【小白量化智能體】應用6:根據通達信指標等生成機器學習Python程序
【小白量化智能體】是指能夠自主或半自主地通過與環境的交互來實現目標或任務的計算實體。智能體技術是一個百科全書,又融合了人工智能、計算機科學、心理學和經濟學等多個領域的知識,能夠在復雜環境中自主決策和行動的實體。能夠實現量化投資的各方面應用,例如自動設計指標,自動編寫Python自動交易策略等等。
【小白量化智能體】能夠通過中文描述,轉化為指標公式和Python程序,以及生成機器學習程序。
如果自己不會寫Python策略,去定做一個指標公式是需要3位數,定做一個策略需要花費4位數。花錢是次要的,你能保證你的技術公式和策略是100%準確嗎?
大家知道,失敗是成功之母,我相信你的努力嘗試100次失敗后,最終會做出成功的策略。問題是你有100個4位數的開發資金嗎?
【小白量化智能體】能夠1分鐘內寫出交易指標公式,1秒鐘生成各種Python策略。每天可以生成無數個策略,開發成本就是電費。
我們下面給大家介紹根據通達信公式并生成機器學習Python程序的過程。
一、通達信指標公式生成機器學習Python程序
打開小白量化智能體,點按鈕【機器學習】:
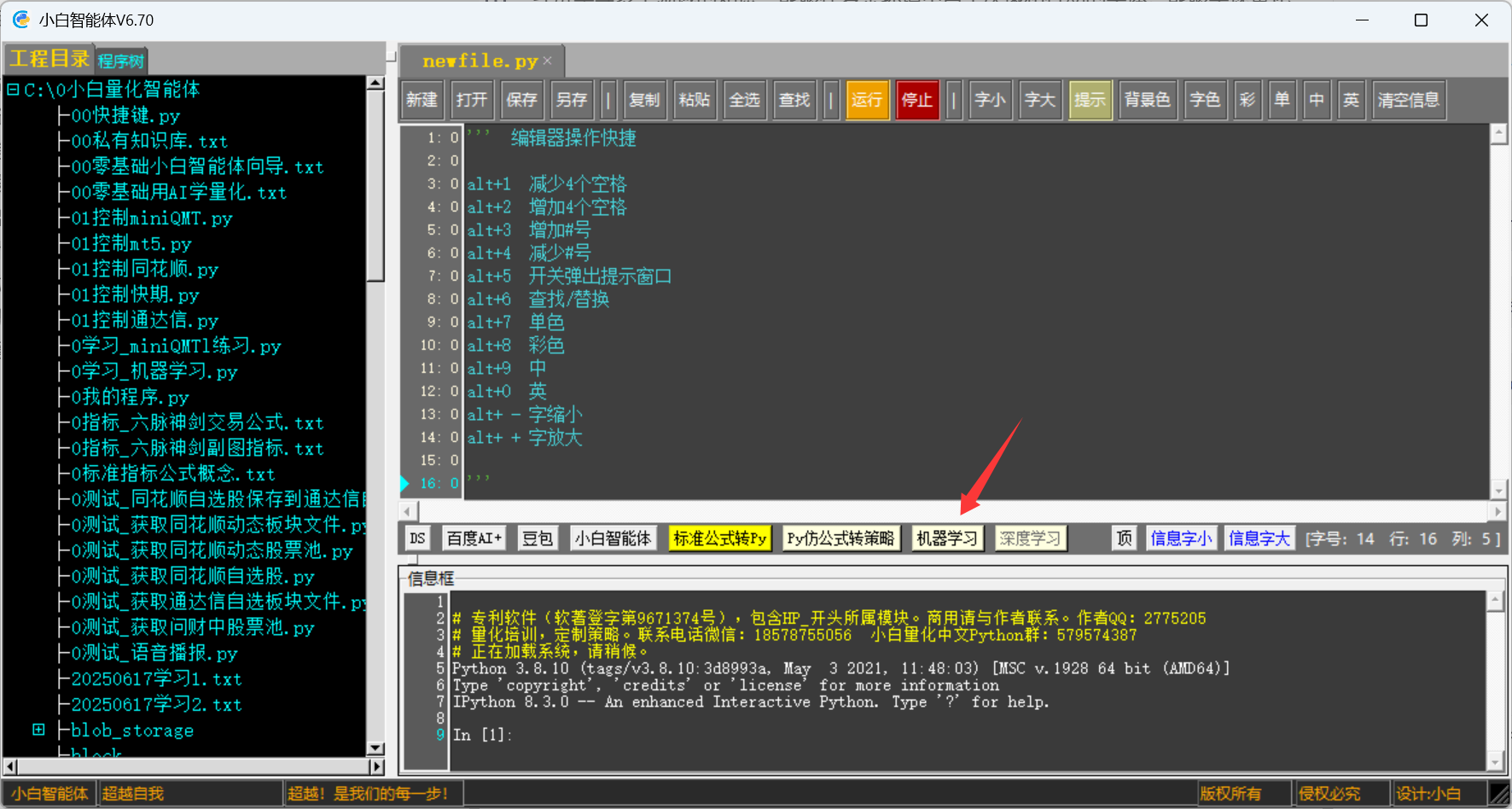
在彈出窗口中選擇一個機器學習算法。
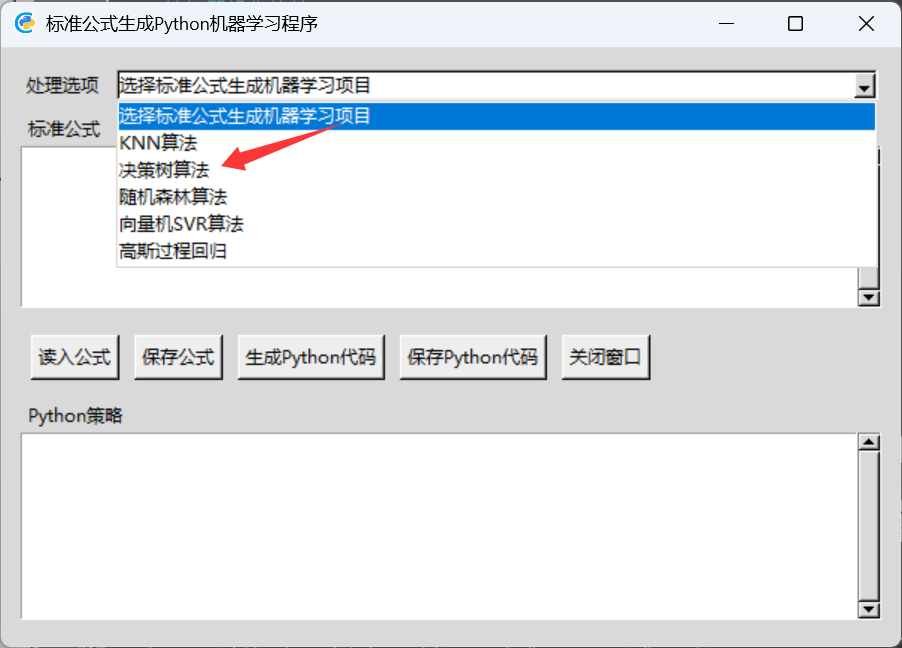
然后輸入一個指標公式,點【生成Python代碼】。
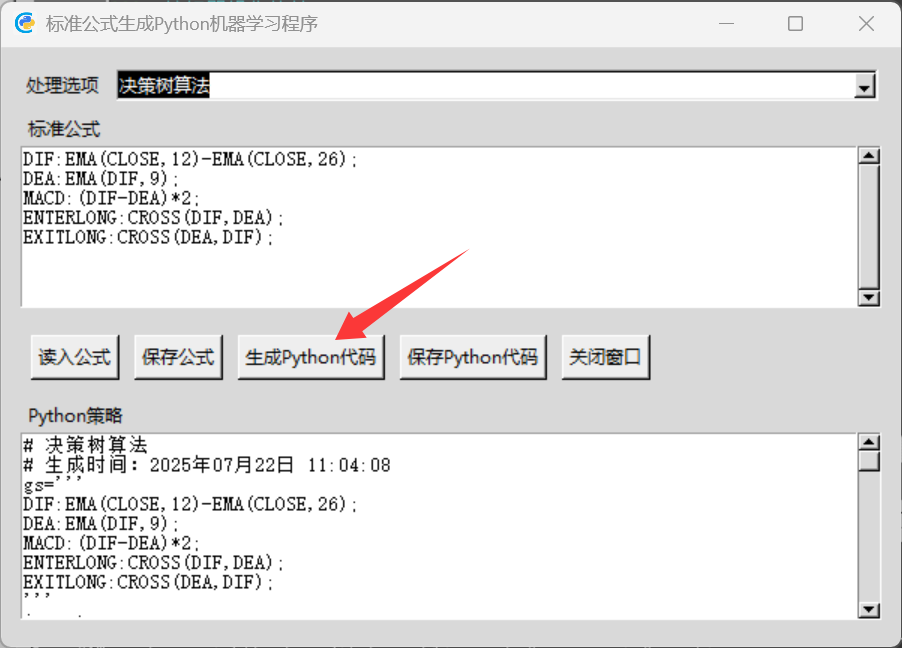
自動把指標公式作為分析因子生成一個機器學習Python代碼。
# 決策樹算法
# 生成時間:2025年07月22日 11:04:08
gs='''
DIF:EMA(CLOSE,12)-EMA(CLOSE,26);
DEA:EMA(DIF,9);
MACD:(DIF-DEA)*2;
ENTERLONG:CROSS(DIF,DEA);
EXITLONG:CROSS(DEA,DIF);
'''
import os,sys
sys.path.append(os.path.abspath('.'))
