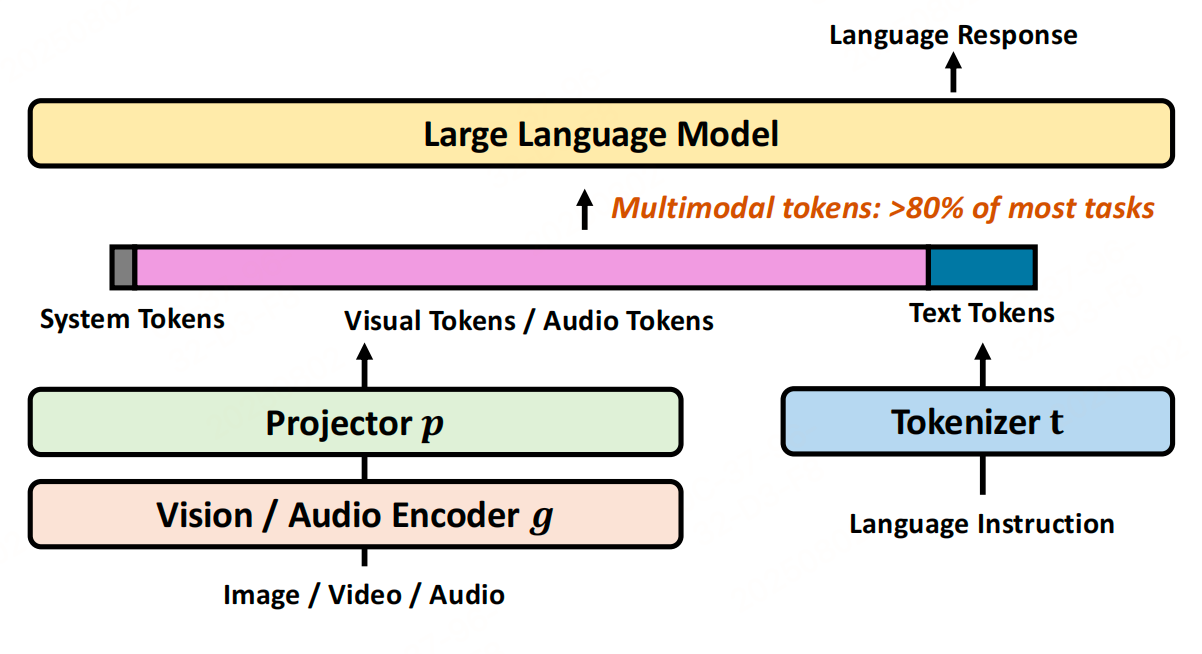
MLLMs通常框架由三個組件構成:
- 特定模態編碼器((g)):負責處理圖像、音頻等原始輸入,將高維數據壓縮為緊湊的語義嵌入序列(如圖像通過視覺編碼器轉化為視覺token,音頻通過音頻編碼器轉化為音頻token)。常用的視覺編碼器包括CLIP、SigLIP等,音頻編碼器包括Whisper、Audio-CLIP等。
- 投影器(連接器)模塊((P)):將編碼器輸出的嵌入映射到與語言模型(LLM)文本嵌入相同的潛在空間,使多模態數據能與文本指令融合。
- 大語言模型(LLM):接收投影后的多模態嵌入與文本提示嵌入的拼接序列,通過自回歸解碼生成響應。
2、大模型的token壓縮
MLLMs的核心通常基于文本大型語言模型(LLMs)微調而來,因此文本LLMs的token壓縮技術(常稱為“prompt壓縮”)是重要基礎。這些技術旨在處理長文本上下文(如整本書、代碼庫),方法包括:
- 自編碼器與摘要壓縮:如AutoCompressor將上下文壓縮為摘要向量,SentenceVAE用單個token表示句子。
- 選擇性修剪:如Selective Context通過自信息度量移除低信息token,LLMLingua系列通過層級修剪和語義密度排序減少token。
- 查詢引導過濾:如QUITO利用注意力分數篩選與查詢相關的token,AdaComp根據查詢復雜度動態提取關鍵信息。
