本篇文章記錄近期嘗試在個人筆記本上、全離線狀態下搭建知識庫的流程。用到的工具包括:Cherry Studio、ollama。主要過程是:首先下載ollama用于管理大模型;然后,從魔塔社區下載需要的deepseek、千問大模型和bge-m3嵌入模型,導入到ollama;最后在cherry studio構建知識庫進行配置和使用。
搭建私人知識庫能讓知識管理更高效,實現集中存儲與分類整理;使知識檢索更便捷,可快速精準查詢;特別是全離線狀態下能增強數據安全與隱私保護,讓個人自主掌控數據。
ollama下載與使用
第一步是下載ollama[1],Ollama是一個開源的大型語言模型服務工具,能讓用戶在本地計算機上便捷地部署和運行多種先進的語言模型,如Qwen、Llama、DeepSeek - R1等。它提供簡單的命令行界面和API,支持模型微調與自定義,具有多平臺支持、性能優化、數據隱私保護等特點,適用于開發與測試、研究與學習、企業級應用等多種場景。
模型管理
# 拉取模型
# 如ollama pull llama2,其作用是從 Ollama 庫中下載指定模型。
ollama pull <模型名稱>
# 刪除本地模型
# ollama rm <模型名稱>,例如ollama rm llama2,能將本地的指定模型刪除。
ollama rm <模型名稱>