sys.path.append(os.path.abspath('..'))
import math,joblib
import datetime,time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from HP_formula import * #小白量化仿通達信公式函數庫
import HP_tdx as htdx#小白通達信行情庫
import HP_formula as hgs #小白通達信公式庫
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_errorplt.rcParams['font.sans-serif']=['SimHei'] #用來正常顯示中文標簽
plt.rcParams['axes.unicode_minus']=False #用來正常顯示負號tdxapi=htdx.TdxInit(ip='183.60.224.178',port=7709)#(nCategory, nMarket, sStockCode, nStart, nCount)
#獲取市場內指定范圍的證券K 線,
#指定開始位置和指定K 線數量,指定數量最大值為800。
#參數:
#nCategory -> K 線種類
#0 5 分鐘K 線
#1 15 分鐘K 線
#2 30 分鐘K 線
#3 1 小時K 線
#4 日K 線
#5 周K 線
#6 月K 線
#7 1 分鐘
#8 1 分鐘K 線
#9 日K 線
#10 季K 線
#11 年K 線
#nMarket -> 市場代碼0:深圳,1:上海
#sStockCode -> 證券代碼;
#nStart -> 指定的范圍開始位置;
#nCount -> 用戶要請求的K 線數目,最大值為800。
m=0
code='000002'
today=time.strftime('%Y-%m-%d',time.localtime(time.time()))
df=htdx.get_bars(nCategory=4,nMarket =m,code=code,start='1991-01-01',end=today)#小白數據規格化
mydf=initmydf(df) ##初始化mydf表
mydf=mydf.reset_index(level=None,drop=True,col_level=0,col_fill='')
C=CLOSE=mydf['close']
L=LOW=mydf['low']
H=HIGH=mydf['high']
O=OPEN=mydf['open']
V=VOL=mydf['volume']
from HP_formula import * #小白股票指標公式函數庫tgs1=hgs.Tdxgs()
tgs1.loaddf(mydf)
mydf=tgs1.rungs(gs)mydf['ZF']=(C-REF(C,1))/(REF(C,1)+0.000000001) #漲幅
mydf['label']=REF(mydf['ZF'],-1) #明日漲幅## 數據整理
mydf.dropna(inplace=True) ##刪除無效數據
mydf=mydf.reset_index(level=None,drop=True,col_level=0,col_fill='')
print(mydf)