- 概念蒸餾與遞歸框架:如Concept Distillation通過抽象意義表示(AMR)圖提煉核心概念,RCC通過遞歸融合生成分段摘要。
然而,文本壓縮技術難以直接應用于MLLMs,因為多模態數據(圖像、視頻、音頻)存在獨特的冗余模式(如空間相關性、時空連續性),需要專門的壓縮策略。
3、視覺Transformer的token壓縮
視覺Transformer(ViTs)的token壓縮技術為MLLMs的視覺token壓縮提供了借鑒,其核心是解決圖像的空間冗余(如相鄰patch的相似性、前景與背景的語義不平衡):
- 動態修剪:如DynamicViT、EViT通過注意力分數量化token相關性,修剪低顯著性token。
- token合并與學習:如ToMe通過相似性度量合并語義相近的token,TokenLearner通過學習的空間注意力生成緊湊token集。
- 蒸餾與跨模態過濾:如DeiT用輕量級“學生頭”從壓縮token子集預測標簽,MADTP利用跨模態對齊過濾token。
與MLLMs的差異:MLLMs不僅包含視覺token,還需處理文本token和更長的序列,因此其token壓縮面臨更復雜的挑戰,但ViTs的技術思路(如注意力引導修剪、相似性合并)更具參考價值。
下面來看下具體的token壓縮方法。
多模態token壓縮方法