# 模型運行
# 如ollama run llama2,可以開啟與指定模型的交互會話,在會話中能輸入問題并獲取模型的回答。
ollama run <模型名稱>下載完后,打開命令行工具,使用ollama pull 命令就可以直接把需要的名字拉取過來,下載完成后,使用ollama run 命令,可以在命令行運行起來大模型了。
模型下載
由于我們想在離線狀態下部署、安裝和使用,所以我們不使用上述命令拉取。魔塔社區類似hugging face,里面匯集了很多模型和數據文件。
我們從魔塔社區下載模型,注意ollama導入模型的文件格式是guff格式。以deepseekR1 7B蒸餾版為例,我們可以從連接[2]下載到guff格式的模型。這里我用的是4.66GB 版本的模型,在我的筆記本上可以跑起來。
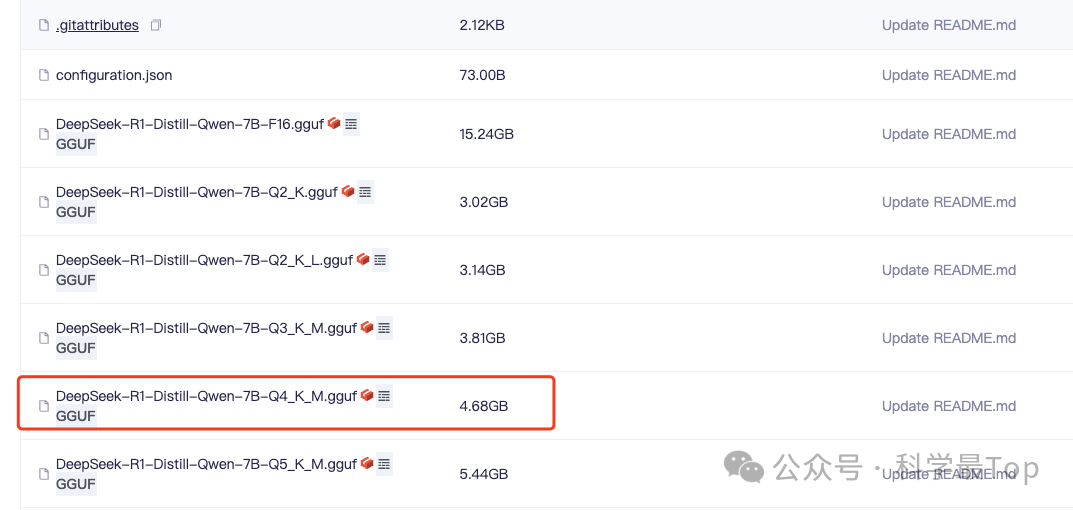
此外,由于我們構建知識庫,還需要把知識庫文件轉換為向量,因為還要使用嵌入模型,這里我們也是從魔塔社區下載bge-m3[3]下載guff格式的嵌入模型。至此,我們需要的模型文件就下載好了,一個7B的大模型和一個嵌入模型。
下一步,我們需要把從魔塔社區下載的模型導入到ollama平臺,不過在此之前要新建一個modelfile文件,里面寫入模型的存儲路徑,下圖是一個千問7B的例子。