#mydf.to_csv('ls.csv' , encoding= 'gbk')
# 將日期時間列轉換為數值類型
for col in ['datetime', 'date', 'date2']:mydf[col] = pd.to_datetime(mydf[col]).astype('int64')# 提取特征和目標變量
X = mydf.drop([ 'label'], axis=1)
y = mydf['label']# 劃分訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)##################################################
from sklearn.tree import DecisionTreeRegressor
#構建決策樹回歸器
clf = DecisionTreeRegressor()# 在訓練集上訓練模型
clf.fit(X_train, y_train)# 在測試集上進行預測
y_pred = clf.predict(X_test)# 計算模型的均方誤差
mse = mean_squared_error(y_test, y_pred)
print(f'模型的均方誤差:{mse}')#print(list(y_test)[-5:],'\n', list(y_pred)[-5:])## 保存模型
## 模型和數據文件路徑
MODEL_PATH = 'model.pkl'
joblib.dump(clf, MODEL_PATH)
print(f'模型已保存到: {MODEL_PATH}')二、在《小白量化智能體》軟件中運行程序
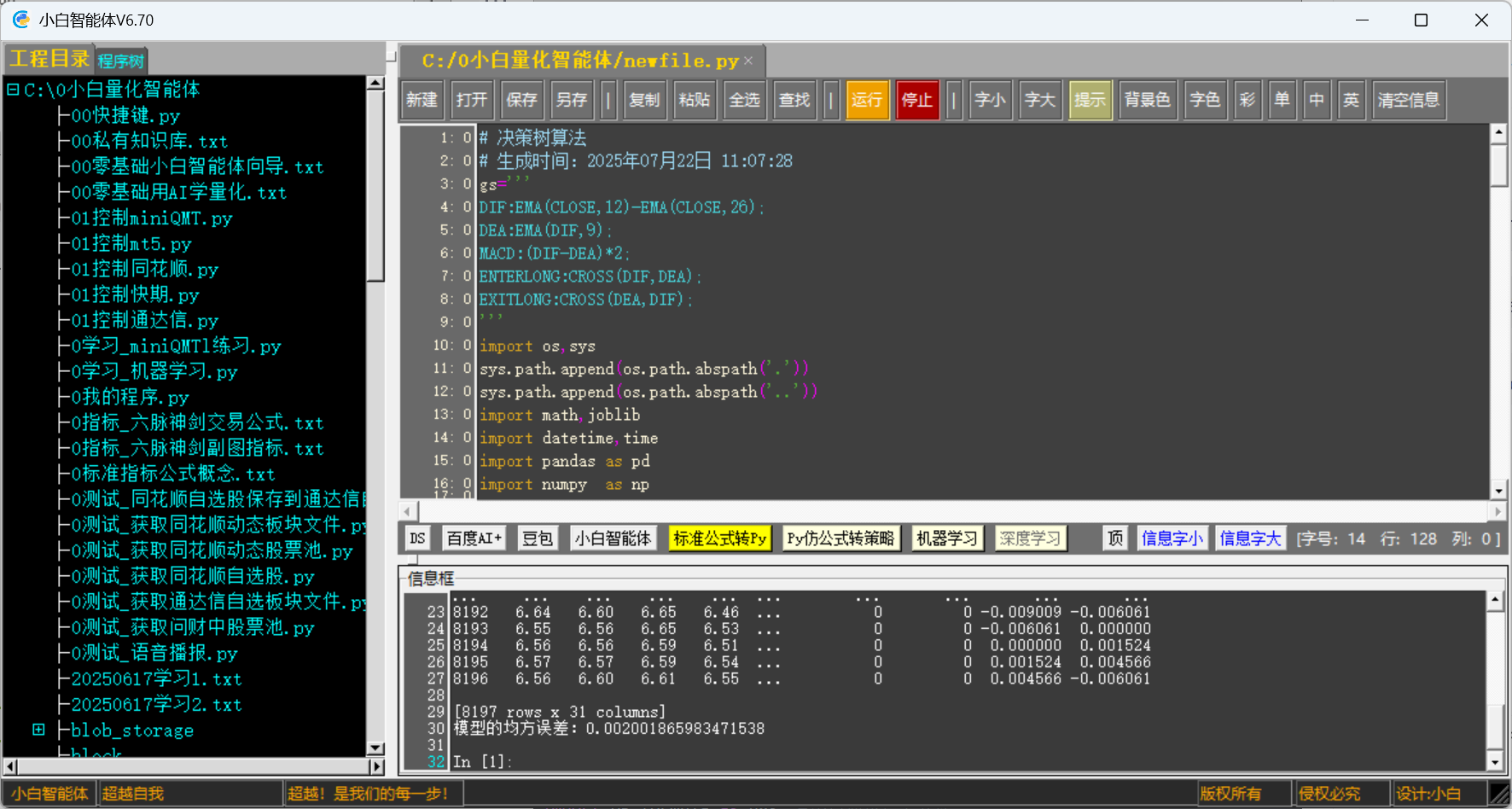
機器學習的模型及結果保存到文件 'model.pkl’中。
三、在用策略中使用機器學習模型
如果機器學習預測有效,可以在策略中直接使用訓練好的機器模型數據,不用重新進行機器學習。下面是使用訓練好的機器模型數據的代碼。
## 加載模型
clf2 = joblib.load(MODEL_PATH)
print(f'模型已從 {MODEL_PATH} 加載')# 在訓練集上訓練模型
clf2.fit(X_train, y_train)# 在測試集上進行預測
y_pred = clf2.predict(X_test)# 計算模型的均方誤差
mse = mean_squared_error(y_test, y_pred)
print(f'模型的均方誤差:{mse}')
上面給出了自動生成機器學習Python程序的示例。
我們可以嘗試使用更多的因子,更多的數據進行訓練。
也可以選擇不同的機器學習模型,實現自己的目的。
《小白量化智能體》相當一位計算機本科生免費幫你寫指標公式,免費寫策略,輔助你做機器學習、深度學習量化研究。
本身是支持中文Python語法和西文Python語法的集成開發工具,適合7歲-70歲人都適合學習中文Python編程。
今天的文章先寫到這里,歡迎繼續關注我的博客。后面我還介紹更多的【小白量化智能體】開發Python策略的知識。
超越自己是我的每一步!我的進步就是你的進步!



![[C/C++內存安全]_[中級]_[安全處理字符串]](http://pic.xiahunao.cn/[C/C++內存安全]_[中級]_[安全處理字符串])








)