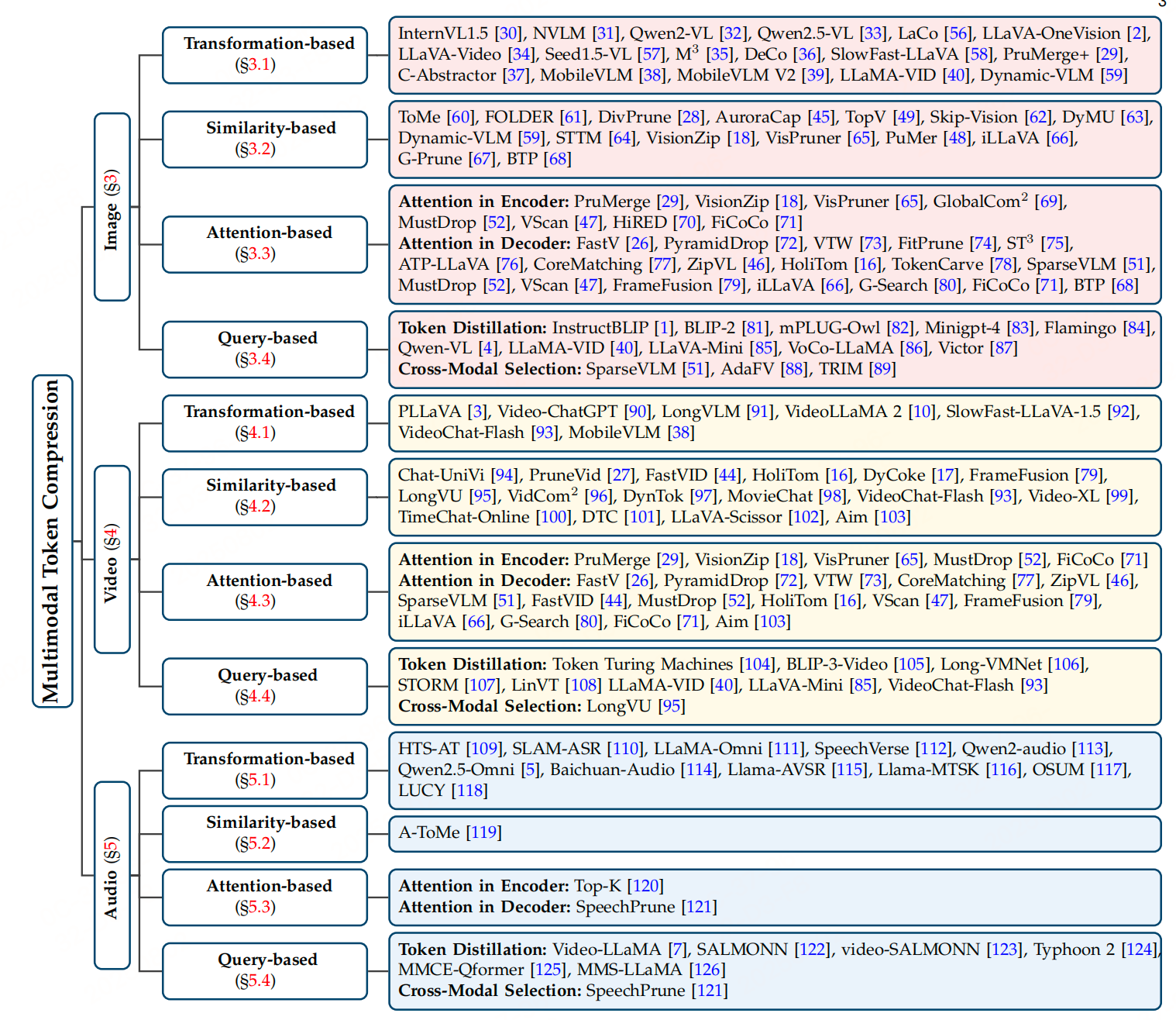
1、 以圖像為中心的Token壓縮
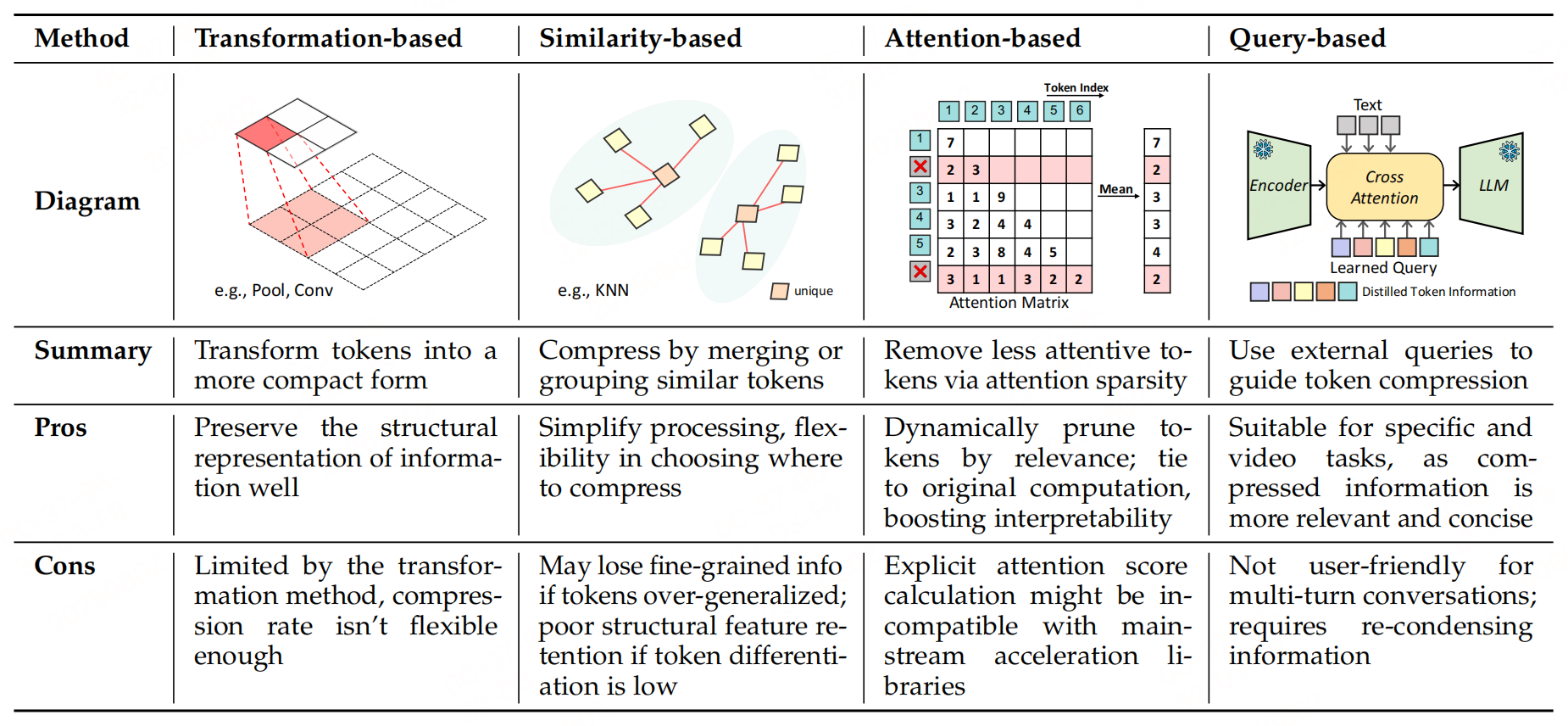
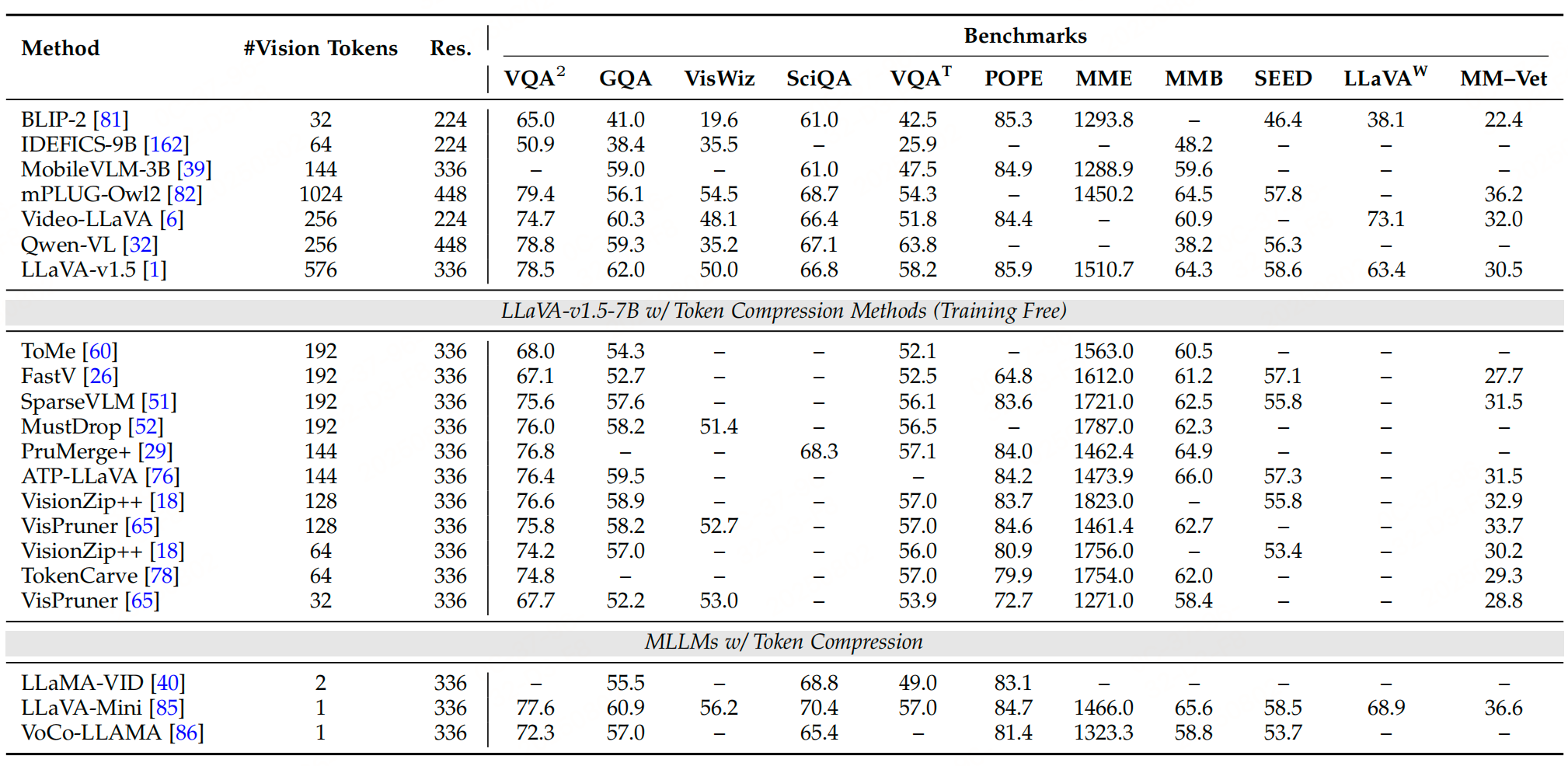
總結:
圖像中心的 token 壓縮方法針對空間冗余,從變換、相似性、注意力、查詢四個維度提出解決方案:
- 變換方法通過下采樣直接減少 token 數量,適合保留空間結構;
- 相似性方法合并語義重復 token,適合去除冗余;
- 注意力方法動態篩選高重要性 token,可解釋性強;
- 查詢方法聚焦任務相關信息,適合交互式場景。
下面具體看看。
1.1 基于Transformer的圖像中心壓縮
這類方法通過對圖像特征進行空間變換(如下采樣)來減少token數量,核心是利用圖像的空間結構特性,在保留關鍵信息的同時降低維度。主要包括以下四類操作:
-
像素重排(Pixel Unshuffle)
像素重排是像素洗牌(Pixel Shuffle)的逆操作,將高分辨率、低通道的特征圖轉換為低分辨率、高通道的特征圖,從而減少token數量:
H×W×D→Hr×Wr×(D?r2) H \times W \times D \to \frac{H}{r} \times \frac{W}{r} \times (D \cdot r^2) H×W×D→rH?×rW?×(D?r2)其中,H、WH、WH、W 為特征圖的高和寬,DDD 為通道數,rrr 為下采樣率。
代表性工作:InternVL系列、Qwen2系列、NVLM等,通過像素重排將視覺編碼器生成的token數量減少為原來的1/4,再通過MLP對齊視覺與文本的維度。
優勢:無額外參數,不增加模型權重。
-
空間池化/插值
直接對token進行二維下采樣,不改變通道維度,數學表達式為:
H×W×D→HS×WS×D H \times W \times D \to \frac{H}{S} \times \frac{W}{S} \times D H×W×D→SH?×SW?×D
其中,SSS 為下采樣因子。代表性工作:LLaVA-OneVision采用雙線性插值,LLaVA-Video使用平均池化,M3M^3M3 通過池化學習多粒度表示,在推理時用更少token保持性能。
優勢:可無訓練實現,直接作用于對齊后的token維度。
-
空間卷積(Spatial Convolution)
通過卷積操作學習局部信息抽象,同時降低空間維度,數學表達式為:
H×W×Din→HS×WS×Dout H \times W \times D_{in} \to \frac{H}{S} \times \frac{W}{S} \times D_{out} H×W×Din?→SH?×SW?×Dout?