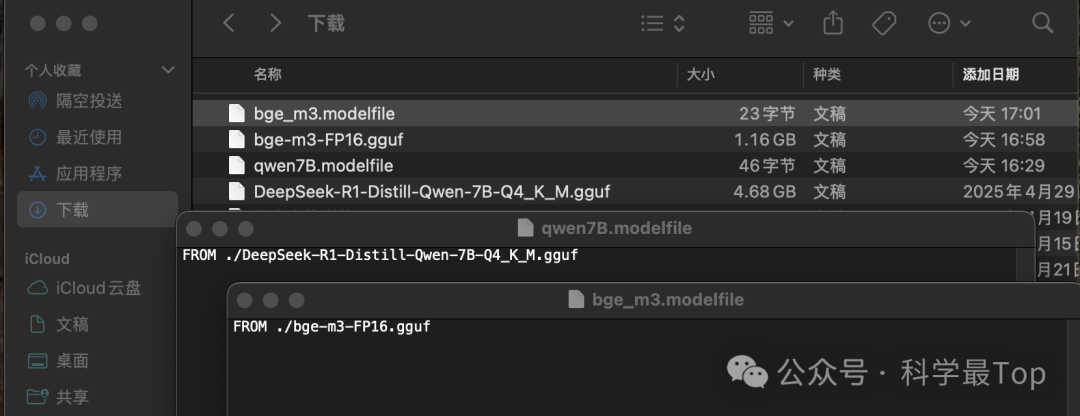
我們為qwen:7B大模型和bge-m3嵌入模型新建好modelfile文件,然后在當前目錄下使用以下命令,把兩個模型導入到ollama平臺。create 后面跟著的是你定義的模型的名字,可以自己靈活定義;-f后面跟著的是modelfile的文件名。
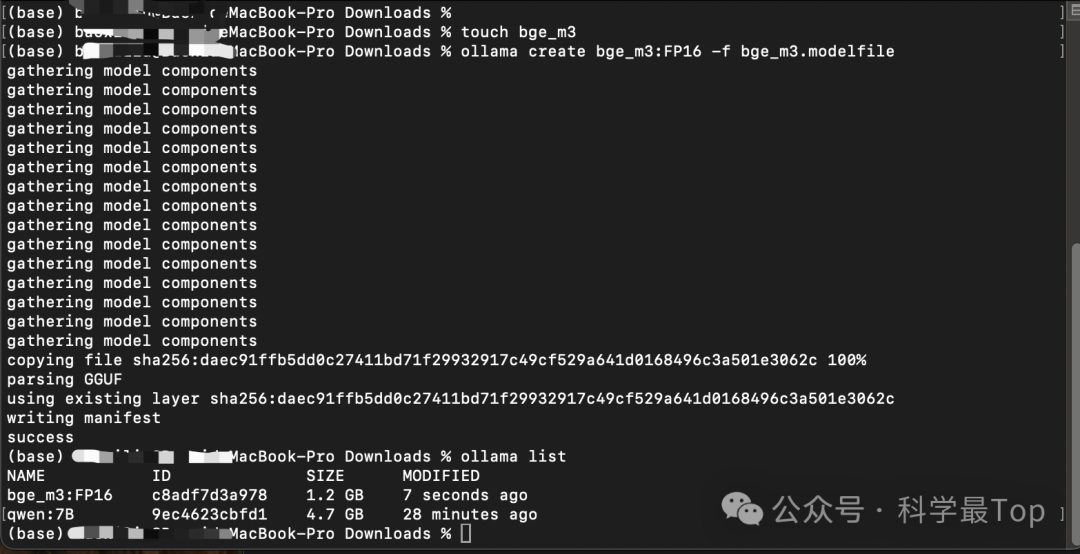
ollama create bge_m3:FP16 -f bge_m3.modelfile
ollama create qwen:7B -f qwen7B.modelfile導入成功后的截圖如下所示,并且通過ollama list命令可以看到當前ollama平臺擁有的模型。
使用cherry studio離線構建個人知識庫
在cherry studio 官網[4]下載客戶端,下載完成后,按照如下步驟操作。
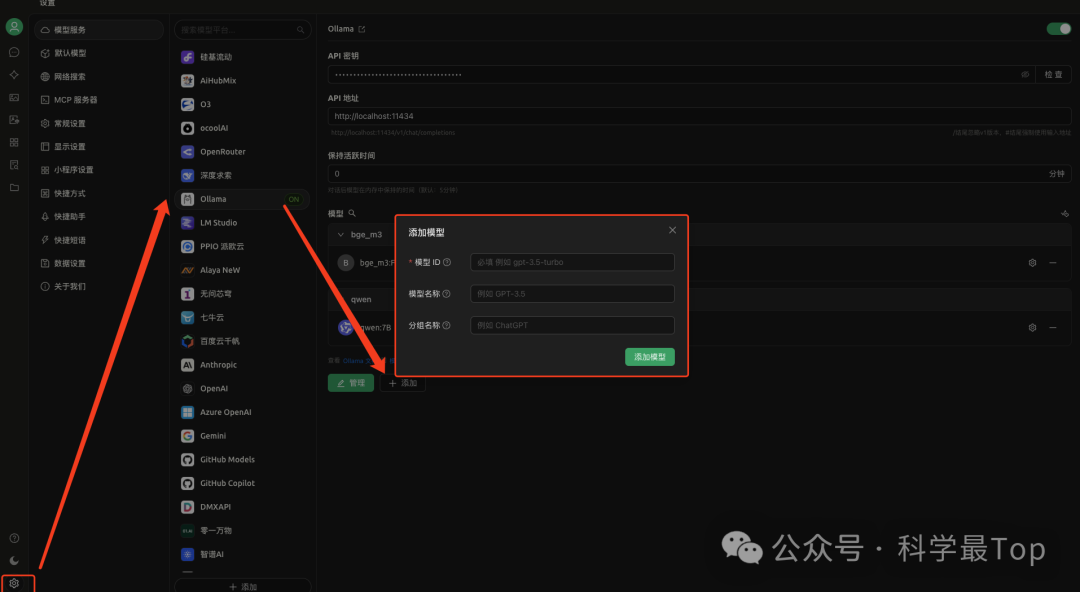
首先:點擊左下角設置按鈕,選擇ollama,打開右上角的開關,打開后如圖所示會出現‘ON’的字樣。
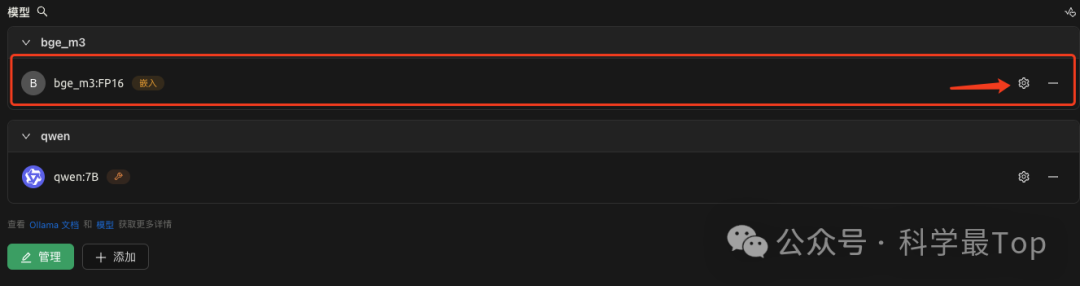
