1.卷積
1.局部連接
定義:只是于輸入數據的一部分區域相連,每個神經元只關注一小部分
作用:模仿人類的視野機制,極大的減少了模型參數的數量,降低了計算成本
2.權重共享
定義:所有神經元使用相同的權重向量來檢測輸入數據的不同局部區域。換句話說,卷積核(濾波器)在整個輸入上滑動時,其內部的權重保持不變。
作用:不僅進一步減少了模型參數的數量,提高了計算效率,還賦予了模型平移不變性(translation invariance),意味著無論某個特征出現在圖像的哪個位置,模型都能識別它。這使得CNN非常適合處理具有平移不變性的任務,如圖像分類。
3.池化
定義:減少特征圖的空間尺寸,從而降低計算復雜度并控制過擬合。最常見的形式是最大池化(Max Pooling),它通過取每個固定大小子區域的最大值來縮小特征圖的尺寸。
作用:減少維度外,池化還能提供某種程度的位置不變性,因為它減少了輸出對輸入中小變化的敏感性。
1.1 卷積運算
滑動卷積核,在每個局部區域先乘再和,最終生成特征圖,輸出標量。
代碼實現二維卷積算子
import torch
import torch.nn as nn# 定義輸入矩陣和卷積核
input_matrix = torch.tensor([[1., 2., 3.],[4., 5., 6.],[7., 8., 9.]
], dtype=torch.float32) kernel = torch.tensor([[0., 1.],[2., 3.]
], dtype=torch.float32) # 將輸入擴展為四維張量
input_tensor = input_matrix.view(1, 1, 3, 3) # 創建卷積層(
conv_layer = nn.Conv2d(in_channels=1,out_channels=1,kernel_size=2,bias=False # 禁用偏置項
)# 手動設置卷積核權重
conv_layer.weight.data = kernel.view(1, 1, 2, 2)# 執行卷積操作
output = conv_layer(input_tensor)# 輸出結果
result = output.squeeze().detach() print("卷積結果:\n", result)
1.2 權重共享
這個卷積核包含了一組權重,用于從輸入數據中提取特征。通過權值共享,網絡能夠在不同的輸入位置之間共享計算和參數,從而大大減少模型參數的數量,提高網絡的泛化能力。
減少模型的參數數量,降低了過擬合風險,因為使用了相同的權重和偏置,所以實現平移不變性。且更加簡潔
1.3 卷積之步長
假設有一個大小為5×5的輸入圖像(為了簡化問題,不考慮顏色通道等復雜情況),而卷積核的大小是3×3。
如果步長設置為1,那么卷積核就從左上角開始,每次向右移動1個單位,當到達圖像邊緣后,向下移動1個單位,繼續向右掃描。這樣在橫向和縱向都會有很多重疊的計算區域,最終得到的輸出特征圖尺寸較大,會得到一個3×3的矩陣,可以捕捉到更密集的空間細節。
若步長設置為2,則卷積核在每次移動時會跳過1個單位(因為步長是2),這樣輸出特征圖的尺寸就會減小,會得到一個2×2的矩陣,計算量也會相應減少。較大的步長容易導致特征圖中信息的稀疏,但可以有效降低模型的復雜度。
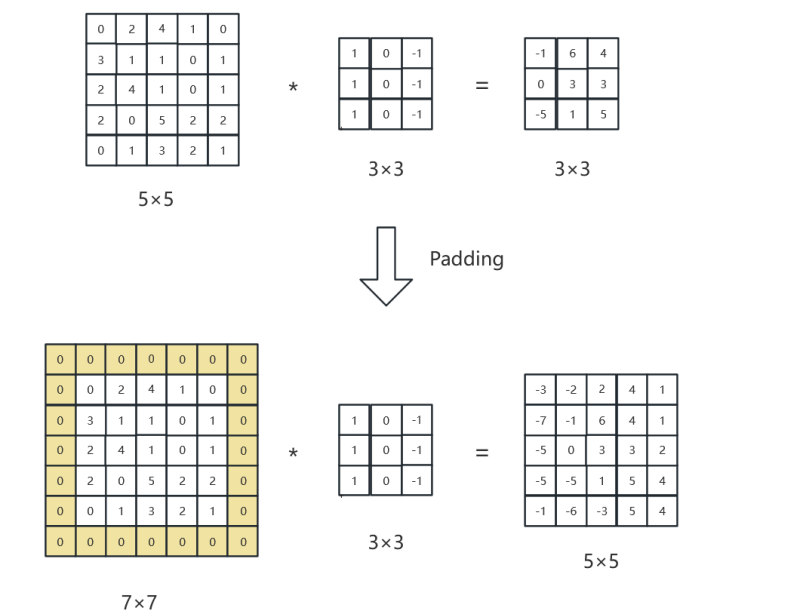
2.4 卷積的Padding邊緣填充
保持輸入和輸出圖像尺寸保持一致性。
?
?卷積之后的特征圖大小可以通過一個具體的公式來計算。假設輸入圖像的尺寸是 W×H(寬度和高度),卷積核的大小是 F×F,步長(stride)為 S,填充(padding)大小為 P,則輸出特征圖的尺寸 W×H 可以通過以下公式計算:
?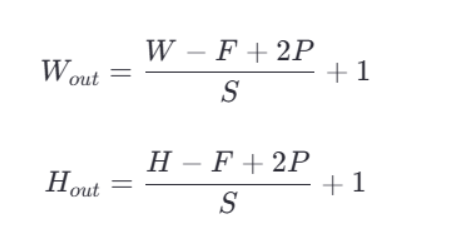







)








積分推導)