其中,SSS 為步長(下采樣因子),Din、DoutD_{in}、D_{out}Din?、Dout? 為輸入/輸出通道數。
代表性工作:Honeybee的C-Abstractor模塊用卷積提取壓縮信息,MobileVLM的LDP模塊通過深度卷積減少75%的token。優勢:通過可學習權重捕捉更復雜的局部特征。
對比總結:
- 像素重排、池化、插值均為無參數操作,不增加權重開銷;卷積引入可學習參數,能更精細地抽象局部信息。
- 像素重排會改變通道維度,需后續MLP對齊文本維度;池化和插值可直接作用于對齊后的維度,無需額外處理。
- 壓縮率通常有限(常見為25%),受限于二維下采樣的特性。
1.2、基于相似性的圖像中心壓縮
這類方法通過度量token在隱空間中的相似性(如距離或相似度),合并相似token,保留代表性的“簇中心”token,從而減少冗余。核心思路是通過聚類或匹配算法識別語義相近的token,將其合并為單個代表性token,降低序列長度。
代表性工作:
- ToMe:在ViT的注意力和MLP模塊間插入token合并模塊,通過二分軟匹配合并相似token。
- FOLDER:在視覺編碼器的最后一個注意力塊中插入合并模塊,減少傳入LLM的token。
- DivPrune:將壓縮問題轉化為“最大-最小多樣性”問題,篩選內部差異最大的token子集。
- TopV:在LLM層中綜合特征的相似性和距離函數,直接在多模態表示空間中壓縮token。
優勢:能有效去除語義重復的token,保留關鍵信息。
局限性:過度合并可能丟失細粒度信息;聚類算法的復雜度可能引入額外計算開銷。
1.3、基于注意力的圖像中心壓縮
這類方法利用注意力機制的稀疏性,通過注意力分數篩選高重要性token,修剪低關注度token,分為編碼器內和解碼器內兩種策略。
-
編碼器內注意力(Attention in Encoder)
基于視覺Transformer(ViT)的注意力分數,在視覺編碼器內部篩選關鍵token,減少傳入LLM的數量。通常通過視覺token與[CLS] token的注意力分數選擇top-K token:
Tencoder=TopKk({Attention(vi,vcls)∣vi∈V}) \mathcal{T}_{\text{encoder}} = \text{TopK}_k\left(\left\{\text{Attention}(v_i, v_{cls}) \mid v_i \in \mathcal{V}\right\}\right) Tencoder?=TopKk?({Attention(vi?,vcls?)∣vi?∈V})其中,V\mathcal{V}V 為原始視覺token集,vclsv_{cls}vcls? 為[CLS] token。
代表性工作:- PruMerge:基于[CLS]注意力選擇簇中心,通過KNN合并低關注度token。
- VisionZip:保留高注意力token,聚類合并剩余token。
- VisPruner:先保留高注意力token,再通過多輪相似度修剪重復token,保留多樣性。
-
解碼器內注意力(Attention in Decoder)
利用LLM解碼器的注意力分數,在視覺token與文本token的聯合空間中篩選關鍵token。通過計算視覺token從所有其他token(視覺+文本)獲得的平均注意力分數選擇top-K token:
A ̄(vi)=1∣S∣∑sj∈SAttention(vi,sj),Tdecoder=TopKk({A ̄(vi)∣vi∈V}) \overline{A}(v_i) = \frac{1}{|\mathcal{S}|} \sum_{s_j \in \mathcal{S}} \text{Attention}(v_i, s_j), \quad \mathcal{T}_{\text{decoder}} = \text{TopK}_k\left(\left\{\overline{A}(v_i) \mid v_i \in \mathcal{V}\right\}\right) A(vi?)=∣S∣1?sj?∈S∑?Attention(vi?,sj?),Tdecoder?=TopKk?({A(vi?)∣vi?∈V})
其中,S\mathcal{S}S 為當前層注意力窗口中的所有token。
代表性工作:- FastV:在第二層后基于注意力分數修剪50%的視覺token,保持性能。