然后:點擊下方出現的管理模型,在模型ID處填寫ollama list 列表中出現的模型名字。例如我這里是qwen:7B,點擊添加模型。
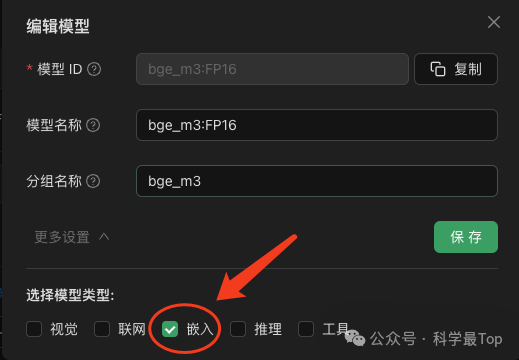
注意:如果是添加的bge_m3嵌入模型,則點擊設置按鈕,如下圖把模型類型選擇為嵌入類型。
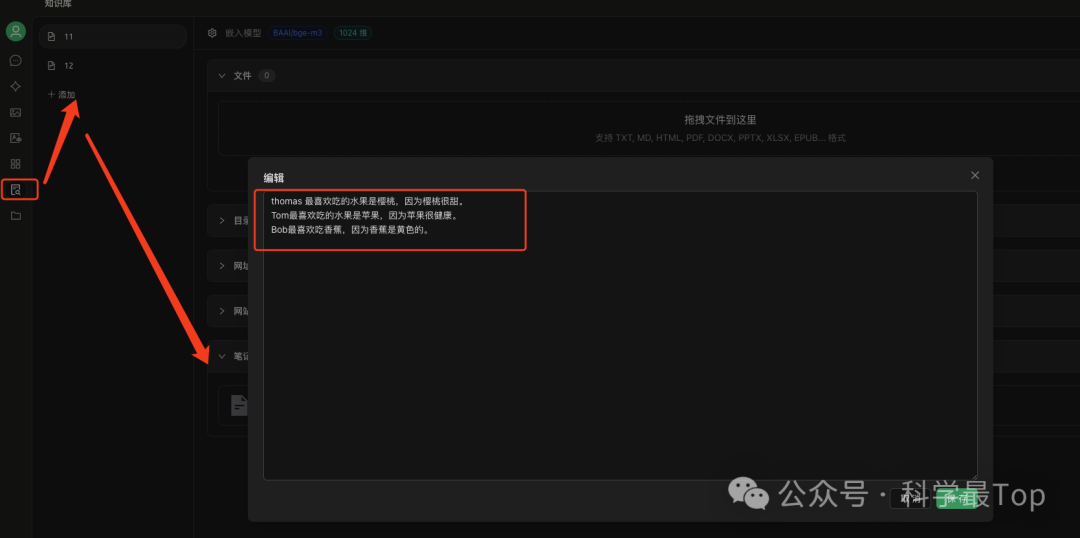
最后:我們新建知識庫,知識庫這里可以添加各類文件、為了簡單我這里只添加了三條筆記,如下圖所示。
知識庫使用
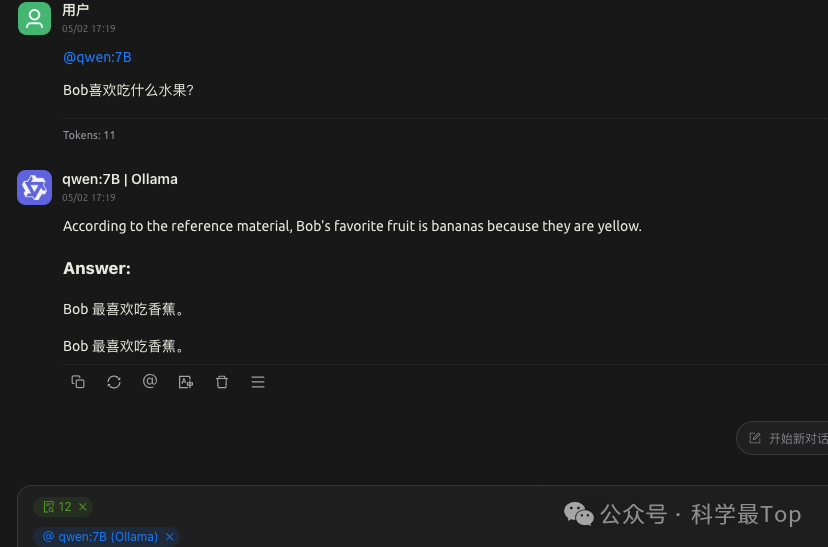
如上圖所示,我們選擇新建的知識庫12和導入的7B模型,通過對話詢問Bob最喜歡吃的水果,模型通過知識庫檢索回答了正確的答案。
參考鏈接:
https://ollama.com/
https://www.modelscope.cn/models/unsloth/DeepSeek-R1-Distill-Qwen-7B-GGUF/files
https://www.modelscope.cn/models/gpustack/bge-m3-GGUF/files
https://www.cherry-ai.com/






)




)





技術解析)

)