- ZipVL:通過解碼器注意力動態壓縮token,平衡效率與精度。
- SparseVLM:結合編碼器和解碼器注意力,篩選與文本相關的視覺token。
優勢:基于注意力的動態篩選能自適應保留任務相關token, interpretability(可解釋性)強。
局限性:需顯式計算注意力分數,與優化加速庫(如FlashAttention)不兼容,可能引入額外計算開銷。
1.4 基于查詢的圖像中心壓縮
這類方法利用文本查詢(prompt)引導視覺token壓縮,分為token蒸餾和跨模態選擇兩類,聚焦于保留與查詢相關的信息。
-
Token Distillation(token蒸餾)
將視覺token蒸餾為少量與文本相關的token,同時實現模態對齊。
代表性工作:- Q-Former系列:通過可學習查詢和交叉注意力提取與文本相關的視覺線索,壓縮為固定數量token。
- LLaMA-VID:用文本查詢聚合視覺嵌入中的文本相關線索,將整幅圖像表示為2個token。
- LLaVA-Mini:將視覺信息預融合到文本token中,僅需1個視覺token即可保持性能。
- Victor:引入少量可學習“寄存器token”,通過大模型淺層將視覺信息蒸餾到寄存器中,丟棄原始視覺token。
-
Cross-Modal Selection(跨模態選擇)
利用模態間的對齊關系,通過一種模態的token篩選另一種模態的關鍵token。
代表性工作:- SparseVLM:用視覺token預篩選相關文本token,縮小文本搜索空間。
- AdaFV:結合文本-圖像相似度和視覺顯著性,選擇語義對齊且視覺突出的token。
- TRIM:先通過文本-視覺相似度識別“離群token”(視為重要),再聚類合并剩余token。
優勢:壓縮后的token與查詢高度相關,適合任務驅動場景(如視覺問答)。
局限性:依賴文本查詢的質量;多輪對話中需重新計算壓縮,可能增加開銷。
2、以視頻為中心的Token壓縮
視頻數據因包含空間和時間維度的雙重信息,其token數量遠超靜態圖像(如90分鐘視頻可生成5400萬token),成為多模態大型語言模型(MLLMs)處理的主要瓶頸。視頻中心的token壓縮需同時解決空間冗余(同幀內相鄰區域的相似性)和時間冗余(連續幀間的重復性),該部分按底層機制分為四類方法,因為視頻的每一幀是圖像,因此圖像部分和前面是一樣的,重點看下針對時間維度的優化策略。
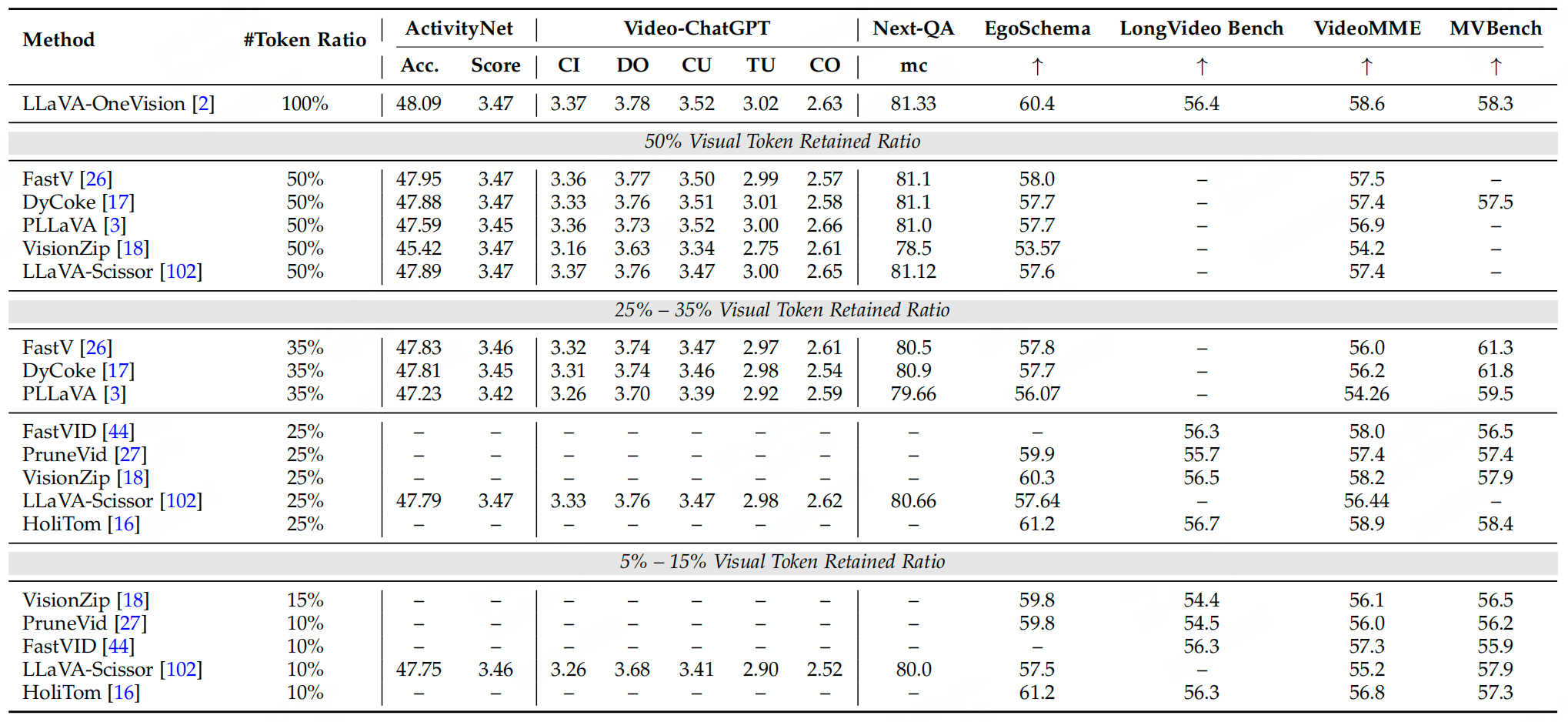
總結:
視頻中心的token壓縮需同時應對空間和時間冗余,核心策略包括:
- 變換方法通過時空池化/卷積直接減少token,適合保留全局結構;
- 相似性方法通過幀聚類合并時間冗余,效率高但需避免丟失動態信息;
- 注意力方法動態篩選關鍵token,可解釋性強但受限于加速庫兼容問題;
- 查詢方法聚焦任務相關幀,適合交互式場景。
2.1、基于Transformer的視頻中心壓縮
這類方法延續圖像壓縮中的變換思路,結合視頻的時間維度特性,通過池化或卷積操作減少token數量,核心是在空間壓縮基礎上增加時間維度下采樣。
-
2D/3D池化(2D/3D Pooling)
- 空間池化:對單幀圖像進行下采樣(如LLaVA-Video用平均池化減少單幀token),但對長視頻效果有限。
- 時間池化:針對視頻幀序列進行下采樣,降低幀率以減少時間維度的token。例如:
- PLLaVA、Video-ChatGPT、LongVLM等采用 temporal pooling(時間池化),實驗表明模型性能對時間池化更敏感。
- LLaMA-VID對單圖像保留原始分辨率,對視頻幀則壓縮為單個token,大幅減少數據量。
- 混合策略:SlowFast-LLaVA-1.5采用雙路徑架構——“慢路徑”采樣少量高分辨率幀,“快路徑”采樣更多低分辨率幀,拼接后輸入LLM,在減少token的同時保留時空細節。
-
2D/3D卷積(2D/3D Convolution)
與池化的簡單聚合不同,卷積通過學習濾波器捕捉時空特征并壓縮維度。例如: VideoLLaMA 2對比2D和3D卷積后發現,3D卷積能更好地學習復雜的時空關系,在性能和效率間取得平衡。
特點:
- 空間變換(池化/卷積)與圖像壓縮方法類似,時間變換是視頻特有的優化。
- 需平衡幀率/分辨率與信息保留(如24 FPS是捕捉完整動作的最低幀率,但實際常采用1 FPS采樣)。
2.2、基于相似性的視頻中心壓縮
針對視頻的時間冗余(相鄰幀高度相似),通過聚類或相似度匹配合并冗余幀或token,優先壓縮時間維度。核心思路主要包括:
- 對視頻幀進行聚類(基于幀級表示的相似度),合并非關鍵幀;
- 在聚類后的幀內進一步合并空間冗余token,最終保留“時空緊湊表示”。
- 代表性工作:
- Chat-UniVi:先將每幀池化為單個幀級token,再用DPC-KNN(基于K近鄰的密度峰值聚類)合并相似幀,最后在簇內對多幀token二次聚類,得到時空緊湊表示。
- PruneVid:與Chat-UniVi類似,但先合并時間上靜態的token(如靜止背景),再進行時空token合并,減少冗余。
- HoliTom:將時間冗余壓縮視為優化問題,最大化聚類幀內的可壓縮冗余特征,更全面地處理時間維度冗余。
- FrameFusion:針對流式視頻,在模型淺層直接合并超過相似度閾值的時間冗余token,適合實時處理。
優勢:通過聚類針對性減少時間冗余,壓縮效率高于單純空間壓縮。
局限性:過度合并可能丟失關鍵動態信息(如快速動作幀)。
2.3、基于注意力的視頻中心壓縮
利用注意力機制的稀疏性篩選重要token,與圖像壓縮思路類似,但需結合視頻的時序特性。
-
編碼器內注意力
將視頻視為獨立幀的序列輸入圖像編碼器,通過幀內注意力分數篩選高重要性空間token(如PruMerge、VisionZip)。但此類方法忽略幀間關系,本質仍是“圖像級壓縮”的擴展。 -
解碼器內注意力
在LLM解碼器中處理幀序列的拼接token,通過跨幀注意力捕捉時間關聯,并篩選關鍵時空token。例如:- FastV、ZipVL等延續圖像解碼器的注意力篩選策略,計算視頻token與文本查詢的交叉注意力,保留高相關token。
- 對長視頻采用窗口注意力(windowed attention),僅關注局部時間窗口內的幀,降低計算復雜度。
2.4、基于查詢的視頻中心壓縮
以文本查詢為引導,篩選與任務相關的關鍵幀或token,減少無關時序信息的冗余。
-
token蒸餾
通過專用適配器模塊(如Q-former、Token Turing Machines)將長視頻token蒸餾為少量緊湊表示:- Token Turing Machines(TTMs):維護外部“摘要token內存”,通過Transformer的讀寫機制逐幀壓縮輸入token與內存,支持長視頻的高效處理。
- BLIP-3-Video:用時間編碼器將數百幀的視覺token抽象為16–32個時空token,平衡效率與信息保留。
- LinVT:通過線性視頻tokenizer,結合時空評分和文本條件聚合,將幀級token壓縮為緊湊視頻token,使圖像LLM可直接處理視頻。
-
跨模態選擇
基于查詢與視頻幀的相關性動態調整壓縮率,保留關鍵幀的更多信息:LongVU:計算每幀與查詢的相關性分數,對高相關幀采用低壓縮率(保留更多token),低相關幀采用高壓縮率,確保總token數在模型上下文窗口內。
優勢:聚焦查詢相關的時空信息,適合視頻問答、行為識別等任務。
局限性:依賴查詢質量,對無明確任務的場景(如視頻摘要)適用性有限。
3、以音頻為中心的Token壓縮
音頻數據作為多模態輸入的重要組成部分,其token數量隨采樣率和時長增加而顯著增長,給MLLMs的高效處理帶來挑戰。音頻信號本質是時間維度上的振幅變化(1D信號),通常通過頻譜圖(如梅爾頻譜圖)轉換為類圖像的2D表示,以便復用視覺處理技術。音頻中心的token壓縮需解決時間冗余(如長靜音段)和頻譜冗余(如特定頻率的重復信號),該部分也分為四類方法。
3.1、基于Transformer的音頻中心壓縮
這類方法通過下采樣操作直接減少音頻token數量,借鑒圖像壓縮中的變換思路,針對音頻的時間或頻譜維度進行壓縮。
-
token堆疊
類似圖像的“像素重排”操作,將連續的多個音頻token沿隱藏維度堆疊,減少總token數。例如:- HTS-AT最早將梅爾頻譜圖的2D特征通過像素重排減少音頻token;
- SLAM-ASR、LLaMA-Omni等采用該技術,通過堆疊調整隱藏維度后,需用MLP對齊其他模態的維度。
-
Pooling(池化)
直接對音頻序列進行時間維度下采樣,無額外參數。例如:- Qwen2-audio、Qwen2.5-Omni使用步長為2的池化層,直接縮短音頻表示長度;
- Llama-MTSK采用“套娃式(matryoshka)”訓練,通過多尺度平均池化或堆疊,實現推理時動態調整token數量,平衡壓縮率與性能。
-
時間卷積
用1D卷積在時間維度上壓縮token,同時調整隱藏維度以適配后續LLM。例如: SpeechVerse、Baichuan-Audio等采用該技術,下采樣后音頻表示的有效采樣率通常為12.5 Hz,在減少token的同時保留關鍵時序特征。
特點:Transformer的方法均通過降低時間或頻譜維度減少token,其中池化和堆疊為無參數操作,卷積通過學習權重捕捉更復雜的局部特征。
3.2、基于相似性的音頻中心壓縮
通過度量音頻token的相似度,合并冗余token,保留獨特信息。核心思路類似視覺領域的ToMe方法,在音頻Transformer的層間插入token合并模塊,合并高相似度的相鄰token(如通過余弦相似度度量)。
- 代表性工作: A-ToMe:在多頭自注意力(MHSA)和前饋網絡(FFN)之間插入模塊,合并余弦相似度高的相鄰音頻token,減少冗余。
優勢:針對性去除時間或頻譜上的重復信息,適合處理包含長靜音或固定背景噪聲的音頻。
局限性:過度合并可能丟失短時關鍵信號(如突發聲音)。
3.3、基于注意力的音頻中心壓縮
利用注意力機制的稀疏性,通過注意力分數篩選高重要性token,修剪低關注度token。
-
編碼器內注意力
在音頻Transformer塊中,基于自注意力分數保留top-K token。例如: Top-K:直接保留音頻頻譜圖Transformer中注意力分數最高的K個token,聚焦關鍵頻譜特征。 -
解碼器內注意力
在LLM解碼器中,基于音頻token與文本token的交叉注意力分數篩選關鍵token。例如:SpeechPrune:利用LLM第一層的注意力分數,在處理早期修剪低重要性音頻token,減少后續計算量。
優勢:動態適配音頻內容的重要性,保留與任務相關的關鍵信號(如語音中的關鍵詞)。
局限性:需顯式計算注意力分數,與優化加速庫(如FlashAttention)兼容性差,可能增加額外開銷。
3.4、基于查詢的音頻中心壓縮
以文本查詢或其他模態信息為引導,壓縮與任務無關的音頻token,分為token蒸餾和跨模態選擇兩類。
-
token蒸餾
用可學習查詢token提取音頻的關鍵信息,壓縮為固定長度的緊湊表示。例如:- Video-LLaMA、SALMONN系列:通過音頻Q-former將變長音頻輸入轉換為固定長度的可學習查詢序列,供LLM處理;
- MMCE-Qformer:結合全局聲學上下文(通過可學習查詢提取)和局部文本相關聲學特征(通過文本引導的交叉注意力),蒸餾出緊湊的音頻表示;
- MMS-LLaMA:先通過“早期音視頻融合模塊”減半序列長度,再用AV Q-Former進一步壓縮為固定數量的查詢token,捕捉完整語音上下文。
-
跨模態選擇
利用音頻與其他模態(如文本)的相關性篩選關鍵token。例如:SpeechPrune:計算音頻-文本的余弦相似度矩陣,基于跨模態相關性修剪無關音頻token,保留語義重要的片段。
優勢:壓縮后的token與查詢高度相關,適合語音識別、音頻問答等任務。
局限性:依賴查詢質量,對無明確任務的場景(如音頻摘要)適用性有限。
總結:音頻中心的token壓縮針對時間和頻譜冗余,核心策略包括:
- 變換方法通過堆疊、池化或卷積直接減少token,適合保留全局時序結構;
- 相似性方法合并高相似度token,有效去除重復信號;
- 注意力方法動態篩選關鍵token,可解釋性強但受限于加速庫兼容性;
- 查詢方法聚焦任務相關音頻信息,適合交互式場景。
參考文獻:When Tokens Talk Too Much: A Survey of Multimodal Long-Context Token Compression across Images, Videos, and Audios,https://arxiv.org/pdf/2507.20198
:MultipartResolver - 文件上傳的幕后指揮官)

》免費中文翻譯 (第3章) --- Data transformation(1))



)





簡介與簡單示例)

)
Day14——性能監控與調優(一))



